一、关于数据的准备及项目背景
Notion提供了团队管理的功能,方便团队成员进行在线协作办公,提高交互效率,notion上面的数据可能包括项目的数据,进度管理的数据,企业服务的数据等等,这里使用了从notion网站(https://www.notion.so)导出的一些样例数据供本项目使用大模型框架LangChain来调用。下面展示的是样例数据中的一些关于office的数据:

本项目是以对话的方式来获取notion上面的数据,这是一件有价值的事情,这是因为随着时间的推移,notion上面的数据会越来越多,那么这时直接去notion上查询或者定位信息是一个很费时费力的过程,如果我们使用一个简单的接口,以自然语言的方式通过LangChain以模型驱动为基础来与企业私有数据进行交互,这对提升团队协作效率等很有帮助。
二、项目构建及简单演示
为了测试方便,可以使用streamlit来搭建一个简单的界面:
import streamlit as st
from streamlit_chat import message
使用LangChain访问私有数据,这里的VectorDBQAWithSourcesChain可以看做是一个use case,譬如与数据库进行交互,或者与一个vector space进行交互等:
from langchain import OpenAI
from langchain.chains import VectorDBQAWithSourcesChain

使用向量化检索工具faiss,以大模型为驱动通过LangChain框架来查询存储在notion上的私有数据,在下面的方法from_llm中使用的store就是基于faiss构建的向量索引库:

当用户输入信息后,返回查询结果:

以下是演示结果,当用户输入以下信息:
How long is the probation period?
LangChain访问数据并与模型交互后返回了相应的查询结果和所引用的notion page文件:

根据演示界面提到的引用文件,打开后可以发现有相关的信息如下:

三、关于LangChain使用进一步分析
除了上面提到的使用VectorDBQAWithSourcesChain来调用LangChain框架,也可以使用下面的方式:

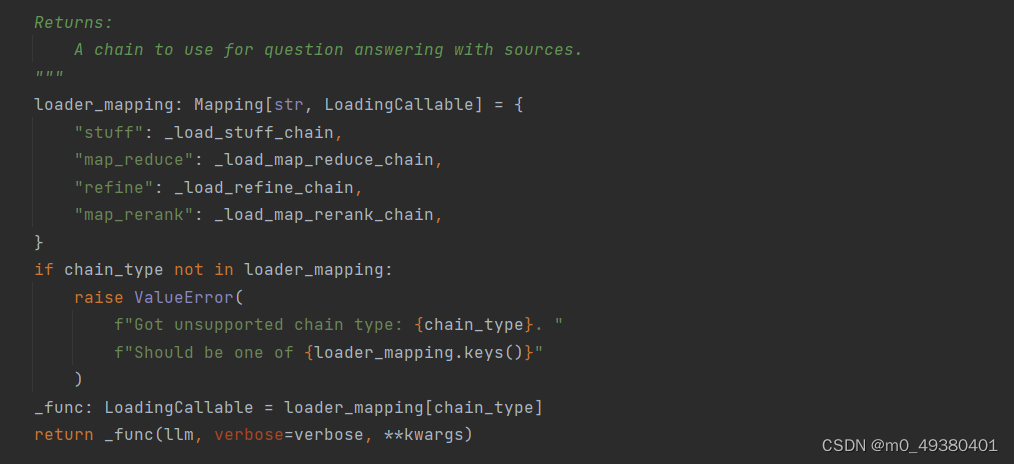
首先根据chain type构建一个chain,主要参数包括语言模型,chain type,这里使用chain type的主要原因在于跟本地私有数据进行交互时,会涉及到数据规模的问题和处理速度的问题,相应的解决方案是:
-map reduce(数据切分,适用于大数据文件)
-rerank(选取confidence最高的那个文件)
-stuff(一次性加载所有数据)
-refine(把文件切成多个片段时,分析第二个片段时会结合第一个片段的内容)

所以在调用方法load_qa_with_sources_chain的内部,我们可以看到相关的处理逻辑:









![[Docker] Windows 下基于WSL2 安装](https://img-blog.csdnimg.cn/66917c62f683477b97962f7035b7d1ea.png#pic_center)