目录
- 一、最大池化
- 最大池化进行压缩
- 平移不变性
- 二、代码示例
- 步骤2:图像读取转换
- 步骤2:Filter & ReLU
- 步骤3:Pool
一、最大池化
最大池化进行压缩
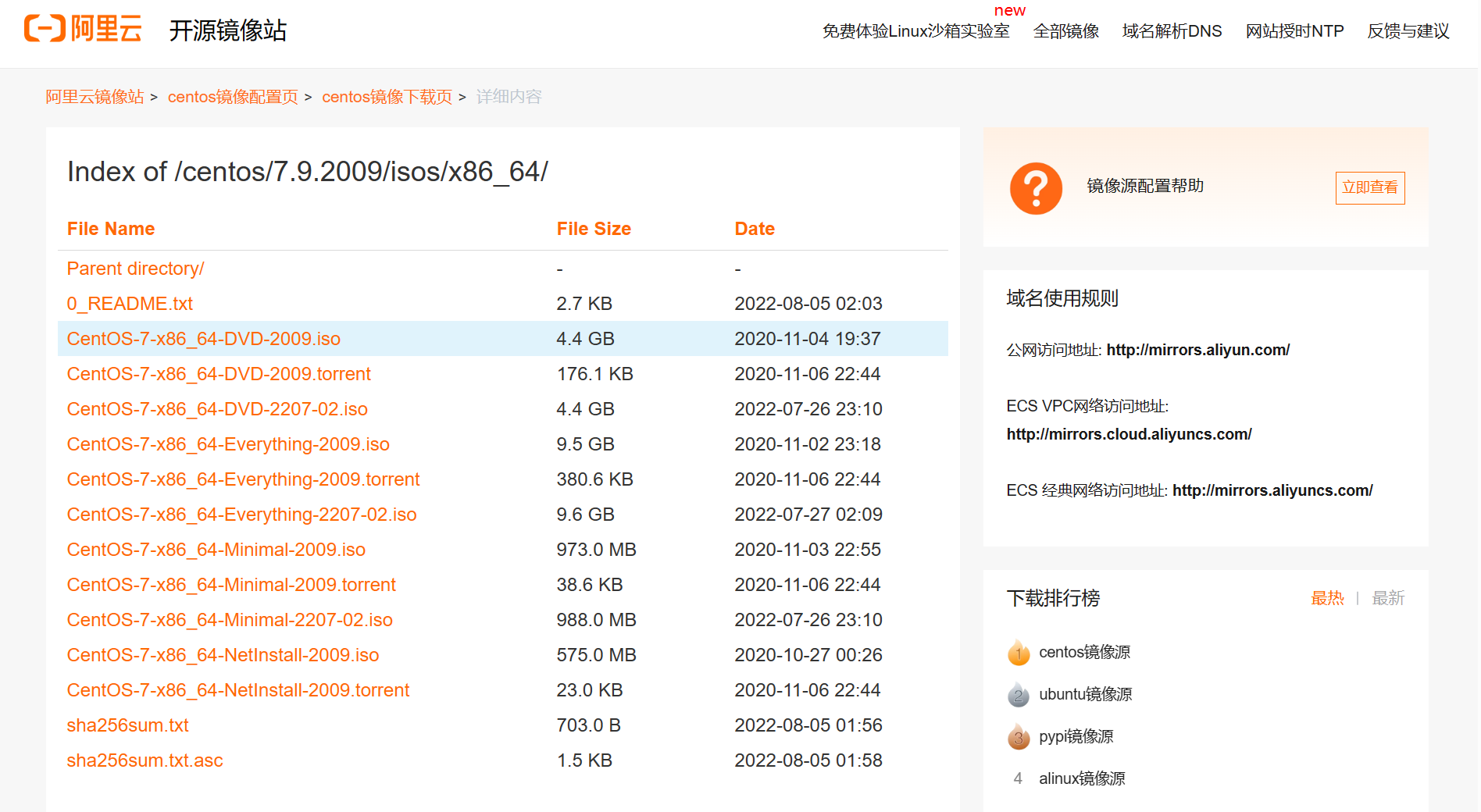
在Keras中,通过一个 MaxPool2D 层,将压缩步骤添加到之前的模型中:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3), # 激活函数为 None
layers.MaxPool2D(pool_size=2),
# 后续添加更多层
])
MaxPool2D层很像Conv2D层,不同之处在于它使用了一个简单的最大函数而不是卷积核,pool_size参数类似于kernel_size。然而,MaxPool2D层不像卷积层的卷积核中那样有任何可训练的权重。
让我们再次看一下上一节的特征提取图。记住,MaxPool2D是压缩步骤。

见上图,在应用ReLU函数(Detect)之后,特征图会出现很多“死区”,即大面积仅包含0的区域(图像中的黑色区域)。如果必须在整个网络中保留这些0激活,将会增加模型的大小,而没有添加太多有用的信息。相反,我们希望将特征图进行压缩,只保留最有用的部分 —— 即特征本身。
这实际上就是最大池化的作用。最大池化采用原始特征图中的一小块激活,并将它们替换为该块中的最大激活值。

当应用在ReLU激活之后,它具有“加强”特征的效果。池化步骤增加了活动像素与零像素的比例。
平移不变性
我们称零像素为“不重要”。这是否意味着它们完全不携带任何信息?实际上,零像素携带着位置信息。空白像素仍然在图像中定位特征。当MaxPool2D移除一些像素时,它也会移除特征图中的一些位置信息。这使得卷积网络具有一种称为平移不变性的属性。这意味着带有最大池化的卷积网络往往不会根据特征在图像中的位置来区分它们。
观察当我们反复应用最大池化到下面的特征图时会发生什么。
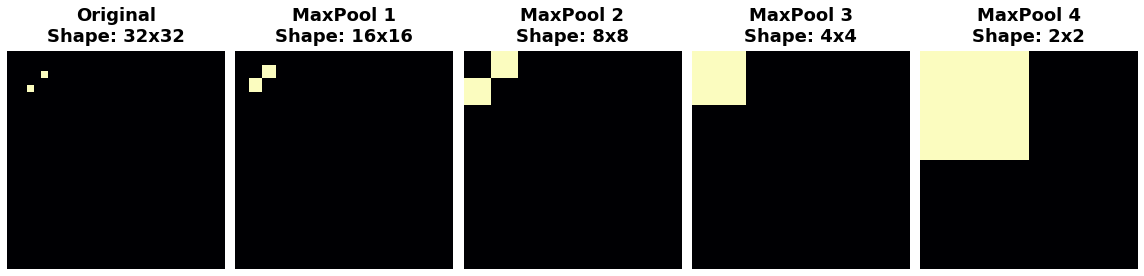
原始图像中的两个点在经过重复池化后变得无法区分。换句话说,池化破坏了一些位置信息。由于网络在特征图中无法区分它们,因此也无法在原始图像中区分它们:它对于这种位置的差异已经变得不变。
事实上,池化只会在网络小距离上产生平移不变性,就像图像中的两个点一样。开始距离较远的特征在经过池化后仍然保持分开;只是一些位置信息丢失了,但并不是全部。
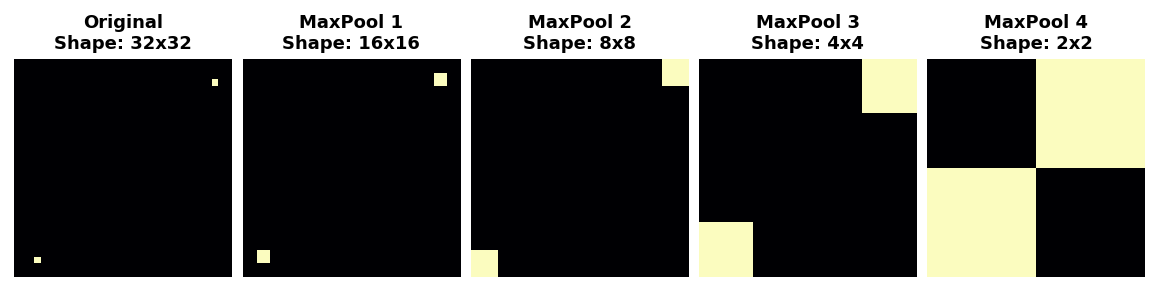
特征之间位置上小的差异的这种不变性对于图像分类器来说是一个很好的特性。由于视角或构图的差异,同一种特征可能位于原始图像的不同部分,但我们仍然希望分类器能够识别它们是相同的。因为这种不变性内置在网络中,我们可以使用更少的训练数据:我们不再需要教它忽略这种差异。这使得卷积网络在效率上比仅使用密集层的网络具有很大的优势。
二、代码示例
步骤2:图像读取转换
import numpy as np
from itertools import product
import tensorflow as tf
import matplotlib.pyplot as plt
import warnings
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
warnings.filterwarnings("ignore") # to clean up output cells
def show_kernel(kernel, label=True, digits=None, text_size=28):
kernel = np.array(kernel)
if digits is not None:
kernel = kernel.round(digits)
cmap = plt.get_cmap('Blues_r')
plt.imshow(kernel, cmap=cmap)
rows, cols = kernel.shape
thresh = (kernel.max()+kernel.min())/2
if label:
for i, j in product(range(rows), range(cols)):
val = kernel[i, j]
color = cmap(0) if val > thresh else cmap(255)
plt.text(j, i, val,
color=color, size=text_size,
horizontalalignment='center', verticalalignment='center')
plt.xticks([])
plt.yticks([])
image_path = 'car_feature.jpg'
image = tf.io.read_file(image_path)
image = tf.io.decode_jpeg(image)
kernel = tf.constant([
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1],
], dtype=tf.float32)
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.expand_dims(image, axis=0)
kernel = tf.reshape(kernel, [*kernel.shape, 1, 1])
步骤2:Filter & ReLU
# Filter step
image_filter = tf.nn.conv2d(
input=image,
filters=kernel,
# we'll talk about these two in the next lesson!
strides=1,
padding='SAME'
)
# Detect step
image_detect = tf.nn.relu(image_filter)
plt.figure(figsize=(12, 6))
plt.subplot(131)
plt.imshow(tf.squeeze(image), cmap='gray')
plt.axis('off')
plt.title('Input')
plt.subplot(132)
plt.imshow(tf.squeeze(image_filter))
plt.axis('off')
plt.title('Filter')
plt.subplot(133)
plt.imshow(tf.squeeze(image_detect))
plt.axis('off')
plt.title('Detect')
plt.show();

步骤3:Pool
image_condense = tf.nn.pool(
input=image_detect, # image in the Detect step above
window_shape=(2, 2),
pooling_type='MAX',
# we'll see what these do in the next lesson!
strides=(2, 2),
padding='SAME',
)
image_condense2 = tf.nn.pool(
input=image_detect, # image in the Detect step above
window_shape=(3, 3),
pooling_type='MAX',
# we'll see what these do in the next lesson!
strides=(2, 2),
padding='SAME',
)
plt.figure(figsize=(12, 6))
plt.subplot(131)
plt.imshow(tf.squeeze(image_detect))
plt.axis('off')
plt.title('Detect')
plt.subplot(132)
plt.imshow(tf.squeeze(image_condense))
plt.axis('off')
plt.title('Pool')
plt.subplot(133)
plt.imshow(tf.squeeze(image_condense2))
plt.axis('off')
plt.title('Pool2')
plt.show();

图像由左到右,由于池化压缩,图片逐步模糊。