目录
- 一. 🦁 产品引入
- 二. 🦁 TDSQL-C数据库使用体验——实战案例
- 2.1 实战案例介绍
- 2.2 实操指导
- 1. 购买TDSQL数据库
- 2. [配置选择](https://buy.cloud.tencent.com/cynosdb#/)
- 3. 配置TDSQL-C 集群
- 4. 点击授权并创建
- 5. 记住主机名和端口
- 6. 登录TDSQL
- 7. 链接数据库
- 8. 自己创建相应的库(这里省略)
- 9. 项目目录结构
- 10. 创建读取excel文件的函数
- 11. 根据excel文件名创建数据库表名
- 12. 将读取的excel 数据保存到数据库对应的表中
- 13. 读取数据库中存入的数据
- 14. 执行函数,并生成词云图
- 15. 词云图效果展示
- 16.终端效果展示
- 17. 完整代码
- 三. 🦁 传统主从架构与TDSQL-C 计算与存储分离架构的对比
- 3.1 传统MySQL主从架构痛点
- 3.2 TDSQL-C 计算与存储分离架构的优势
- 3.3 存储架构原理
- 四. 🦁 总结
- 五. 🦁 文末福利
一. 🦁 产品引入
在当今云计算时代,不同类型的业务对高弹性、高可用性和可扩展性的需求越来越强烈,按需使用资源成为企业所需要的关键功能。为了满足这些需求,云原生数据库的Serverless化已经成为云数据库发展的重要方向之一。
过去,云数据库的发展经历了几个时代。在1.0时代,主要侧重于提供云托管的数据库服务,使用户能够将数据库迁移到云中,但管理仍然需要一定程度的关注。在2.0时代,随着容器技术的发展,出现了容器架构的云原生数据库,使数据库能够更好地与容器和微服务一起工作,实现更灵活的部署和管理。
然而,3.0时代正在迅速到来,云Serverless数据库将成为主流趋势。Serverless数据库将进一步解放用户,让他们无需关心底层基础设施的管理。这种模型下,用户只需关注数据和应用逻辑,而云服务提供商会自动处理底层的资源管理、扩展性和备份等任务。这不仅可以提高开发效率,还可以降低成本,因为资源使用是按需付费的。
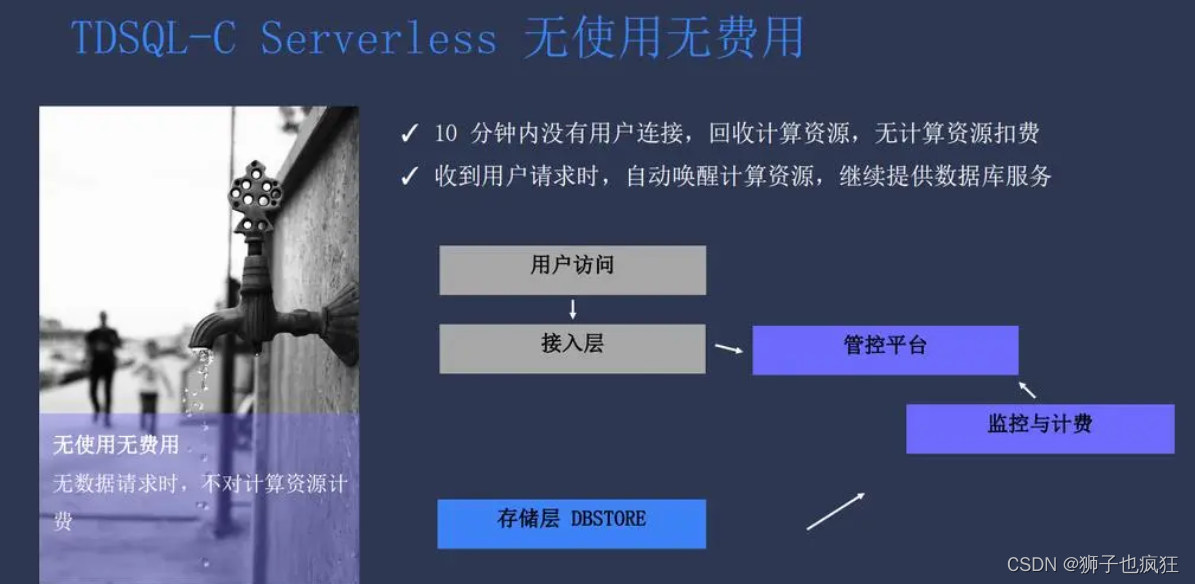
腾讯云数据库的"TDSQL-C Serverless"新版本的发布,标志着云原生数据库的Serverless化进程已经进入全面推进的阶段。这个趋势将继续推动云数据库的创新,满足不断变化的业务需求,为企业提供更强大、更灵活的数据库解决方案。
新升级的TDSQL-C推出全球首个可释放存储架构的Serverless服务。当前,业内的Serverless无法完全做到不使用不付费,一般实例暂停后仍然会收取高昂的存储费用,可释放存储将彻底解决这一问题。当实例暂停后,数据会进行归档存储,用户无需再为高额的分布式存储进行付费,可在原实例暂停后的存储费用上降低成本80%。
看到这里小伙伴们已经非常迫不及待了吧?跟着狮子来体验一下这个产品的性能是否真如介绍那样优秀叭!!!
二. 🦁 TDSQL-C数据库使用体验——实战案例
2.1 实战案例介绍
本次我们使用python 语言 进行TDSQL Serverless MySQL 进行体验, 实现思路如下:
- 读取多个本地的 excel 文件 ,并将读取的数据存储到TDSQL 中
- 从TDSQL 读取存储的数据
- 将读取的数据生成词云图,并展示;
2.2 实操指导
1. 购买TDSQL数据库
-
点击链接进入腾讯云 腾讯云链接 注册并登录
-
在搜索框输入
TDSQL-C MYSQL 版, 点击搜索
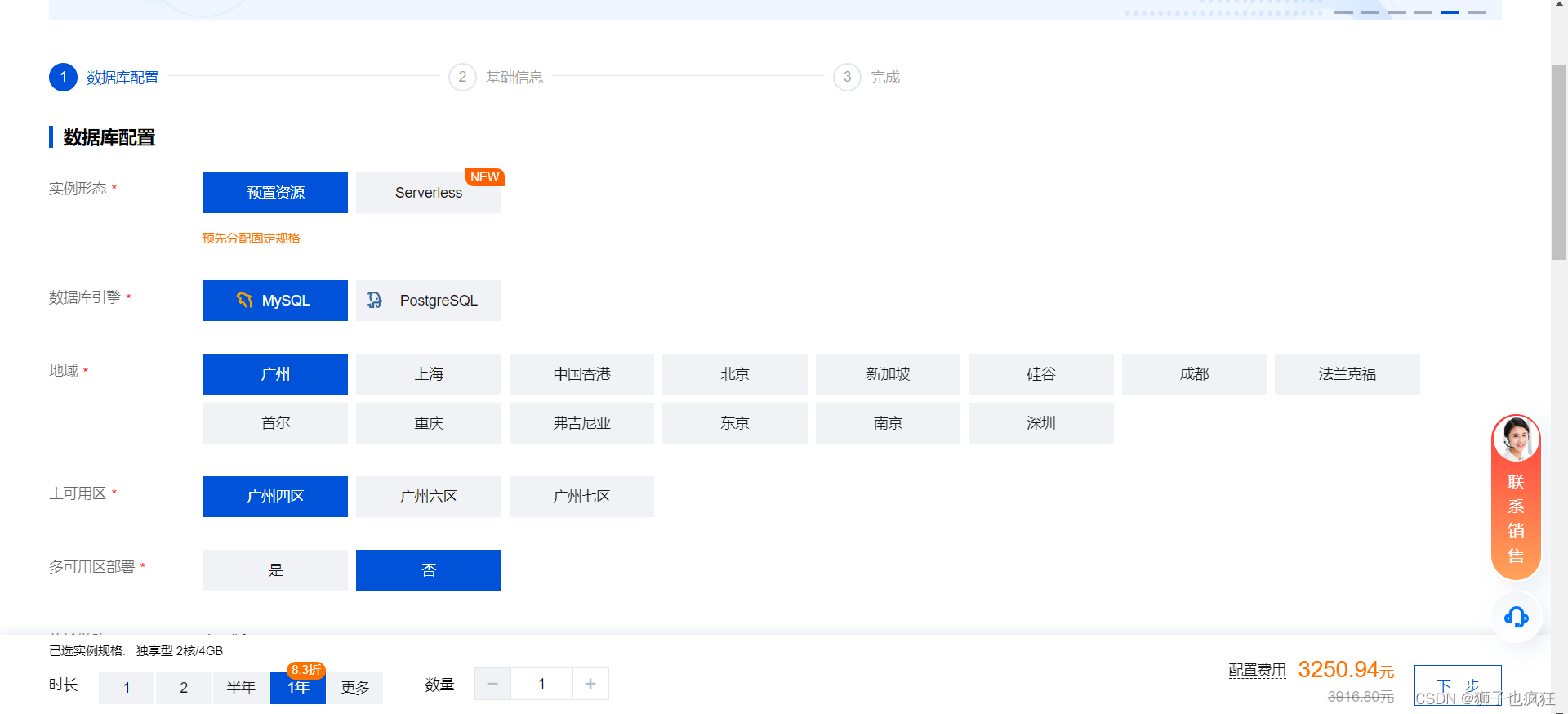
2. 配置选择
注意 选择Serverless 的实例形态哦!!!
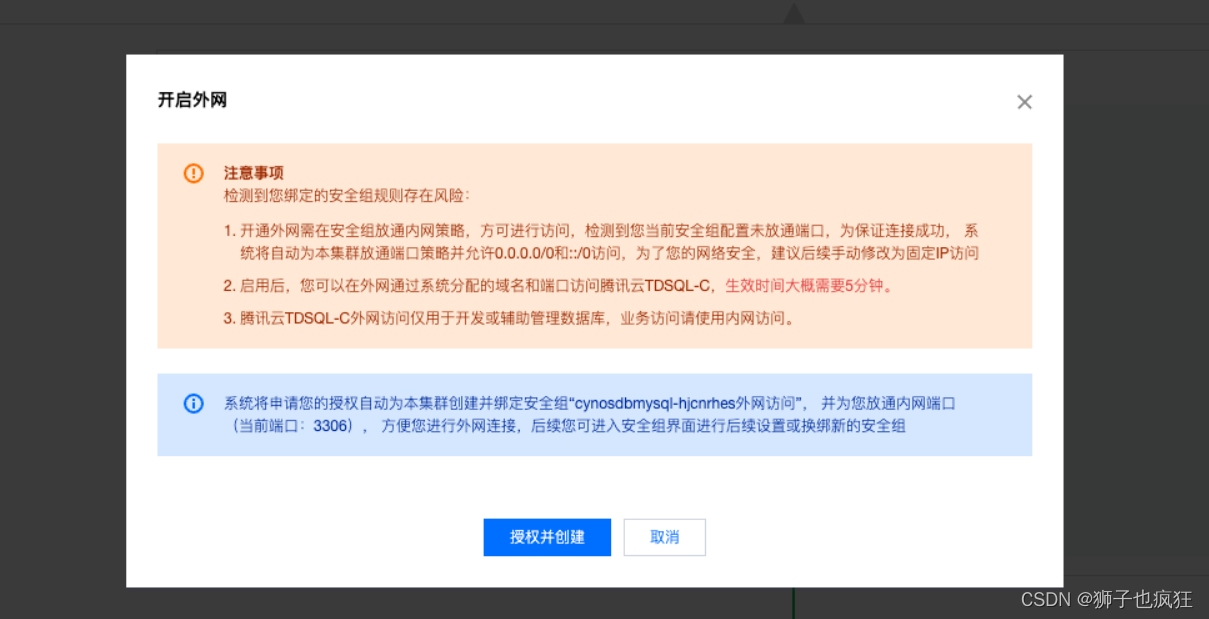
3. 配置TDSQL-C 集群
将外部读写地址开启

4. 点击授权并创建
5. 记住主机名和端口
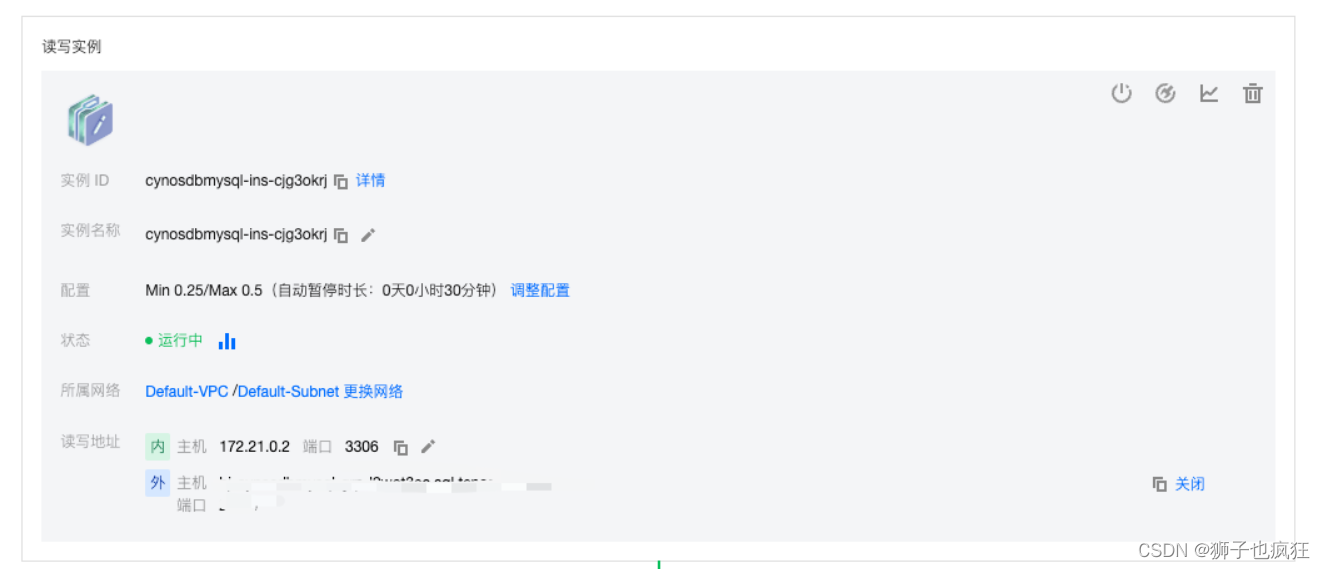
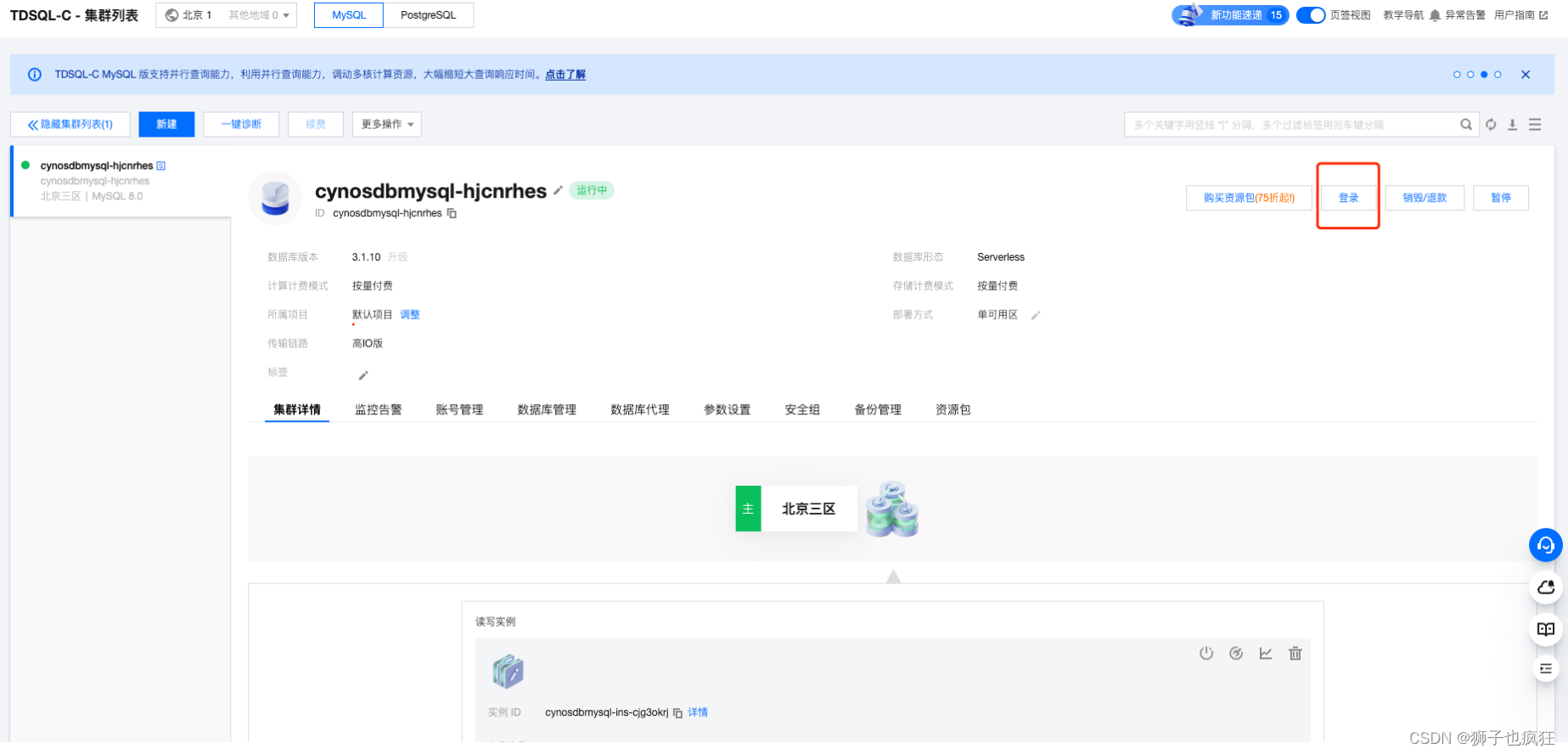
6. 登录TDSQL
点击集群的登录按钮
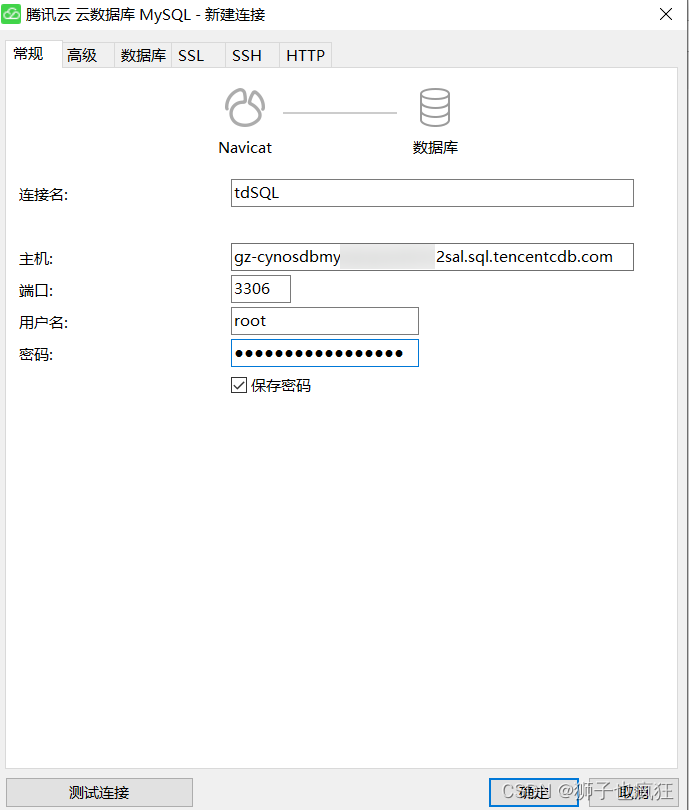
7. 链接数据库
8. 自己创建相应的库(这里省略)
9. 项目目录结构
拉取完相关资源文件后,来实操一把,项目目录结构如下:
10. 创建读取excel文件的函数
def excelTomysql():
path = '词频' # 文件所在文件夹
files = [path + "/" + i for i in os.listdir(path)] # 获取文件夹下的文件名,并拼接完整路径
for file_path in files:
print(file_path)
filename = os.path.basename(file_path)
table_name = os.path.splitext(filename)[0] # 使用文件名作为表名,去除文件扩展名
# 使用pandas库读取Excel文件
data = pd.read_excel(file_path, engine="openpyxl", header=0) # 假设第一行是列名
columns = {col: "VARCHAR(255)" for col in data.columns} # 动态生成列名和数据类型
create_table(table_name, columns) # 创建表
save_to_mysql(data, table_name) # 将数据保存到MySQL数据库中,并使用文件名作为表名
print(filename + ' uploaded and saved to MySQL successfully')
11. 根据excel文件名创建数据库表名
def create_table(table_name, columns):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 组装创建表的 SQL 查询语句
query = f"CREATE TABLE IF NOT EXISTS {table_name} ("
for col_name, col_type in columns.items():
query += f"{col_name} {col_type}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ")"
# 执行创建表的操作
cursor.execute(query)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
12. 将读取的excel 数据保存到数据库对应的表中
def save_to_mysql(data, table_name):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 将数据写入MySQL表中(假设数据只有一个Sheet)
for index, row in data.iterrows():
query = f"INSERT INTO {table_name} ("
for col_name in data.columns:
query += f"{col_name}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ") VALUES ("
values = tuple(row)
query += ("%s, " * len(values)).rstrip(", ") # 动态生成值的占位符
query += ")"
cursor.execute(query, values)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
13. 读取数据库中存入的数据
def query_data():
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 查询所有表名
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
data = []
dic_list = []
table_name_list = []
for table in tables:
# for table in [tables[-1]]:
table_name = table[0]
table_name_list.append(table_name)
query = f"SELECT * FROM {table_name}"
# # 执行查询并获取结果
cursor.execute(query)
result = cursor.fetchall()
if len(result) > 0:
columns = [desc[0] for desc in cursor.description]
table_data = [{columns[i]: row[i] for i in range(len(columns))} for row in result]
data.extend(table_data)
dic = {}
for i in data:
dic[i['word']] = float(i['count'])
dic_list.append(dic)
conn.commit()
cursor.close()
conn.close()
return dic_list, table_name_list
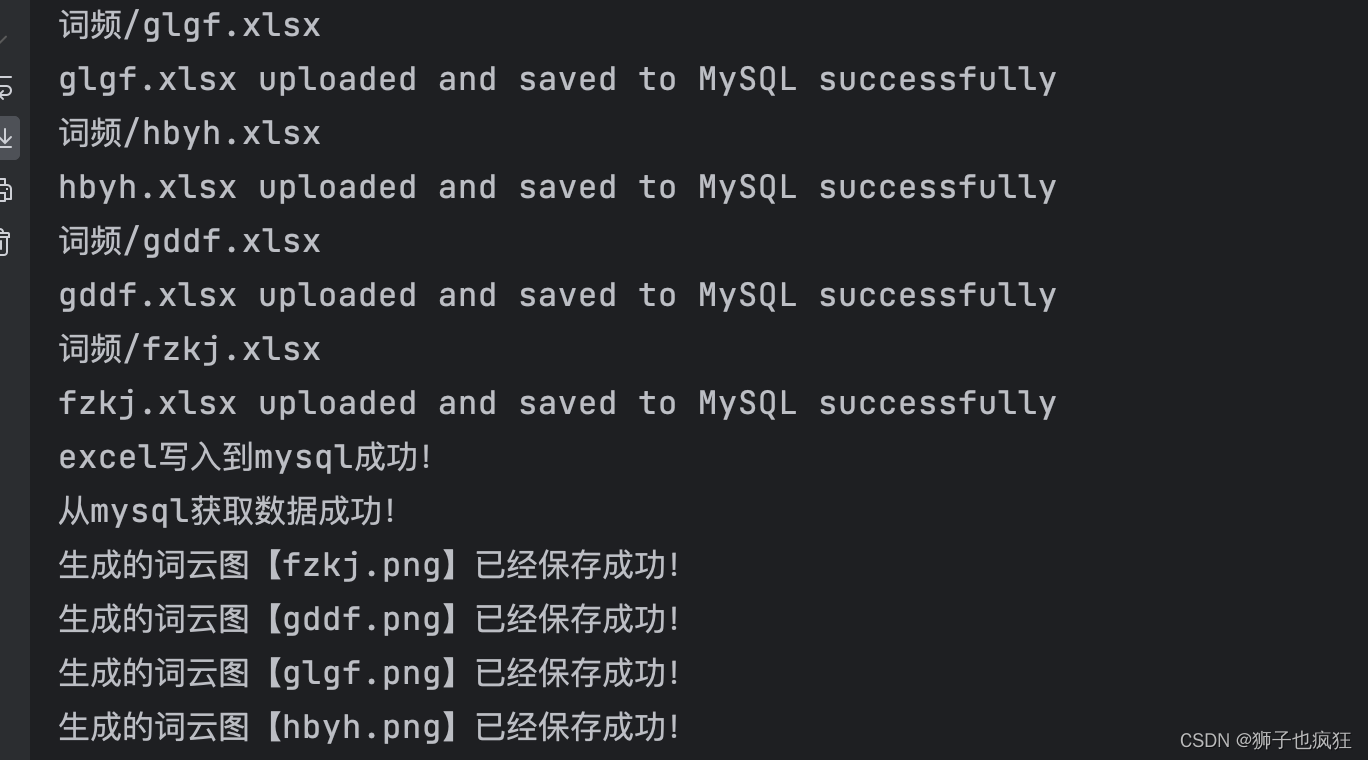
14. 执行函数,并生成词云图
if __name__ == '__main__':
##excelTomysql()方法将excel写入到mysql
excelTomysql()
print("excel写入到mysql成功!")
# query_data()方法将mysql中的数据查询出来,每张表是一个dic,然后绘制词云
result_list, table_name_list = query_data()
print("从mysql获取数据成功!")
for i in range(len(result_list)):
maskImage = np.array(Image.open('background.PNG')) # 定义词频背景图
# 定义词云样式
wc = wordcloud.WordCloud(
font_path='PingFangBold.ttf', # 设置字体
mask=maskImage, # 设置背景图
max_words=500, # 最多显示词数
max_font_size=100) # 字号最大值
# 生成词云图
wc.generate_from_frequencies(result_list[i]) # 从字典生成词云
# 保存图片到指定文件夹
wc.to_file("词云图/{}.png".format(table_name_list[i]))
print("生成的词云图【{}】已经保存成功!".format(table_name_list[i] + '.png'))
# 在notebook中显示词云图
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
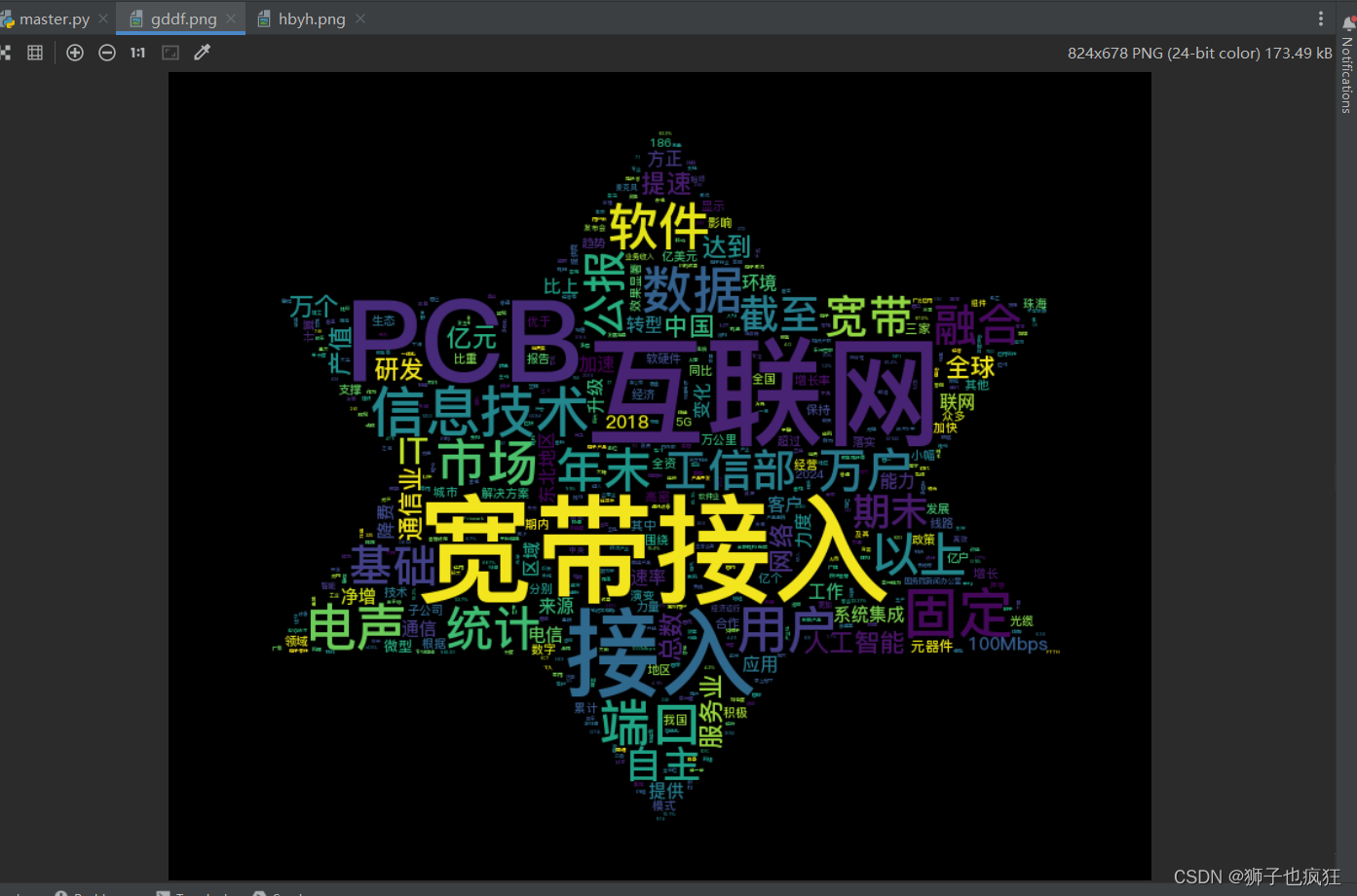
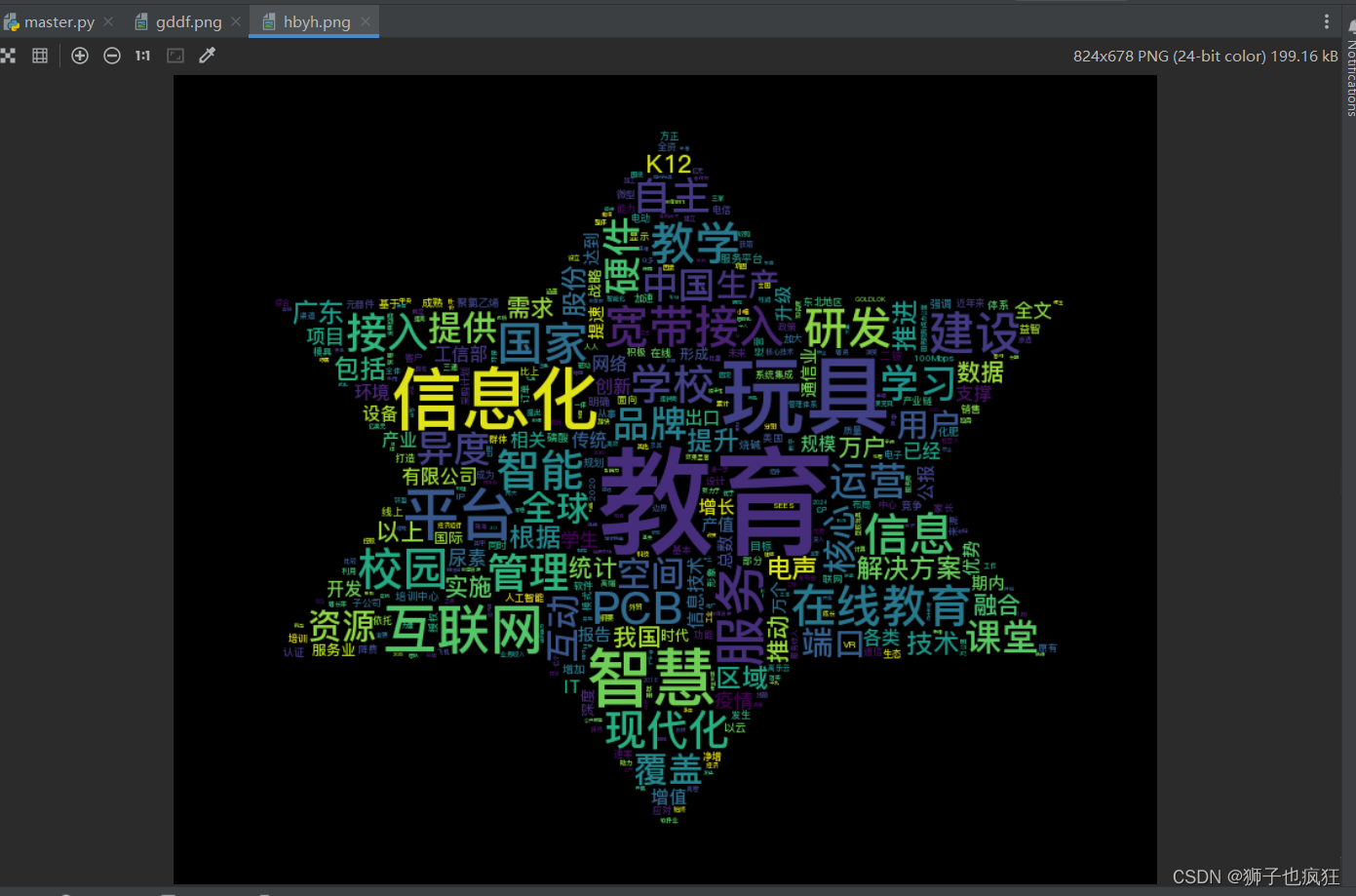
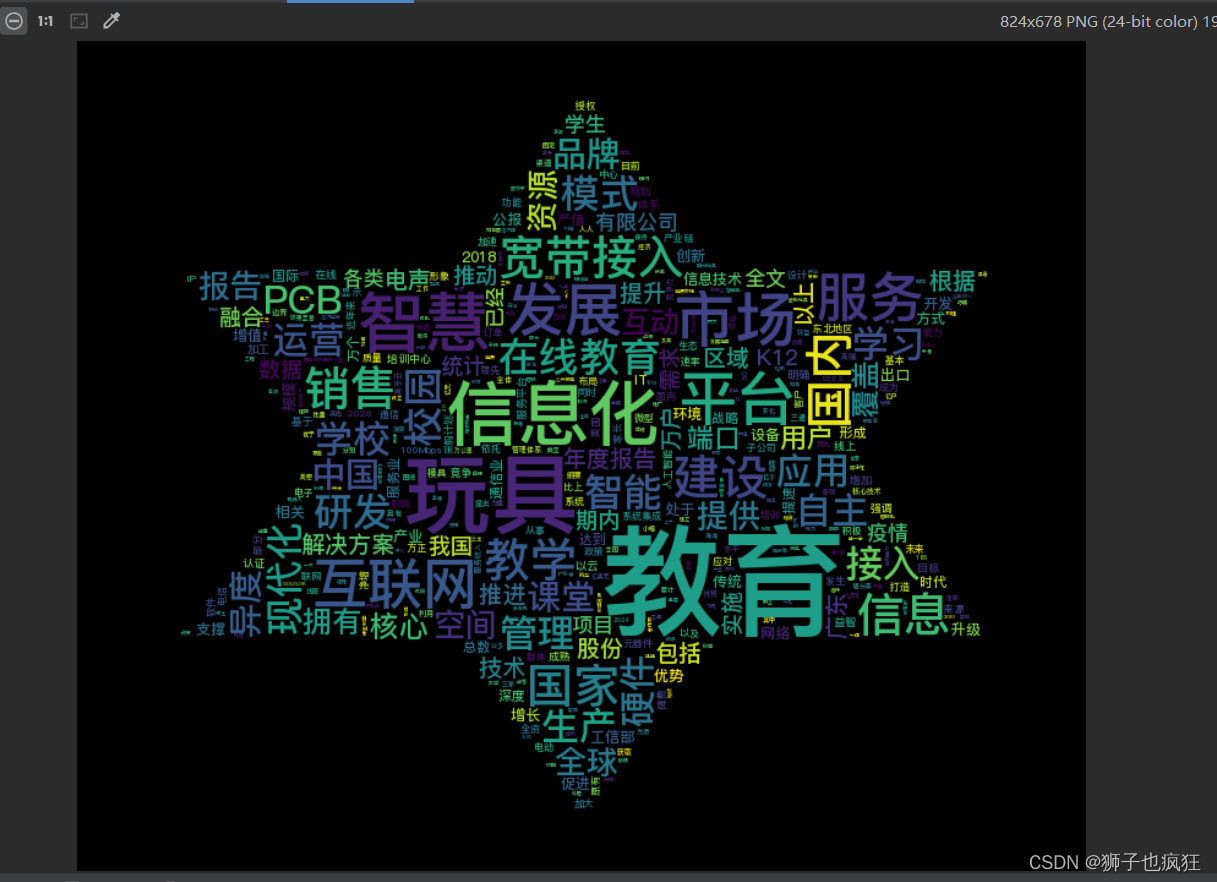
15. 词云图效果展示
16.终端效果展示
17. 完整代码
import pymysql
import pandas as pd
import os
import wordcloud
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
# MySQL数据库连接配置
db_config = {
'host': "gz-xxxxxxysql-grp-kb212sal.sql.tencentcdb.com", # 主机名
'port': 25648, # 端口
'user': "root", # 账户
'password': "TDSQL-C@!@Rgpk14.", # 密码
'database': 'db0',
}
def create_table(table_name, columns):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 组装创建表的 SQL 查询语句
query = f"CREATE TABLE IF NOT EXISTS {table_name} ("
for col_name, col_type in columns.items():
query += f"{col_name} {col_type}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ")"
# 执行创建表的操作
cursor.execute(query)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
def excelTomysql():
path = '词频' # 文件所在文件夹
files = [path + "/" + i for i in os.listdir(path)] # 获取文件夹下的文件名,并拼接完整路径
for file_path in files:
print(file_path)
filename = os.path.basename(file_path)
table_name = os.path.splitext(filename)[0] # 使用文件名作为表名,去除文件扩展名
# 使用pandas库读取Excel文件
data = pd.read_excel(file_path, engine="openpyxl", header=0) # 假设第一行是列名
columns = {col: "VARCHAR(255)" for col in data.columns} # 动态生成列名和数据类型
create_table(table_name, columns) # 创建表
save_to_mysql(data, table_name) # 将数据保存到MySQL数据库中,并使用文件名作为表名
print(filename + ' uploaded and saved to MySQL successfully')
def save_to_mysql(data, table_name):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 将数据写入MySQL表中(假设数据只有一个Sheet)
for index, row in data.iterrows():
query = f"INSERT INTO {table_name} ("
for col_name in data.columns:
query += f"{col_name}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ") VALUES ("
values = tuple(row)
query += ("%s, " * len(values)).rstrip(", ") # 动态生成值的占位符
query += ")"
cursor.execute(query, values)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
def query_data():
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 查询所有表名
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
data = []
dic_list = []
table_name_list = []
for table in tables:
# for table in [tables[-1]]:
table_name = table[0]
table_name_list.append(table_name)
query = f"SELECT * FROM {table_name}"
# # 执行查询并获取结果
cursor.execute(query)
result = cursor.fetchall()
if len(result) > 0:
columns = [desc[0] for desc in cursor.description]
table_data = [{columns[i]: row[i] for i in range(len(columns))} for row in result]
data.extend(table_data)
dic = {}
for i in data:
dic[i['word']] = float(i['count'])
dic_list.append(dic)
conn.commit()
cursor.close()
conn.close()
return dic_list, table_name_list
if __name__ == '__main__':
##excelTomysql()方法将excel写入到mysql
excelTomysql()
print("excel写入到mysql成功!")
# query_data()方法将mysql中的数据查询出来,每张表是一个dic,然后绘制词云
result_list, table_name_list = query_data()
print("从mysql获取数据成功!")
for i in range(len(result_list)):
maskImage = np.array(Image.open('background.PNG')) # 定义词频背景图
# 定义词云样式
wc = wordcloud.WordCloud(
font_path='PingFangBold.ttf', # 设置字体
mask=maskImage, # 设置背景图
max_words=500, # 最多显示词数
max_font_size=100) # 字号最大值
# 生成词云图
wc.generate_from_frequencies(result_list[i]) # 从字典生成词云
# 保存图片到指定文件夹
wc.to_file("词云图/{}.png".format(table_name_list[i]))
print("生成的词云图【{}】已经保存成功!".format(table_name_list[i] + '.png'))
# 在notebook中显示词云图
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
三. 🦁 传统主从架构与TDSQL-C 计算与存储分离架构的对比
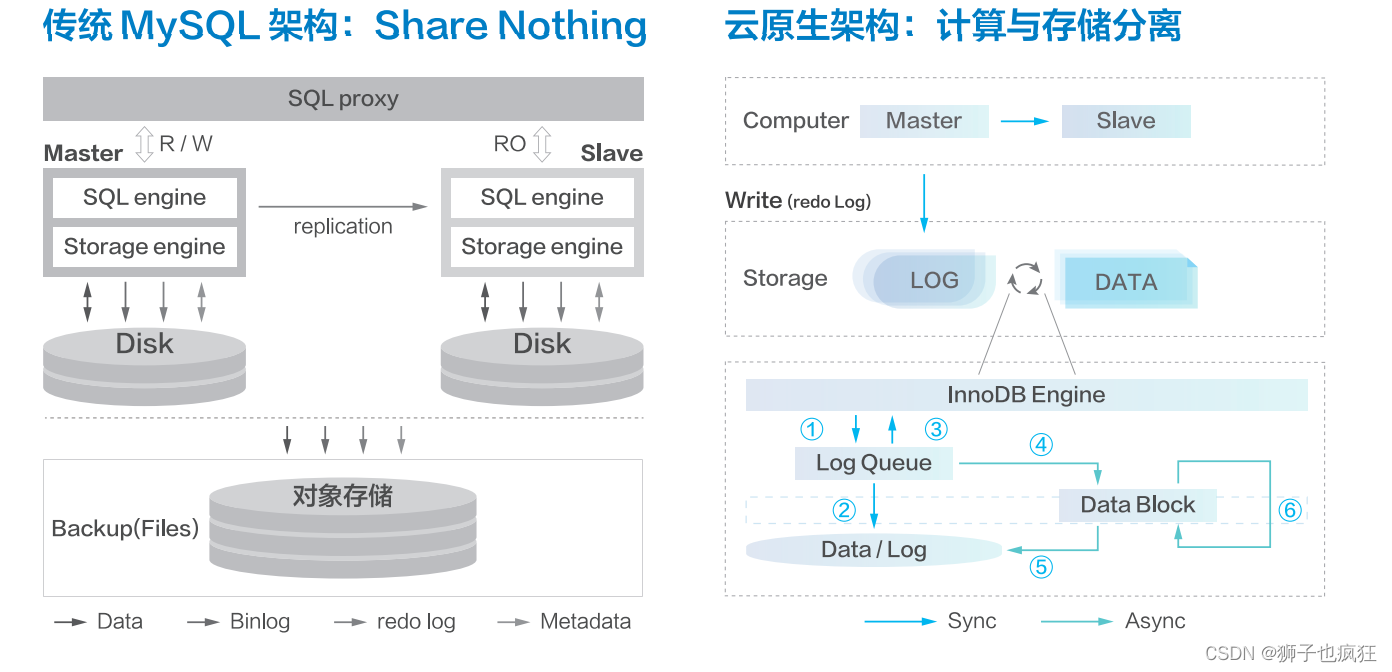
3.1 传统MySQL主从架构痛点
-
复制延迟: 主从复制中,从服务器复制主服务器上的数据。由于网络延迟、大事务、复杂查询等原因,从服务器上的数据可能会滞后于主服务器,造成数据不一致。
-
单点故障: 主从复制架构中,主服务器是关键的单点。如果主服务器发生故障,从服务器无法继续同步数据,可能需要进行手动切换以恢复。
-
数据一致性: 由于复制延迟等原因,从服务器上的数据可能不是实时更新的,这可能会导致应用程序在读取从服务器时获得不一致的结果。
-
写入压力集中: 所有写入操作都要发送到主服务器,可能会导致主服务器成为性能瓶颈,尤其是在高写入负载下。
-
复制链路故障: 如果主从复制链路遇到故障,可能会导致从服务器无法正常复制数据,需要进行手动干预来修复。
-
数据冲突: 如果在主从复制架构中同时进行写入操作,可能会导致数据冲突和不一致,需要谨慎处理。
-
拓扑复杂性: 在复杂的应用场景中,可能涉及多个主服务器和从服务器,管理和维护这些服务器的拓扑关系可能会变得复杂。
-
备份和恢复: 备份和恢复可能会变得复杂,需要确保备份不会影响主从复制的正常运行。
-
数据处理能力不均衡: 由于主从复制是单向的,从服务器无法直接处理写入操作,可能导致主服务器和从服务器之间的数据处理能力不均衡。
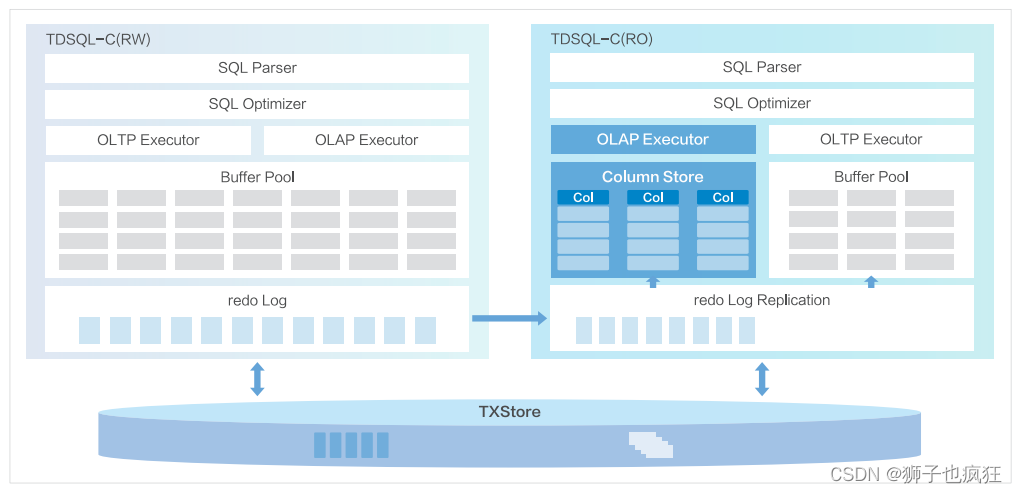
3.2 TDSQL-C 计算与存储分离架构的优势
在传统的 MySQL 主从复制架构的基础上进行了创新,带来了许多优势:
-
性能与扩展性: 基于全新架构 HTAP 能力,基于列的数据存储和查询处理,与面向行的传统存储相比,最多可实现十倍以上的查询性能提升,计算与存储分离架构使得计算节点和存储节点可以独立扩展。这意味着可以根据实际需求,独立地扩展计算资源和存储资源,从而更好地适应不同的负载情况,提高了数据库的整体性能和扩展性。
-
资源隔离: 通过将计算和存储分开,可以更好地隔离不同的工作负载。计算节点可以专注于处理查询、分析等任务,而存储节点可以专注于数据的持久化和管理,从而降低了互相干扰的可能性。
-
灵活性和弹性: 由于计算和存储是独立的,可以根据需要灵活地调整计算资源和存储资源的比例。这样在负载波动较大的情况下,可以更有效地分配资源,提供更好的弹性。
-
降低复杂性: 传统的主从复制架构中,主从之间需要保持同步,管理复杂。计算与存储分离架构简化了复制和同步的逻辑,减少了复杂性和潜在的问题。
-
高可用性: 由于计算和存储是分离的,可以更容易地实现计算节点和存储节点的高可用性。在某个节点发生故障时,可以更快速地进行故障转移或恢复。
-
资源利用率: 通过独立扩展计算和存储节点,可以更有效地利用资源。例如,可以根据查询和分析的需求,灵活地配置计算资源,从而提高资源利用率。
3.3 存储架构原理
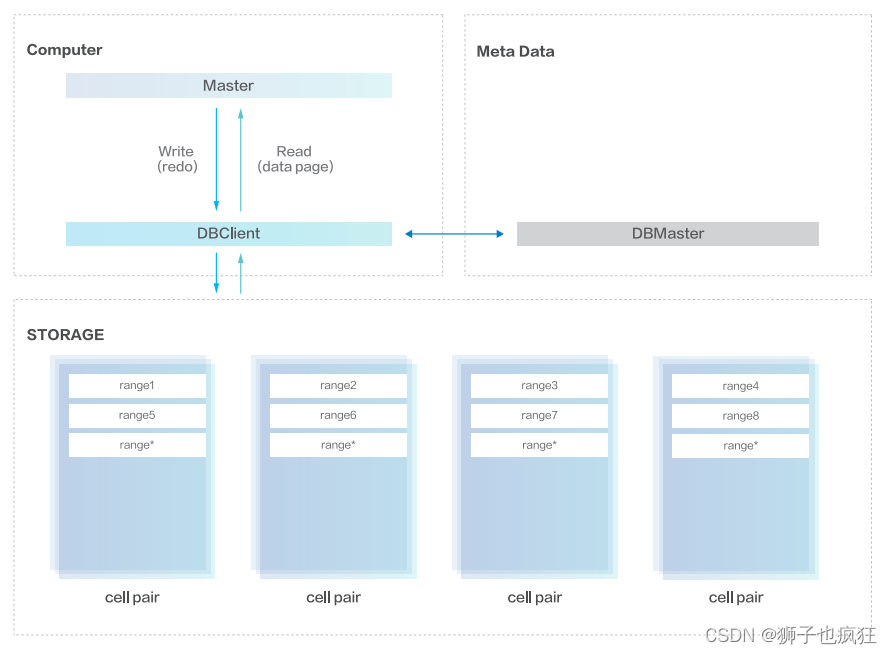
- DBClient数据路由机制
-
- 当计算节点启动时,DBClient 从 DBMaster 查询 Space 信息、Range 列表等;
-
- 计算节点写入表数据时,DBClient 根据路由信息,将 log 发送到对应的 cell pair。存储层接受日志并持久化到物理存储后回复 DBCIient,后者回复给计算节点,最终完成写入;
-
- 当计算节点读取数据时,将请求委派给 DBCIent,后者通过路由信息从存储获取数据页,并返回给计算节点,从而完成数据读取。
- 存储层架构
-
- 1个存储集群由几十或上百个 cell pair 组成;
-
- cell pair 采用主从架构,保证数据三副本;
-
- 每个range 是2G(可调整)文件,一张大表(比如 100G)拆分成多个range 分布在多个 cell pair,最终实现海量存储空间及超高10 能力;
四. 🦁 总结
云原生时代,面对海量数据的存储,高并发负载和复杂查询等场景,这样的数据库出现,你爱了吗?
五. 🦁 文末福利

🦁 送书抽奖活动 🦁

Spring Cloud Alibaba核心技术宝典:通过底层架构原理+大量即用型优质代码+经典实战案例,手把手教你掌握Spring Cloud Alibaba
本书简介
本书从分布式系统的基础概念讲起,逐步深入分布式系统中间件Spring Cloud Alibaba进阶实战,重点介绍了使用Spring Cloud Alibaba框架整合各种分布式组件的完整过程,让读者不但可以系统地学习分布式中间件的相关知识,
而且还能对业务逻辑的分析思路、实际应用开发有更为深入的理解。
全书共分5大章节,第1章开篇部分,讲解分布式系统的演进过程和Spring Cloud Alibaba概述及版本的选择,以及单体架构/微服务架构的优缺点;第2章讲解如何使用Spring Cloud Alibaba实现RPC通讯;第3章在介绍主流Nacos组件时,介绍了三元的概念以及使用Nacos实现注册中心和配置中心,包含环境的动态切换、配置的动态刷新、通用型配置、版本回滚等核心技术,为微服务环境提供基础的架构;第4章介绍了负责限流和熔断降级的Sentinel组件,包含收集系统运行状态、流量控制、熔断降级、热点、授权、系统规则、流控的异常处理、熔断的异常处理、规则持久化等;第4章介绍了网关常用案例,以及在软件项目中常用的高频使用技术点,力求为开发微服务项目的程序员提供一个快速学习的
京东链接:https://item.jd.com/14010448.html
本次活动赠书3本,评论区抽取3位小伙伴送书
活动时间: 截止到2023-08-30 20: 00 参与方式: 点赞、收藏本文章,并任意评论 抽奖时间: 2023.8.30 公布时间: 2023.8.30 通知方式:交流群内公布或私信通知
更多活动可继续关注上方🦁的博客,好运总会轮到你!!!