目录
一、概述
1、脚本就是将手动一次性执行的命令进行规范且自动化
2、学习路径
2.1表达式
2.2语句
2.3函数
2.4正则表达式
2.5文件操作四剑客
二、表达式
1、shell
2、表达式
2、1 变量
2、2 运算符
2、3shell脚本编写规范
2、4shell运行规则
2、5shell脚本运行追踪
2、6$[$RANDOM%100]
2、7 seq 1 10
2、8{1,,10}
2、9seq 1.1 10.1
3、read -p "提示语" 变量名
3.1语句
3.2文件操作四剑客
一、概述
1、脚本就是将手动一次性执行的命令进行规范且自动化
2、学习路径
2.1表达式
变量
预定义变量
位置变量
自定义变量
运算符
数学运算
数值比较
字符串比较
文件判断
布尔运算符
2.2语句
条件语句 if
分支语句 case
循环语句 for
while
2.3函数
2.4正则表达式
标准正则
扩展正则
2.5文件操作四剑客
find
egrep
sed
awk
二、表达式
1、shell
shell命令解释环境
类型
sh
ash
bsh
csh
bash
tcsh
dsh
zsh
登录后默认使用的shell程序,一般为/bin/bash
不同shell的内部指令、运行环境等会有所不同
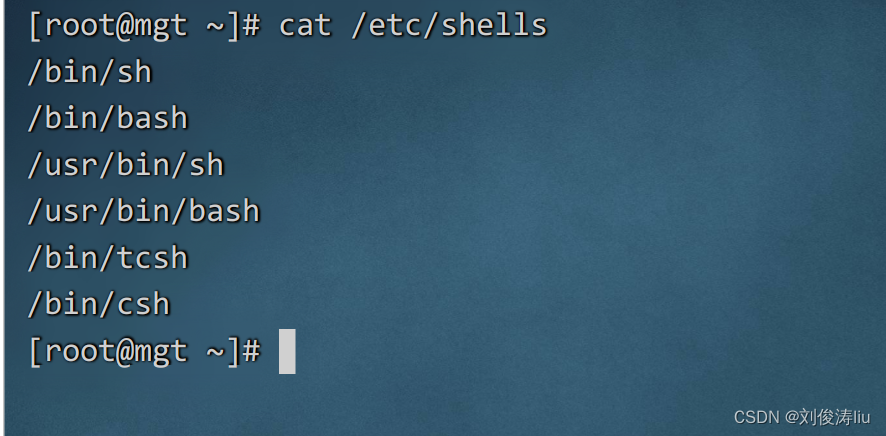
查看系统中支持的shell cat /etc/shells
cat /etc/shells
查看系统默认shell echo $SHELL
echo $SHELL
locale
还有一个命令locale查看所有的编码集

这是与语言和区域设置相关的环境变量设置,用于定义系统的地理和文化特性。
具体意义如下:
- `LANG=zh_CN.UTF-8`: 指定系统的语言环境为中文(中国),字符编码为UTF-8。
- `LC_CTYPE="zh_CN.UTF-8"`: 设置字符集的区域环境为中文(中国),字符编码为UTF-8。
- `LC_NUMERIC="zh_CN.UTF-8"`: 设置数字格式的区域环境为中文(中国),字符编码为UTF-8。
- `LC_TIME="zh_CN.UTF-8"`: 设置时间格式的区域环境为中文(中国),字符编码为UTF-8。
- `LC_COLLATE="zh_CN.UTF-8"`: 设置字符串排序的区域环境为中文(中国),字符编码为UTF-8。
- `LC_MONETARY="zh_CN.UTF-8"`: 设置货币格式的区域环境为中文(中国),字符编码为UTF-8。
- `LC_MESSAGES="zh_CN.UTF-8"`: 设置消息和输出的区域环境为中文(中国),字符编码为UTF-8。
- `LC_PAPER="zh_CN.UTF-8"`: 设置纸张和打印格式的区域环境为中文(中国),字符编码为UTF-8。
- `LC_NAME="zh_CN.UTF-8"`: 设置名称和个人信息的区域环境为中文(中国),字符编码为UTF-8。
- `LC_ADDRESS="zh_CN.UTF-8"`: 设置地址格式的区域环境为中文(中国),字符编码为UTF-8。
- `LC_TELEPHONE="zh_CN.UTF-8"`: 设置电话号码格式的区域环境为中文(中国),字符编码为UTF-8。
- `LC_MEASUREMENT="zh_CN.UTF-8"`: 设置度量单位的区域环境为中文(中国),字符编码为UTF-8。
- `LC_IDENTIFICATION="zh_CN.UTF-8"`: 设置身份证明和标识符的区域环境为中文(中国),字符编码为UTF-8。
- `LC_ALL=`: 这个环境变量可以用来覆盖前面提到的所有区域环境设置。这些环境变量设置可以影响到程序的输出、日期时间格式、字符排序等方面,以适应特定语言和地区的需求。
2、表达式
2、1 变量
⑴ 组成
变量名
不会变化
杯子
瓢
容器...
声明规范
不能是数字或数字开头
以_或字母开头
变量名中不能包含特殊字符
声明方法
驼峰式 userName
双驼峰 UserName
shell写法 user_name
username
USERNAME
shell脚本中大写变量为常量,一般为不动
变量值
不断变化 承载的物体
数字、字符
⑵类型
系统内置变量(环境变量) env
env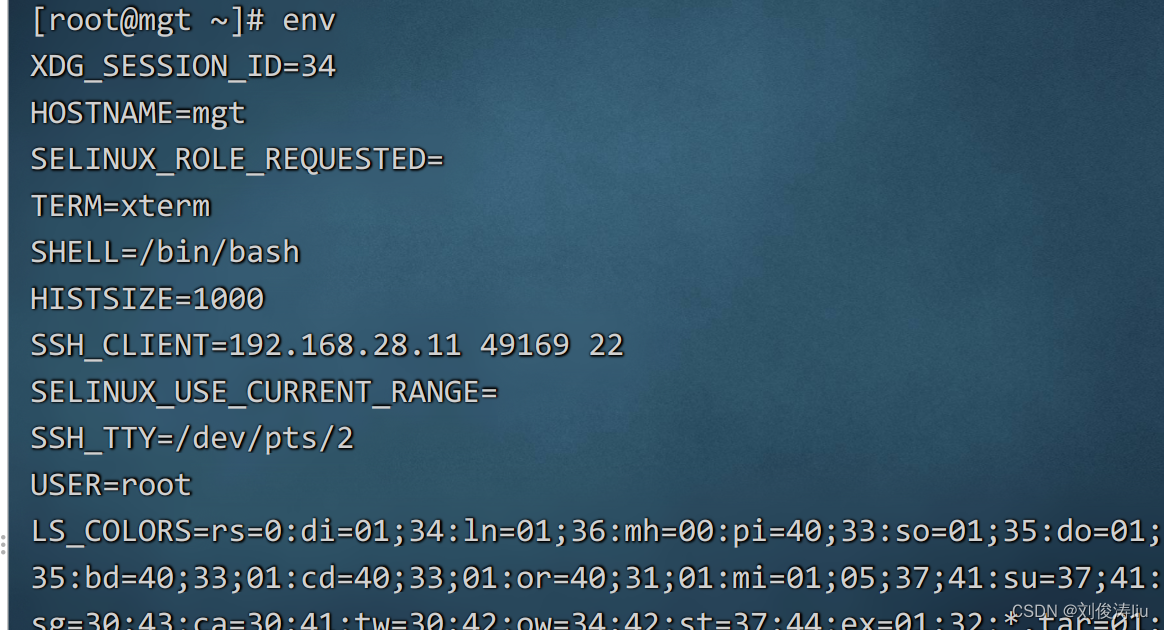
自定义变量
varName=varValue
等号两边不能有空格
数字 var1=1

shell 脚本的概念
将要执行的命令按顺序保存到一个文本文件
给该文件可执行权限
可结合各种Shell控制语句以完成更复杂的操作
我们先简单的写一个shell脚本
一般文件的权限有三种,读(r)、写(w)、执行(x)。通常Shell脚本写完是不具备执行(x)权限的,所以我们需要给予它执行权限
vim first.sh
chmod +x first.sh
ls
./first.sh
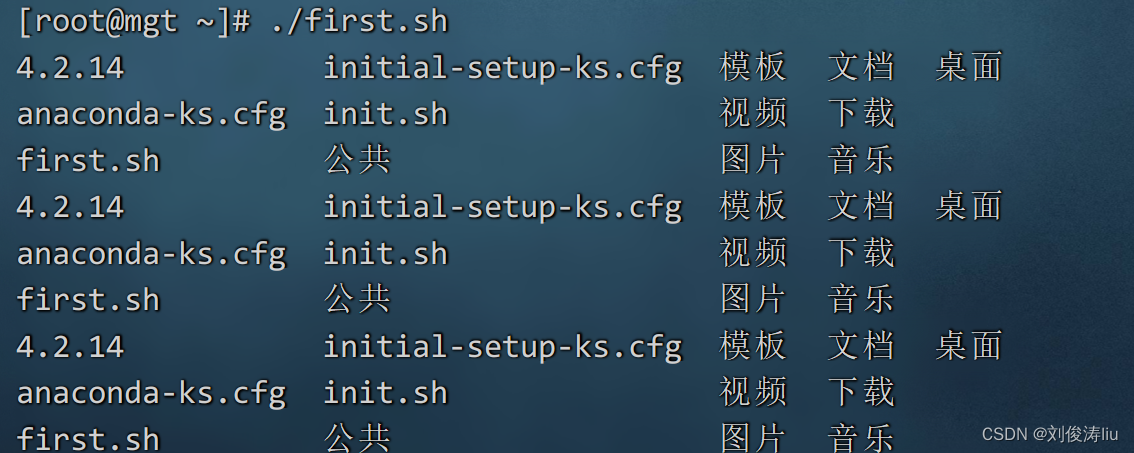
字符串 shell中可以不使用引号
当包含有空格时,需要使用引号
引号的用法
不会引用变量值 单引号 '
会应用变量值 双引号 "
引用命令结果 反撇号 `
单引号‘’:强引用,六亲不认,变量和命令都不识别,都当成了普通的字符串,“最傻”
双引号”“:弱引用,不能识别命令,可以识别变量,“半傻不精”
反向单引号··:里面的内容必须是能执行的命令并且有输出信息,变量和命令都识别,并且会将反向单引号的内容当成命令进行执行后,再交给调用反向单引号的命令继续,“最聪明
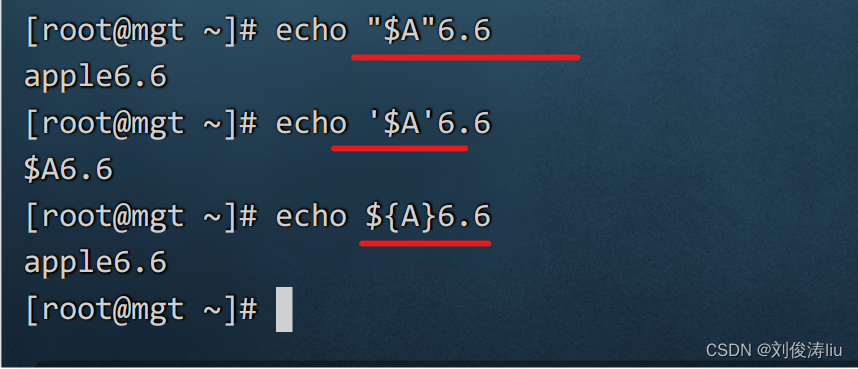
定义A=apple而66没有被定义所以输出apple 66 (中间空格分开)

因为A6没有被定义,所以无法输出

可以使用{}和“”进行分割,{}是应用在变量名,“”是应用在$变量名,如果使用‘’则视为普通字符
反撇号``,直接调用命令结果 ,因为echo "A " 5.5 = a p p l e 6.6 a b c = ‘ " A"5.5=apple6.6 abc=`"A"5.5=apple6.6abc=‘"A"6.6` 所以 abc=apple6.6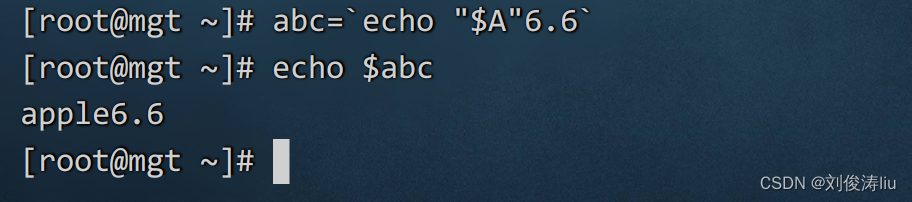
解析:
echo "$A": 打印环境变量$A的值。- ``: 反引号(backticks),用于将命令的输出结果赋值给变量。
"6.6": 字符串"6.6"。
所以,命令abc=echo "$A"6.6`` 将会把环境变量$A的值与字符串"6.6"连接后,将连接的结果赋值给变量abc。
$(命令) 应用场景较多
位置变量 脚本后参数所在的位置
$1
...
$9
预定义变量
$0 脚本本身的名称

$# 脚本后参数的个数

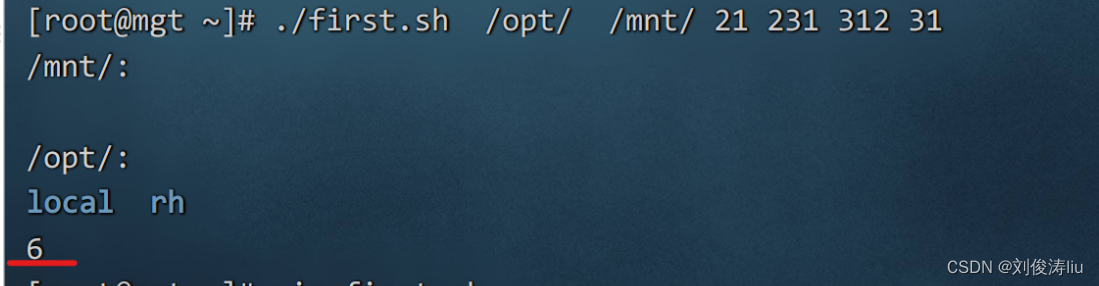
$* 脚本运行时参数的内容(整体输出)

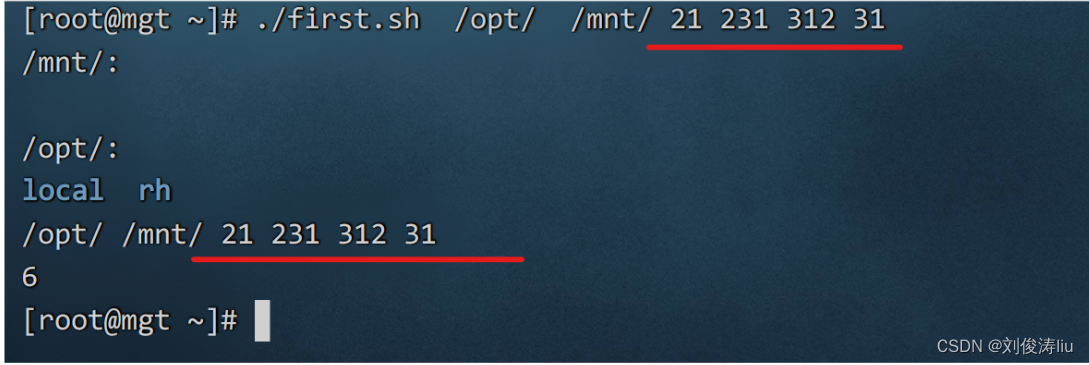
$@ 脚本运行时参数的内容(逐个输出)
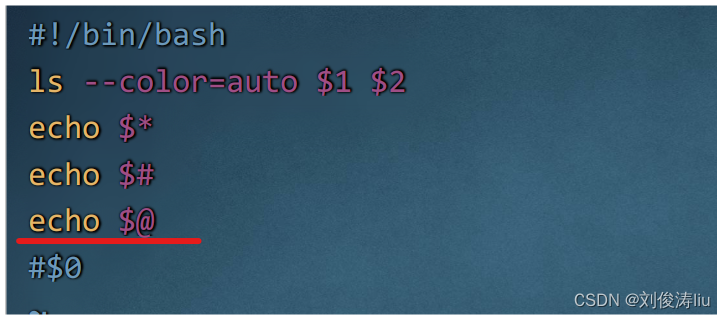

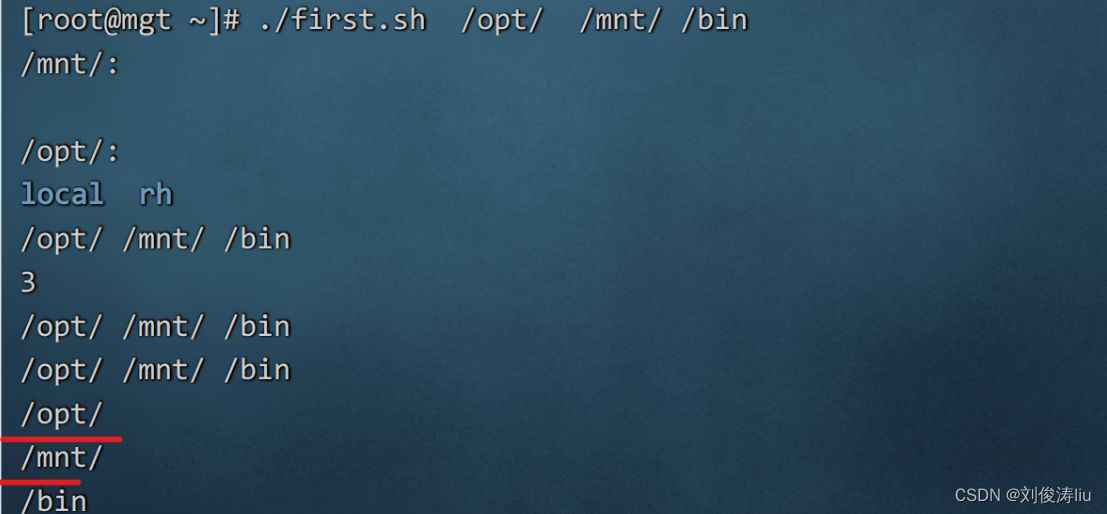

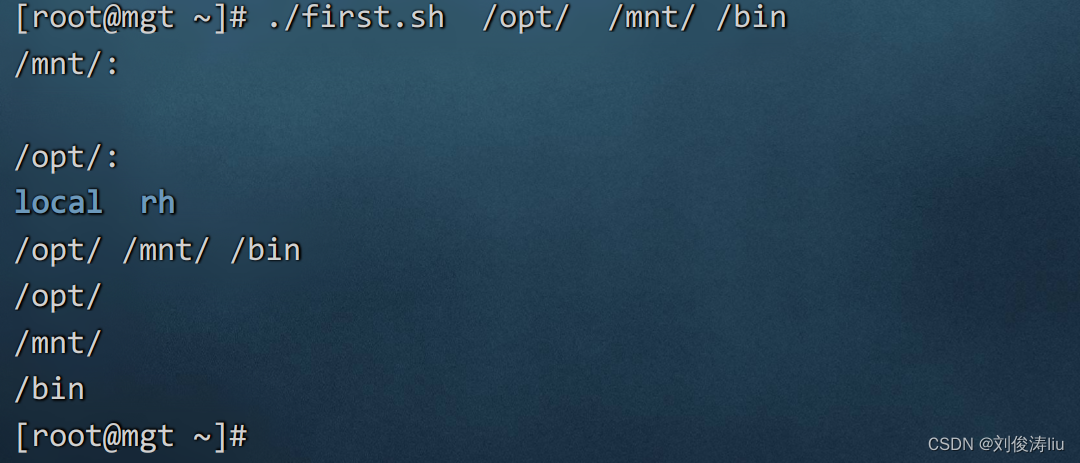
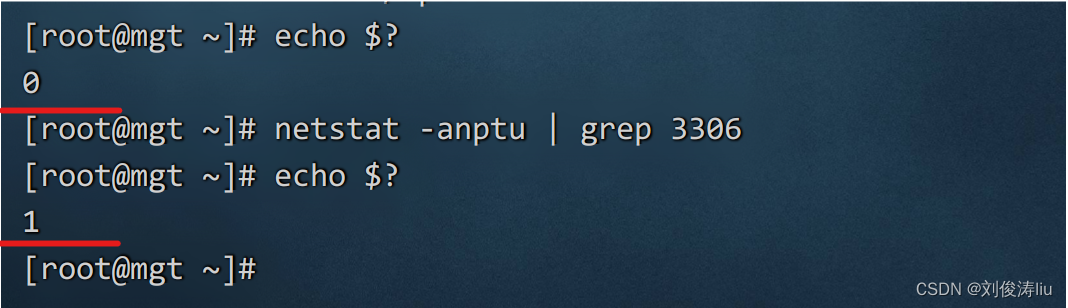
$? 脚本运行完毕后的返回值
默认情况
0 成功
非0 失败
作用域
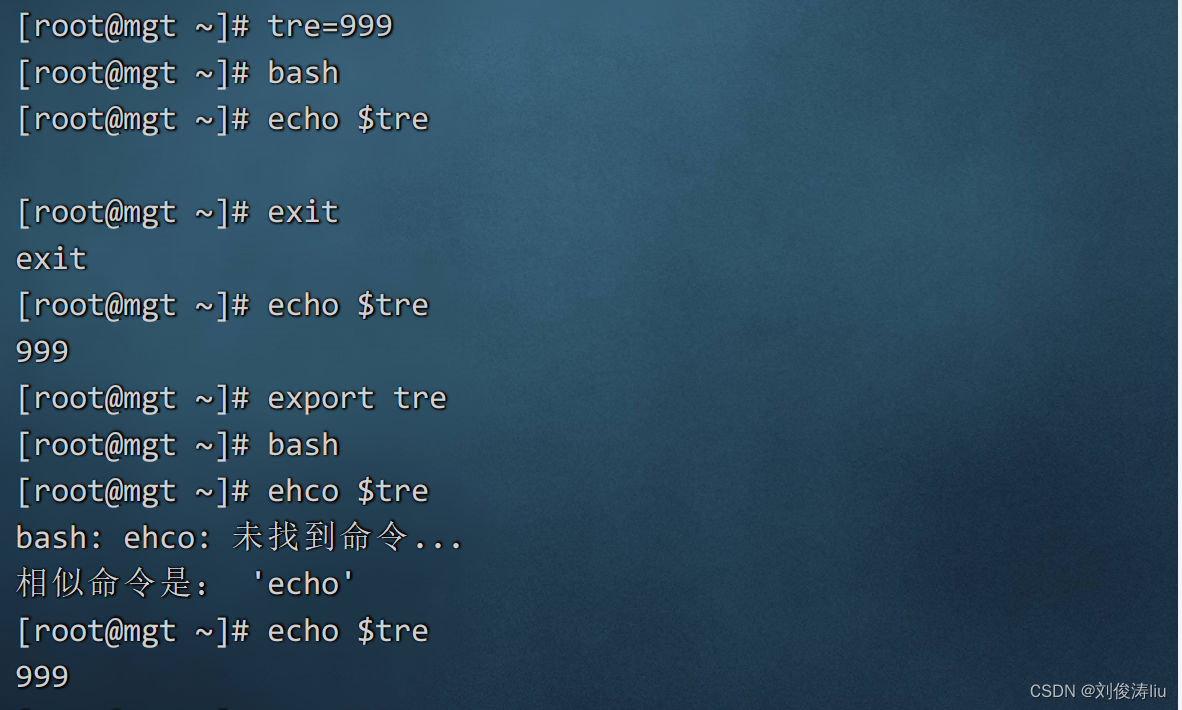
默认变量只在当前shell下生效
若要在当前及其子shell下生效,需要声明为全局变量 export
输出 echo $varName
为了使用户定义的变量在所有的子 shell环境中能够继续使用,减少重复设置工作,可以通过内部命令export将指定的变量导出为全局变量。用户可以同时指定多个变量名称作为参数(无须使用"$"符号),变量名之间以空格分隔.
格式1:export 变量名
格式2:export 变量名=变量值
shell中的字符串:
string
赋值: str1=foodfornoting.gpg
1)获得字符串的长度
语法: ${#StringName}
案例: echo ${#str1}
输出结果:17

2)字符串取子串
语法: ${#StringName:position:lenght}
案例: echo ${str1:0:3}
输出结果:foo

注意:lenght没有定义时,一直取到字符串的结尾!
3)字符串的截取
a)从左至右截取最后一个匹配字符串string之后的所有字符串
语法: ${StringName##*string}
案例: echo ${str1##*fo}
输出结果:rnoting.gpg

b)从左至右截取第一个匹配字符串string之后的所有字符串
语法: ${StringName#*string}
案例: echo ${str1#*fo}
输出结果:odfornoting.gpg

c)从右至左截取最后一个匹配字符串string之后的所有字符串
语法: ${StringName%%string*}
案例: echo ${str1%%o*}
输出结果:f

d)从右至左截取第一个匹配字符串string之后的所有字符串
语法: ${StringName%string*}
案例: echo ${str1%o*}
输出结果:foodforn

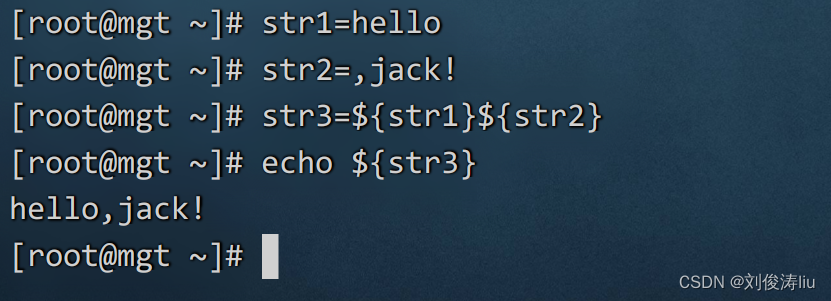
4)字符串的拼接
语法: StringName3=${StingName1}${StringName2}
案例: str1=Hello
str2=,Jack!
str3=${str1}${str2}
echo ${str3}
输出结果: Hello,Jack!
str1=hello
str2=,jack!
str3=${str1}${str2}
echo ${str3}
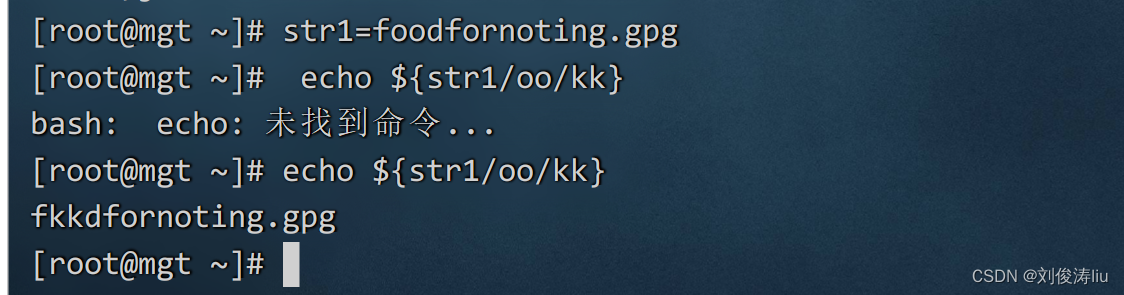
5)字符串替换:
语法: ${StringName/OldString/NewString}
案例: str1=foodfornoting.gpg
echo ${str1/oo/kk}
输出结果:fkkdfornoting.gpg
str1=foodfornoting.gpg
echo ${str1/oo/kk}
2、2 运算符
数学运算
+ - * / % * 作为乘号时需要加转义符\

expr 不仅支持常量还支持变量的运算
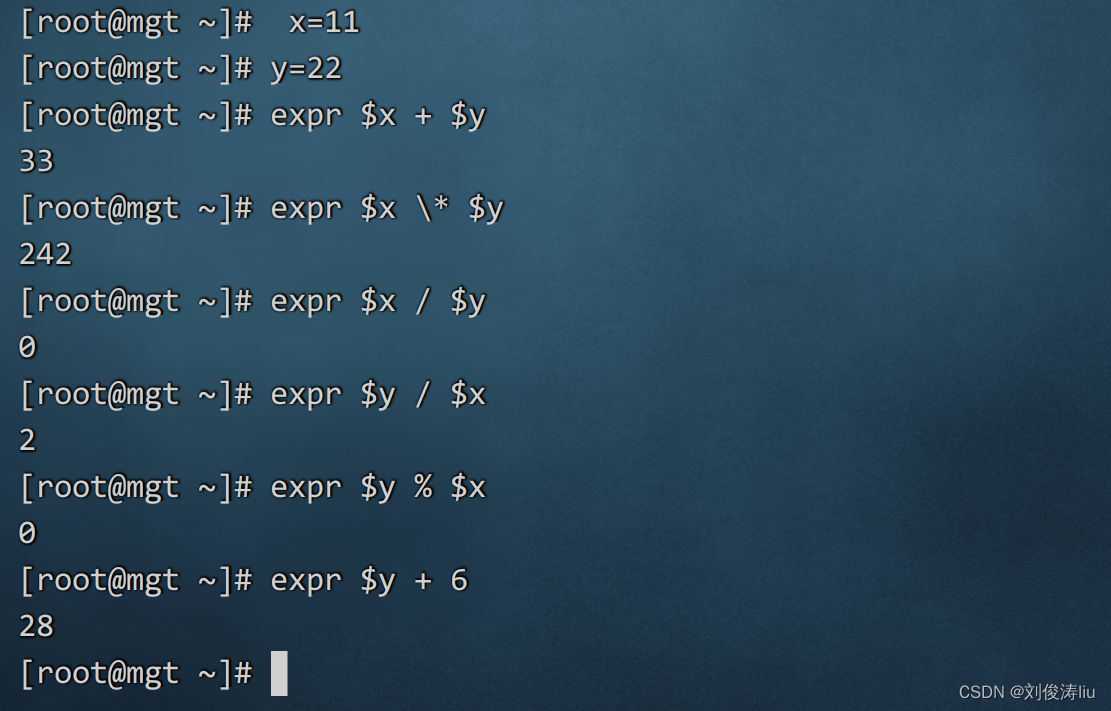
运算方法
expr expr $a + $b
$((a+b)) echo $((a+b))
$[a+b] echo $[a+b]
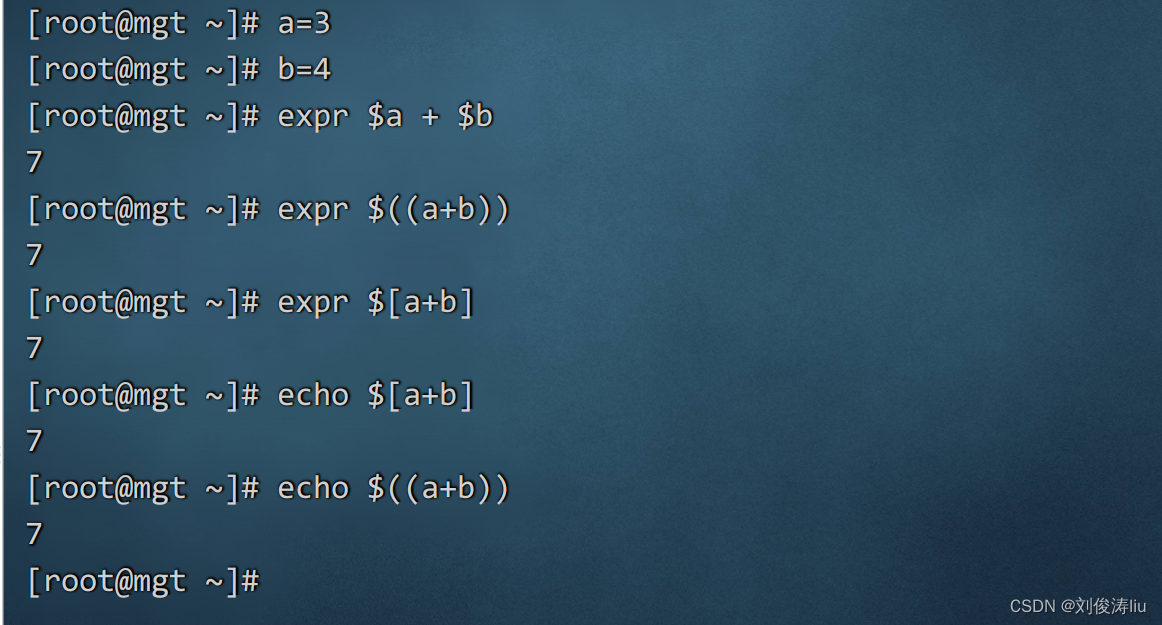
注意 shell不支持浮点数的显示
比较运算
条件测试
test var1 比较符 var2
[ var1 比较符 var2 ]
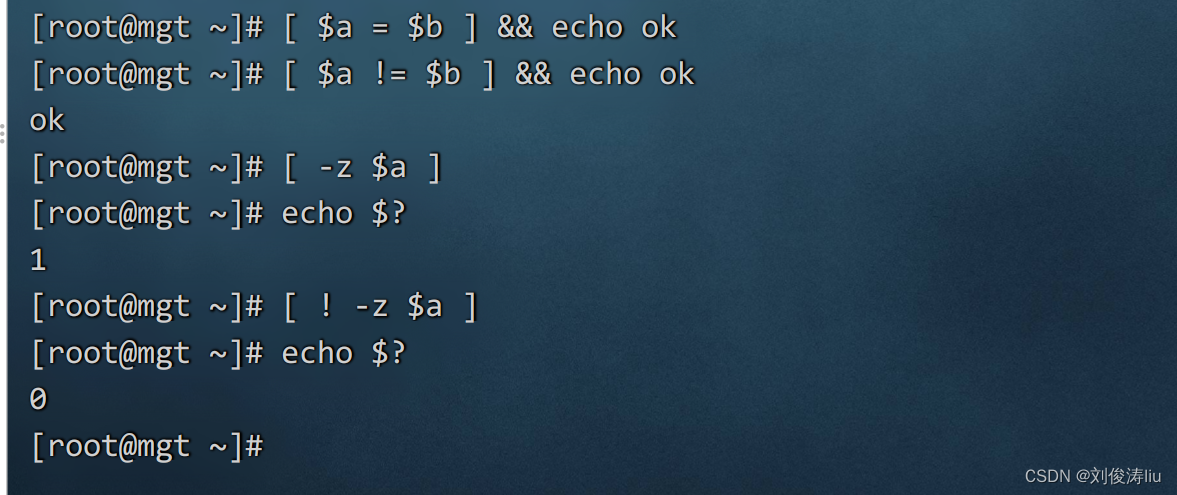
&& [ $a -ne $b ] && echo OK
条件 && 输出结果
条件为真输出
|| [ $a -ne $b ] || echo OK
条件 || 输出结果
条件为假输出
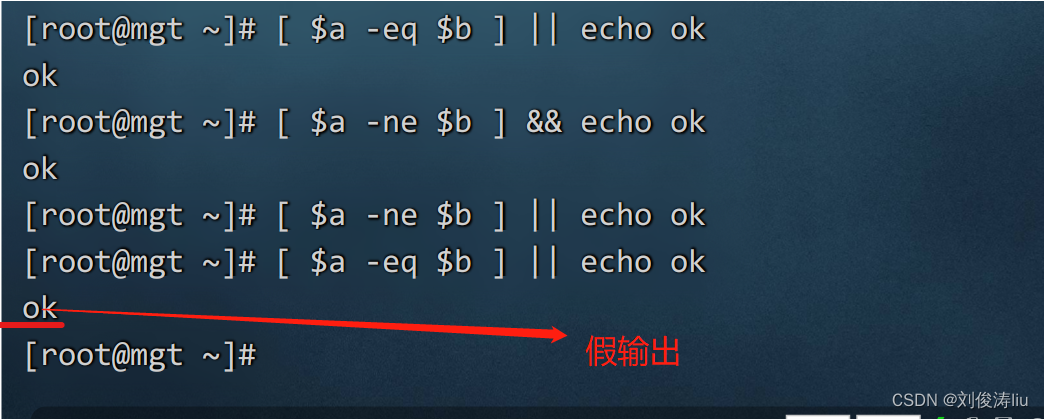
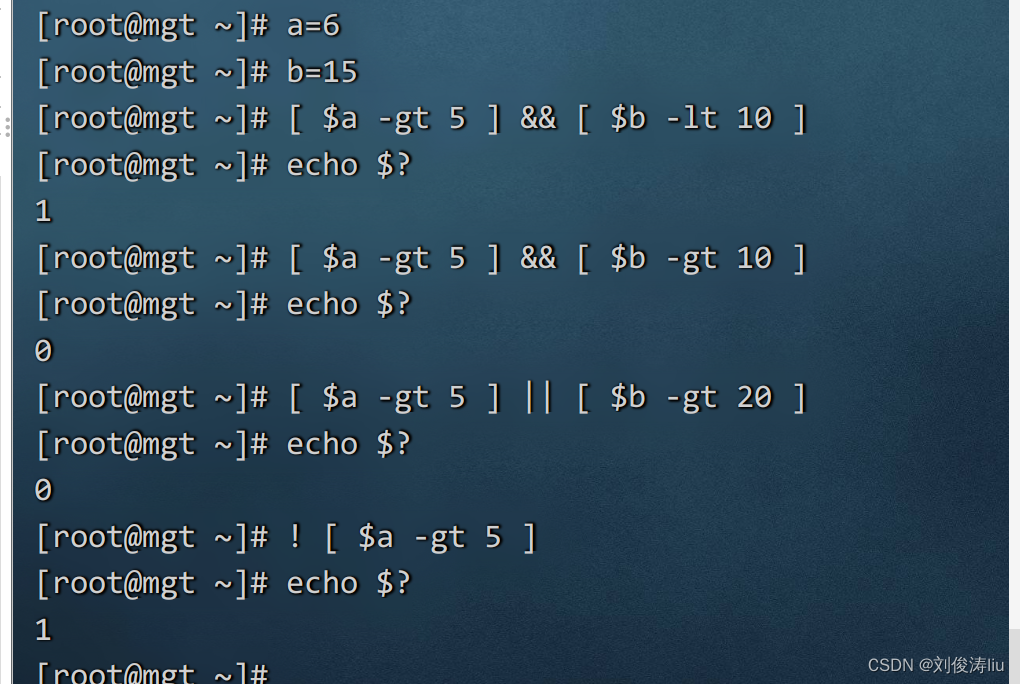
数值比较
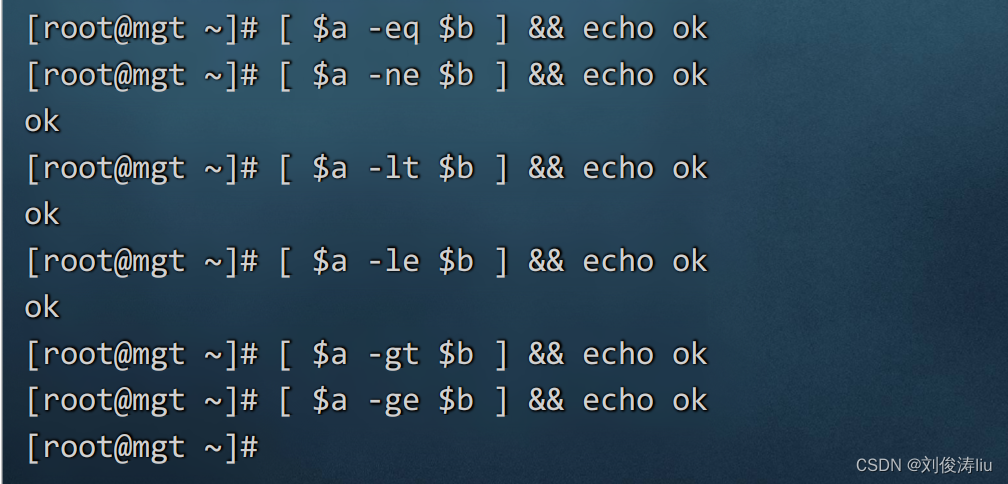
-eq 等于
-ne 不等于
-lt 小于
-le 小于等于
-gt 大于
-ge 大于等于
字符串比较
= 字符串一致
!= 字符串不一致
-z 字符串为空
! -z 字符串不为空
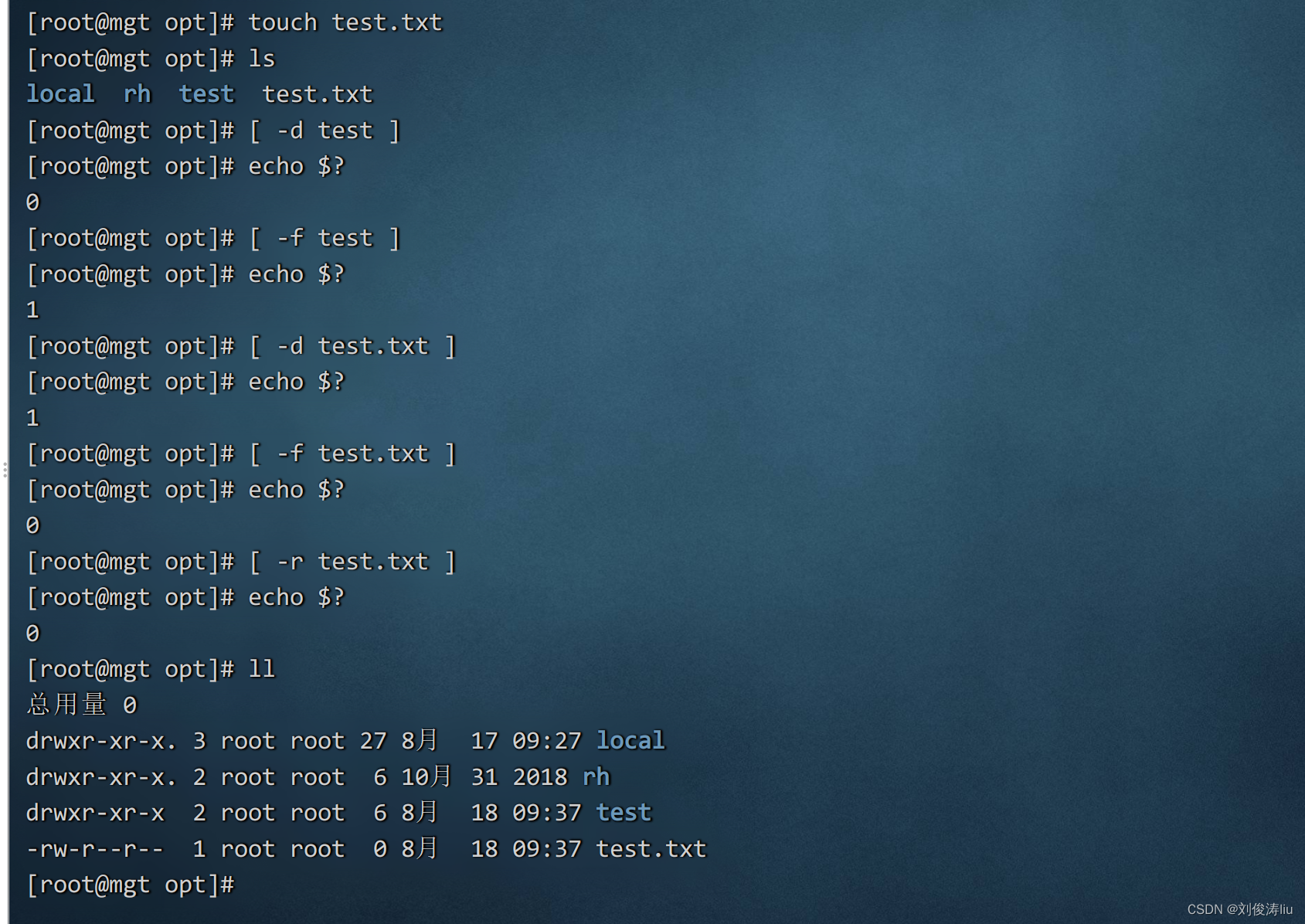
文件比较
-e 文件或目录是否存在
-f 是否为文件
-d 是否为目录
-r 判断文件是否可读
-w 判断文件是否可写
-x 判断文件是否可执行
逻辑运算符
&&
-a 并且,有假则假,全真为真 [ -r 111 -a -w 111 -a -x 111 ]
[ -r 111 ] && [ -w 111 ] && [ -x 111 ]
[ -x /root/file1 -a -d /root/file1 ]
[ -x /root/file1 ] && [ -d /root/file1 ]
|| -o 或者,有真则真,全假为假
! 取反 有真则假,有假则真
2、3shell脚本编写规范
第一行 #!/bin/bash
第二行 #脚本的说明
第三行 脚本正文
2、4shell运行规则
没有x权限
bash 脚本所在路径/脚本文件
source 脚本所在路径/脚本文件
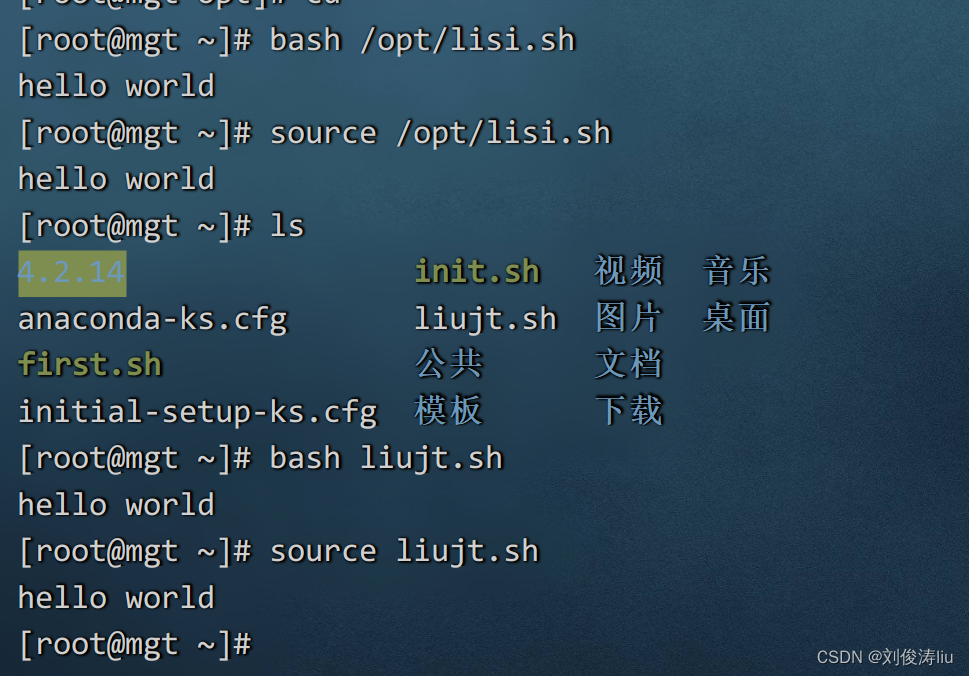
. 脚本所在路径/脚本文件
脚本存在cd 时,会切换到目标目录
有x权限
./脚本文件

脚本绝对路径/脚本文件
脚本存在cd 时,会切换到目标目录
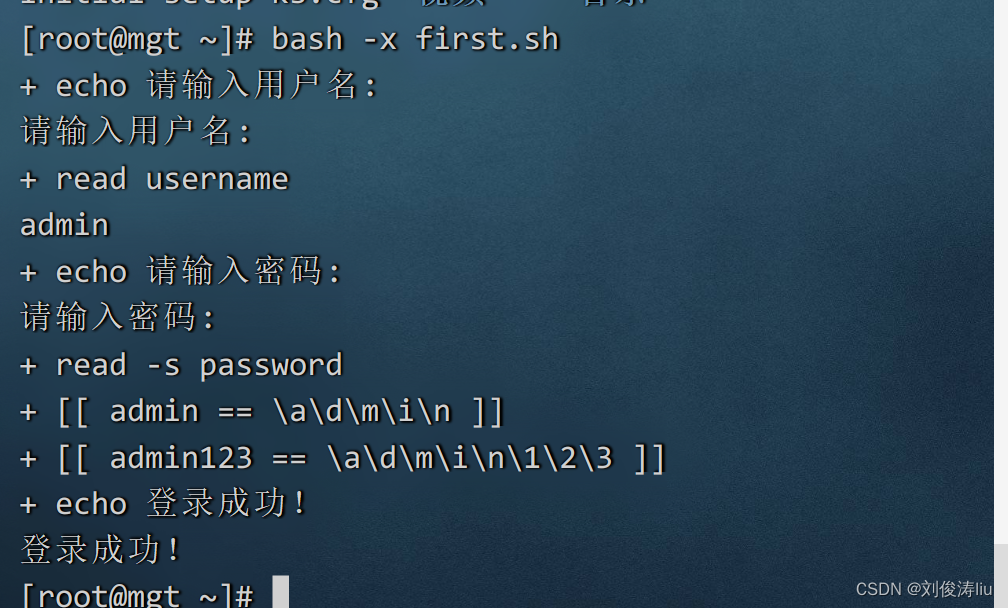
2、5shell脚本运行追踪
bash -x 脚本所在路径/脚本文件
2、6$[$RANDOM%100]
返回100内随机数

2、7 seq 1 10
返回1到10 的连续数字

2、8{1,,10}
返回1到10 的连续数字

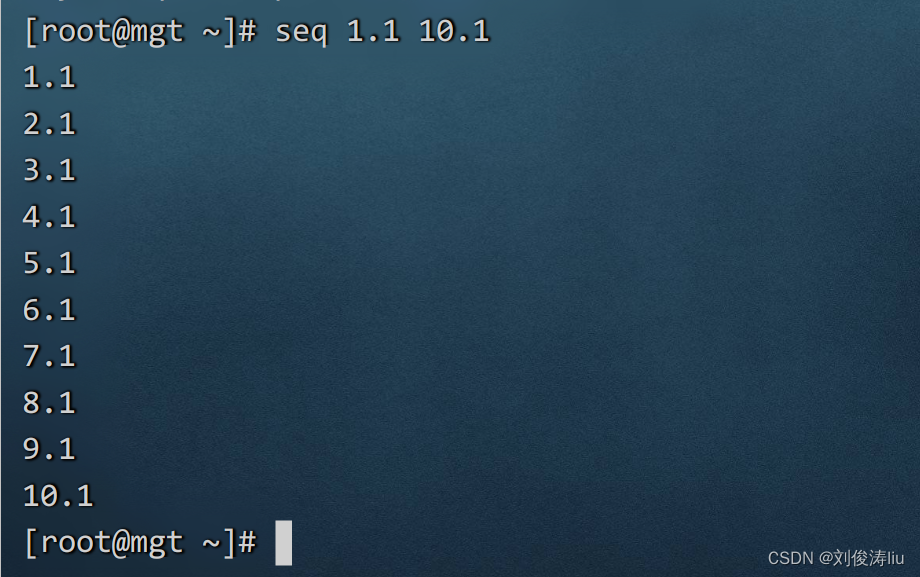
2、9seq 1.1 10.1
返回1.1 2.1 3.1.... 10.1
3、read -p "提示语" 变量名
读取键盘输入并赋值给变量名
3.1语句
条件语句
单分支if
if [ ];then
fi
双分支if
if [ ];then
else
fi
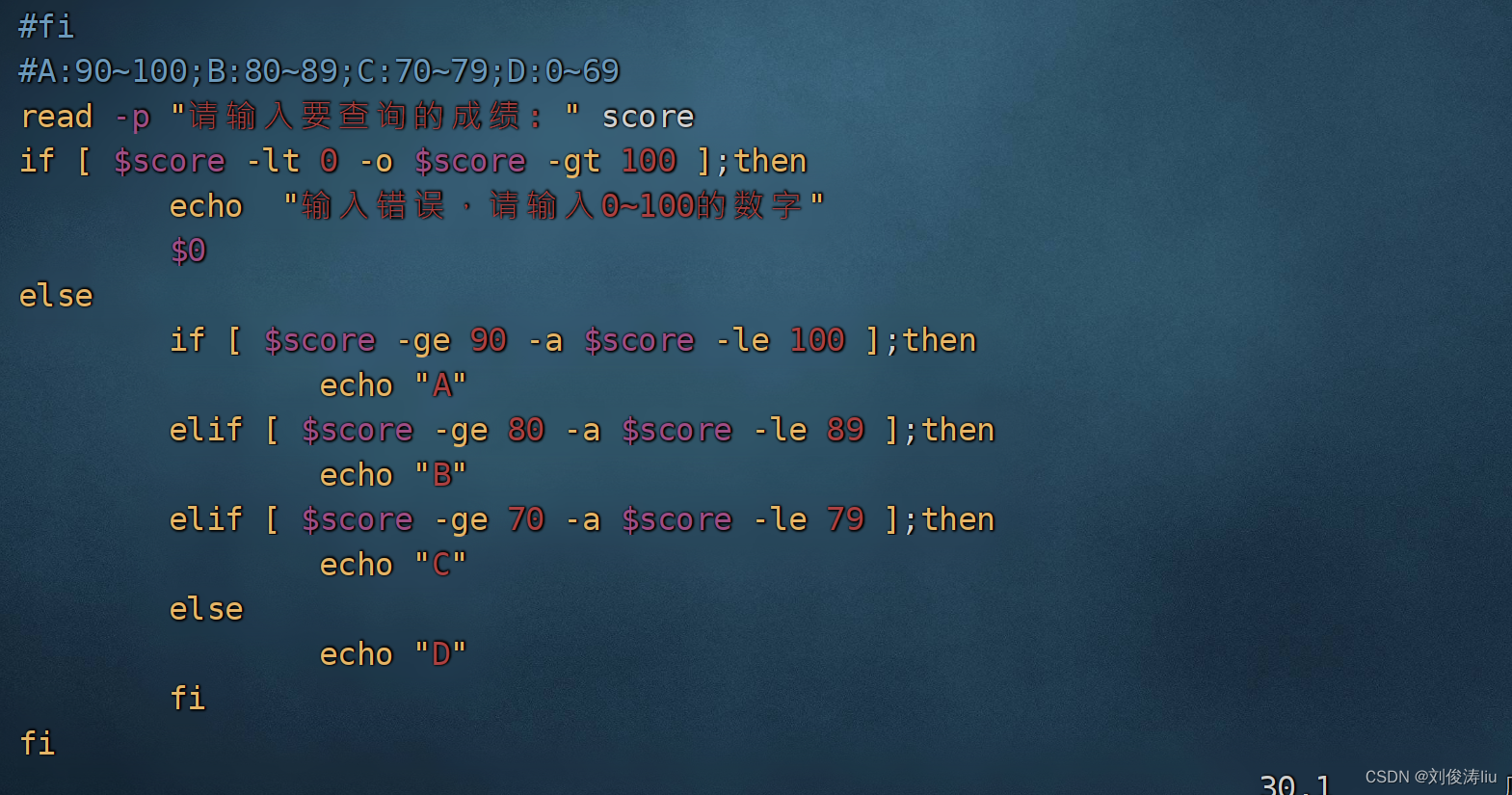
多分支if
if [ ];then
elif [ ];then
else
fi

循环语句
forfor 条件(i in 值)|((i=1;i<=10;i++))
do
语句
done
while
i=1
while 条件
do
语句
let i++
done
关于$*与$@的验证



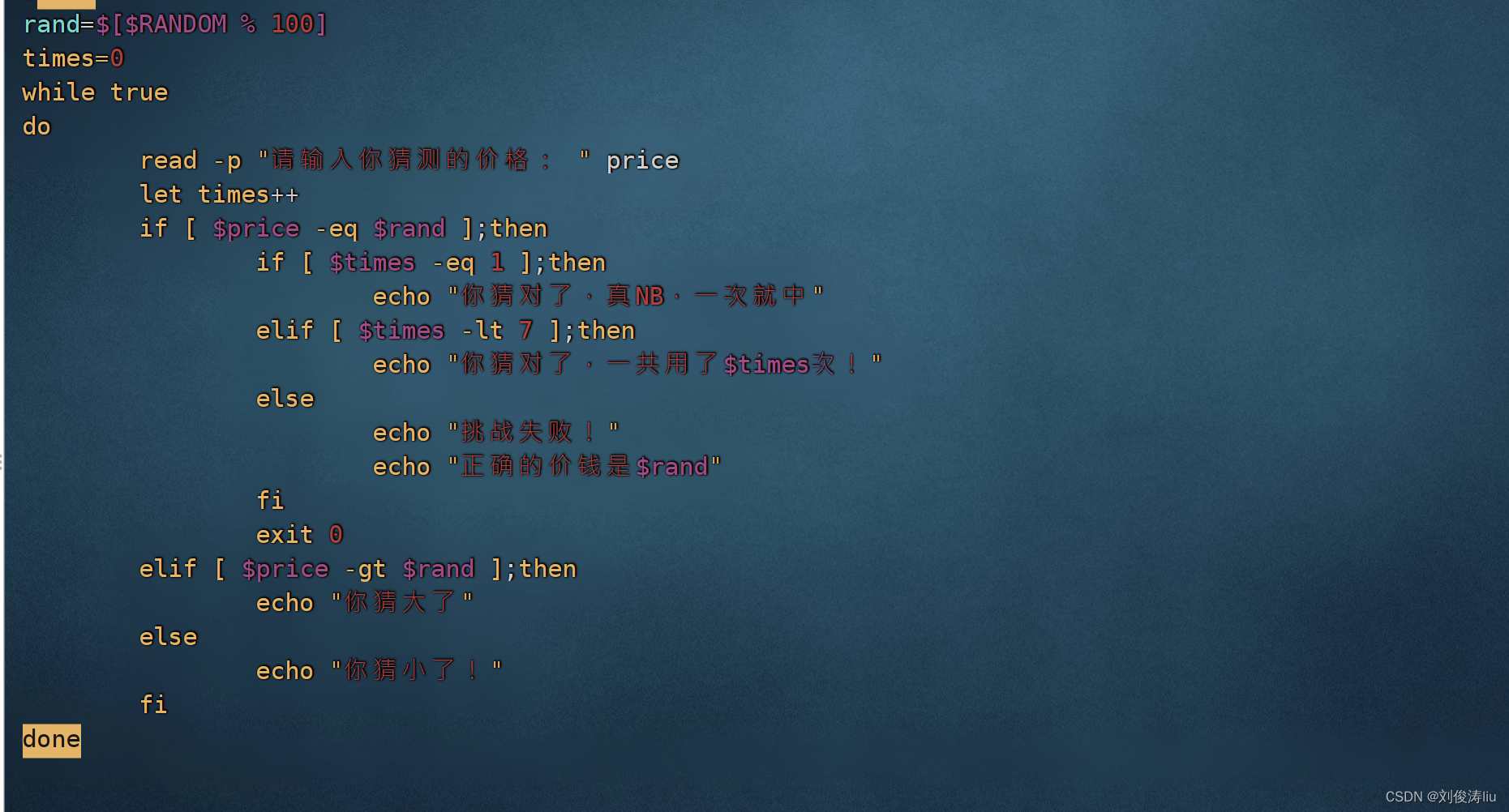
开关语句
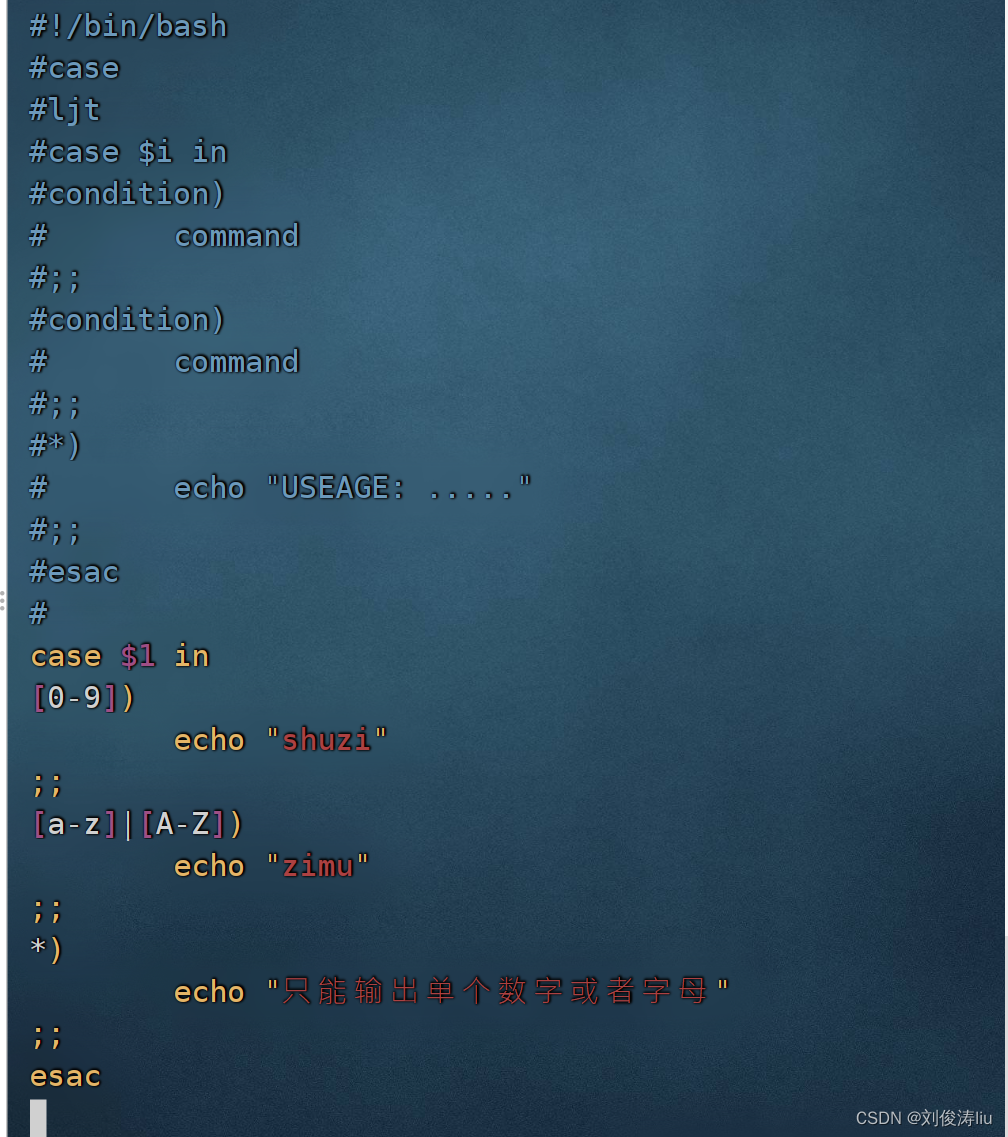
case
case $1 in
条件1)
语句
;;
条件2)
语句
;;
*)
帮助信息
;;
esac

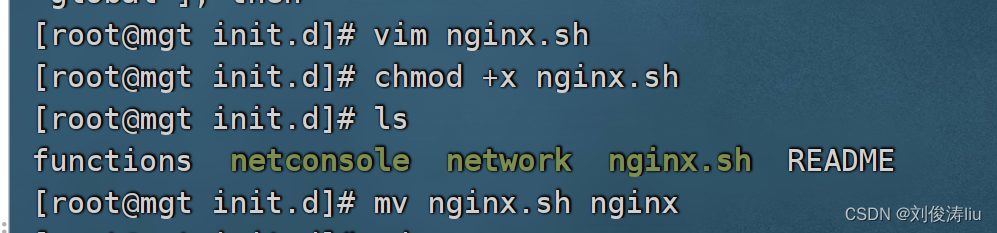
对于开关语句来说我们简单的来写一个nginx的启动脚本吧
编译安装nginx


安装完依赖开始做文件
vim nginx.sh
chmod +x nginx.sh
mv nginx.sh nginx
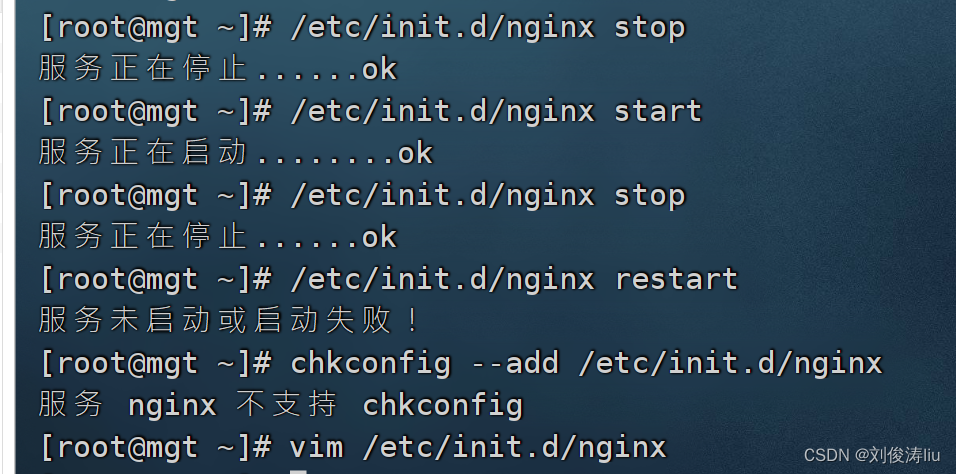
/etc/init.d/nginx stop
#!/bin/bash
#nginx start|reload|stop
#ljt
# chkconfig: 35 85 75
NGINX="/usr/local/nginx/sbin/nginx"function start(){
$NGINX
}
function stop(){
$NGINX -s stop
}
function reload(){
$NGINX -s reload
}
case $1 in
start)
start
if [ $? -eq 0 ];then
echo -e "服务正在启动........ok"
fi
;;
stop)
stop 2> /dev/null
if [ $? -ne 0 ];then
echo "服务器未启动,不需要停止!"
else
echo "服务正在停止......ok"
fi
;;
reload)
reload
if [ $? -eq 0 ];then
echo "平滑加载配置文件中.......ok"
else
echo "服务器未启动或者加载失败!"
fi
;;
restart)
stop 2> /dev/null && start
if [ $? -eq 0 ];then
echo "服务器重启成功"
else
echo "服务未启动或启动失败!"
fi
;;
*)
echo "USEAGE $0 start|stop|restart|reload"
;;
esac
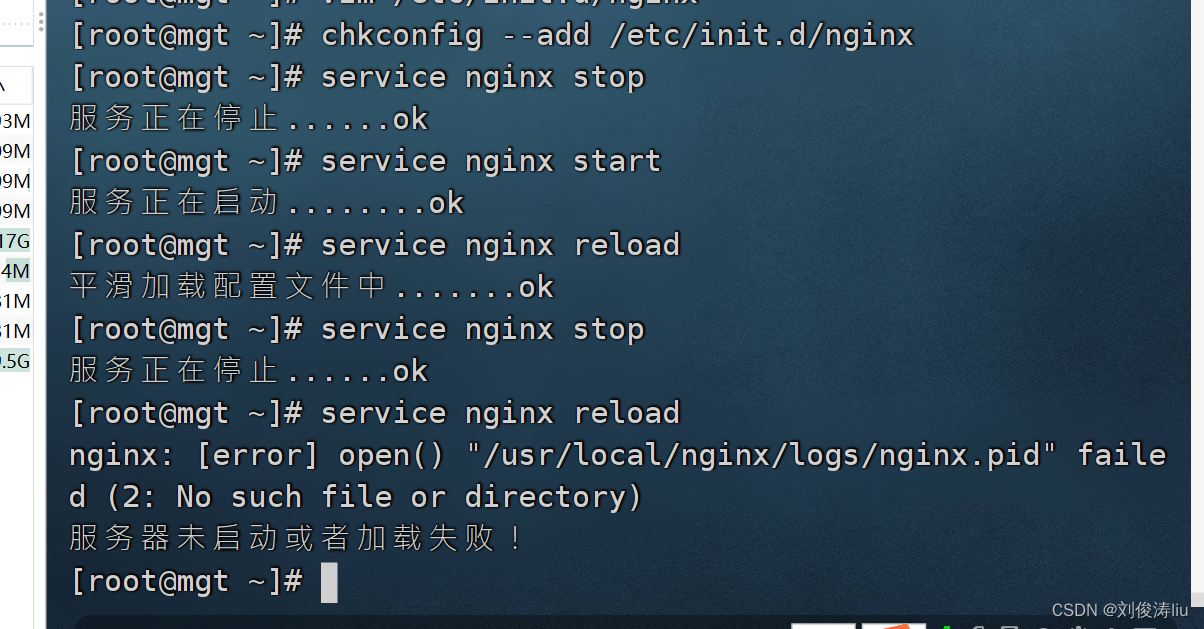
或者加入
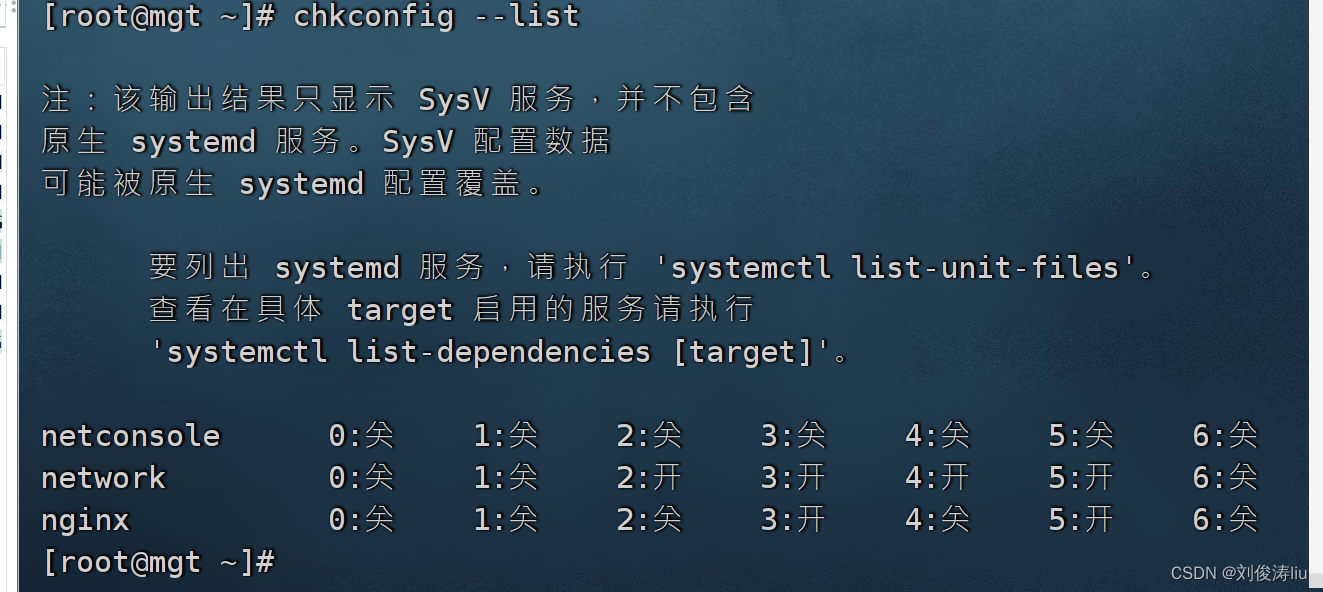
chkconfig --add /etc/init.d/nginx
3.2文件操作四剑客
正则表达式
基础正则
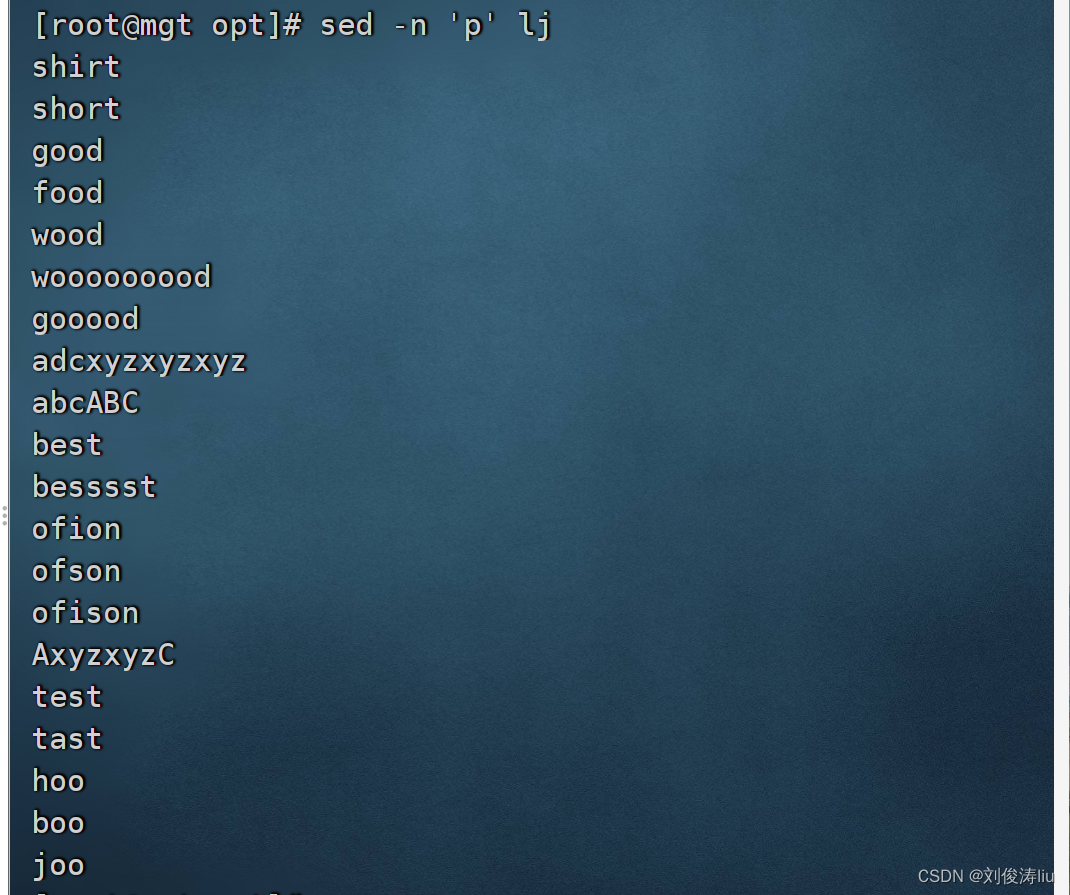
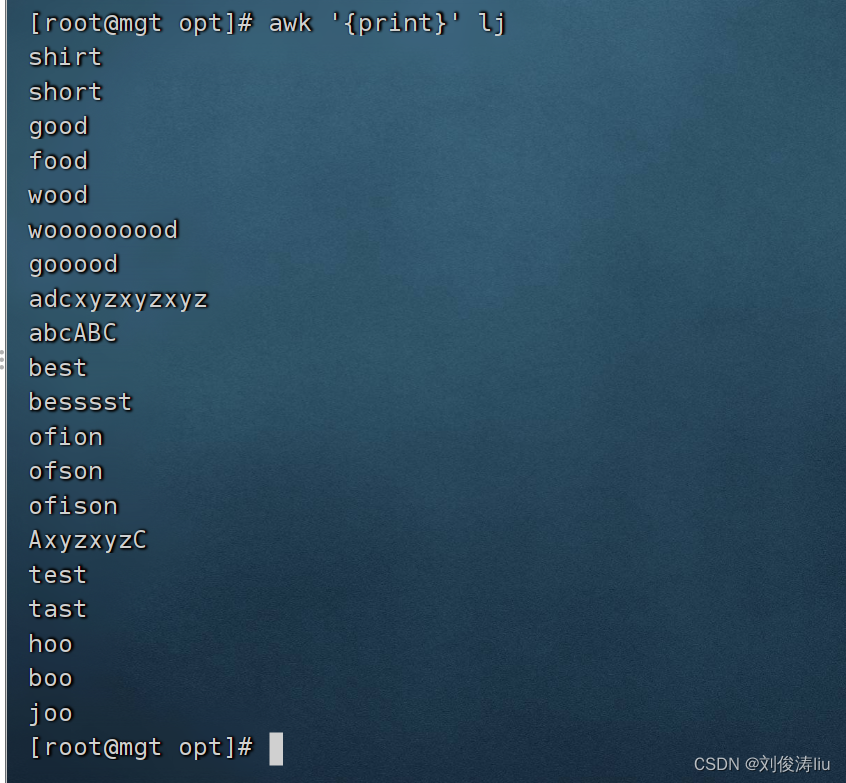
文本为
shirt
short
good
food
wood
wooooooood
gooood
adcxyzxyzxyz
abcABC
best
besssst
ofion
ofson
ofison
AxyzxyzC
test
tast
hoo
boo
joo
a)查找特定字符 cat test.txt | grep -n 'was'
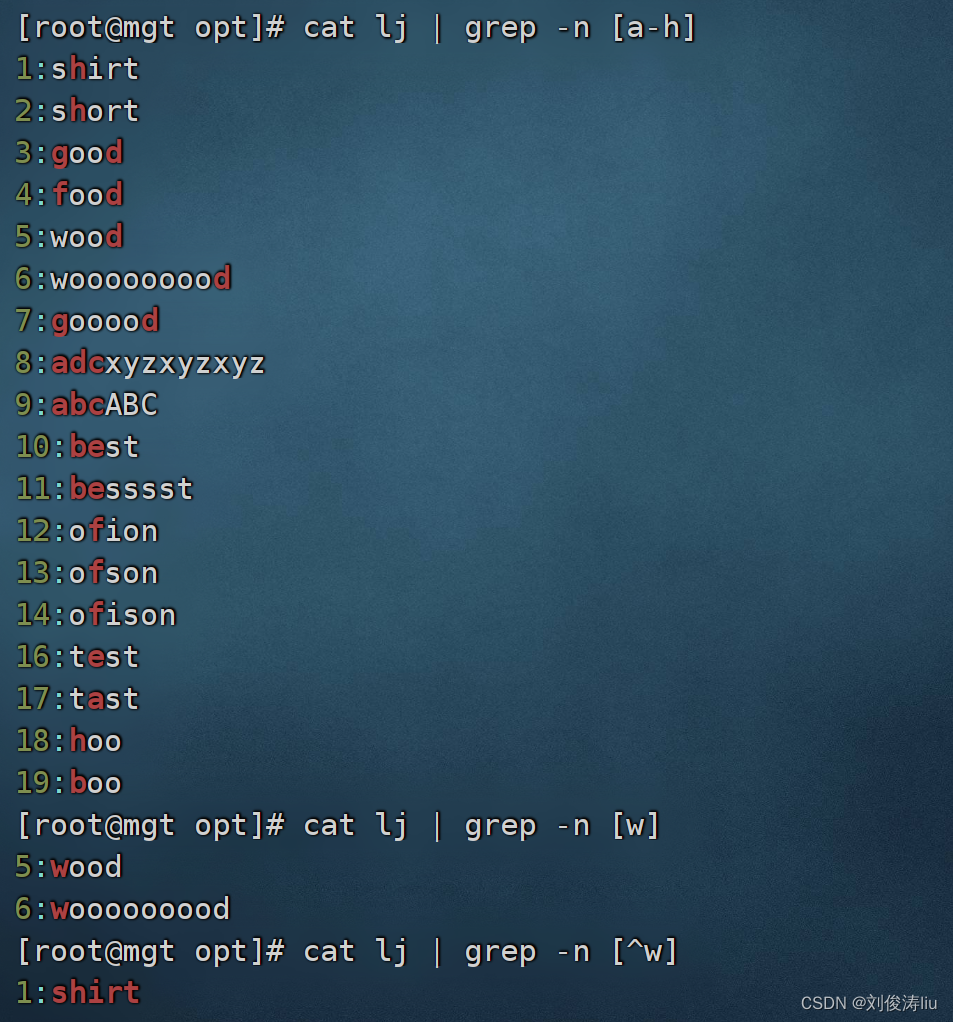
b)利用[]查找集合字符 cat test.txt | grep -n 'sh[io]rt' 匹配i或者o
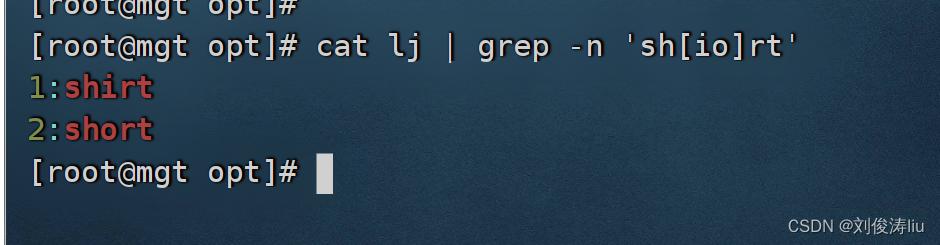
cat test.txt | grep -n '[^w]' 排除w
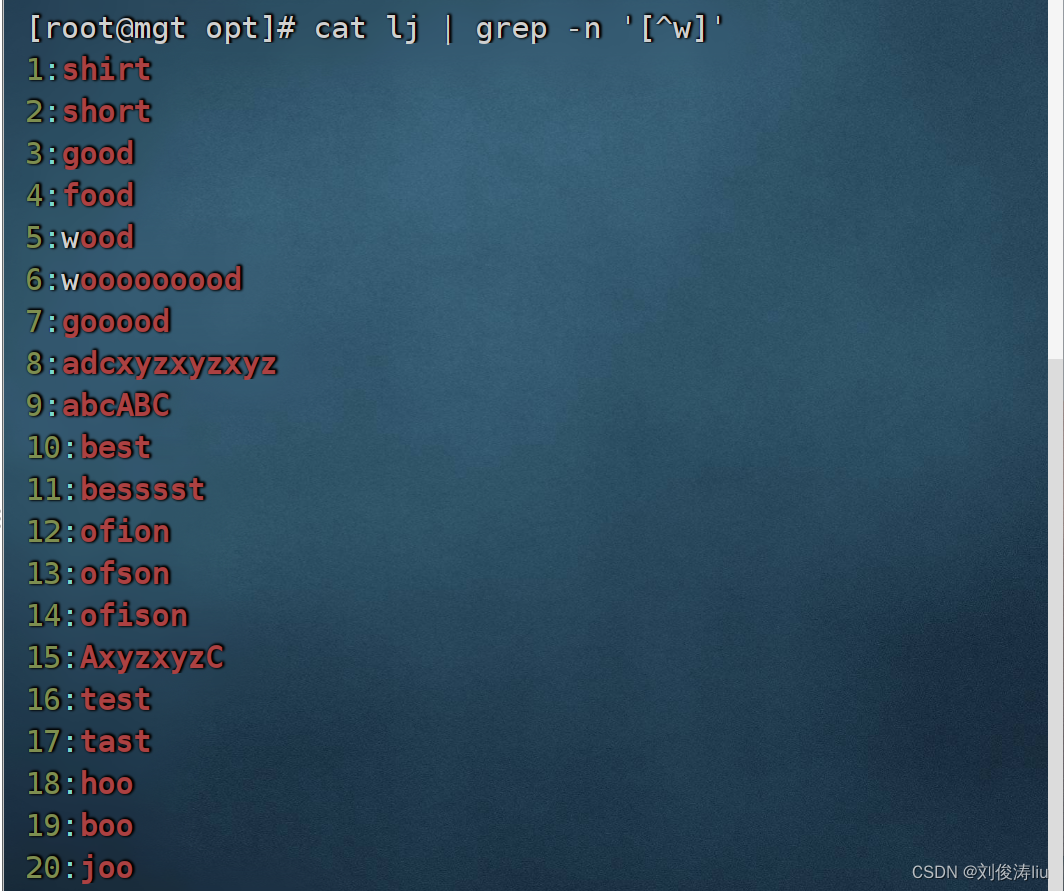
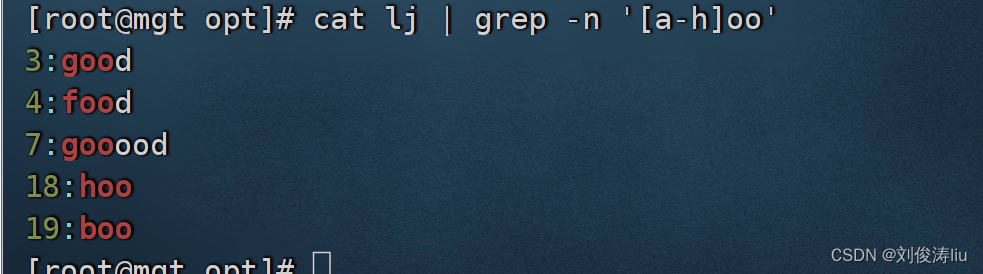
cat test.txt | grep -n '[a-h]oo'
cat test.txt | grep -n '[0-9]'
c)查找行首"^"与行尾"$"
cat test.txt | grep -n '^[A-Z]'

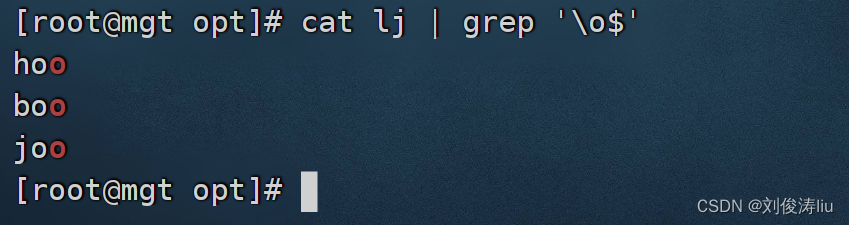
cat test.txt | grep '\.$' \ 为转义符
d)查找任意一个字符"."与重复字符"*"
cat test.txt | grep -n 'w..d'

cat test.txt | grep -n 'ooo*'
cat lj | grep -n 'ooo'

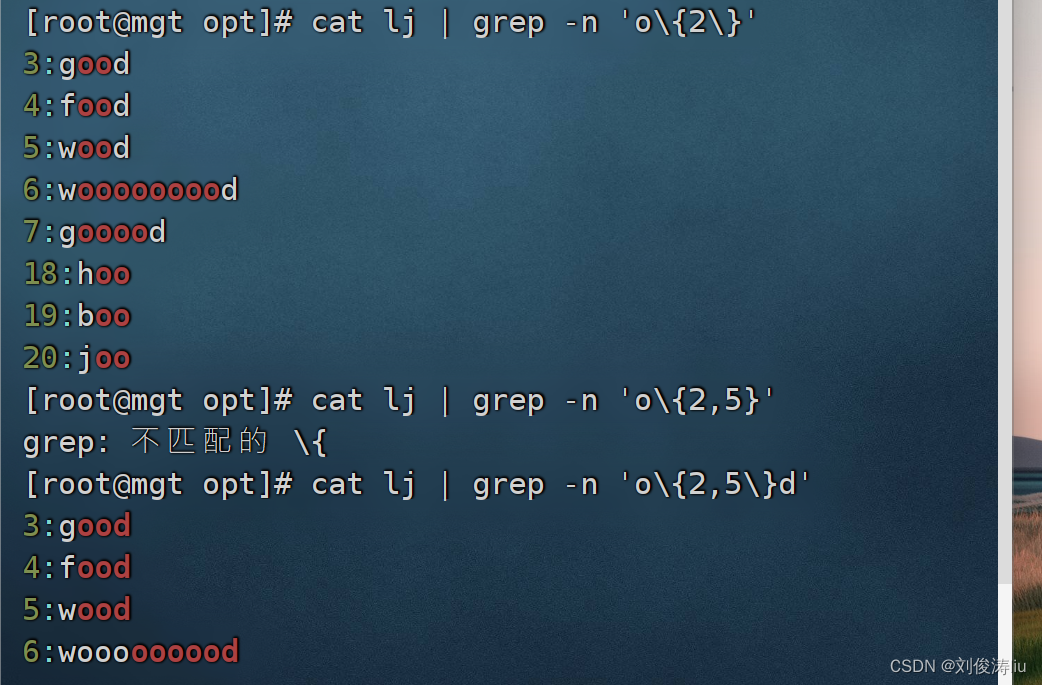
e)查找连续的字符范围"{}",需要使用转义符,"\{\}"
cat test.txt | grep -n 'o\{2\}'
cat test.txt | grep -n 'wo\{2,5\}d'
cat test.txt | grep -n 'wo\{2,\}d'
扩展正则
a)+,重复一个或一个以上的前一个字符
cat test.txt | grep -nE 'wo+d' 或者

cat test.txt | egrep -n 'wo+d'
b)?,零个或者一个前一个字符 cat test.txt | egrep -n 'bes?t'

c)|,使用或者的方式找出多个字符 cat test.txt | egrep -n 'of|is|on'

d)(),查找组字符串 cat test.txt | egrep -n 't(a|e)st'

e)()+,辨别多个重复的组 cat test.txt | egrep -n 'A(xyz)+C'

常见正则表达式
数字
“^[0-9]*[1-9][0-9]*$” //正整数
“^((-\d+)|(0+))$” //非正整数(负整数 + 0)
“^-[0-9]*[1-9][0-9]*$” //负整数
“^-?\d+$” //整数
“^\d+(\.\d+)?$” //非负浮点数(正浮点数 + 0)
“^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$” //正浮点数
“^((-\d+(\.\d+)?)|(0+(\.0+)?))$” //非正浮点数(负浮点数 + 0)
“^(-?\d+)(\.\d+)?$” //浮点数
字符串
“^[A-Z]+$” //由26个英文字母的大写组成的字符串
“^[a-z]+$” //由26个英文字母的小写组成的字符串
“^[A-Za-z0-9]+$” //由数字和26个英文字母组成的字符串
“^\w+$” //由数字、26个英文字母或者下划线组成的字符串
Email
“^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$” //email地址
“^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$” //Email
Url “^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$” //url
IP
“^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$” //IP地址
Tel
/^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ //电话号码
日期校验
/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日 yyyy-MM-dd / yy-MM-dd 格式
"^[0-9]{4}-((0([1-9]{1}))|(1[1|2]))-(([0-2]([0-9]{1}))|(3[0|1]))$" // 年-月- 日 yyyy-MM-dd 格式
/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年
grep进阶
选项
-r 递归扫描指定目录下的每一个文件
-l 只显示匹配到指定关键字的文件名,而不是文件内容
案例
查看/etc目录下所有包含bash的文件名
grep -rl bash /etc
egrep 完美支持正则表达式
find进阶
按照权限查找 -perm

使用命令只查看文件不查看目录或者更详细的信息
按照时间戳查找
-atime
-mtime
-ctime
-exec find /var/spool/mail -type f -exec rm -rf {} \;
xargs find /var/spool/mail -type f | xargs rm -rf
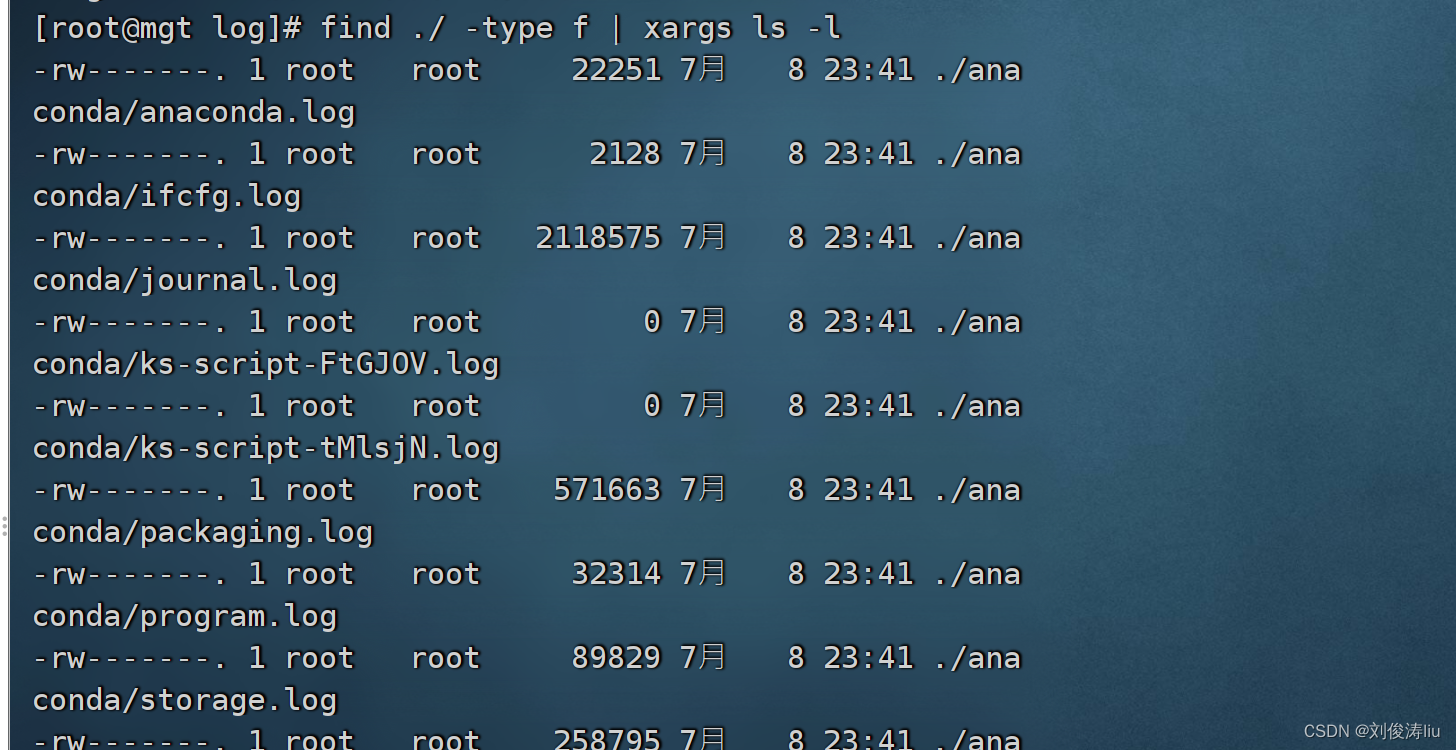
find ./ -type f | xargs ls -l
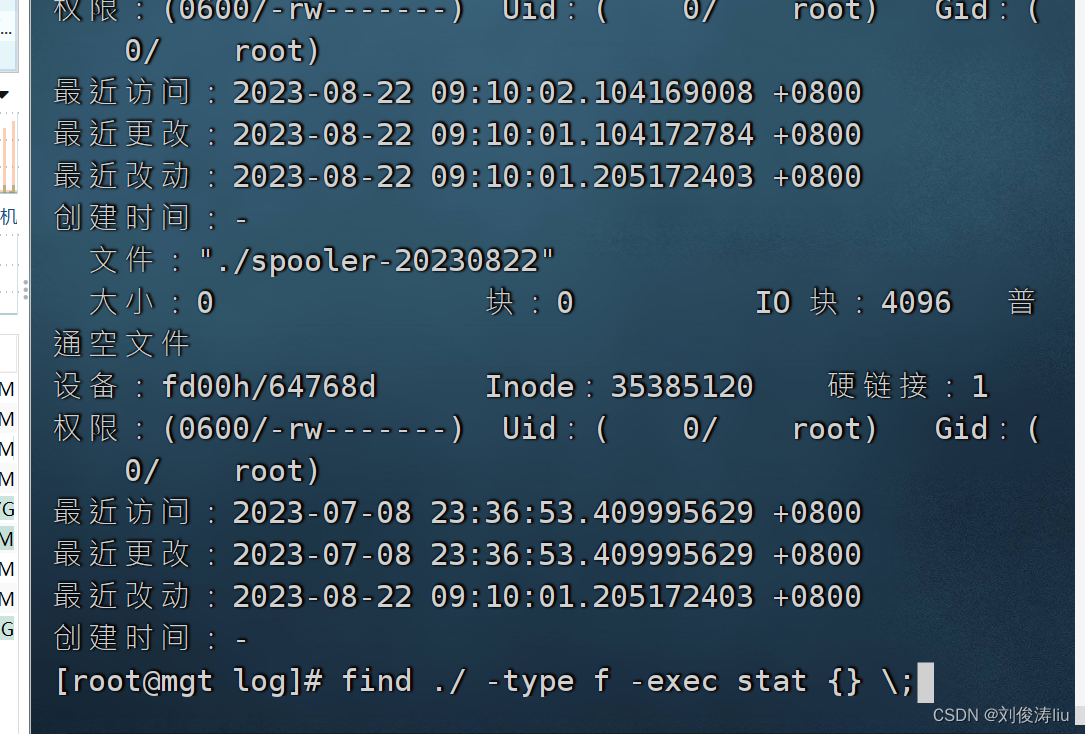
find ./ -type f -exec stat {} \;
sed
语法
sed [选项] '操作' 参数
sed [选项] -f scriptfile 参数
选项
-e:表示用指定命令或脚本处理
-f:指定脚本文件
-h:帮助
-n:表示仅显示处理后的结果
-i:直接编辑文本文件
-r:支持扩展正则
操作
a:增加,在当前行下面以行增加指定内容
c:替换,将选定行替换
d:删除,删除指定行
i:插入,在选定行的上面插入一行
p:打印
s:替换,替换指定字符
y:字符转换
案例
1.输出符合条件的文本:
sed -n 'p' test.txt #相当于cat
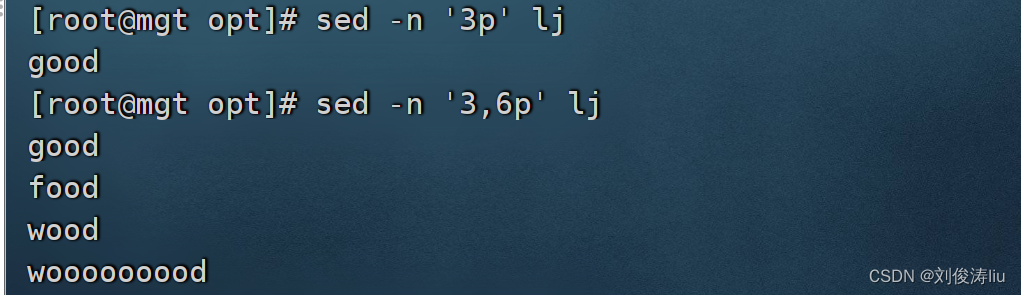
sed -n '3p' test.txt #打印第3行
sed -n '3,6p' test.txt #打印第3到6行的内容
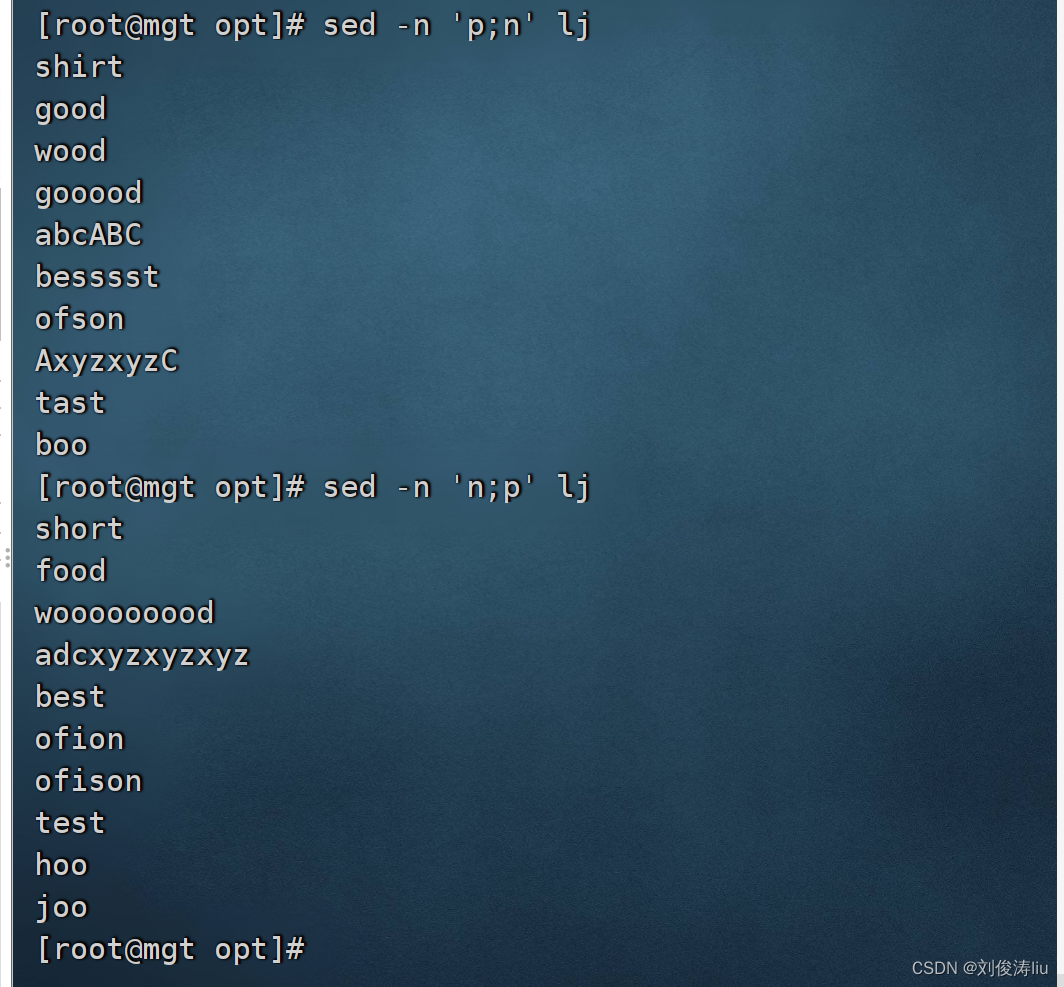
sed -n 'p;n' test.txt #打印奇数行
sed -n 'n;p' test.txt #打印偶数行
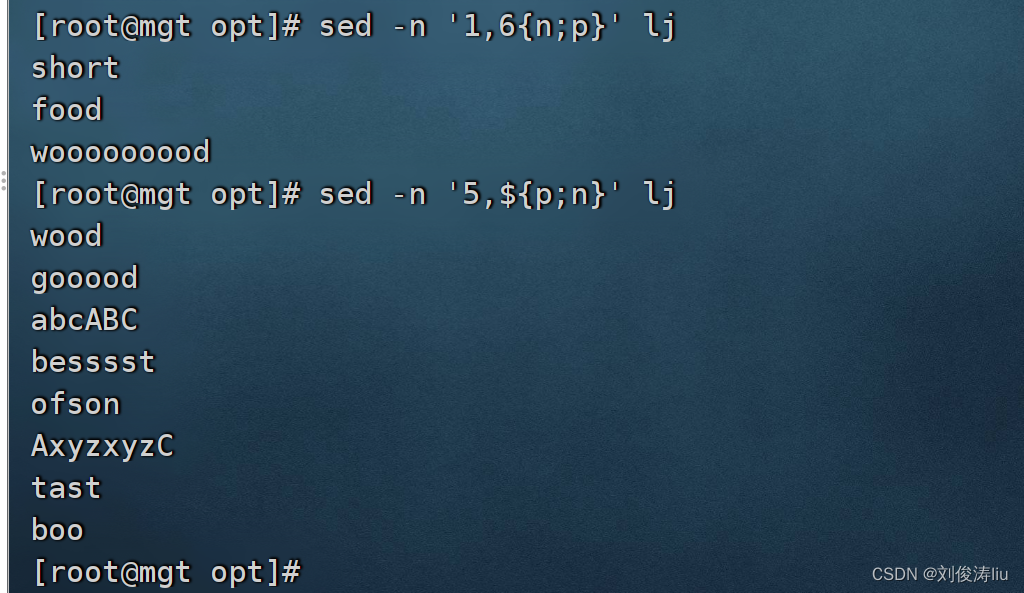
sed -n '1,6{p;n}' test.txt #打印1到6行之间的奇数行
sed -n '5,${p;n}' test.txt #从第5行开始打印奇数行
sed -n '/the/p' test.txt #匹配the
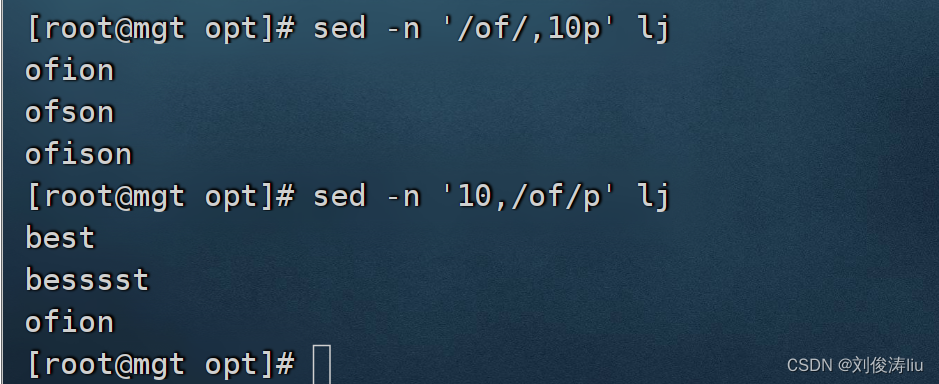
sed -n '5,/the/p' test.txt #匹配从第5行开始到包含the的行
sed -n '/the/,10p' test.txt #匹配从包含the的行到第10行结束
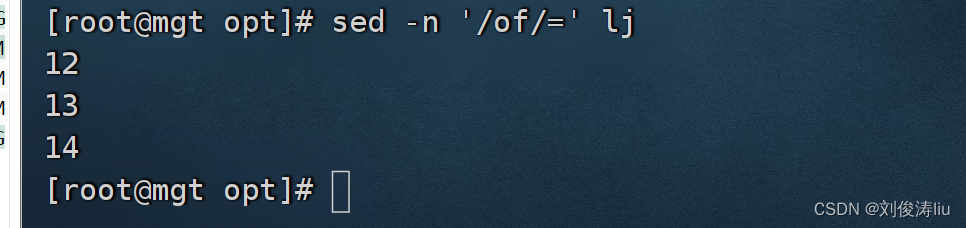
sed -n '/the/=' test.txt #打印包含the的行号

2.删除符合条件的文本
nl lj | sed '3d' #删除第3行
nl lj | sed '3,5d'
nl lj | sed '/the/d' #删除of所在行
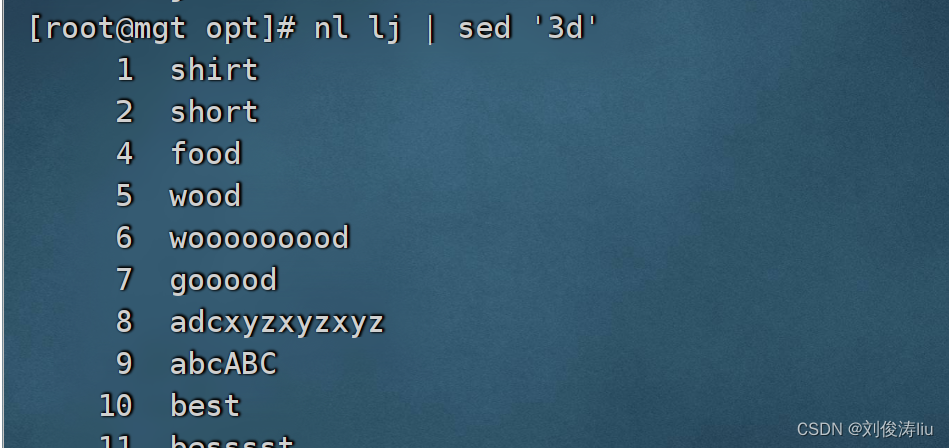

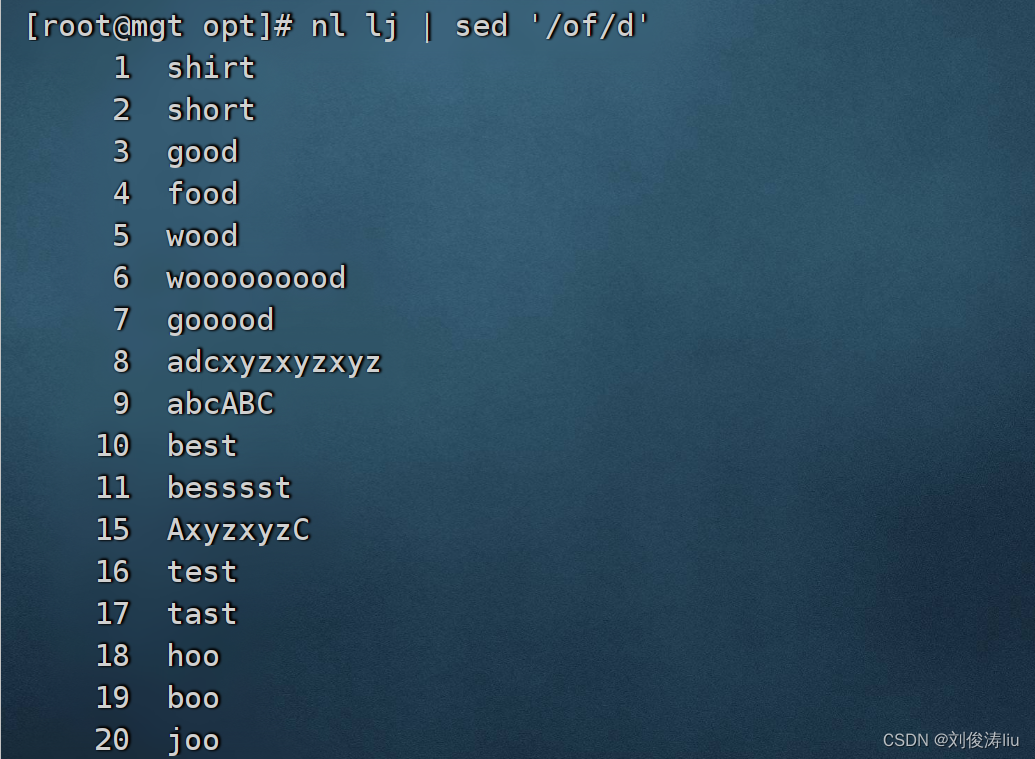
3.替换符合条件的文本
nl test.txt | sed 's/the/TTTTTT/' #替换全文本
nl test.txt | sed '4s/oo/TTTTTT/' #替换第4行
nl test.txt | sed 's/l/L/2' #替换匹配到的第2个l
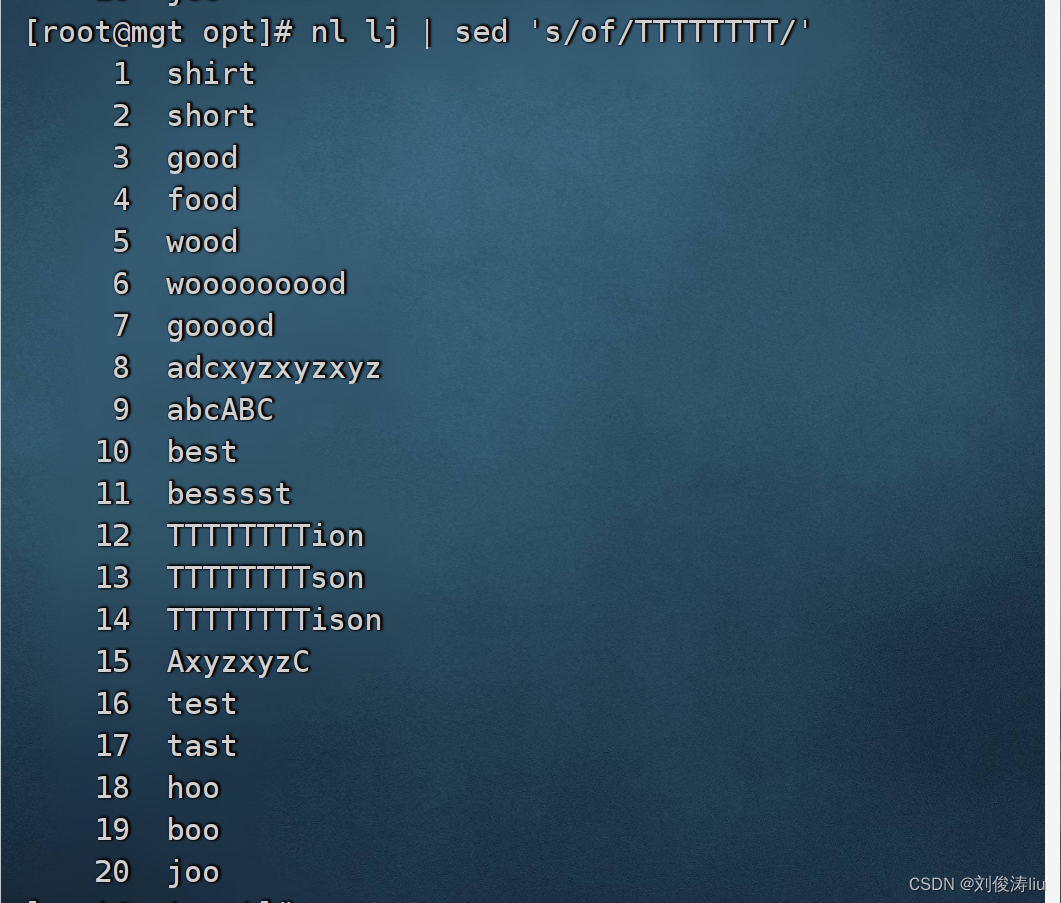
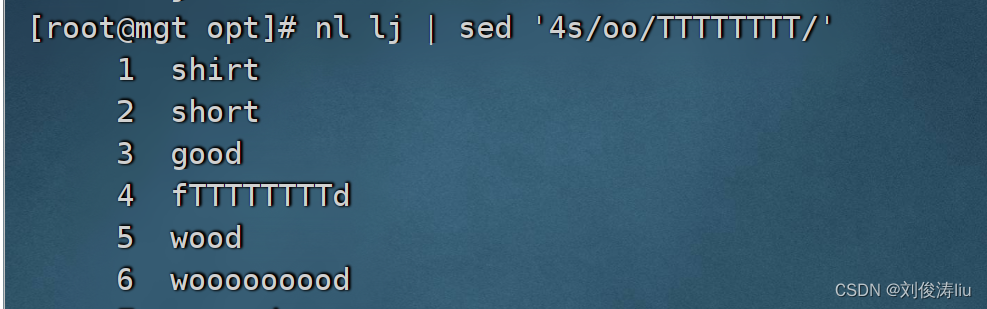
4.迁移符合条件的文本
H:复制;g:覆盖;G:追加行;w:保存;r:读取;a:追加内容
sed '/the/{H;d};$G' test.txt #匹配the所在行并迁移至文件末尾
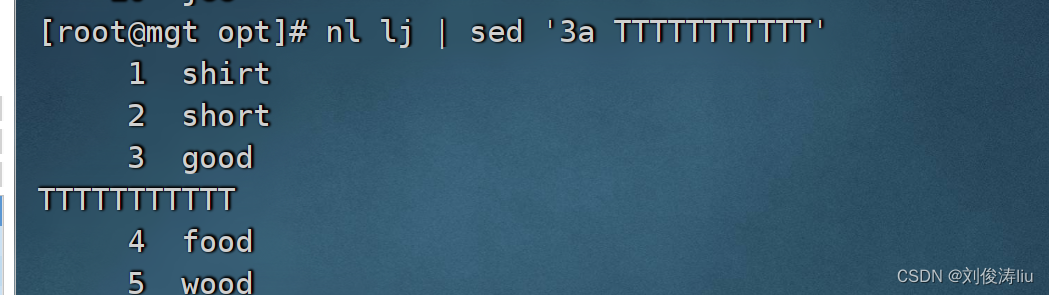
sed '3aTest' test.txt #在第3行下面新建行并写入Test
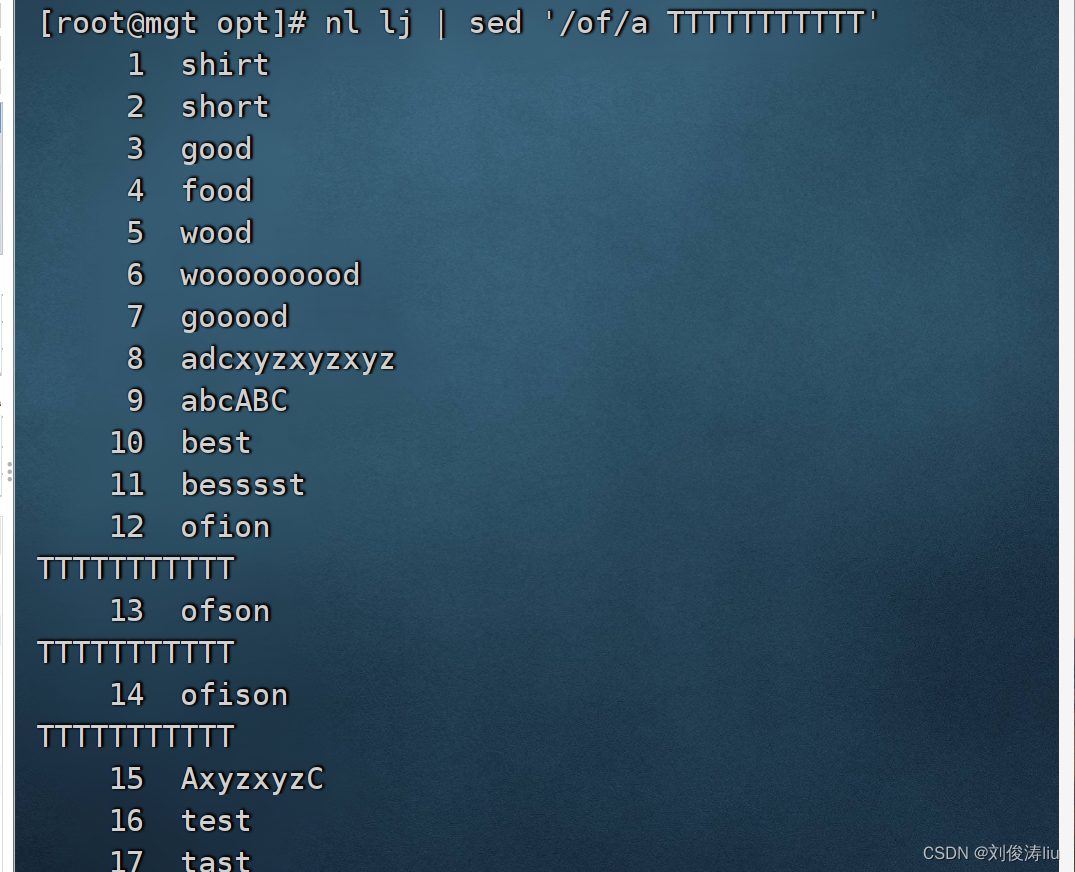
sed '/of/aTTTTTT' lj #匹配of所在行并在下一行写入TTTTTTTT
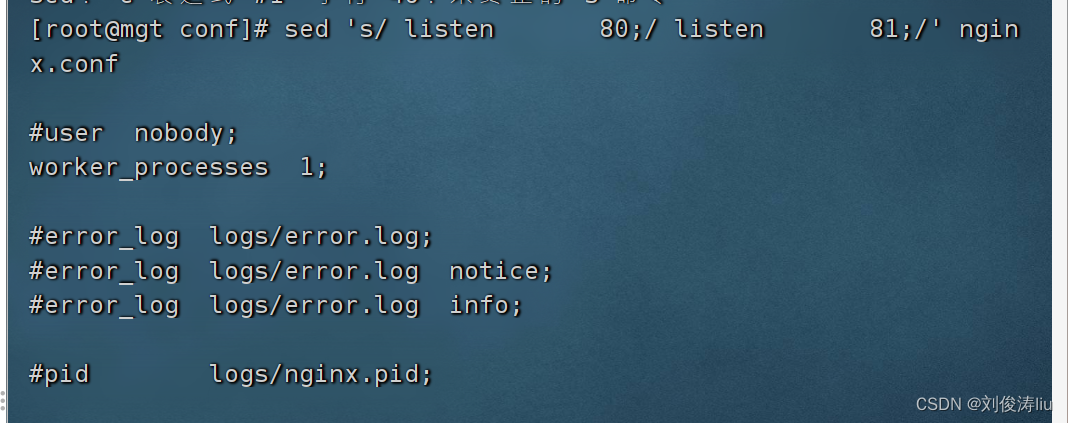
来一个实例
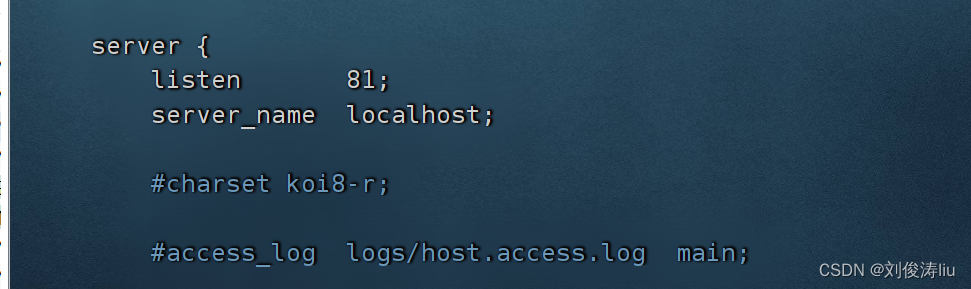
sed 's/ listen 80;/ listen 81;/' nginx.conf
sed 's/ listen 80;/ listen 81;/' nginx.conf

先看一下是否更改成功
然后开始更改
sed -i 's/ listen 80;/ listen 81;/' nginx.conf
sed -n '/ listen 81;/p' nginx.conf
vim nginx.conf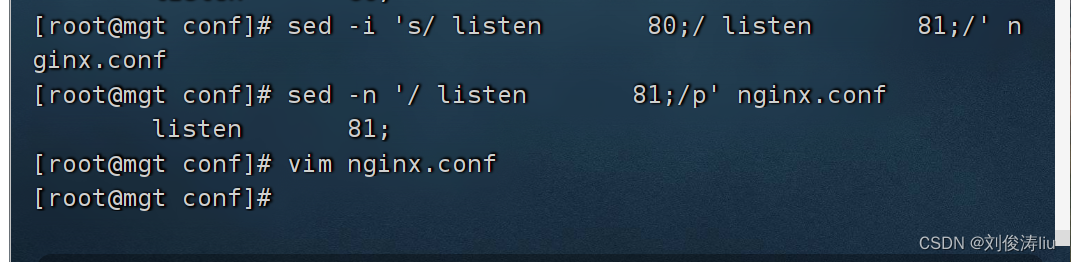
写一个脚本吧
5.使用脚本编辑文件内容
vim opt.txt
1,5H
1,5d
16G
sed -f opt.txt test.txt #将1到5行迁移至16行后
6.以上修改想要直接修改文本源文件,只需要加入选项"-i"
awk
语法
awk 选项 '模式或条件{编辑命令}' 文件1 文件2 ...
awk -f 脚本文件 文件1 文件2 ...
选项
-F 指定每行的分隔符
默认分隔符为空格
内建变量
FS:指定每行的分隔符
NF:指定当前处理行的字段个数
NR:当前处理行的行号
$0:当前处理行的整行内容
$n:当前处理的第n个字段
FILENAME:处理文件名
RS:数据记录分隔,默认是\n
案例:
a)按行输出
awk '{print}' test.txt #等同cat
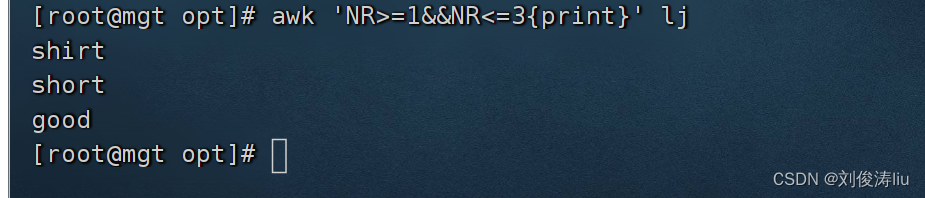
awk 'NR>=1&&NR<=3{print}' test.txt
这个AWK命令的意思是从文件"test.txt"的第1行到第3行
awk 'NR==1,NR==3{print}' test.txt #打印1到3行
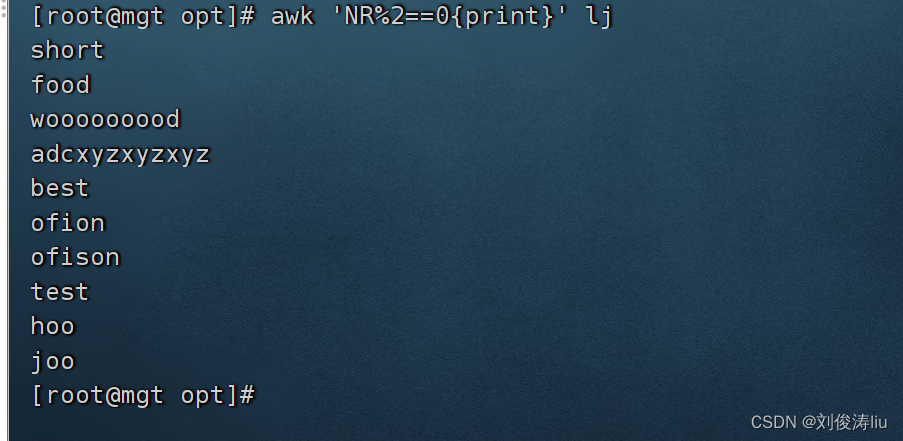
awk 'NR%2==0{print}' test.txt #打印偶数行
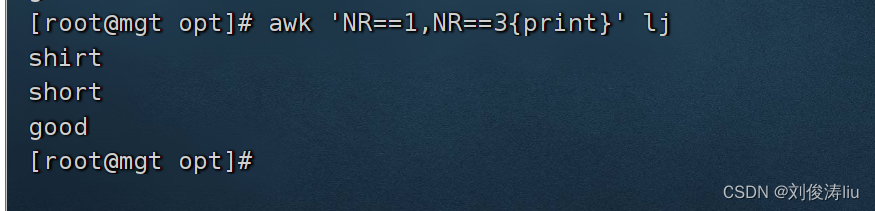
b)按段输出
默认以"空格"分段!
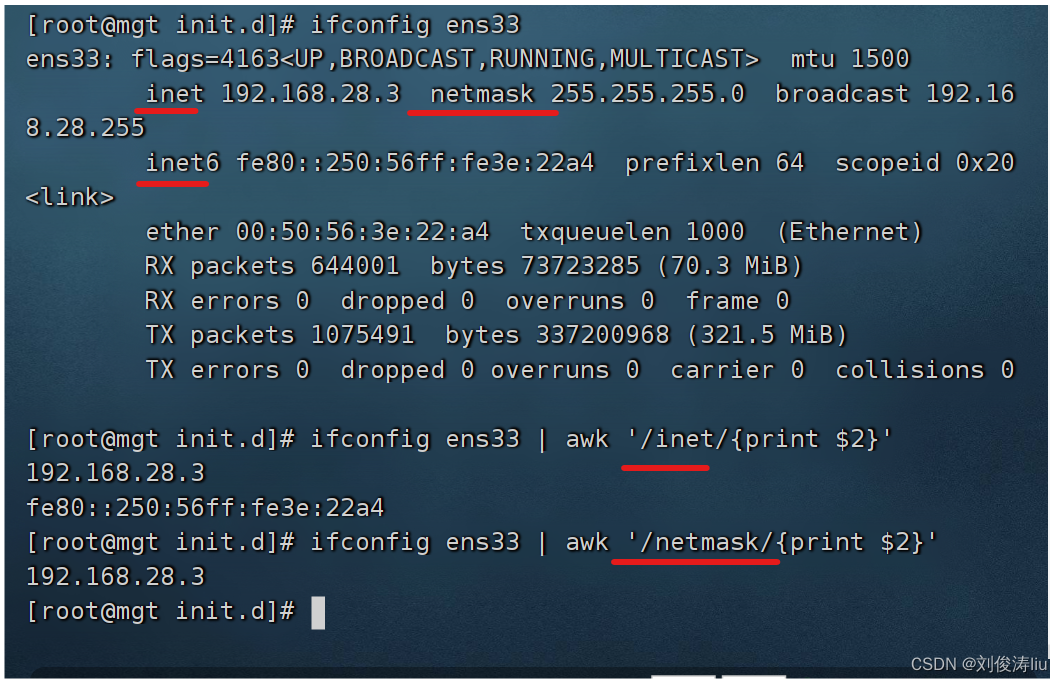
ifconfig ens33 |awk '/netmask/{print $2}' #筛选IP地址
cat /etc/shadow | awk -F : '$2=="!!"{print $1}' #打印不能登录系统的用户
c)调用shell命令
cat /etc/passwd | awk -F : '/bash$/{print | "wc -l"}' /etc/passwd #统计能够登录系统的用户个数
还有一个等一会执行的命令
sleep后面是多少就是多少秒