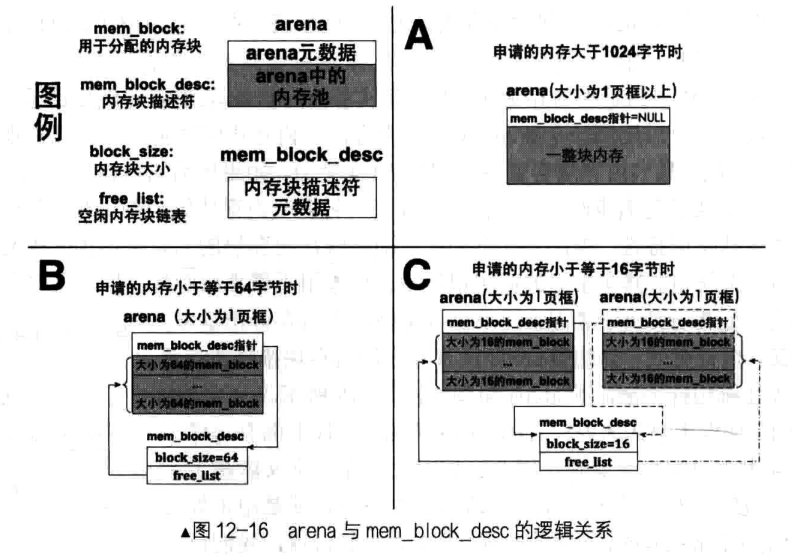
鲲鹏处理器片上系统架构
- 一、鲲鹏处理器片上系统与Taishan处理器内核架构
- 1. 鲲鹏处理器片上系统概况
- a. 鲲鹏处理器片上系统与鲲鹏芯片家族
- b. 鲲鹏920处理器片上系统的组成部件
- c. 鲲鹏920处理器片上系统的特征
- d. 鲲鹏920处理器片上系统的逻辑结构
- 2. Taishan V110 处理器内核微架构
- a. Taishan V110 处理器内核的特征
- b. Taishan V110 处理器内核的功能结构
- 3. 鲲鹏920处理器片上系统的逻辑结构
- a. 处理器内核集群
- b. I/O集群
- c. 超级内核集群
- d. 超级I/O集群
- e. 鲲鹏920系统的部件互联
- 4. 鲲鹏920处理器片上系统的内存存储系统
- a. 鲲鹏920处理器存储系统的层次结构
- b. 鲲鹏920处理器的片上系统的L3 Cache
- c. 鲲鹏920处理器的片上系统的主存系统
- d. 鲲鹏920处理器的片上系统的DDR控制器
- e. 鲲鹏920处理器片上系统的NUMA架构
- f. 鲲鹏920处理器的片上系统的地址映射与变换
处理器体系结构,是一个偏底层的内容,但这是任一计算机系统的底层。
系统的性能、生态和功能很大程度上都依赖于计算机系统底层——处理器体系结构。任何一个系统程序员、固件设计者、应用程序员 甚至 服务器管理员,如果想要充分利用现代高性能处理器的硬件性能、进行高效的软件运行,都必须理解处理器体系结构。

一、鲲鹏处理器片上系统与Taishan处理器内核架构
1. 鲲鹏处理器片上系统概况

a. 鲲鹏处理器片上系统与鲲鹏芯片家族
鲲鹏处理器片上系统(Kunpeng 920) 是华为公司基于ARM架构研发的企业级处理器产品,主要应用于“计算、存储、传输、管理、人工智能”等五个应用领域。鲲鹏芯片家族是华为海思自研的芯片家族的总称,其中包括鲲鹏系列处理器芯片、昇腾人工智能芯片、固态硬盘控制芯片、智能融合网络芯片及智能管理芯片等。这个家族中的每个成员都有各自的特点和功能,共同为计算、存储、传输、管理和人工智能应用提供支持。
总结来说,鲲鹏处理器片上系统是鲲鹏芯片家族中的一个重要成员,而鲲鹏芯片家族则是华为在多个领域自主研发的芯片产品的总称。
b. 鲲鹏920处理器片上系统的组成部件

c. 鲲鹏920处理器片上系统的特征
鲲鹏920处理器片上系统具有以下特征:
- 基于ARMv8.2架构设计,支持64位多核服务器处理器。
- 采用可扩展向量扩展(SVE)技术,能够在低功耗的情况下提供强大的性能和并行计算能力。
- 支持多种互连协议,包括CCIX和PCIe等,适用于不同类型的服务器系统。
- 集成16个A76处理器核心,主频最高可达2.6GHz,每个核心均可支持多线程。
- 采用创新的L3缓存技术,有效提升数据传输速率。
- 支持高达8通道内存控制器,每个通道可支持DDRx内存。
d. 鲲鹏920处理器片上系统的逻辑结构
鲲鹏920处理器片上系统的逻辑结构主要包括以下几个部分:
- CPU:鲲鹏920处理器片上系统由两个CPU DIE(硅片上独立执行特定任务的独立单元)组成,每个CPU DIE包含4个Cluster(计算簇),每个Cluster包含2个Core(核心)。因此,整个处理器包含8个Core。
- Cache:每个Core都配备了L1和L2级Cache,L1 Cache又分为指令Cache和数据Cache,L2 Cache是共享的。此外,所有Core共享L3级Cache。
- DDR控制器:鲲鹏920处理器片上系统配备了8个DDR4通道,用于内存存储和数据访问。
- I/O子系统:鲲鹏920的I/O子系统通过IO DIE进行扩展,支持多种互连协议,包括CCIX和PCIe等,适用于不同类型的服务器系统。同时,鲲鹏处理器还支持基于PCle 4.0的设备扩展,可支持网卡、GPU等板卡。
- 中断子系统:鲲鹏920的中断子系统在兼容ARM GIC规范的基础上,实现了线中断、消息中断支持。
2. Taishan V110 处理器内核微架构
a. Taishan V110 处理器内核的特征
Taishan V110 是一种基于 ARM 架构的处理器内核微架构。它是由华为公司开发的,主要用于其服务器产品。
具体来说,Taishan V110 处理器内核是基于 ARM v8.2 架构的,支持 64 位多核服务器处理器。它采用了可扩展向量扩展(SVE)技术,可以在低功耗的情况下提供强大的性能和并行计算能力。
Taishan V110 处理器内核微架构包括多个核心,每个核心可以支持多线程。它还采用了创新的 L3 缓存技术,以有效提升数据传输速率。此外,该处理器内核还支持高达 8 通道内存控制器,每个通道可以支持 DDRx 内存。
Taishan V110 处理器内核微架构是一种高性能、低功耗的 ARM 服务器处理器内核,适用于多种计算和数据处理应用。
b. Taishan V110 处理器内核的功能结构
Taishan V110 处理器内核的功能结构包括以下部分:
- 取指(Instruction Fetch)部件:负责从 L1 I Cache 取出指令并向指令译码部件发送指令,每个周期最多发送 4 条指令。支持动态分支预测和静态分支预测。集成了 64KB 的 4 路组相联 L1 I Cache,Cache 行大小为 64B,其数据 RAM 和标记 RAM 每 8 个二进制位含 1 位奇偶校验保护位。
> 取指(Instruction Fetch)部件是计算机处理器中的一个关键部分,负责从一级指令缓存(L1 I Cache)中取出指令,并将这些指令发送到指令译码部件。每个周期,该部件最多可以发送4条指令。
- 指令译码(Instruction Decode)部件:负责接收来自取指部件的指令,并进行指令解码,每个周期最多发送 4 条解码后的指令。
-
指令分发(Instruction Dispatch)部件:负责将解码后的指令发送到各个执行单元,每个周期最多发送 4 条指令。
-
整数执行(Integer Execute)部件:负责执行整数运算指令,包括算术运算、逻辑运算等。
-
加载/存储单元(Load/Store Unit):负责数据在寄存器和内存之间的传输,包括加载和存储指令的执行。
-
第二级存储系统(L2 Memory System):负责管理 L2 Cache,包括数据的读取和写入。
-
增强的 SIMD 与浮点运算单元(Advanced SIMD and Floating Point Unit):负责执行 SIMD 和浮点运算指令。
-
通用中断控制器 CPU 接口(GIC CPU Interface):负责与通用中断控制器进行通信,处理来自外部设备的中断请求。
-
通用定时器(Generic Timer):负责计时和定时操作。
-
PMU 及调试与跟踪部件(Debug and Trace):负责性能监控、调试和跟踪操作。
以上是 Taishan V110 处理器内核的主要功能结构。处理器内核的各个部件相互协作,共同完成处理器的运算和控制任务。
3. 鲲鹏920处理器片上系统的逻辑结构
a. 处理器内核集群
鲲鹏920处理器片上系统的逻辑结构中,处理器内核集群是指多个处理器内核的集合,这些内核通过共享缓存和互连通道相互通信和协作。
在鲲鹏920处理器片上系统中,内核集群是处理器内核之间的逻辑组合方式,每个集群由4个核心组成,每个核心都支持多线程。这种内核集群的设计有助于提高处理器的并行处理能力和整体性能。
通过内核集群的设计,处理器可以更好地平衡负载和处理任务,同时保持高效率和低功耗。这种逻辑结构也有助于提高处理器的响应速度和吞吐量,从而满足不同应用场景的需求。
鲲鹏920处理器片上系统的内核集群是处理器内核之间的逻辑组合方式,它有助于提高处理器的并行处理能力和整体性能,适用于各种高性能计算和数据处理应用。
b. I/O集群
在鲲鹏920处理器片上系统中,I/O集群是负责处理和管理I/O(输入/输出) 请求的逻辑组件。I/O集群通过与I/O子系统进行通信,实现对输入/输出设备的控制和管理。
I/O集群通常包括以下功能:
1. 设备驱动程序:I/O集群中包含多个设备驱动程序,用于与不同类型的I/O设备进行通信。这些驱动程序负责与设备的硬件接口进行交互,实现数据的传输和控制。
2. 中断处理:I/O集群负责处理来自I/O设备的中断请求。当设备完成一项任务或发生特定事件时,会向处理器发送中断请求。I/O集群接收这些请求并通知操作系统进行处理。
3. 数据传输管理:I/O集群负责数据的传输和管理。它可以将数据从I/O设备读取到处理器,或将数据从处理器发送到I/O设备。I/O集群还支持数据缓冲和数据校验等功能,以确保数据的准确性和完整性。
4. 虚拟化支持:I/O集群还支持虚拟化技术,可以同时与多个虚拟机进行通信。通过虚拟化技术,多个虚拟机可以共享有限的物理资源,并实现高效的I/O操作。
通过I/O集群的设计,处理器可以更好地管理和控制I/O设备的操作,从而提高系统的整体性能和可靠性。同时,I/O集群还可以简化设备驱动程序的开发和管理工作,降低系统维护的复杂度。
c. 超级内核集群
超级内核集群(Super Kernel Cluster) 是鲲鹏920处理器片上系统的一个核心组件,它包含了多个内核集群和I/O集群,用于实现高性能计算和数据处理。
每个超级内核集群包含6个内核集群、2个I/O集群和4个DDR控制器。每个内核集群包含4个核心,每个核心支持多线程。这样的设计有助于提高处理器的并行处理能力和整体性能。
超级内核集群的每个内核集群都集成了L3 Cache,分为L3 Cache TAG和L3 Cache DATA两部分。L3 Cache TAG集成在每个内核集群中,用于降低监听延迟,L3 Cache DATA则直接连接片上总线。这样的设计可以提高数据传输的效率和准确性。
此外,超级内核集群还配置了一个通用中断控制器分发器(GICD) 模块,兼容ARM的GICv4规范,用于处理多芯片系统Cache一致性协议。
通过超级内核集群的设计,鲲鹏920处理器片上系统可以更好地平衡负载和处理任务,同时保持高效率和低功耗,适用于各种高性能计算和数据处理应用。
d. 超级I/O集群
超级I/O集群(Super I/O Cluster) 是鲲鹏920处理器片上系统的一个组件,它负责处理和管理I/O(输入/输出)请求,并与外部设备进行通信。
超级I/O集群通过与I/O子系统进行通信,实现对输入/输出设备的控制和管理。它包含多个I/O集群,每个I/O集群包含多个设备驱动程序,用于与不同类型的I/O设备进行通信。
超级I/O集群还负责处理来自I/O设备的中断请求。当设备完成一项任务或发生特定事件时,会向处理器发送中断请求。超级I/O集群接收这些请求并通知操作系统进行处理。
此外,超级I/O集群还支持虚拟化技术,可以同时与多个虚拟机进行通信。通过虚拟化技术,多个虚拟机可以共享有限的物理资源,并实现高效的I/O操作。
通过超级I/O集群的设计,处理器可以更好地管理和控制I/O设备的操作,从而提高系统的整体性能和可靠性。同时,超级I/O集群还可以简化设备驱动程序的开发和管理工作,降低系统维护的复杂度。
e. 鲲鹏920系统的部件互联
鲲鹏920系统的部件主要通过AMBA(Advanced Microcontroller Bus Architecture)总线进行互联。具体来说,主要的部件包括两个CPU DIE、一个IO DIE,以及共8组DDR4 channel。这些部件之间的互联关系如下:
1. 两个CPU DIE之间通过系统总线进行互联。
2. CPU DIE和IO DIE之间通过IO总线进行互联。
3. 8组DDR4 channel之间通过内存总线进行互联。
这样的互联方式可以满足处理器在高性能计算和数据处理方面的需求。同时,为了方便软件编程,鲲鹏处理器内部的高速设备也基于PCle,且可以通过PCle的配置空间进行配置。
4. 鲲鹏920处理器片上系统的内存存储系统
a. 鲲鹏920处理器存储系统的层次结构
鲲鹏920处理器存储系统的层次结构可以分为四层,从下到上分别是:
- DDR内存子系统:该层是最低层,提供64位内存接口,支持8通道DDR4内存,容量可以根据实际需求进行扩展。
- L3缓存子系统:该层为每个CPU核心提供独立的L3缓存,容量为64KB,访问延时为3个时钟周期。
- L2缓存子系统:该层由两个L2缓存模块组成,每个模块的容量为32KB,访问延时为15个时钟周期。
- L1缓存子系统:该层包括指令、数据和分支指令,每个CPU核心都拥有独立的L1指令和数据缓存,容量为64KB,访问延时为1个时钟周期。
通过这种层次化的设计,可以显著减少内存访问延时,提高处理器的性能。同时,这种层次结构也使得处理器的存储系统更加灵活,可以根据不同的应用需求进行定制和扩展。
b. 鲲鹏920处理器的片上系统的L3 Cache
鲲鹏920处理器的片上系统的L3 Cache是处理器内核的共享缓存,它为每个CPU核心提供共享访问。L3 Cache的容量非常大,可以达到64KB,这意味着处理器内核可以在一个时钟周期内从L3 Cache中获取数据,这对于高性能计算和数据处理应用非常重要。
同时,L3 Cache还被分成了两个独立的子系统:L3 Tag和L3 Data。L3 Tag负责存储虚拟地址到物理地址的映射关系,而L3 Data则负责存储数据。这种设计可以有效地提高数据访问的速度和准确性。
鲲鹏920处理器的片上系统的L3Cache是处理器内核的重要组件之一,它具有大容量、高性能的特点,可以满足各种高性能计算和数据处理应用的需求。
c. 鲲鹏920处理器的片上系统的主存系统
鲲鹏920处理器的片上系统的主存系统包括DDR4内存条和L3缓存。
首先,DDR4内存条是鲲鹏920处理器片上系统的基本存储器,它直接与处理器内核相连,并被设计成可以在一个时钟周期内访问一次。DDR4内存条的容量可以根据实际需求进行选择,最大容量没有明确限制。
其次,L3缓存是鲲鹏920处理器片上系统的核心存储器,它是处理器内核的共享缓存,被设计成可以在一个时钟周期内访问一次。L3缓存的容量非常大,可以达到64MB,可以满足高性能计算和数据处理应用的需求。
同时,鲲鹏920处理器的片上系统还采用了14纳米工艺,拥有64个CPU核心,支持SMT超线程技术,最高主频可达2.6GHz。另外,鲲鹏920还配备了32MB的二级缓存和48个PCIe 4.0通道,可支持高速数据传输和流畅的数据处理。
总之,鲲鹏920处理器的片上系统的主存系统具有大容量、高性能的特点,可以满足各种高性能计算和数据处理应用的需求。
d. 鲲鹏920处理器的片上系统的DDR控制器
鲲鹏920处理器的片上系统的DDR控制器是处理器与DDR4内存条之间的接口。这个控制器可以支持8个DDR4通道,每个通道的最大速率是2.6GHz,最大容量是1TB。这种设计可以满足高性能计算和数据处理应用的需求,同时也为系统提供了更大的内存空间。
通过DDR控制器,处理器内核可以与DDR4内存条进行高速数据交换,实现快速的数据读写操作。这种设计可以显著提高系统的整体性能和数据处理能力。
总之,鲲鹏920处理器的片上系统的DDR控制器是处理器与内存之间的关键接口,它支持大容量、高性能的DDR4内存条,可以满足各种高性能计算和数据处理应用的需求。
e. 鲲鹏920处理器片上系统的NUMA架构
鲲鹏920处理器片上系统的NUMA(Non-Uniform Memory Access) 架构是一种内存管理架构,它具有非统一内存访问的特点。在NUMA架构中,内存被分为多个区域,每个区域称为一个节点,每个节点都有其自己的内存控制器和处理器。
在鲲鹏920处理器片上系统中,NUMA架构被分为四个层次:处理器层、本地节点层、home节点层和远程节点层。
- 处理器层:这是最底层,包含单个物理核,称为处理器层。
- 本地节点层:对于某个节点中的所有处理器,此节点称为本地节点。
- home节点层:与本地节点相邻的节点称为home节点。
- 远程节点层:非本地节点或邻居节点的节点,称为远程节点。
在NUMA架构中,访问本地节点的内存比访问远程节点的内存更快,因此,在执行内存访问操作时,系统会自动将数据分配到最近的节点。这种内存管理方式可以提高内存访问速度和系统的整体性能。
鲲鹏920处理器片上系统的NUMA架构是一种非统一内存访问的架构,它可以提高内存访问速度和系统的整体性能,适用于各种高性能计算和数据处理应用。
f. 鲲鹏920处理器的片上系统的地址映射与变换
鲲鹏920处理器的片上系统的地址映射与变换主要涉及虚拟地址到物理地址的转换。这个过程是通过页表机制实现的。
具体来说,地址映射过程包括以下几个步骤:
- 地址转换:首先,CPU内核会根据虚拟地址计算出对应的物理地址。这个过程涉及到页表机制,其中页表是用来保存虚拟地址和物理地址映射关系的数据结构。
- 访问内存:然后,CPU内核将计算出的物理地址发送给内存控制器,通过内存控制器访问相应的内存单元。
- 数据传输:内存控制器根据物理地址读取或写入数据,实现数据在CPU内核和内存之间的传输。
在这个过程中,页表机制是实现地址映射的核心。页表机制将虚拟地址和物理地址建立了映射关系,使得CPU内核可以通过虚拟地址访问内存。同时,由于这种映射关系是动态变化的,因此系统可以根据实际需求动态调整内存的映射关系,以满足不同的应用需求。
鲲鹏920处理器的片上系统的地址映射与变换是通过页表机制实现的,这个过程实现了虚拟地址到物理地址的转换,使得CPU内核可以通过虚拟地址访问内存。这种机制提高了内存访问的灵活性和效率,适用于各种高性能计算和数据处理应用。
参考:《鲲鹏处理器 架构与编程》(戴志涛 刘建培)
《Kunpeng处理器组织和芯片架构详解》(华为云社区-Jack20)
《Taishan处理器内核架构》
鲲鹏社区:完善的Kupeng开发者社区&论坛
海思官网:官方链接地址