前几个月在B站听到了许多AI孙燕姿的“作品”,自己也很好奇是如何做到的。这不最近有了点时间,体验实践了一下。
其实so-vits-svc的文档写的已经比较详细了。但实际操作起来,因为环境的原因会遇到各种问题。本篇也是将我遇到的问题整理出来,希望可以帮到你。
首先听一下我的成果,感觉还行:
【AI 周杰伦】乌梅子酱
初体验
首先说一下我的电脑环境:
- MacBook Pro M1 Pro
- Python 3.9.6
首先克隆项目到本地:
git clone https://github.com/svc-develop-team/so-vits-svc.git
然后进入项目根目录安装依赖:
pip install -r requirements.txt
Mac上安装环境及运行都没有太大问题,但是由于显卡的限制,不能完成训练操作。但是可以用来数据预处理和推理。
所以一开始,我先用了别人训练好的模型来体验了一下推理。具体操作如下:
项目根目录运行命令启动服务:
python webUI.py
终端返回结果:
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
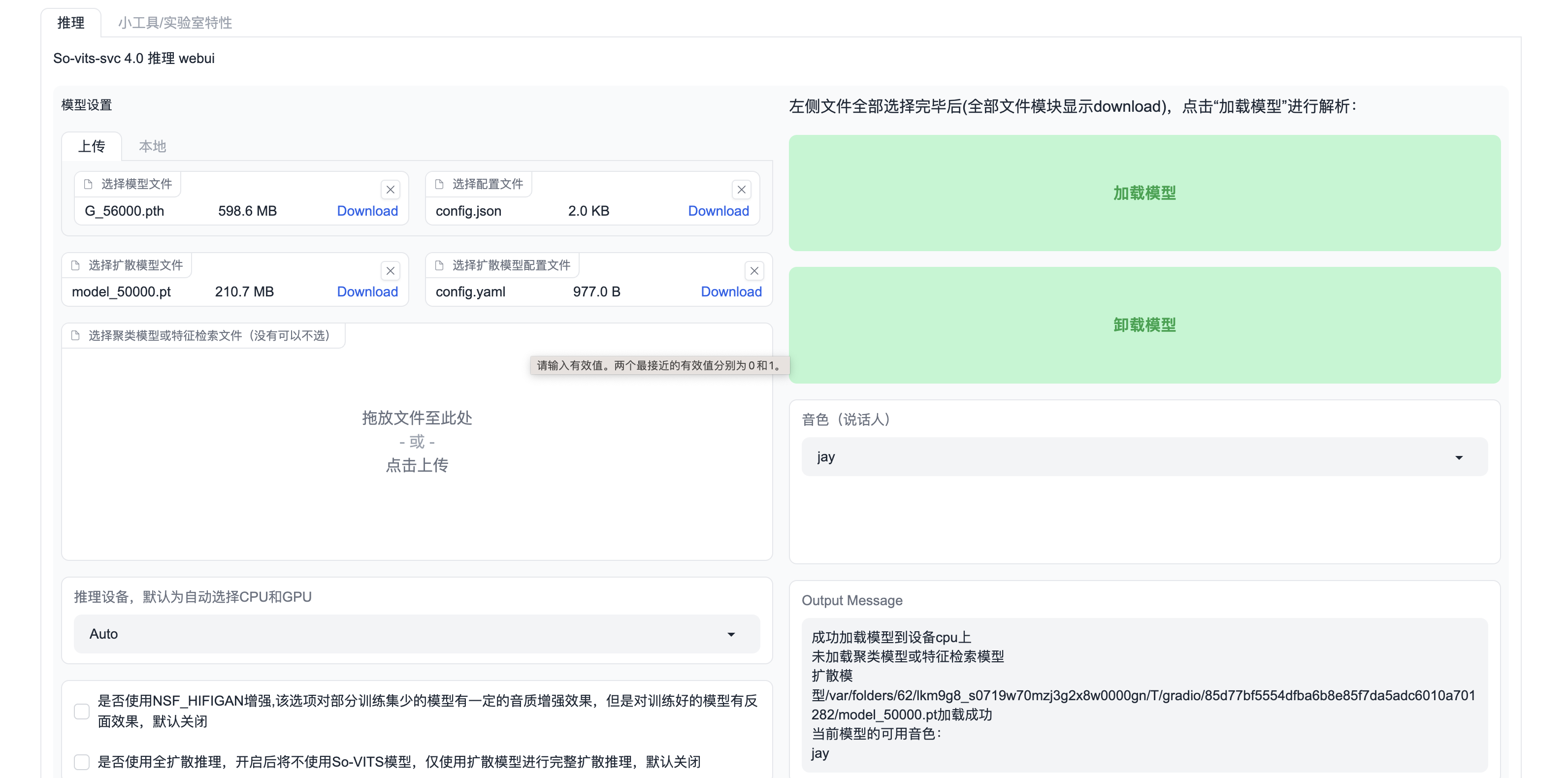
浏览器打开上面的地址,选择模型文件和配置文件然后点击右侧加载按钮。

然后滑到页面下面,上传你需要替换的音频,点击转换即可。

这里我遇到一个问题,由于使用的是4.0版本训练的模型,直接无法使用。所以为了兼容可通过修改 4.0 模型的 config.json 的配置进行支持,具体需要在 config.json 的 model 字段中添加 speech_encoder 字段。
"model": {
.........
"speech_encoder":"vec256l9"
}
4.1版本 speech_encoder 默认值为 vec768l12。这部分文档也有说明,只是一开始比较懵,没有注意到这点。
准备工作
我自己在推理之后发现效果还不错,所以就有了自己训练一个模型的想法,体验一下整个流程。
- 准备人物的干声,没有背景音,杂音,伴奏,合声,混响的纯人声。
- 时长最好1小时以上,即使时长不够也要保证声音的质量。不要滥竽充数,这会大大影响训练结果的质量。
- 音频需要切割成10s左右的片段,不要过短或者过长,wav格式。
下面我们详细说一下如何准备这些素材。
如果你准备训练自己的声音,那就可以跳过这一步。因为这一步是分离歌曲的人声和伴奏的。使用到的软件是UVR5。
第一步:选择Demucs - v3 | UVR_Model_1分离人声和伴奏。

第二步:选择VR Architecture - 5_HP-Karaoke-UVR分离上一步人声里面的和声。

如果有混响和回声,可以选择VR Architecture - UVR-DeEcho-DeReverb去除。
同理,如果推理歌曲,也是先分离出干声再推理,然后使用ffmpeg合成伴奏。
ffmpeg -i 1.wav -i 2.wav -filter_complex "[0]adelay=0s:all=1[0a];[1]adelay=0s:all=1[1a];[0a][1a]amix=inputs=2[a]" -map "[a]" output.wav
PS:上面提到的模型,需要点击图中的扳手图标,进入下载中心下载。
经过上一步我们就得到了干声。接下来我们使用Audio Slicer来进行音频切片。配置如下图:
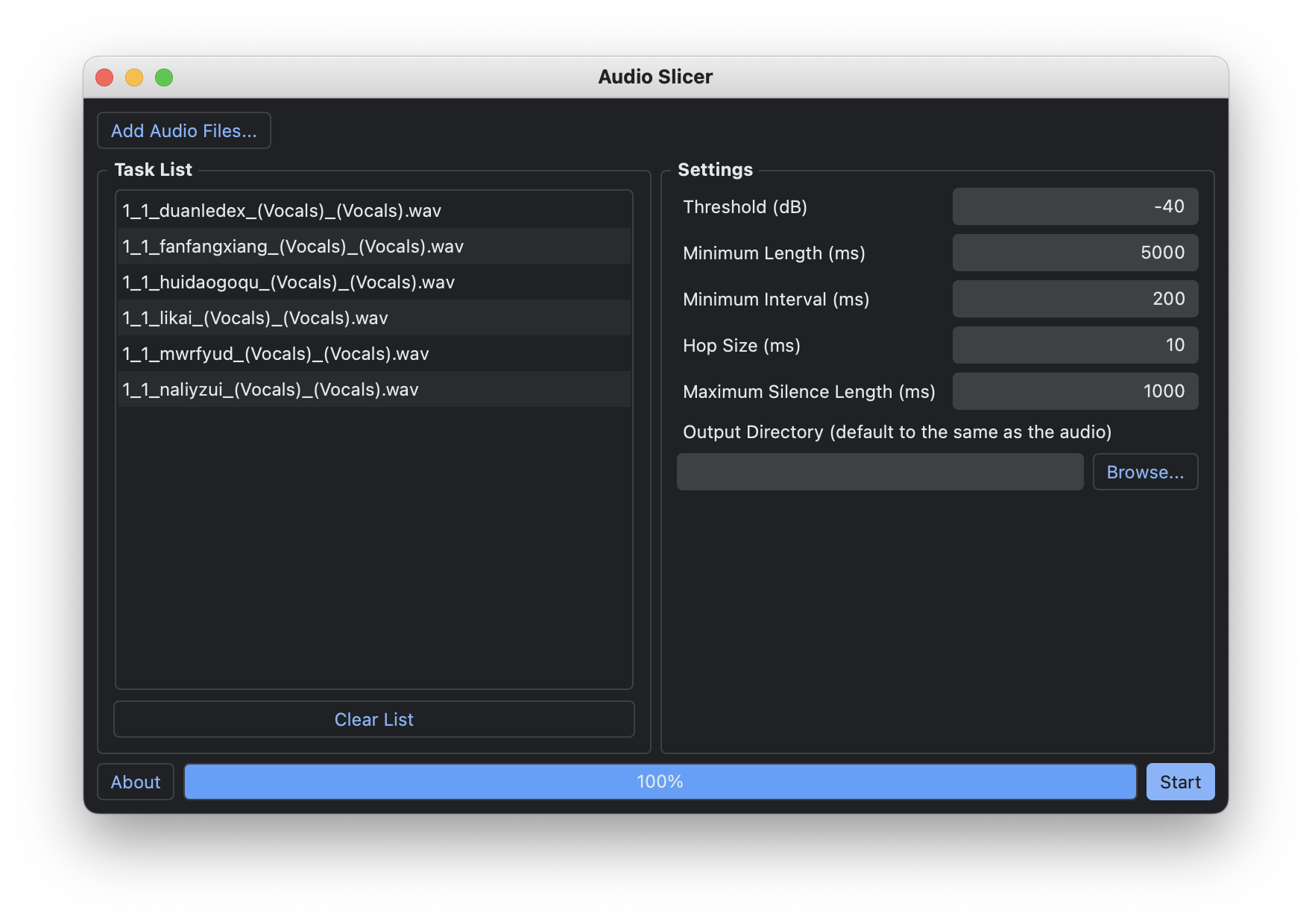
如果切片长度过长,可以降低minimum interval的值。最后挨个听一下这些切片,去掉时长,质量不符合的。
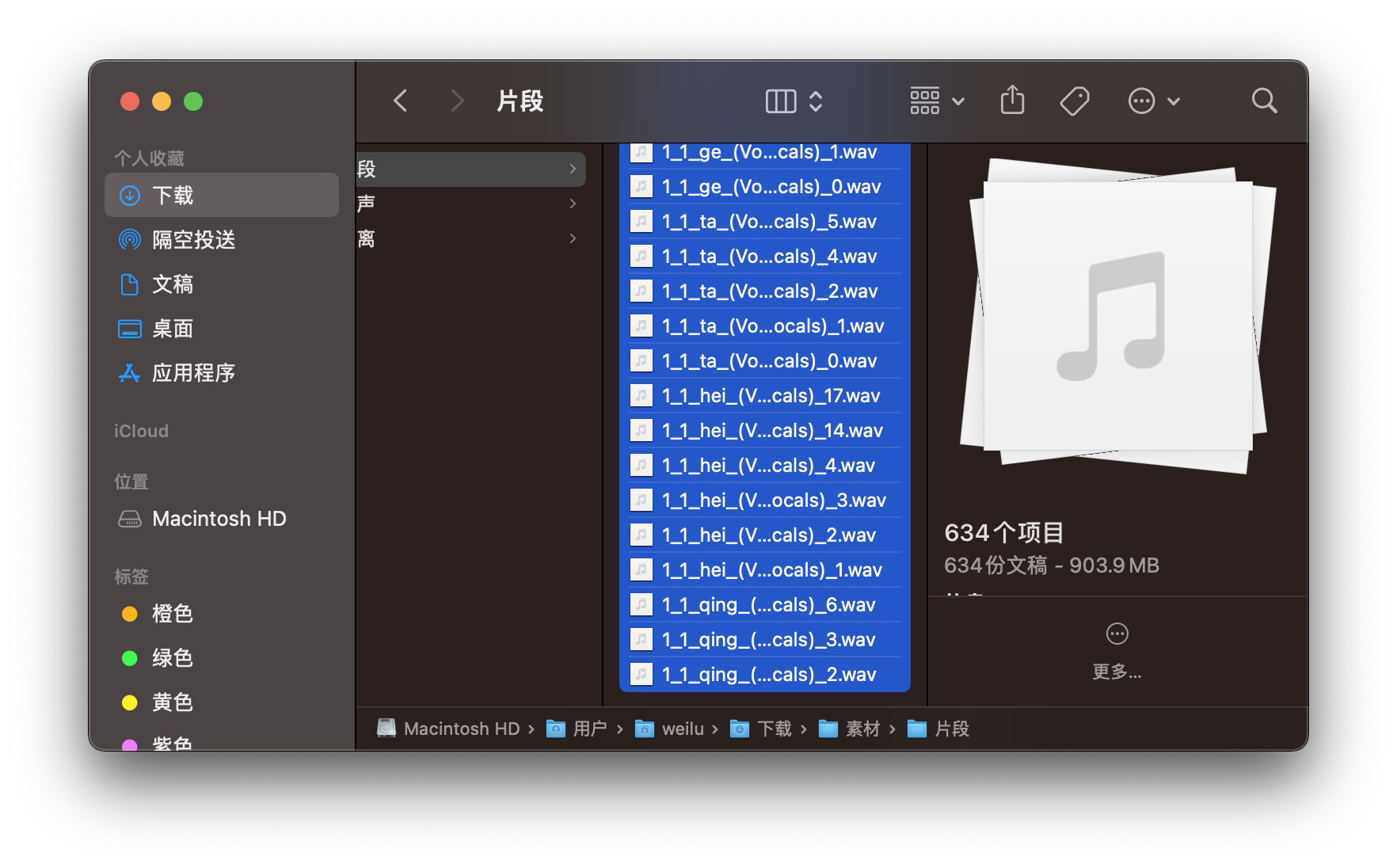
我自己按上述步骤处理了50首歌,累计花费了10个小时。。。好累。。。下图是当时的成果。注意文件名字不要有中文。
数据预处理
- 下载
checkpoint_best_legacy_500.pt放在pretrain目录下。 - 下载预训练底模文件
G_0.pth和D_0.pth放在logs/44k目录下。 - 使用浅层扩散需要下载
nsf_hifigan_20221211.zip解压后,将四个文件放在pretrain/nsf_hifigan目录下。(推荐)
以上下载链接在文档中都有,为了避免链接失效,这里就不提供了。
然后将上面准备好的数据集放入 dataset_raw 目录即可。结构如下:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
重采样至 44100Hz 单声道:
python resample.py
自动划分训练集、验证集,以及自动生成配置文件:
python preprocess_flist_config.py
生成 hubert 与 f0:
python preprocess_hubert_f0.py --f0_predictor dio
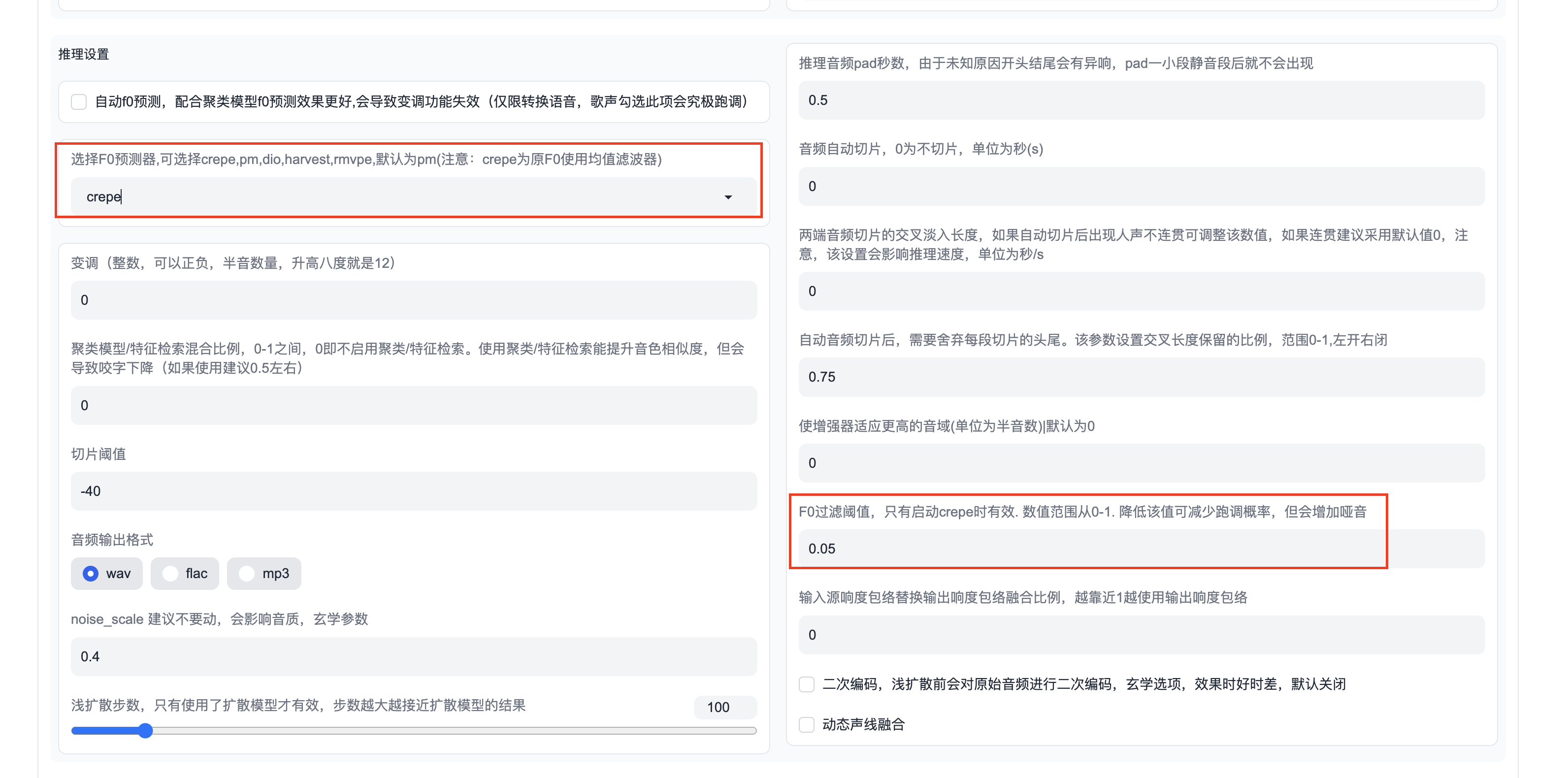
f0_predictor 拥有以下选择crepe,dio,pm,harvest,rmvpe,fcpe。如果训练集过于嘈杂,请使用 crepe 处理 f0。如果省略f0_predictor 参数,默认值为 rmvpe。
需要浅扩散功能(个人推荐),需要增加--use_diff 参数,例如:
python preprocess_hubert_f0.py --f0_predictor dio --use_diff
主模型训练
python train.py -c configs/config.json -m 44k
扩散模型(个人推荐)
尚若需要浅扩散功能,需要训练扩散模型,扩散模型训练方法为:
python train_diff.py -c configs/diffusion.yaml
模型训练结束后,模型文件保存在logs/44k目录下,扩散模型在logs/44k/diffusion下。
4.1的一个变化就是有了浅扩散,4.0的vec256l9编码器不支持扩散模型。4.1默认的vec768l12编码器优点是还原音色,缺点是咬字能力较弱,有时转换的歌曲会出现发音不准。但是浅扩散可以显著改善电音、底噪等问题。
实操
上面也提到了我自己的电脑不支持,所以只能尝试使用云端训练。方法和平台有很多,也有可以白嫖算力的。我自己最后使用的是智星云服务,前前后后折腾花了快两百块钱(租的是一小时两块的GeForce RTX 3090),具体配置和环境如下:

当然配置好的机子也有,价格也更贵。我的经验是为了节省租用费用,我们最好提前做好上面的准备工作,上传到服务提供的云盘,云端上去就是下载装环境然后训练。
但是说到装环境,或者说装Windows的环境,是我遇到问题最多的环节。下面我来分享我遇到的坑。。。
1.远程连接到云服务器后,第一件事就是确认gpu的情况是否正常。
import torch
print(torch.cuda.is_available()) #是否有可用的gpu
print(torch.cuda.device_count()) #有几个可用的gpu
我一开始有租用两个gpu的4090设备,直到训练时提示torch.cuda.OutOfMemoryError: CUDA out of memory,我就纳闷24显存的设备,我的配置也设置正常为啥提示爆显存了。后面发现只有一个gpu可用,然后我修改了代码(os.environ["CUDA_VISIBLE_DEVICES"] = "1"),指定了可用gpu,然后正常了。但是租用两个gpu价格是一个的双倍,我为啥花这个冤枉钱。这种问题的原因不清楚,可能是驱动?但我没必要花时间去处理这种问题,直接换机子最快。
2.安装依赖前先安装C++ 组件,否则会提示C++ extension is not available.。下载地址:https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/
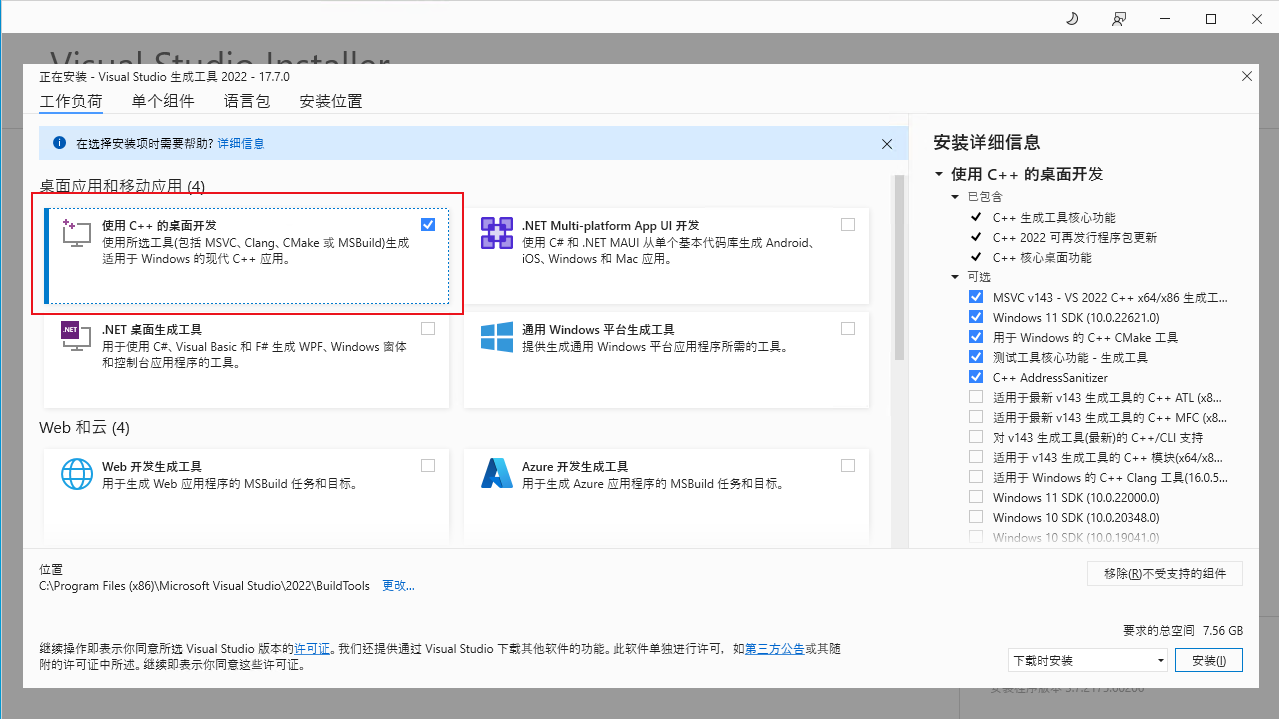
按图中选择然后点击安装。安装后可以运行pip install -r requirements_win.txt --user 安装依赖了。
3.AttributeError: module ‘numpy’ has no attribute ‘bool’.
解决方法:pip install numpy==1.23.4 --user ,安装指定numpy版本1.23.4(不加限制会下载到1.24的),所以可以一开始在requirements_win.txt文件中修改。
4.No module named ‘faiss’
解决方法:pip install faiss-cpu --user
5.Cannot uninstall ‘llvmlite’.
解决方法:pip install librosa --ignore-installed llvmlite --user
6.TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
解决方法:pip install protobuf==3.19.0 --user
7.module ‘PIL.Image’ has no attribute ‘ANTIALIAS’
解决方法:pip install Pillow==9.5.0 --user
8.OSError: [WinError 1455] 页面文件太小,无法完成操作 或 torch.multiprocessing.spawn.ProcessExitedException: process 0 terminated with exit code 3221225477
解决方法:按文中内容操作设置。
9.torch.cuda.OutOfMemoryError: CUDA out of memory
解决方法:修改configs/config.json文件中的batch_size参数。比如24G显存我设置的18。
10.TypeError: init() got an unexpected keyword argument ‘dtype’
解决方法:我直接删除了train.py代码中的dtype参数。
11.ImportError: cannot import name ‘Mish’ from ‘torch.nn’
这个是训练扩散模型时遇到的,需要升级torch。首先是我租用设备的版本信息如下:
>>> import torch
>>> torch.__version__
'1.8.0+cu111'
>>> import torchvision
>>> torchvision.__version__
'0.9.0+cu111'
所以升级选择的是:
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
经过上述一系列的坑,现在我上去装这一套环境到能正常跑起来只需要三四十分钟(主要是下载耗时,虽然下载速度已经很快了)。真是熟练的让人心疼,哈哈。
过程记录
我准备了379个音频片段,时长45分钟。(一开始有六百多片段,一个半小时。后面发现训练出来的效果不理想,删除了一些效果不好的。)
主模型训练过程图:
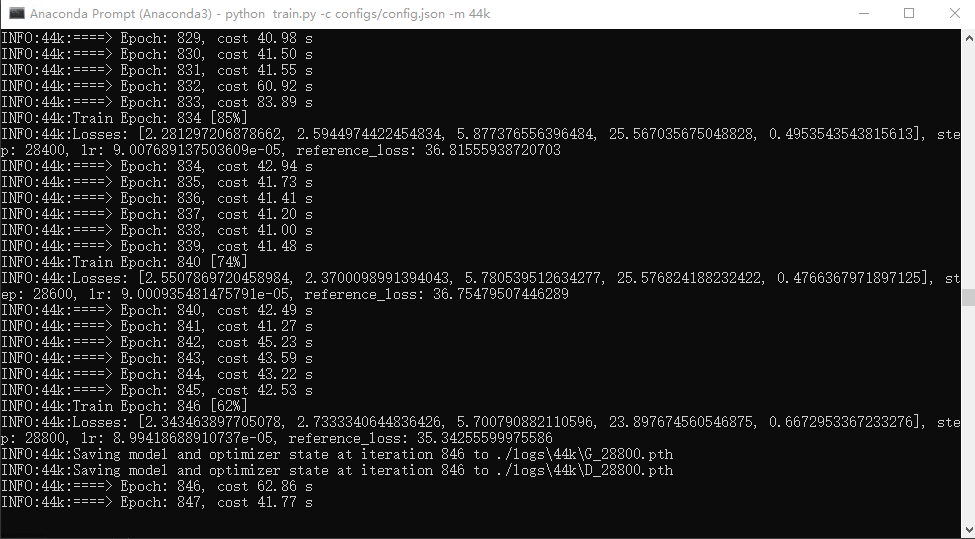
这个截图是当时训练六百多条数据时的,如果没有将configs/config.json文件中all_in_mem改为true,大概一次epoch 60s左右。七八分钟两百步的样子。图中是开启后的效果,提升了30%的样子。后面三百多条数据时,大概一次epoch 25s左右。
扩散模型训练过程图:

浅扩散速度就很快了,跑了大约三小时5万步就出来了。
关于浅扩散步数
完整的高斯扩散为 1000 步,当浅扩散步数达到 1000 步时,此时的输出结果完全是扩散模型的输出结果,So-VITS 模型将被抑制。浅扩散步数越高,越接近扩散模型输出的结果。如果你只是想用浅扩散去除电音底噪,尽可能保留 So-VITS 模型的音色,浅扩散步数可以设定为 50-100.
TensorBoard:(查看命令:tensorboard --logdir=logs/44k)
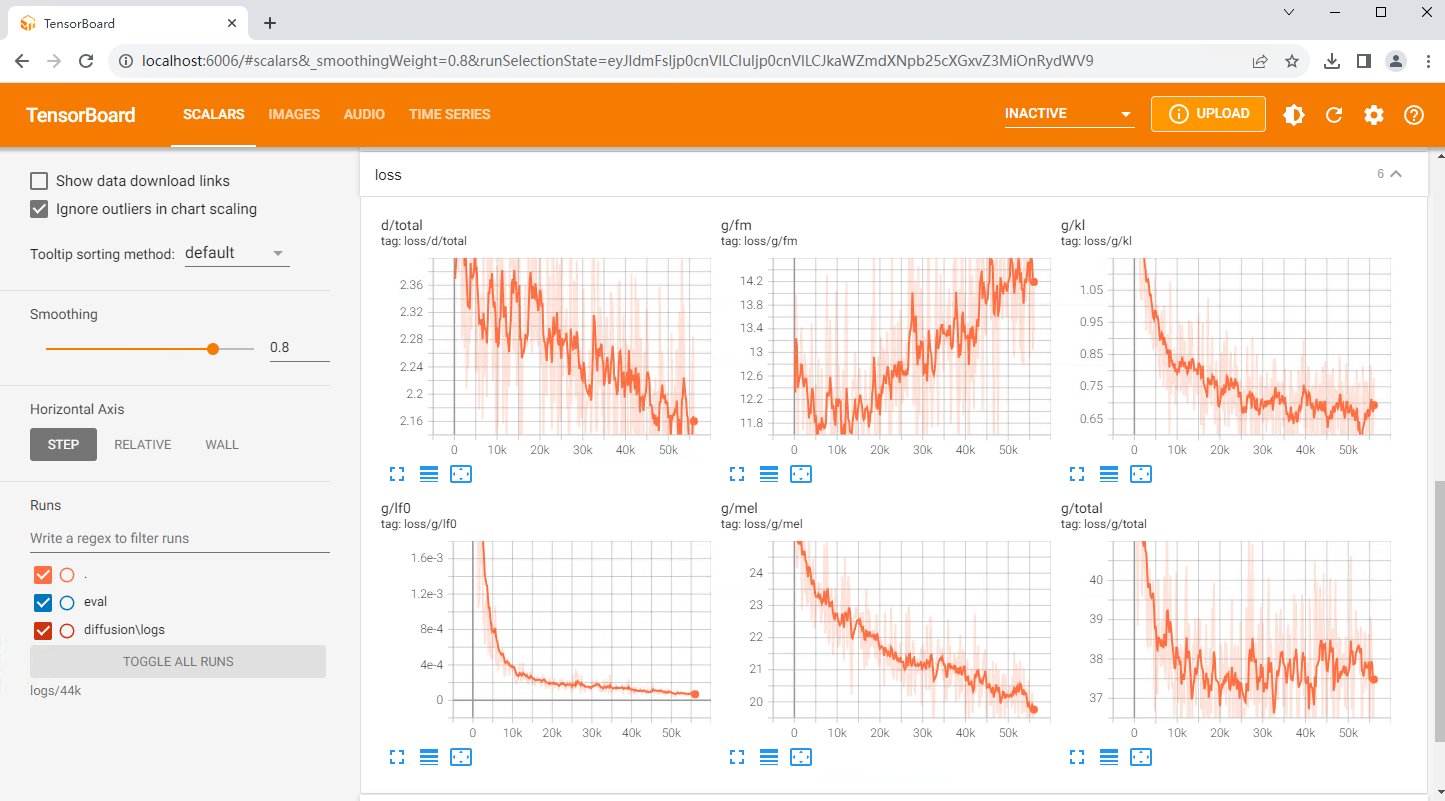
下面引用大佬关于loss的指标说明:
- loss/g/total上升,loss/d/total收敛:考虑数据集质量问题。
- loss/g/fm上升为正常现象。
- loss/g/total先下降后上升:考虑是否过拟合。
- loss/g/lf0应收敛在1e-4以下,loss/g/kl应收敛在0.5以下,loss/g/mel应震荡下降。
- 这绝不是衡量模型的唯一标准,最好的loss计算器就是你自己。
总结
目前我主模型和扩散模型都训练了5万步,效果还可以。硬伤还是音频数据集质量不高,再练下去感觉提升也不会太多了。
以我目前的亲测尝试,选择crepe作为f0预测器可以减少一些哑音,但是会跑调(具体数值需要自己去调整)。使用浅扩散模型可以减少电流音。当然这两个同时打开推理的时间也会变得很长。但是效果也是相对较好的。另外发现rmvpe的效果也不错。
文末,我也贴出来了我参考过的一些相关内容,希望可以帮到你。
到此,就是我最近对so-vits-svc-4.1的完整心得记录,后面如果有新的发现也会继续更新。如果你也有好的经验及建议,欢迎评论区讨论。文中如果有理解不对的地方也欢迎指出,让我们共同进步!
参考
- 最强 AI 人声伴奏分离工具 UVR5
- So-VITS-SVC 4.0 训练/推理常见报错和Q&A
- 【AI变声/翻唱】so-vits-svc指南
- so-vits-svc4.0 中文详细安装、训练、推理使用教程
- 手把手教你声音克隆(so-vits-svc)
- 喂饭级SO-VITS-SVC教程,轻松生成AI歌曲


![自动化脚本本地可以跑成功云服务器报错:FileNotFoundError:[Errno 2] No such file or directory](https://img-blog.csdnimg.cn/4e9df83219f740379c34909193fe5f9a.png#pic_center)