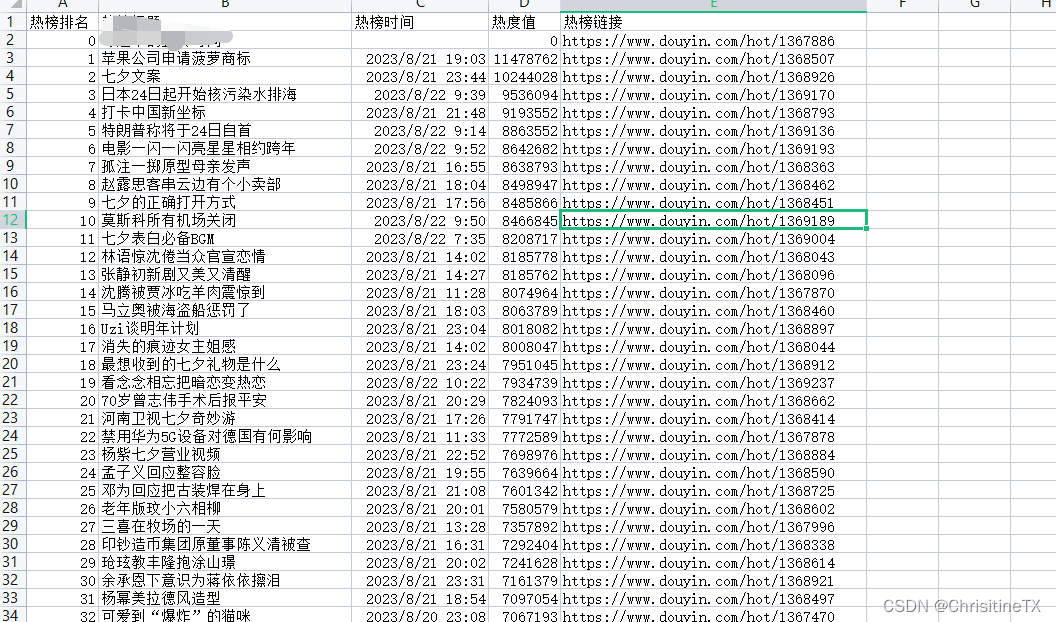
一、说明
2D 傅里叶变换是本世纪最重要的计算机科学算法之一。它已在我们的日常生活中得到应用,从Instagram过滤器到MP3文件的处理。
普通用户最常用的实现,有时甚至是在不知不觉中,是 NumPy 的改编。然而,尽管它很受欢迎,但他们的算法并不是最有效的。通过一些简单的操作和 2015 年的一篇文章,我们在性能上击败了 NumPy 算法 30-60%。当前实现的核心问题是一个简单的事实,即它最初是从性能弱算法派生的。
二、NumPy实现的算法
从本质上讲,NumPy实现的算法将常规的一维FFT依次应用于二维,这显然不能成为最优解。
相反,在2015年,两位俄罗斯科学家提出了他们的算法版本,将一维蝶蝶变换的想法应用于二维信号。我们通过添加我们的想法有效地实现了他们的基本算法概念。
在构建了本文中的朴素算法后,我们继续进行优化,如下所示:
void _fft2d( /* Square matrix of size N */ ) {
// base case {
if (N == 1) return;
// } base case
int n = N >> 1;
/* pseudo code {
...Creating 4 temprorary matrices here...
// X(x, y, i, j)
// x, y -- indexing over temporary submatricies
// i, j -- indexing over rows, columns in each submatrix
_fft2d(&X(0, 0), root * root, ...);
_fft2d(&X(0, 1), root * root, ...);
_fft2d(&X(1, 0), root * root, ...);
_fft2d(&X(1, 1), root * root, ...);
} pseudo code */
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
auto x00 = X(0, 0, i, j);
auto x10 = X(1, 0, i, j) * /* W[i] */;
auto x01 = X(0, 1, i, j) * /* W[j] */;
auto x11 = X(1, 1, i, j) * /* W[i] * W[j] */;
X(0, 0, i, j) = x00 + x10 + x01 + x11;
X(0, 1, i, j) = x00 + x10 - x01 - x11;
X(1, 0, i, j) = x00 - x10 + x01 - x11;
X(1, 1, i, j) = x00 - x10 - x01 + x11;
}
}
}任何递归算法都可以通过增加基本情况的大小来增强。以下是我们的处理方式:
void _fft2d( /* Square matrix of size N */ ) {
// base case {
if (N == 1) return;
if (N == 2) {
#define Y(y, x) (V[(y)*rowsize + (x)])
auto x00 = Y(0, 0);
auto x10 = Y(1, 0);
auto x01 = Y(0, 1);
auto x11 = Y(1, 1);
Y(0, 0) = x00 + x10 + x01 + x11;
Y(0, 1) = x00 + x10 - x01 - x11;
Y(1, 0) = x00 - x10 + x01 - x11;
Y(1, 1) = x00 - x10 - x01 + x11;
return;
}
// } base case
// ...
}
进一步的逻辑步骤是消除在每个递归步骤中创建四个不必要的临时子矩阵,而支持单个子矩阵。为此,我们使用了 algorithmica 文章中的概念,并将其修改为二维矩阵。此功能还有助于我们减少不必要的分配并增加缓存命中次数。
// Computing values for rev_bits[n]
auto revbits = [](size_t *v, size_t n) {
int lg_n = log2(n);
forn(i, n) {
int revi = 0;
forn(l, lg_n) revi |= ((i >> l) & 1) << (lg_n - l - 1);
v[i] = revi;
}
};
size_t *rev_n = new size_t[N], *rev_m = new size_t[M];
revbits(rev_n, N), revbits(rev_m, M);
// Transforming matrix
forn(i, N) {
int rev_i = rev_n[i];
forn(j, M) {
if ((i < rev_i) || ((i == rev_i) && (j < rev_m[j])))
std::swap(V[i * M + j], V[rev_i * M + rev_m[j]]);
}
}我们的下一个挑战是预先计算团结的根源:
int mxdim = std::max(N, M);
const int lg_dim = log2(mxdim);
auto W = new fft_type[mxdim];
auto rooti = std::polar(1., (inverse ? 2 : -2) * fft::pi / mxdim);
// Computing look-up matrix for roots
auto cur_root = rooti;
W[0] = 1;
forn (i, mxdim - 1) W[i + 1] = W[i] * cur_root;我们怎么能用这样的数组过关?让我们注意到,在朴素实现中,在初始递归步骤中,我们经过一个根的数组。我们还传递到下一个递归级别,即此根的平方(W[2])。在下一个递归级别,我们传递相同的幂数组,但以 2 为增量。从这个观察中,我们可以推导出,在第 i 个递归级别上,我们将通过数组 W 的步骤是 2ⁱ。
在此阶段,我们收到以下代码:
void _fft2d(
fft_type *__restrict__ V,
size_t N,
size_t rowsize,
fft_type *__restrict__ W,
int step
) {
// base case {
if (N == 1) return;
if (N == 2) {
#define Y(y, x) (V[(y)*rowsize + (x)])
auto x00 = Y(0, 0);
auto x10 = Y(1, 0);
auto x01 = Y(0, 1);
auto x11 = Y(1, 1);
Y(0, 0) = x00 + x10 + x01 + x11;
Y(0, 1) = x00 + x10 - x01 - x11;
Y(1, 0) = x00 - x10 + x01 - x11;
Y(1, 1) = x00 - x10 - x01 + x11;
return;
}
// } base case
int n = N >> 1;
#define X(y, x, i, j) (V[((y)*n + (i)) * rowsize + ((x)*n) + j])
#define params n, rowsize, W, (step << 1)
_fft2d(&X(0, 0, 0, 0), params);
_fft2d(&X(0, 1, 0, 0), params);
_fft2d(&X(1, 0, 0, 0), params);
_fft2d(&X(1, 1, 0, 0), params);
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
auto x00 = X(0, 0, i, j);
auto x10 = X(1, 0, i, j) * W[step * i];
auto x01 = X(0, 1, i, j) * W[step * j];
auto x11 = X(1, 1, i, j) * W[step * (i + j)];
X(0, 0, i, j) = x00 + x10 + x01 + x11;
X(0, 1, i, j) = x00 + x10 - x01 - x11;
X(1, 0, i, j) = x00 - x10 + x01 - x11;
X(1, 1, i, j) = x00 - x10 - x01 + x11;
}
}
}原始算法还有另一个明显的缺点——它只处理维度等于 2 次方的平方矩阵。使用一些简单的修改,我们可以将其扩展到矩形矩阵。
void _plan(
fft_type *__restrict__ V,
size_t N,
size_t M,
size_t rowsize,
fft_type *__restrict__ W,
int step_i,
int step_j
) {
// Computing square matrix
if (N == M) _fft2d(V, N, rowsize, W, step_i);
// Performing vertical split
else if (N > M) {
int n = N >> 1;
#define Y(y, i, j) (V[((y)*n + (i)) * rowsize + j])
#define params n, M, rowsize, W, (step_i << 1), step_j
_plan(&Y(0, 0, 0), params);
_plan(&Y(1, 0, 0), params);
forn (i, n) {
forn (j, M) {
auto y00 = Y(0, i, j);
auto y10 = Y(1, i, j) * W[i * step_i];
Y(0, i, j) = y00 + y10;
Y(1, i, j) = y00 - y10;
}
}
// Performing horizontal split
} else { /* ...Analogical approach... */ }
}值得一提的是,NumPy在其算法中在FFT下进行了额外的分配,将其中的类型带到了np.complex128;如果我们避免这一步,我们可以获得大约 10% 的优势。我们最终也实现了多线程。
作为可视化表示,我们可以提供带有运行时的表格,还可以提供显示我们关于 NumPy 的工作效率的图表:
结果表

三、结论
俄罗斯数学家修改后的算法在效率方面超过了NumPy引擎盖下的“行和列”。一些逻辑操作,例如基本大小写增加,显着提高了我们的优化。
至关重要的是,我们在实现过程中执行的步骤也可以用于其他算法,这在未来可能对您有所帮助。同样值得注意的是,虽然我们已经做出了坚实的努力,但仍然可以通过添加不同大小的填充矩阵来加强实现。这篇文章旨在分享源代码,这可能有助于改进各种项目中转换的计算。
存储库链接可以在下面找到,或者您也可以使用终端直接导入包:
pip3 install git+https://github.com/2D-FFT-Project/2d-fft参考资源:
包含源代码的存储库
- FFT, 算法
- 二维快速傅里叶变换:Cooley-Tukey算法模拟中的蝴蝶,V. S. Tutatchikov为IEEE,2016年
亚历山大·莱文