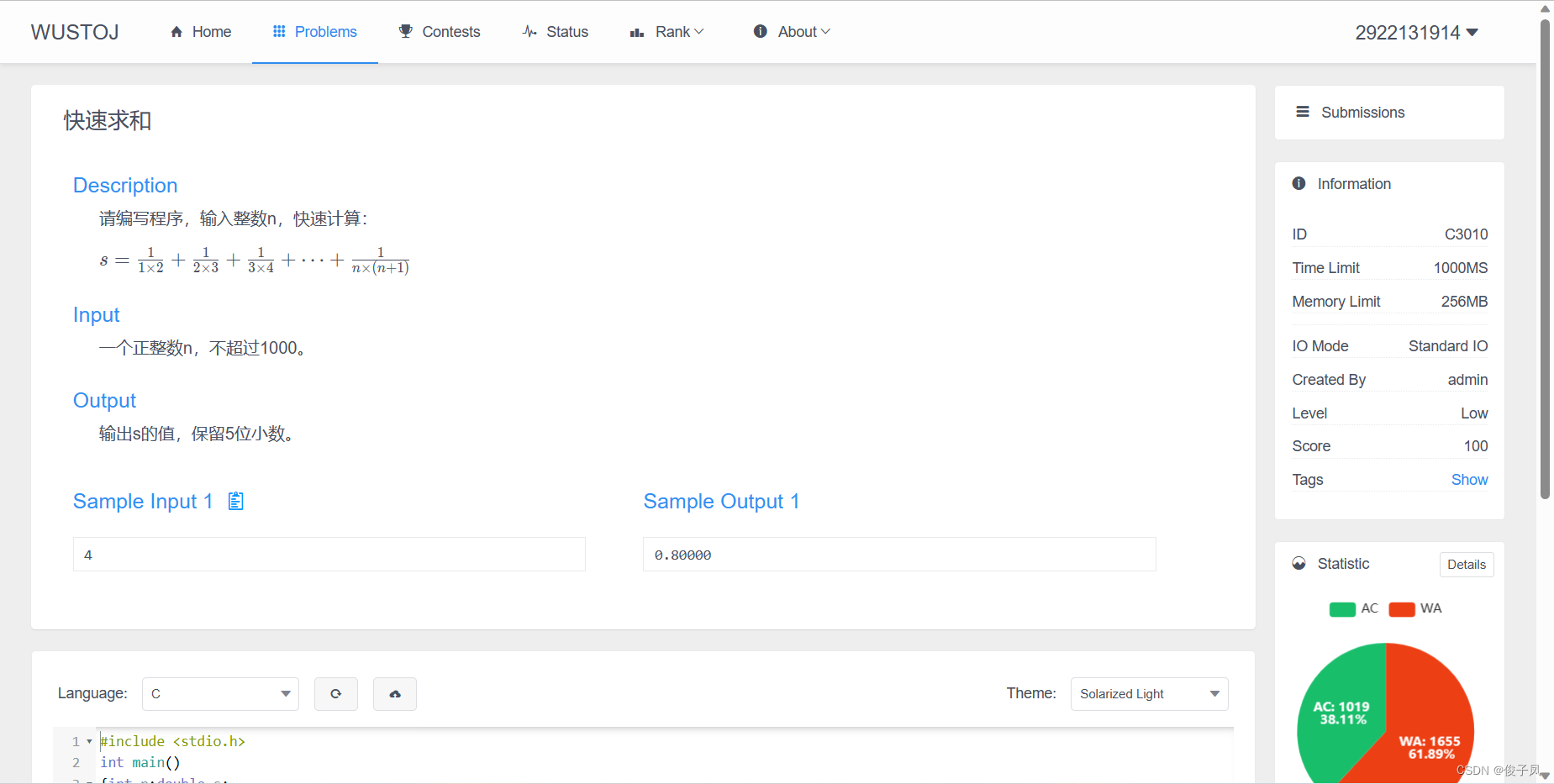
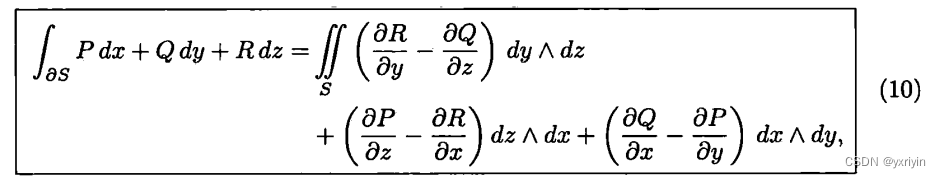0、基础:Bean的生命周期
在Spring中,由于IOC的控制反转,创建对象不再是简单的new出来,而是交给Spring去创建,会经历一系列Bean的生命周期才创建出相应的对象。而循环依赖问题也是由Bean的生命周期过程导致的问题,因此我们首先需要了解Bean的生命周期。
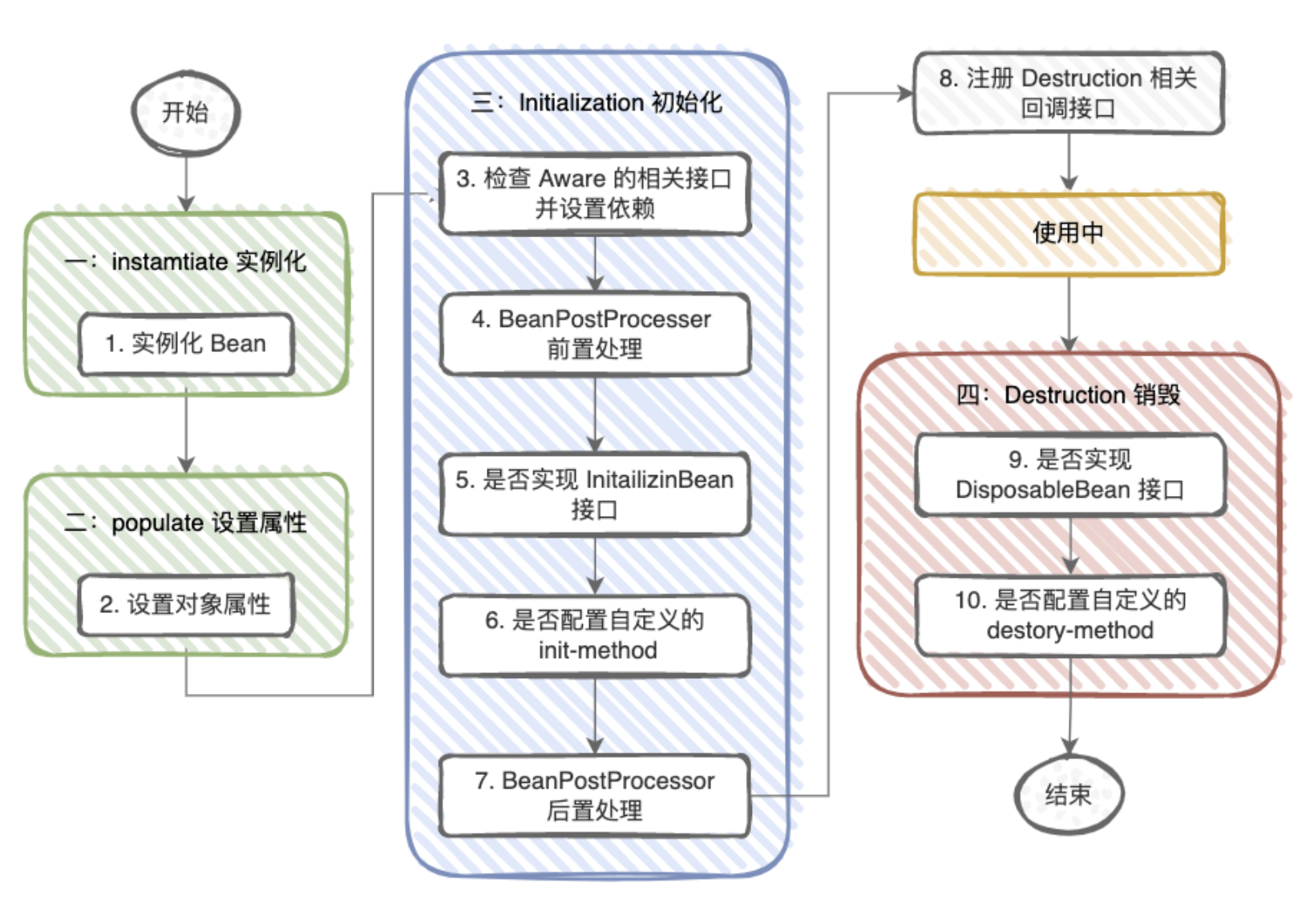
Bean的生命周期可以概括为4步:
实例化----属性注入----初始化----销毁
详细的讲,步骤如下:
******************************************实例化123*******************************************
- 定位:Spring容器会根据配置文件(如XML、注解等)或编程式配置来确定需要创建的Bean。
加载:Spring容器会加载配置文件并解析其中的Bean定义,将其转换为内部数据结构,例如BeanDefinition。
实例化:在实例化阶段,Spring容器会根据Bean定义中的信息创建Bean的实例。这个过程可以通过构造函数实例化、工厂方法实例化或者通过反射机制来实现。*****************************************属性注入4*********************************************
属性注入:在实例化Bean之后,Spring容器会对Bean进行属性注入。这可以通过setter方法注入、构造函数参数注入或字段注入等方式来完成。
****************************************初始化5~9********************************************Aware接口回调:如果Bean实现了Spring的Aware接口,容器会通过回调方式将一些特殊的资源注入到Bean中。例如,如果Bean实现了BeanFactoryAware接口,容器会将当前的BeanFactory实例注入到Bean中。
初始化前回调:如果Bean实现了InitializingBean接口,容器会在初始化之前调用它的
afterPropertiesSet()方法,给Bean一个机会执行一些初始化操作。同时,Spring容器还支持使用自定义的初始化方法。初始化后回调:如果Bean配置了初始化回调方法,容器会调用该方法进行一些自定义的初始化逻辑处理。
后置处理器(BeanPostProcessor):Spring容器会调用注册的Bean后置处理器对Bean进行加工和增强。例如,可以通过AOP技术在这个阶段为Bean动态生成代理对象。
完成:至此,Bean已经成功创建,并且已经完成了所有的初始化过程。此时可以将Bean提供给其他对象使用。
****************************************销毁10、11******************************************销毁前回调(PreDestroy):在容器关闭之前,调用Bean的销毁前回调方法,执行一些清理操作和释放资源的任务。
销毁:容器关闭时,销毁所有Bean实例,包括调用相应Bean的销毁方法,进行最终的清理和资源释放。
 1、循环依赖问题
1、循环依赖问题
例如下面的代码,A和B类就构成了循环依赖,原因如下:
@Component
public class A {
@Autowired
private B b;
}
@Component
public class B{
@Autowired
private A a;
}
创建Bean的步骤:
- Spring 扫描 class 得到 BeanDefinition;
- 根据得到的 BeanDefinition 去生成 bean;
- 首先根据 class 推断构造方法;
- 根据推断出来的构造方法,反射,得到一个对象(我们称为原始对象);
- 填充原始对象中的属性(依赖注入);
- 如果原始对象中的某个方法被 AOP 了,那么则需要根据原始对象生成一个代理对象;
- 把最终生成的代理对象放入单例池(源码中叫做 singletonObjects)中,下次 getBean 时就直接从单例池拿即可;
对于上述步骤的第4步, 得到原始对象后需要注入属性,A 类中存在一个 B 类的 b 属性,此时就会根据 b 属性的类型和属性名去 BeanFactory 中去获取 B 类所对应的单例bean。
如果此时 B 类在 BeanFactory 中还没有生成对应的 Bean,那么就需要去生成,就会经过 B 的 Bean 的生命周期,也就会同样的,需要A类的Bean,就发生了循环依赖,导致A和B的bean都创建不出来。
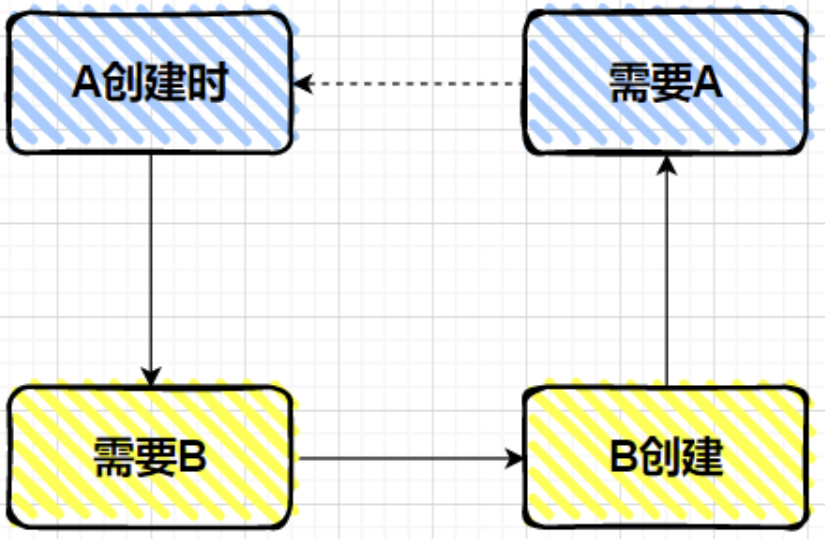
概括而言:
A Bean创建–>依赖了 B 属性–>触发 B Bean创建—>B 依赖了 A 属性—>需要 A Bean(但A Bean还在创建过程中)
然而实际上,Spring通过三级缓存的方式自动解决了这个问题 。
2、三级缓存的引入
2.1 非AOP情况下的解决方案
根据上文的分析我们发现,出现循环依赖的根本原因,是B的Bean需要注入A属性的时候,Bean A还没有创建出来,导致的。那么相应的,只要:
在进行依赖注入之前,先把 A 的原始 Bean 放入缓存(提早暴露,只要放到缓存了,其他 Bean 需要时就可以从缓存中拿了,这个缓存就应该是earlySingletonObjects),放入缓存后,再进行依赖注入。
由于提前暴露,在创建B的Bean过程中,当需要注入A的属性时,就可以从缓存中拿到A提前暴露的原始对象(还不是最终Bean),就解决了问题。关键在于全程只有一个A的原始对象,其后续的生命周期没有变化。
如下图所示:
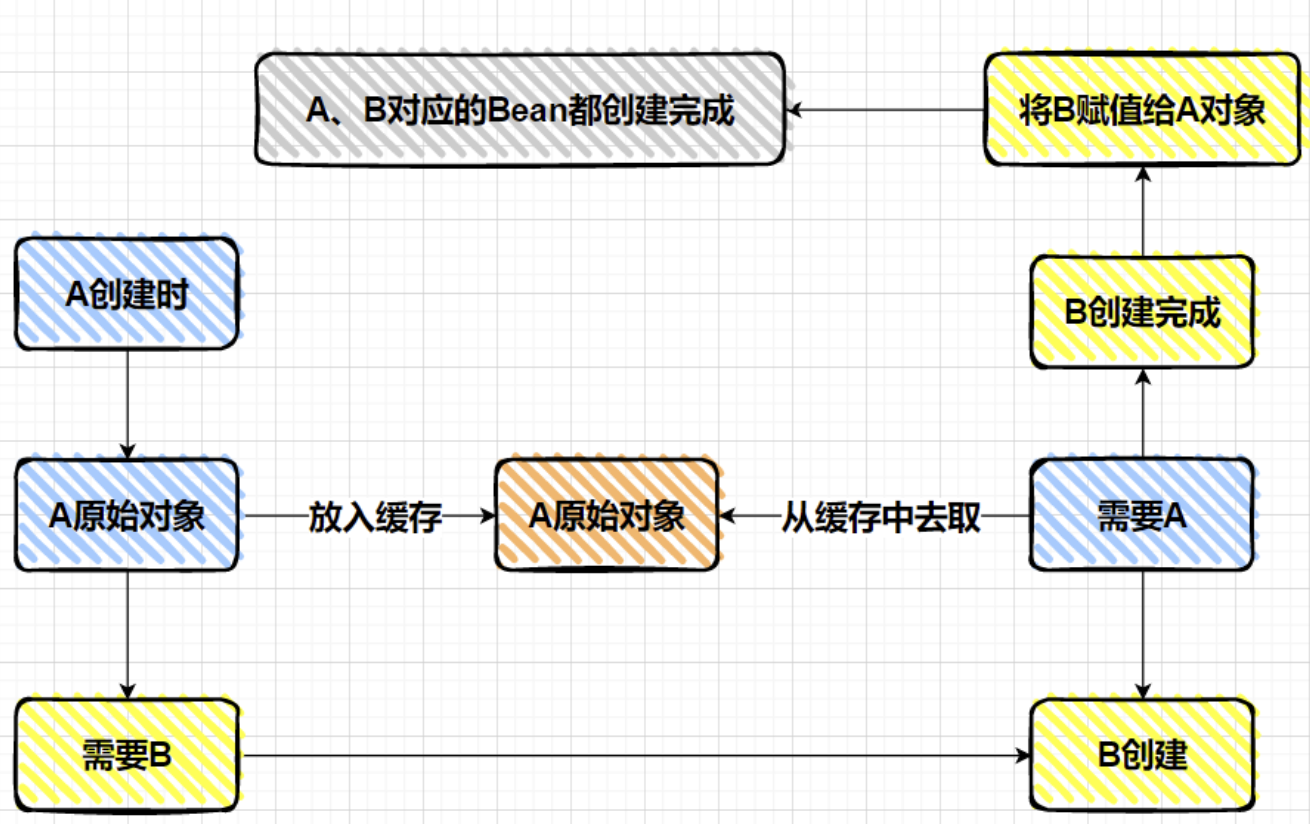
2.2 三级缓存具体
因此,对于不同时期的Bean,如原始Bean、完整周期的Bean,需要不同的缓存来存放,底层源码中有三级缓存:
/** Cache of singleton objects: bean name –> bean instance */
private final Map singletonObjects = new ConcurrentHashMap(256);
/** Cache of singleton factories: bean name –> ObjectFactory */
private final Map> singletonFactories = new HashMap>(16);
/** Cache of early singleton objects: bean name –> bean instance */
private final Map earlySingletonObjects = new HashMap(16);
- 一级缓存:singletonObjects;缓存的是已经经历了完整生命周期的bean对象。
- 二级缓存:earlySingletonObjects;比 singletonObjects 多了一个 early ,表示缓存的是早期的 bean对象(原始对象)。早期指的是 Bean 的生命周期还没走完就把这个 Bean 放入了 earlySingletonObjects
- 三级缓存:singletonFactories;缓存的是 ObjectFactory,表示对象工厂,用来创建某个对象的。
3、有AOP情况下使用singletonFactories
3.1 引入三级缓存
看似我们只需要1、2级缓存就能够解决问题了,为什么需要三级缓存呢?
这就需要考虑到AOP代理对象的问题了:
上文的红字提到,之所以能够提前暴露,是因为假定的A的原始对象始终是同一个对象,但如果有AOP的情况下呢?我们考虑这样的场景:
按照上文的分析,假设创建B的bean过程中,注入了A的原始对象属性。然后,A的原始对象采用AOP产生了一个代理对象,即,A的Bean变成了 AOP 之后的代理对象。而B中的 属性a对应的并不是 AOP 之后的代理对象,而仍然是原始对象。
也就是说,这种情况下,B 依赖的 A 和最终的 A 不是同一个对象!
而解决这个问题的方法,就是引入三级缓存的 singletonFactories
3.2 三级缓存具体解析
实际上,在有AOP的情况下,Spring并没有像第2节所说,直接将示例缓存到二级缓存,而是生成完原始对象之后”多此一举“地将实例先封装到objectFactory中,在需要引用的时候再通过singletonFactory.getObject()获取。
跟进getObject()方法,其实执行了getEarlyBeanReference这个关键方法。
this.addSingletonFactory(beanName, () -> {
return this.getEarlyBeanReference(beanName, mbd, bean);
});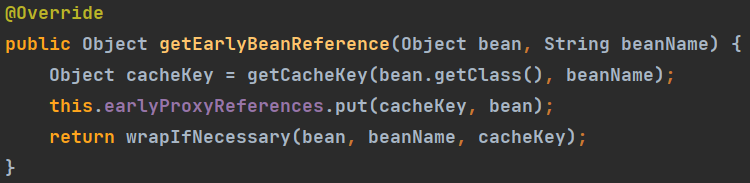
也就是说,Spring将当前bean缓存到earlyProxyReferences中,标识提前曝光的bean。而wrapIfNecessary是用于Spring AOP自动代理的,也就是说在被提前引用前,进行了AOP代理,并得到了代理对象。
此时earlySingletonObjects 缓存中的对象就是代理对象了!
因此,假设此时有其他对象依赖了A,就可以从earlySingletonObjects中获取到A原始对象的代理对象了,并且和A是同一个对象,实现了目标。
3.3 后续依赖问题
当 B 创建完了之后,A 继续进行生命周期,而 A 在完成属性注入后,会按照它本身的逻辑去进行AOP,而此时我们知道 A 原始对象已经经历过了 AOP ,所以对于 A 本身而言,不会再去进行 AOP了,那么怎么判断一个对象是否经历过了 AOP 呢?
注意postProcessAfterInitialization方法,会当前beanName是否在earlyProxyReferences中,如果在就AOP过了,不在则执行AOP方法。

此时对于Bean A对象而言已经完成创建了,可以把它放入缓存singletonObjects中了,因此从earlySingletonObjects 中得到代理对象,然后入 singletonObjects 中。
至此,整个循环依赖解决完毕。
4、总结
这里引用看到的一篇写的很清晰的博客http://t.csdn.cn/GeHkA的图来说明具体流程:
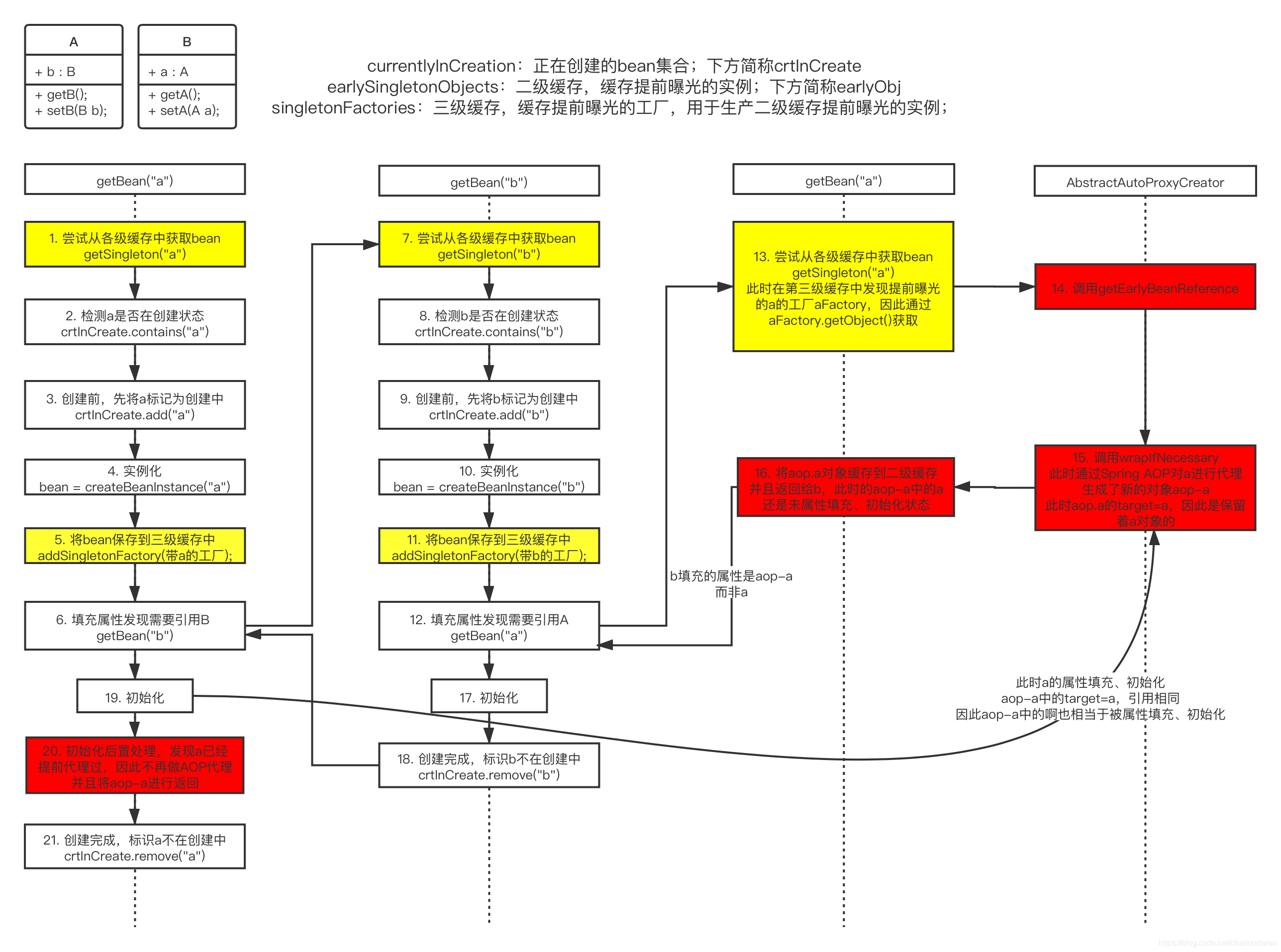
对于三级缓存的singletonFactories,总结而言:
缓存的是一个 ObjectFactory ,主要用来去生成原始对象进行了 AOP之后得到的「代理对象」。
在每个 Bean 的生成过程中,都会提前暴露一个工厂,这个工厂可能用到,也可能用不到:
(1)如果没有出现循环依赖依赖本 bean,那么这个工厂无用,本 bean 按照自己的生命周期执行,执行完后直接把本 bean 放入 singletonObjects 中即可(对应本文章的第1节)
(2)如果出现了循环依赖依赖了本 bean,则:
<2.1>如果有 AOP 的话,另外那个 bean 执行 ObjectFactory 提交得到一个 AOP 之后的代理对象。(对应本文章第3节)
<2.2>如果无需 AOP ,则直接得到一个原始对象。(对应本文章第2节)