本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 前言
- mmap原理
- madvise / mlock / msync
- 放弃使用mmap的理由
- Influxdb
- singlestore
- RocksDB
- VictoriaMetrics
- scylladb
- 现在还在使用mmap的理由
- mongoDB
- 冷数据沉降
- RUMA(Rewired User-space Memory Access)
- 总结
前言
最近正在研究InfluxDB1.8的series file实现,竟发现其中大量使用mmap,这和我的固有认知有非常大的差异,因为一年以前曾看过一篇出自Andrew Pavlo之手的吐槽文《Are You Sure You Want to Use MMAP in Your Database Management System?》,此后对mmap深恶痛绝,没想到现在竟然真的在线上运营的系统上看到了它。
So, Is mmap shit or not?
mmap原理
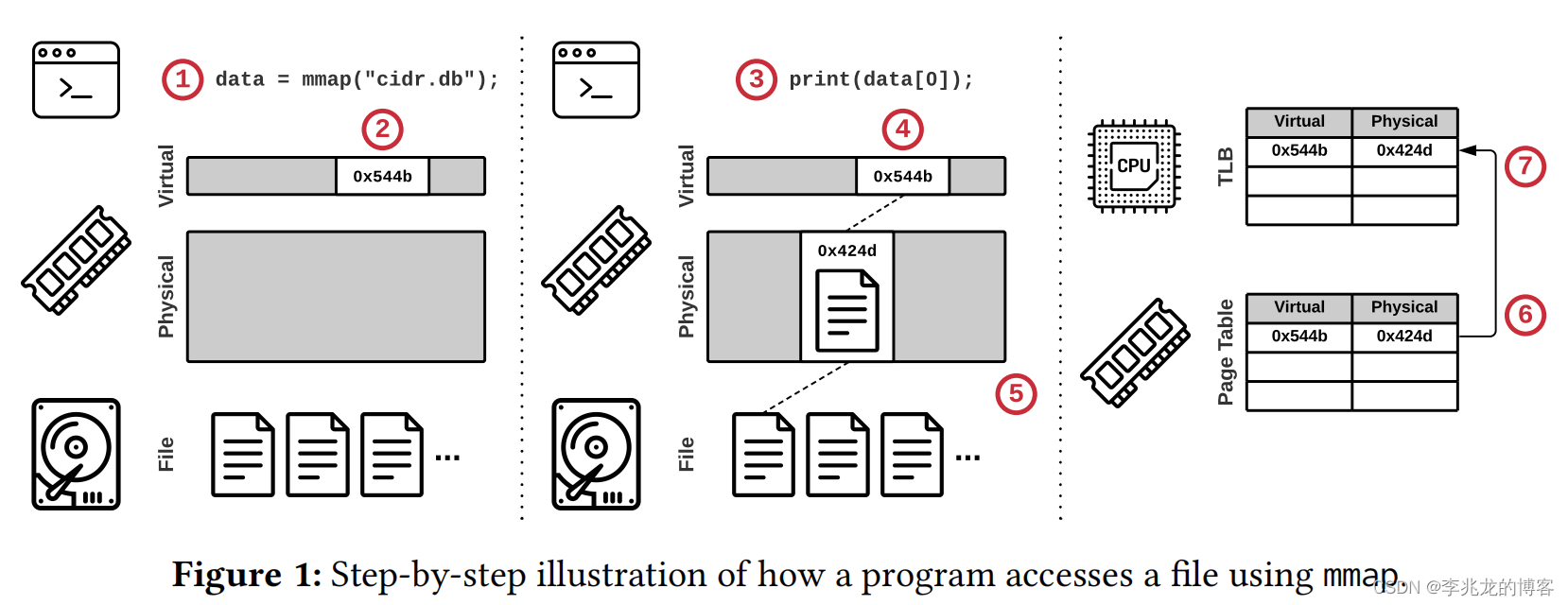
- 调用
void *mmap(void addr[.length], size_t length, int prot, int flags, int fd, off_t offset);,获取一个指向内存映射文件的指针 - OS保留内存映射区域的虚拟内存(在VMA中创建一项),但是不载入文件
- 程序使用第一步返回的指针操作文件内容
- OS在VMA中检索对应的虚拟地址空间,发现不存在有效映射
- 触发缺页中断,从二级存储中读取这部分数据
- 在页表项中添加一个新的条目,并将虚拟地址映射到物理地址
- 在TLB中缓存该页表项,以加速后续访问
madvise / mlock / msync
还有部分系统调用可以配合mmap使用,达到加速访问(madvise,mlock)和安全(msync)的功能。
这里最全的解释还是参考[1],这里man文档的解释没有注释中清晰。
int madvise(void addr[.length], size_t length, int advice);
int mlock(const void addr[.len], size_t len);
int msync(void addr[.length], size_t length, int flags);
下面是一些madvise常用的flag,可以看到都是一些很通用化的策略:
- MADV_NORMAL:When a page fault occurs in Linux with the default MADV_NORMAL hint, the OS will fetch the accessed page, as well as the next 16 and previous 15 pages. With 4 KB pages, MADV_NORMAL causes the OS to read 128 KB from secondary storage, even though the caller only requested a single page.
- MADV_RANDOM:the system should read the minimum amount of data on any access, since it is unlikely that the application will need more than what it asks for.
- MADV_SEQUENTIAL :pages in the given range will probably be accessed once, so they can be aggressively read ahead, and can be freed soon after they are accessed.
- MADV_DONTNEED:the application is finished with the given range, so the kernel can free resources associated with it.
- MADV_FREE:the application marks pages in the given range as lazy free, where actual purges are postponed until memory pressure happens.
放弃使用mmap的理由
Influxdb
在我们公司的实际线上运营经验来看,influxdb使用mmap是一个灾难性的事情。
influxdb使用mmap管理series file,包括hash->id id->offset的index,以及存储seriesKey的segment,series file是shard间共享的,意味着这一个series file其实可能承载上亿条时间线(mmap映射的文件大小没有上限,这对于IO数来讲是一个毁灭性打击),这在时间线爆炸是对性能有毁灭性打击:
- 每次查询时都需要在tsi中通过tagvalue反查series id,随后查询series file获取实际的series key;其次写入时需要查询series file检查是否存在某个series key,这个过程不命中内存的话会直接查询mmap映射的哈希表(线性探测再散列的两个哈希表),其次确定不存在时还会直接插入segment,触发mmap的IO操作;这里也可以看出这个文件其实是无限增长的,暂且不谈每次查询的IO操作,当大小超过TLB的限制时也可预见的会造成TLB shootdown;
- influxdb iox支持S3接口,意味着需要允许容器中没有挂载磁盘时使用influxdb,mmap使得这个需求无法完成,所以必须使用自定义管理IO操作
singlestore
单纯的遇到了性能瓶颈,本质的原因是mmap_lock争用。
同进程的不同线程虽然对应不同的task_struct ,但因为共享虚拟地址空间都共享同一个mm_struct,每个mm_struct包含一个mmap_lock(信号量),进程内大部分的内存操作都需要先对它上锁,比如如下操作:
- 所有对 VMA 的操作 (mmap、munmap)
- 所有对页表的修改 (page fault 等)
- madvise (如 jemalloc 经常使用的 MADV_DONTNEED)
在[3]中作者使用16 个线程(每个 CPU 核心一个)执行 select count(*) from t where i > 5,按照现在的磁盘效率,这应该是一个经典的CPU密集型场景,磁盘只需要读取原始数据,剩下的全部是内存中的计算任务,但是结果是近50%的时间都处于空闲状态,导致性能较差,作者使用off-cpu分析程序阻塞的瓶颈,可以看到如下火焰图:

可以很明显的看到瓶颈是由于大量的缺页/munmap造成的对mmap_lock的争用,这就导致了没次调用都会产生10-20ms的誓言,当修改为read系统调用后这个问题就解决了,也很好理解,因为缺页对vma的修改是细粒度的,而read可以一次修改大量vma项,这就使得锁粒度变低了不少。
RocksDB
在[5]中可以看到rocksdb认为leveldb性能较差的几个问题:
- We found that LevelDB’s single-threaded compaction process was insufficient to drive server workloads.
- We saw frequent write-stalls with LevelDB that caused 99-percentile latency to be tremendously large.
- We found that mmap-ing a file into the OS cache introduced performance bottlenecks for reads. We could not make LevelDB consume all the IOs offered by the underlying Flash storage.
levelDB的随机读抽象接口RandomAccessFile允许使用mmap和pread来实现,在[6]中可以看到这个修改使得性能提升了不少,但是仅仅是在磁盘小于内存时,当磁盘远大于内存时mmap无法充分利用磁盘的IO能力。
VictoriaMetrics
mmap非常糟糕,在go中使用mmap更加糟糕[7]。
我曾经实现过用户态抢占式协程框架[9]和协作式协程框架[8],对这个问题可谓极其感同身受。考虑一个问题,在一个N:M的协程框架中何时执行协程的执行权切换?
- 协作式框架会在显示调用阻塞式系统调用时切换到其他协程执行
- 抢占式框架会在某个协程执行达到某个条件时主动切换其执行权(比如执行时间过长)
这两点都可以看出协程可以理解为一个逻辑单位,对于底层线程的执行时不关心的,换句话说协程眼中自己是始终在执行的,但显然这只是一种假设,协程最怕的就是线程突然阻塞,哪些情况可能导致这一点呢?
- 正常的线程切换
- 内核中慢操作(page fault,跨CPU数据同步(总线锁)等等)
这些操作都会导致此线程上的协程全部阻塞,进而导致影响sla。
而mmap在二级运储远大于内存时会造成大量的缺页中断,前面还讲到同一个进程的缺页中断还会抢夺mm->mmap_lock。
scylladb
[11]中阐述了scylladb使用AIO而不是其他IO方法的原因,这里对于mmap的不满主要是以下几个方面:
- 内核中的预读策略和驱逐策略是通用的,虽然提供了
madvise和fadvise,但是还是无法满足部分应用的定制化需求,比如何时预读多少,那些内存合适淘汰,是否需要batch等 - 较大的内存开销,mmap需要大量的RSS,当文件较大时页表的内存开销非常大,一个页表项8字节,映射4kb空间,这需要映射文件大小的约0.2%,如果二级存储是1T,内存中有2G都会用于页表。
- 程序失去了对于IO的控制,当内核大量回写脏页时可以印象此时的读延迟;其次内核无法区分重要与不重要的IO操作,可能导致不重要的IO比重要的IO更先执行
现在还在使用mmap的理由
mongoDB
正如[2]中提到,mongoDB给出了在今天依旧使用mmap的合理理由。这是一个很好的思路,但是我个人认为仍旧存在mmap的固有缺陷。
随着硬件性能的提升,通用存储栈的成本比例越来越高,[2]中提到[13]的研究表明通过使用mmap进行 I/O,并在文件需要增长时预先分配一些额外的空间,他们可以实现几乎与完全不存在文件系统时的相同性能。在 MongoDB 的存储引擎 WiredTiger 中验证了这个想法,并获得了较为明显的性能提升。
这个思路其实本质是为了减少IO次数,mmap的基本访问原理如下:
- 如果包含文件数据的物理页仍在缓冲区高速缓存中并且页表条目位于 TLB 中,不需要OS参与
- 如果包含文件数据的页面仍在缓冲区高速缓存中,但 TLB 条目已被逐出,则需要陷入内核模式,遍历页表以找到该页表项,将其安装到 TLB 中
- 如果包含文件数据的页面不在缓冲区高速缓存中,则需要陷入内核模式,OS要求文件系统获取该页面,设置页表项,然后执行第二步
如果始终处于第一步则性能可以节省两个主要开销:
- read/write 系统调用开销
- 内核态向用户态拷贝数据的开销
此外文章还提到如果将数据从内存映射文件区域复制到另一个应用程序缓冲区,则通常会使用高度优化的基于 AVX 的 memcpy 实现。当通过系统调用将数据从内核空间复制到用户空间时,内核必须使用效率较低的实现,因为内核不使用 AVX 寄存器 [14]。
冷数据沉降
[16]利用mmap的几个优势:
- 拷贝快可能更快
- 减少拷贝次数
- 减少系统调用数
这样可以低开销的方式把内存冷数据沉降到二级存储中。
RUMA(Rewired User-space Memory Access)
[17]中提到的技术利用mmap在运行时重新分配虚拟内存地址到物理内存地址的映射,这篇论文没有看,但是看起来diaodiao的。
总结
以下几个原因是导致mmap不该被使用在DBMS中的主要原因:
- 性能问题,主要集中在三个方面 :
a.TLB shootdown[11]
b.kswapd 单线程驱逐瓶颈[12]
c. 锁竞争,在二级存储远大于内存时,单线程和多线程mmap都无法利用全部的IO带宽 - 内存问题:mmap会创建与文件大小相同的虚拟内存,并创建VMA和页表,在文件较大时对内存影响较大
- 错误处理:很多DBMS使用内存不安全的语言编写,且存在CPU/内存错误导致比特跳变,页级别的校验和就显得非常重,但是mmap的回写是OS控制的,可能写入一个受损坏的页。
- I/O Stalls:mmap无法异步化,且任何操作都可能导致缺页,虽然mlock/madvise可以在部分情况下缓解,但是错误的提示可能导致性能大幅度下降,其次可以选择使用一个独立的线程负责预取,以防止主线程阻塞
- 事务不安全:无法控制何时下刷脏页,需要其他复杂的机制来保障
- 无法容器化部署:随着对象存储的发展,越来越到的云原生数据库用对象存储作为存储层,而mmap假设底层一定是磁盘。
引用:
- linux kernel 6.2 madvise.c
- Getting Storage Engines Ready for Fast Storage Devices
- Investigating Linux Performance with Off-CPU Flame Graphs
- Off-CPU分析
- https://rocksdb.org/docs/support/faq.html
- https://groups.google.com/g/leveldb/c/mkKRKA4XGb0
- mmap may slow down your Go app
- https://github.com/Super-long/RocketCo
- https://github.com/xiyou-linuxer/LUTF
- Different I/O Access Methods for Linux, What We Chose for ScyllaDB, and Why
- DiDi: Mitigating the Performance Impact of TLB Shootdowns Using a Shared TLB Directory,PACT 2011
- linux kswapd浅析
- Finding and Fixing Performance Pathologies in Persistent Memory Software Stacks,ASPLOS 2019
- Why mmap is faster than system calls
- Are You Sure You Want to Use MMAP in Your Database Management System? CIDR 2022
- Ailamaki. Enabling Efficient OS Paging for Main-Memory OLTP Databases, DaMoN 2013.
- RUMA has it: Rewired User-space Memory Access is Possible! vldb2016




![8th参考文献:[8]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑出版传媒,2022.](https://img-blog.csdnimg.cn/08322314740f425daeb21e42a7d2c012.jpeg#pic_center)