一 BERT_Base 110M参数拆解
BERT_base模型的110M的参数具体是如何组成的呢,我们一起来计算一下:
刚好也能更深入地了解一下Transformer Encoder模型的架构细节。
借助transformers模块查看一下模型的架构:
import torch
from transformers import BertTokenizer, BertModel
bertModel = BertModel.from_pretrained('bert-base-uncased', output_hidden_states=True, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
for name,param in bertModel.named_parameters():
print(name, param.shape)得到的模型参数为:
embeddings.word_embeddings.weight torch.Size([30522, 768])
embeddings.position_embeddings.weight torch.Size([512, 768])
embeddings.token_type_embeddings.weight torch.Size([2, 768])
embeddings.LayerNorm.weight torch.Size([768])
embeddings.LayerNorm.bias torch.Size([768])
encoder.layer.0.attention.self.query.weight torch.Size([768, 768])
encoder.layer.0.attention.self.query.bias torch.Size([768])
encoder.layer.0.attention.self.key.weight torch.Size([768, 768])
encoder.layer.0.attention.self.key.bias torch.Size([768])
encoder.layer.0.attention.self.value.weight torch.Size([768, 768])
encoder.layer.0.attention.self.value.bias torch.Size([768])
encoder.layer.0.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.0.attention.output.dense.bias torch.Size([768])
encoder.layer.0.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.0.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.0.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.0.intermediate.dense.bias torch.Size([3072])
encoder.layer.0.output.dense.weight torch.Size([768, 3072])
encoder.layer.0.output.dense.bias torch.Size([768])
encoder.layer.0.output.LayerNorm.weight torch.Size([768])
encoder.layer.0.output.LayerNorm.bias torch.Size([768])
encoder.layer.11.attention.self.query.weight torch.Size([768, 768])
encoder.layer.11.attention.self.query.bias torch.Size([768])
encoder.layer.11.attention.self.key.weight torch.Size([768, 768])
encoder.layer.11.attention.self.key.bias torch.Size([768])
encoder.layer.11.attention.self.value.weight torch.Size([768, 768])
encoder.layer.11.attention.self.value.bias torch.Size([768])
encoder.layer.11.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.11.attention.output.dense.bias torch.Size([768])
encoder.layer.11.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.11.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.11.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.11.intermediate.dense.bias torch.Size([3072])
encoder.layer.11.output.dense.weight torch.Size([768, 3072])
encoder.layer.11.output.dense.bias torch.Size([768])
encoder.layer.11.output.LayerNorm.weight torch.Size([768])
encoder.layer.11.output.LayerNorm.bias torch.Size([768])
pooler.dense.weight torch.Size([768, 768])
pooler.dense.bias torch.Size([768])其中,BERT模型的参数主要由三部分组成:
Embedding层参数
Transformer Encoder层参数
LayerNorm层参数
二 Embedding层参数
由于词向量是由Token embedding,Position embedding,Segment embedding三部分构成的,因此embedding层的参数也包括以上三部分的参数。
BERT_base英文词表大小为:30522, 隐藏层hidden_size=768,文本最大长度seq_len = 512
Token embedding参数量为:30522 * 768;
Position embedding参数量为:512 * 768;
Segment embedding参数量为:2 * 768。
因此总的参数量为:(30522 + 512 +2)* 768 = 23,835,648

LN层在Embedding层
norm使用的是layer normalization,每个维度有两个参数
768 * 2 = 1536
三 Transformer Encoder层参数
可以将该部分拆解成两部分:Self-attention层参数、Feed-Forward Network层参数。
1.Self-attention层参数
改层主要是由Q、K、V三个矩阵运算组成,BERT模型中是Multi-head多头的Self-attention(记为SA)机制。先通过Q和K矩阵运算并通过softmax变换得到对应的权重矩阵,然后将权重矩阵与 V矩阵相乘,最后将12个头得到的结果进行concat,得到最终的SA层输出。
1. multi-head因为分成12份, 单个head的参数是 768 * (768/12) * 3, 紧接着将多个head进行concat再进行变换,此时W的大小是768 * 768
12个head就是 768 * (768/12) * 3 * 12 + 768 * 768 = 1,769,472 + 589,824 = 2359296
3. LN层在Self-attention层
norm使用的是layer normalization,每个维度有两个参数
768 * 2 = 1536
2.Feed-Forward Network层参数
由FFN(x)=max(0, xW1+b1)W2+b2可知,前馈网络FFN主要由两个全连接层组成,且W1和W2的形状分别是(768,3072),(3072,768),因此该层的参数量为:
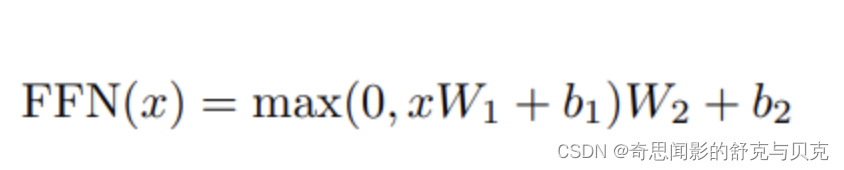
feed forward的参数主要由两个全连接层组成,intermediate_size为3072(原文中4H长度) ,那么参数为12*(768*3072+3072*768)= 56623104
LN层在FFN层
norm使用的是layer normalization,每个维度有两个参数
768 * 2 = 1536
layer normalization
layer normalization有两个参数,分别是gamma和beta。有三个地方用到了layer normalization,分别是embedding层后、multi-head attention后、feed forward后,这三部分的参数为768*2+12*(768*2+768*2)=38400
四 总结
综上,BERT模型的参数总量为:
23835648 + 12*2359296(28311552) + 56623104 + 38400 = 108808704 ≈103.7M
Embedding层约占参数总量的20%,Transformer层约占参数总量的80%。
注:本文介绍的参数仅是BERT模型的Transformer Encoder部分的参数,涉及的bias由于参数很少,本文也未计入。