PostgreSQL-预研
是个很厉害的数据库的样子 ψ(*`ー´)ψ
官方文档:http://www.postgres.cn/docs/12/
总的结论和备注
PgSQL 支持对JSON的支持很强大,以及提供了很多数学几何相关的数据类型【例:点,线条,几何等】
基本语法其实和MySQL差不多,具体的就要在使用的时候去适应和学习了!!!
概述
PostgreSQL数据库是目前功能最强大的开源数据库,支持丰富的数据类型(如JSON和JSONB类型、数组类型)和自定义类型。而且它提供了丰富的接口,可以很容易地扩展它的功能,如可以在GiST框架下实现自己的索引类型等,它还支持使用C语言写自定义函数、触发器,也支持使用流行的语言写自定义函数,比如其中的PL/Perl提供了使用Perl语言写自定义函数的功能,当然还有PL/Python、PL/Tcl,等等。
PostgreSQL是为特性非常齐全的对象-关系型数据库,同时还支持NoSql的文档型存储。
PostgreSQL 对比MySQL
一、事务隔离之间的比较
| 事务隔离级别 | postgresql | mysql |
|---|---|---|
| 读未提交 | 无法读脏数据 | 有 |
| 读已提交 | 快照实现 | 快照实现 |
| 可重复读 | 有,无幻读,发生冲突时,牺牲其中一个事务 | 已实现,有幻读,悲观锁,因为Gap Lock问题,存在性能问题 |
| 可串行化 | 已实现,通过SSI实现,乐观锁,性能比较好 | 悲观锁,S2PL,性能不好,实用性比较差 |
二、持久化之间的比较
| 持久化技术 | postgresql | mysql |
|---|---|---|
| 事务的持久化 | WAL日志 | binlog和innodb的redo log |
| 页断裂问题 | full_page_writes | double write |
| 检查块的一致性 | checksum | checksum,db_lock_checking |
| 事务同步提交 | 默认是同步synchronous_commit=on,session级别可以设置,更灵活 | sync_binlog=1,innodb_flush_log_at_trx_commit=1全局参数 |
三、复制之间的比较
| postgresql | mysql |
|---|---|
| 支持物理复制和逻辑复制 | 仅支持逻辑复制 |
| 物理复制延迟小 | 逻辑复制延时大 |
| 大更新对复制延迟影响小 | 大更新对复制延迟的影响很大,很容易导致复制延迟 |
| 物理复制主备之间数据绝对一致 | 逻辑复制可能出现准备数据不一致情况 |
| 支持一主多从,支持联级复制,不支持双主架构 | 支持一主多从,支持联级复制,支持双主架构 |
四、查询相关功能的比较
| postgresql | mysql |
|---|---|
| 成熟的基于代价的SQL优化器,复杂SQL性能很好 | 查询优化器不够成熟,非完全的基于代价的SQL优化器,对复杂查询的性能较低 |
| 多种表连接类型:nested-loop join,sort-merge join,hash join | 一种表连接类型:nested-loop |
| 非常智能,可以走多个索引 | 大部分查询只能使用表上得单一索引;在某些情况下,会存在使用多个索引的查询,但是查询优化器通常会低估其成本,它们常常比表扫描还有慢 |
| pg11版本之前表增加列基本上是重建表和索引,消耗时间比较长,pg11之后对非空列添加不需要重建 | 表增加列,只是在数据字典中增表定义,不会重建表 |
| 支持在线创建索引,pg10开始支持并行创建索引 | 支持在线创建索引,不支持并发索引 |
| 支持并行查询 | mysql8.0之前不支持并行查询 |
| 支持B-树,哈希,R-树和Gist索引 | B-树,哈希(不同存储引擎) |
五、表功能之间的比较
| postgresql | mysql |
|---|---|
| 除了支持pl/pgsql写存储过程,还支持pl/perl,pl/python,pl/tcl;也支持用C语言的写存储过程 | 存储过程与触发器功能有限 |
| 有单独的sequence | 没有单独的sequence,sequence在表主键上 |
| PostGIS插件支持,PostGIS是目前使用最广泛地开源GIS系统 | GIS的支持有限 |
| 通过GIN索引提供了对JSON内部数据的索引,只要创建索引之后,不管存储json的数据格式如何变化,都能利用GIN索引加快查询 | json类型只支持虚拟列方式创建索引,不支持json内部数据的索引,当json内部的列结构不确定时,不能事先创建索引来提高查询性能 |
| 通过FDW框架完善支持外部表功能,可以方便连接其他异构数据源,如mysql,mongodb等 | 外部表功能有限,基本不具有太多实用价值 |
| 堆表,不支持索引组织表 | 索引组织表,不支持堆表 |
| ddl可以回滚,支持原子性DDL | DDL不支持回滚,mysql8.0之前多个ddl不能原子执行 |
| 支持窗口函数 | mysql8.0之前不支持窗口函数 |
六、视图和安全之间的比较
| postgresql | mysql |
|---|---|
| 支持物化视图 | 不支持物化视图 |
| 支持临时表 | 支持临时表 |
| 支持主键,外键,唯一键,检查,非约束,还支持exclusion constraints | 支持主键,外键,唯一键,检查,非约束 |
| 支持两阶段提交 | 支持两阶段提交 |
| 认证方式丰富,信任/口令/PAM/LDAP/Kerberos/基于ident | 基本支持密码认证 |
| 可以使用pgcrypto库中的函数对列进行加密/解密;可以通过ssl连接实现网络加密 | 可以在表级制定密码来对数据进行加密;可以使用aes_encrypt和aes_decrypt函数对列数据进行加密和解密;可以通过ssl连接实现网络加密 |
| 使用explain命令查看查询的解释计划,结果很直观,也很详细 | 使用explain命令查看查询解释计划,但结果不直观,不详细 |
| postgresql完成遵从ACID | mysql只有innodb等少量存储引擎遵从ACID |
安装教程【CentOS7 - 14版本】
# 官方https://www.postgresql.org/download/linux/redhat/
# Install the repository RPM:
sudo yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# Install PostgreSQL:
sudo yum install -y postgresql14-server
# Optionally initialize the database and enable automatic start:
sudo /usr/pgsql-14/bin/postgresql-14-setup initdb
sudo systemctl enable postgresql-14
sudo systemctl start postgresql-14
# ================================================================
### 其他操作
# =============================================
## 自定义数据存储目录【1】
# 创建目录
mkdir -p /usr/local/postgresql/data
# 授权, postgres用户与组在第2步会自动创建好
chown -R postgres:postgres /usr/local/postgresql
# =============================
# 初始化数据库【2】
su - postgres
# 使用自定义数据存储目录【选一个】
/usr/pgsql-14/bin/initdb -D /usr/local/postgresql/data/
# 使用默认数据存储目录【选一个】
/usr/pgsql-14/bin/initdb
# =============================
## 修改启动脚本【3】
# 使用root用户
vim /usr/lib/systemd/system/postgresql-14.service
......
# Location of database directory
Environment=PGDATA=/usr/local/postgresql/data/
......
# 重新加载系统服务
systemctl daemon-reload
# =============================
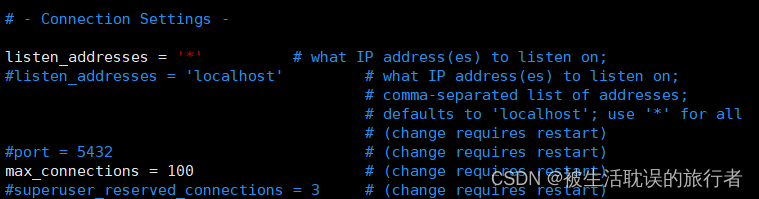
## 设置监听地址【4】
# 使用postgres用户
vim /usr/local/postgresql/data/postgresql.conf
......
# - Connection Settings -
listen_addresses = '*' # what IP address(es) to listen on;
......
# =============================
# 新增密码认证【5】
vim /usr/local/postgresql/data/pg_hba.conf
......
。。。。。
host replication all ::1/128 trust
# 添加可通过密码对所有用户和主机进行认证【就下面这一行】
host all all 0.0.0.0/0 trust
# =============================# =============================
## 修改postgres超级用户密码【6】
# 使用postgres用户
psql -p 5432 -U postgres
ALTER USER postgres WITH PASSWORD '123456';
# ============================= 完成 =============================
# docker 方案【未尝试】
docker run -d -p 5432:5432 --name postgresql -v pgdata:/var/lib/postgresql/data -e POSTGRES_PASSWORD=123321 postgres
安装pgAdmin4-web服务
官网:https://www.pgadmin.org/
官方安装教程:https://www.pgadmin.org/download/pgadmin-4-rpm/
安装好了之后的截面图:
安装教程:(如下)
rpm -ivh https://ftp.postgresql.org/pub/pgadmin/pgadmin4/yum/pgadmin4-redhat-repo-2-1.noarch.rpm --force --nodeps
sudo yum install pgadmin4-web
# 设置 selinux 这个需要重启
vim /etc/selinux/config
SELINUX=disable
# 设置 selinux 临时不用重启
setenforce 0
# 修改端口
vim /etc/httpd/conf.d/pgadmin4.conf
<VirtualHost *:80>
ServerName pgadmin.cn
# 自带内容
</VirtualHost>
# 执行
/usr/pgadmin4/bin/setup-web.sh
# 完成:后续按提示初始化就可以里
# docker方案【未尝试】
docker pull dpage/pgadmin4
docker run -d -p 5433:80 --name pgadmin4 -e PGADMIN_DEFAULT_EMAIL=123@123.com -e PGADMIN_DEFAULT_PASSWORD=123456 dpage/pgadmin4
一些SQL写法-Demo参考
聚集-过滤
SELECT
count(*) AS unfiltered,
count(*) FILTER (WHERE i < 5) AS filtered # 这里的过滤
FROM generate_series(1,10) AS s(i);
unfiltered | filtered
------------+----------
10 | 4
高级分组统计
CUBE和ROLLUP更高级的排列
=> SELECT * FROM items_sold;
brand | size | sales
-------+------+-------
Foo | L | 10
Foo | M | 20
Bar | M | 15
Bar | L | 5
(4 rows)
=> SELECT brand, size, sum(sales) FROM items_sold GROUP BY GROUPING SETS ((brand), (size), ());
brand | size | sum
-------+------+-----
Foo | | 30
Bar | | 20
| L | 15
| M | 35
| | 50
(5 rows)
手动构建临时Table
=> SELECT * FROM (VALUES (1, 'one'), (2, 'two'), (3, 'three')) AS t (num,letter);
num | letter
-----+--------
1 | one
2 | two
3 | three
(3 rows)
WITH单查询内辅助查询
WITH regional_sales AS ( # 有点像临时表的查询,预处理
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
), top_regions AS (
SELECT region
FROM regional_sales
WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales)
)
SELECT region,
product,
SUM(quantity) AS product_units,
SUM(amount) AS product_sales
FROM orders
WHERE region IN (SELECT region FROM top_regions)
GROUP BY region, product;
中文全文检索
全文索引的实现要靠 PgSQL 的 gin 索引。分词功能 PgSQL 内置了英文、西班牙文等,但中文分词需要借助开源插件 zhparser;
参考文档:https://www.cnblogs.com/zhenbianshu/p/7795247.html
![[PyTorch][chapter 51][Auto-Encoder -1]](https://img-blog.csdnimg.cn/ad287288c7c942129815f6fced4716db.png)