经过项目的验证测试以及初步商用化,本篇将进一步讲解greenplum外部表的实现原理,包括设计原则、交互协议与实现流程。gpfdist工具的简介与使用见回顾greenplum gpfdist工具。
1 设计原则
greenplum作为分布式分析型数据库,其每个节点都是独立的计算单元,因此充分利用多节点的优势进行并发高效加载是gpfdist设计的首要目标。
1.1 将耗时任务并行化
如果master节点进行copy操作时并对其进行性能分析,会发现绝大部分的时间都花费在分隔符的判定和行列数据解析上。随着segment数目的增多,master节点解析数据的速度会成为明显的单点瓶颈;虽然master将100%的CPU时间花在数据解析上,但是所有的segment都在等待master分发数据。对此,gpfdist采用的策略是“有难同当”,即所有的节点做同样的事情:数据解析,分发和持久化。为达这一目的,gpfdist首要工作是对文件进行高效切分。
1.2 最小化单节点瓶颈
当所有的源数据都保存在同一个文件中时,文件的读取速度便成为制约性能的关键因素。为尽可能保证保证读取速度,gpfdist采用的单进程数据读取模式,避免随机磁盘访问导致的性能下降。此外,gpfdist对文件中行边界进行准确切分,以保证每个segment节点收到完整的数据行。gpfdist并不解析文件中的每一行,而是以文件块为单位进行查找。在读取一个数据块之后,gpfdist只需找到最后一个行分隔符即可,它不知道也不关心这个数据块中有多少行数据,进一步解析是每个segment的职责。gpfdist准备好数据以后,将其发送给各个segment节点。为保证性能,gpfdist采用libevent的单进程程模式避免进程切换所带来的开销,进而最大限度地利用单个CPU资源。
1.3 支持水平扩展
gpfdist利用单个CPU读取单个文件文本,通常情况是gpfdist将单个CPU资源打满,但对整个ETL服务器而言仍然有很多空闲资源。gpfdist可以通过多进程的方式,充分利用整个ETL服务器的物理资源。gpfdist进程之间是独立,因此也完全可以运行在多个ETL服务器上。需要注意的是这种多进程方式有一个前提,即在加载前要预先将数据切分成多个文件文本,同事为了保证加载效率。文件不应该多余系统中磁盘的数目,并尽量保证不同文件放在不同的物理硬盘上。
2 gpfdist协议
greenplum中gpfdist外部表由两部分组成,一部分是外部表的gpfdist服务器,另一部分是与greenplum在一起的gpfdist外部表模块。二者之间通过gpfdist协议通信,而gpfdist协议是HTTP的扩展协议。
gpfdist外部表的工作方式是外部的gpfdist进程向segment节点发送数据或者是从segment节点接收数据。gpfdist进程与数据库间通过HTTP方式进行通信,外部表的gpfdist进程是HTTP服务端,segment是HTTP的客户端。
简答来说,对制度的外部表执行select操作时,gpfdist会从磁盘读取文件,将其内容分发到各个segment,从而实现数据并行加载,对只写外部表执行insert操作时,gpfdist将segment分发的数据保存至相应的文件。此外,gpfdist还支持压缩文件(gzip,bzip2)。
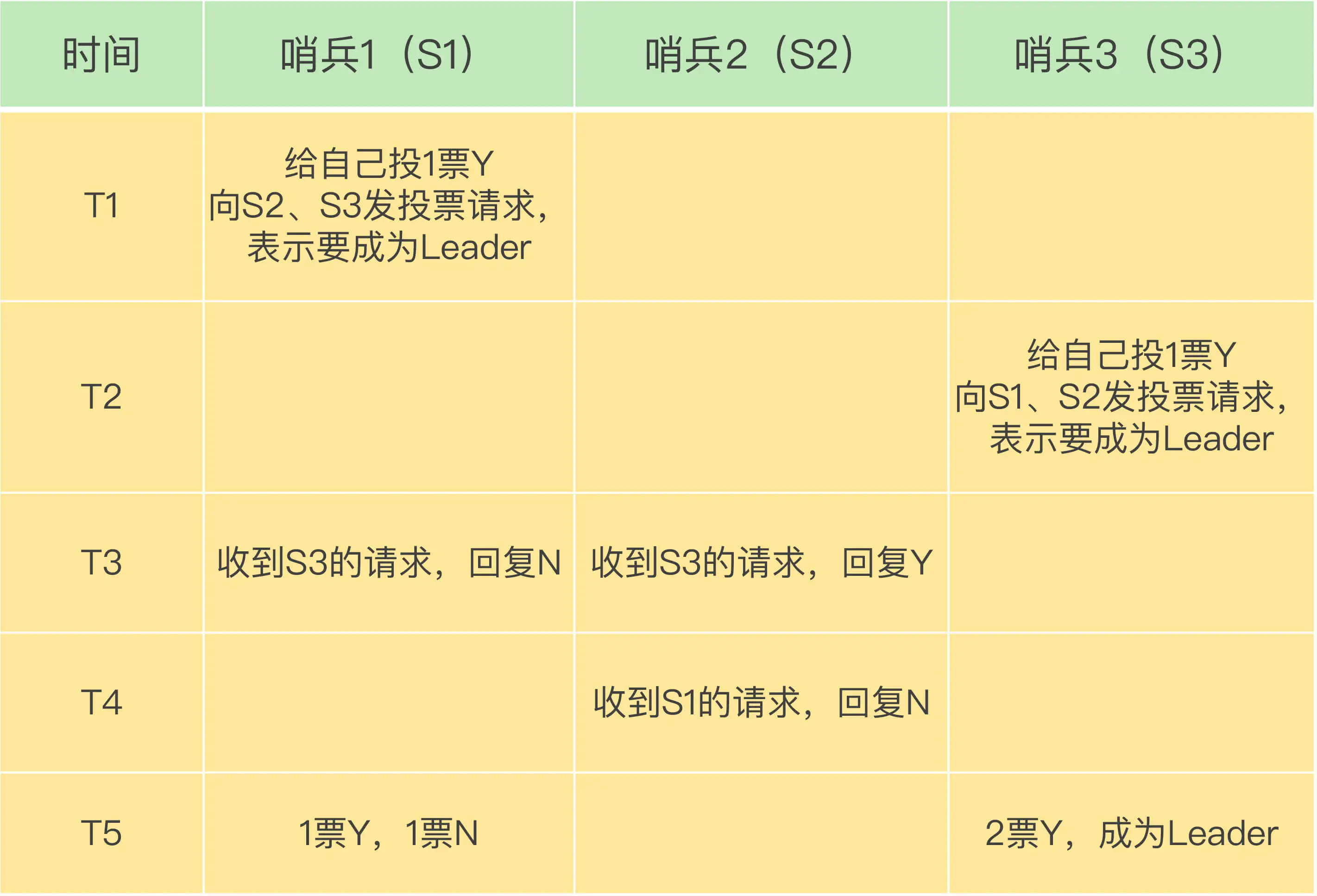
3 gpfdist外部表的工作流程
gpfdist是通过每个segment节点并行加载数据,在数据传输过程中不需要Master节点的参与(只需要协调控制)。如图,假定greenplum集群有一个master和四个segment以及单独部署的ETL服务器,该ETL服务器上运行一个gpfdist进程。工作流程:
1)客户端工具向Master节点发送命令;
2)Master节点对SQL进行解析,生成查询计划分发至所有segment节点;
3)每个segment节点开始执行查询,并向gpfdist进行发起HTTP请求;
4)对于只读外部表,gpfdist读取文件,将文件分块,确定行边界位置;对于只写外部表,gpfdist将收到的数据写入磁盘;
5)gpfdist将数据块或者是执行结果分发给segment;
6)segment将处理结果返回给master;
7)master将查询结果返回给客户端。

4 gpfdist只读外部表
gpfdist只读外部表通过gpfdist进程,接收来自各个segment节点的HTTP GET请求,将数据大致均匀分布在各个segment上,其协议与具体工作方式如下:
(1)只读外部表的HTTP头解析
segment节点通过HTTP头协议与gpfdist进程进行传递信息,主要HTTP头信息如下:

(2)gpfdist进程的请求处理
对于只读外部表执行SELECT操作时,gpfdist服务进程的工作方式与HTTP服务器响应GET请求的过程类似。参与处理的segment会同时向gpfdist进程发送数据请求;gpfdist根据<X-GP-XID,X-GP-CID, X-GP-SN>三元组确定那些请求属于同一个会话,来自同一会话的segment共同完成一次数据扫描。gpfdist进程按顺序依次从文件中读取一个数据分块,并保证分块中包含完整数据行。然后,将这个数据分块通过HTTP响应的方式发送给一个segment。gpfdist重复此过程,直至读取完所有的文件。
(3)分快处理
由于gpfdist事先不知道发送给每个segment的数据总长度,无法在HTTP响应报文提前设置ContentLength参数,因此gpfdist的HTTP响应报文是以chunked的方式发送。首先在HTTP响应头中设置”Transfer-Encoding:chunked”告知segment节点数据将以分块的形式传输。在每个数据块之前都会包含该数据块的长度,当传输结束时,发送长度为0的空数据块表示数据结尾。chunked模式的传输数据包示例如下:

由于采用Chunked的方式传输数据,每个segment向gpfdist进程发送GET请求后,gpfdist会将数据不停发往segment节点,直到gpfdist显示地告知segment传输数据结束为止。
gpfdist以数据块为单位,按照segment请求的先后顺序将数据块发送给不同的segment。因此可以认为数据近似随机的分发到每个segment上。每个segment会对收到的数据进行行和列的解析,从而完成一次读取工作。
(4)数据重分布
利用外部表执行数据加载,是通过对目标表进行INSERT操作,将外部表返回的结果插入到数据库中。执行INSERT操作时,segment上的QE进程会根据目标表的分布键将接收到的外部表数据进行重分布。

Redistribute表示数据需要重分布。在上例中,数据重分布发生在2个segment节点之间,在没有数据倾斜的情况下,各个segment节点可以并行、高效地完成数据交换。数据重分布之后,每个segment节点会将收到的数据写入磁盘,从而实现加载。
(5)多实例加载
gpfdist采用的是基于libevent的单进程事件驱动模型,在同一个进程中按照先来后到的顺序,轮流响应收到的GET请求。在处理某一个请求时,其他请求就会被阻塞。为了提高加载速度,可以采用运行多个gpfdist实例的方式,利用多个CPU处理能力。在网络和磁盘IO允许的情况下,每增加一个gpfdist实例,就可以充分利用一个CPU的计算资源,从而提高数据加载的速度。可以通过设置不同的监听端口地址来实现多gpfdist实例。
参考:greenplum从大数据战略到实现