目录
前言
一、正则表达式
二、grep
三、find
四、sed
五、awk
前言
文件四剑客是指在计算机领域中常用的四个命令行工具,包括awk、find、grep和sed。它们在处理文本文件和搜索文件时非常强大和实用。
1. awk是一种强大的文本处理工具,它允许用户根据指定的规则处理文本文件。它可以根据字段分隔符对文本进行分割,并且可以对行、列或者多个列进行操作。它还支持条件语句、循环和函数等功能,可以进行复杂的文本处理和数据分析。
2. find是一种用于搜索文件的工具,它可以在指定的文件夹及其子文件夹中查找满足指定条件的文件。用户可以根据文件名、日期、大小等条件来搜索文件。它还支持使用正则表达式进行高级搜索。
3. grep是一种用于搜索文本的工具,它可以在文本文件中查找满足指定模式的行。用户可以根据关键字、正则表达式等条件来搜索文本。它还支持递归搜索、忽略大小写和显示上下文等功能。
4. sed是一个流编辑器,用于对文本进行编辑和转换。它可以根据指定的规则对文本进行替换、删除、插入和打印等操作。它还支持正则表达式、条件语句和循环等功能,可以进行灵活的文本处理。
这四个工具在命令行中经常被使用,它们可以单独使用,也可以结合起来实现更复杂的操作。它们在文本处理、数据分析和文件搜索等方面提供了强大而灵活的功能。
一、正则表达式
在此之前我们先准备一份文件test.txt用来练习
##创建
vim /test.txt
##插入
shirt
short
good
food
wood
wooooooood
gooood
adcxyzxyzxyz
abcABC
best
besssst
ofion
ofson
ofison
AxyzxyzC
test
tast
hoo
boo
jooa)查找特定字符 cat test.txt | grep -n '需要查找的内容' 其中-n表示显示行数
例如我查找hoo

b)利用[]查找集合字符
cat test.txt | grep -n 'w[io]' 查找以w开头并匹配其中带有i或o的内容

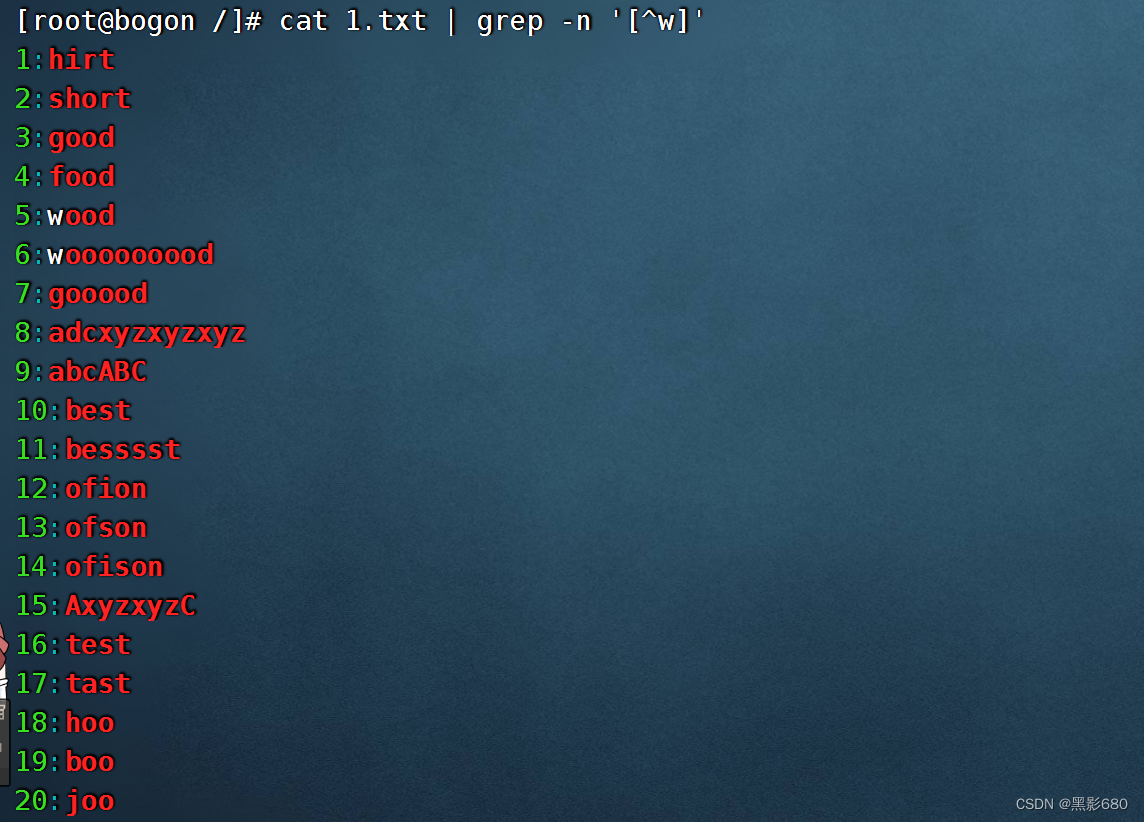
cat test.txt | grep -n '[^w]' 排除开头为w的内容
cat test.txt |grep -n '^[w]' 筛选出以w开头的内容

cat test.txt | grep -n '[a-h]oo' 筛选出含有a.b.c并有 oo的内容

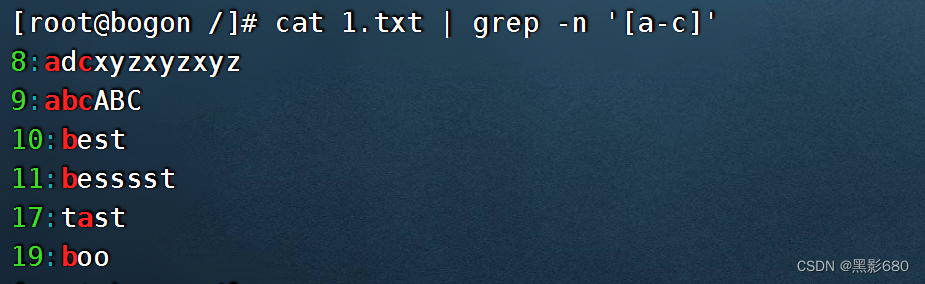
cat test.txt | grep -n '[a-c]' 筛选出含有abcd的内容
c)查找行首"^"与行尾"$"
cat test.txt | grep -n '^[a]' 查找a开头的内容
cat test.txt | grep 'C$' 查找C结尾的内容
d)查找任意一个字符"."与重复字符"*"
cat test.txt | grep -n 'b.o'查找开头是b结尾是o的三个字符的内容
cat test.txt | grep -n 'oooo*'查找所有oooo的内容
e)查找连续的字符范围"{}",需要使用转义符,"\{\}"
1. `cat test.txt | grep -n 'o\{2\}'`
这条命令首先使用cat命令将test.txt文件的内容输出到标准输出,然后通过管道(|)将其传递给grep命令进行搜索。grep命令使用`-n`选项来显示匹配行的行号,并使用正则表达式`'o\{2\}'`来匹配含有两个连续的字母o的行。
2. `cat test.txt | grep -n 'wo\{2,5\}d'`
这条命令的操作与第一条命令类似,只是正则表达式`'wo\{2,5\}d'`用来匹配以两个到五个连续的字母o开始,并以字母d结尾的行。
3. `cat test.txt | grep -n 'wo\{2,\}d'`
这条命令仍然与前两条命令类似,正则表达式`'wo\{2,\}d'`用来匹配以两个或更多连续的字母o开始,并以字母d结尾的行。
f)+,重复一个或一个以上的前一个字符
cat test.txt | grep -nE 'wo+d' 或者cat test.txt | egrep -n 'wo+d'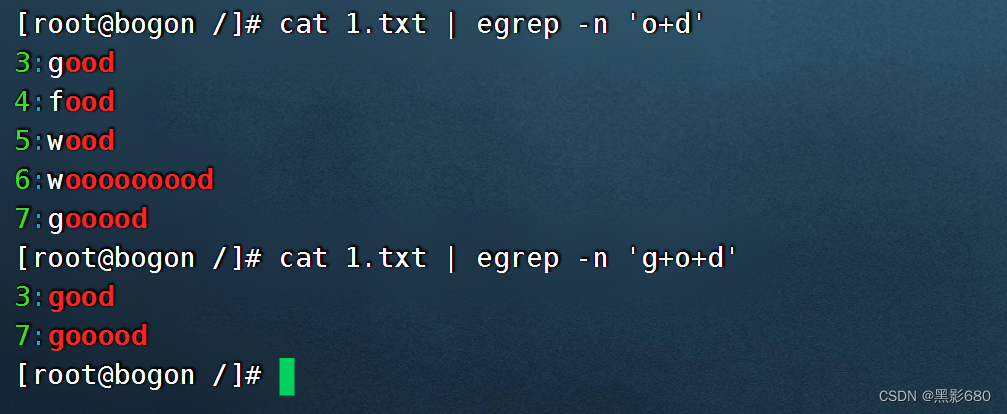
g)?,零个或者一个前一个字符
cat test.txt | egrep -n 'g?od'在正则表达式'g?od'中,?是一个特殊字符,表示前面的字符(这里是字母g)可出现0次或1次。因此,这个正则表达式将匹配包含“od”或“god”的行。也就是说,它匹配包含“od”或“god”的行,其中字母g可选。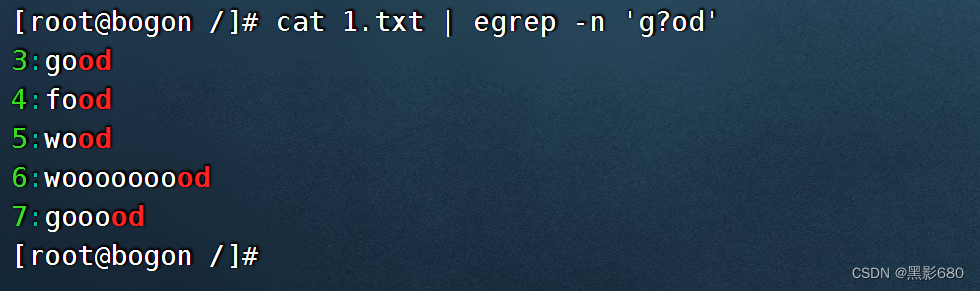 '
'
h)|,使用或者的方式找出多个字符
cat test.txt | egrep -n 'of|is|on' 这里是表示多个晒选条件,可以不是同一个,这里是查找带有of/is/on的内容
i)(),查找组字符串
cat test.txt | egrep -n 't(a|e)st'
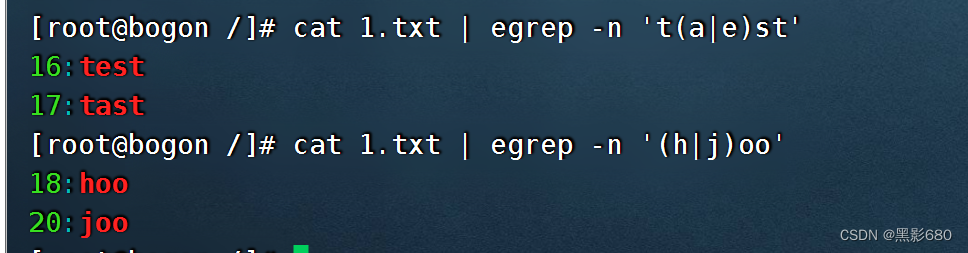
l)()+,辨别多个重复的组
cat test.txt | egrep -n 'A(xyz)+C'
以下为了解:
常见正则表达式
数字
“^[0-9]*[1-9][0-9]*$” //正整数
“^((-\d+)|(0+))$” //非正整数(负整数 + 0)
“^-[0-9]*[1-9][0-9]*$” //负整数
“^-?\d+$” //整数
“^\d+(\.\d+)?$” //非负浮点数(正浮点数 + 0)
“^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$” //正浮点数
“^((-\d+(\.\d+)?)|(0+(\.0+)?))$” //非正浮点数(负浮点数 + 0)
“^(-?\d+)(\.\d+)?$” //浮点数
字符串
“^[A-Z]+$” //由26个英文字母的大写组成的字符串
“^[a-z]+$” //由26个英文字母的小写组成的字符串
“^[A-Za-z0-9]+$” //由数字和26个英文字母组成的字符串
“^\w+$” //由数字、26个英文字母或者下划线组成的字符串
Email
“^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$” //email地址
“^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$” //Email
Url
“^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$” //url
IP
“^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$” //IP地址
Tel
/^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ //电话号码
日期校验
/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日 yyyy-MM-dd / yy-MM-dd 格式
"^[0-9]{4}-((0([1-9]{1}))|(1[1|2]))-(([0-2]([0-9]{1}))|(3[0|1]))$" // 年-月- 日 yyyy-MM-dd 格式
/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年
二、grep
1、grep用于筛选文件的内容 :
-r递归扫描指定目录下的每一个文件
-l只显示匹配到指定关键字的文件名,而不是文件内容
[root@bogon opt]# grep -lr "good" .
./test.txt
####这表示在当前目录查询那个文件内有“good”这个内容2、案例
查看/etc目录下所有包含bash的文件名
grep -rl bash /etc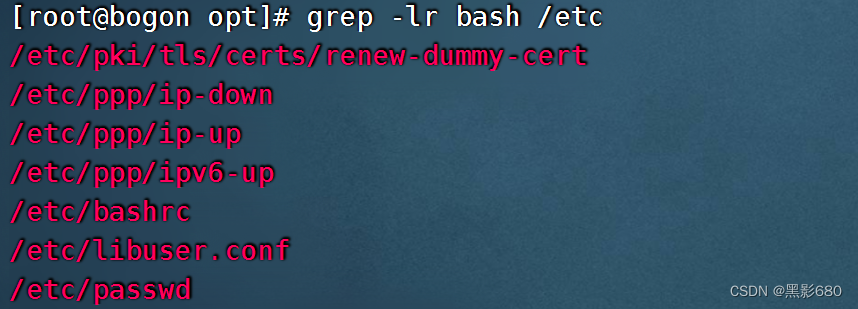
3、egrep完美支持正则表达式
三、find
1、find ./ -type f -prem 644 查找当前目录下权限为644的文件
[root@localhost opt]# find ./ -type f -perm 644
./test.txt
./1.sh
[root@localhost opt]# ll
总用量 8
-rw-r--r-- 1 root root 767 8月 21 22:00 1.sh
drwxr-xr-x. 2 root root 6 10月 31 2018 rh
-rw-r--r-- 1 root root 12 8月 21 21:59 test.txt
2、按照时间戳查找
-atime
-mtime
-ctime
按照时间戳查找是指根据文件的访问时间、修改时间和状态改变时间来搜索文件的过程。在Linux系统中,可以使用find命令来进行这样的时间戳搜索。
具体的时间戳搜索可以使用以下三个选项:
1. -atime:根据文件的访问时间来搜索文件。访问时间指的是文件最后一次被访问的时间。使用该选项时,可以指定一个时间参数,如+n、-n或n,来搜索在指定时间范围内被访问的文件。
示例:查找在过去30天内被访问过的文件
find /path/to/search -type f -atime -30
2. -mtime:根据文件的修改时间来搜索文件。修改时间指的是文件内容最后一次被修改的时间。使用该选项时,也可以指定一个时间参数,来搜索在指定时间范围内被修改的文件。
示例:查找在过去7天内被修改过的文件
find /path/to/search -type f -mtime -7
3. -ctime:根据文件的状态改变时间来搜索文件。状态改变时间指的是文件元数据(如权限、所有者等)最后一次改变的时间。同样地,可以指定一个时间参数来搜索在指定时间范围内状态改变的文件。
示例:查找在过去24小时内状态改变过的文件
find /path/to/search -type f -ctime -1
在这些示例中,`/path/to/search`是要搜索的目录路径,`-type f`用于限制搜索仅包括文件而不包括目录。
通过这些选项,可以根据文件的访问时间、修改时间和状态改变时间来精确搜索和筛选文件。3、-exec find /var/spool/mail -type f -exec rm -rf {} \;
xargs find /var/spool/mail -type f | xargs rm -rf
查看所有邮箱中的文件并
##-exec
find /var/spool/mail -type f -exec rm -rf {} \;
##xargs
find /var/spool/mail -type f | xargs rm -rf四、sed
语法:sed [选项] '操作' 参数
sed [选项] -f scriptfile 参数
选项
-e:表示用指定命令或脚本处理
-f:指定脚本文件
-h:帮助
-n:表示仅显示处理后的结果
-i:直接编辑文本文件
-r:支持扩展正则
操作
a:增加,在当前行下面以行增加指定内容
c:替换,将选定行替换
d:删除,删除指定行
i:插入,在选定行的上面插入一行
p:打印
s:替换,替换指定字符
y:字符转换
1.输出符合条件的文本:
sed -n 'p' test.txt #相当于cat
sed -n '3p' test.txt #打印第3行
sed -n '3,6p' test.txt #打印第3到6行的内容
sed -n 'p;n' test.txt #打印奇数行
sed -n 'n;p' test.txt #打印偶数行
sed -n '1,6{p;n}' test.txt #打印1到6行之间的奇数行
sed -n '5,${p;n}' test.txt #从第5行开始打印奇数行
sed -n '/the/p' test.txt #匹配the
sed -n '5,/the/p' test.txt #匹配从第5行开始到包含the的行
sed -n '/the/,10p' test.txt #匹配从包含the的行到第10行结束
sed -n '/the/=' test.txt #打印包含the的行号2.删除符合条件的文本
nl test.txt | sed '3d' #删除第3行
nl test.txt | sed '3,5d'
nl test.txt | sed '/the/d' #删除the所在行3.替换符合条件的文本
nl test.txt | sed 's/the/TTTTTT/' #替换全文本
nl test.txt | sed '4s/the/TTTTTT/' #替换第4行
nl test.txt | sed 's/l/L/2' #替换匹配到的第2个l
以上修改想要直接修改文本源文件,只需要加入选项"-i"
五、awk
语法
awk 选项 '模式或条件{编辑命令}' 文件1 文件2 ...
awk -f 脚本文件 文件1 文件2 ...
语法
awk 选项 '模式或条件{编辑命令}' 文件1 文件2 ...
awk -f 脚本文件 文件1 文件2 ...
选项
-F
指定每行的分隔符
默认分隔符为空格
内建变量
FS:指定每行的分隔符
NF:指定当前处理行的字段个数
NR:当前处理行的行号
$0:当前处理行的整行内容
$n:当前处理的第n个字段
FILENAME:处理文件名
RS:数据记录分隔,默认是\n
案例:
a)按行输出
awk '{print}' test.txt #等同cat
awk 'NR>=1&&NR<=3{print}' test.txt
awk 'NR==1,NR==3{print}' test.txt #打印1到3行
awk 'NR%2==0{print}' test.txt #打印偶数行
b)按段输出
默认以"空格"分段!
ifconfig ens33 |awk '/netmask/{print $2}' #筛选IP地址
cat /etc/shadow | awk -F : '$2=="!!"{print $1}' #打印不能登录系统的用户
c)调用shell命令
cat /etc/passwd | awk -F : '/bash$/{print | "wc -l"}' /etc/passwd #统计能够登录系统的用户个数