近年来,随着国产化大潮不断推进和数据库分布式技术趋势发展,越来越多的企业开始选择国产数据库替换原有数据库。然而,核心数据库迁移又是“令人闻风丧胆”的IT操作,稍有不慎就有“删库跑路”的巨大破坏性。
由于国产数据库主要采用分布式架构,技术差异大,很多企业在数据库国产化应用改造过程中,常常遇到各种问题,包括但不限于架构差异大、数据不兼容、语法差异、性能等问题,导致数据库迁移工作苦不堪言。
应用改造就那些事
数据库国产化应用改造,业务层面并没有发生变化,其本质是解决数据库之间的差异性,那么国产化与传统数据库间的差异,无非就以下几个方面:
- 架构差异:在架构规划上存在差异,因此在进行数据模型设计时需注意这些差异,尽可能保证数据存储和分布合理性。
- 功能差异:在语法和函数上存在差异,因此在进行改造时需要注意这些差异,避免出现语法错误、功能不完整或数据不一致的问题。
- 性能差异:在性能方面也可能存在差异,因此在进行改造时需要注意这些差异,尽可能保证迁移后的数据库系统具有高性能和稳定性。
- 其他方面:还有其他一些方面也需要注意,比如安全性、可扩展性、可维护性等等。
我们的实践之路
面对这些差异,我们在应用改造过程中,要综合考虑,并做出相应的调整和优化,以确保改造后的系统能够满足业务需求,并具备高性能、稳定性、安全性等特点。我们结合研发管理流程,采用“3阶段11步骤”解决方案,实现国产化数据库迁移应用改造。
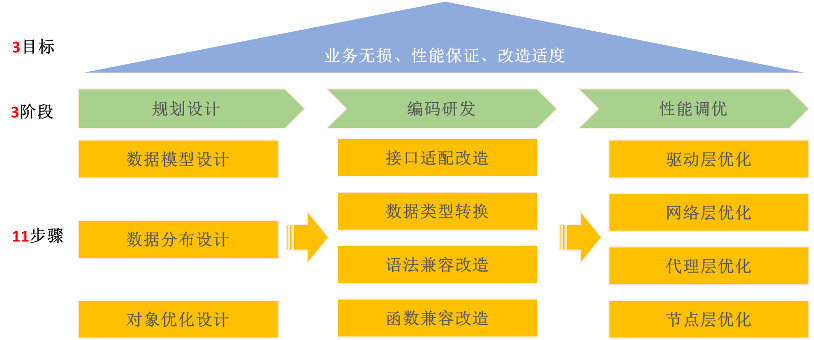
- 规划设计:根据所选型的数据库特性,通过调整表类型、分片键、分片算法等重新规划数据库表结构,设计出最合理的模型。
- 编码研发:细化数据库差异点,通过接口适配、数据类型、语法兼容、函数四方面兼容性对代码进行改造,以确保业务功能无损。
- 性能调优:结合数据库优化模型,对驱动层、网络层、代理层、节点层进行数据库和SQL优化,确保性能和可靠性。
分布式数据模型设计
国产数据库一般采用分布式架构,其数据模型设计流程包括以下几个步骤,比传统集中式数据库多了分片设计、分布设计以及对象优化调整。在数据库应用改造时,我们补齐这三个步骤。

数据分片设计
在分片设计前,我们先了解一下国产数据库架构,它包括计算节点、数据节点、全局事务这三层,此外,还有一个非常重要的概念是,分布式数据库是把数据分散存储在各个分片中。例如,GoldenDB分片存储在MySQL实例中。国产数据库需要关注一个非常重要的设计:正确地把数据分片,充分发挥分布式数据库架构的优势。

为满足分片键选择中唯一性、均匀性、高数据关联性的关键原则,有以下三个思路:
-
尽量选择distinct值比较多的列,保证数据均匀分布。分布均匀是为了避免木桶效应,各个主机对等执行。
-
尽量选择join列或group列,避免数据节点之间数据流动,提高性能。
-
尽量选择带入参的列,减少中间结果集回流CN节点(计算节点)及CN节点的SQL拆分计算。
选出分片键后,就要选择分片算法,不同分布式数据库的拆分算法都支持LIST、RANGE、HASH、复合分片等,选择拆分算法与业务场景密切相关,大多数业务场景都能根据需要作出良好的决策,以下是几种常见的场景。
-
如果按照时间字段拆分,最好选RANGE或者LIST。
-
针对批量场景,主要涉及范围查询和批量写入两个场景,如果对范围查询性能要求高,那可以选用RANGE,但可能导致写入各个分片承受压力不均衡;如果对批量写入性能要求高,就使用HASH,但范围查询肯定会扫描全部分片,性能会较慢。
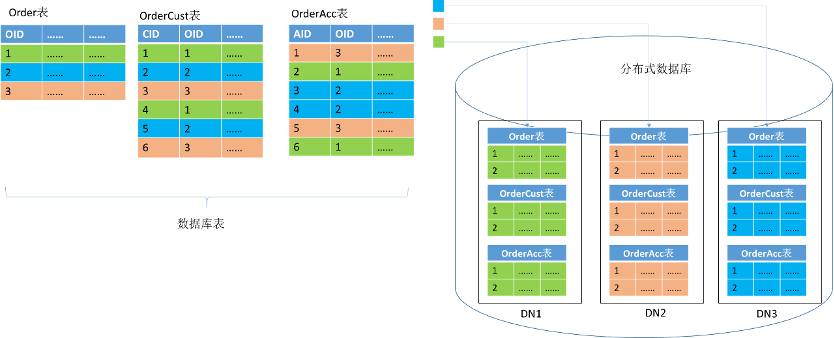
数据分布设计
数据库表分布设计,主要考虑数据的冗余分配和位置的条带化分配两个方面:
- 冗余分配:即将一份数据映射到多个节点,也称复制表。复制表是以空间换性能的做法,设计时,通过分析表类型、行数量、访问频次、关联复杂度,可将高频访问表、配置表、关联常用驱动表等设置成复制表。
- 条带化分配:分布式数据库中的表,要尽量选出一个统一的分片键,即大部分表都能根据这个分片键打散数据,这样当后续业务进行访问数据时,可以在一个分片中完成单元化的闭环操作,不用涉及跨分片的访问。在设计时,应分析高频SQL和慢SQL,并不断调整表的分析键,以实现数据条带化分布。
对象优化设计
分布式数据库架构对象优化主要是对索引设计调整,需要充分发挥分布式架构的线性可扩展优势,主要有2类索引设计调整。
主键选择:集中式数据库,很多采用自增序号作为主键,但其自增性能差、安全性不高,不适用于分布式架构。建议用全局唯一的键作为主键,比如 MySQL 自动生成的有序 UUID;业务生成的全局唯一键;或者是开源的 UUID 生成算法,比如雪花算法(但存在时间回溯问题)。
普通索引设计:索引字段经常不包含分片键,那么使用索引时需要查询所有分片,性能比较差。可以采用以下两种设计:1)将索引字段设置为分片键,创建一个索引表实现;2)在索引中额外添加分片键的信息。
代码四大兼容性改造
在调整数据模型后,接着对代码进行兼容性改造,有两个要求:广适配数据库对象,深挖掘差异改造点。首先,在广度上,应对代码中涉及的数据库接口、数据类型、语法、函数等四方面进行全面兼容性改造。
接口适配改造
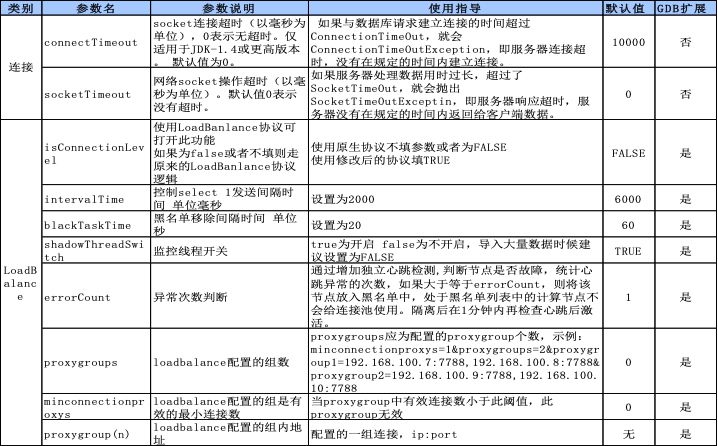
JAVA应用通常使用JDBC协议连接数据库,除替换驱动程序外,还需要对分布式数据库的驱动连接和高可用特性参数进行设置,以更好地利用分布式数据库优势,以下是GoldenDB改造过程中的常用驱动协议属性改造点。
数据类型转换
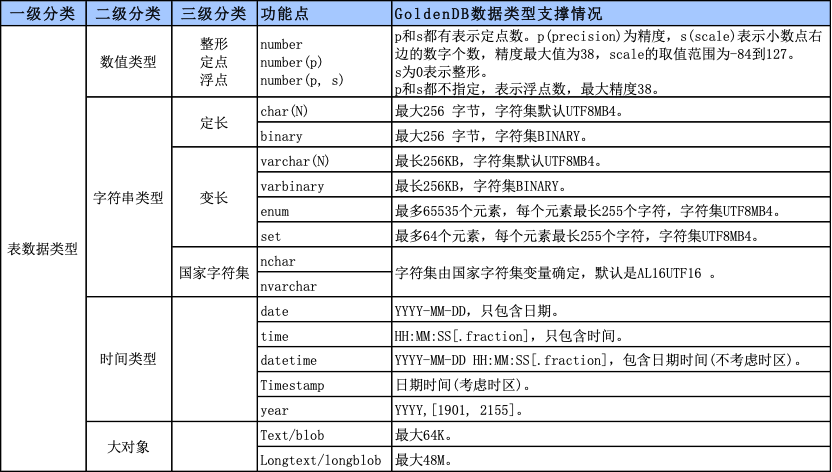
数据类型转换涉及字段类型、精度、长度、字符集之间的转换,很多成熟第三方工具或厂家工具都可实现,这里不再详述。需要注意的是字符串长度算法和字符集问题,例如Oracle按字节算字符串长度,MySQL(GoldenDB/OB)按字符计算;UTF8字符集,Oracle默认UTF8mb3, MySQL (GoldenDB/OB) 默认UTF8mb4。这些类型都需要进行长度转换。以下是GoldenDB字段类型的精度、长度、字符集支持情况。
语法兼容改造
主流分布式数据库主要选型PG(openGauss)和MySQL(OB、GoldenDB),因此需要对Oracle、PG、MySQL之间的语法兼容性做一下差异分析(分布式厂家会对兼容性差异做适配,减少差异,该部分不在讨论范围),然后研发按图索骥对不兼容项进行改造,以下为三者之间的主要区别:
函数兼容改造
与语法兼容性类似,除厂家进行兼容性改造外,Oracle、PG、MySQL之间也需要对函数差异进行改造,常见的函数差异如下:

需要注意的是字段NULL值,数据库中的NULL值是比较特殊的存在,不同数据库可能存在一些差异,例如,GoldenDB对NULL存在以下限制:
-
NULL字段不能作为全局索引和分片键。
-
NULL不等于任何值(包括 TRUE、FALSE 或者 NULL);不能进行关系运算(大于、小于、等于、不等于)。
-
NULL 值能做IS NULL 或 IS NOT NULL 判断,可以用函数转换为普通值,如 NVL 、NVL2 函数。
-
在 NOT IN 子查询里,如果子查询返回结果集包含了 NULL 值,则整个 NOT IN 条件都是返回为空。
在广度剖析代码中的差异性后,如何深度挖掘存在差异的SQL呢?可以采用两种回放方式来收集数据库不兼容项。
方式一: 利用MyBatis 插件机制,编写自定义插件,在SQL Prepare阶段插入自定义逻辑,从而获取 SQL 语句并输出,实现应用SQL的录制。
方式二: 利用Oracle的WCR工具录制数据库执行SQL,虽然该种方式可以捕获所有的SQL,但无法标识具备应用,且需要对SQL进行过滤,剔除运维和Oracle内部事务等非应用SQL。

WCR回放流程
最后,将捕捉到的SQL转成目标库语法,进行回放检测出不兼容项,并形成改造标准项,以供研发和测试人员按图索骥修改。
数据库分层性能优化
分析数据库优化之前,我们先看看SQL执行的路径,以理解可能影响SQL执行速度的相关因素。

大多数分布式数据库的执行路径为:应用->驱动程序->Proxy->数据节点,即从应用发起SQL,调用驱动程序,经过Proxy解析拆分后到达数据节点,数据节点执行SQL并将结果反馈给Proxy聚合处理或直接返回给应用,从这个过程中,可以得到几个影响SQL执行速度的因素:
-
驱动程序的连接性能。
-
应用与Proxy间的网络传输。
-
Proxy的聚合处理能力。
-
数据节点本身的SQL执行效率。
驱动层优化
驱动程序作为应用与数据库之间的桥梁和连接入口,在引入驱动时,往往忽略参数优化。可以通过优化驱动参数,如数据库连接、SQL缓存、负载均衡等,来提高SQL执行性能,例如,GoldenDB驱动可通过以下参数进行性能调优:

网络层优化
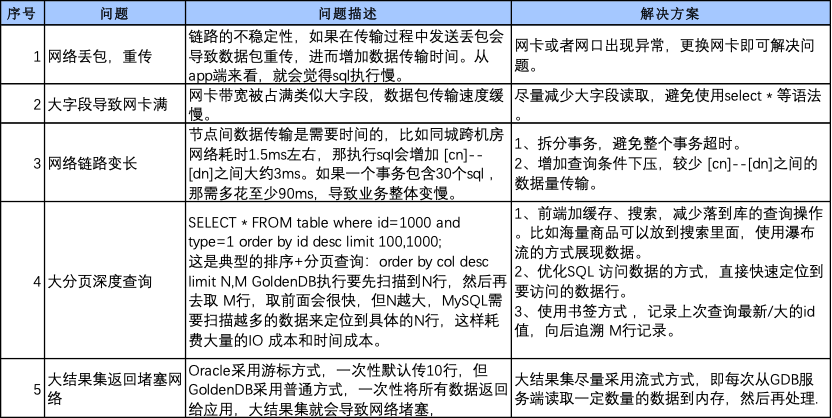
应用与Proxy间的网络传输也是重要问题,可能导致问题包括网络本身问题、数据获取机制、数据结果集过大等,以下是我们在GoldenDB改造踩过的一些坑及解决方案:
代理层优化
Proxy主要负责数据汇聚处理,对从各DN获取到的数据进行二次关联,这涉及到分布式特有的关联操作,即“分布式JOIN”。
分布式JOIN有多种情况,主要分为两大类:
可下推的JOIN,即JOIN操作由数据节点完成,Proxy层对JOIN结果进行汇总,这种方式效率更高,因为存储和计算在一起,例如,同维度的JOIN和复制表的JOIN。
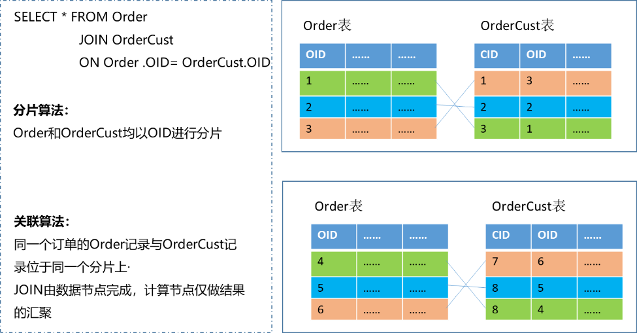
同维度的JOIN

复制表的JOIN
不可下推的JOIN,数据节点做单表查询,Proxy完成JOIN操作,这种方式涉及大量数据同步,效率较低,如Nested Loop Join。
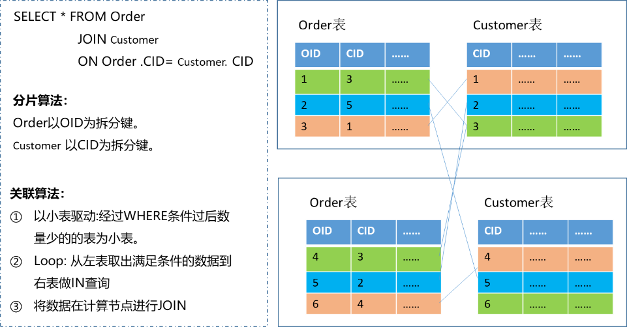
Nested Loop Join
SQL在代理层调优时,主要考虑避免Nested Loop Join。以下是我们在项目中积累的一些优化经验:

节点层优化
数据节点实际上就是单个MySQL或者PG实例,优化手段与传统数据库差异不大,这里不再赘述。
结语
数据库国产化不仅仅是为了“国产”这个标签,更是“分布式替代集中式”的云计算发展趋势的体现。这种技术革新对业务软件的重塑,需要在数据库国产化应用重构的过程中,将分布式架构的技术、特性和原理融入到规划设计、代码研发和性能优化的各个阶段,以充分利用分布式数据库的优势。这样,新系统才能拥有传统数据库无法比拟的能力,才能为业务提供更高的性能、稳定性和敏捷支持。只有通过专业团队的支持,才能帮助客户在数据库国产化的浪潮中脱颖而出,才能在数据库迁移的过程中苦中带一点乐。
本文是国产化数据库改造实践中的一点浅见,以期为正在 “国产化数据库改造”的您提供一些参考和启示。