https://zhuanlan.zhihu.com/p/308301901
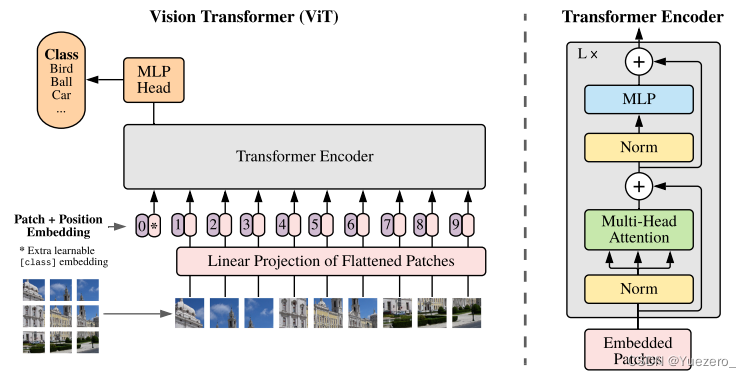
1 图片分块和降维
因为transformer encoder的输入需要序列,所以最简单做法就是把图片切分为patch,然后拉成序列即可。 假设输入图片大小是256x256,打算分成64个patch,每个patch是32x32像素:
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)
这个写法是采用了爱因斯坦表达式,具体是采用了einops库实现,内部集成了各种算子,rearrange就是其中一个,非常高效。p就是patch大小,假设输入是[b,3,256,256],则rearrange操作是先变成(b,3,8x32,8x32),最后变成(b,8x8,32x32x3)即(b,64,3072),将每张图片切分成64个小块,每个小块长度是32x32x3=3072,也就是说输入长度为64的图像序列,每个元素采用3072长度进行编码。
考虑到3072有点大,故作者先进行降维:
# 将3072变成dim,假设是1024
self.patch_to_embedding = nn.Linear(patch_dim, dim)
x = self.patch_to_embedding(x)
仔细看论文上图,可以发现假设切成9个块,但是最终到transfomer输入是10个向量,额外追加了一个0和。为啥要追加?原因是我们现在没有解码器了,而是编码后直接就进行分类预测,那么该编码器就要负责一点点解码器功能,那就是:需要一个类似开启解码标志,非常类似于标准transformer解码器中输入的目标嵌入向量右移一位操作。试下如果没有额外输入,9个块输入9个编码向量输出,那么对于分类任务而言,我应该取哪个输出向量进行后续分类呢?选择任何一个都说不通,所以作者追加了一个可学习嵌入向量输入。那么额外的可学习嵌入向量为啥要设计为可学习,而不是类似nlp中采用固定的token代替?个人不负责任的猜测这应该就是图片领域和nlp领域的差别,nlp里面每个词其实都有具体含义,是离散的,但是图像领域没有这种真正意义上的离散token,有的只是一堆连续特征或者图像像素,如果不设置为可学习,那还真不知道应该设置为啥内容比较合适,全0和全1也说不通。 自此现在就是变成10个向量输出,输出也是10个编码向量,然后取第0个编码输出进行分类预测即可。从这个角度看可以认为编码器多了一点点解码器功能。具体做法超级简单,0就是位置编码向量,是可学习的patch嵌入向量。
# dim=1024
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# 变成(b,64,1024)
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
# 额外追加token,变成b,65,1024
x = torch.cat((cls_tokens, x), dim=1)
![[MySQL]02关于事务的解析](https://img-blog.csdnimg.cn/bb20f0ef36e54e66b91617178060e80f.png)