文章目录
- 一、什么是RLHF?
- 二、RLHF适用于哪些任务?
- 三、RLHF和其他构建奖励模型的方法相比有何优劣?
- 四、什么样的人类反馈才是好的反馈
- 五、RLHF算法有哪些类别,各有什么优缺点?
- 七、如何降低人类反馈带来的负面影响?
- 八、阅读本书将会给我带来什么?
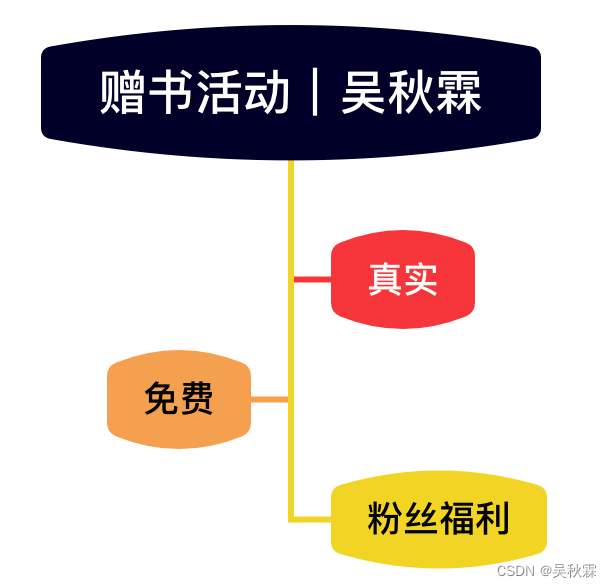
声明:赠书活动是博主与出版社达成合作,只属于粉丝的专属福利
本期书籍:《强化学习:原理与Python实战》
参与方式:关注博主在其评论区:点赞|收藏|留言
评论区留言:“Python实战为王”
活动截止时间::2023年8月26日
赠送数量::3~5本
时间截止将会在次日晚8点在动态更新中奖名单!中奖后博主会私信通知 | 三天内不回复将视为 | 自动放弃

本书籍理论完备,涵盖强化学习主干理论和常见算法,带你参透ChatGPT技术要点;
实战性强,每章都有编程案例,深度强化学习算法提供TenorFlow和PyTorch对照实现;
配套丰富,逐章提供知识点总结,章后习题形式丰富多样。还有Gym源码解读、开发环境搭建指南、习题答案等在线资源助力自学!
一、什么是RLHF?
强化学习利用奖励信号训练智能体。有些任务并没有自带能给出奖励信号的环境,也没有现成的生成奖励信号的方法。为此,可以搭建奖励模型来提供奖励信号。在搭建奖励模型时,可以用数据驱动的机器学习方法来训练奖励模型,并且由人类提供数据。我们把这样的利用人类提供的反馈数据来训练奖励模型以用于强化学习的系统称为人类反馈强化学习:
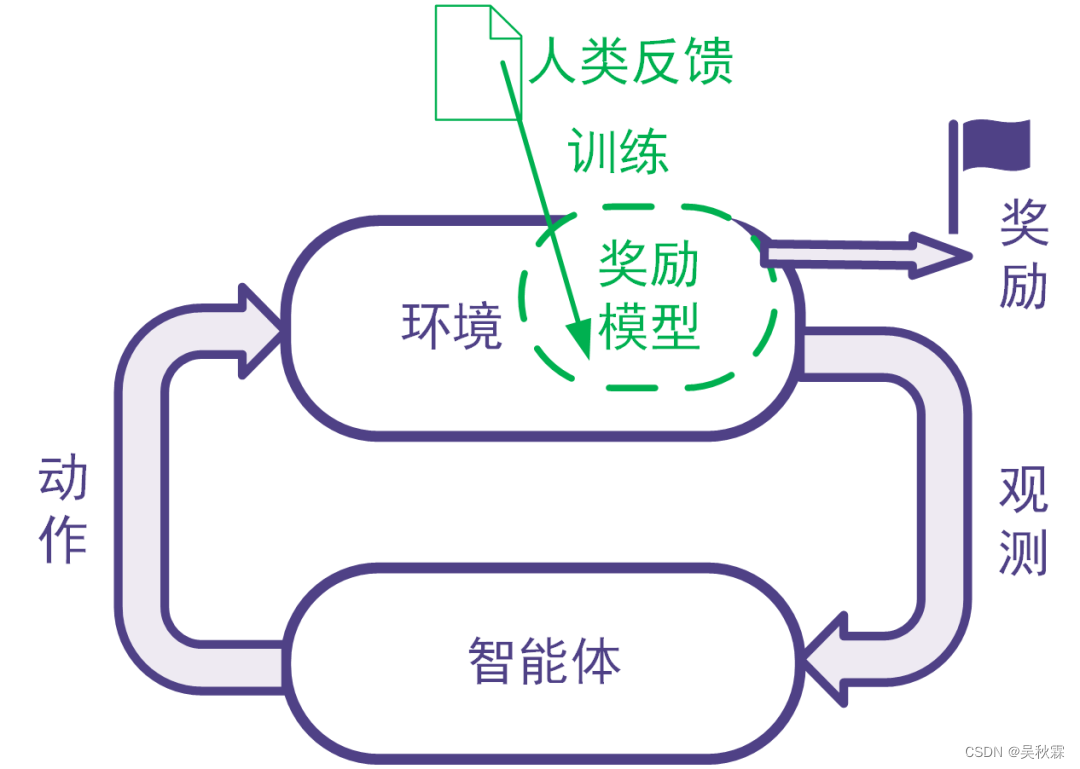
二、RLHF适用于哪些任务?
- 要解决的任务是一个强化学习任务,但是没有现成的奖励信号并且奖励信号的确定方式事先不知道。为了训练强化学习智能体,考虑构建奖励模型来得到奖励信号。
反例:比如电动游戏有游戏得分,那样的游戏程序能够给奖励信号,那我们直接用游戏程序反馈即可,不需要人类反馈。
反例:某些系统奖励信号的确定方式是已知的,比如交易系统的奖励信号可以由赚到的钱完全确定。这时直接可以用已知的数学表达式确定奖励信号,不需要人工反馈。 - 不采用人类反馈的数据难以构建合适的奖励模型,而且人类的反馈可以帮助得到合适的奖励模型,并且人类来提供反馈可以在合理的代价(包括成本代价、时间代价等)内得到。如果用人类反馈得到数据与其他方法采集得到数据相比不具有优势,那么就没有必要让人类来反馈
三、RLHF和其他构建奖励模型的方法相比有何优劣?
奖励模型可以人工指定,也可以通过有监督模型、逆强化学习等机器学习方法来学习。RLHF使用机器学习方法学习奖励模型,并且在学习过程中采用人类给出的反馈。
比较人工指定奖励模型与采用机器学习方法学习奖励模型的优劣:这与对一般的机器学习优劣的讨论相同。机器学习方法的优点包括不需要太多领域知识、能够处理非常复杂的问题、能够处理快速大量的高维数据、能够随着数据增大提升精度等等。机器学习算法的缺陷包括其训练和使用需要数据时间空间电力等资源、模型和输出的解释型可能不好、模型可能有缺陷、覆盖范围不够或是被攻击(比如大模型里的提示词注入)。
比较采用人工反馈数据和采用非人工反馈数据的优劣:人工反馈往往更费时费力,并且不同人在不同时候的表现可能不一致,并且人还会有意无意地犯错,或是人类反馈的结果还不如用其他方法生成数据来的有效,等等。我们在后文会详细探讨人工反馈的局限性。采用机器收集数据等非人工反馈数据则对收集的数据类型有局限性。有些数据只能靠人类收集,或是用机器难以收集。这样的数据包括是主观的、人文的数据(比如判断艺术作品的艺术性),或是某些机器还做不了的事情(比如玩一个AI暂时还不如人类的游戏)
四、什么样的人类反馈才是好的反馈
- 好的反馈需要够用:反馈数据可以用来学成奖励模型,并且数据足够正确、量足够大、覆盖足够全面,使得奖励模型足够好,进而在后续的强化学习中得到令人满意的智能体。
这个部分涉及的评价指标包括:对数据本身的评价指标(正确性、数据量、覆盖率、一致性),对奖励模型及其训练过程的评价指标、对强化学习训练过程和训练得到的智能体的评价指标。 - 好的反馈需要是可得的反馈。反馈需要可以在合理的时间花费和金钱花费的情况下得到,并且在成本可控的同时不会引发其他风险(如法律上的风险)。
涉及的评价指标包括:数据准备时间、数据准备涉及的人员数量、数据准备成本、是否引发其他风险的判断
五、RLHF算法有哪些类别,各有什么优缺点?
RLHF算法有以下两大类:用监督学习的思路训练奖励模型的RLHF、用逆强化学习的思路训练奖励模型的RLHF。
1.在用监督学习的思路训练奖励模型的RLHF系统中,人类的反馈是奖励信号或是奖励信号的衍生量(如奖励信号的排序)。
直接反馈奖励信号和反馈奖励信号衍生量各有优缺点。这个优点在于获得奖励参考值后可以直接把它用作有监督学习的标签。缺点在于不同人在不同时候给出的奖励信号可能不一致,甚至矛盾。反馈奖励信号的衍生量,比如奖励模型输入的比较或排序。有些任务给出评价一致的奖励值有困难,但是比较大小容易得多。但是没有密集程度的信息。在大量类似情况导致某部分奖励对应的样本过于密集的情况下,甚至可能不收敛。
一般认为,采用比较类型的反馈可以得到更好的性能中位数,但是并不能得到更好的性能平均值。
2.在用逆强化学习的思路训练奖励模型的RLHF系统中,人类的反馈并不是奖励信号,而是使得奖励更大的奖励模型输入。即人类给出了较为正确的数量、文本、分类、物理动作等,告诉奖励模型在这时候奖励应该比较大。这其实就是逆强化学习的思想。
这种方法与用监督学习训练奖励模型的RLHF相比,其优点在于,训练奖励模型的样本点不再拘泥于系统给出的需要评判的样本。因为系统给出的需要评估奖励的样本可能具有局限性(因为系统没有找到最优的区间)。
在系统搭建初期,还可以将用户提供的参考答案用于把最初的强化学习问题转化成模仿学习问题。
这类设计还可以根据反馈的类型进一步分类,一类是让人类独立给出专家意见,另一类是在让人类在已有数据的基础上进行改进。让人类提供意见就类似于让人类提供模仿学习里的专家策略(当然可能略有不同,毕竟奖励模型的输入不只有动作)。让用户在已有的参考内容上修改可以减少人类每个标注的成本,但是已有的参考内容可能会干扰到人类的独立判断(这个干扰可能是正面的也可能是负面的)
七、如何降低人类反馈带来的负面影响?
针对人类反馈费时费力且可能导致奖励模型不完整不正确的问题,可以在收集人类反馈数据的同时就训练奖励模型、训练智能体,并全面评估奖励模型和智能体,以便于尽早发现人类反馈的缺陷。发现缺陷后,及时进行调整。
针对人类反馈中出现的反馈质量问题以及错误反馈,可以对人类反馈进行校验和审计,如引入已知奖励的校验样本来校验人类反馈的质量,或为同一样本多次索取反馈并比较多次反馈的结果等。
针对反馈人的选择不当的问题,可以在有效控制人力成本的基础上,采用科学的方法选定提供反馈的人。可以参考数理统计里的抽样方法,如分层抽样、整群抽样等,使得反馈人群更加合理。
对于反馈数据中未包括反馈人特征导致奖励模型不够好的问题,可以收集反馈人的特征,并将这些特征用于奖励模型的训练。比如,在大规模语言模型的训练中可以记录反馈人的职业背景(如律师、医生等),并在训练奖励模型时加以考虑。当用户要求智能体像律师一样工作时,更应该利用由律师提供的数据学成的那部分奖励模型来提供奖励信号;当用户要求智能体像医生一样工作时,更应该利用由医生提供的数据学成的那部分奖励模型来提供奖励信号。
另外,在整个系统的实施过程中,可以征求专业人士意见,以减小其中法律和安全风险
八、阅读本书将会给我带来什么?

好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章