文章目录
- 阻塞队列(BlockQueue)介绍
- 生产者消费者模型 介绍
- 代码实现
- lockGuard.hpp()
- Task.hpp(任务类)
- BlockQueue.hpp(阻塞队列)
- conProd.cc(生产者消费者模型 主进程)
- 执行结果
阻塞队列(BlockQueue)介绍
阻塞队列(Blocking Queue)是一种特殊类型的队列,它具有阻塞操作的特性。在并发编程中,阻塞队列可以用于实现线程间的安全通信和数据共享。
阻塞队列的 主要特点 是:
- 当队列为空时,消费者线程尝试从队列中获取(出队)元素时会被阻塞,直到有新的元素被添加到队列中为止。
- 当队列已满时,生产者线程尝试向队列中添加(入队)元素时也会被阻塞,直到有空闲容量可用。
阻塞队列通常提供入队操作、出队操作以及获取队列大小等基本方法。
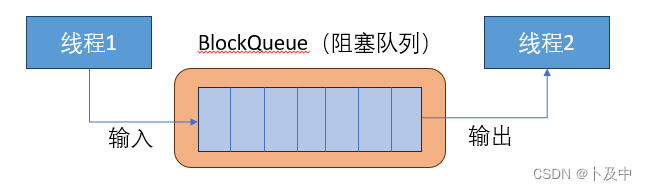
阻塞队列的实现在下文
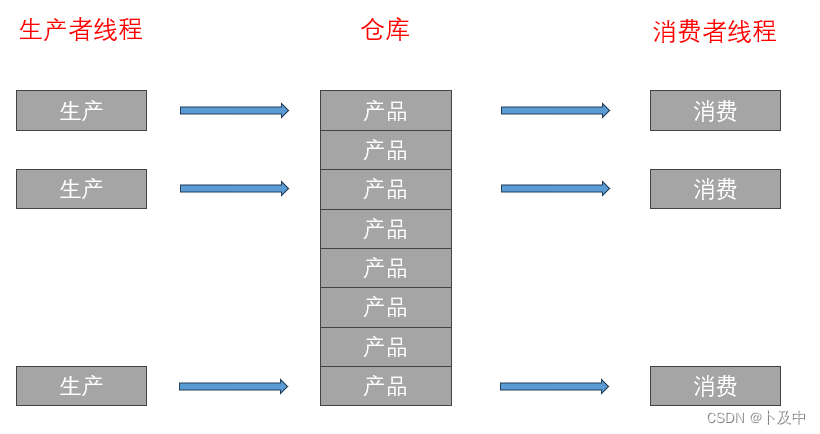
生产者消费者模型 介绍
生产者消费者模型 是一种常用的 并发编程模型 ,用于解决多线程或多进程环境下的协作问题。该模型包含两类角色:生产者和消费者。
生产者负责生成数据,并将数据存放到共享的缓冲区中。消费者则从缓冲区中获取数据并进行处理。生产者和消费者之间通过共享的缓冲区进行数据交互。
为了确保线程安全,生产者和消费者需要遵循一些规则:
- 如果缓冲区已满,则生产者需要等待直到有空间可用。
- 如果缓冲区为空,则消费者需要等待直到有数据可用。
- 生产者和消费者都不能访问缓冲区的内部结构,只能通过特定的接口进行操作。
代码实现
在代码实现上,生产者消费者模型通常涉及以下几个 角色和操作 :
- 生产者(Producer):负责生成数据并将其放入共享的缓冲区。
- 消费者(Consumer):从共享的缓冲区中获取数据并进行处理。
- 缓冲区(Buffer):用于暂存生产者生成的数据,供消费者使用。
- 同步机制:用于确保生产者和消费者之间的协调和同步,以避免竞态条件和数据不一致性等问题。
我们将要实现的代码中:
阻塞队列 作为缓冲区,Task任务类 由生产者生产传入阻塞队列,以便消费者拿去任务消费,lockGuard 与条件变量 保证 生产者消费者之间的协调,同步。
lockGuard.hpp()
在 lockGuard.hpp中我们 实现了一个 需封装了互斥锁的Mutex类和一个 实现自动加解锁的lockGuard类。
Mutex类封装了pthread_mutex_t类型的互斥锁, lockGuard类是一个RAII风格的加锁方式。
通过这种方式,lockGuard对象的生命周期和锁的生命周期绑定在一起,可以确保在任何情况下都能保证锁的正确释放,避免死锁等问题
完整代码:
#pragma once
#include <iostream>
#include <pthread.h>
using std::cout; using std::endl;
// Mutex类封装 pthread_mutex_t 互斥锁
class Mutex
{
public:
// 构造
Mutex(pthread_mutex_t* mtx):_pmtx(mtx){}
// 调用lock 进行加锁
void lock()
{
cout << "进行加锁" << endl;
pthread_mutex_lock(_pmtx);
}
// 调用unlock 进行解锁
void unlock()
{
cout << "进行解锁" << endl;
pthread_mutex_unlock(_pmtx);
}
~Mutex()
{}
private:
pthread_mutex_t* _pmtx;
};
// RAII 风格的加锁方式
// 以实现自动加解锁
class lockGuard
{
public:
// 构造
lockGuard(pthread_mutex_t* mtx):_mtx(mtx)
{
_mtx.lock();
}
// 析构
~lockGuard()
{
_mtx.unlock();
}
private:
Mutex _mtx;
};
Task.hpp(任务类)
下面的代码 是一个简化的 任务封装类 ,用于生产者产生任务并将其放入阻塞队列,供消费者取出并执行。通过将函数与参数打包成任务,实现了任务的传递和执行。
#pragma once
#include <iostream>
#include <functional>
// 表示一个函数类型。
// func_t是一个接受两个整数参数并返回整数的函数类型
typedef std::function<int(int, int)> func_t;
// 任务类型: 用于生产者产生任务
class Task
{
public:
Task(){};
// 传入三个参数x,y,以及一个函数,task则执行func(x, y)
Task(int x, int y, func_t func):_x(x),_y(y),_func(func)
{}
// 用于执行任务。在函数体内部,会调用存储在 _func 中的函数对象,
// 并将 _x 和 _y 作为参数传递给这个函数对象。
// 最后 返回执行结果。
int operator()()
{
return _func(_x,_y);
}
public:
// 用作函数参数
int _x;
int _y;
func_t _func;
};
BlockQueue.hpp(阻塞队列)
对 阻塞队列 进行类的实现:
BlockQueue包含以下成员变量:
std::queue<T> _bq; // 阻塞队列
int _capacity; // 容量上限
pthread_mutex_t _mtx; // 互斥锁: 保证队列安全
pthread_cond_t _empty; // 表示bq是否为空
pthread_cond_t _full; // 表示bq是否为满
以及除构造函数/析构函数外的以下 BlockQueue包含以下成员函数:
bool isQueueEmpty() // 判断队列是否为空
bool isQueueFull() // 判断队列是否为满
void push(const T &in) // 生产者用于制造任务
void pop(const T &in) // 消费者用于消耗任务
完整代码:
#pragma once
#include <iostream>
#include <queue>
#include <mutex>
#include <pthread.h>
#include "lockGuard.hpp"
const int gDefaultCap = 5; // 作为阻塞队列的默认容量
// 阻塞队列
template <class T>
class BlockQueue
{
private:
// 判断队列是否为空
bool isQueueEmpty()
{
return _bq.size() == 0;
}
// 判满
bool isQueueFull()
{
return _bq.size() == _capacity; // 当size == _capacity 证明队列已满
}
public:
// 构造
BlockQueue(int capacity = gDefaultCap) : _capacity(capacity)
{
// 初始化互斥锁 && 条件变量
pthread_mutex_init(&_mtx, nullptr);
pthread_cond_init(&_empty, nullptr);
pthread_cond_init(&_full, nullptr);
}
// 析构
~BlockQueue()
{
// 销毁 互斥锁 && 条件变量
pthread_mutex_destroy(&_mtx);
pthread_cond_destroy(&_full);
pthread_cond_destroy(&_empty);
}
// 生产者进程
void push(const T &in)
{
// 创建一个lockGuard 变量
lockGuard lockguard(&_mtx);
while(isQueueFull())
{
// 如果此时阻塞队列为满,进程等待,直到有空位时改变_full
pthread_cond_wait(&_full, &_mtx);
}
// 此时阻塞队列有空位,正常插入元素,并
_bq.push(in);
pthread_cond_signal(&_empty); // 发送信号,表示队列不再为空
pthread_mutex_unlock(&_mtx);
}
// 消费者进程
void pop(T *out)
{
lockGuard lockguard(&_mtx);
// pthread_mutex_lock(&mtx_);
while (isQueueEmpty()) // 如果队列为空,等待生产者制造任务
pthread_cond_wait(&_empty, &_mtx);
// 此时队列内有任务,
*out = _bq.front(); // 拿_bq的头部元素,并执行pop(拿任务+销毁)
_bq.pop();
pthread_cond_signal(&_full);
pthread_mutex_unlock(&_mtx);
}
private:
std::queue<T> _bq; // 阻塞队列
int _capacity; // 容量上限
pthread_mutex_t _mtx; // 互斥锁: 保证队列安全
pthread_cond_t _empty; // 表示bq是否为空
pthread_cond_t _full; // 表示bq是否为满
};
conProd.cc(生产者消费者模型 主进程)
该文件中包含以下函数:
-
myAdd 函数:一个简单的加法函数,即实际执行任务所执行的函数。
-
consumer 函数:消费者线程的执行函数。该函数从阻塞队列中获取任务,并执行任务的函数。
-
productor 函数:生产者线程的执行函数。该函数随机生成两个整数参数,创建一个任务对象,并将任务对象插入到阻塞队列中。
-
main 函数:主函数,用于创建并启动多个消费者线程和生产者线程。通过调用 pthread_create 创建线程,并通过 pthread_join 等待线程结束。
完整代码:
#include "blockQueue.hpp"
#include "Task.hpp"
#include <pthread.h>
#include <unistd.h>
// 加法函数,用于生产者进程产生任务
int myAdd(int x, int y)
{
return x + y;
}
// 消费者进程
void *consumer(void* args)
{
// 将获得的agrs 参数 强制转化为BlockQueue<Task>* 类型 并赋值给变量bqueue
BlockQueue<Task>* bqueue = (BlockQueue<Task>*)args;
while(true)
{
// 获取任务
Task t;
bqueue->pop(&t); // 执行任务 + 销毁
// 打印任务信息,因为我们使用的仅仅是一个加法函数,所以直接打印"+"
cout << pthread_self() << " consumer: " << t._x << " + " << t._y << " = " << t() << endl;
}
return nullptr;
}
// 生产者进程
void* productor(void* args)
{
BlockQueue<Task>* bqueue = (BlockQueue<Task>*)args;
while(true)
{
// 制造任务
// 生产者将任务传到缓冲区,消费者再将其消耗
// 任务不一定有生产者制造,也可能通过外部获得
// 随机产生x, y两个参数,执行Task
int x = rand() % 10 + 1;
usleep(rand() % 1000);
int y = rand() % 5 + 1;
Task t(x, y, myAdd);
// 发送任务
bqueue->push(t);
// 输出消息
cout << pthread_self() << " productor: " << t._x << " + " << t._y << " = ?" << endl;
sleep(1);
}
return nullptr;
}
int main()
{
// getpid():获取当前进程的进程ID(PID),用于区分不同的进程。
// 0x11451 用于增加种子的随机性
srand((uint64_t)time(nullptr) ^ getpid() ^ 0x11451);
BlockQueue<Task>* bqueue = new BlockQueue<Task>();
pthread_t con[2], pro[2]; // 声明两个消费者 / 生产者,增加并行性
// 可以将 &con[1] 换为 con+1
pthread_create(&con[0], nullptr, consumer, bqueue);
pthread_create(&con[1], nullptr, consumer, bqueue);
pthread_create(&pro[0], nullptr, productor, bqueue);
pthread_create(&pro[1], nullptr, productor, bqueue);
// 执行完毕,等待进程销毁
pthread_join(con[0], nullptr);
pthread_join(con[1], nullptr);
pthread_join(pro[0], nullptr);
pthread_join(pro[1], nullptr);
delete bqueue; // 销毁队列
return 0;
}
执行结果
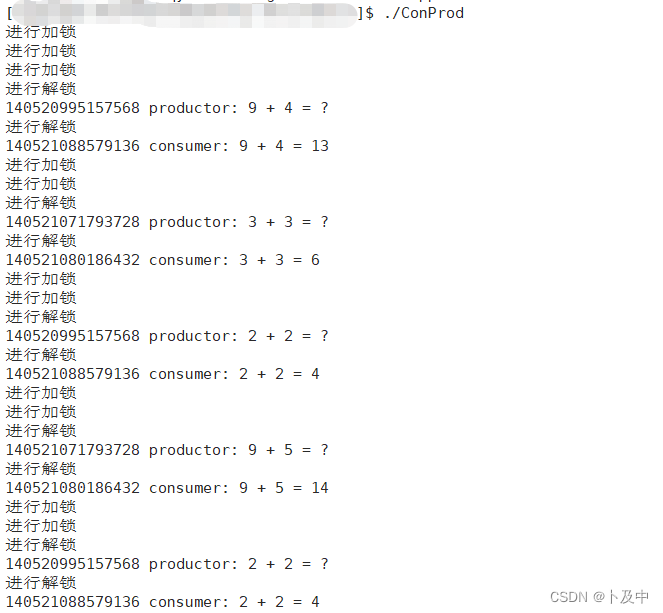
根据上面的执行结果,可以看出,程序先连续生产(即加锁信息的打印),阻塞队列满了后开始消费,后面重复 生产消费(即加锁解锁)的步骤。