代码中涉及的图片实验数据下载地址:https://download.csdn.net/download/m0_37567738/88235543?spm=1001.2014.3001.5501
(一)手动实现卷积算法
代码:
import os
import torch.nn.functional as F
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch.utils.data import Dataset
from torchvision import transforms
import random
num_classes = 3 # 分类数量
batch_size = 256
num_epochs = 10 # 训练轮次
lr = 0.02
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 读取并展示图片
file_root = "./cnn/train"
#file_root = "d:/work/DeepLearning/实验三数据集/数据集/车辆分类数据集"
classes = ['bus', 'car', 'truck'] # 分别对应0,1,2
nums = [218, 779, 360] # 每种类别的个数
def read_data(path):
file_name = os.listdir(path) # 获取所有文件的文件名称
train_data = []
train_labels = []
test_data = []
test_labels = []
# 每个类别随机抽取20%作为测试集
train_num = [int(num * 4 / 5) for num in nums]
test_num = [nums[i] - train_num[i] for i in range(len(nums))]
for idx, f_name in enumerate(file_name): # 每个类别一个idx,即以idx作为标签
im_dirs = path + '/' + f_name
im_path = os.listdir(im_dirs) # 每个不同类别图像文件夹下所有图像的名称
index = list(range(len(im_path)))
random.shuffle(index) # 打乱顺序
im_path_ = list(np.array(im_path)[index])
test_path = im_path_[:test_num[idx]] # 测试数据的路径
train_path = im_path_[test_num[idx]:] # 训练数据的路径
for img_name in train_path:
# 会读到desktop.ini,要去掉
if img_name == 'desktop.ini':
continue
img = Image.open(im_dirs + '/' + img_name) # img shape: (120, 85, 3) 高、宽、通道
# 对图片进行变形
img = img.resize((32, 32), Image.ANTIALIAS) # 宽、高
train_data.append(img)
train_labels.append(idx)
for img_name in test_path:
# 会读到desktop.ini,要去掉
if img_name == 'desktop.ini':
continue
img = Image.open(im_dirs + '/' + img_name) # img shape: (120, 85, 3) 高、宽、通道
# 对图片进行变形
img = img.resize((32, 32), Image.ANTIALIAS) # 宽、高
test_data.append(img)
test_labels.append(idx)
print('训练集大小:', len(train_data), ' 测试集大小:', len(test_data))
return train_data, train_labels, test_data, test_labels
# 一次性读取全部的数据
train_data, train_labels, test_data, test_labels = read_data(file_root)
# 定义一个Transform操作
transform = transforms.Compose(
[transforms.ToTensor(), # 变为tensor
# 对数据按通道进行标准化,即减去均值,再除以方差, [0-1]->[-1,1]
transforms.Normalize(mean=[0.4686, 0.4853, 0.5193], std=[0.1720, 0.1863, 0.2175])
]
)
# 自定义Dataset类实现每次取出图片,将PIL转换为Tensor
class MyDataset(Dataset):
def __init__(self, data, label, trans):
self.len = len(data)
self.data = data
self.label = label
self.trans = trans
def __getitem__(self, index): # 根据索引返回数据和对应的标签
return self.trans(self.data[index]), self.label[index]
def __len__(self):
return self.len
# 调用自己创建的Dataset
train_dataset = MyDataset(train_data, train_labels, transform)
test_dataset = MyDataset(test_data, test_labels, transform)
# 生成data loader
train_iter = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0
)
test_iter = torch.utils.data.DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=0
)
def conv2d(X, K):
#print(X.size())
#print(K.size())
#exit()
'''
:param X: 样本输入,shape(batch_size,H,W)
:param K: 卷积核,shape(k_h,k_w)
:return: Y 卷积结果,shape(batch_size, H-k_h+1, W-k_w+1)
'''
batch_size, H, W = X.shape
k_h, k_w = K.shape
# 初始化 Y
Y = torch.zeros((batch_size, H - k_h + 1, W - k_w + 1)).to(device)
for i in range(Y.shape[1]):
for j in range(Y.shape[2]):
Y[:, i, j] = (X[:, i: i + k_h, j:j + k_w] * K).sum(dim=2).sum(dim=1)
return Y
def conv2d_multi_in(X, K):
'''
:param X: (batch_size, C_in,H,W)代表有C个输入通道
:param K: (C_in, k_h, k_w)
:return: (batch_size, H_out, W_out)
'''
#print(X.size())
#print(K.size())
res = conv2d(X[:, 0, :, :], K[0, :, :])
for i in range(1, X.shape[1]): # 多个通道的结果相加
res += conv2d(X[:, i, :, :], K[i, :, :])
return res
# 实现多输出通道
# 输出通道数 = 卷积核个数
def conv2d_multi_in_out(X, K):
'''
:param X: (batch_size, C_in,H,W)代表有C个输入通道
:param K: (K_num, C_in, k_h, k_w) k_num表示卷积核的个数
:return: (batch_size, K_num, H_out, W_out)
'''
#for k in K:
# print(k.size())
# exit()
tmp = [conv2d_multi_in(X, k) for k in K]
#print(tmp)
#exit()
#返回4维矩阵
return torch.stack(tmp, dim=1)
class MyConv2D(torch.nn.Module):
def __init__(self, in_channels, out_channels, kernel_size):
super(MyConv2D, self).__init__()
# 初始化卷积层2个参数:卷积核、偏差
if isinstance(kernel_size, int): # 如果kernel size是一个数
kernel_size = (kernel_size, kernel_size)
# weight的shape:(卷积核个数/输出通道数,输入通道数,卷积核高,卷积核宽)
# torch.randn:返回一个符合均值为0,方差为1的正态分布(标准正态分布)中填充随机数的张量
combo = (out_channels, in_channels)
print(combo)
tmp = torch.randn(combo + kernel_size)
print(tmp.size())
self.weight = torch.nn.Parameter(tmp)
print("out:{} int:{} weight size:{}".format(out_channels,in_channels,self.weight.size()))
self.bias = torch.nn.Parameter(torch.randn(out_channels, 1, 1))
def forward(self, x):
'''
:param x:
:return:
'''
return conv2d_multi_in_out(x, self.weight) + self.bias
class MyConvModule(torch.nn.Module):
def __init__(self):
super(MyConvModule, self).__init__()
# 定义一层卷积
self.conv = torch.nn.Sequential(
MyConv2D(in_channels=3, out_channels=32, kernel_size=3),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU(inplace=True) # inplace=True表示计算出来的结果会替换掉原来的Tensor
)
# 输出层,将输出通道数变为分类数量
self.fc = torch.nn.Linear(32, num_classes)
def forward(self, X):
# 图片经过一层卷积,输出(batch_size,C_out, H, W)
out = self.conv(X)
# 使用平均池化层将图片大小变为1*1(图片原大小32*32,卷积后为30*30
out = F.avg_pool2d(out, 30)
# 将out从shape batch_size*32*1*1变为batch_size*32
out = out.squeeze() # squeeze的用法:
# 输入到全连接层
out = self.fc(out)
return out
# 使用torch.nn实现二维卷积
class ConvModule(torch.nn.Module):
def __init__(self):
super(ConvModule, self).__init__()
# 定义一个三层卷积(卷积层越少曲线越平滑,卷积层越多acc越高)
self.conv = torch.nn.Sequential(
# 第一层卷积
# stride步长,padding填充
torch.nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=0),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU(inplace=True),
# 第二层卷积
torch.nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=0),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU(inplace=True),
# 第三层卷积
torch.nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0),
torch.nn.BatchNorm2d(128),
torch.nn.ReLU(inplace=True)
)
# 输出层,将输出通道数变为分类数
self.fc = torch.nn.Linear(128, num_classes)
def forward(self, X):
out = self.conv(X) # 输出维度(batch_size, C_out, H, W)
# 平均池化
out = F.avg_pool2d(out, 26) # 池化后图片大小1*1
# 将out从batch size*128*1*1变为batch size*128
out = out.squeeze()
out = self.fc(out)
return out
net = MyConvModule()
#net = ConvModule()
net.to(device)
# 损失函数和优化器
loss = torch.nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
def train(net, data_loader, device):
net.train() # 指定为训练模式
train_batch_num = len(data_loader)
total_loss = 0.0
correct = 0 # 记录共有多少个样本被正确分类
sample_num = 0
# 遍历每个batch进行训练
for data, target in data_loader:
# 将图片和标签放入指定的device中
data = data.to(device)
target = target.to(device)
# 将当前梯度清零
optimizer.zero_grad()
# 使用模型计算出结果
y_hat = net(data)
# 计算损失
loss_ = loss(y_hat, target)
# 进行反向传播
loss_.backward()
optimizer.step()
total_loss += loss_.item()
cor = (torch.argmax(y_hat, 1) == target).sum().item()
correct += cor
# 累加当前的样本总数
sample_num += target.shape[0]
print('loss: %.4f acc: %.4f' % (loss_.item(), cor/target.shape[0]))
# 平均loss和准确率
loss_ = total_loss / train_batch_num
acc = correct / sample_num
return loss_, acc
# 测试
def test(net, data_loader, device):
net.eval() # 指定当前模式为测试模式(针对BN层和dropout层)
test_batch_num = len(data_loader)
total_loss = 0
correct = 0
sample_num = 0
# 指定不进行梯度计算(没有反向传播也会计算梯度,增大GPU开销
with torch.no_grad():
for data, target in data_loader:
data = data.to(device)
target = target.to(device)
output = net(data)
loss_ = loss(output, target)
total_loss += loss_.item()
correct += (torch.argmax(output, 1) == target).sum().item()
sample_num += target.shape[0]
loss_ = total_loss / test_batch_num
acc = correct / sample_num
return loss_, acc
# 模型训练与测试
train_loss_list = []
train_acc_list = []
test_loss_list = []
test_acc_list = []
for epoch in range(num_epochs):
# 在训练集上训练
train_loss, train_acc = train(net, data_loader=train_iter, device=device)
# 测试集上验证
test_loss, test_acc = test(net, data_loader=test_iter, device=device)
train_loss_list.append(train_loss)
train_acc_list.append(train_acc)
test_loss_list.append(test_loss)
test_acc_list.append(test_acc)
print('epoch %d, train loss: %.4f, train acc: %.3f' % (epoch+1, train_loss, train_acc))
print('test loss: %.4f, test acc: %.3f' % (test_loss, test_acc))
# 绘制函数
def draw_(x, train_Y, test_Y, ylabel):
plt.plot(x, train_Y, label='train_' + ylabel, linewidth=1.5)
plt.plot(x, test_Y, label='test_' + ylabel, linewidth=1.5)
plt.xlabel('epoch')
plt.ylabel(ylabel)
plt.legend() # 加上图例
plt.show()
# 绘制loss曲线
x = np.linspace(0, len(train_loss_list), len(train_loss_list))
draw_(x, train_loss_list, test_loss_list, 'loss')
draw_(x, train_acc_list, test_acc_list, 'accuracy')
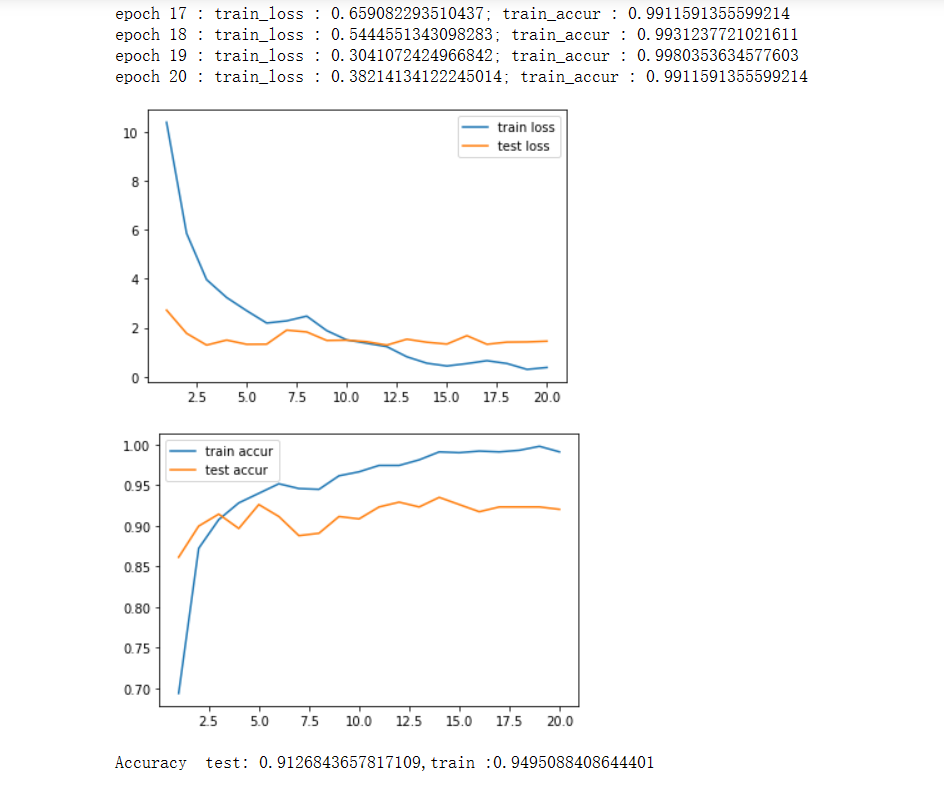
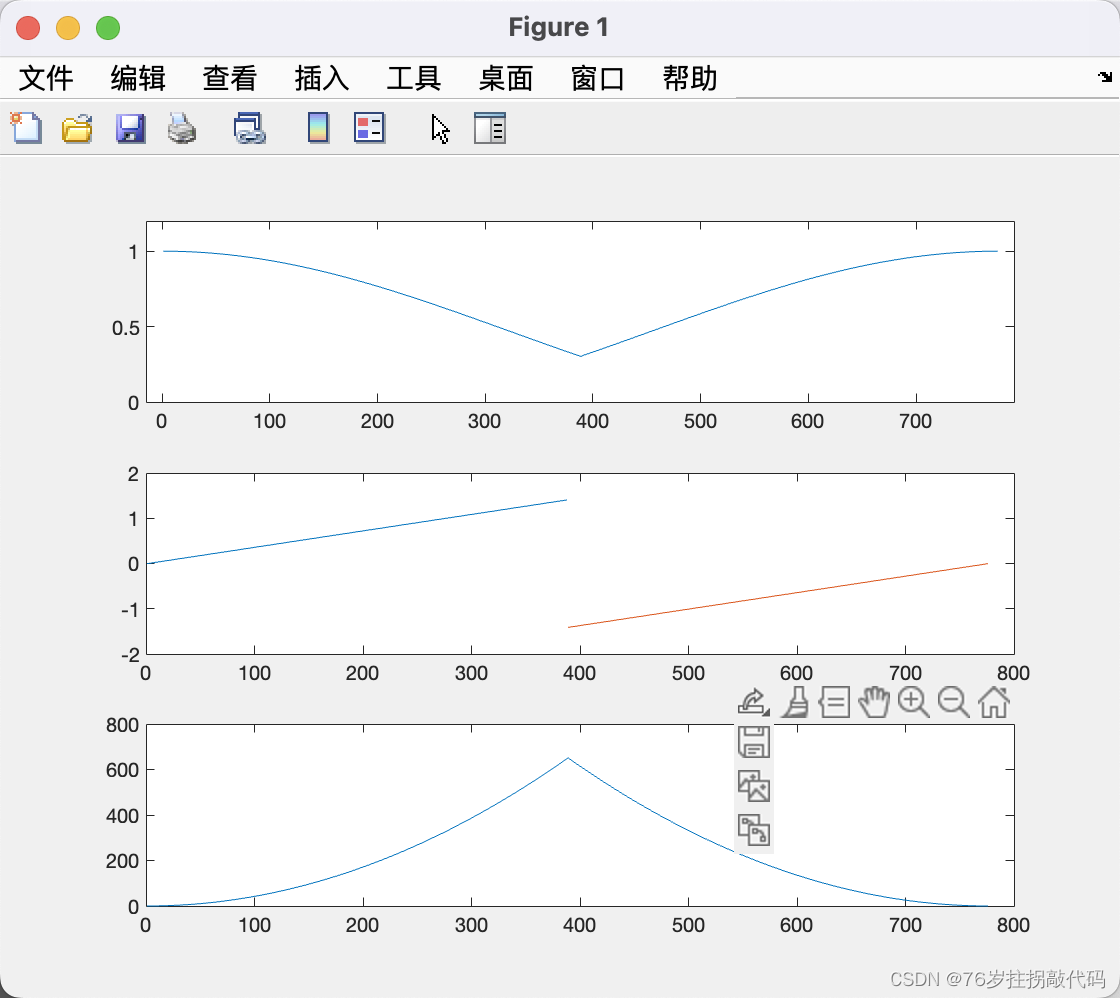
运行结果:
说明:
- 卷积函数conv2d
- 切片操作 conv2d(X[:, i, :, :]实现的效果是,取第1维度中第i个,这样的效果相当于去掉了第1维度。
- torch.stack(tmp, dim=1)操作跟第2点的操作相反,相当于增加了一维,具体细节看api文档。
- tmp = torch.randn(combo + kernel_size)这一行,将[32,3]和[3,3]这两个向量组成了[32,3,3,3]四维向量。
- 从执行结果看,准确率效果远不如nn实现。
(二)nn实现卷积算法
代码:
import torch.nn as nn
#from utils import get_accur,load_data,train
from matplotlib import pyplot as plt
import numpy as np
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
import torch
import torch.optim as optim
import numpy as np
def load_data(path, batch_size):
transform = transforms.Compose([transforms.ToTensor() ])
datasets = torchvision.datasets.ImageFolder(root = path,transform = transform )
dataloder = DataLoader(datasets, batch_size=batch_size, shuffle=True)
return datasets,dataloder
def get_accur(preds, labels):
preds = preds.argmax(dim=1)
return torch.sum(preds == labels).item()
def train(model, epochs, learning_rate, dataloader, criterion, testdataloader):
optimizer = optim.Adam(model.parameters(),lr=learning_rate)
train_loss_list = []
test_loss_list = []
train_accur_list = []
test_accur_list = []
train_len = len(dataloader.dataset)
test_len = len(testdataloader.dataset)
for i in range(epochs):
train_loss = 0.0
train_accur = 0
test_loss = 0.0
test_accur = 0
for batch in dataloader:
imgs, labels = batch
preds = model(imgs)
optimizer.zero_grad()
loss = criterion(preds, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_accur += get_accur(preds,labels)
train_loss_list.append(train_loss)
train_accur_list.append(train_accur / train_len)
for batch in testdataloader:
imgs, labels = batch
preds = model(imgs)
loss = criterion(preds, labels)
test_loss += loss.item()
test_accur += get_accur(preds,labels)
test_loss_list.append(test_loss)
test_accur_list.append(test_accur / test_len)
print("epoch {} : train_loss : {}; train_accur : {}".format(i + 1, train_loss, train_accur / train_len))
return np.array(train_accur_list), np.array(train_loss_list), np.array(test_accur_list), np.array(test_loss_list)
class ConvNetwork(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=7, stride=2, padding=0),
nn.BatchNorm2d(32),
nn.ReLU()
)
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=2, padding=0),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.layer3 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.layer4 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=3, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(3),
nn.ReLU()
)
self.out = nn.Linear(in_features=3 * 9 * 9, out_features=3, bias=True)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.reshape(x.shape[0], -1)
out = self.out(x)
return out
if __name__ == "__main__":
train_path = "./cnn/train/"
test_path = "./cnn/test/"
train_datasets, train_dataloader = load_data(train_path, 64)
test_datasets, test_dataloader = load_data(test_path, 64)
model = ConvNetwork()
critic = nn.CrossEntropyLoss()
epoch = 20
lr = 0.01
train_accur_list, train_loss_list, test_accur_list, test_loss_list = train(model,epoch, lr ,
train_dataloader, critic, test_dataloader)
'''
test_accur = 0
for batch in test_dataloader:
imgs, labels = batch
preds = model(imgs)
test_accur += get_accur(preds,labels)
print("Accuracy on test datasets : {}".format(test_accur / len(test_datasets)))
'''
x_axis = np.arange(1, epoch + 1)
plt.plot(x_axis, train_loss_list, label="train loss")
plt.plot(x_axis, test_loss_list, label = "test loss")
plt.legend()
plt.show()
plt.plot(x_axis, train_accur_list, label = "train accur")
plt.plot(x_axis, test_accur_list, label = "test accur")
plt.legend()
plt.show()
print("Accuracy test: {},train :{}".format(test_accur_list.sum() / epoch,
train_accur_list.sum()/epoch ))
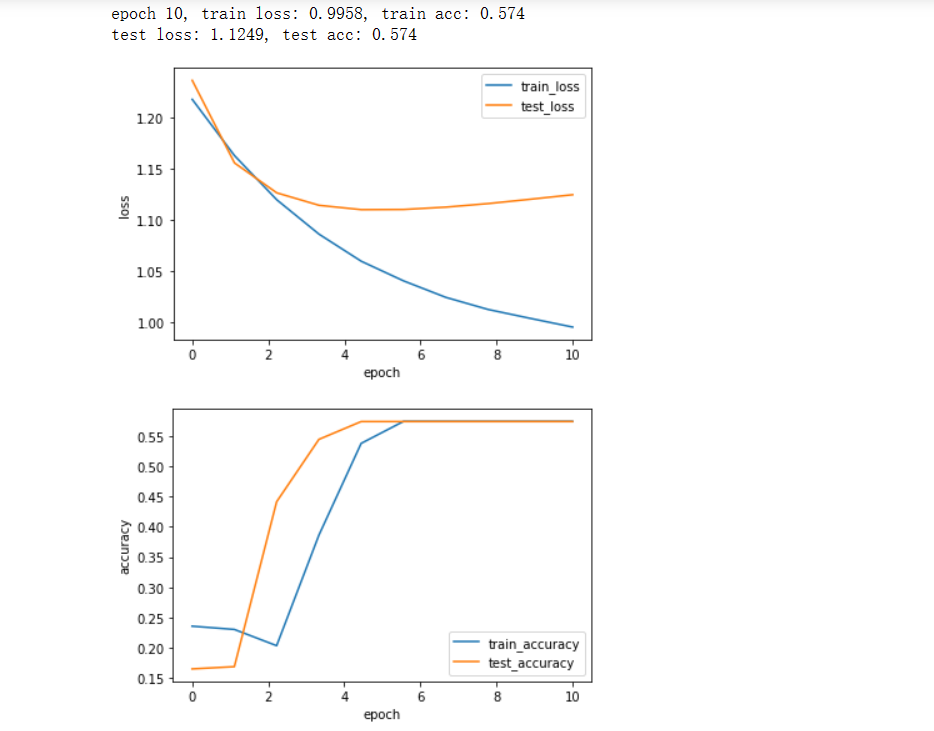
运行结果: