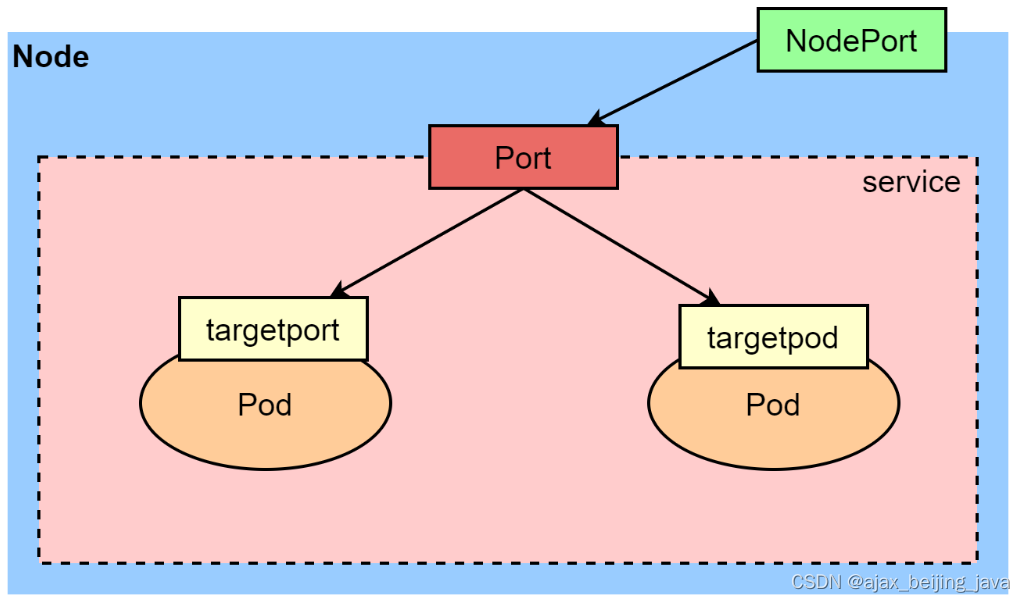
【界面介绍】
【个人主页】
注册之后(国内邮箱免费注册)会有个人主页,用来调试创建自己的模型和数据集

右边是网站中的模型使用趋势,左边:

注册账户后可以提供免费训练模型和数据集的工作台,创建即可(因为暂时用不到,不做详细说明)
【模型】
主要用到的是挑选别人已经做好的模型


右上几个功能见 [3] 的介绍,另外扩展处有其他使用率相对不高的选项:

可以点击相关标签进一步筛选模型

【模型名称解读】

在Hugging Face上,模型名称通常是对模型架构、训练数据和任务的一种描述。这些模型名称通常包含了一些关键信息,帮助用户理解模型的基本特征。
【例子】
1、“bert-base-uncased”
这个模型名称中的"bert"代表了模型架构为BERT(Bidirectional Encoder Representations from Transformers)。
"base"表示这是基本版的模型,通常是指相对较小的模型规模。
"uncased"表示这个模型是在训练数据中将所有文本转换为小写处理的,没有区分大小写。
"bert-base-uncased"表示了一个基于BERT架构的小型模型,适用于不区分大小写的任务。
2、“gpt2-medium”
这个模型名称中的"gpt2"代表了模型架构为GPT-2(Generative Pre-trained Transformer 2)。
"medium"表示这是GPT-2模型系列中的中型规模模型。
"gpt2-medium"表示了一个中等规模的GPT-2模型。
3、“roberta-large”
这个模型名称中的"roberta"代表了模型架构为RoBERTa(Robustly Optimized BERT approach)。
"large"表示这是RoBERTa模型系列中的大型规模模型。
"roberta-large"表示了一个大型的RoBERTa模型。
4、“distilbert-base-uncased-finetuned-sst-2-english”
这个模型名称解释了一些特定的信息。"distilbert"指的是经过蒸馏(distillation)处理的BERT模型,特点是具有较小的模型规模和更快的推理速度。
"base"和"uncased"与之前提到的意义相同。
"finetuned-sst-2"表示这个模型是在SST-2(斯坦福情感树库)数据集上进行了微调(Fine-tuning)以用于情感分类任务。
"english"表示这个模型是为英语任务预训练和微调而创建的。
5、“t5-base”
这个模型名称中的"t5"是指T5(Text-to-Text Transfer Transformer)模型,这是一种基于Transformer架构的文本生成模型。
"base"与之前提到的意义相同,表示模型的基本版本。
6、“facebook/wmt19-mu-en-1024”
这个模型名称指的是Facebook团队针对WMT19 Multilingual Translation任务训练的英语-多语言(mu)翻译模型。
"-en"表示英语作为源语言
"1024"表示模型的隐藏状态大小为1024。
7、TheBloke/Llama-2-13B-chat-GGML
"TheBloke":这部分可能是指该模型的创建者、团队或者用户名。
"Llama-2-13B":这部分可能是指模型的架构、版本或系列。它可能是从较早版本的Llama模型发展而来,或者是在Llama模型系列中的第二个版本。 "2-13B"可能指的是模型参数和规模,表明该模型具有130亿个参数。
"chat":这部分可能指出该模型是专门用于对话或聊天任务的。这种指明任务类型的信息有助于用户了解模型的适用性。
GGML":这部分可能是指模型的训练或微调框架、方法或技术。
8、stabilityai/sd-vae-ft-mse-original
“stabilityai”:这部分可能是指模型的创建者、提供者或组织名称。它可能代表一个名为 “stabilityai” 的实体或团队。
“sd-vae-ft-mse-original”:这部分可能提供了关于模型的其他关键信息。例如,“sd-vae” 可能表示变分自动编码器(VAE)的一种改进或特定类型。“ft” 可能是指模型进行了微调(fine-tuning)。“mse-original” 可能是指在模型训练过程中使用了均方误差(Mean Squared Error)作为损失函数或评价指标。
【命名目的】
旨在为用户提供有关模型的关键信息,以帮助用户做出正确的选择。
1、模型架构
名称中可能包含模型的架构或基础模型的名称,例如BERT、GPT-2、RoBERTa等。这有助于用户了解所选择模型的基本架构和背后的原理。
2、规模或版本
模型名称中可能包含描述模型规模或版本的术语,如"base"、"large"、"medium"等。这给用户一个粗略的判断模型大小和性能之间的关系,并鼓励他们选择适合自己任务需求的规模。
3、据集或任务
有些模型名称可能会提到模型训练或微调使用的数据集,以及特定的任务。这使用户能够理解模型针对特定领域或任务的训练和适用性。例如,"finetuned-sst-2"表示模型在SST-2数据集上进行了微调,适用于情感分类任务。
4、语言或领域
模型名称中可能还包含与语言或领域相关的信息。这对于用户选择适用于特定语言或特定领域的模型非常有帮助。
【模型功能解读--以pszemraj/distill-pegasus-CompMath为例】

【files and versions】

1、config
控制模型的名称、最终输出的样式、隐藏层宽度和深度、激活函数的类别等。对于初学者来说,大家一般不需要调整。这些参数都可以通过configuration类更改。
2、tokenizer(包含三个文件)
这些文件是tokenizer类生成的,或者处理的,只是处理文本,不涉及任何向量操作。tokenizer.json和config是分词的配置文件
【community】

【挑选模型基本流程】
1、访问Hugging Face模型库网站:https://huggingface.co/models
2、在搜索栏中输入与你任务相关的关键词,例如,"文本分类"、"问答"、"命名实体识别"等。你还可以输入特定的模型名称或框架(如BERT、GPT等)来查找相关模型。
3、浏览搜索结果,其中包含与你关键词匹配的模型列表。这些模型由不同作者和团队开发,具有不同的性能和特点。你可以根据模型名称、描述、语言、任务类型、模型大小等信息进行筛选和比较。
4、点击感兴趣的模型卡片,以查看有关该模型的更多详细信息,如模型说明、示例代码和结果等。
5、检查模型的适用性和性能。阅读模型的文档和示例代码,其中包括如何加载和使用模型的说明。还可以查看与模型相关的论文或技术报告,了解模型的训练数据、性能评估和使用约束等方面的详细信息。
6、考虑模型的大小和计算资源需求。较大的模型可能需要更多的计算资源和存储空间。
7、查看模型的许可证。确保所选择的模型符合你的使用需求并符合相关法律和条款。
8、根据你的需求评估和比较几个有潜力的模型,最终选择最适合你任务的模型。
- a) Hugging Face的模型文档:https://huggingface.co/docs,了解如何使用不同模型和框架,以及如何进行微调和特定任务的细节。
- b) 模型说明:https://huggingface.co/docs/transformers/index
- c) 模型库github:https://github.com/huggingface/transformers
【实践】
因为目前语言模型使用领域大多在:自然语言处理、计算机视觉、语音识别与语音合成,强化学习、数据分析与预测、自动驾驶与智能交通。
现在老师给我的任务是自己通过在电脑本地部署调用语言模型建立一个工具,确认好了我接下来要做的是:选择一个模型经过预训练,可以通过输入数学表达式进行求解、计算和推理。用于处理数学计算、问题求解和自动化证明等任务。
【知晓任务需要的基本技术--以symbolab为例】
Symbolab使用了以下自然语言处理(NLP)和数学语法分析技术
1、词法分析:
Symbolab采用词法分析来将输入的自然语言问题拆分成单词和符号。它使用分词技术将输入的文本序列分割成离散的标记,例如单词、标点符号和数学符号。
2、句法分析:
Symbolab使用句法分析来理解输入问题的结构和关系。它可以识别句子中的主语、谓语、宾语等语法成分,并构建语法树或依赖关系图来表示问题的语法结构。
3、语义分析:
Symbolab进行语义分析以理解数学问题的含义和上下文。它将输入问题中的单词和短语映射到数学概念,并处理语义关系,例如识别变量、操作符、等式等。
4、数学语法分析:
Symbolab采用数学语法分析技术来解析数学表达式和方程。它识别数学表达式中的操作符、变量和常数,并根据数学语法规则进行解析和求解。
【挑选模型】
对于数学领域的词法分析、句法分析和语义分析,一般来说,没有专门为数学开发的特定模型。这是因为数学领域的自然语言处理任务相对较少,并且与一般的自然语言处理任务有所不同。使用一些通用的自然语言处理模型来处理数学领域的文本来进行基本的句子分割、词性标注和命名实体识别等任务。根据上面的了解可能需要以以下关键词进行搜索:
- Symbolic math models: 符号数学模型
- Calculus models: 微积分模型
- Differential equations models: 微分方程模型
- Mathematical optimization models: 数学优化模型
- Mathematical theorem provers: 数学定理证明器
- Step-by-step problem solving models: 逐步问题解决模型
- Explainable AI models: 可解释的 AI 模型
- Tutoring models: 辅导模型
- Educational models for math problem solving: 数学问题解决的教育模型
- Interactive problem-solving models: 交互式问题解决模型

选择几个关键词后直接在搜索栏搜索(左边勾选需要的类型),结合模型描述、关键词高亮、README.md文件选出了:
1、lschlessinger/bert-finetuned-math-prob-classification:
https://huggingface.co/lschlessinger/bert-finetuned-math-prob-classification
这是一个在competition_math数据集的一部分上对bert-base-uncased进行微调的模型。具体而言,它是一个在问题文本上进行多类多标签训练的模型。这里使用的问题类型(标签)包括"Counting & Probability"(计数与概率)、"Prealgebra"(初代数)、"Algebra"(代数)、"Number Theory"(数论)、"Geometry"(几何)、"Intermediate Algebra"(中级代数)和"Precalculus"(预微积分)。
模型描述
有关详细信息,请参阅bert-base-uncased模型。唯一的架构修改是在分类头部。这里使用了7个类别。
使用目的和限制
此模型仅用于演示目的。问题类型数据为英文,并包含许多LaTeX标记。
训练和评估数据
训练和评估输入数据来自competition_math数据集的问题字段。目标数据来自类型字段。
训练过程
训练超参数
在训练过程中使用了以下超参数:
learningrate:5e-05
trainbatchsize:8
evalbatchsize:8
seed:42
optimizer:Adam,betas=(0.9,0.999),epsilon=1e-08
lrschedulertype:linear
numepochs:3.0
2、AnReu/math_albert:
https://huggingface.co/AnReu/math_albert
模型描述:



大意是说“Math-aware ALBERT是一个针对ARQMath 3的最佳基础模型的代码库。它是从ALBERT-base-v2初始化的,并在Math StackExchange上进行了三个不同阶段的进一步预训练。我们还向分词器添加了更多LaTeX标记,以实现对数学公式更好的分词。这个模型还没有在特定任务上进行微调。如果您正在寻找已经微调过的模型,请参考此页面:AnReu/albert-for-arqmath-3。
如果您正在寻找一个数学预训练的BERT模型:请查看我们的AnReu/math_pretrained_bert,该模型的训练方式与此模型相同。”,那么就要去它说的模型。

3、AnReu/math_pretrained_bert:
https://huggingface.co/AnReu/math_pretrained_bert#math-aware-bert
据了解后得知,该模型是从BERT-base-cased权重初始化,并在三个阶段使用不同的数据进行进一步预训练,同时进行掩码语言建模任务。此外,我们还向分词器中添加了约500个LaTeX标记,以更好地处理数学公式。
下图说明了三个预训练阶段:首先,我们只对数学公式进行训练。NSP分类器预测哪个部分包含公式的左手边,哪个部分包含右手边。通过这种方式,我们建模了公式之间的一致性。第二阶段建模了公式与句子之间的一致性,即公式是原始文档中的第一个部分还是自然语言部分在前。最后,我们添加了默认的句子之间的一致性阶段,这是ALBERT/BERT的默认行为。在这个阶段,句子通过句子分隔符进行划分。请注意,在这三个阶段中,我们没有像BERT的NSP任务通常那样使用来自不同文档的句子,而是仅交换两个连续的序列(公式、句子等)。这是ALBERT的SOP任务的默认行为。它与我们的ALBERT模型完全相同,而ALBERT模型是ARQMath 3(2022)中表现最好的模型。关于我们的ALBERT模型的详细信息可以在这里找到。
用法:
您可以使用这个模型在您心目中的任何数学感知任务上进行进一步的微调,例如分类、问答等。请注意,该存储库中的模型仅经过预训练,而没有进行微调。

但是从下载次数上看,2比3要多
4、jmeadows17/MathT5-large:
https://huggingface.co/jmeadows17/MathT5-large
MathT5-large是基于FLAN-T5-large进行细调的版本,它在15K个(使用LaTeX表示的)合成数学推导中进行了25个epochs的训练,每个推导包含4到10个方程式,这些推导是使用符号求解器(SymPy)生成的。在ROUGE、BLEU、BLEURT和GLEU得分上,它在推导生成任务的少样本表现上超过了GPT-4和ChatGPT,并显示出一定的泛化能力。它在155个物理符号上进行了训练,但对于词汇表之外的符号可能表现不佳。
论文:https://arxiv.org/abs/2307.09998
5、invokerliang/MWP-BERT-en:
https://huggingface.co/invokerliang/MWP-BERT-en

MWP-BERT的预训练模型,旨在解决数学应用问题,即数学课本上常见的需要转化为数学计算的问题。这些问题通常需要解读问题陈述,提取出关键信息,并将其转化为可处理的数学表达式。通过在大规模数学问题数据集上进行预训练来学习数学领域的知识和数值推理能力。
模型进行了预训练和使用数值增强技术
似乎可以用
6、pszemraj/distill-pegasus-CompMath:
https://huggingface.co/pszemraj/distill-pegasus-CompMath
针对计算数学(Computational Mathematics)领域或与数学计算相关的任务进行了专门改进或微调的PEGASUS模型。它可能包含对数学公式、数学问题、数学推理等等进行建模和生成的能力。
似乎比较符合
7、fnlp/moss-003-sft-data:
https://huggingface.co/datasets/fnlp/moss-003-sft-data
https://github.com/OpenLMLab/MOSS/tree/main
偶然发现了moss,看了下详情里面有简单的数学解析代码,可以用作参考。
【待补充】
【参考资料】
[1] 【计算机视觉 | 自然语言处理】Hugging Face 超详细介绍和使用教程:https://blog.csdn.net/wzk4869/article/details/130670248
[2] Huggingface 超详细介绍:https://zhuanlan.zhihu.com/p/53jie5100411
[3] Huggingface的介绍,使用(CSDN最强Huggingface入门手册):https://blog.csdn.net/a1920993165/article/details/128082968
[4] 入门huggingface,简单了解如何调用BERT模型:
- a) HuggingFace-transformers系列的介绍以及在下游任务中的使用:https://www.cnblogs.com/dongxiong/p/12763923.html
- b) 官方教程:https://huggingface.co/docs/transformers/model_doc/bert
- c) 论文参考:https://arxiv.org/abs/1706.03762
- d) 论文笔记:
- -Transformer模型结构(一)attention结构详解:https://zhuanlan.zhihu.com/p/526155983
- -Transformer模型结构(二)模型详细结构:https://zhuanlan.zhihu.com/p/526694027
-
-原来你是这样的-BERT大解析:https://zhuanlan.zhihu.com/p/528867839
[5] Hugging Face 模型下载方法一览。:https://blog.csdn.net/YI_SHU_JIA/article/details/127490591
[6] 如何下载Hugging Face 模型(pytorch_model.bin, config.json, vocab.txt)以及如何在local使用:,https://blog.csdn.net/season77us/article/details/104311195
【本文提到的部分术语】
1、视觉问答(Visual Question Answering,VQA)
是一种人工智能任务,旨在让计算机能够理解并回答与图像相关的问题。VQA结合了计算机视觉和自然语言处理的技术,使计算机能够根据给定的图像和问题,输出相应的文字答案。
在视觉问答任务中,系统会接收一张图像和一个关于该图像的问题作为输入。问题可以是关于图像中物体的属性、位置、数量,或是要求推理、比较或推断等。系统通过理解图像内容和问题,将其转化为一个可回答的形式,并生成相应的文字答案。
视觉问答涉及到多个领域,包括计算机视觉、自然语言处理、图像理解和推理等。它有广泛的应用场景,如智能助理、图像搜索、虚拟现实和增强现实等领域。通过视觉问答,计算机可以与人进行自然而直接的交互,提供对图像内容的理解和解释。
2、文档问答(Document Question Answering)
是一种人工智能任务,旨在让计算机能够根据给定的文档和问题,从文档中提取信息和理解内容,并生成准确的答案。
在文档问答任务中,系统会接收一个包含文本内容的文档和一个问题作为输入。问题通常是关于文档中某个特定信息、相关概念或细节的询问。系统需要通过自然语言处理和文本理解技术,对文档进行理解、搜索和推断,以找到相关的信息并生成适当的答案。
文档问答任务需要解决一些挑战,例如理解多义词、上下文依赖、解决模棱两可的问题和处理长文本等。它涉及到信息检索、自然语言处理、机器学习和知识表示等多个领域的技术。
文档问答在很多领域有着广泛的应用。例如,在文档搜索引擎中,用户可以通过提问相关问题来获取更精确的搜索结果。在教育领域,文档问答可以帮助学生获取特定领域的知识和解答问题。在企业领域,文档问答可以用于知识管理和自动化客户服务等方面。通过文档问答技术,计算机可以处理和回答大量的文本信息,为用户提供准确、高效的答案和解决方案。
3、图机器学习(Graph Machine Learning)
是机器学习领域的一个分支,专注于处理和分析图结构数据的算法和方法。图结构数据是由节点和节点之间的关系(边)组成的网络数据,可以用来表示各种实际场景中的复杂关系和交互。
传统的机器学习方法通常基于向量或矩阵表示数据,而图机器学习将重点放在图形上的节点和边上,利用节点和边的关系信息进行建模和学习。它结合了图论、统计学、机器学习和深度学习等技术,旨在挖掘图结构数据中的模式、特征和知识,并用于节点分类、链接预测、图聚类、图生成等任务。
图机器学习有多种方法和算法,包括基于图的特征提取、图卷积网络(Graph Convolutional Networks)、图注意力网络(Graph Attention Networks)、图神经网络(Graph Neural Networks)等。这些方法能够捕捉节点之间的局部和全局依赖关系,从而对图数据进行建模和预测。
图机器学习在许多领域有重要的应用,包括社交网络分析、推荐系统、化学分子分析、生物信息学、交通网络分析等。通过图机器学习,我们可以揭示图数据中隐藏的模式和结构,从而提取有用的信息和知识,为实际问题的解决提供更全面的理解和预测能力。
4、数学语法分析技术
数学语法分析技术,也称为数学句法分析技术,是一种用于分析和解析数学语句结构的技术。它将数学表达式或数学语句作为输入,并使用算法和规则来识别语法结构、分解组成要素以及构建语法树。
可以应用在数学教育、自动化证明、计算机代数系统等。可以帮助理解数学句子的结构,进行语法验证和纠错,并支持自动化的数学推导和计算。在数学教育中,语法分析技术可以用于解析学生的数学公式或算式,帮助掌握数学表达式的语法规则,帮助学生纠正语法错误。在自动化证明中,数学语法分析技术能够分析、验证和生成数学证明的语法结构,提高证明的有效性和正确性。在计算机代数系统中,该技术用于解析和操作数学表达式,支持数学符号计算和算法的实现。
数学语法分析技术通常涉及到形式语言理论、上下文无关文法、语法树生成算法和语法规则的设计。常用的技术方法包括自下而上的语法分析、自上而下的递归下降分析、图结构分析等。
5、计算机代数系统(Computer Algebra System,缩写为CAS)
是一种软件工具或系统,用于执行符号计算和数学表达式处理。CAS可以处理符号形式的数学对象(如变量、函数、方程、多项式等),并提供了一系列功能和算法来进行符号计算、代数操作、求解方程、微积分、离散数学等数学计算任务。
CAS能够解决一些复杂的数学问题,包括自动化证明、符号推导、数值计算的精确化等。它通过内部的算法和数据结构表示和操作数学对象,并提供了用户友好的界面或编程接口,使用户能够方便地进行符号计算和数学研究。
CAS旨在提供一种高级的数学计算环境,使用户能够进行符号计算而无需手动进行代数运算。CAS系统通常具有丰富的数学函数和算法库,可以支持代数、微积分、线性代数、离散数学等多个领域的计算。
【延伸问答】
1、Hugging Face 和 Langchain 的区别
Hugging Face:
Hugging Face 的主要经营领域是自然语言处理(NLP)。他们专注于开发和维护用于处理和理解文本数据的工具、模型和库。其中最著名的是他们的Transformers库,该库包含了各种预训练的语言模型,并提供了训练、微调和推理这些模型的工具和接口。Hugging Face 的库被广泛应用于各种 NLP 任务,如文本分类、情感分析、机器翻译、问答系统等。
Langchain:
Langchain 是一家专注于语言学习和跨语言交流领域的创业公司。他们的主要经营领域包括开发语言学习技术、教育解决方案和跨语言交流工具。Langchain 的目标是利用人工智能和自然语言处理技术改善语言学习的效果,并打破语言壁垒,促进不同语言之间的交流和理解。他们提供的平台和工具可用于个人学习者、语言教育机构和企业等领域。
总结起来,Hugging Face 主要集中在开发 NLP 模型和工具的领域,而 Langchain 则专注于语言学习和跨语言交流的应用。