随着硬件晶体管的尺寸越来越小,CPU 的频率上限已经基本保持在 4G 左右,但现代人类对于网络的要求不断升级,想要占领市场各厂商只能激发自己的潜能,将单线程代码发展为多核/多线程系统,在这其中,并行是充分利用这些系统性能的最优办法。
并行编程是一个革新式的变化,它涉及众多领域,包括硬件平台的实现方式、软件任务间的通信、任务同步等等,可以说是一个实打实的“斜杆青年”了。
今天,我们就以 Linux 中的常用 RCU 机制看看,并行编程到底是怎么被卷出来的!

RCU 全称 read-copy-update ,是一种数据同步机制。
RCU 主要针对的数据对象是指针,目的是提高遍历读取数据的效率。以链表为例,为了提高效率,我们在使用 RCU 机制读取数据的时候可以不对链表进行加锁操作。这时,每当线程在共享内存中插入或删除数据结构的元素时,可以保证所有读者都看到并遍历旧结构或新结构,从而避免不一致(例如,取消引用空指针)。

RCU 主要用在读取性能至关重要的场合中,为了保证所有读者的继续不受影响,并可以更快地完成实现速度,它不得不占用更多空间。这也成就了 RCU 的特点:
-
RCU 读端和更新端可以同时操作,并发执行;
-
RCU 采用数据担保的方式,为读端提供可靠数据;
-
读端读到的数据有可能是旧的也可能是新的;
-
宽限期结束时,读端要退出临界区;
-
典型 RCU 读端在临界区内不允许中断、休眠等操作。


我们可以将 RCU 的基本执行过程分为三个步骤:
-
采用发布——订阅机制添加新的数据;
-
等待已有的 RCU 读者退出临界区;
-
允许在不影响或者延迟其他并发 RCU 读者的前提下改变数据。

![]()
q = kmalloc(sizeof(*p), GFP_KERNEL);*q = *p;q->b = 11;list_replace_rcu(&p->list, &q->list);synchronize_rcu();kfree(p);
![]()
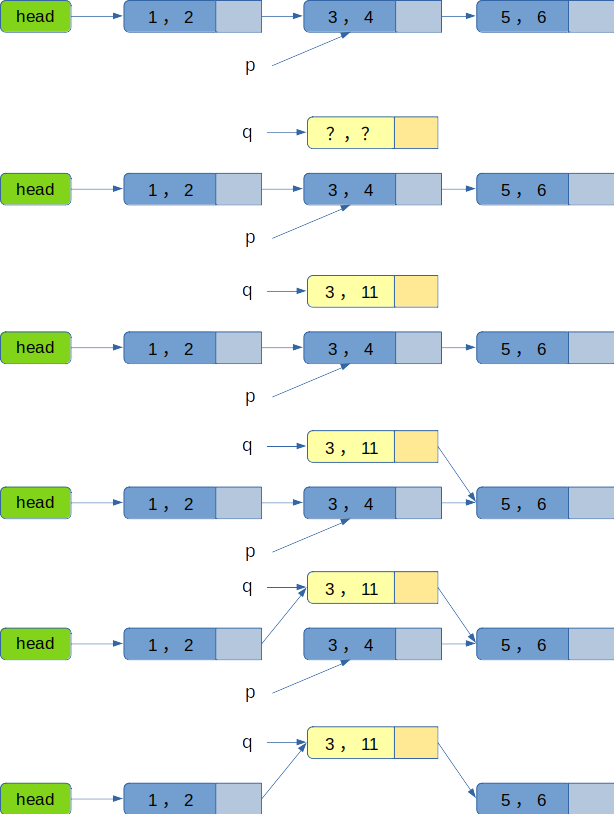
从上图我们可以看出, RCU 的基本构建思想可以归纳成:
-
先给指针 q 分配一个空间;
-
给指针 q 赋值;
-
将新生成的 q 指向 p 的下一个节点;
-
再将 p 的上一个节点指向 q ;
-
等宽限期结束后,再将 p 释放掉。
需要注意的是,第三步和第四步的顺序不能反,否则会造成读端在读取数据的时候出现指针错误。

-
读端通过 rcu_read_lock() 进入临界区;
-
读端通过 rcu_read_unlock() 退出临界区;
-
更新端通过 rcu_assign_pointer() 等发布原语发布数据;
-
更新端通过 synchronize_rcu() 同步原语等待宽限期结束。
![]()
-
读端
rcu_read_lock();p = rcu_dereference(head);... ...rcu_read_unlock();
当我们进入临界区后,就可以操作获取指针 p ,并对 p 进行一系列的操作了。
-
更新端
spin_lock(&lock);p = head;rcu_assign_pointer(head, NULL);spin_unlock(&lock);synchronize_rcu();kfree(p);
该段代码先通过 rcu_assign_pointer() 函数将 head 置为 NULL ,然后通过 synchronize_rcu() 等待宽限期结束。当 synchronize_rcu() 函数返回时,表示宽限期结束,所有的读端都已经退出临界区,此时就可以释放 p(原来head) 指向的空间。
![]()

![]()


当我们了解了 RCU 的全部执行过程时,就可以将其基本思想概括为三类:
-
读者无锁访问数据,标记进出临界区;
-
写者读取,复制,更新;
-
旧数据延迟回收。
说起来容易,但其在 Linux 内核中实现却不是这么简单。除了要实现基本功能,还需要考虑很多复杂情况。内核的 RCU 系统可以说是内核最复杂系统之一,为了高性能和多核扩展性,它被设计了非常精巧的数据结构,还结合了预处理,批量处理,延后(异步)处理,多核并发,原子操作,异常处理,多场景精细优化等多种技术,也体现很多编程思想和代码设计思想,有一定的学习和参考价值。
想要打造一款以人为本,为用户提供更便捷、智能、安全的操作系统,我们保持着对各类新兴技术的关注与热情,RCU 具备的性能好,可扩展性强,稳定性强等特点,正符合鼎道智联想要打造 DingOS 的目标。合理运用 RCU 技术,就可以提高用户的响应速度、提升系统的稳定性和可靠性,从而给用户带来更安全、流畅的操作体验。如果你也认可我们的想法,有相同的目标,欢迎加入或关注鼎道生态。