Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
文章目录
- Flink 系列文章
- 一、Table & SQL Connectors
- 1、概述
- 2、支持的外部连接
- 3、使用示例:kafka
- 4、Transform table connector/format resources
- 5、Schema Mapping
- 6、Metadata
- 7、Primary Key
- 8、Time Attributes
- 9、Proctime Attributes
- 10、Rowtime Attributes
- 11、完整示例
- 1)、建表
- 2)、测试数据
- 3)、展示结果
- 12、SQL Types
- 二、Table & SQL Connectors 示例: Filesystem
- 1、Filesystem的依赖
- 1)、本地文件
- 2)、外部文件系统
- 3)、添加新的外部文件系统实现
- 4)、Hadoop 文件系统 (HDFS) 及其其他实现
- 2、文件系统 SQL 连接器
- 1)、分区文件
- 2)、File Formats
- 3)、Source
- 1、目录监控
- 2、可用的 Metadata
- 4)、Streaming Sink
- 1、滚动策略
- 2、文件合并
- 3、分区提交
- 1)、分区提交触发器
- 2)、分区时间提取器
- 5)、分区提交策略
- 5)、Sink Parallelism
- 6)、示例
本文简单的介绍了Filesystem文件的使用及可运行环境的示例。
本文依赖环境是hadoop、kafka环境好用,如果是ha环境则需要zookeeper的环境。
本文分为2个部分,即connector介绍以及filesystem示例。
一、Table & SQL Connectors
1、概述
Flink 的 Table API 和 SQL 程序可以连接到其他外部系统,用于读取和写入批处理表和流表。表源提供对存储在外部系统(如数据库、键值存储、消息队列或文件系统)中的数据的访问。表接收器向外部存储系统发出表。根据源和接收器的类型,它们支持不同的格式,例如 CSV、Avro、Parquet 或 ORC。
本文介绍如何使用原生支持的连接器在 Flink 中注册表源和表接收器。注册源或接收器后,可以通过表 API 和 SQL 语句访问它。
如果要实现自己的自定义表源或接收器,请查看 5、Flink的source、transformations、sink的详细示例(二)-source和transformation示例 和 5、Flink的source、transformations、sink的详细示例(三)-sink示例 。
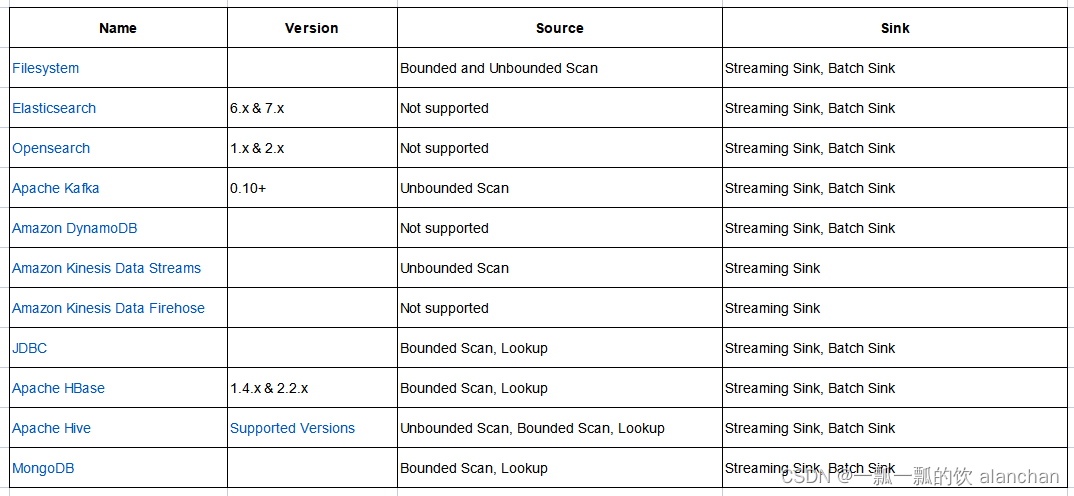
2、支持的外部连接
以版本1.17.1为例,该版本支持以下外部连接。
3、使用示例:kafka
Flink 支持使用 SQL CREATE TABLE 语句来注册表。可以定义表名称、表架构和用于连接到外部系统的表选项。
有关创建表的详细信息,请参阅 Flink(二十二)Flink 的table api与sql之创建表的DDL。
以下代码显示了如何连接到 Kafka 以读取和写入 JSON 记录的完整示例。
CREATE TABLE t_kafka_test (
`id` INT,
name string,
age BIGINT,
t_insert_time TIMESTAMP(3) METADATA FROM 'timestamp',
WATERMARK FOR t_insert_time as t_insert_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't_kafkasource_t2',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'format' = 'json'
);
-- 测试数据
{ "id":"1" ,"name":"alan","age":"12" }
{ "id":"2" ,"name":"alanchan","age":"22" }
{ "id":"3" ,"name":"alanchanchan","age":"32" }
{ "id":"4" ,"name":"alan_chan","age":"42" }
{ "id":"5" ,"name":"alan_chan_chn","age":"52" }
所需的连接属性将转换为基于字符串的键值对。工厂将根据工厂标识符(在本例中为 kafka 和 json)从键值对创建配置的表源、表接收器和相应格式。在为每个组件搜索一个匹配的工厂时,可以通过 Java 的Service Provider Interfaces (SPI) 找到的所有工厂都会被考虑在内。
如果找不到工厂或多个工厂与给定属性匹配,则会引发异常,其中包含有关所考虑的工厂和支持的属性的其他信息。
4、Transform table connector/format resources
Flink 使用 Java 的Service Provider Interfaces (SPI) 通过其标识符加载表连接器/格式工厂。由于每个表连接器/格式的名为 org.apache.flink.table.factories.Factory 的 SPI 资源文件位于同一目录 META-INF/services 下,因此在构建使用多个表连接器/格式的项目的 uber-jar 时,这些资源文件将相互覆盖,这将导致 Flink 无法加载表连接器/格式工厂。
在这种情况下,推荐的方法是通过 maven shade 插件的 ServicesResourceTransformer 转换目录 META-INF/services 下的这些资源文件。给定包含连接器 flink-sql-connector-hive-3.1.3 并在项目中格式化 flink-parquet 的示例的 pom.xml 文件内容。
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>myProject</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- other project dependencies ...-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-hive-3.1.3_2.12</artifactId>
<version>1.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_2.12</artifactId>
<version>1.17.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<executions>
<execution>
<id>shade</id>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers combine.children="append">
<!-- The service transformer is needed to merge META-INF/services files -->
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<!-- ... -->
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
配置服务资源转换器后,在构建上述项目的 uber-jar 时,目录 META-INF/services 下的表连接器/格式资源文件将被合并而不是相互覆盖。
5、Schema Mapping
SQL CREATE TABLE 语句的 body 子句定义了物理列、约束和水印的名称和类型。Flink 不保存数据,因此模式定义只声明如何将物理列从外部系统映射到 Flink 的表示。映射可能不会按名称映射,这取决于格式和连接器的实现。例如,MySQL 数据库表按字段名称(不区分大小写)映射,CSV 文件系统按字段顺序映射(字段名称可以是任意的)。这将在每个连接器中解释。
以下示例显示了一个没有时间属性的简单schema,以及输入/输出到表列的一对一字段映射。
CREATE TABLE MyTable (
MyField1 INT,
MyField2 STRING,
MyField3 BOOLEAN
) WITH (
...
)
6、Metadata
某些连接器和格式公开其他元数据字段,这些字段可在物理有效负载列旁边的元数据列中访问。有关元数据列的详细信息,请参阅 22、Flink 的table api与sql之创建表的DDL。
7、Primary Key
主键约束表示表的一列或一组列是唯一的,并且不包含 null。主键唯一标识表中的行。
源表的主键是用于优化的元数据信息。接收器表的主键通常由接收器实现用于更新插入。
SQL 标准指定约束可以 ENFORCED或 NOT ENFORCED。这将控制是否对传入/传出数据执行约束检查。Flink 不拥有数据,我们想要支持的唯一模式是非强制模式。由用户来确保查询强制实施密钥完整性。
CREATE TABLE MyTable (
MyField1 INT,
MyField2 STRING,
MyField3 BOOLEAN,
PRIMARY KEY (MyField1, MyField2) NOT ENFORCED -- defines a primary key on columns
) WITH (
...
)
8、Time Attributes
使用无界流式处理表时,时间属性至关重要。因此,可以将 proctime 和 rowtime 属性定义为schema的一部分。
有关 Flink 中时间处理的更多信息,尤其是事件时间,请参阅15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置。
9、Proctime Attributes
为了在schema中声明 proctime 属性,可以使用计算列语法来声明从 PROCTIME() 内置函数生成的计算列。计算列是不存储在物理数据中的虚拟列。
CREATE TABLE MyTable (
MyField1 INT,
MyField2 STRING,
MyField3 BOOLEAN,
MyField4 AS PROCTIME() -- declares a proctime attribute
) WITH (
...
)
10、Rowtime Attributes
为了控制表的事件时间行为,Flink 提供了预定义的时间戳提取器和水印策略。
请参考 创建 TABLE 语句,了解有关在22、Flink 的table api与sql之创建表的DDL的更多信息。
支持以下时间戳提取器:
-- use the existing TIMESTAMP(3) field in schema as the rowtime attribute
CREATE TABLE MyTable (
ts_field TIMESTAMP(3),
WATERMARK FOR ts_field AS ...
) WITH (
...
)
-- use system functions or UDFs or expressions to extract the expected TIMESTAMP(3) rowtime field
CREATE TABLE MyTable (
log_ts STRING,
ts_field AS TO_TIMESTAMP(log_ts),
WATERMARK FOR ts_field AS ...
) WITH (
...
)
支持以下水印策略:
-- Sets a watermark strategy for strictly ascending rowtime attributes. Emits a watermark of the
-- maximum observed timestamp so far. Rows that have a timestamp bigger to the max timestamp
-- are not late.
CREATE TABLE MyTable (
ts_field TIMESTAMP(3),
WATERMARK FOR ts_field AS ts_field
) WITH (
...
)
-- Sets a watermark strategy for ascending rowtime attributes. Emits a watermark of the maximum
-- observed timestamp so far minus 1. Rows that have a timestamp bigger or equal to the max timestamp
-- are not late.
CREATE TABLE MyTable (
ts_field TIMESTAMP(3),
WATERMARK FOR ts_field AS ts_field - INTERVAL '0.001' SECOND
) WITH (
...
)
-- Sets a watermark strategy for rowtime attributes which are out-of-order by a bounded time interval.
-- Emits watermarks which are the maximum observed timestamp minus the specified delay, e.g. 2 seconds.
CREATE TABLE MyTable (
ts_field TIMESTAMP(3),
WATERMARK FOR ts_field AS ts_field - INTERVAL '2' SECOND
) WITH (
...
)
11、完整示例
本示例flink cli 执行
1)、建表
CREATE TABLE t1 (
`id` INT,
name STRING,
age BIGINT,
t_insert_time TIMESTAMP(3) METADATA FROM 'timestamp',
WATERMARK FOR t_insert_time as t_insert_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't_kafkasource',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'format' = 'csv'
);
2)、测试数据
1,alan,15
2,alanchan,20
3,alanchanchn,25
4,alan_chan,30
5,alan_chan_chn,45
[root@server2 bin]# kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource
>1,alan,15
>2,alanchan,20
>3,alanchanchn,25
>4,alan_chan,30
>5,alan_chan_chn,45
----kafka相关操作命令
kafka-topics.sh --delete --topic t_kafkasource --bootstrap-server server1:9092
kafka-topics.sh --create --bootstrap-server server1:9092 --topic t_kafkasource --partitions 1 --replication-factor 1
kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource
3)、展示结果
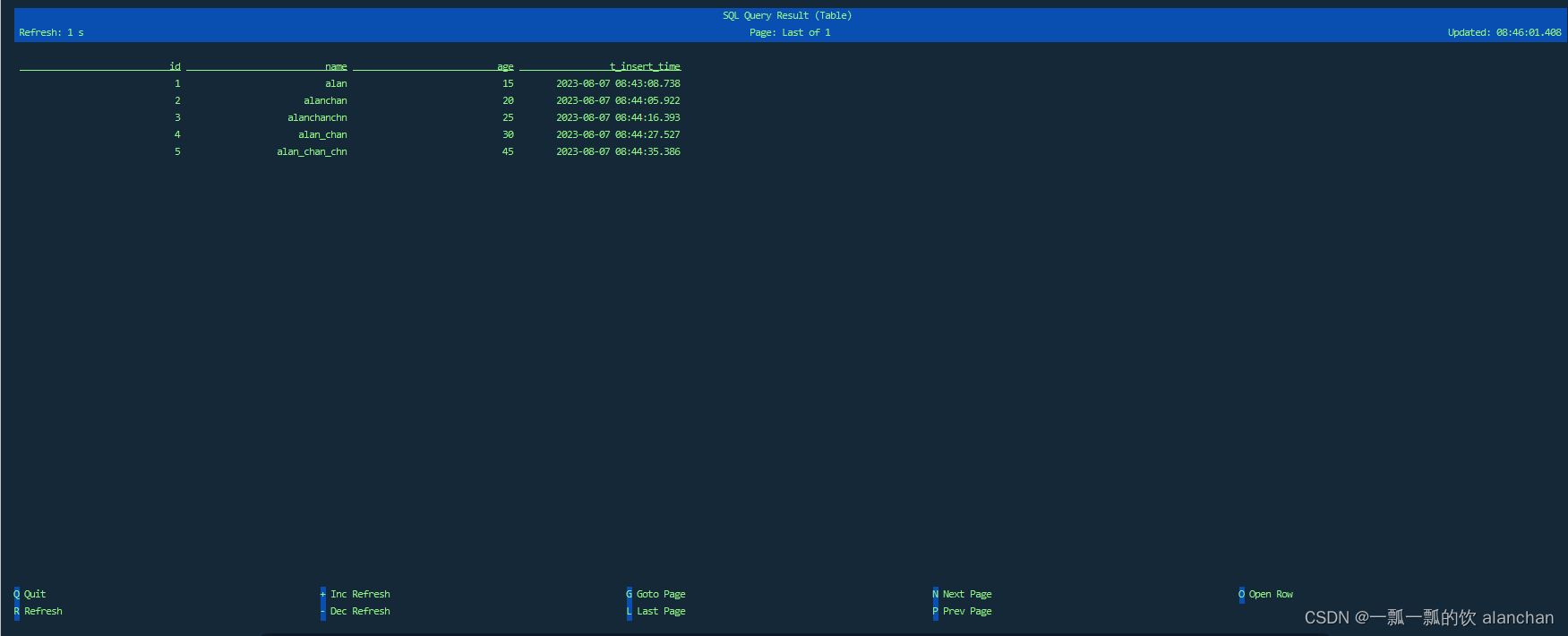
确保始终声明时间戳和水印。触发 time-based的操作需要水印。
12、SQL Types
关于数据类型,请参考14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
二、Table & SQL Connectors 示例: Filesystem
1、Filesystem的依赖
Apache Flink 使用文件系统来消费和持久化地存储数据,以处理应用结果以及容错与恢复。以下是一些最常用的文件系统:本地存储,hadoop-compatible,Amazon S3,阿里云 OSS 和 Azure Blob Storage。
文件使用的文件系统通过其 URI Scheme 指定。例如 file:///home/user/text.txt 表示一个在本地文件系统中的文件,hdfs://server1:8020/flink/test/text.txt 表示一个在指定 HDFS 集群中的文件。
文件系统在每个进程实例化一次,然后进行缓存/池化,从而避免每次创建流时的配置开销,并强制执行特定的约束,如连接/流的限制。
1)、本地文件
Flink 原生支持本地机器上的文件系统,包括任何挂载到本地文件系统的 NFS 或 SAN 驱动器,默认即可使用,无需额外配置。本地文件可通过 file:// URI Scheme 引用。
2)、外部文件系统
Apache Flink 支持下列文件系统:
- Amazon S3 对象存储由 flink-s3-fs-presto 和 flink-s3-fs-hadoop 两种替代实现提供支持。这两种实现都是独立的,没有依赖项。
- 阿里云对象存储 由 flink-oss-fs-hadoop 支持,并通过 oss:// URI scheme 使用。该实现基于 Hadoop Project,但其是独立的,没有依赖项。
- Azure Blob Storage 由flink-azure-fs-hadoop 支持,并通过 abfs(s):// 和 wasb(s):// URI scheme 使用。该实现基于 Hadoop Project,但其是独立的,没有依赖项。
- Google Cloud Storage 由gcs-connector 支持,并通过 gs:// URI scheme 使用。该实现基于 Hadoop Project,但其是独立的,没有依赖项。
上述文件系统可以并且需要作为插件使用。
使用外部文件系统时,在启动 Flink 之前需将对应的 JAR 文件从 opt 目录复制到 Flink 发行版 plugin 目录下的某一文件夹中,例如:
mkdir ./plugins/s3-fs-hadoop
cp ./opt/flink-s3-fs-hadoop-1.17.1.jar ./plugins/s3-fs-hadoop/
文件系统的插件机制在 Flink 版本 1.9 中引入,以支持每个插件专有 Java 类加载器,并避免类隐藏机制。您仍然可以通过旧机制使用文件系统,即将对应的 JAR 文件复制到 lib 目录中,或使用您自己的实现方式,但是从版本 1.10 开始,S3 插件必须通过插件机制加载,因为这些插件不再被隐藏(版本 1.10 之后类不再被重定位),旧机制不再可用。
尽可能通过基于插件的加载机制使用支持的文件系统。未来的 Flink 版本将不再支持通过 lib 目录加载文件系统组件。
3)、添加新的外部文件系统实现
文件系统由类 org.apache.flink.core.fs.FileSystem 表示,该类定义了访问与修改文件系统中文件与对象的方法。
要添加一个新的文件系统:
- 添加文件系统实现,它应是 org.apache.flink.core.fs.FileSystem 的子类。
- 添加 Factory 类,以实例化该文件系统并声明文件系统所注册的 scheme, 它应是 org.apache.flink.core.fs.FileSystemFactory 的子类。
- 添加 Service Entry。创建文件 META-INF/services/org.apache.flink.core.fs.FileSystemFactory,文件中包含文件系统 Factory 类的类名。
在插件检索时,文件系统 Factory 类会由一个专用的 Java 类加载器加载,从而避免与其他类或 Flink 组件冲突。在文件系统实例化和文件系统调用时,应使用该类加载器。
实际上这表示您的实现应避免使用 Thread.currentThread().getContextClassLoader() 类加载器。
4)、Hadoop 文件系统 (HDFS) 及其其他实现
所有 Flink 无法找到直接支持的文件系统均将回退为 Hadoop。 当 flink-runtime 和 Hadoop 类包含在 classpath 中时,所有的 Hadoop 文件系统将自动可用。
因此,Flink 无缝支持所有实现 org.apache.hadoop.fs.FileSystem 接口的 Hadoop 文件系统和所有兼容 Hadoop 的文件系统 (Hadoop-compatible file system, HCFS):
- HDFS (已测试)
- Google Cloud Storage Connector for Hadoop(已测试)
- Alluxio(已测试,参见下文的配置详细信息)
- XtreemFS(已测试)
- FTP via Hftp(未测试)
- HAR(未测试)
…
Hadoop 配置须在 core-site.xml 文件中包含所需文件系统的实现。
除非有其他的需要,建议使用 Flink 内置的文件系统。在某些情况下,如通过配置 Hadoop core-site.xml 中的 fs.defaultFS 属性将文件系统作为 YARN 的资源存储时,可能需要直接使用 Hadoop 文件系统。
- Alluxio示例
在 core-site.xml 文件中添加以下条目以支持 Alluxio:
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
</property>
2、文件系统 SQL 连接器
此连接器提供了对 Flink FileSystem abstraction 支持的文件系统中分区文件的访问。
在 Flink 中包含了该文件系统连接器,不需要添加额外的依赖。相应的 jar 包可以在 Flink 工程项目的 /lib 目录下找到。从文件系统中读取或者向文件系统中写入行时,需要指定相应的 format。
文件系统连接器允许从本地或分布式文件系统进行读写。文件系统表可以定义为:
CREATE TABLE MyUserTable (
column_name1 INT,
column_name2 STRING,
...
part_name1 INT,
part_name2 STRING
) PARTITIONED BY (part_name1, part_name2) WITH (
'connector' = 'filesystem', -- 必选:指定连接器类型
'path' = 'file:///path/to/whatever', -- 必选:指定路径
'format' = '...', -- 必选:文件系统连接器指定 format
-- 有关更多详情,请参考 Table Formats
'partition.default-name' = '...', -- 可选:默认的分区名,动态分区模式下分区字段值是 null 或空字符串
-- 可选:该属性开启了在 sink 阶段通过动态分区字段来 shuffle 数据,该功能可以大大减少文件系统 sink 的文件数,但是可能会导致数据倾斜,默认值是 false
'sink.shuffle-by-partition.enable' = '...',
...
)
#具体事例
CREATE TABLE AlanChanUserTable_hdfs_2 (
`id` INT,
name STRING,
age BIGINT,
dt STRING,
`mins` STRING
) PARTITIONED BY (dt, `mins`) WITH (
'connector'='filesystem',
'path' = 'hdfs://server2:8020/flinktest/sql3/',
'format'='csv',
'sink.partition-commit.delay'='10 s',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.watermark-time-zone'='Asia/Shanghai', -- 假设用户配置的时区为 'Asia/Shanghai',
'sink.partition-commit.policy.kind'='success-file'
);
请确保包含 Flink File System 依赖已经完成配置且可用。
文件系统连接器的特性与 previous legacy filesystem connector 有很大不同: path 属性指定的是目录,而不是文件,该目录下的文件也不是肉眼可读的。
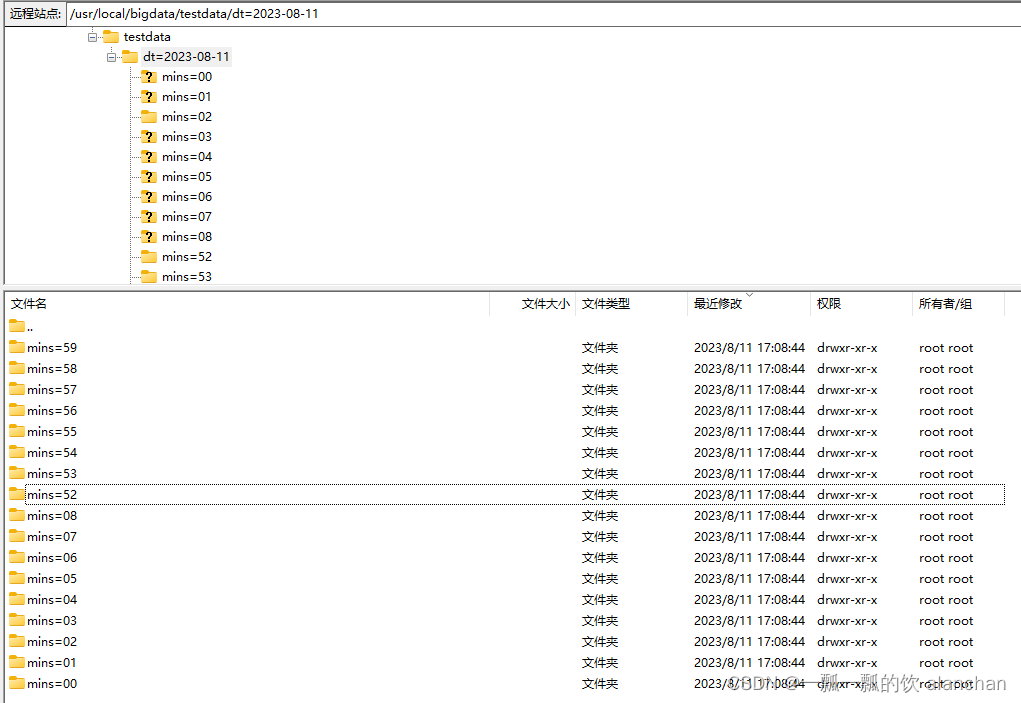
1)、分区文件
Flink 的文件系统连接器支持分区,使用了标准的 hive。但是,不需要预先注册分区到 table catalog,而是基于目录结构自动做了分区发现。例如,根据下面的目录结构,分区表将被推断包含 dt 和 mins分区。
-
file
-
hdfs
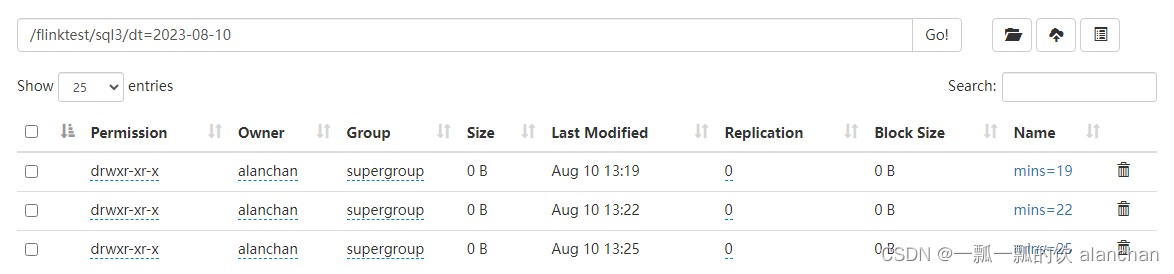
文件系统表支持分区新增插入和分区覆盖插入。请参考 Flink(二十八)Flink 的SQL之DROP 语句、ALTER 语句、INSERT 语句、ANALYZE 语句 。当对分区表进行分区覆盖插入时,只有相应的分区会被覆盖,而不是整个表。
2)、File Formats
文件系统连接器支持多种 format:
- CSV:RFC-4180。是非压缩的。
- JSON:文件系统连接器的 JSON format 与传统的标准的 JSON file 的不同,而是非压缩的。换行符分割的 JSON。
- Avro:Apache Avro。通过配置 avro.codec 属性支持压缩。
- Parquet:Apache Parquet。兼容 hive。
- Orc:Apache Orc。兼容 hive。
- Debezium-JSON:debezium-json。
- Canal-JSON:canal-json。
- Raw:raw。
3)、Source
文件系统连接器可用于将单个文件或整个目录的数据读取到单个表中。
当使用目录作为 source 路径时,对目录中的文件进行 无序的读取。
1、目录监控
默认情况下,文件系统连接器是有界的,也就是只会扫描配置路径一遍后就会停止。
如果需要,可以通过设置 source.monitor-interval 属性来开启目录监控,以便在新文件出现时继续扫描。

2、可用的 Metadata
以下连接器 metadata 可以在表定义时作为 metadata 列进行访问。所有 metadata 都是只读的。
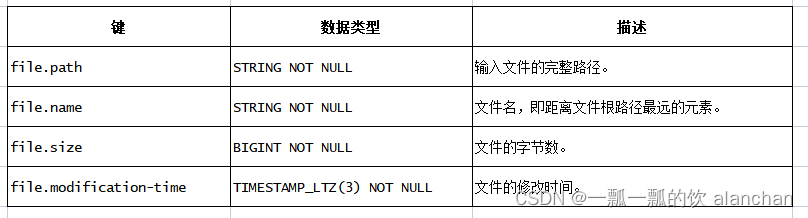
扩展的 CREATE TABLE 示例演示了标识某个字段为 metadata 的语法:
CREATE TABLE MyUserTableWithFilepath (
column_name1 INT,
column_name2 STRING,
`file.path` STRING NOT NULL METADATA
) WITH (
'connector' = 'filesystem',
'path' = 'file:///path/to/whatever',
'format' = 'json'
)
4)、Streaming Sink
文件系统连接器支持流写入,是基于 Flink 的 Flink(三十四)Flink 的Datastream connector之文件系统 写入文件的。CSV 和 JSON 使用的是 Row-encoded Format。Parquet、ORC 和 Avro 使用的是 Bulk-encoded Format。
可以直接编写 SQL,将流数据插入到非分区表。 如果是分区表,可以配置分区操作相关的属性。请参考本文的分区提交部分了解更多详情。
1、滚动策略
分区目录下的数据被分割到 part 文件中。每个分区对应的 sink 的收到的数据的 subtask 都至少会为该分区生成一个 part 文件。根据可配置的滚动策略,当前 in-progress part 文件将被关闭,生成新的 part 文件。该策略基于大小,和指定的文件可被打开的最大 timeout 时长,来滚动 part 文件。
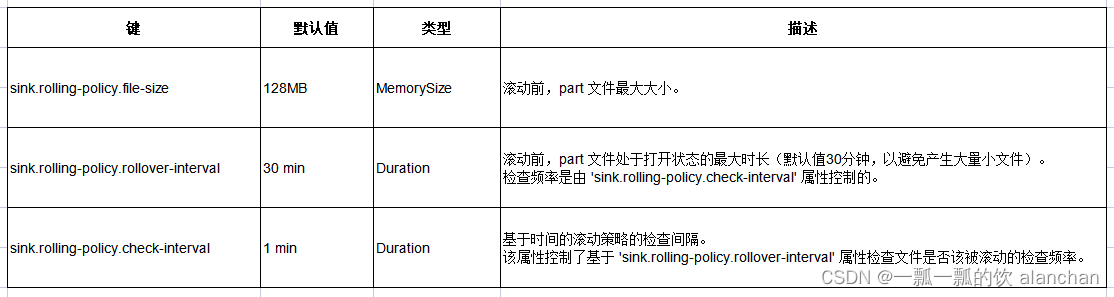
下面这段话非常重要,不同的文件格式配置方式不同。
对于 bulk formats 数据 (parquet、orc、avro),滚动策略与 checkpoint 间隔(pending 状态的文件会在下个 checkpoint 完成)控制了 part 文件的大小和个数。
对于 row formats 数据 (csv、json),如果想使得分区文件更快在文件系统中可见,可以设置 sink.rolling-policy.file-size 或 sink.rolling-policy.rollover-interval 属性以及在 flink-conf.yaml 中的 execution.checkpointing.interval 属性。 对于其他 formats (avro、orc),可以只设置 flink-conf.yaml 中的 execution.checkpointing.interval 属性。
2、文件合并
file sink 支持文件合并,允许应用程序使用较小的 checkpoint 间隔而不产生大量小文件。
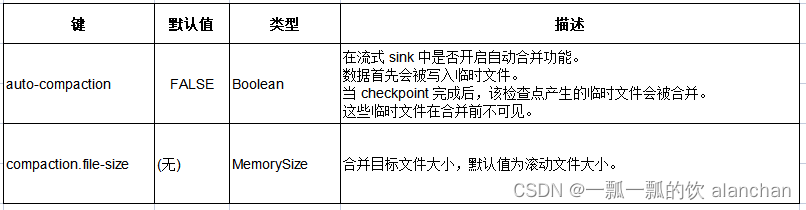
如果启用文件合并功能,会根据目标文件大小,将多个小文件合并成大文件。 在生产环境中使用文件合并功能时,需要注意:
- 只有 checkpoint 内部的文件才会被合并,至少生成的文件个数与 checkpoint 个数相同。
- 合并前文件是不可见的,那么文件的可见时间是:checkpoint 间隔时长 + 合并时长。
- 如果合并时间过长,将导致反压,延长 checkpoint 所需时间。
3、分区提交
数据写入分区之后,通常需要通知下游应用。例如,在 hive metadata 中新增分区或者在目录下生成 _SUCCESS 文件。分区提交策略是可定制的。具体分区提交行为是基于 triggers 和 policies 的组合。
- Trigger:分区提交时机,可以基于从分区中提取的时间对应的 watermark,或者基于处理时间。
- Policy:分区提交策略,内置策略包括生成 _SUCCESS 文件和提交 hive metastore,也可以实现自定义策略,例如触发 hive 生成统计信息,合并小文件等。
分区提交仅在动态分区插入模式下才有效。
1)、分区提交触发器
通过配置分区提交触发策略,来决定何时提交分区:
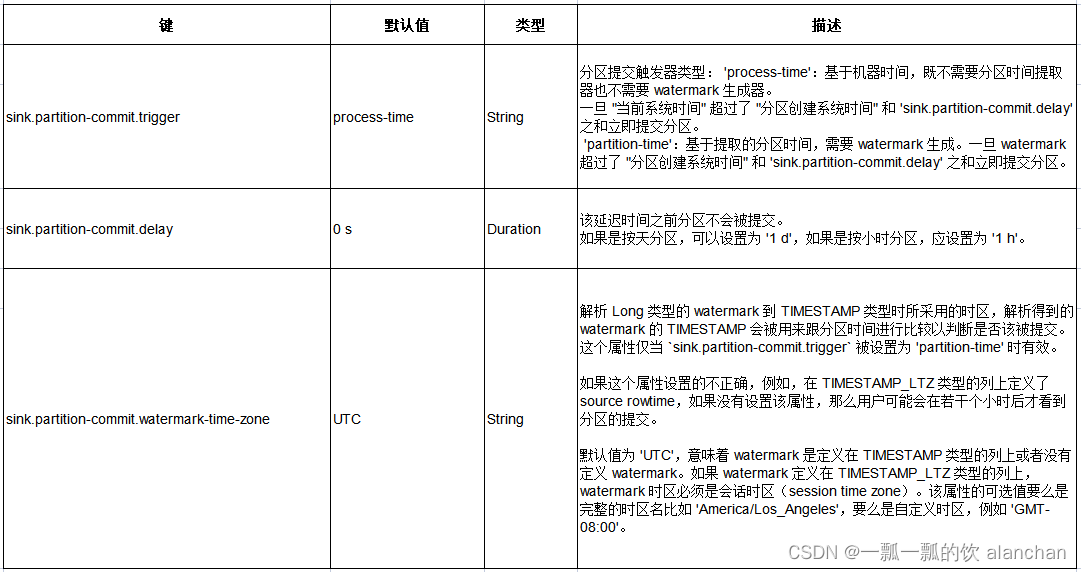
Flink 提供了两种类型分区提交触发器:
- 第一种是根据分区的处理时间。既不需要额外的分区时间,也不需要 watermark 生成。这种分区提交触发器基于分区创建时间和当前系统时间。 这种触发器更具通用性,但不是很精确。例如,数据延迟或故障将导致过早提交分区。
- 第二种是根据从分区字段提取的时间以及 watermark。 这需要 job 支持 watermark 生成,分区是根据时间来切割的,例如,按小时或按天分区。
不管分区数据是否完整而只想让下游尽快感知到分区:
- ‘sink.partition-commit.trigger’=‘process-time’ (默认值)
- ‘sink.partition-commit.delay’=‘0s’ (默认值) 一旦数据进入分区,将立即提交分区。注意:这个分区可能会被提交多次。
如果想让下游只有在分区数据完整时才感知到分区,并且 job 中有 watermark 生成,也能从分区字段的值中提取到时间:
- ‘sink.partition-commit.trigger’=‘partition-time’
- ‘sink.partition-commit.delay’=‘1h’ (根据分区类型指定,如果是按小时分区可配置为 ‘1h’) 该方式是最精准地提交分区的方式,尽力确保提交分区的数据完整。
如果想让下游系统只有在数据完整时才感知到分区,但是没有 watermark,或者无法从分区字段的值中提取时间:
- ‘sink.partition-commit.trigger’=‘process-time’ (默认值)
- ‘sink.partition-commit.delay’=‘1h’ (根据分区类型指定,如果是按小时分区可配置为 ‘1h’) 该方式尽量精确地提交分区,但是数据延迟或者故障将导致过早提交分区。
延迟数据的处理:延迟的记录会被写入到已经提交的对应分区中,且会再次触发该分区的提交。
2)、分区时间提取器
时间提取器从分区字段值中提取时间。
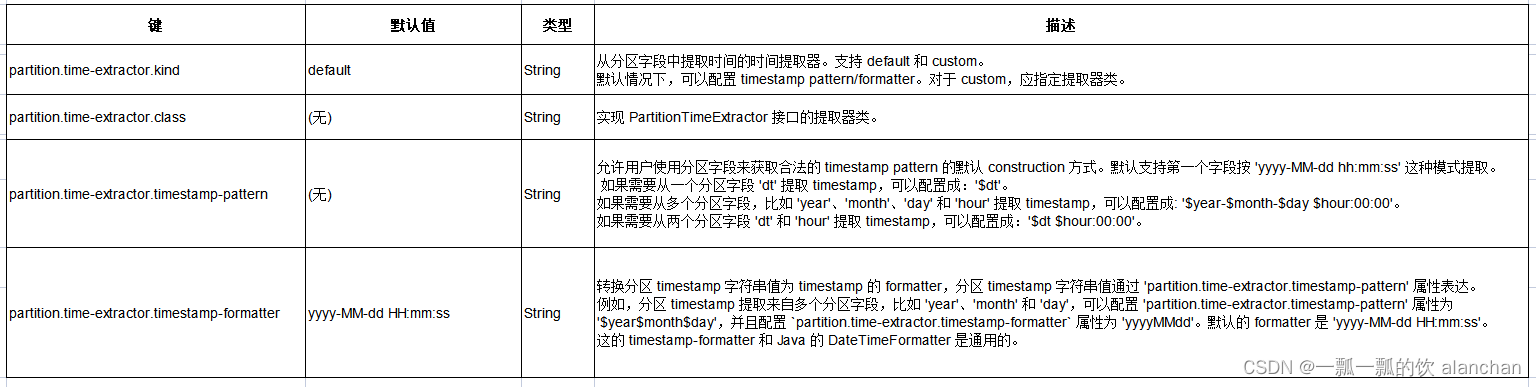
默认情况下,提取器基于由分区字段组成的 timestamp pattern。也可以指定一个实现接口 PartitionTimeExtractor 的自定义提取器。
public class HourPartTimeExtractor implements PartitionTimeExtractor {
@Override
public LocalDateTime extract(List<String> keys, List<String> values) {
String dt = values.get(0);
String hour = values.get(1);
return Timestamp.valueOf(dt + " " + hour + ":00:00").toLocalDateTime();
}
}
5)、分区提交策略
分区提交策略定义了提交分区时的具体操作。
- 第一种是 metadata 存储(metastore),仅 hive 表支持该策略,该策略下文件系统通过目录层次结构来管理分区。
- 第二种是 success 文件,该策略下会在分区对应的目录下生成一个名为 _SUCCESS 的空文件。
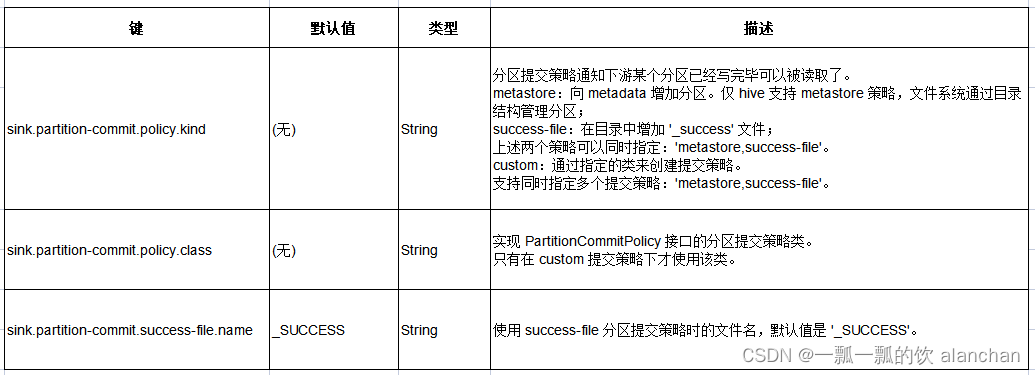
也可以自定义提交策略,例如:
public class AnalysisCommitPolicy implements PartitionCommitPolicy {
private HiveShell hiveShell;
@Override
public void commit(Context context) throws Exception {
if (hiveShell == null) {
hiveShell = createHiveShell(context.catalogName());
}
hiveShell.execute(String.format(
"ALTER TABLE %s ADD IF NOT EXISTS PARTITION (%s = '%s') location '%s'",
context.tableName(),
context.partitionKeys().get(0),
context.partitionValues().get(0),
context.partitionPath()));
hiveShell.execute(String.format(
"ANALYZE TABLE %s PARTITION (%s = '%s') COMPUTE STATISTICS FOR COLUMNS",
context.tableName(),
context.partitionKeys().get(0),
context.partitionValues().get(0)));
}
}
5)、Sink Parallelism
在流模式和批模式下,向外部文件系统(包括 hive)写文件时的 parallelism 可以通过相应的 table 配置项指定。默认情况下,该 sink parallelism 与上游 chained operator 的 parallelism 一样。当配置了跟上游的 chained operator 不一样的 parallelism 时,写文件和合并文件的算子(如果开启的话)会使用指定的 sink parallelism。

目前,当且仅当上游的 changelog 模式为 INSERT-ONLY 时,才支持配置 sink parallelism。否则,程序将会抛出异常。
6)、示例
注意:该示例运行环境需要配置checkpoint,否则需要等任务运行完成后才能查询得到结果,一般流式获取数据,任务是不会结束的,故而不能查询到数据。
如此,如果是一般数据格式环境需要设置sink.rolling-policy.rollover-interval和execution.checkpointing.interval参数才能查得到数据,如果是parquet、orc、avro格式文件,只需要设置execution.checkpointing.interval参数即可。
以下示例展示了如何使用文件系统连接器编写流式查询语句,将数据从 Kafka 写入文件系统,然后运行批式查询语句读取数据。
运行环境可以是flink 1.13.5或1.17.0版本,示例均在该2个环境中验证通过。
--- 创建kafka消息接收表
CREATE TABLE alanchan_kafka_table (
`id` INT,
name STRING,
age BIGINT,
t_insert_time TIMESTAMP(3) METADATA FROM 'timestamp',
WATERMARK FOR t_insert_time as t_insert_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 't_kafkasource',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'format' = 'csv'
);
-- 创建将kafka消息表接收到文件系统表,此处为一个分区表,特别注意不同的文件格式对不同的滚动策略的设置
-- 需要设置sink.rolling-policy.rollover-interval 和 execution.checkpointing.interval 参数才可以及时的查询到结果
CREATE TABLE AlanChanUserTable_hdfs_2 (
`id` INT,
name STRING,
age BIGINT,
dt STRING,
`mins` STRING
) PARTITIONED BY (dt, `mins`) WITH (
'connector'='filesystem',
'path' = 'hdfs://server2:8020/flinktest/sql5/',
'format'='csv',
'sink.partition-commit.delay'='10 s',
'sink.partition-commit.watermark-time-zone'='Asia/Shanghai', -- 假设用户配置的时区为 'Asia/Shanghai',
'sink.partition-commit.policy.kind'='success-file',
'sink.rolling-policy.rollover-interval'='5s'
);
-- 流式 sql,插入文件系统表
INSERT INTO AlanChanUserTable_hdfs_2
SELECT
`id` ,
name ,
age ,
DATE_FORMAT(t_insert_time, 'yyyy-MM-dd'),
DATE_FORMAT(t_insert_time, 'mm')
FROM alanchan_kafka_table;
-- 批式 sql,使用分区查询,也可以不分区查询
SELECT * FROM AlanChanUserTable_hdfs_2 WHERE dt='2023-08-21' and `mins`='30';
---------------------------------------------------------------------------------
--验证结果
1、kafka消息
[alanchan@server3 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource
>1,alan,15
>
2、hdfs分区信息
[alanchan@server2 bin]$ hadoop fs -ls /flinktest/sql5
Found 1 items
drwxr-xr-x - alanchan supergroup 0 2023-08-21 00:32 /flinktest/sql5/dt=2023-08-21
[alanchan@server2 bin]$ hadoop fs -ls /flinktest/sql5/dt=2023-08-21
Found 1 items
drwxr-xr-x - alanchan supergroup 0 2023-08-21 00:33 /flinktest/sql5/dt=2023-08-21/mins=29
[alanchan@server2 bin]$ hadoop fs -ls /flinktest/sql5/dt=2023-08-21/mins=29
Found 2 items
-rw-r--r-- 3 alanchan supergroup 0 2023-08-21 00:33 /flinktest/sql5/dt=2023-08-21/mins=29/_SUCCESS
-rw-r--r-- 3 alanchan supergroup 10 2023-08-21 00:33 /flinktest/sql5/dt=2023-08-21/mins=29/part-6c05b8ac-fb76-4026-a302-b219e5c3b4a5-0-0
3、flink sql 查询结果
Flink SQL> SELECT * FROM AlanChanUserTable_hdfs_2 WHERE dt='2023-08-21' and `mins`='29';
2023-08-21 00:33:47,691 INFO org.apache.hadoop.yarn.client.AHSProxy [] - Connecting to Application History server at server1/192.168.10.41:10200
2023-08-21 00:33:47,691 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2023-08-21 00:33:47,694 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface server4:40896 of application 'application_1688448920799_0009'.
+----+-------------+--------------------------------+----------------------+--------------------------------+--------------------------------+
| op | id | name | age | dt | mins |
+----+-------------+--------------------------------+----------------------+--------------------------------+--------------------------------+
| +I | 1 | alan | 15 | 2023-08-21 | 29 |
+----+-------------+--------------------------------+----------------------+--------------------------------+--------------------------------+
Received a total of 1 row
如果 watermark 被定义在 TIMESTAMP_LTZ 类型的列上并且使用 partition-time 模式进行提交,sink.partition-commit.watermark-time-zone 这个属性需要设置成会话时区,否则分区提交可能会延迟若干个小时。
CREATE TABLE alanchan_kafka_table2 (
`id` INT,
name STRING,
age BIGINT,
ts BIGINT, -- 以毫秒为单位的时间
t_insert_time AS TO_TIMESTAMP_LTZ(ts,3),
WATERMARK FOR t_insert_time AS t_insert_time - INTERVAL '5' SECOND -- 在 TIMESTAMP_LTZ 列上定义 watermark
) WITH (
'connector' = 'kafka',
'topic' = 't_kafkasource2',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'format' = 'csv'
);
CREATE TABLE AlanChanUserTable_hdfs_3 (
`id` INT,
name STRING,
age BIGINT,
dt STRING,
`mins` STRING
) PARTITIONED BY (dt, `mins`) WITH (
'connector'='filesystem',
'path' = 'hdfs://server2:8020/flinktest/sql6/',
'format'='csv',
'partition.time-extractor.timestamp-pattern'='$dt 00:$mins:00',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='10 s',
'sink.partition-commit.watermark-time-zone'='Asia/Shanghai', -- 假设用户配置的时区为 'Asia/Shanghai',
'sink.partition-commit.policy.kind'='success-file',
'sink.rolling-policy.rollover-interval'='5s'
);
-- 流式 sql,插入文件系统表
INSERT INTO AlanChanUserTable_hdfs_3
SELECT
`id` ,
name ,
age ,
DATE_FORMAT(t_insert_time, 'yyyy-MM-dd'),
DATE_FORMAT(t_insert_time, 'mm')
FROM alanchan_kafka_table2;
-- 批式 sql,使用分区修剪进行选择
select * from AlanChanUserTable_hdfs_3 where dt='2023-08-21' and `mins`='51';
------------------------------验证结果----------------------------------------
1、kafka topic中输入数据
[alanchan@server3 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource2
>1,alan,15,1692593500222
>2,alanchan,20,1692593501230
>3,alanchanchn,25,1692593502242
>4,alan_chan,30,1692593503256
>5,alan_chan_chn,45,1692593504270
2、查询hdfs目录结构
[alanchan@server2 bin]$ hadoop fs -ls /flinktest/sql6/dt=2023-08-21/mins=51
Found 4 items
-rw-r--r-- 3 alanchan supergroup 0 2023-08-21 05:01 /flinktest/sql6/dt=2023-08-21/mins=51/_SUCCESS
-rw-r--r-- 3 alanchan supergroup 10 2023-08-21 04:58 /flinktest/sql6/dt=2023-08-21/mins=51/part-5c46b8f3-9421-4ca1-a6f8-8c812337fe21-0-0
-rw-r--r-- 3 alanchan supergroup 14 2023-08-21 04:59 /flinktest/sql6/dt=2023-08-21/mins=51/part-5c46b8f3-9421-4ca1-a6f8-8c812337fe21-0-1
-rw-r--r-- 3 alanchan supergroup 51 2023-08-21 05:00 /flinktest/sql6/dt=2023-08-21/mins=51/part-5c46b8f3-9421-4ca1-a6f8-8c812337fe21-0-2
3、查询数据
Flink SQL> select * from AlanChanUserTable_hdfs_3 where dt='2023-08-21' and `mins`='51';
2023-08-21 05:01:08,196 INFO org.apache.hadoop.yarn.client.AHSProxy [] - Connecting to Application History server at server1/192.168.10.41:10200
2023-08-21 05:01:08,196 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2023-08-21 05:01:08,199 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface server4:40896 of application 'application_1688448920799_0009'.
+----+-------------+--------------------------------+----------------------+--------------------------------+--------------------------------+
| op | id | name | age | dt | mins |
+----+-------------+--------------------------------+----------------------+--------------------------------+--------------------------------+
| +I | 3 | alanchanchn | 25 | 2023-08-21 | 51 |
| +I | 4 | alan_chan | 30 | 2023-08-21 | 51 |
| +I | 5 | alan_chan_chn | 45 | 2023-08-21 | 51 |
| +I | 1 | alan | 15 | 2023-08-21 | 51 |
| +I | 2 | alanchan | 20 | 2023-08-21 | 51 |
+----+-------------+--------------------------------+----------------------+--------------------------------+--------------------------------+
Received a total of 5 rows
以上,简单的介绍了Filesystem文件的使用及可运行环境的示例。