前言
模型训练是指使用算法和数据对机器学习模型进行参数调整和优化的过程。模型训练一般包含以下步骤:数据收集、数据预处理、模型选择、模型训练、模型评估、超参数调优、模型部署、持续优化。

文章目录
- 前言
- 数据收集
- 数据预处理
- 模型选择
- 模型训练
- 模型评估
- 超参数调优
- 模型部署
- 持续优化
- 总结
数据收集
数据收集是指为机器学习或数据分析任务收集和获取用于训练或分析的数据。数据质量和数据多样性对于模型的性能和泛化能力至关重要。以下是一些常见的数据收集方法:
- 公开数据集:可以使用公开可用的数据集,例如UCI Machine Learning Repository、Kaggle等平台上提供的各种数据集。这些数据集通常经过整理和标注,适用于各种机器学习任务。
- 爬虫抓取:通过网络爬虫工具抓取网页内容或者从API接口中获取数据。这种方式适用于需要大量文本、图像或其他媒体数据的任务,例如舆情分析、图像识别等。
- 传感器数据:在物联网应用中,可以通过传感器收集物理世界的数据,例如温度、湿度、加速度等。这些数据可以用于监测、预测或控制系统。
- 用户反馈和调查:通过用户反馈、调查问卷或观察记录等方式收集用户行为数据或主观评价数据。这种方式适用于个性化推荐、情感分析等任务。
- 实验设计:设计并进行实验来收集数据。例如,在医学研究中,可以设计随机对照实验来收集患者的生理指标和治疗结果。
- 合作伙伴或第三方数据供应商:与合作伙伴或第三方数据供应商合作,购买或获取特定领域或行业的数据。例如,金融数据、医疗保健数据等。

在数据收集过程中,需要注意以下几点:
- 数据隐私和合规性:确保收集的数据符合相关法律法规,保护用户的隐私和敏感信息。
- 数据标注和清洗:对收集的数据进行标注和清洗,确保数据的质量和一致性。
- 数据平衡:确保数据集在各类别或各样本之间具有平衡性,避免偏见和倾斜现象。
- 特征工程:在数据收集过程中,可以考虑设计和收集更多的特征,以提高模型的表达能力和性能。
数据收集是机器学习和数据分析的关键步骤之一,需要综合考虑数据的来源、质量、多样性和可靠性,以支持后续的模型训练和分析工作。
数据预处理
在进行模型训练之前,通常需要对原始数据进行预处理。预处理包括数据清洗、数据转换、特征选择等步骤。这些步骤旨在提高数据的质量和可用性,为后续的特征工程和模型训练做准备。
以下是一些常见的数据预处理代码示例,用于清洗、转换和划分数据:
- 数据清洗
# 删除缺失值
data.dropna()
# 填充缺失值
data.fillna(value)
# 删除重复值
data.drop_duplicates()
# 处理异常值
data = data[(data['column'] > lower_bound) & (data['column'] < upper_bound)]
- 特征选择和转换
# 特征选择
from sklearn.feature_selection import SelectKBest, chi2
selector = SelectKBest(chi2, k=5) # 选择k个最佳特征
X_new = selector.fit_transform(X, y)
# 特征标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 类别特征编码
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
X_encoded = encoder.fit_transform(X)
- 数据划分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
模型选择
模型选择有两层含义:一是在假设空间上训练得到的模型可能不止一个,需要从中进行选择,在实践中往往是选择同等效果下复杂度较小的模型;二是对于一个具体问题,我们可能希望尝试不同方法,于是就有了不同的模型,在这些模型训练结束后,我们需要决定使用哪一个,但这种模型选择往往需要结合模型评估方法,因为对于某种归纳偏好,不同方法下的不同模型的实现各不相同,只能根据在测试集上的最终表现效果来选择。

以下是一些常见的模型选择策略和方法:
- 理解任务类型:首先,需要明确任务的类型是分类、回归、聚类还是其他类型的问题。根据任务类型选择相应的模型类型。
- 数据分析和探索:对数据进行初步分析和探索,了解数据的特征、结构和关系。这有助于确定适合数据的模型类型和方法。
- 基准模型:选择一个简单的基准模型作为比较对象。例如,在分类问题中,可以尝试使用逻辑回归或决策树等简单模型作为基准。
- 考虑算法的优势和限制:了解各个算法的优势和限制,并根据任务需求进行选择。例如,如果数据具有复杂的非线性关系,可以考虑使用神经网络模型。
- 特征和样本数量:考虑特征的数量和质量,以及可用的样本数量。某些模型对特征数量和样本数量的要求较高,而其他模型则适用于小样本或高维数据。
- 交叉验证和评估指标:使用交叉验证和适当的评估指标来比较不同模型的性能。常用的评估指标包括准确率、精确率、召回率、F1值等。
- 集成方法:考虑使用集成方法,如随机森林、梯度提升树等,来结合多个模型的预测结果,以提高性能和泛化能力。
- 参考文献和实践经验:查阅相关文献和实践经验,了解在类似任务上表现良好的模型,并借鉴相应的方法和技巧。
模型训练
使用训练集对模型进行训练。这涉及到输入训练数据、计算模型的输出,并根据输出与真实标签之间的差异来更新模型的参数。训练过程通常使用优化算法进行迭代优化,直到达到某个停止条件(如达到最大迭代次数或损失函数收敛)为止。
对于大规模数据和复杂模型,通常需要使用分布式训练和加速技术来提高训练效率和性能。常见的分布式训练和加速技术包括并行计算、GPU加速和深度学习框架的优化等。
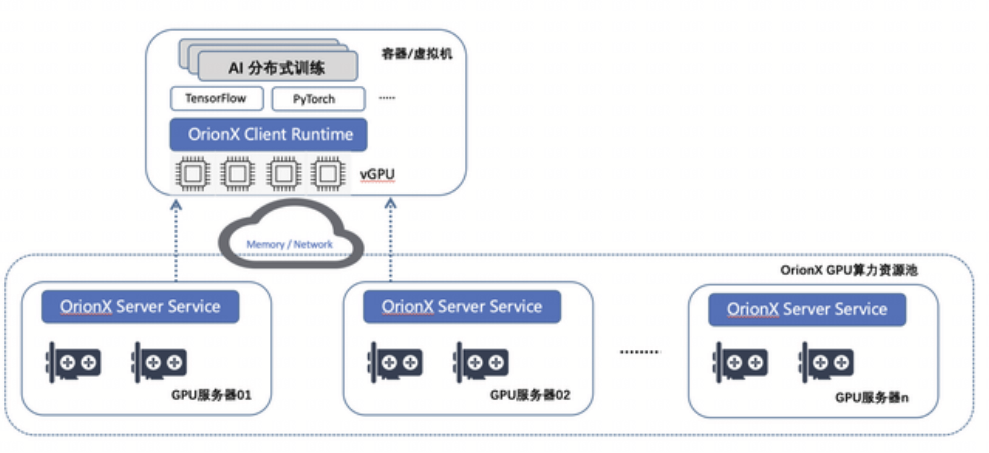
代码示例
# 使用并行计算库进行分布式训练
from joblib import Parallel, delayed
# 并行计算示例
results = Parallel(n_jobs=-1)(delayed(model.fit)(X_train_batch, y_train_batch) for X_train_batch, y_train_batch in zip(X_train_batches, y_train_batches))
模型评估
模型评估是指对于一种具体方法输出的最终模型,使用一些指标和方法来评价它的泛化能力。这一步骤通常在模型训练和模型选择之后,正式部署模型之前。
模型评估方法不针对模型本身,只针对问题和数据,因此可以用来评价来自不同方法的模型的泛化能力,进行用于部署的最终模型的选择。
我们评估一个模型,最关心的是它的泛化能力,对于监督学习问题,泛化能力可以用泛化误差(generalization error)来衡量,泛化误差指的是模型在训练集以外的数据上的风险函数。

超参数调优
超参数调优是在模型训练过程中对模型超参数进行选择和调整的过程,以优化模型性能。超参数调优是一个迭代的过程,需要根据实际情况进行多次尝试和调整。同时,要注意避免过拟合,以及在选择最佳超参数时要考虑模型的泛化能力和实际应用需求。
以下是一些常见的超参数调优方法:
- 网格搜索(Grid Search):网格搜索是一种穷举搜索的方法,通过指定超参数的候选值范围,尝试所有可能的组合,并评估每个组合的模型性能。选择性能最好的超参数组合作为最终的模型配置。
- 随机搜索(Random Search):与网格搜索不同,随机搜索从超参数的取值范围中随机选择一组参数进行评估。可以根据需要设置迭代次数或采样数量,从而寻找最佳超参数组合。
- 贝叶斯优化(Bayesian Optimization):贝叶斯优化是一种基于概率模型和贝叶斯推断的方法。它通过建立模型的性能和超参数之间的映射函数,并使用贝叶斯推断来选择最有可能改进性能的超参数组合。
- 梯度优化(Gradient-based Optimization):某些超参数可以通过梯度下降等优化算法进行调优。例如,在神经网络中,学习率、正则化参数等可以使用梯度优化算法进行更新,以提高模型性能。
- 学习曲线和验证曲线分析:通过绘制学习曲线和验证曲线,观察模型在不同超参数下的训练误差和验证误差的变化趋势。根据曲线的形状和趋势,调整超参数的取值范围和步长。
- 交叉验证(Cross-Validation):在超参数调优过程中,使用交叉验证来评估模型性能。通过将训练集划分为训练子集和验证子集,可以多次训练模型,并计算每个超参数组合的平均性能指标。
- 自动调参工具:还可以使用一些自动调参工具和框架,如Hyperopt、Optuna等,来简化超参数调优的过程。这些工具通常结合了不同的搜索策略和算法,提供了更高效的超参数优化方法。
贝叶斯优化 (Bayesian Optimization, BO) 是处理贵重黑箱优化问题的一类主流方法,在很多领域都有着广泛应用,比如机器学习领域的神经网络架构搜索、航空/航天/航海/汽车等领域的流体动力外形设计、电子信息领域的芯片软硬件协同设计、材料领域的材料配比优化、化学领域的化学反应优化、医学领域的自动化抗体设计、甚至曲奇饼干的配方改良。
模型部署
对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。相比于软件部署,模型部署会面临更多的难题:
- 运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
- 深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。
为了让模型最终能够部署到某一环境上,开发者们可以使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型。
持续优化
模型的持续优化是指在模型训练完成后,对其进行进一步改进和调整的过程。模型持续优化是一个迭代的过程,需要不断地分析和理解问题领域,探索新的方法和技术,并根据实际应用情况进行改进和调整。持续优化能够确保模型的鲁棒性和适应性,使其在实际应用中能够取得更好的结果。
总结
对于以上提到的模型训练的步骤并不是完全固定的,在实际的应用过程中可以根据具体的需求做个性化的调整。切记模型训练的过程是为了进一步优化模型性能,并为下一阶段的工作提供指导。通过不断总结和改进,可以逐步提升模型的性能和适应性,使其更好地满足实际应用需求。