一、介绍
欢迎来到我们关于 PyTorch Lightning 系列的第二篇文章!在上一篇文章中,我们向您介绍了 PyTorch Lightning,并探讨了它在简化深度学习模型开发方面的主要功能和优势。我们了解了 PyTorch Lightning 如何为组织和构建 PyTorch 代码提供高级抽象,使研究人员和从业者能够更多地关注模型设计和实验,而不是样板代码。
在本文中,我们将深入研究 PyTorch Lightning,并探索它如何通过分布式训练实现深度学习工作流的扩展。分布式训练对于在海量数据集上训练大型模型至关重要,因为它允许我们利用多个 GPU 或机器的强大功能来加速训练过程。然而,分布式训练往往伴随着一系列挑战和复杂性。
二、安装 Pytorch Lightning & Torchvision
pip install torch torchvision pytorch-lightning 三、实现
首先,我们需要从 PyTorch 和 PyTorch Lightning 导入必要的模块:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
from torchvision import transforms
import pytorch_lightning as pl 接下来,我们使用 PyTorch 的类定义我们的神经网络架构。在这个例子中,我们使用一个简单的卷积神经网络,其中包含两个卷积层和三个全连接层:nn.Module
class Net(pl.LightningModule):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(nn.functional.relu(self.conv1(x)))
x = self.pool(nn.functional.relu(self.conv2(x)))
x = torch.flatten(x, 1)
x = nn.functional.relu(self.fc1(x))
x = nn.functional.relu(self.fc2(x))
x = self.fc3(x)
return x 然后,我们为 .在该方法中,我们接收一批输入和标签,将它们通过我们的神经网络来获取 logits,计算交叉熵损失,并使用该方法记录训练损失。在该方法中,我们执行与 相同的操作,但不记录损失:LightningModuletraining_stepxyself.logvalidation_steptraining_step
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = nn.functional.cross_entropy(logits, y)
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = nn.functional.cross_entropy(logits, y)
self.log("val_loss", loss)
return loss 我们还在方法中定义了优化器和学习率调度器:configure_optimizers
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.1)
return [optimizer], [scheduler] 接下来,我们使用 PyTorch 和 定义数据加载和预处理步骤:DataLoadertransforms
def prepare_data(self):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
CIFAR10(root='./data', train=True, download=True, transform=transform)
CIFAR10(root='./data', train=False, download=True, transform=transform)
def train_dataloader(self):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = CIFAR10(root='./data', train=True, download=False, transform=transform)
return DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=8)
def val_dataloader(self):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
val_dataset = CIFAR10(root='./data', train=False, download=False, transform=transform)
return DataLoader(val_dataset, batch_size=64, shuffle=False, num_workers=8)prepare_data(self):此函数负责在训练模型之前准备数据。它首先使用该类定义一系列转换。转换包括将数据转换为张量并对其进行规范化。定义转换后,该函数将下载用于训练和测试拆分的 CIFAR10 数据集。数据集将下载到目录,并将指定的转换应用于数据。transforms.Compose'./data'train_dataloader(self):此函数为训练数据集创建数据加载器。它首先定义与函数中相同的转换。接下来,它为训练拆分创建 CIFAR10 数据集的实例。从目录中加载数据集,并应用指定的转换。最后,使用训练数据集创建一个对象。数据加载程序配置为 64 的批大小,对数据进行随机排序,并使用 8 个工作线程进行数据加载。它返回数据加载器。prepare_data'./data'DataLoaderval_dataloader(self):此函数为验证数据集创建数据加载器。它遵循与函数类似的结构。它首先使用 定义转换,这些转换与前面的函数相同。然后,为验证拆分创建 CIFAR10 数据集的实例。从目录中加载数据集,并应用指定的转换。最后,使用验证数据集创建一个对象。数据加载器配置为 64 的批大小,无需随机处理数据,并使用 8 个工作线程进行数据加载。它返回数据加载器。train_dataloadertransforms.Compose'./data'DataLoader
该函数将模型作为输入,并对测试数据集执行评估。它首先对测试数据应用转换,将其转换为张量并规范化。然后,它为测试数据集创建数据加载程序。模型将移动到相应的设备(GPU,如果可用)。评估标准设置为交叉熵损失。evaluate_model
def evaluate_model(model):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
test_dataset = CIFAR10(root='./data', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=8)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss()
model.eval()
test_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100.0 * correct / total
average_loss = test_loss / len(test_loader)
print(f"Test Loss: {average_loss:.4f}")
print(f"Test Accuracy: {accuracy:.2f}%")将模型置于评估模式,并初始化测试损失、正确预测和总数据点的变量。在无梯度上下文中,该函数遍历测试数据加载器,通过模型转发成批的输入,计算损失并累积测试损失。它还计算正确预测的数量和数据点的总数。最后,它计算并打印平均测试损失和测试精度。
最后,我们实例化我们的模型和来自 PyTorch Lightning,指定用于分布式训练的所需数量的 GPU 或机器:NetTrainer
net = Net()
trainer = pl.Trainer(
num_nodes=1, # Change to the number of machines in your distributed setup
accelerator="auto", # Distributed Data Parallel, Available names are: auto, cpu, cuda, hpu, ipu, mps, tpu.
max_epochs=5,
devices=1 # Change to the desired number of GPUs or use `None` for CPU training
)
trainer.fit(net)
evaluate_model(net)num_nodes:它指定分布式设置中的计算机数量。在这种情况下,它设置为 ,表示单台计算机设置。1accelerator:它确定训练的加速器类型。该值允许 PyTorch Lightning 根据硬件和软件环境自动选择适当的加速器。其他可能的值包括 、 和 ,它们对应于特定的硬件加速器。"auto""cpu""cuda""hpu""ipu""mps""tpu"max_epochs:它设置用于训练模型的最大周期数(通过训练数据集的完整遍历)。在本例中,它设置为 。5devices:它指定用于训练的 GPU 数量。将其设置为 表示使用单个 GPU 进行训练。如果要在 CPU 上进行训练,可以将其设置为 。1None
这些选项允许您控制训练过程的各个方面,例如分布式训练、加速器选择以及用于训练的周期数和设备数。
设置好所有内容后,我们只需调用对象的方法,传入我们的模型、训练数据加载器和验证数据加载器。fitTrainerNet
四、输出
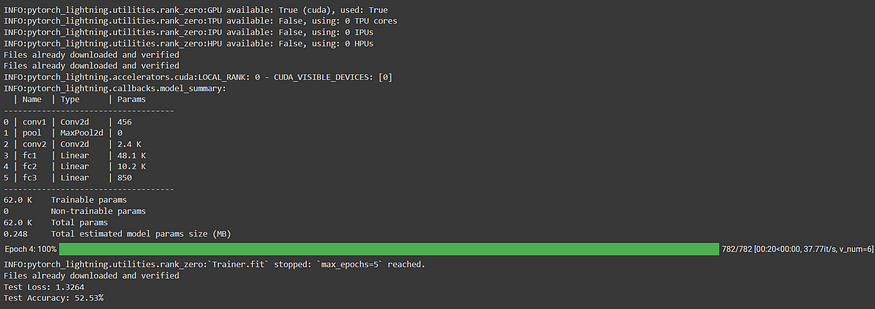
五、结论
PyTorch Lightning 通过分布式训练简化了扩展深度学习工作流的过程。通过抽象化分布式训练的复杂性,PyTorch Lightning 使我们能够专注于设计和实现我们的深度学习模型,而不必担心低级细节。在本文中,我们演练了一个使用 PyTorch Lightning 进行分布式训练的示例代码实现。通过利用多个GPU或机器的强大功能,我们可以显著减少大型深度学习模型的训练时间。
六、引用
- PyTorch Lightning: Welcome to ⚡ PyTorch Lightning — PyTorch Lightning 2.1.0.rc0 documentation
- PyTorch: PyTorch
- torchvision.datasets.CIFAR10: Datasets — Torchvision 0.15 documentation
- torch.utils.data.DataLoader: torch.utils.data — PyTorch 2.0 documentation
- 火炬亚当:Adam — PyTorch 2.0 documentation
- torch.optim.lr_scheduler。步长:StepLR — PyTorch 2.0 documentation
- Torch.nn.CrossEntropyLoss: CrossEntropyLoss — PyTorch 2.0 documentation
- torch.cuda.is_available:torch.cuda — PyTorch 2.0 documentation
阿奈·东格雷
皮托奇
分布式系统