文章目录
- 数据集
- Fashion-MNIST 数据集
- 数据预处理
- 包的导入
- 在Pytorch中进行 ETL
- 利用torchvison包获取和处理数据集(E+T)
- 访问数据集
- 访问和查看 train_set 中的单个数据
- 利用 DataLoader 成批访问数据
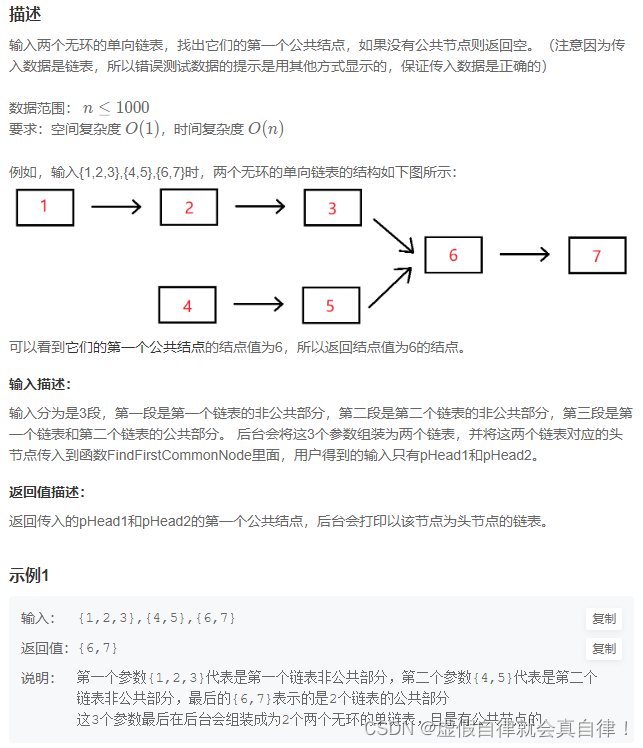
数据集
Fashion-MNIST 数据集
-
MNIST
MNIST,Modified National Institute of Standards and Technology database,前面加了“modified ”是因为这个数据集已经是在原始的 NIST 数据集上修改过的版本。简单来说 MNIST 就是一个包含了 0-9 十个数字(十个类别)的手写图片数据集,都是灰度图片,每张图片 28x28 像素,每个类别 7000 张图片,一共 70000 张。并且划分了 60000 张图片作为训练集,10000 张图片作为测试集。

MNIST 在图像分类领域非常流行,主要有两个原因:一是这个数据集特别简单,适合新手上手;二是学术圈为了比较各自的算法优劣,会在相同的数据集上训练算法,就是 MNIST。MNIST 也有它的问题就是太简单了(图像分类领域的“hello world”),所以有一帮人就开发了 Fashion-MNIST 想要来取代 MNIST。
-
Fashion-MNIST
Fashion-MNIST 是一个德国的时装公司 Zalando 下面的研究院 Zalando Research 开发的,它用10类服装的图片取代了十类手写数字图片。十个类别分别是:
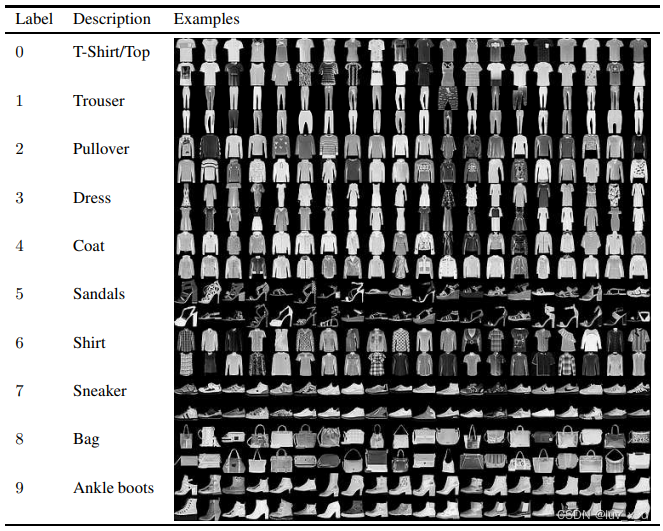
Fashion-MNIST 的设计理念就是作为 MNIST 的直接取代(direct dropin replacement),就是说以前使用 MNIST 的模型,除了数据集的链接(URL),其他什么都不用改。但替换之后的图像分类有了更高的难度。所以 Fashion-MNIST 和 MNIST 一样,都是灰度图片,28x28 像素,每类 7000 张,一共 70000 张,其中训练集 60000 张,测试集 10000 张。数据集链接
Fashion-MNIST 是直接从 Zalando 网站上的商品图片提取出来制作的,包括以下7步:① 转换为PNG;② 裁剪;③ 长边缩放为28像素;④ 锐化;⑤ 补足空白;⑥ 取负片;⑦ 取灰度。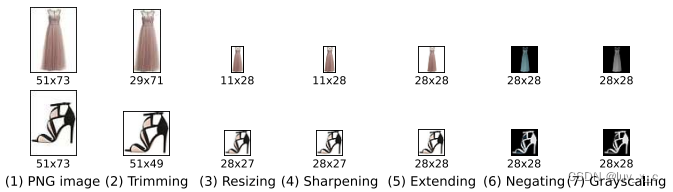
数据预处理
通过 PyTorch 的 torchvision 包获取 Fashion-MNIST 数据集。
一般而言,对一个数据集的预处理流程为 ETL,即包含 extract、transform、load 三个步骤。
1.Extract - Get the Fashion-MNIST image data from the data source.Transform - 2.Transform image data into a desirable PyTorch tensor format.
3.Load - Put data into a suitable structure to make it easily accessible.
完成 ETL 流程之后,就可以开始构建和训练深度学习模型。
包的导入
需要把所有需要的PyTorch包导入:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
对各个包的描述如下:
- torch - The top-level PyTorch package and tensor library.
- torch.nn - A subpackage that contains modules and extensible classes for building neural networks.
- torch.optim - A subpackage that contains standard optimization operations like SGD and Adam.
- torch.nn.functional - A functional interface that contains typical operations used for building neural networks like loss functions and convolutions.
- torchvision - A package that provides access to popular datasets, model architectures, and image transformations for computer vision.
- torchvision.transforms - An interface that contains common transforms for image processing.
在Pytorch中进行 ETL
对于 ETL 流程,PyTorch 提供了两个类(class):

使用 PyTorch 创建自定义的数据集,我们通过创建子类并继承 Dataset 中的函数,来实现 Dataset 的扩展,然后就可以传递给 DataLoader 对象。
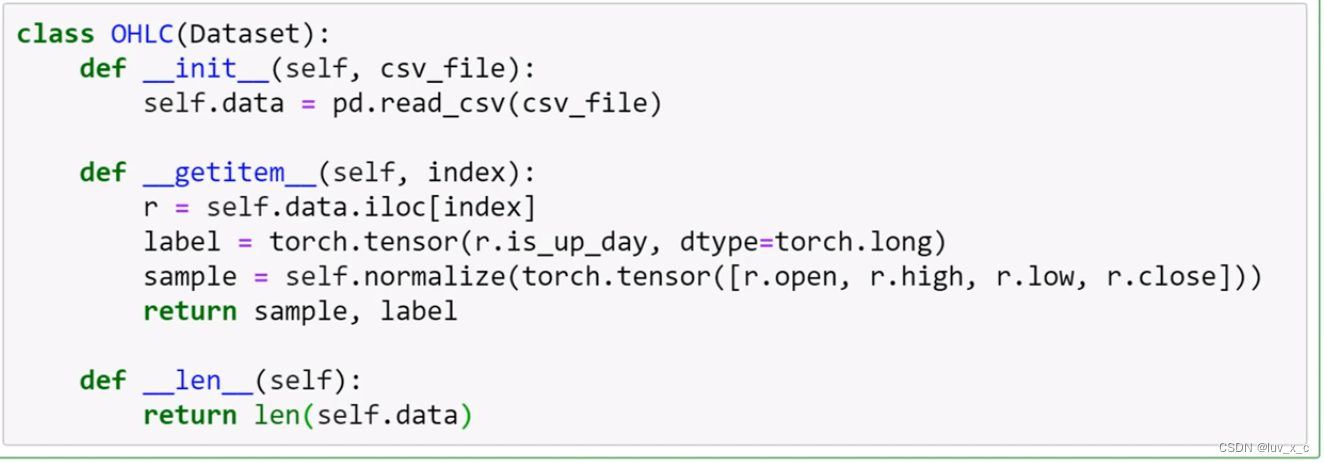
len() 和 getitm() 是其中两个必要的函数,前者的功能是计算数据集的长度,后者的功能是在数据集中按指定的索引编号将数据取出。
利用torchvison包获取和处理数据集(E+T)
利用 torchvision 获取并创建 Fashion-MNIST 数据集的一份实例(instance),这个过程中同时完成的数据集的获取(E)和转化(T),代码如下:
train_set = torchvision.datasets.FashionMNIST(
root='./data'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)

参数解释如下:
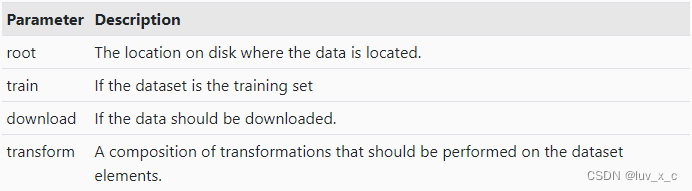
因为希望将图片数据集转换为张量,所以在 transform 中使用了 transforms.ToTensor();将此数据集命名为train_set,是因为我们希望将其作为训练数据;另外数据集仅会被下载一次,程序下载之前会检查本地有没有。
之后将获取的 train_set 打包给 DataLoader,使得数据集可以通过 DataLoader 方便的访问和加载(L):
train_loader = torch.utils.data.DataLoader(train_set)
至此已经完成了数据集的 Extract(利用url从网页下载)和 Transform(上面的transforms.ToTensor()),并且已经打包给了 DataLoader,可以通过 DataLoader 来实现 Load,比如设置 batch_size 和 shuffle:
train_loader = torch.utils.data.DataLoader(train_set
,batch_size=1000
,shuffle=True
)
访问数据集
首先可以查看数据集中有多少个图片,使用 Python 的 len() 函数:
>len(train_set)
60000
查看所有图片的标签,只需要访问 train_set.targets 属性:
> train_set.targets
tensor([9, 0, 0, ..., 3, 0, 5])
如果希望查看数据集中每一个类别有多少个标签(即多少个图片,适用于图片全部有标记的情况),可以用 PyTorch 的 bincount() 函数:
>train_set.targets.bincount()
tensor([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000])
Fashion-MNIST 数据集中每一类都有 6000 个图片和标签对,这种每一类的样本数量相等的数据集称作 balanced dataset,反之类别之间样本数量不一致的数据集称为 unbalanced dataset。
访问和查看 train_set 中的单个数据
一次只查看单张图片,首先将 train_set 这个对象传递给 Python 内建的 iter() 函数,它会返回一个可以在其上迭代的代表数据流(stream of data)的对象,使我们可以沿数据流访问数据。
接下来再使用 Python 的内建函数 next() 来获取数据流中的下一个数据元素,如此就可以获取数据集中的一个单独数据(因此下面命名变量都是单数形式):
> sample = next(iter(train_set))
> len(sample)
2
> type(sample)
tuple
获取的一个单独数据长度为 2,这是因为数据集是由图片-标签对的形式组成的,每一个 data element 中都包含两个东西,一个是存储图片数据的张量,另一个是其对应的标签。
sample 的数据类型是 tuple,tuple 是Python中的一种 sequence types,是一个可以迭代的顺序不可变的数据序列。
可以用 sequence unpacking 来将其中的图像和标签分别提取出来:
> image, label = sample
和下面这种写法是等效的:
> image = sample[0]
> label = sample[1]
查看数据类型和shape:
> type(image)
torch.Tensor
> type(label)
int
> image.shape
torch.Size([1, 28, 28])
> torch.tensor(label).shape
torch.Size([])
Fashion-MNIST 数据集是单通道的灰度图,所一张图片的 tensor shape 就是 1x28x28。把没有用的颜色通道 squeeze 掉:
> image.squeeze().shape
torch.Size([28, 28])
显示出图片和标签:
> plt.imshow(image.squeeze(), cmap="gray")
> torch.tensor(label)
tensor(9)
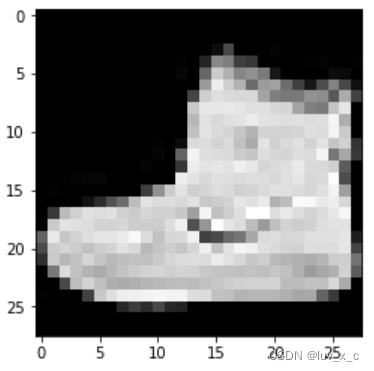
标签是“9”,代表靴子,与图片是相符的。
利用 DataLoader 成批访问数据
> batch = next(iter(train_loader))
> len(batch)
2
> type(batch)
list
list 也是一种 Python sequence types,与 tuple 的不同在于 list 是可变序列。
一次访问 10 张图片,则需要给 DataLoader 指定 batch_size:
> display_loader = torch.utils.data.DataLoader(
train_set, batch_size=10
)
关于 DataLoader 中的“shuffle=True”:如果“shuffle=True”,则每次调用 next() 返回的 batch 都会不同,训练集中的第一组样本将在第一次调用 next() 时返回,这个功能默认是 False。
可以像上面一样对 display_loader 使用 iter() 和 next() 来每次查看 10 张图片:
> batch = next(iter(display_loader))
> print('len:', len(batch))
len: 2
进行 sequence unpacking:
> images, labels = batch
> print('types:', type(images), type(labels))
> print('shapes:', images.shape, labels.shape)
types: <class 'torch.Tensor'> <class 'torch.Tensor'>
shapes: torch.Size([10, 1, 28, 28]) torch.Size([10])
此时返回的图像张量是 [10, 1, 28, 28] 的四阶张量,标签是一个长度为 10 的一阶张量。可以单独查看其中每一个图片和标签:
> images[0].shape
torch.Size([1, 28, 28])
> labels[0]
tensor(9)
一次绘制一批图像,可以使用 torchvision.utils.make_grid() 函数创建一个可以按网格绘制图片的 grid:
> grid = torchvision.utils.make_grid(images, nrow=10) # nrow指定每行多少列图片
> plt.figure(figsize=(15,15)) # 缩放图像显示大小?
> plt.imshow(grid.permute(1,2,0)) # 这一步让grid符合imshow的要求,不清楚细节
> print('labels:', labels)
labels: tensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5])\