前言
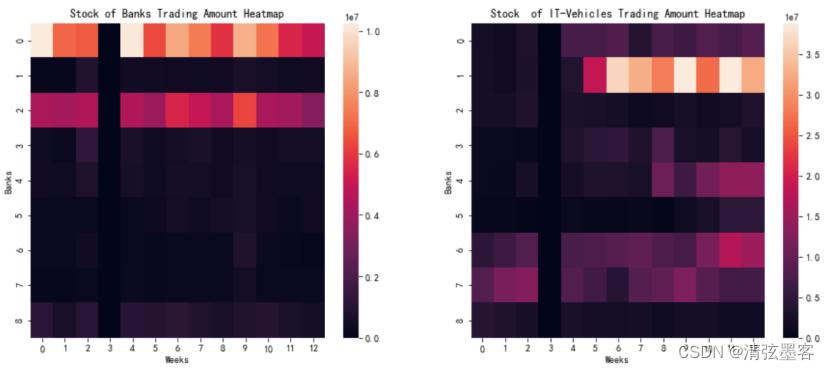
下图表示的是一个简单的flink-job的计算图,这种图被称为DAG(有向无环图),表示的这个任务的计算逻辑,无论是spark、hive、还是flink都会把用户的计算逻辑转换为这样的DAG,数据的计算按照DAG触发,理论上只要构建出这样一个DAG图,就可以描述清楚用户的计算逻辑,在DAG的基础上,将Node并行化就可以将整个job并行化。
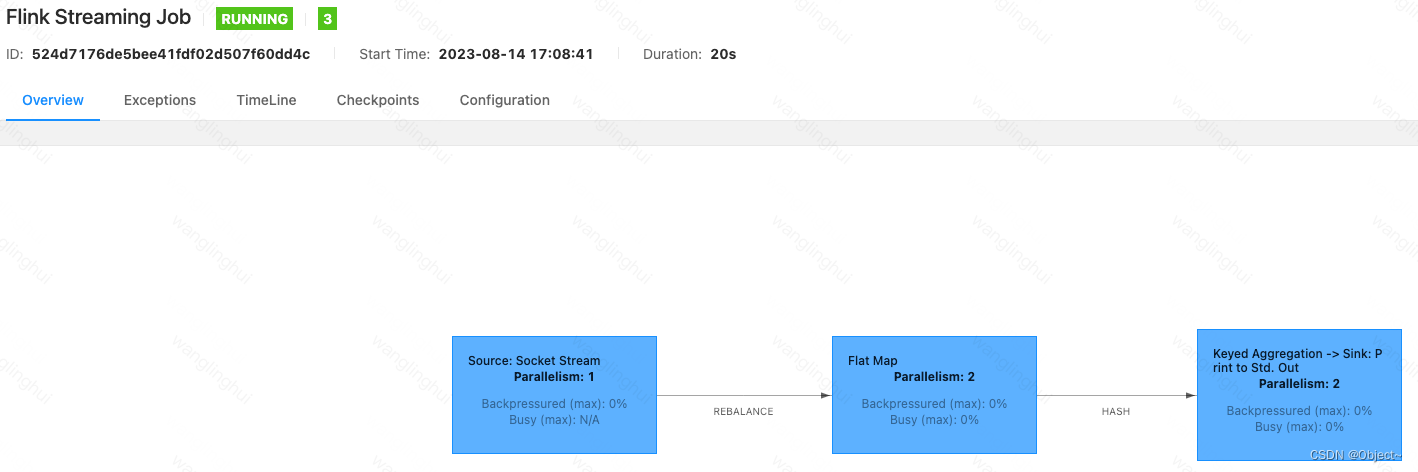
在Flink之前的上一代流式计算框架Apache Storm的hello world如下(节选了一部分):从storm的helloworld代码可以很清楚的看到storm构建dag是依赖用户自己构建,用户将自己脑中的dag图使用代码画出来,line2创建了一个DAG的builder,line4新增了一个节点,line6也新增了一个节点,dag画完了后在line16将DAG生成出来提交到集群执行。从这里可以看出storm构建DAG的逻辑是用户心中有图,自己画出来。
// 实例化TopologyBuilder类。
TopologyBuilder topologyBuilder = new TopologyBuilder();
// 设置喷发节点并分配并发数,该并发数将会控制该对象在集群中的线程数。
topologyBuilder.setSpout("SimpleSpout", new SimpleSpout(), 1);
// 设置数据处理节点并分配并发数。指定该节点接收喷发节点的策略为随机方式。
topologyBuilder.setBolt("SimpleBolt", new SimpleBolt(), 3).shuffleGrouping("SimpleSpout");
Config config = new Config();
config.setDebug(true);
if (args != null && args.length > 0) {
config.setNumWorkers(1);
StormSubmitter.submitTopology(args[0], config, topologyBuilder.createTopology());
} else {
// 这里是本地模式下运行的启动代码。
config.setMaxTaskParallelism(1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("simple", config, topologyBuilder.createTopology());
}再看一下flink的helloworld,代码如下,该代码对应的DAG就是文章开头的图片,下面代码中line3获取一个执行的环境,line6从9999端口读入数据,line7做flatmap,ling15做分组操作,line20对分组的数据做sum聚合,line22执行任务;通过和storm的helloworld的对比,可以很明显的看出flink代码中很难看出DAG的样子,flink专注的并不是用户去画DAG,而是用户表达清楚自己的业务,由flink将DAG画出并执行,这也是flink会将storm慢慢淘汰的原因之一
public class Demo01_hello {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.socketTextStream("localhost", 9999)
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String s : value.split(" ")) {
out.collect(Tuple2.of(s, 1));
}
}
})
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}).sum(1).print();
env.execute();
}
}总结一下:flink目前提供了多种api,包裹flink-stream-api,table/sql-api,python-api,这些api的表象不同,但是底层都是将用户表达的逻辑翻译为DAG部署到集群上
那就从Hello-world开始吧
大数据的hello-word都是从wordcount开始的,这是mapreduce时代的传承,让我们再看一下flink的wordcount
public class Demo01_hello {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.socketTextStream("localhost", 9999)
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String s : value.split(" ")) {
out.collect(Tuple2.of(s, 1));
}
}
})
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}).sum(1).print();
env.execute();
}
}line3从StreamExecutionEnvironment获取了一个执行环境,这个环境在本地就是local的,在yarn上就是yarn的,在k8s上就是k8s的
line4设置任务的并行度,这里遇到了第一个概念:并行度,并行度表示任务的并行个数,比如数据源kafka有2个分区,那么最佳的并行度就是2,因为一个分区只能被一个消费者消费,并行度大于2则多余的消费者消费不到数据
line6设置了数据源为socket,监听9999端口
line7对数据源的数据做flatmap操作,输入是string,输出是tuple2<string,integer>
line15对tuple2<string,integer>做了分组操作,按照string分组,这里涉及了另一个概念shuffle,shuffle就是打乱的意思
line20对分组后的数据tuple2<string,integer>做了sum操作,计算出每一个string的数量
ling22执行任务
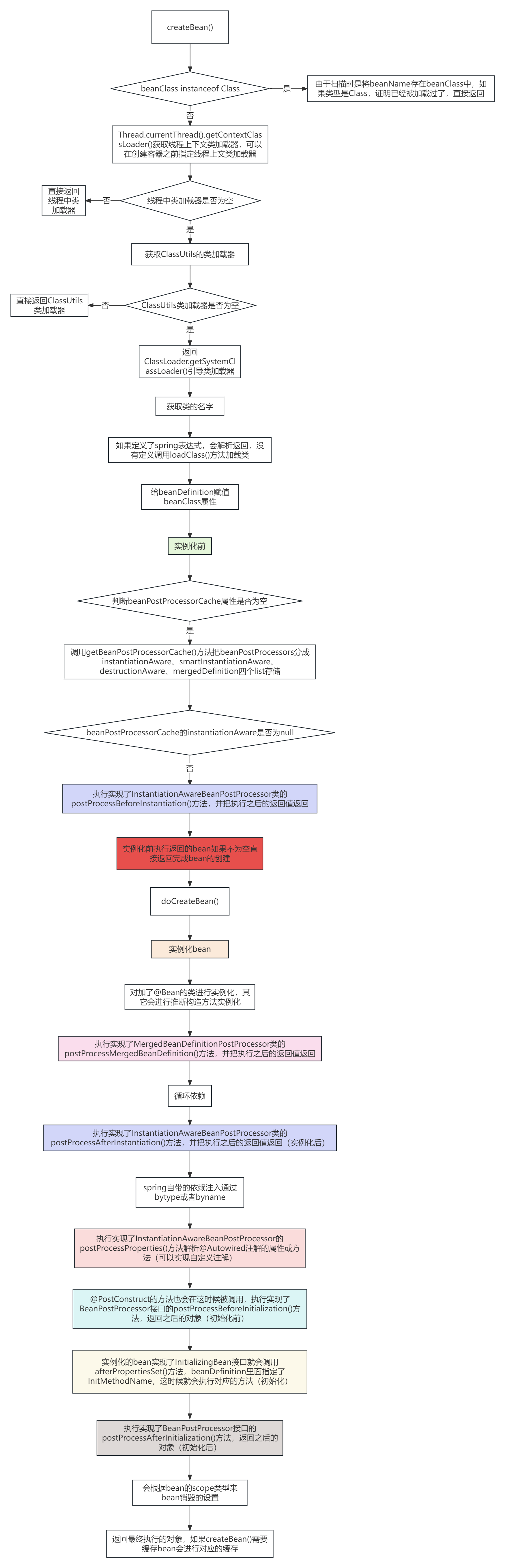
下图展示了该任务如何从代码变成可以运行的执行图运行在分布式环境中
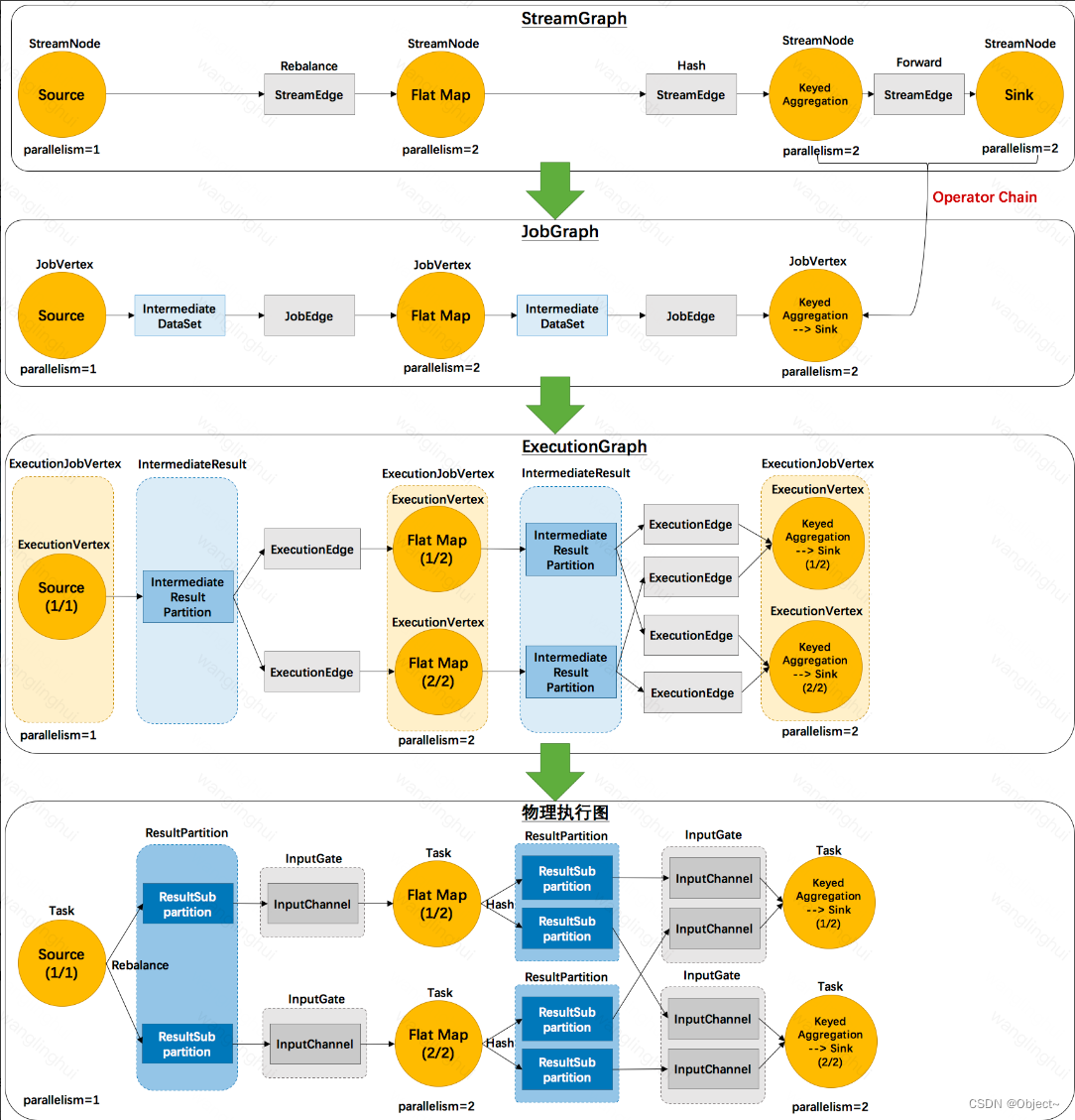
可以看到上图中有四张图,编写的代码会经历
StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图,最终提交到集群执行
(1)StreamGraph
a)StreamNode:表示每一个operator,并且携带了这个operator的若干信息
b)StreamEdge:表示streamnode之间的边,边上还携带了标识:rebalance、hash、forward,表示streamnode之间的数据传输方式
c)StreamGraph其实已经很像前言中的dag图了,但是还有些不同
(2)JobGraph
a)JobVertex:streamgraph中的streamnode如果存在可以优化的情况,比如operator-chain,那么多个streamnode就可以合并为一个jobvertex,operator-chain的条件是streamedge=forward且前后两个streamnode并行度相同
b) IntermediateDataset:jobvertex的产出数据,即若干个operator处理后的结果集
c)JobEdge:数据传输通道,从intermediatedataset传输数据到下游jobvertex
(3)ExecutionGraph
a)ExecutionVertex: jobvertex的并行化节点
b)ExecutionJobVertex:jobvertex对应的节点,一一对应
c)IntermediateResultPartition: 表示ExecutionVertex的输出结果,一个ExecutionVertex对应一个IntermediateResultPartition
d)IntermediateResult:和IntermediateDataset一一对应
e)ExecutionEdge:连接IntermediateResultPartition和ExecutionVertex一一对应
(4)物理执行图
a)Task:具体的调度task,封装了operator的操作,包括用户的逻辑
b)ResultPartition:对应IntermediateResultPartition,一一对应
c)ResultSubPartition:是Resultpartition的子分区,他的数量和下游的task有关,如果source算子就一个,所以他的ResultPartition就一个,但是下游有两个flatmap算子,所以这个ResultPartition会分成2个ResultSubPartition,分别给下游两个flatmap算子消费
d)InputChannel:连接ResultSubPartition和下游task算子的数据通道