编者按:人工智能领域近年来模型规模不断增大,参数规模爆炸式增长。从 GPT-3 的 1,750 亿,再到传闻中的 GPT-4 可能高达惊人的 18,000 亿参数。然而,随着模型规模的不断膨胀,也出现了训练成本高昂、环境影响大、应用部署困难等问题。因此,业内开始反思超大模型的发展方向和意义。
在这样的背景下,“敏捷人工智能”(Nimble AI)应运而生。敏捷AI 指参数量级在百亿级甚至十几亿级的较小模型。它们在训练成本、环境影响等方面具有显著优势,且可通过持续微调升级,快速适应新的应用需求。
本文首先阐明了敏捷AI的定义,并从多个维度分析了它与巨型AI模型的区别。作者认为,敏捷AI可以部分达到巨型模型的能力水平,在许多实际应用中提供更高的性价比。同时,文章详细阐述了推动敏捷AI发展的三大关键因素。最后,文章总结了敏捷AI的多项优势,认为它代表AI发展的新方向。
敏捷AI是一个崭新的概念,或将引领AI技术发展的新浪潮。如果你对人工智能的发展前景感兴趣,本文具有独特的观点和见解,值得一读。
以下是译文,enjoy!
作者 | Gadi Singer
编译 | 岳扬
人工智能(AI)模型的复杂性和计算量等方面经过了长达十年的快速增长,这一状况终于在2023年发生了转变——转向聚焦效率和生成式人工智能(GenAI)的应用。因此,出现了一批参数不足150亿的新型AI模型,被称为敏捷AI(nimble AI),它们在特定垂直领域中可以与超过1000亿参数的ChatGPT式巨型模型的能力相匹敌。 随着GenAI已经在各行各业广泛应用,小型而高智能的模型的使用也正日益增加。可以预见,不久的将来,GenAI在的应用将会呈现少量巨型模型和大量小型、更敏捷的AI模型的格局。
虽然大模型目前来看已经取得了巨大进展,但就训练成本和环境成本而言,模型并非越大越好。据 TrendForce[1] 估计,仅 ChatGPT 的 GPT-4 训练成本就超过了 1 亿美元,而敏捷模型(nimble model)的预训练成本则低几个数量级(例如,MosaicML 的 MPT-7B 报价约为 20 万美元[2])。大部分计算成本是消耗在源源不断的推理过程中,这对特别消耗算力的较大模型来说是一个重大挑战。此外,托管在第三方的巨型模型也会带来安全和隐私方面的挑战。
敏捷模型的运行成本要低得多,而且还具备一系列额外的优势,如适应性(adaptability)、硬件方面的灵活性(hardware flexibility)、在大型应用中的可集成性(integrability within larger applications)、安全性(security)和隐私性(privacy)、可解释性(explainability)等(见图 1)。人们对较小模型性能不如较大模型的看法也正在改变。较小而有针对性的模型并不意味着它们智能程度不高——它们可以在商业、消费者和科学领域提供相同甚至更优异的性能,增加价值的同时减少时间和成本的投入。
越来越多此类敏捷模型的表现已逐渐接近ChatGPT-3.5级别的巨型模型,且性能和适用范围持续快速提升。此外,当敏捷模型能够使用专业领域的私有数据,并根据查询要求进行网页内容检索时,其准确性和性价比可以超过巨型通用模型。

图 1. GenAI 敏捷模型的优势。图片来源:Intel Labs
开源的GenAI敏捷模型持续前进,驱动着该领域的快速发展,这种类似 “iPhone 时刻”的革命性技术正在受到类似“Android革命”的挑战,因为优秀的研究人员和开发者社区正在彼此做出的开源工作基础上,创建能力日益强大的敏捷模型。
01 思考,实践,了解:针对特定领域的敏捷模型可部分达到巨型模型的能力

图 2. 生成式人工智能能力类别。图片来源:Intel Labs
为了进一步了解较小的模型何时以及如何能够为生成式人工智能提供支持,需要注意到,无论是敏捷模型还是巨型GenAI模型,在完成任务时都需要下面这三类能力:
- 用于思考的认知能力:包括语言理解、总结归纳、推理、规划、从经验教训中学习、长篇表达和交互式对话等。
- 特定技能的实践能力:例如阅读真实世界中多样化和复杂的文本数据、读取图表/图片、进行视觉识别、编程(编写和调试代码)、图像和语音生成等。
- 信息获取能力(记忆的或实时检索) :网络内容,包括社交媒体、新闻、研究报告和其他一般内容;或特定领域精选的内容,如医疗、金融和企业数据。
1.1 用于思考的认知能力(Cognitive abilities to think)
根据模型拥有的认知能力,它可以“思考”并理解、概括、综合、推理和组织语言和其他符号表示。敏捷和巨型模型在这些认知任务表现均很出色,目前尚不清楚这些核心能力是否需要庞大的模型规模来支持。例如,像Microsoft Research的 Orca [3]这样的敏捷模型在多个基准测试中表现出的理解、逻辑和推理能力已经达到甚至超过了 ChatGPT。此外,Orca 还证明,推理技能可以从作为教师模型使用的大型模型中提炼出来。
然而,目前用于评估模型认知技能的基准测试还很初级。还需要进一步的研究和基准测试来验证敏捷模型是否可以通过预训练或微调来达到巨型模型的“思维”能力。
1.2 实践能力
由于巨型模型总体定位是全能模型,它可能具有更多技能和知识量。然而,在大多数商业应用中,实际上只需要模型拥有特定范围的技能。用于商业应用的模型应该需要具备敏捷性和扩展性,以适应未来的业务增长和多样化的需求变化,但似乎很少需要无限数量的技能。
GPT-4能够使用多种语言生成文本、代码和图像,然而掌握数百种语言未必意味着这些巨型模型在底层认知能力上具备更多的优势,它们主要是通过增加技能数量来实现完成更多实际任务的能力。
此外,当需要特定功能时,可以将功能专用引擎(functionally specialized engines)与GenAI模型连接使用,比如将数学插件“Wolfram superpowers[4]”作为模块添加到ChatGPT中,可有效提供优秀的数学能力而不增加模型规模。例如,GPT4的插件本质上也是利用小模型实现附加功能。有传言称,GPT-4模型本身也是由多个小于1000亿参数的混合专家模型组成的集合[5],这些模型针对不同的数据和任务进行了训练,而不是像GPT-3.5那种独立的巨型模型。
为了获得最佳的技能组合和模型效率,未来的多功能模型可能会采用更小型、更专注的“混合专家”模型,基本上每个模型的参数都小于150亿。

图3. 基于检索的、用于功能扩展的模型可以提供较大的功能范围和较多的相关信息,这在很大程度上与模型的规模无关。图片来源:Intel Labs
1.3 信息获取能力(内部记忆的或实时检索)
巨型模型通过在参数空间内部记忆大量数据来“知道”更多,但这仅是让他们比小型模型拥有更全面的知识,并不一定让它们更智能。 在都是全新use cases的零样本环境中,巨型模型具有很高的价值。在没有具体针对性场景或目标的情况下,巨型模型可以为大部分消费者提供基础知识,并在提炼和调教敏捷模型时担任教师模型。不过,针对特定领域训练或微调的敏捷模型可以针对特定领域或场景提供的更优秀能力。

图4. 检索机制让小模型可以匹敌更大模型的价值(采用Contriever检索方法)。图片来源:Intel Labs,基于Mallen等人的研究[6]。
例如,针对编程场景训练出的模型与医疗AI系统模型具有不同的能力侧重。此外,通过在已策划好的内部和外部数据集上进行检索,可以大幅提高模型的准确性和内容时效性。最近一项研究表明[6],在PopQA基准测试中[7],仅具有13亿参数的模型在使用检索功能后,可以达到参数量为1750亿的模型的水平(参见图4)。与全能的巨型系统相比,一个具有相关领域知识和高效检索能力的针对性模型系统,具有更高的可用性和扩展性。这对于觉得多数企业来说都更为重要,因为大多数企业在大模型应用中都需要利用领域自有的特定知识,而非基础通用的知识。这就是敏捷模型的价值所在。
02 推动敏捷模型爆发式增长的三大因素
评估敏捷模型的优势和价值需考虑以下三个方面:
- 在适度模型规模下,具备高效性 。
- 以开源或专有软件的形式进行授权。
- 模型可以被设计成通用的,可以应对各种不同的任务和需求,也可以被专门优化用于特定领域或任务,同时还可以具备检索(retrieval)功能,即能够通过访问内部或外部的数据集来提高模型的准确性和效果。
就模型规模而言,通用敏捷模型如Meta的LLaMA-7B和-13B[8],Technology Innovation Institute的Falcon 7B[9]这些开源模型,以及MosaicML的MPT-7B[10]、微软Research的Orca-13B[11]和Salesforce AI Research的XGen-7B[12]等专有模型都在快速改进(见图6)。选择高性能的小型模型,对运营成本和计算环境的选择都具有重大影响。
ChatGPT 175 B参数的模型和估计达1.8万亿参数的GPT-4[13]都需要大规模部署GPU等加速器,来提供足够的计算能力进行训练和微调。相比之下,敏捷模型通常可以在任何硬件上运行推理,从单路CPU到入门级GPU乃至大规模加速集群。根据13 B参数或更小模型的优秀表现,敏捷AI的定义在当下被经验性地设定为15 B参数以内。总体而言,敏捷模型提供了更划算、更可拓展的方法来处理新的用例(参见关于敏捷模型优势和劣势的讨论)。
第二个方面的开源许可使学术界和工业界可以相互迭代对方的模型,推动创新繁荣。开源模型使小型模型的能力获得了难以置信的进步,如图5所示。
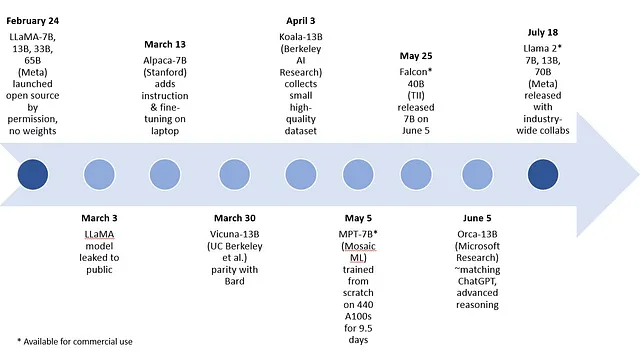
图5. 在2023年上半年,开源可商用和不可商用的GenAI敏捷模型都实现了爆发式增长。图片来源:Intel Labs
2023年初就出现了几个通用敏捷生成式AI模型的例子,首先是Meta的LLaMA[8],其拥有70亿、130亿、330亿和650亿参数的模型。其中70亿和130亿参数规模的模型通过对LLaMA进行微调创建的:斯坦福大学的Alpaca[14],伯克利AI研究院的Koala[15],以及加州大学伯克利分校、卡内基梅隆大学、斯坦福大学、加州大学圣地亚哥分校和穆罕默德·本·扎耶德人工智能大学研究人员合作推出的Vicuna[16]。最近,微软研究院(Microsoft Research)发表论文介绍了Orca[17],这是一个基于LLaMA的130亿参数模型,它模仿了巨型模型的推理过程,在针对特定领域进行微调之前取得了令人印象深刻的成果。

图6. 使用Vicuna评估集由GPT-4对开源chatbots的相对响应质量进行比较。图片来源:Microsoft Research[17]
Vicuna可视为最近从LLaMA衍生的开源敏捷模型典型代表。Vicuna-13B是多所大学合作开发的chatbot,推出Vicuna的目的是“填补现有模型(如ChatGPT)在训练和架构细节方面的空白”[18]。在对来自 ShareGPT 的共享对话数据进行微调后,使用GPT-4对其进行评估,其响应质量与ChatGPT和Google Bard相比,提高了90%以上[16]。但是,这些早期的开源模型不可商用。据报道,MosaicML的MPT-7B[10]和Technology Innovation Institute的Falcon 7B[9]是可商用的开源模型,他们的质量与LLaMA-7B相当。
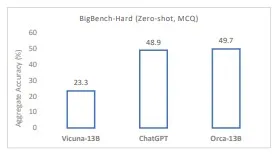
图7. 在BIG-bench Hard的复杂零样本推理任务上,Orca-13B的表现与ChatGPT相当。图片来源:Intel Labs[17]
据研究人员介绍[11],在复杂的零样本推理基准测试(如Big-Bench Hard,BBH[19])上,Orca优于指令调优的模型(如Vicuna-13B)100%以上,在BBH测试集上与ChatGPT-3.5表现持平。Orca-13B 的性能优于其他模型强化了这样一种观点,即出现巨型模型这样的庞大规模可能源自于早期模型训练的野蛮方法。这种观点对某些小模型提炼知识和方法确有裨益,但模型推理时并不一定需要庞大的参数规模,即使是一般情况下也是如此。需警惕的是,只有模型得到大范围地部署和使用之后才能全面评估模型的认知能力、技能掌握情况和知识量。
撰写本文时,Meta发布了参数规模为70亿、130亿和700亿的Llama 2模型[20]。在第一代产品问世仅四个月后,该模型就有了显著的改进。在对比图中[21],敏捷的Llama 2 13B达到了先前较大尺寸的LLaMA以及MPT-30B和Falcon 40B相近的表现。Llama 2是开源的,可供研究和商业用途免费使用。它是与微软以及包括英特尔在内的其他许多合作伙伴共同推出的。Meta对模型开源的承诺及其广泛的合作必将进一步推动我们所看到的此类模型跨行业或学术界的快速进步。
敏捷模型的第三个方面与专业化有关。新推出的许多敏捷模型是通用模型,如LLaMA、Vicuna和Orca。通用敏捷模型可能仅依赖参数记忆,并通过微调方法进行低成本更新,包括大语言模型的低秩自适应(LoRA)[22],以及检索式增强[23]生成方法(在推理时从经过编辑的语料库实时提取相关知识)。检索增强解决方案正在建立,并且借助像LangChain[24]和Haystack[25]这样的GenAI框架不断得到增强。这些框架可以轻松灵活地集成索引,有效地访问大型语料库,并实现基于语义的检索(semantics-based retrieval)。
大多数企业用户更喜欢针对其特定领域进行微调的有针对性的模型(targeted models)。这些有针对性的模型也倾向于采用检索式方法来充分利用所有关键信息资产(key information assets)。例如,医疗保健用户可能希望实现病人沟通的自动化。
这些有针对性的模型主要采用以下两种方法:
- 首先,针对特定任务和所需数据类型,对模型本身进行专业化调整。 此方法可以通过多种方式实现,包括在特定领域知识上进行预训练(例如,phi-1对网络上收集的高质量数据进行预训练),对同等规模的通用基础模型进行微调(例如,Clinical Camel[26]是如何微调LLaMA-13B模型的),或者将巨型模型的知识提炼并迁移到敏捷的学生模型(例如,Orca模仿GPT-4的推理过程,包括记录和跟踪模型推理过程、GPT-4逐步的思考过程和其他复杂指令)。
- 其次,整理相关数据并编制索引,以便实现即时检索。 这些数据可能数量庞大,但仍限定在目标使用案例范围内。模型可以检索持续更新的公共网络中的和私人消费者或企业的内容。用户可以决定对哪些资源进行索引,从而选择高质量的网络资源,以及更完整的、私有的私人数据或企业数据。虽然检索技术现在已被集成到巨型和敏捷系统中,但该技术对小型模型至关重要,因为模型性能表现基本依仗该技术。此外,它还使企业的所有私有数据和本地存储信息可为内部敏捷模型调用。
03 生成式AI敏捷模型的优势和劣势
未来,中型敏捷模型的规模可能上涨至200亿或250亿参数,但仍远小于1000亿参数级。还有参数量介于两者之间的模型,如MPT-30B、Falcon 40B和Llama 2 70B。尽管预计它们在零样本情况下表现会优于更小型的模型,但对于任何明确定义的任务集合(编者注:例如针对问答、翻译、摘要生成等任务),我预计它们的表现不会明显优于更小规模的、有针对性、基于检索的敏捷模型。
与巨型模型相比,敏捷模型具备许多优势,如果模型是有针对性的和基于检索的,这些优势会进一步增强,这些优点包括:
-
可持续性更强,成本更低:训练和推理计算成本大幅降低[27]。推理运行时的计算成本可能是面向业务的模型能否全天候使用的决定性因素,而当需要部署大量模型时,对环境的总体影响程度大幅降低也非常有意义。由于具有可持续性、专注性和功能导向性,敏捷模型无需解决通用AI模型的雄心目标,也较少卷入相关的公众和监管舆论。
-
更快的微调迭代:较小的模型仅需几小时(或更少时间)即可完成微调,通过LoRA等自适应方法[28]为模型添加新信息或新功能。这样可以更频繁地进行模型改进,保证模型持续满足用户的使用需求。
-
检索式模型的优势:检索系统通过从直接参考来源引用大部分信息,而不是从模型的参数记忆中提取信息,提高了以下方面的性能:
- 可解释性:检索模型采用来源归因(source attribution),可以追溯到信息来源并验证可信度。
- 及时性:一旦最新数据源被索引,无需再训练或微调即可被模型立即使用。这样可以近乎实时地持续添加或更新相关信息。
- 数据范围:为便于检索而索引的这些信息可以非常全面和详细。当专注于目标领域时,模型可以覆盖范围广、深度大的私人和公共数据,在该垂直领域中,可能比巨型基础模型的训练数据包含的量和细节还要多。
- 准确性:直接访问数据的原始形式、数据细节和上下文中的数据可以减少幻觉和数据近似的情况,只要数据在检索范围内就可以提供可靠的、完整的答案。对较小的模型来说,每次检索到的可追溯的、经过整理的信息与记忆信息之间的冲突也更小,(如巨型模型)可能过时、不完整且无源追溯。
-
硬件选择:敏捷模型实际上可在任何硬件上进行推理,包括可能已经集成到计算环境中的普遍解决方案。例如,Meta的Llama 2敏捷模型(70亿和130亿参数)可在英特尔的数据中心产品(包括Xeon、Gaudi2 和 Intel Data Center GPU Max Series)上良好运行[29]。
-
集成、安全和隐私:如今的ChatGPT等巨型GenAI模型通常作为独立模型运行在第三方平台的大型数据中心上,通过接口访问。相比之下,敏捷AI模型可以内嵌在更大的业务应用程序中运行,并且可完全集成到本地计算环境中。这对保护安全和隐私具有重大意义,因为无需与第三方模型和计算环境交换信息,甚至可以将市场上应用程序的所有安全机制应用于GenAI引擎。
-
模型优化和模型压缩:如模型量化等可以降低计算需求的模型优化和模型压缩技术,在敏捷模型上表现出较好的效果。
敏捷模型的一些挑战仍值得关注:
- 任务范围缩小:巨型通用模型拥有出色的多样性,在面对新的零样本用例中表现尤为突出。敏捷系统可以达到的广度和范围仍有待评估,但最近的模型这方面似乎有所改善。敏捷领域模型假定任务范围在预训练和微调期间是已知的和定义明确的,所以任务范围的缩小不应影响任何相关能力。敏捷领域模型不是仅针对单一任务,而是一系列相关的能力。这可能导致敏捷模型因任务或业务特定而出现碎片化现象。
- 可能需小样本微调改进性能:为了有效地解决特定领域的问题,不一定总是需要进行微调,但它可以通过调整模型以满足应用程序所需的任务和信息来增强人工智能的效果。目前的技术使该过程仅需很少样本即可完成,无需深度的数据科学专业知识。
- 检索模型需要对所有源数据进行索引:模型在推理时通过索引映射获取所需信息,但存在遗漏信息源的风险,导致其不可为模型调用。为确保具备可溯源、可解释性等特性,基于检索的、有针对性的模型不应依赖参数空间中的详细信息,而主要依赖于索引信息,在需要时可以进行提取。
04 总结
生成式人工智能的重大飞跃带来了新的能力,如 AI agents 以自然语言进行对话、生成引人入胜的文本和图像、利用以前迭代的上下文等等。本文引入“敏捷人工智能”概念,并阐明它为何未来将成为用于部署GenAI的主流方法。简单来说,敏捷人工智能模型运行更快,通过持续微调可以保持模型更快更新,而且更适合通过开源社区的集体创新实现快速的技术迭代。
如多个实例所证,巨型模型的演进显示出的出色性能表明,敏捷模型无需与庞大的巨型等量齐观。一旦掌握基本的认知能力,调整所需功能,并按需提供数据,敏捷模型可为业界带来最大的价值。
当然,敏捷模型不会淘汰巨型模型。 巨型模型仍然有望在零样本、开箱即用的情况下表现更好。大型模型也可用作提炼到更小敏捷模型的来源(教师模型)。虽然巨型模型拥有大量额外的记忆信息以应对各种潜在用途,并且具备多种技能,但对大多数GenAI应用而言这种全能性未必是必须。相反,根据领域相关的信息和技能对模型进行微调的能力,再加上从本地和全球资源中检索最新信息的能力,对许多应用而言选择敏捷模型将是更有价值的选择。
将敏捷的、有针对性的AI模型视为可并入任何现有应用程序的模块,可提供极具吸引力的价值主张,包括:
- 仅需极少的部署和运营成本。
- 可微调适应各种任务和私人、企业数据。
- 可在一夜之间更新模型,可在CPU、GPU或加速器等各种硬件上运行。
- 可集成到当下市场上的计算环境和应用中。
- 可企业内部部署或在私有云上运行。
- 可实施所有安全和隐私设置。
- 更高的准确性和可解释性。
在提供类似巨型生成式AI模型能力的同时,更环保。
少数巨型模型将继续取得令人瞩目的进展。然而,业界最可能仅需要几十个通用敏捷基础模型,它们可用来构建无数有针对性的模型版本。我相信不远的将来,GenAI 将渗透到各行各业,渗透方式主要是通过集成敏捷、有针对性的和安全的智能模块作为各行各业的增长引擎。
END
参考资料
1.https://www.trendforce.com/presscenter/news/20230301-11584.html
2.https://www.mosaicml.com/blog/mpt-7b
3.https://arxiv.org/pdf/2306.02707.pdf
4.https://writings.stephenwolfram.com/2023/03/chatgpt-gets-its-wolfram-superpowers/
5.https://openai.com/blog/chatgpt-plugins
6.https://doi.org/10.48550/arxiv.2212.10511
7.https://paperswithcode.com/dataset/popqa
8.https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
9.https://falconllm.tii.ae/
10.https://www.mosaicml.com/blog/mpt-7b
11.https://arxiv.org/pdf/2306.02707.pdf
12.https://blog.salesforceairesearch.com/xgen/
13.https://the-decoder.com/gpt-4-architecture-datasets-costs-and-more-leaked/
14.https://crfm.stanford.edu/2023/03/13/alpaca.html
15.https://bair.berkeley.edu/blog/2023/04/03/koala/
16.https://lmsys.org/blog/2023-03-30-vicuna/
17.https://arxiv.org/pdf/2306.02707.pdf
18.https://pub.towardsai.net/meet-vicuna-the-latest-metas-llama-model-that-matches-chatgpt-performance-e23b2fc67e6b
19.https://github.com/suzgunmirac/BIG-Bench-Hard
20.https://about.fb.com/news/2023/07/llama-2/
21.https://ai.meta.com/llama/
22.https://arxiv.org/abs/2106.09685
23.https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
24.https://python.langchain.com/docs/get_started/introduction.html
25.https://www.haystackteam.com/core/knowledge
26.https://arxiv.org/abs/2305.12031
27.https://www.semianalysis.com/p/google-we-have-no-moat-and-neither
28.https://arxiv.org/pdf/2106.09685.pdf
29.https://www.intel.com/content/www/us/en/developer/articles/news/llama2.html
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://towardsdatascience.com/survival-of-the-fittest-compact-generative-ai-models-are-the-future-for-cost-effective-ai-at-scale-6bbdc138f618