目录
- 一、scrapy
- 1. scrapy的安装
- (1)什么是scrapy
- (2)scrapy的安装
- 2. scrapy的基本使用
- (1)scrap的使用步骤
- (2)代码的演示
- 3. scrapy之58同城项目结构和基本方法(注:58同城的数据不是公开数据,不能爬取;本次代码也爬取不到相应的数据)
- (1)scrapy项目的组成
- (2)scrapy爬虫文件的组成以及响应response的属性和方法
- (3)代码演示
- 4. 汽车之家scrapy工作原理
- (1)scrapy架构组成
- (2)scrapy的工作原理
- (3)代码演示
- 5.调试工具scrapy shell
- (1)什么是scrapy shell
- (2)安装ipython
- (3)ipython的使用方法
- 6. scrapy之当当网爬取数据(本节获取数据失败,已在第9节成功解决,不想再改动本节内容了)
- (1)yied
- (2)本节的演示
- 7.scrapy_当当网管道封装(本节获取数据失败,已在第9节成功解决,不想再改动本节内容了)
- 8.scrapy_当当网开启多条管道下载(本节获取数据失败,已在第9节成功解决,不想再改动本节内容了)
- 9.scrapy_当当网多页下载
- 10.scrapy_电影天堂多页数据下载
- 11. scrapy_链接提取器CrawlSpider的使用(含MySql、pymysql的使用)
- (1)MySQL的安装和初级使用
- (2)CrawlSpider的作用
- (3)CrawlSpider的使用方法
- (4)代码演示
- 12.scrapy_crawlspider读书网获取图片的封面地址和名字
- (1)CrawlSpider的使用步骤
- (2)代码演示
- 13.scrapy_读书网数据入库和链接跟进(失败,卡在最后的“由于日标计算机积极拒绝”,没有系统学过MySQL,卡住了)
- (1)准备工作(安装Ubuntu、在Ubuntu上安装mysql中途含出现的两个问题的解决办法、Windows上安装pymysql)
- (2)pymysql的使用步骤
- (3)本次的演示(失败,卡在最后的“由于日标计算机积极拒绝”)
- 14. scrapy_日志信息以及日志级别
- (1)日志信息的定义、等级、如何设置日志
- (2)代码演示
- 15.scrapy_百度翻译post请求
- (1)scrapy 下的post请求的用法
- (2)代码演示
说明:该文章是学习 尚硅谷在B站上分享的视频 Python爬虫教程小白零基础速通的 p51-104而记录的笔记,笔记来源于本人,关于python基础可以去CSDN上阅读本人学习黑马程序员的笔记。 若有侵权,请联系本人删除。笔记难免可能出现错误或笔误,若读者发现笔记有错误,欢迎在评论里批评指正。 请合法合理使用爬虫,不爬取任何涉密以及涉及隐私的内容,合理控制请求次数,爬取的内容未经授权请不要用于商用,保护自己,免受牢狱之灾。
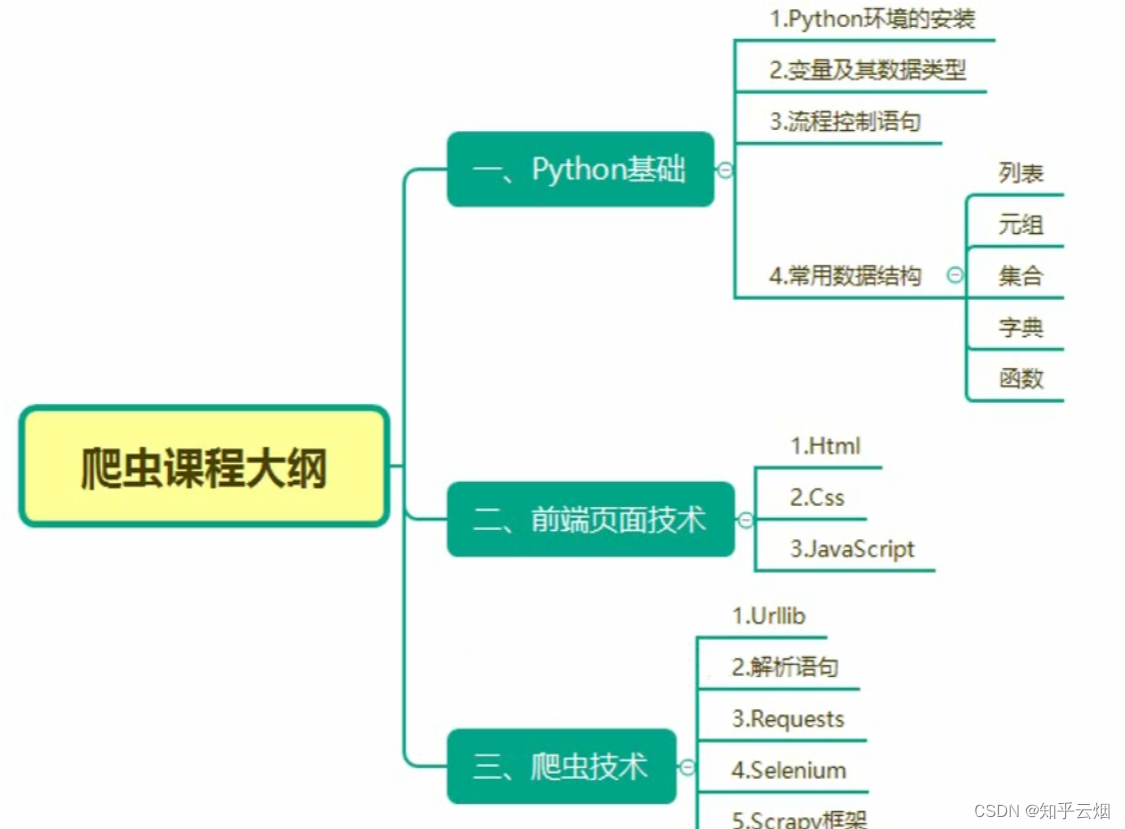
本章将介绍scrapy,它是爬虫在企业级研发中用得最多的技术,由于scrapy使用框架,故具有编程更简单、爬取速度更快、更好地进行爬虫的开发。
注:由于本人是先做word,再将代码复制到CSDN中的,代码可能会出现类似下图的情况,多几个“-”号的问题。代码太多,根本改不完,难免有没改到的。
一、scrapy
1. scrapy的安装
(1)什么是scrapy
scray是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘、信息处理或存储历史数据等一系列的程序中。
什么是结构性数据?结构性就是类似的具有相同特征的东西,里面的数据就是结构性数据。
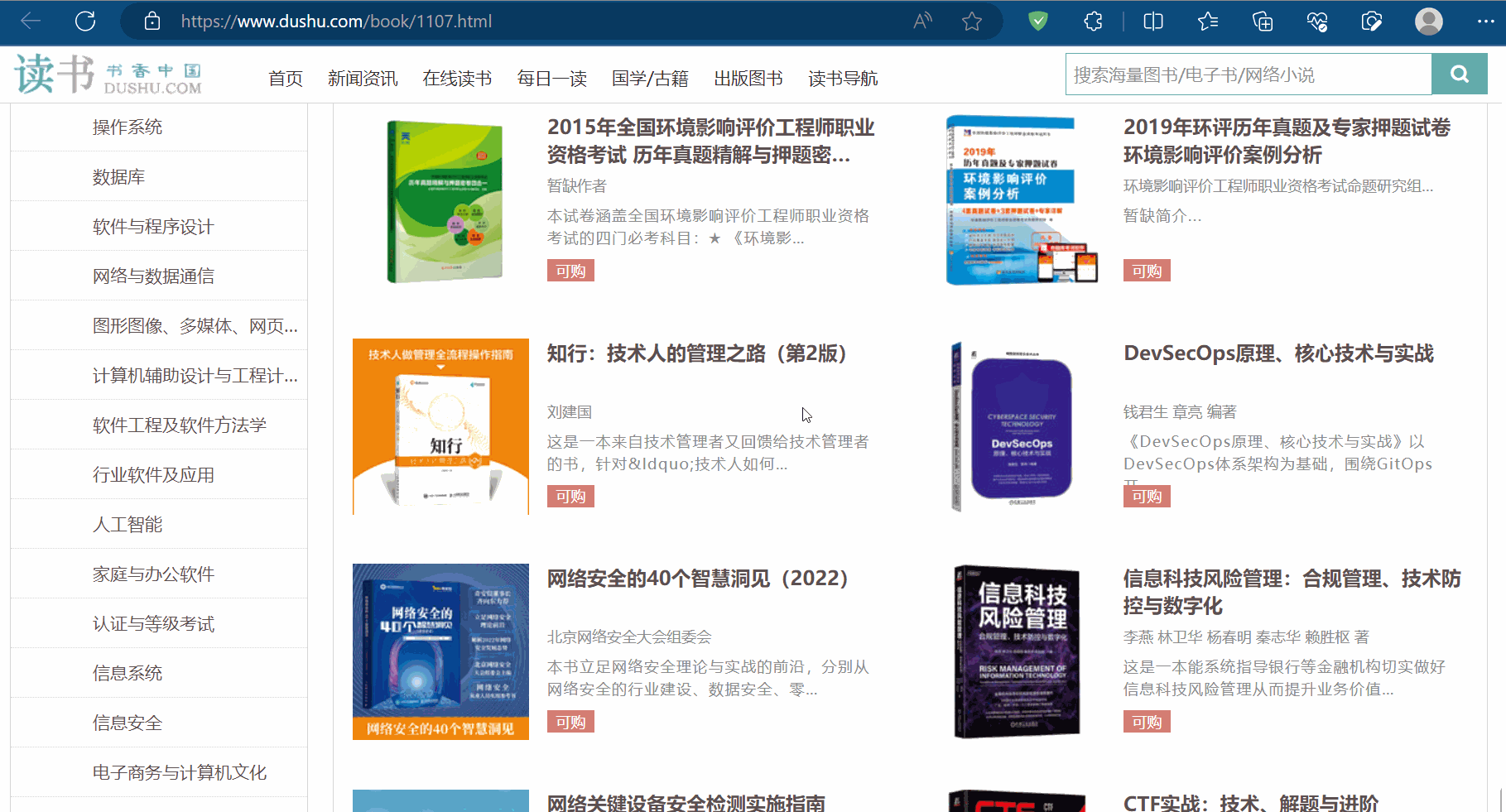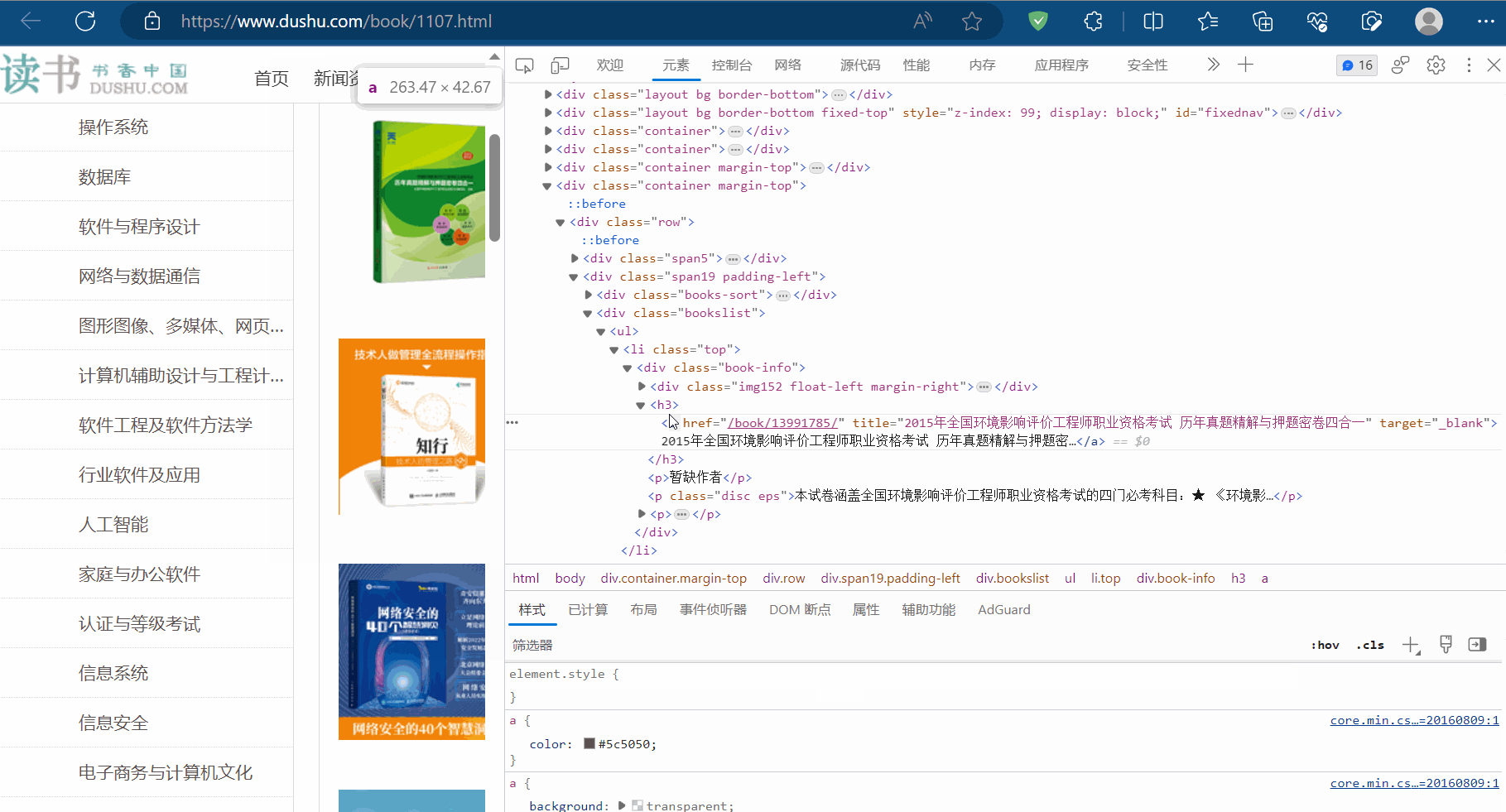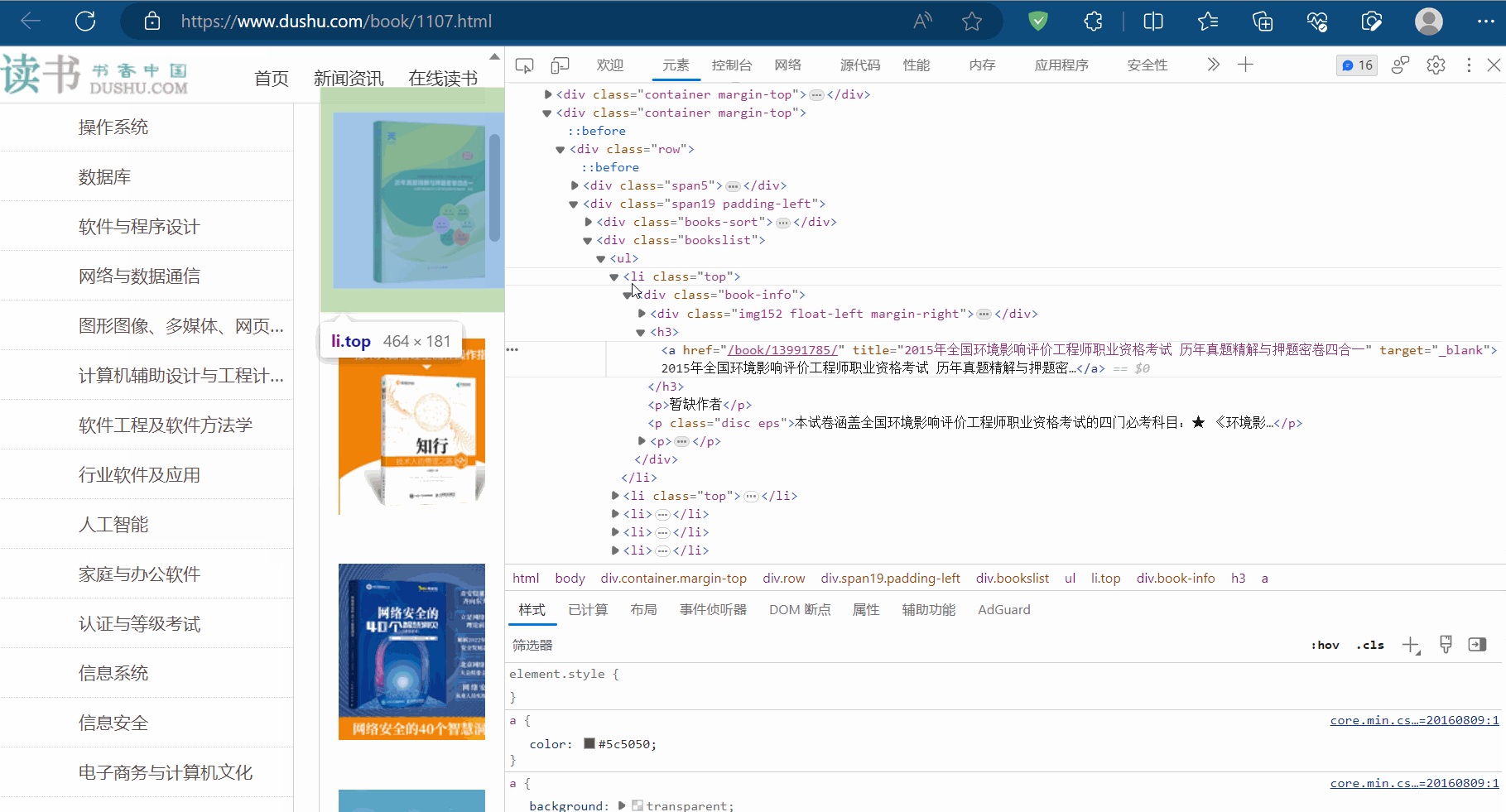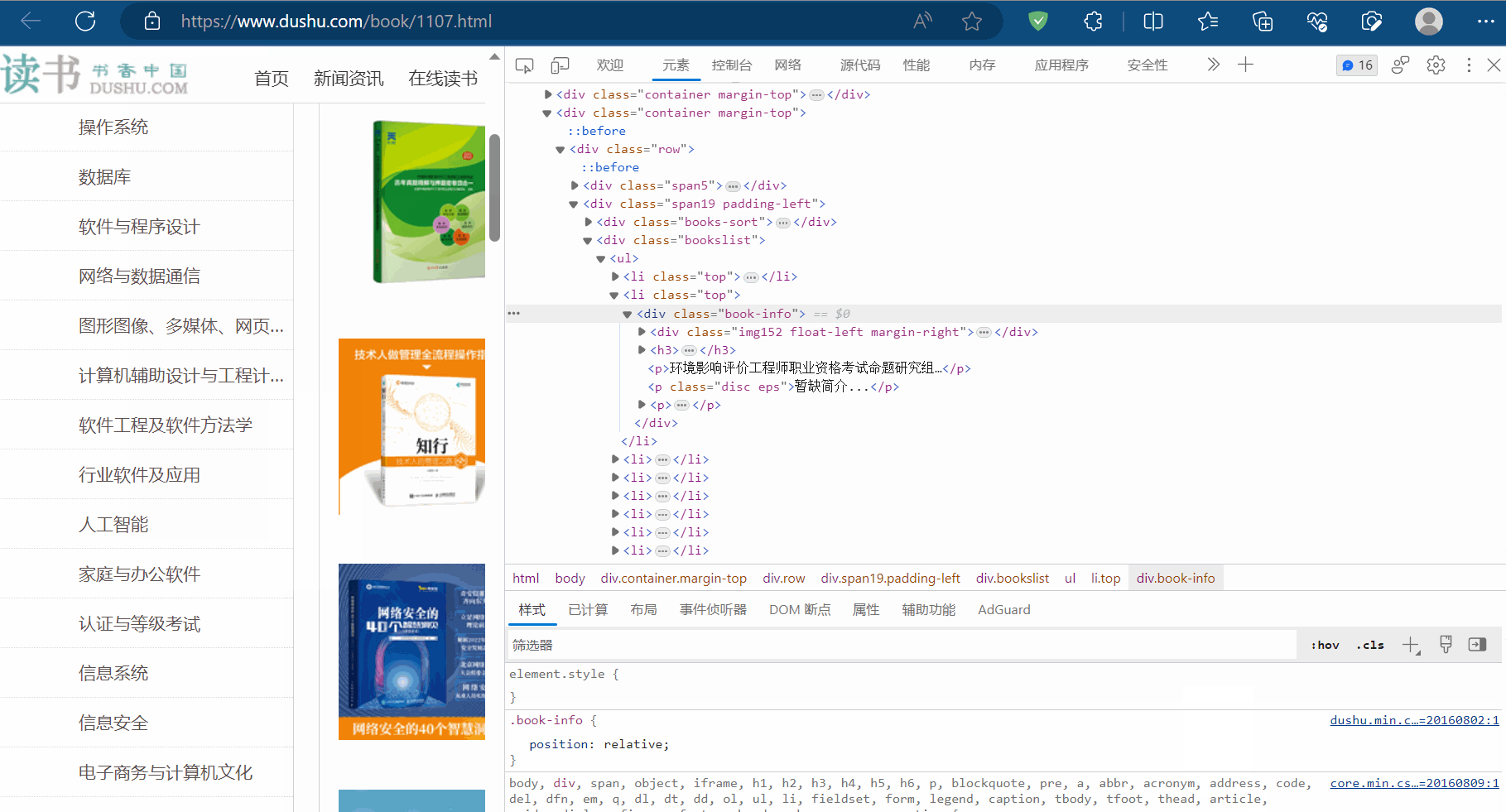
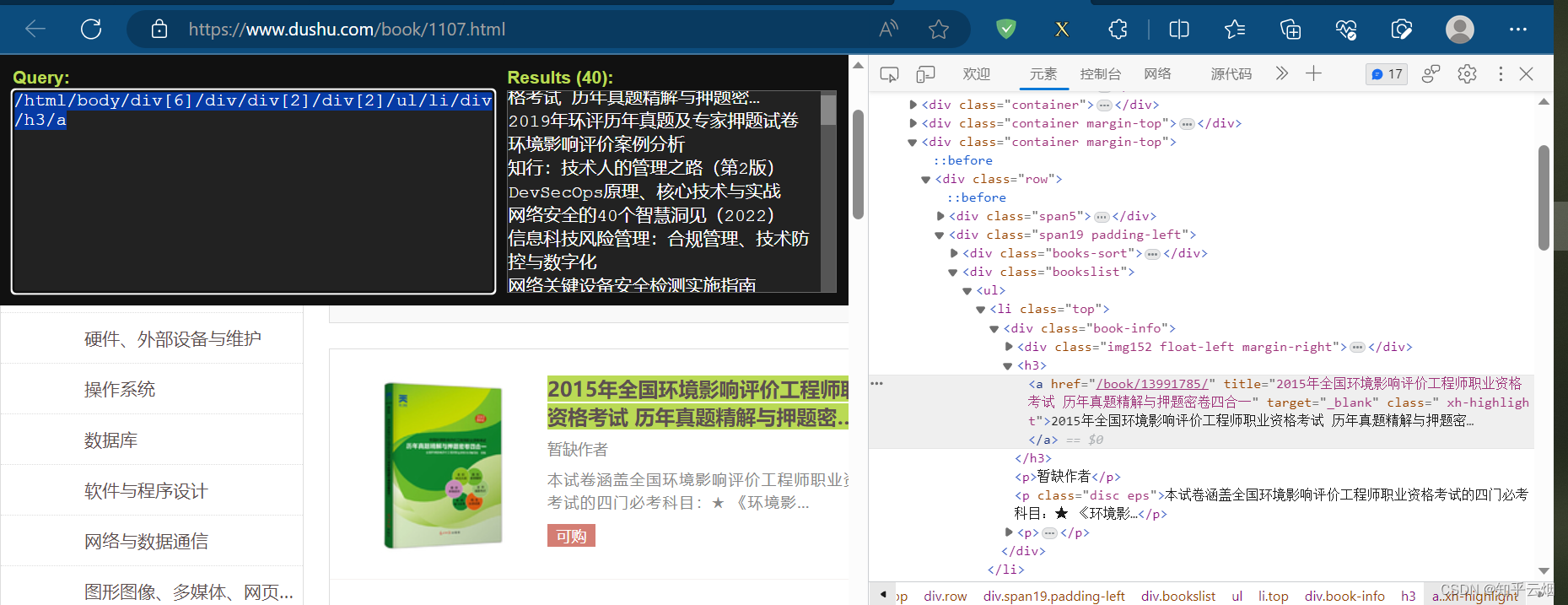
下面将举一个具体例子进行说明。打开读书网,点击“计算机/网络”。假如我们想采取这个网站中所有书的信息,包括名字、作者、简介、图片等。
如下图,选中一本书进行定位(即在某本书处打开检查),发现这些书的信息有一个相同的结构,比如书名都在结构“/html/body/div[6]/div/div[2]/div[2]/ul/li/div/h3/a”下,它们具有相同的结构,这就是结构性的例子。至于结构性数据,比如书名就是该结构下的数据。
(2)scrapy的安装
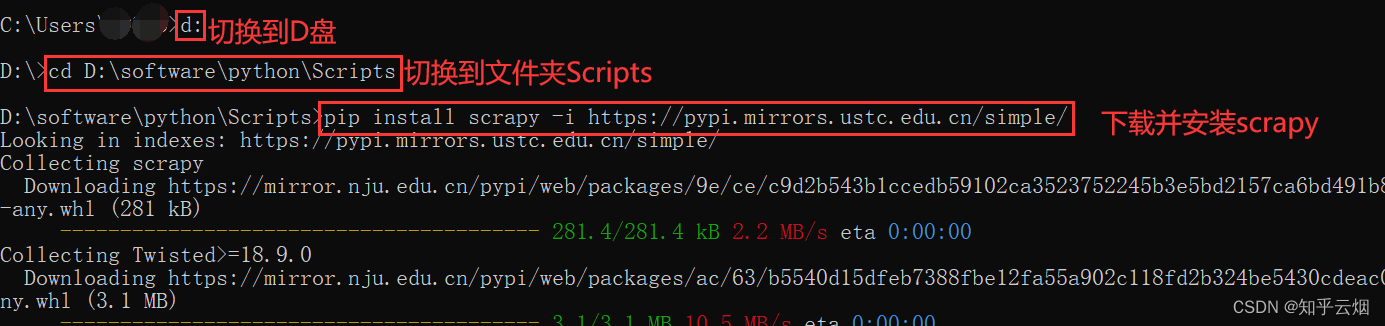
安装命令:pip install scrapy -i https://pypi.mirrors.ustc.edu.cn/simple/
安装具体步骤:如下图,先打开“命令提示符”。

然后在命令提示符里安装scrapy。
2. scrapy的基本使用
(1)scrap的使用步骤
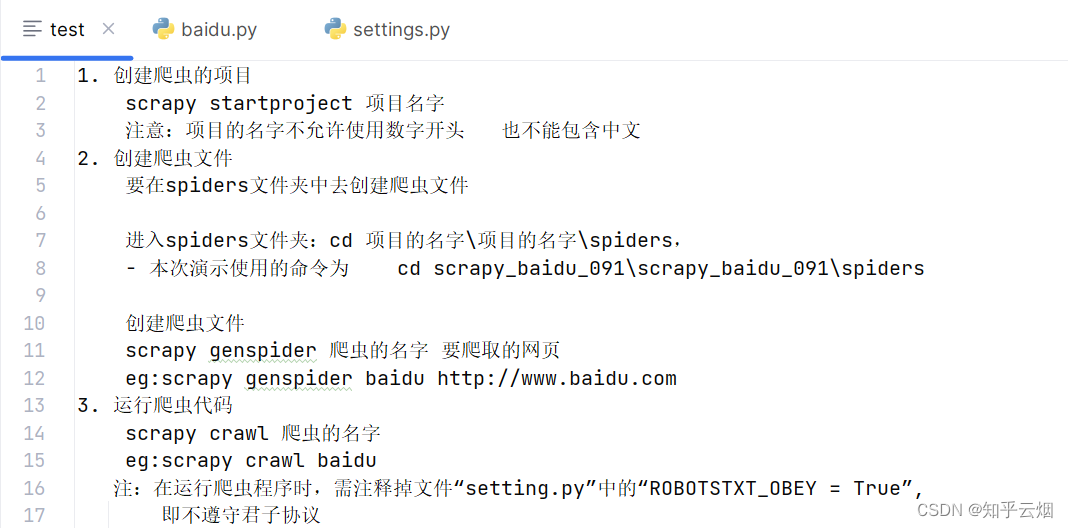
1. 创建爬虫的项目
scrapy startproject 项目名字
注意:项目的名字不允许使用数字开头 也不能包含中文
2. 创建爬虫文件
要在spiders文件夹中去创建爬虫文件
进入spiders文件夹:cd 项目的名字\项目的名字\spiders,
- 本次演示使用的命令为 cd scrapy_baidu_091\scrapy_baidu_091\spiders
创建爬虫文件
scrapy genspider 爬虫的名字 要爬取的网页
eg:scrapy genspider baidu http://www.baidu.com
3. 运行爬虫代码
scrapy crawl 爬虫的名字
eg:scrapy crawl baidu
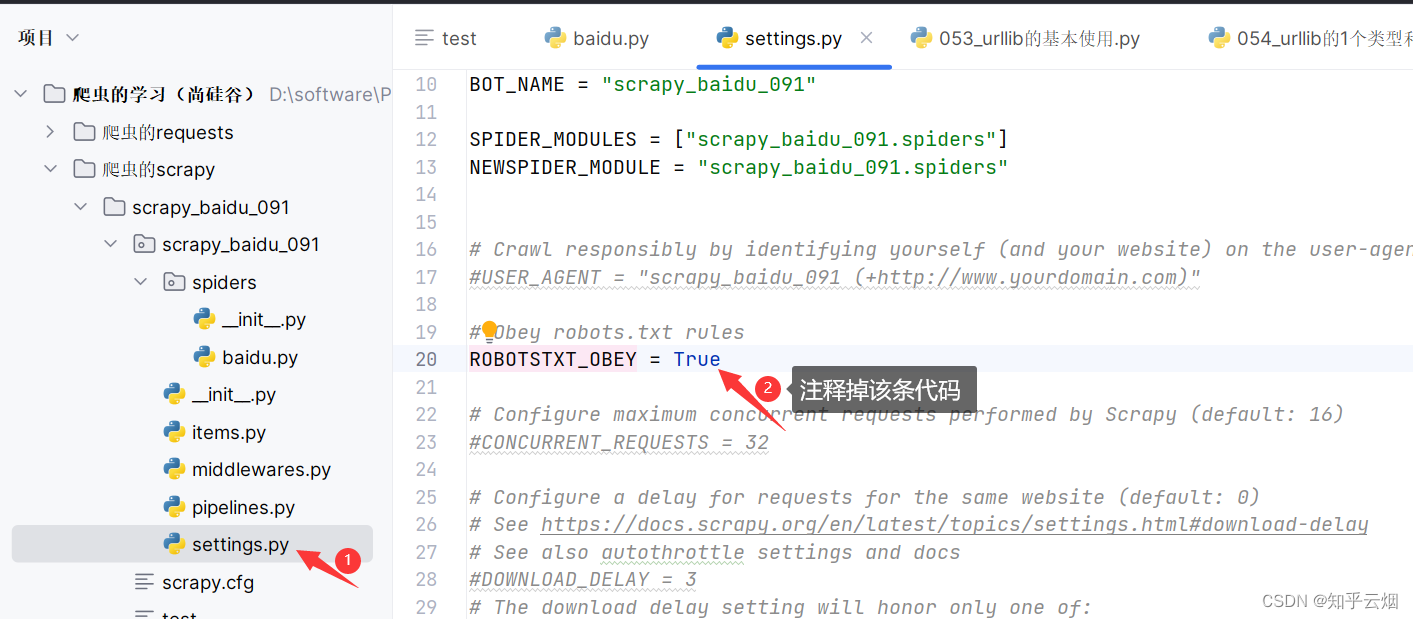
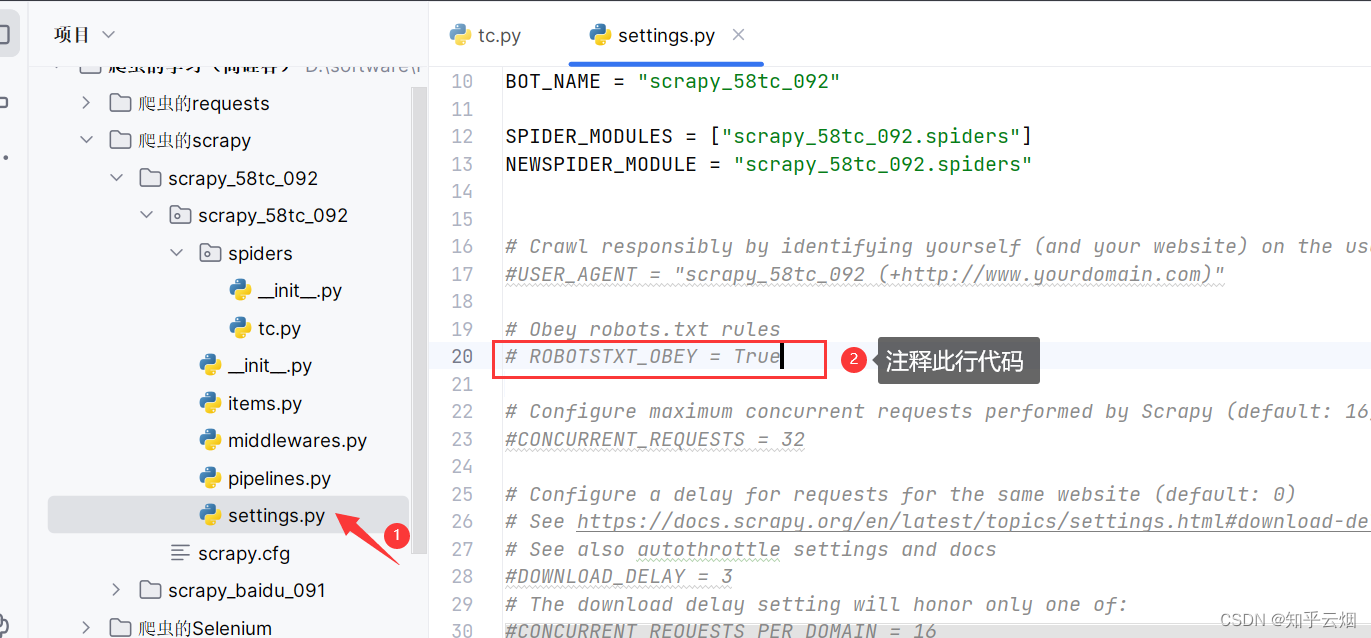
注:在运行爬虫程序时,需注释掉文件“setting.py”中的“ROBOTSTXT_OBEY = True”,
即不遵守君子协议
注意,对于请求的地址,如果含有符号&,则需改成”&”或’&’,不然会报错。
(2)代码的演示
本次演示的目的就是使用scrapy让百度打印一句话,进而熟悉scrapy的基本使用。如下图,创建文件夹“爬虫的scrapy”。
如下图所示,找到新建的文件夹,在命令提示符窗口中将路径切换到这个文件夹。


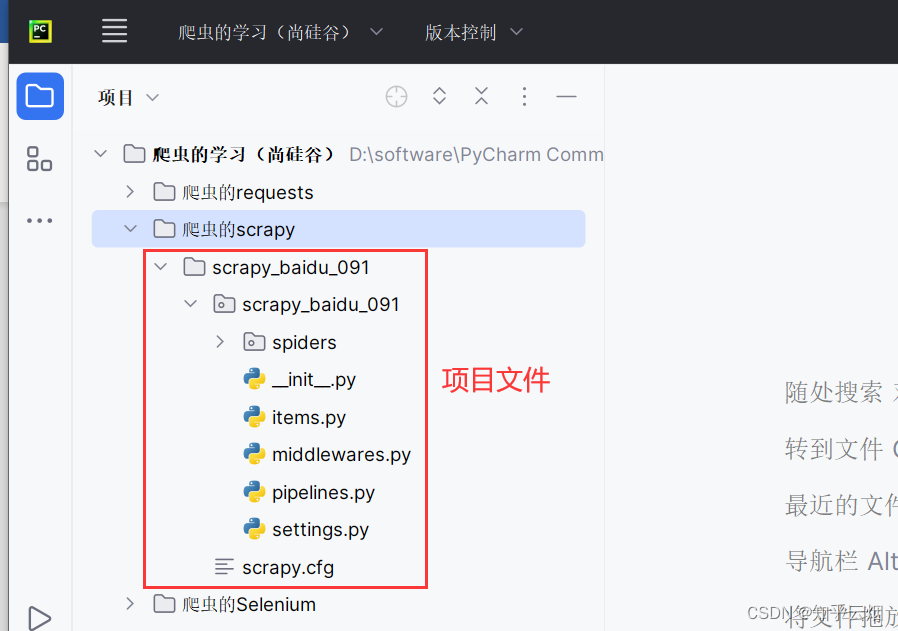
输入命令“scrapy startproject scrapy_baidu_091”来创建一个名为“scrapy_baidu_091”的项目。可以到PyCharm中去查看是否有对应的项目文件。

再在项目文件夹里创建一个test文件,用来记笔记。然后如下所示,将本次演示的思路进行记录。(其实这个test里面记的笔记是随着程序的编写而记录的,但是本人直接放在此处,以便对整个演示有个指导作用。)
1. 创建爬虫的项目
scrapy startproject 项目名字
注意:项目的名字不允许使用数字开头 也不能包含中文
2. 创建爬虫文件
要在spiders文件夹中去创建爬虫文件
进入spiders文件夹:cd 项目的名字\项目的名字\spiders,
- 本次演示使用的命令为 cd scrapy_baidu_091\scrapy_baidu_091\spiders
创建爬虫文件
scrapy genspider 爬虫的名字 要爬取的网页
eg:scrapy genspider baidu http://www.baidu.com
3. 运行爬虫代码
scrapy crawl 爬虫的名字
eg:scrapy crawl baidu
注:在运行爬虫程序时,需注释掉文件“setting.py”中的“ROBOTSTXT_OBEY = True”,
即不遵守君子协议
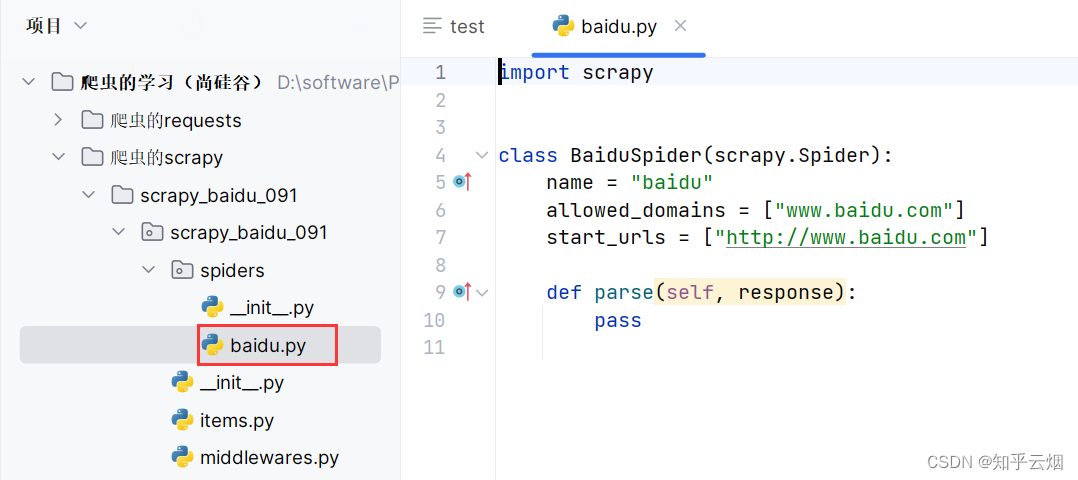
然后使用命令“cd scrapy_baidu_091\scrapy_baidu_091\spiders”切换到文件夹spiders下,使用命令“scrapy genspider baidu http://www.baidu.com”创建爬虫文件(即“baidu.py”)。

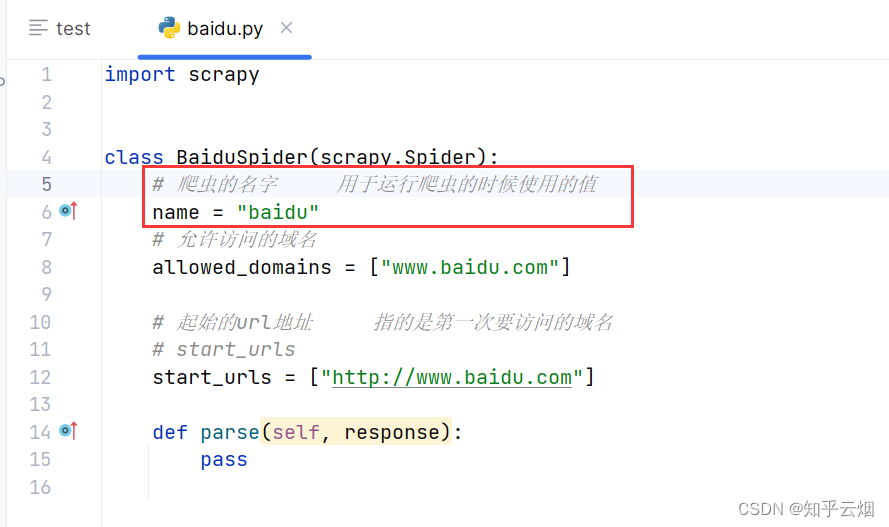
需要知道的是,爬虫的名字一般用于运行爬虫的时候使用的值。
如下,对文件“baidu.py”进行编程,然后再在“命令提示符”窗口中输入“scrapy crawl baidu”运行爬虫代码,发现并没有"苍茫的天涯是我的爱"。说明存在反爬手段。
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候使用的值
name = "baidu"
# 允许访问的域名
allowed_domains = ["www.baidu.com"]
# 起始的url地址 指的是第一次要访问的域名
# start_urls
start_urls = ["http://www.baidu.com"]
# 下面是执行start_urls之后执行的的方法 方法中的response就是返回的那个对象,
# 相当于 response = urllib.request.uropen()
# response = requests.get()
def parse(self, response):
print("苍茫的天涯是我的爱")

第一个需要解决的是所谓的君子协议,故去文件“setting.py”中注释掉图中所示的代码,即不遵守该协议。(注:scrapy一看就是爬虫程序,理论上得遵守君子协议。但有时仅仅是为了爬取网页上公开的不涉及隐私的、且不会对网站造成任何危害的、不用作商业用途、不损害他人利益、合理合法的使用,一般也没人管,也不会出现问题。)
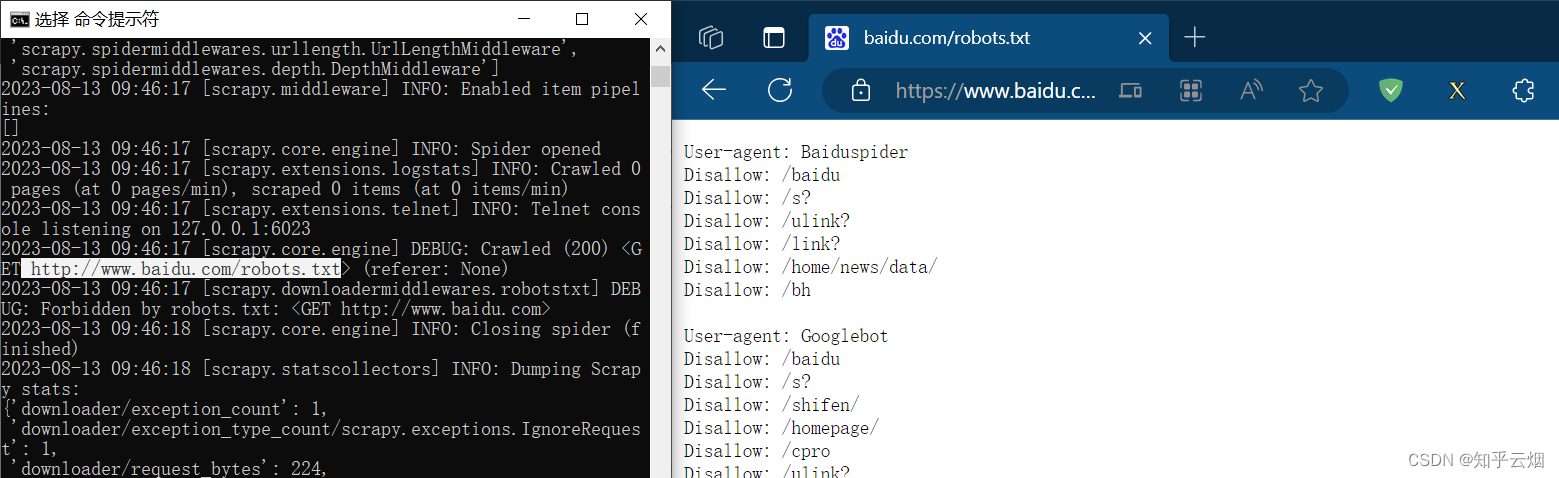
然后再次运行程序,发现“苍茫的天涯是我的爱”已经成功被打印。


3. scrapy之58同城项目结构和基本方法(注:58同城的数据不是公开数据,不能爬取;本次代码也爬取不到相应的数据)
(1)scrapy项目的组成

项目名字
项目名字
spiders文件夹(存储的是爬虫文件)
init
自定义的爬虫文件 核心功能文件 ********
init
items 定义数据结构的地方 即爬取的数据都包含哪些
middlewares 称为中间件 用来设置代理机制
pipelines 称为管道 用来处理下载的数据
settings 称为配置文件 robots协议、UA定义的地方
(2)scrapy爬虫文件的组成以及响应response的属性和方法

response.text 获取的是响应的字符串
response.body 获取的是二进制数据
response.xpath 可以直接是xpath方法来解析response中的内容
response.extract() 提取seletor对象的data属性值
response.extract_first() 提取的seletor列表的第一个数据
(3)代码演示
本次将通过58同城(“https://cn.58.com/”)来介绍response的属性和方法。如下图,打开58同城,搜索前端开发。
然后寻找该网页的接口。打开检查,点击网络,清空一下接口,再刷新,很容易就找到了接口。
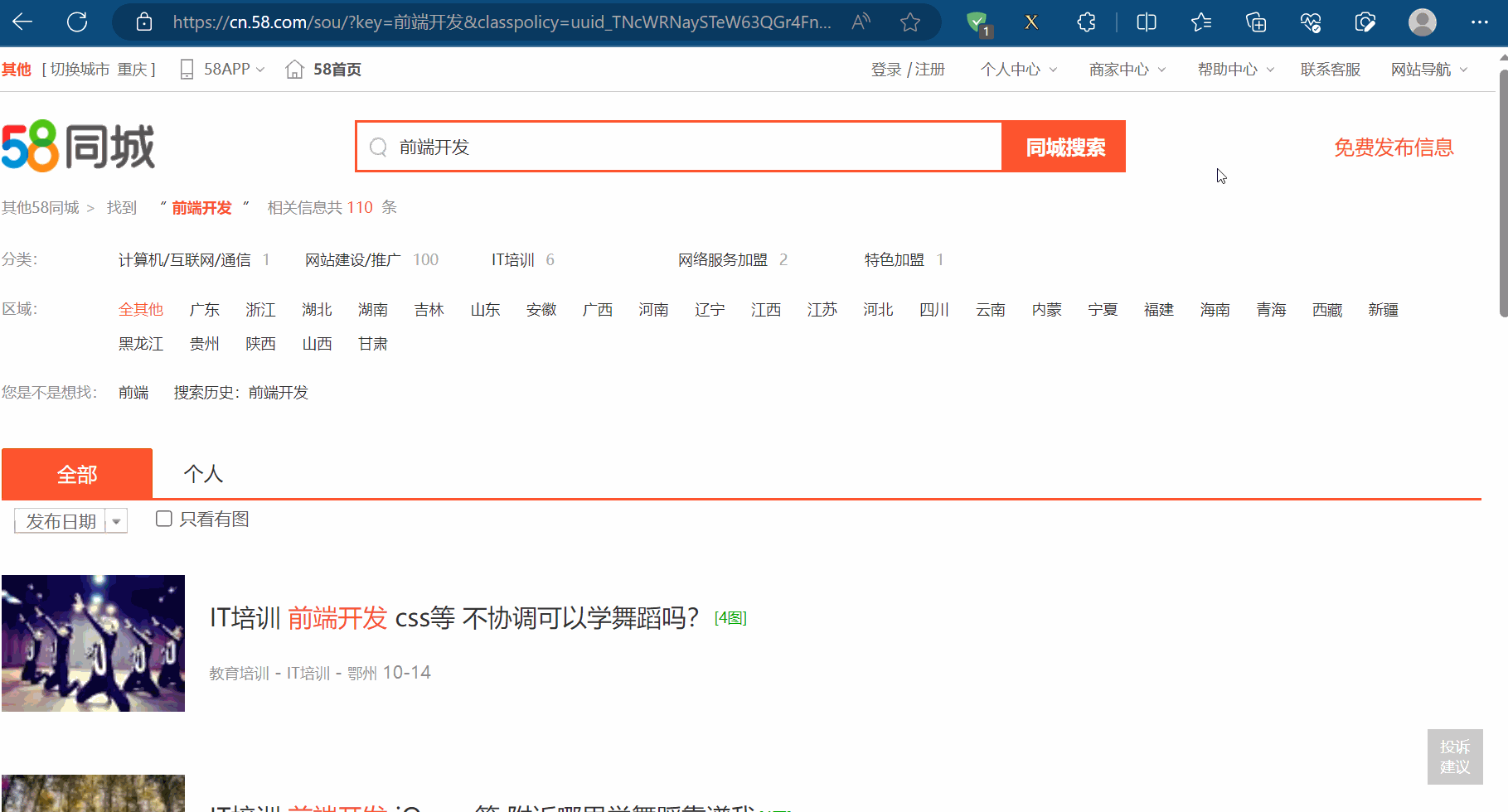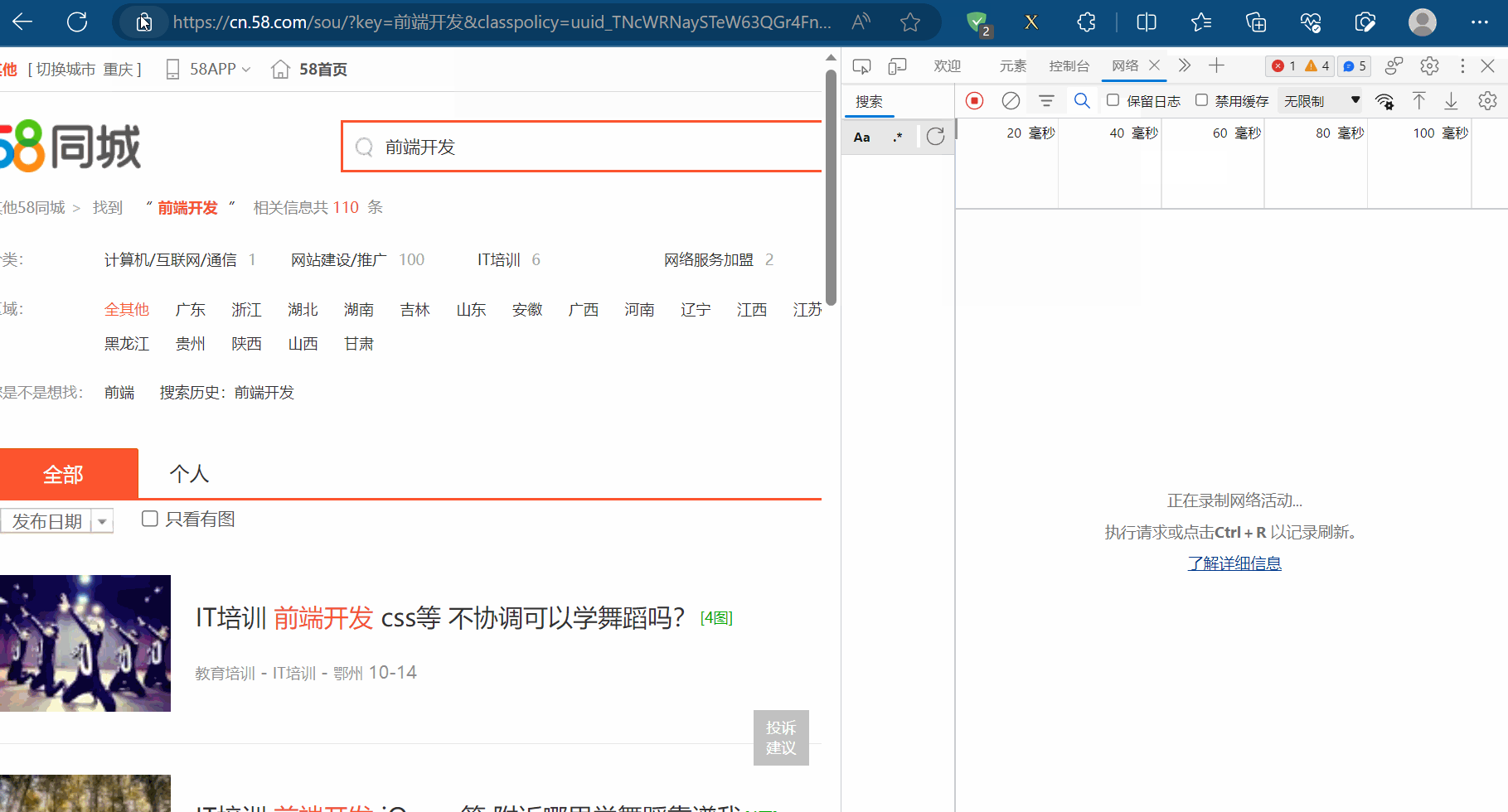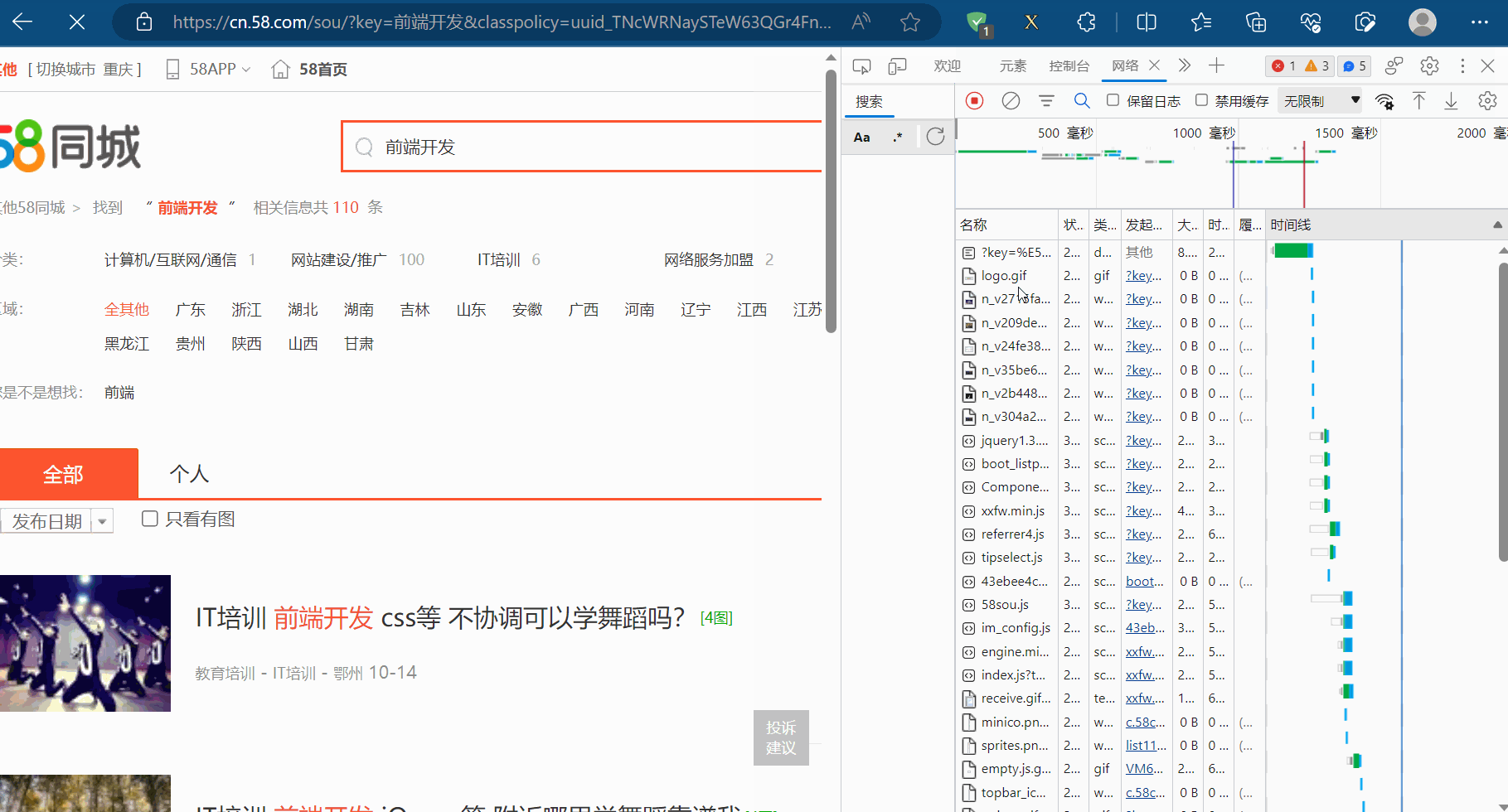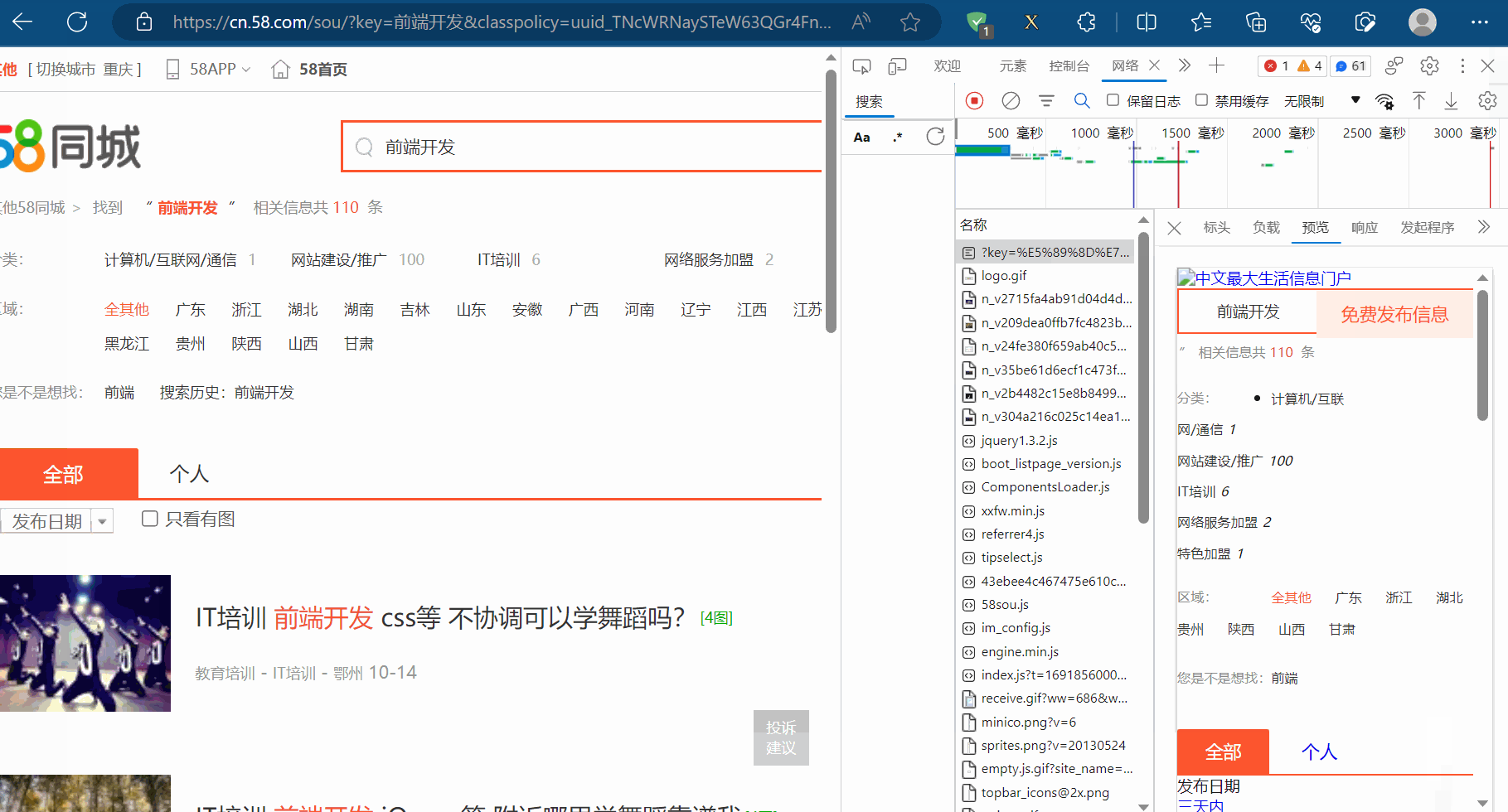
然后去命令提示符创建项目,其实PyCharm终端也可以,本次以终端进行演示。如下图所示,成功创建名为“scrapy_58tc_092”的项目(命令依次为“cd 爬虫的scrapy”、“scrapy startproject scrapy_58tc_092”)。

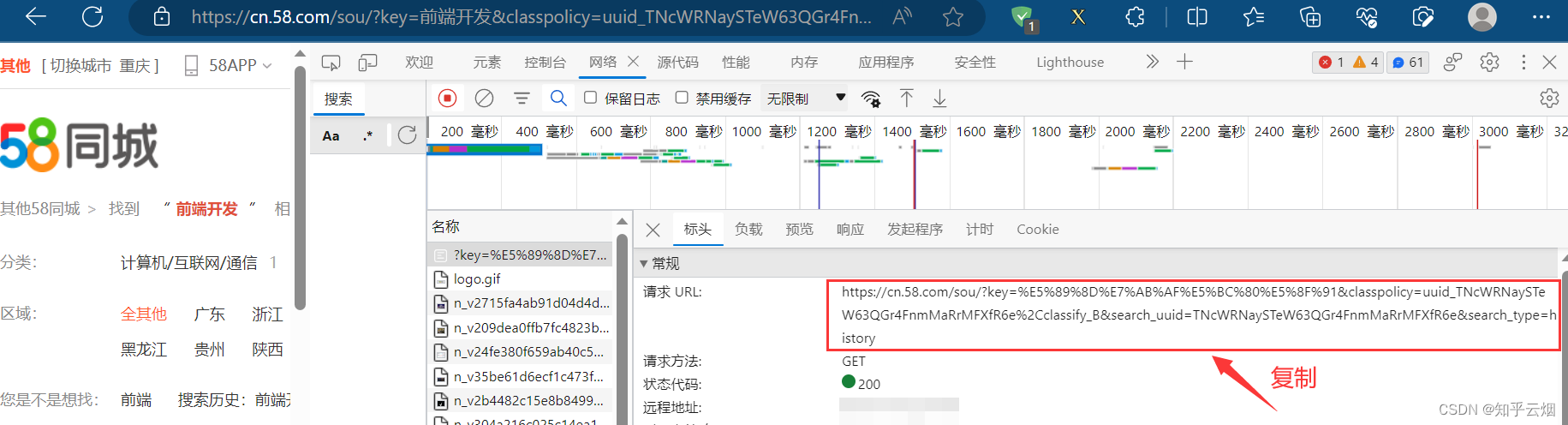
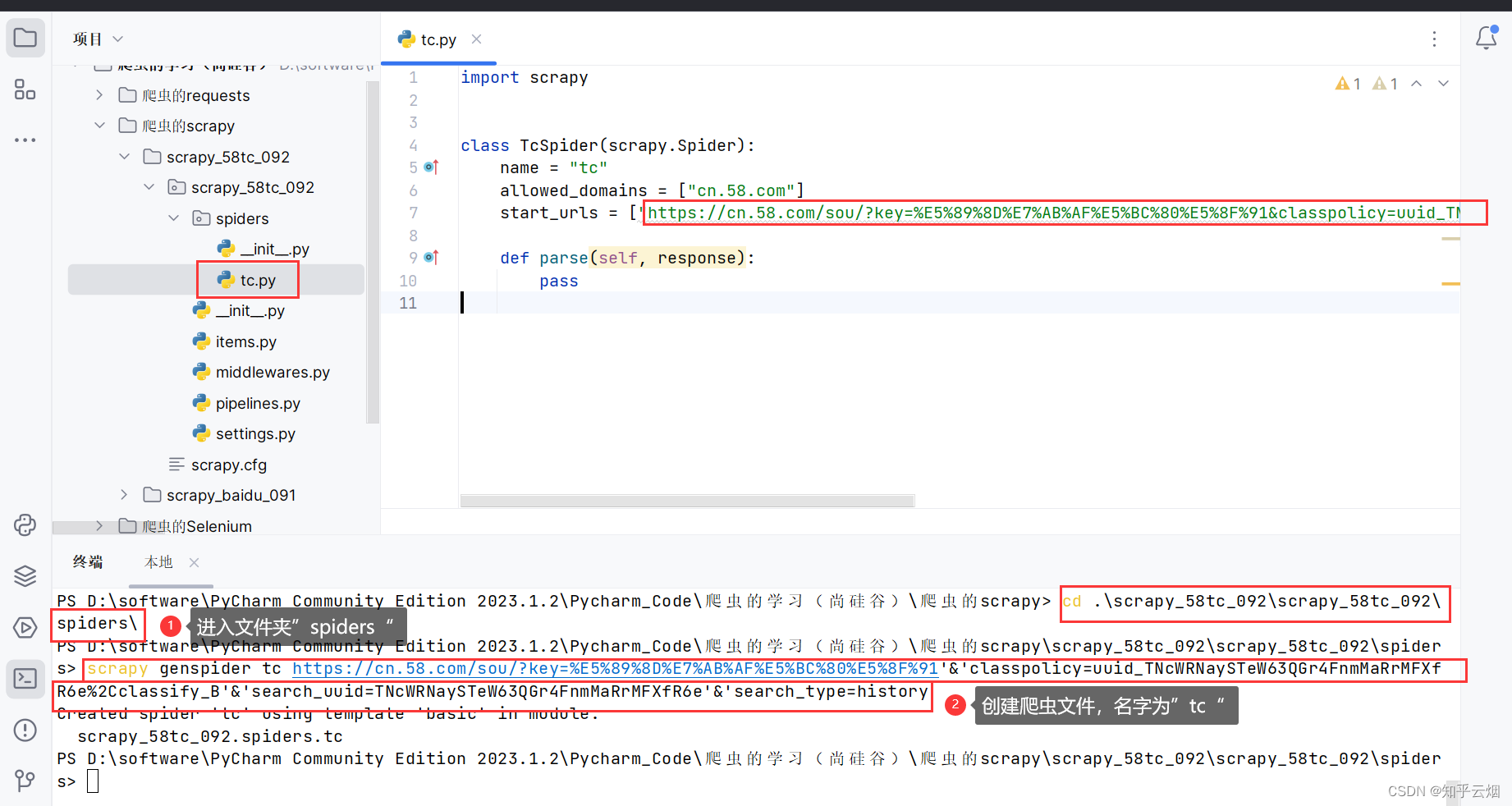
接着复制接口的请求地址,再在PyCharm的终端中进入文件夹“spiders”(命令为“cd .\scrapy_58tc_092\scrapy_58tc_092\spiders\”),再使用命令“scrapy genspider tc 接口请求的地址”创建爬虫文件。(注意:对于请求的地址,如果含有符号&,则需改成”&”或’&’,不然会报错)
如下图,注释掉遵守君子协议(即图中所示代码)。
然后回到爬虫文件,然后如下图所示修改一句代码,运行一下代码文件(指令为“scrapy crawl tc”),验证是否能够成功运行。

然后创建一个名为“test”的文件,用来说明scrapy项目的结构以及response的属性和方法,具体如下。(所记内容应该随着演示的进度边做边记录,但为了起指导作用,个人直接听完了然后再来写的笔记)
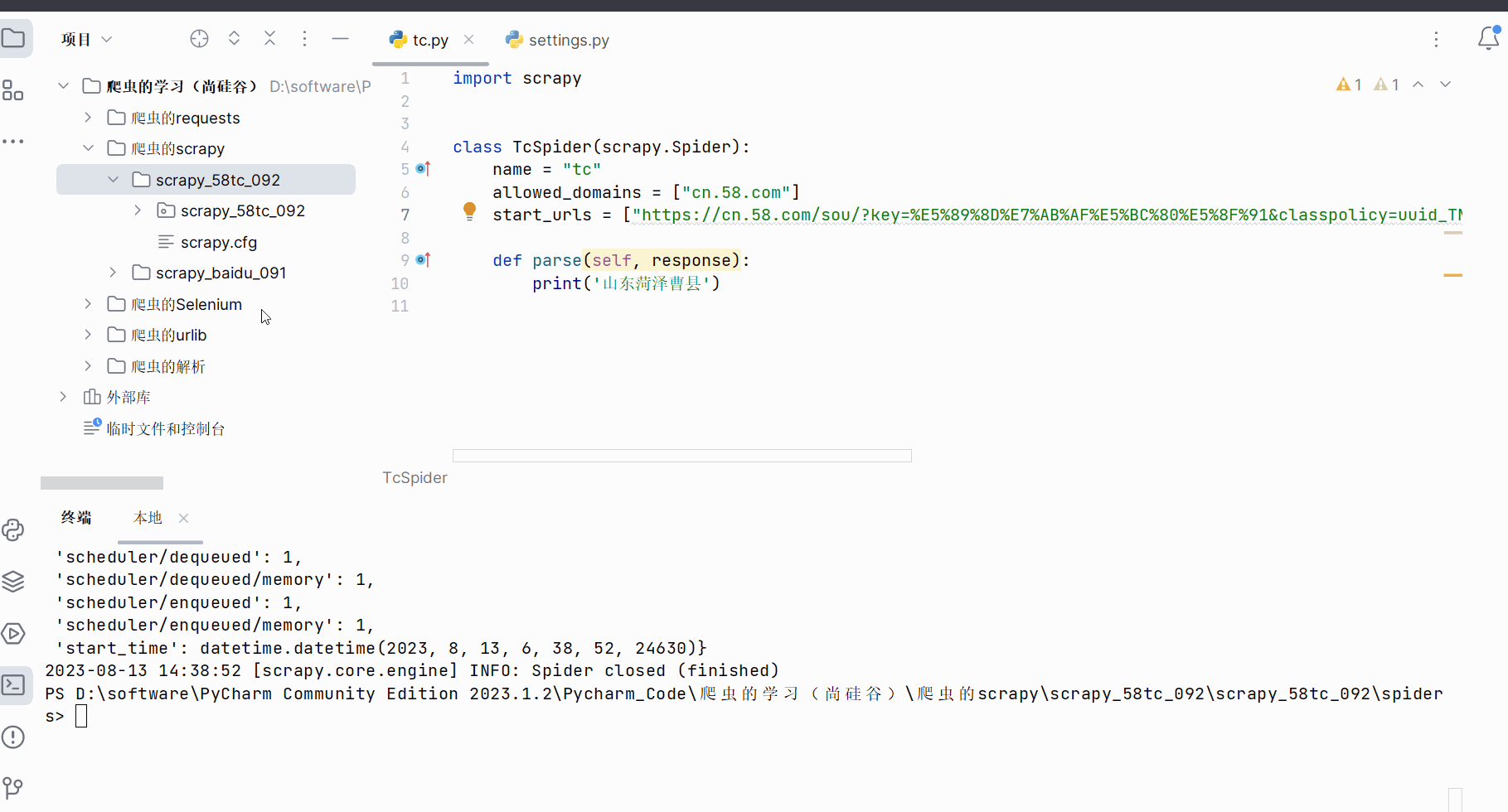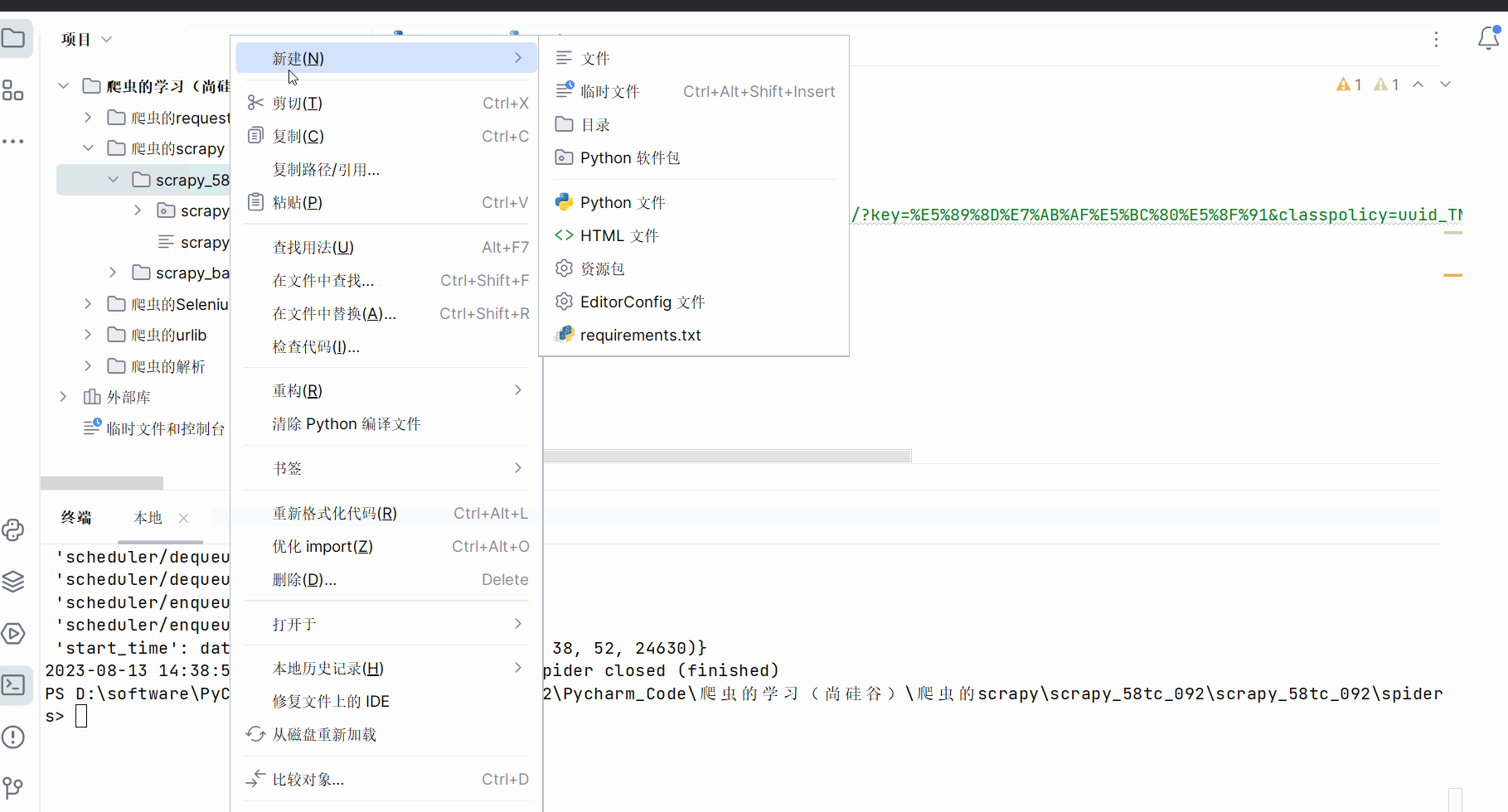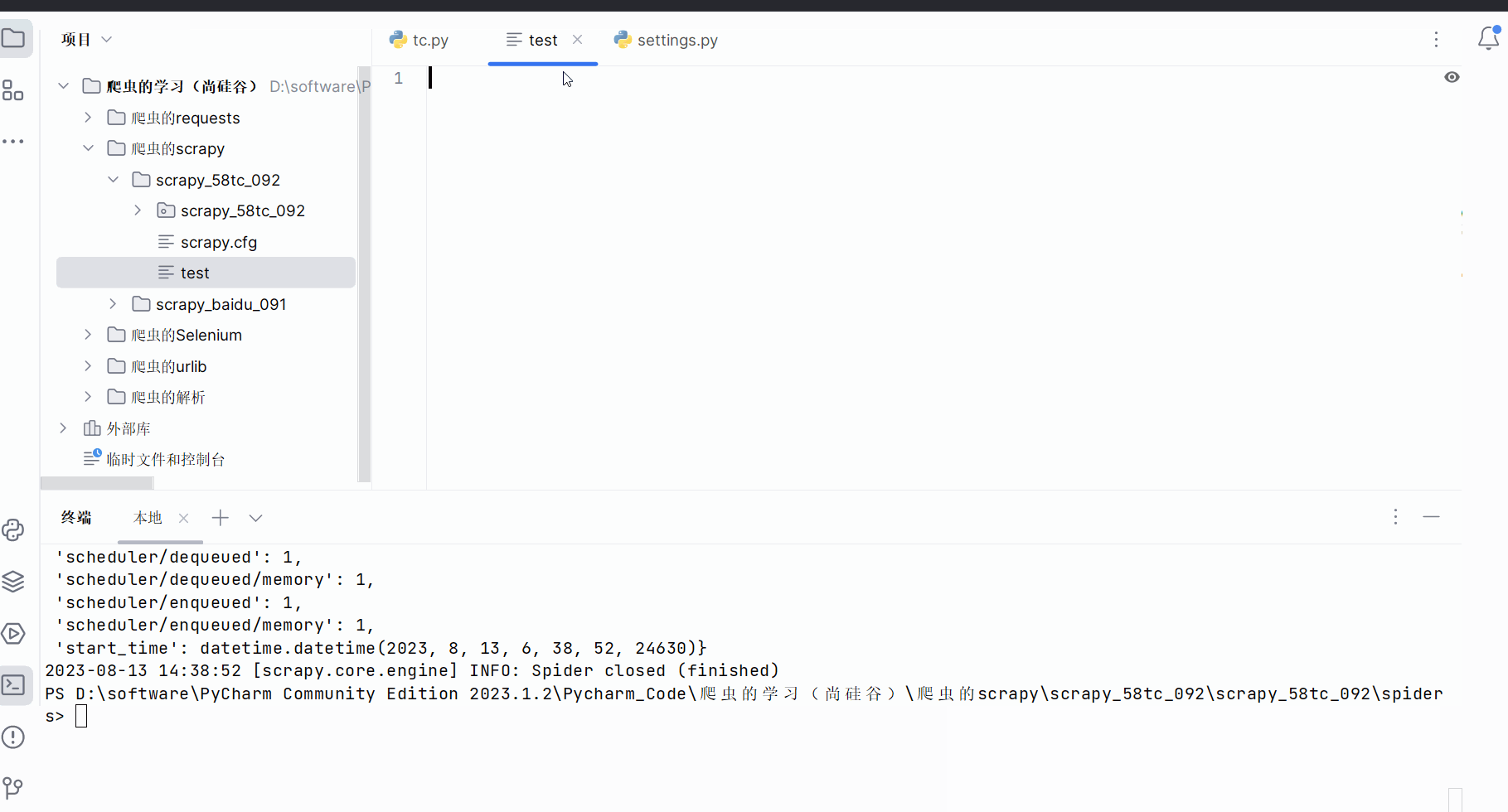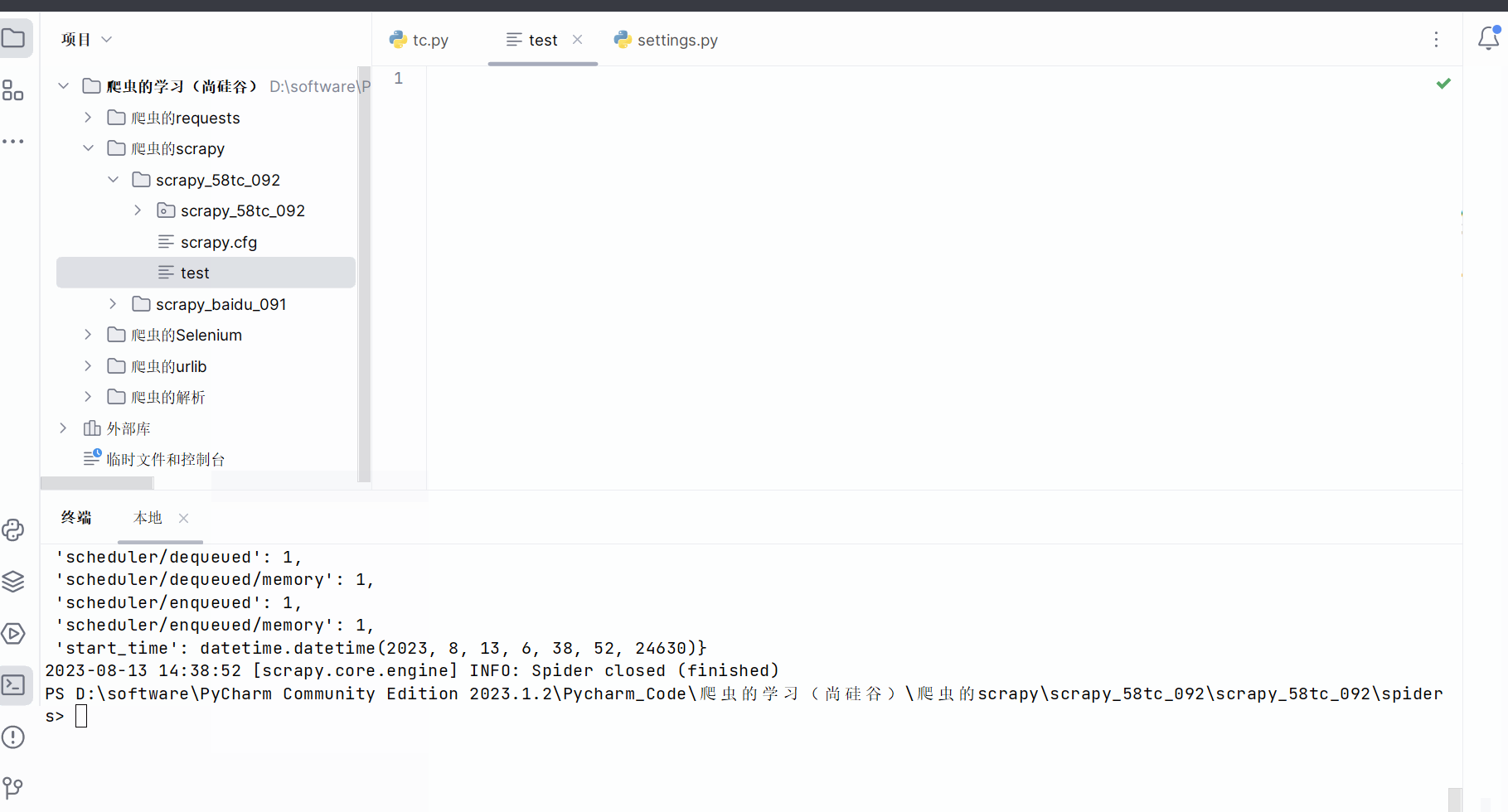
1. scrapy项目的结构
项目名字
项目名字
spiders文件夹(存储的是爬虫文件)
init
自定义的爬虫文件 核心功能文件 ********
init
items 定义数据结构的地方 即爬取的数据都包含哪些
middlewares 称为中间件 用来设置代理机制
pipelines 称为管道 用来处理下载的数据
settings 称为配置文件 robots协议、UA定义的地方
2. response的属性和方法
response.text 获取的是响应的字符串
response.body 获取的是二进制数据
response.xpath 可以直接是xpath方法来解析response中的内容
response.extract() 提取seletor对象的data属性值
response.extract_first() 提取的seletor列表的第一个数据
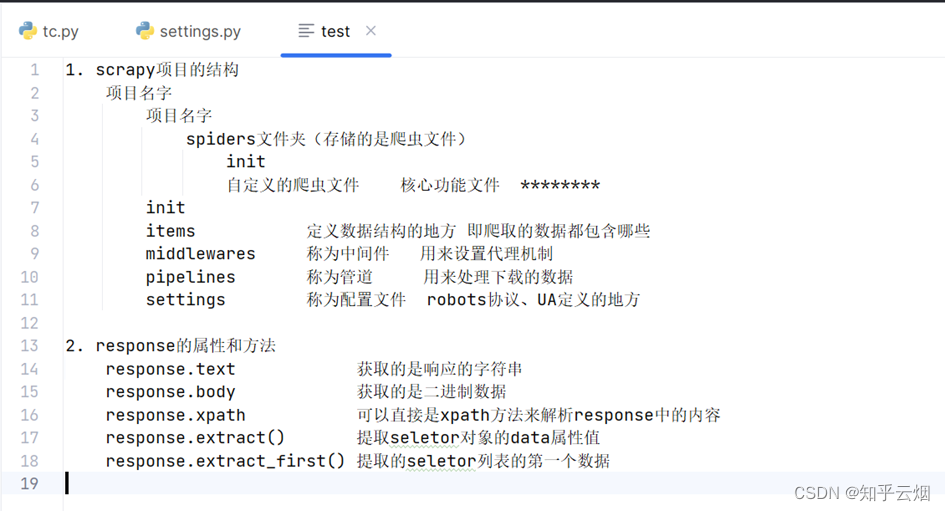
然后爬虫文件“tc.py”中进行如下编程运行(运行指令“scrapy crawl tc”),验证是否能获取网页源码。发现网页需要进行58同城的验证。
import scrapy
class TcSpider(scrapy.Spider):
name = "tc"
allowed_domains = ["cn.58.com"]
start_urls = [
"https://cn.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpoli-cy=uuid_TNcWRNaySTeW63QGr4FnmMaRrMFXfR6e%2Cclassify_B&search_uuid=TNcWRNaySTeW63QGr4FnmMaRrMFXfR6e&search_type=history"]
def parse(self, response):
content = response.text # 获取网页源码
print('=================================') # 打印此行,便于寻找代码的执行结果
print(content)
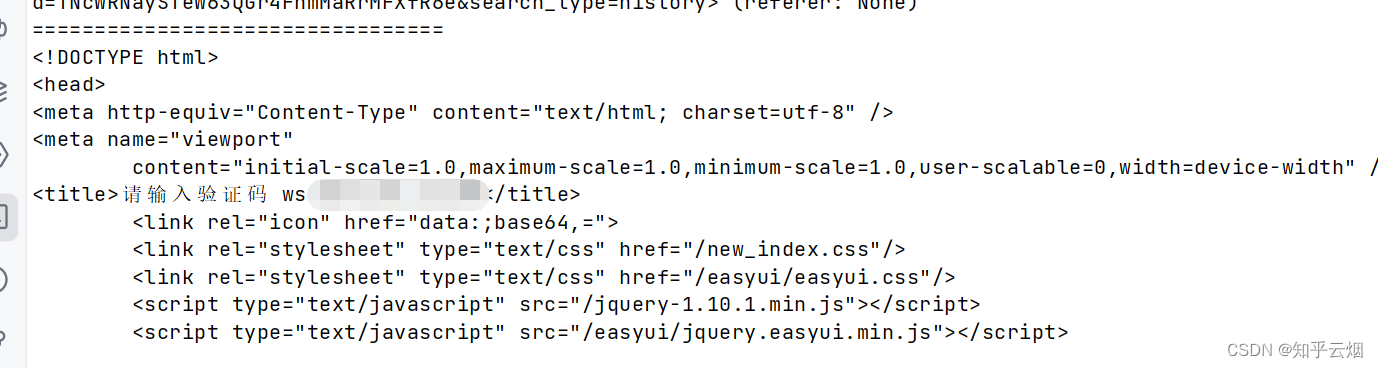
试了一会不会获取,想要研究的自己去搞。而且去网上查了下,还有人因为爬取58同城的数据而犯法的,吓得赶紧上网查了查关于爬虫的法律法规。
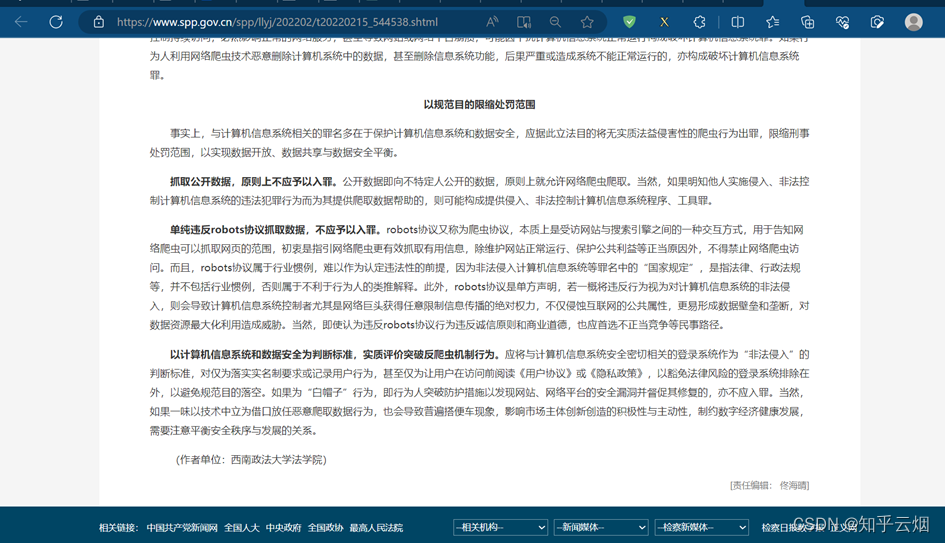
下面的话仅为个人观点:由上图可见单纯的抓取公开数据、仅仅违背robots君子协议都不是违法行为。相反,爬虫技术的发展在一定程度上促进了反爬技术的发展。另外,58同城那些数据,确实属于他们的商业信息,不属于公开信息,不应该被随便爬取。不得不说的是,58同城的一些数据通过鼠标点击就能查看到,如果58同城如果没有设立反爬机制,让爬虫轻松爬取到了信息,那样的话自身也有一定责任,信息保护不到位,未成功让爬虫行为人知道这个不是公开信息,不应该爬取58同城的信息。另外,爬虫行为人也应当思考,58同城是靠一些数据信息营业的,不应该去获取他们的数据。还有那几个违法的过分了,绕开反爬机制来爬取非法数据就存在问题了,还用去盈利,错上加错啊。
因此,我们就不要想着突破58同城,去获取任何数据了。不能突破验证码的代码如下。
import scrapy
class TcSpider(scrapy.Spider):
name = "tc"
allowed_domains = ["cn.58.com"]
start_urls = [
"https://cn.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&classpoli-cy=uuid_TNcWRNaySTeW63QGr4FnmMaRrMFXfR6e%2Cclassify_B&search_uuid=TNcWRNaySTeW63QGr4FnmMaRrMFXfR6e&search_type=history"]
# 请求头
headers = {
'User-Agent': 'ozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)'
}
def parse(self, response):
# 1.字符串
content = response.text # 获取网页源码
# 2.二进制数据
# content = response.body
# print('=================================') # 打印此行,便于寻找代码的执行结果
# print(content)
span = response.xpath('xpath路径[0]')
print('=================================') # 打印此行,便于寻找代码的执行结果
print(span.extract())
4. 汽车之家scrapy工作原理
(1)scrapy架构组成

(2)scrapy的工作原理
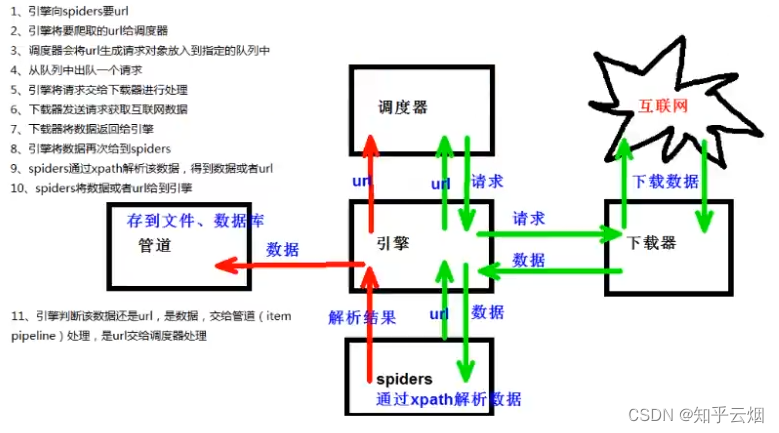
scrapy的工作原理如上图所示,观察绿色的箭头、红色的箭头回路后发现,爬虫spiders先发送一个url给引擎,引擎再将这个url送给调度器。之后,调度器就会生成一个请求对象并发送给引擎,引擎再将这个请求送给下载器,下载器再去向互联网下载数据,并将数据送回引擎,引擎再将数据送给spiders,这个数据就是scrapy爬虫文件中的response,然后spiders再根据需要使用xpath路径来解析数据得到一个解析结果。如果这个解析结果是url,它就会将刚刚的过程再执行一遍;如果这个解析结果是数据,它就被管道下载并保存了。
(3)代码演示
本次将演示如何获取汽车之家中,爬取我们感兴趣的数据,这里具体爬取了热门宝马汽车的名字和价格。
如下图,搜索“汽车之家”(其官网链接为汽车之家),搜索“宝马 热门车”,进入宝马热门车的页面。然后打开检查,点击网络,刷新页面,找到页面的接口。然后复制该接口的请求地址。
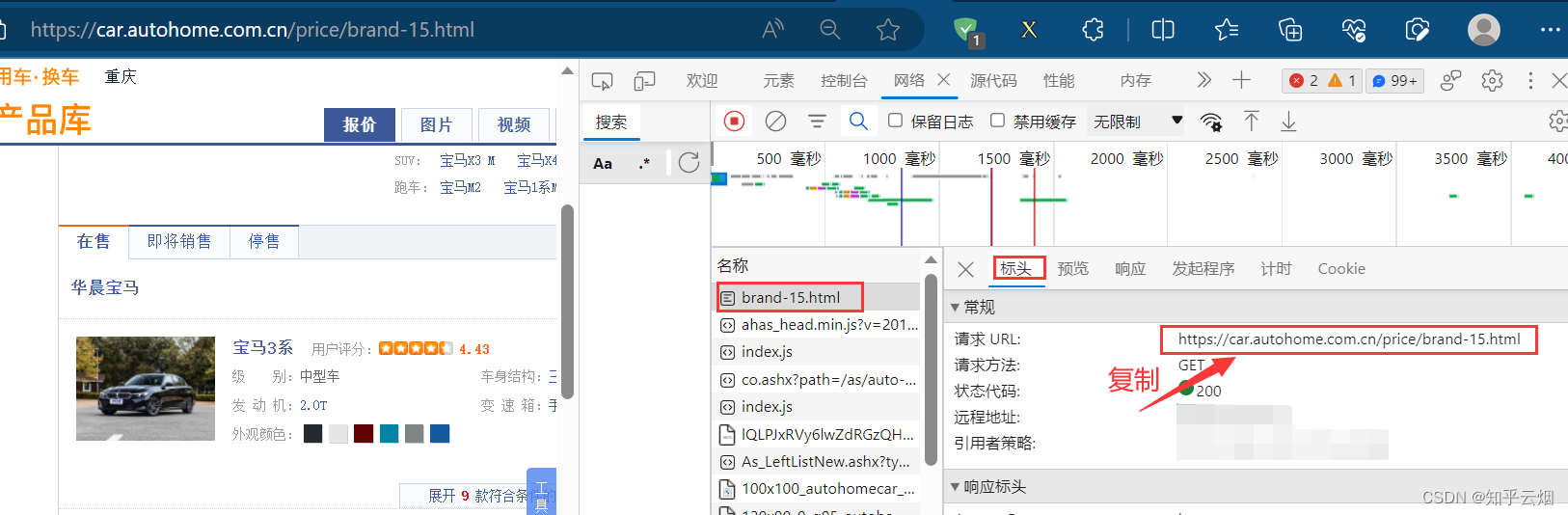
使用指令进入文件夹“爬虫的scrapy”(“cd .\爬虫的scrapy\”),创建名为“scrapy_carhome_093”的项目(“scrapy startproject scrapy_carhome_093”)。
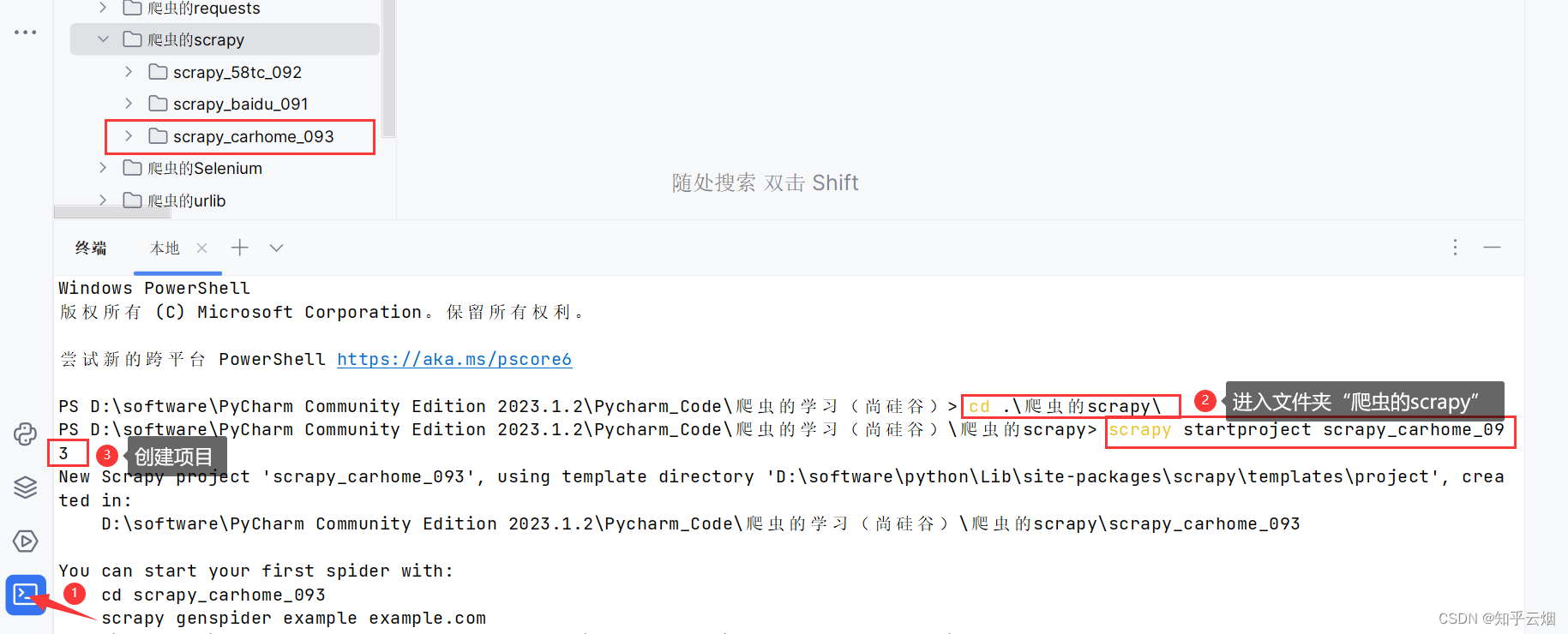
如下图所示,进入文件夹spiders(“cd .\scrapy_carhome_093\scrapy_carhome_093\spiders\”)中创建爬虫文件“car.py”(“scrapy genspider car 接口的请求地址”)。
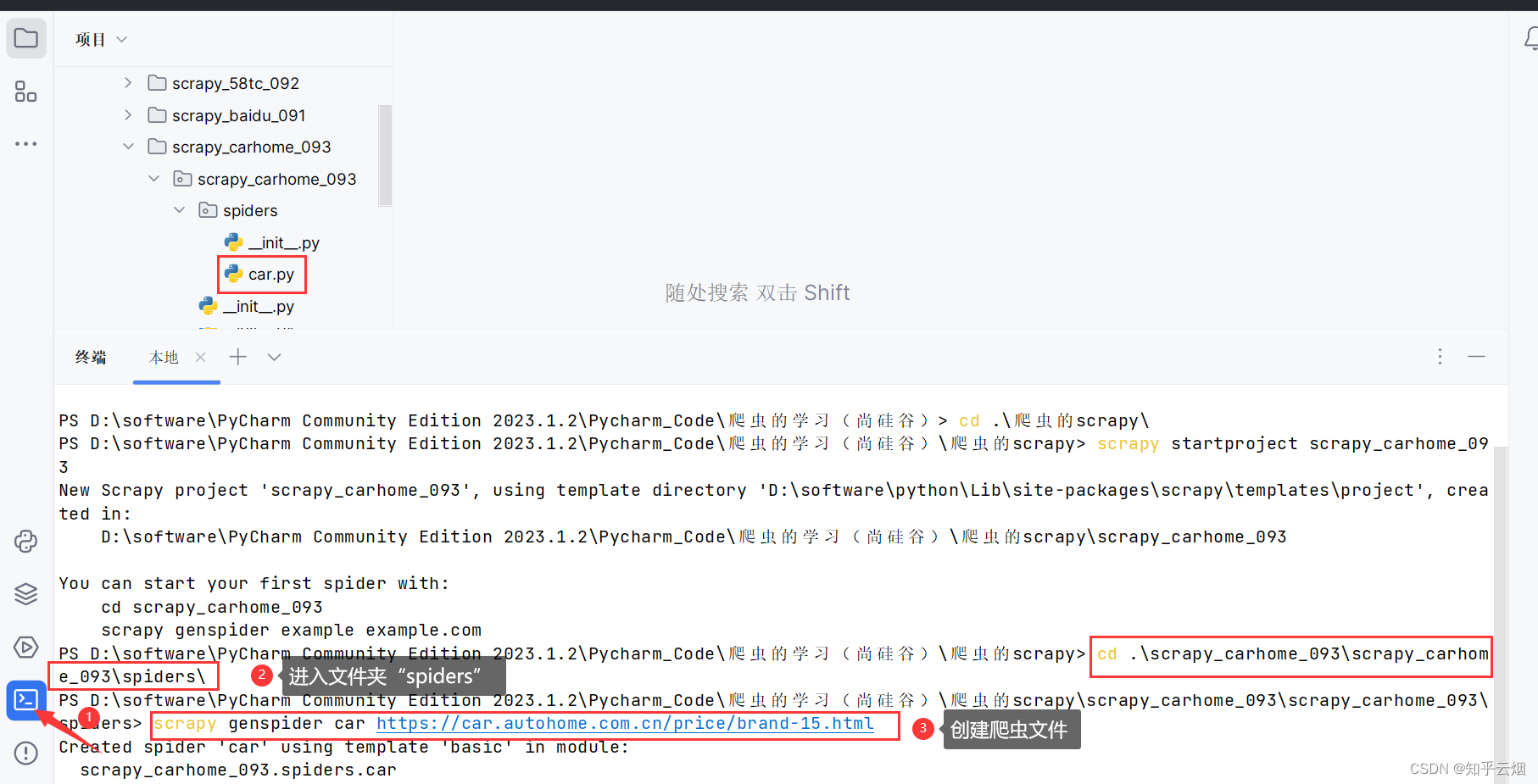
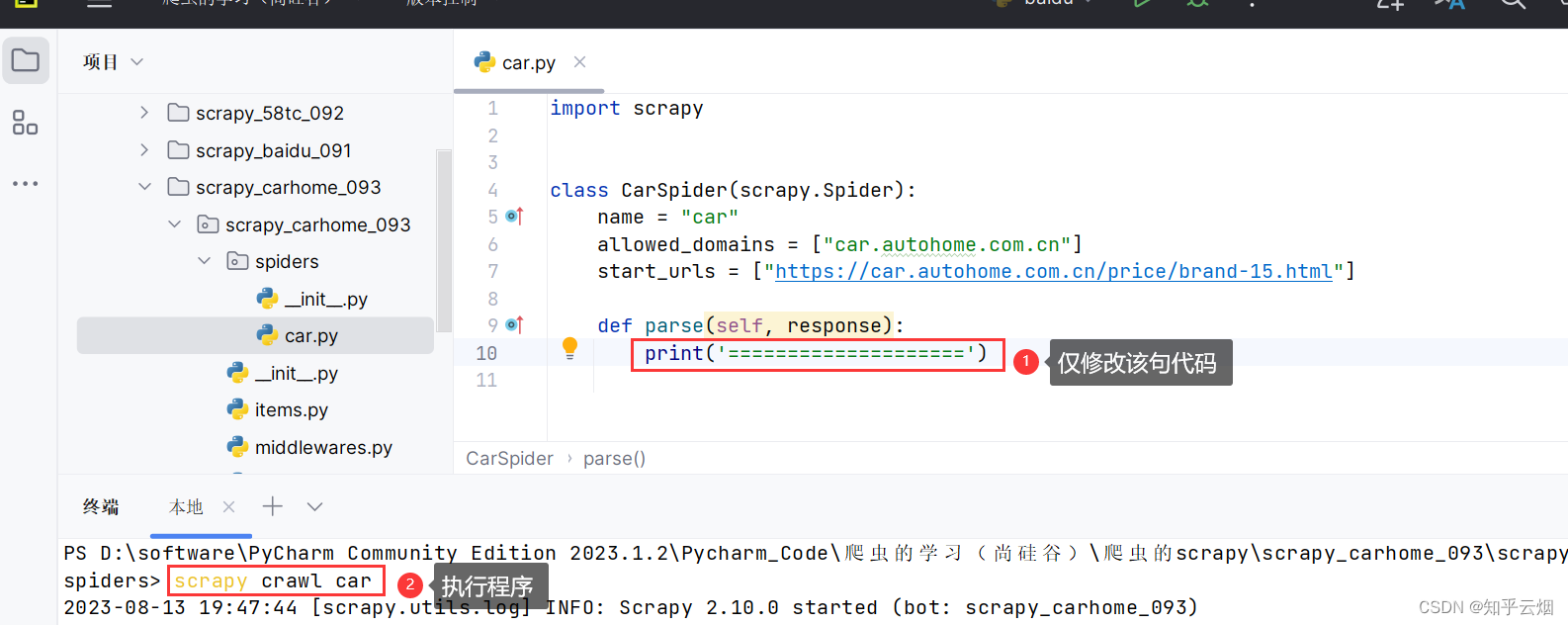
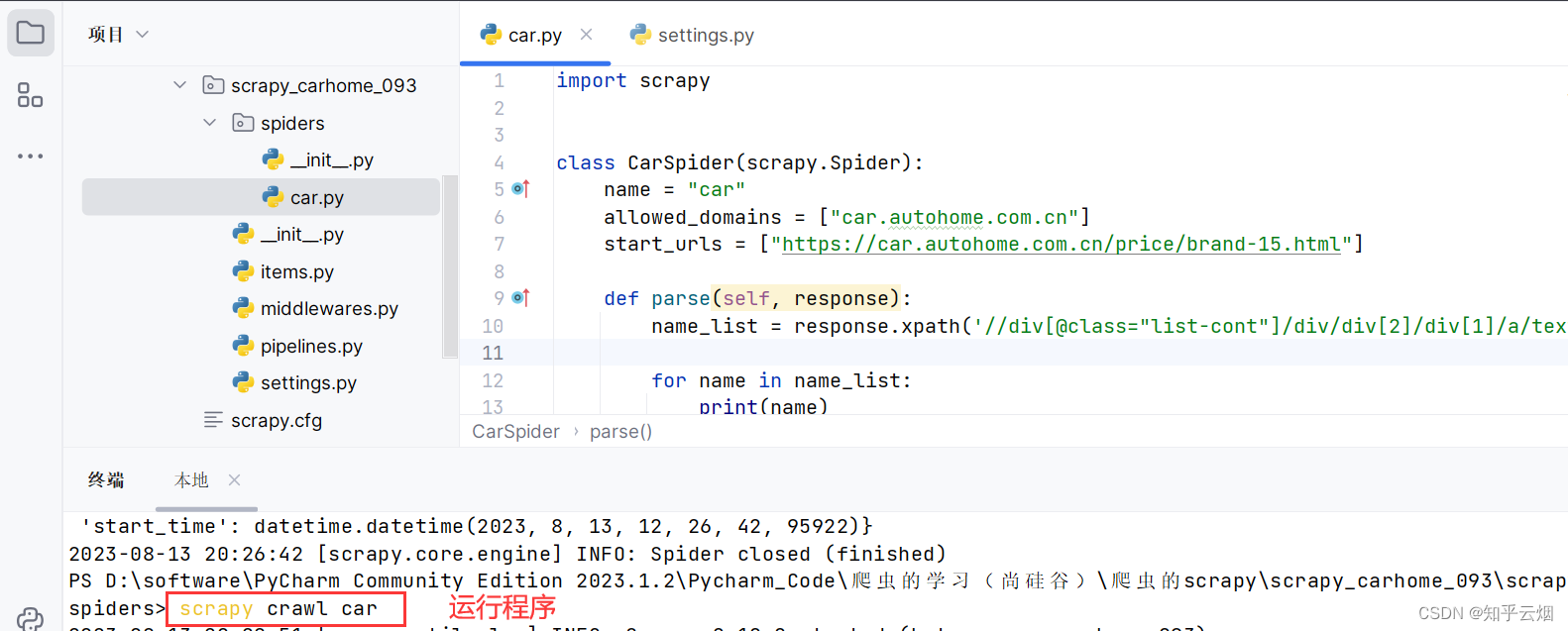
如下图所示,仅修改一句代码,验证在该网站上能否执行程序。

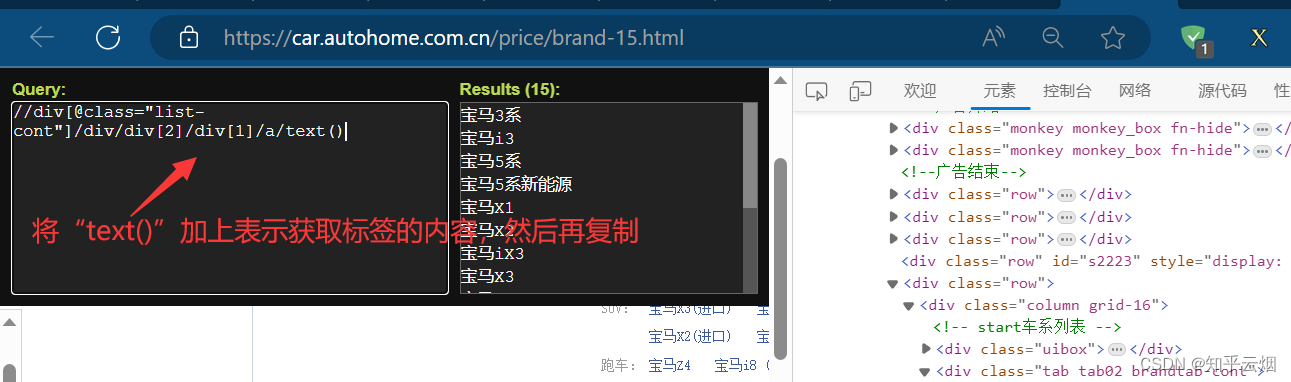
如下图所示,找到各个图片的名字的xpath路径,然后再复制(记得加上“/text()”)。
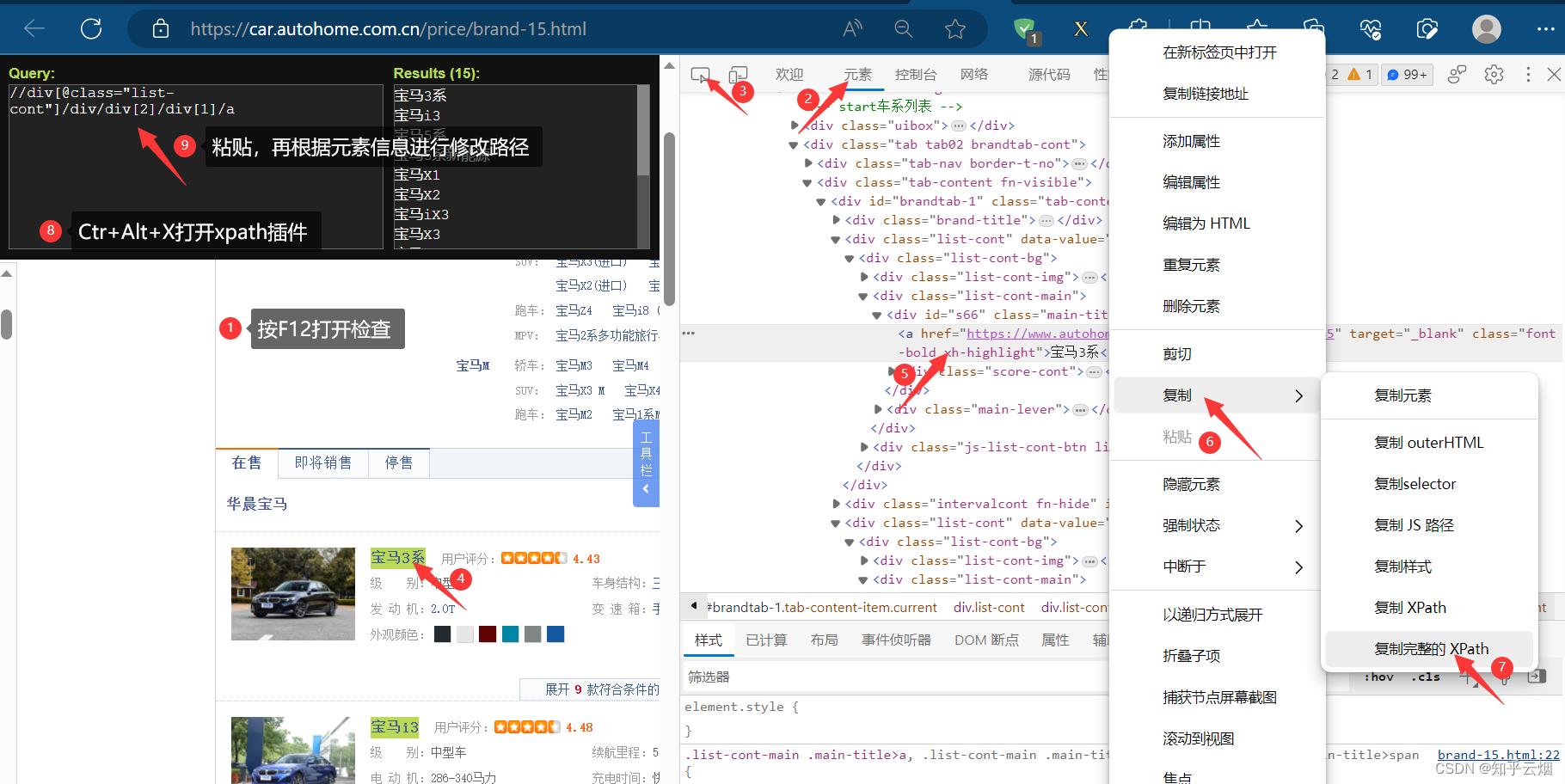
然后编写代码,验证获取的数据是否包含车名。然后思考怎么获取车名的数据。
import scrapy
class CarSpider(scrapy.Spider):
name = "car"
allowed_domains = ["car.autohome.com.cn"]
start_urls = ["https://car.autohome.com.cn/price/brand-15.html"]
def parse(self, response):
name_list = response.xpath('//div[@class="list-cont"]/div/div[2]/div[1]/a/text()')
for name in name_list:
print(name)
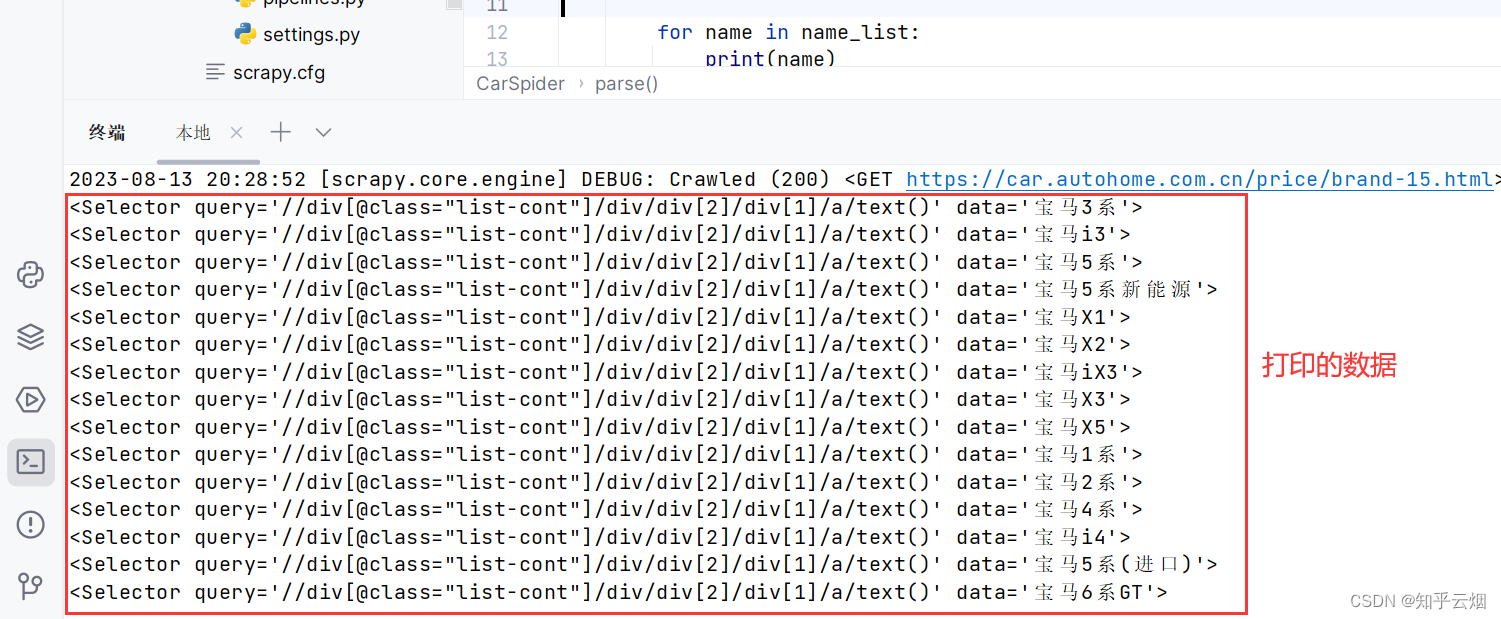
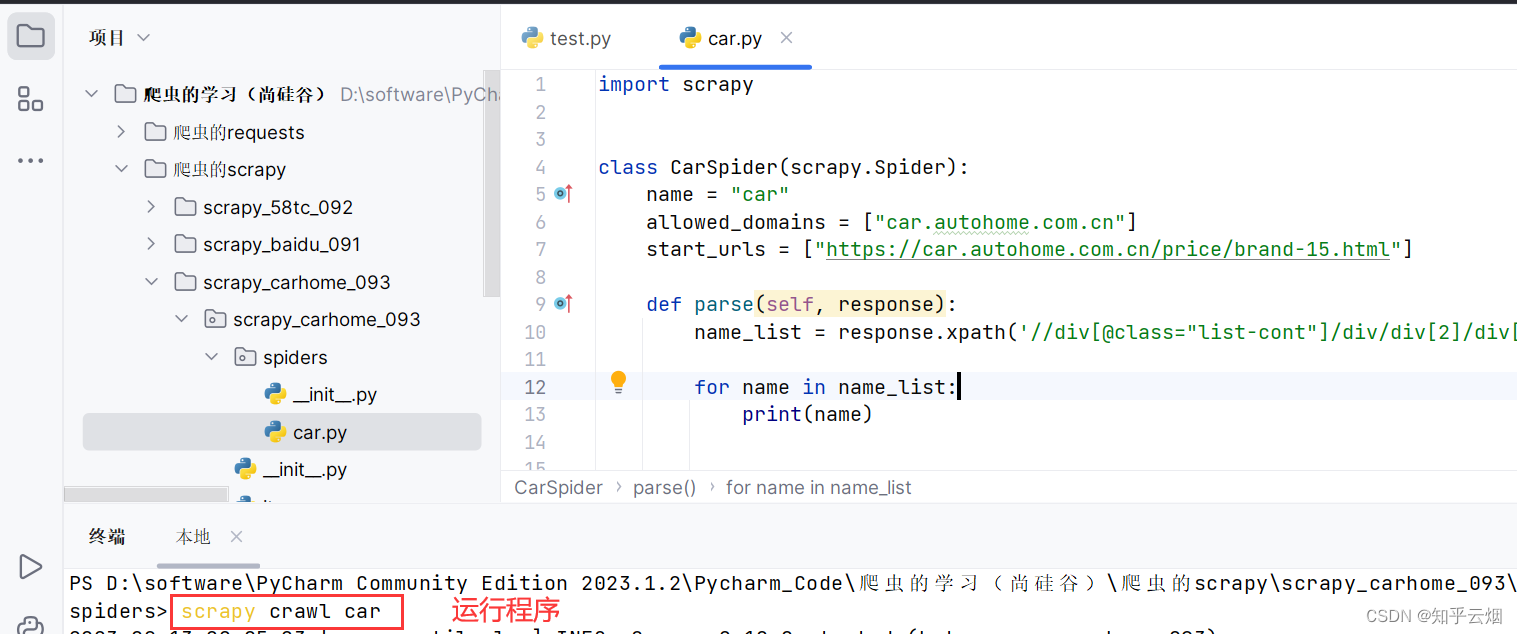
此时我们想到获取标签的属性值需使用extract,故继续编写代码,获取车名。
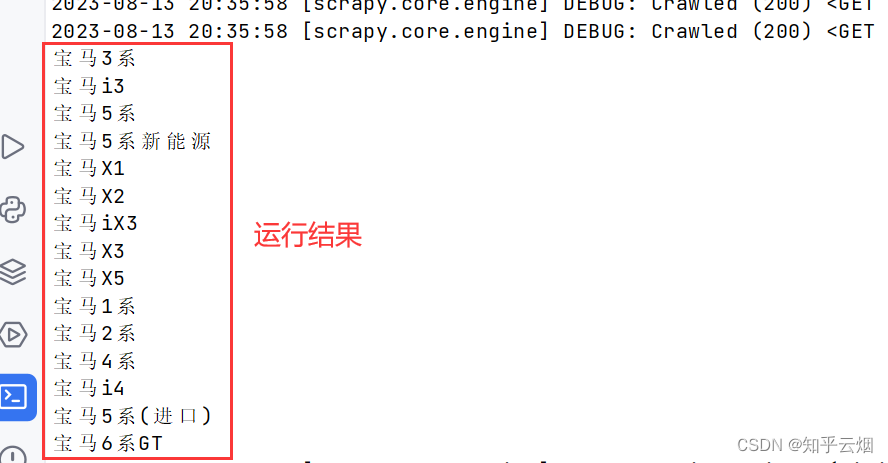
如果我们对车的价格比较感兴趣,可与获取车名的方法一样,找到它们的xpath路径,然后继续编程,获取到对应的数据。
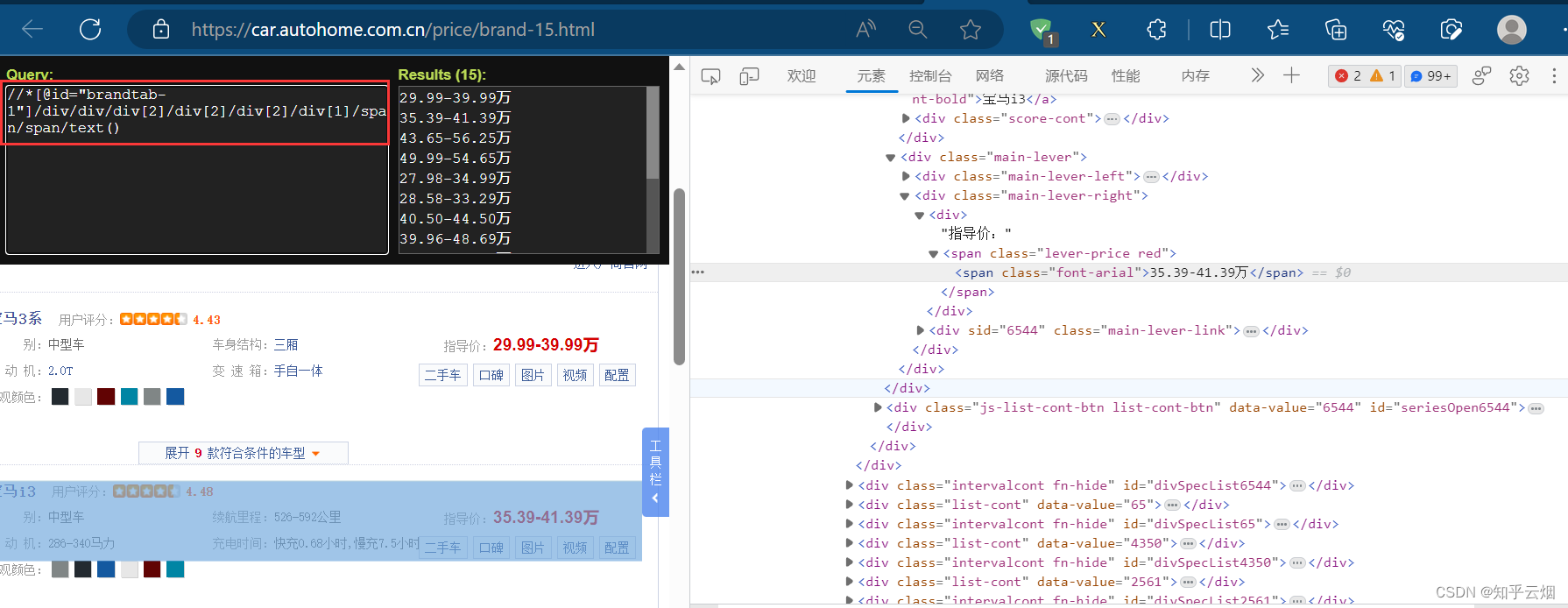
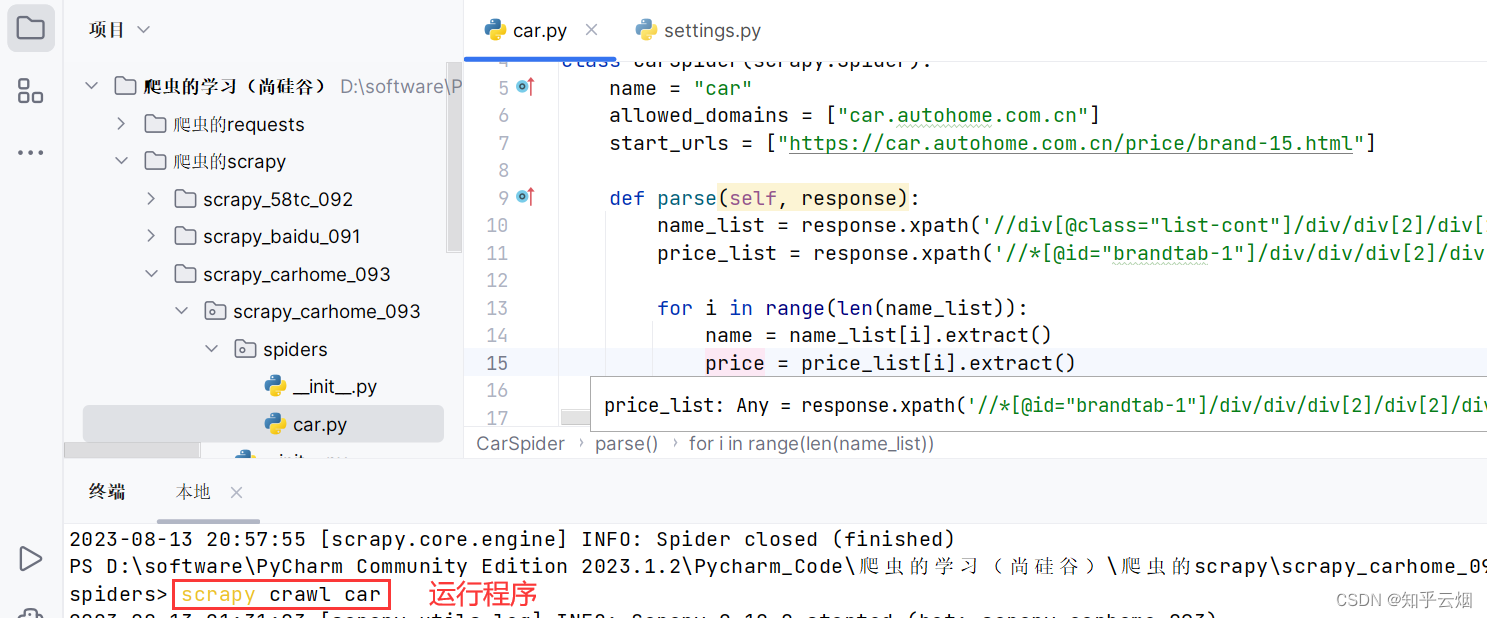
import scrapy
class CarSpider(scrapy.Spider):
name = "car"
allowed_domains = ["car.autohome.com.cn"]
start_urls = ["https://car.autohome.com.cn/price/brand-15.html"]
def parse(self, response):
name_list = response.xpath('//div[@class="list-cont"]/div/div[2]/div[1]/a/text()')
price_list = response.xpath('//*[@id="brandtab-1"]/div/div/div[2]/div[2]/div[2]/div[1]/span/span/text()')
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
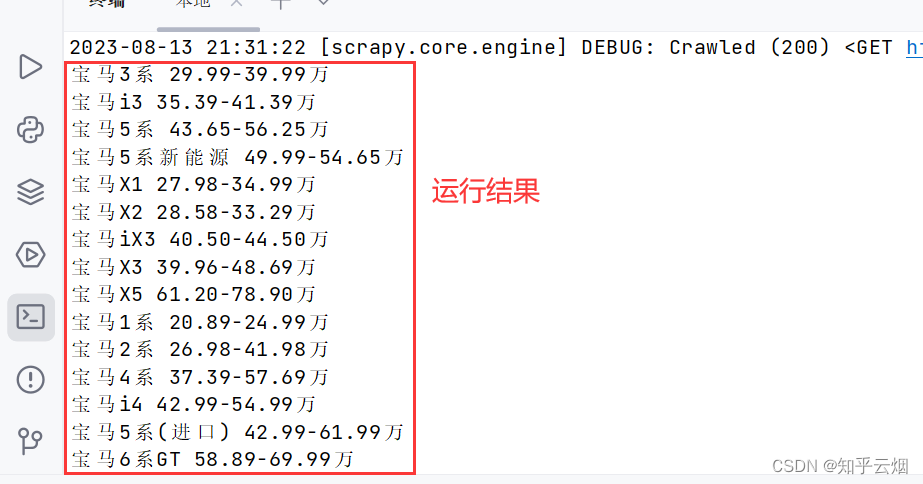
print(name, price)
5.调试工具scrapy shell
(1)什么是scrapy shell

(2)安装ipython

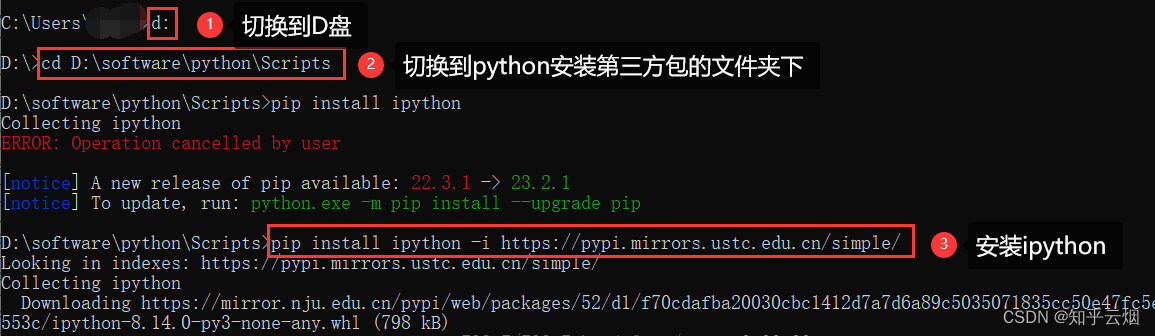
具体安装步骤如下:使用快捷键Win+R打开运行窗口,输入cmd并按Enter键打开命令提示符窗口。
在命令提示符窗口中将目录切换到scripts文件夹中,再使用命令“pip install ipython -i https://pypi.mirrors.ustc.edu.cn/simple/”安装。
(3)ipython的使用方法
# 进入到scrapy shell的终端 直接在windows的终端中输入scrapy shell 域名
# 如果想看到一些高亮 或者 自动补全 那么可以安装ipython 安装命令:pip install ipython
# scrapy shellI www.baidu.com
如下图所示,在终端中使用scrapy shell进入百度,然后就会返回一堆对象。

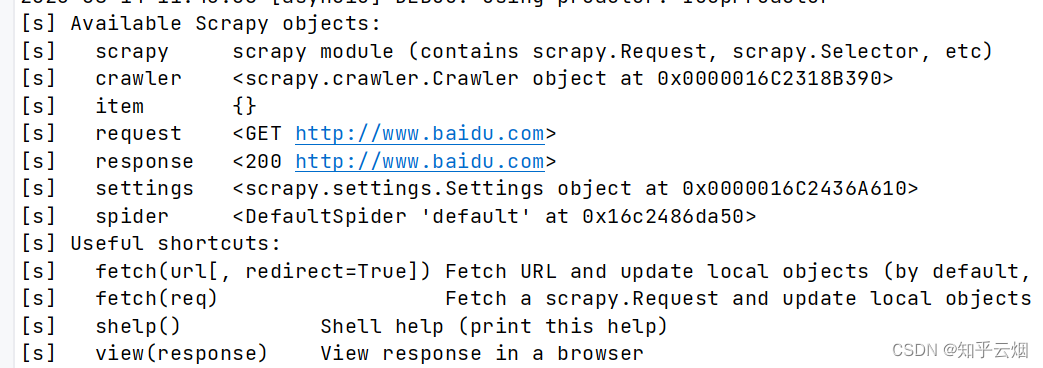
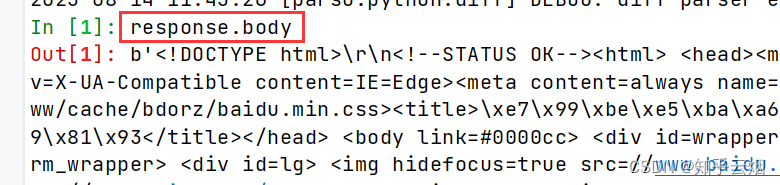
之后就可以按照scrapy的语法正常使用了,可见scrapy shell对于调试、获取复杂网页的数据来说,十分便利。
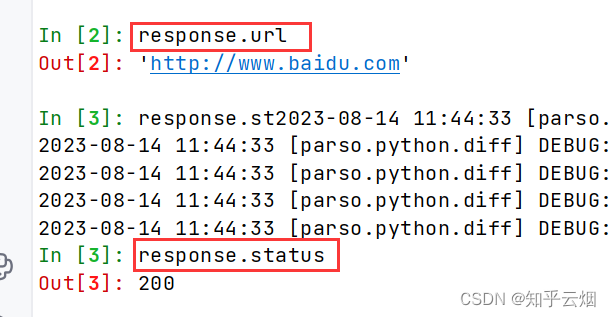
6. scrapy之当当网爬取数据(本节获取数据失败,已在第9节成功解决,不想再改动本节内容了)
(1)yied

(2)本节的演示
本次将演示如何下载当当网中的10页数据。(原视频讲解了如何爬取某个分类的所以有数据,我们就是学习使用而已,爬两页就够了,别人维护网站也不容易。再次强调,爬取数据仅供学习使用,千万别商用。)
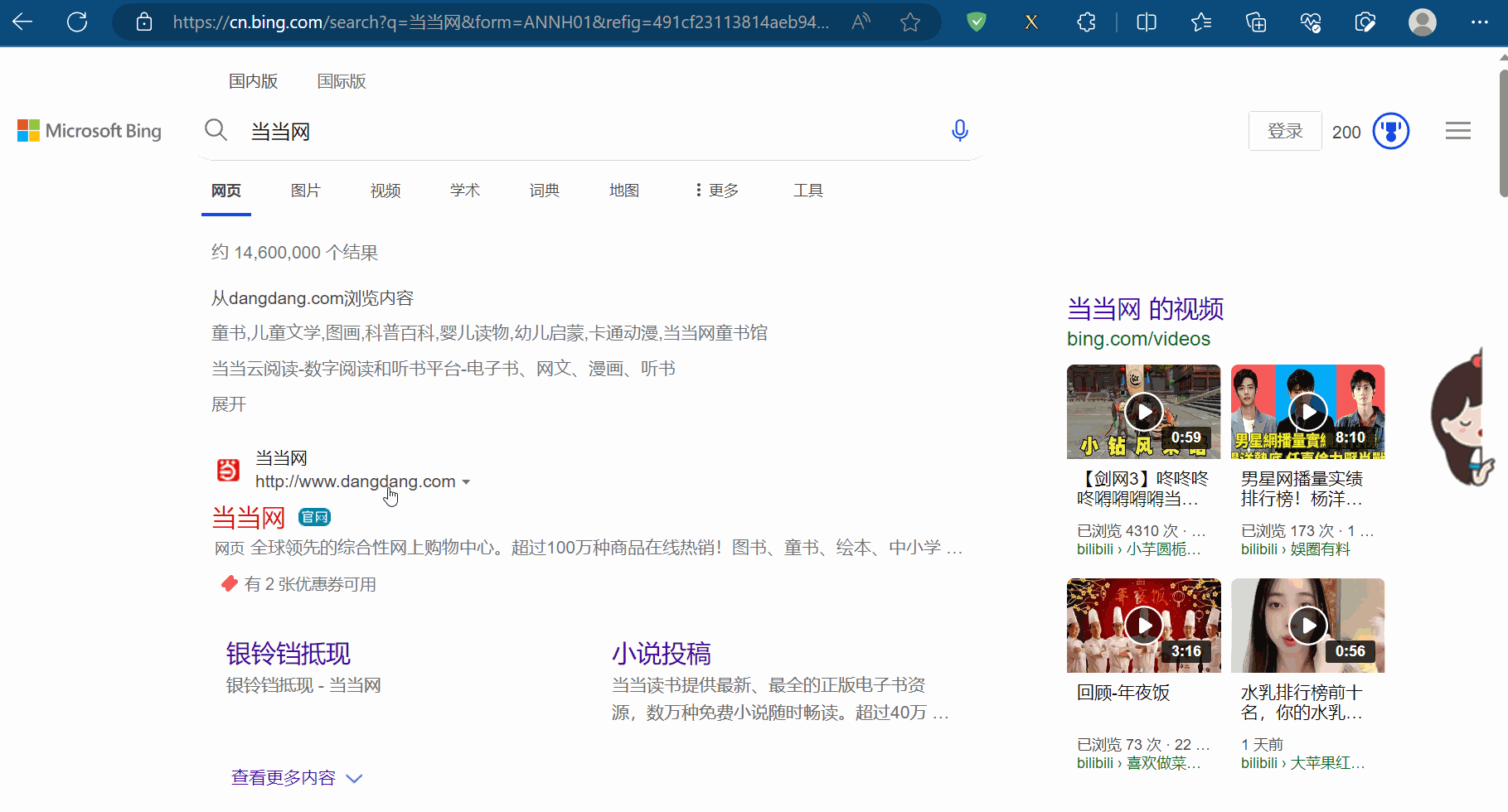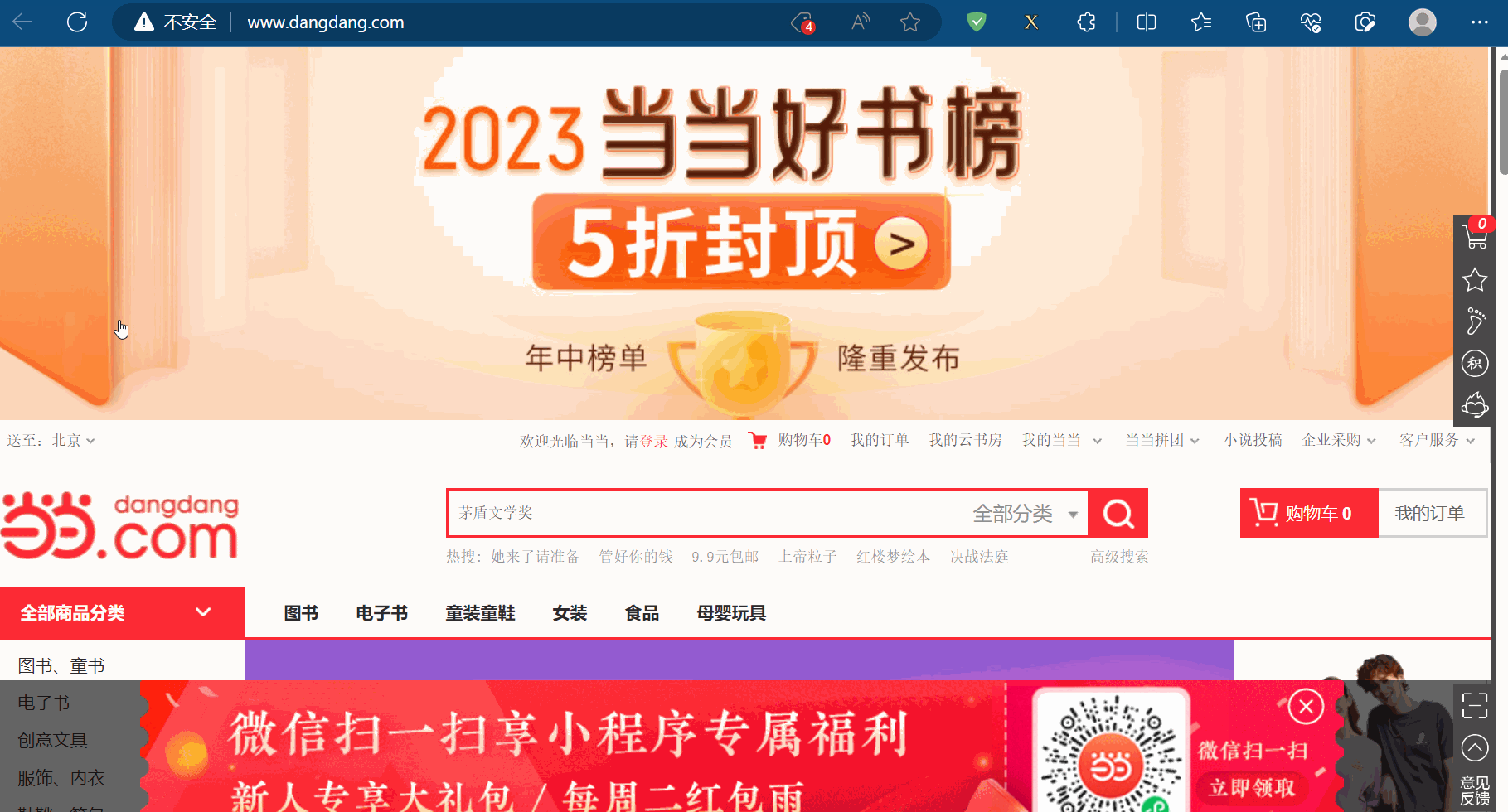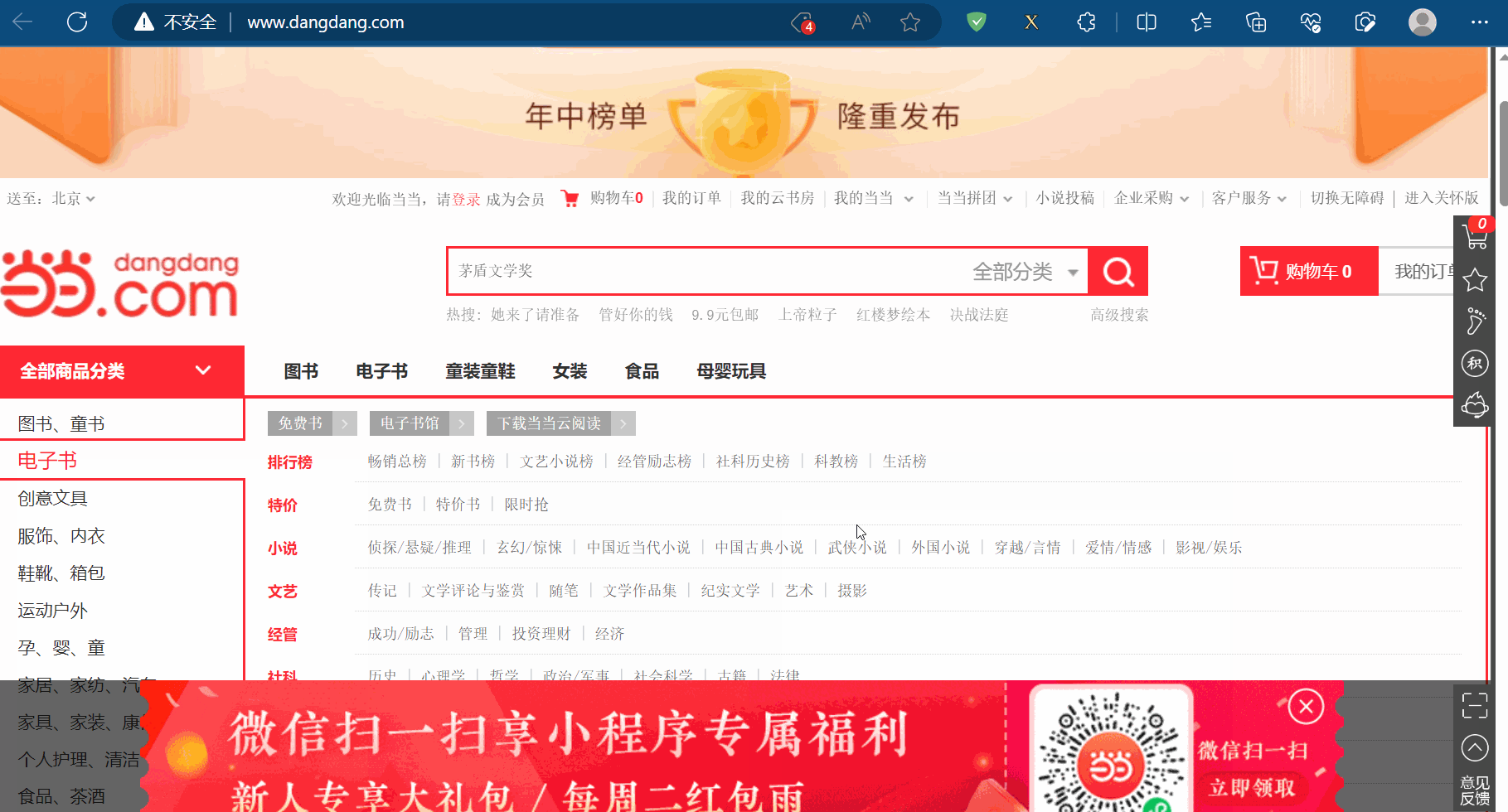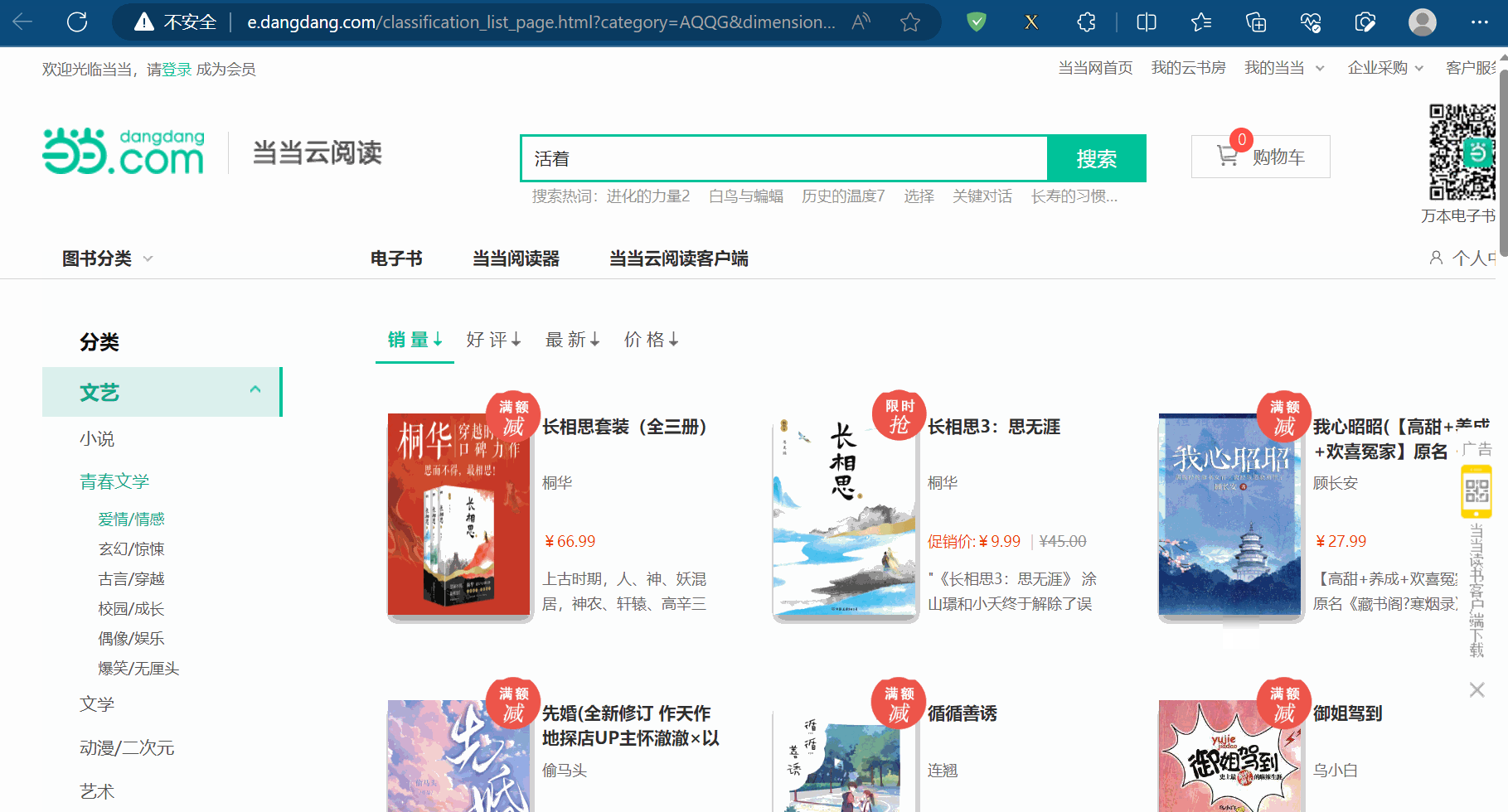
如下图,进入到当当网(“http://www.dangdang.com/”)的“爱情/情感”的电子书的网页中。

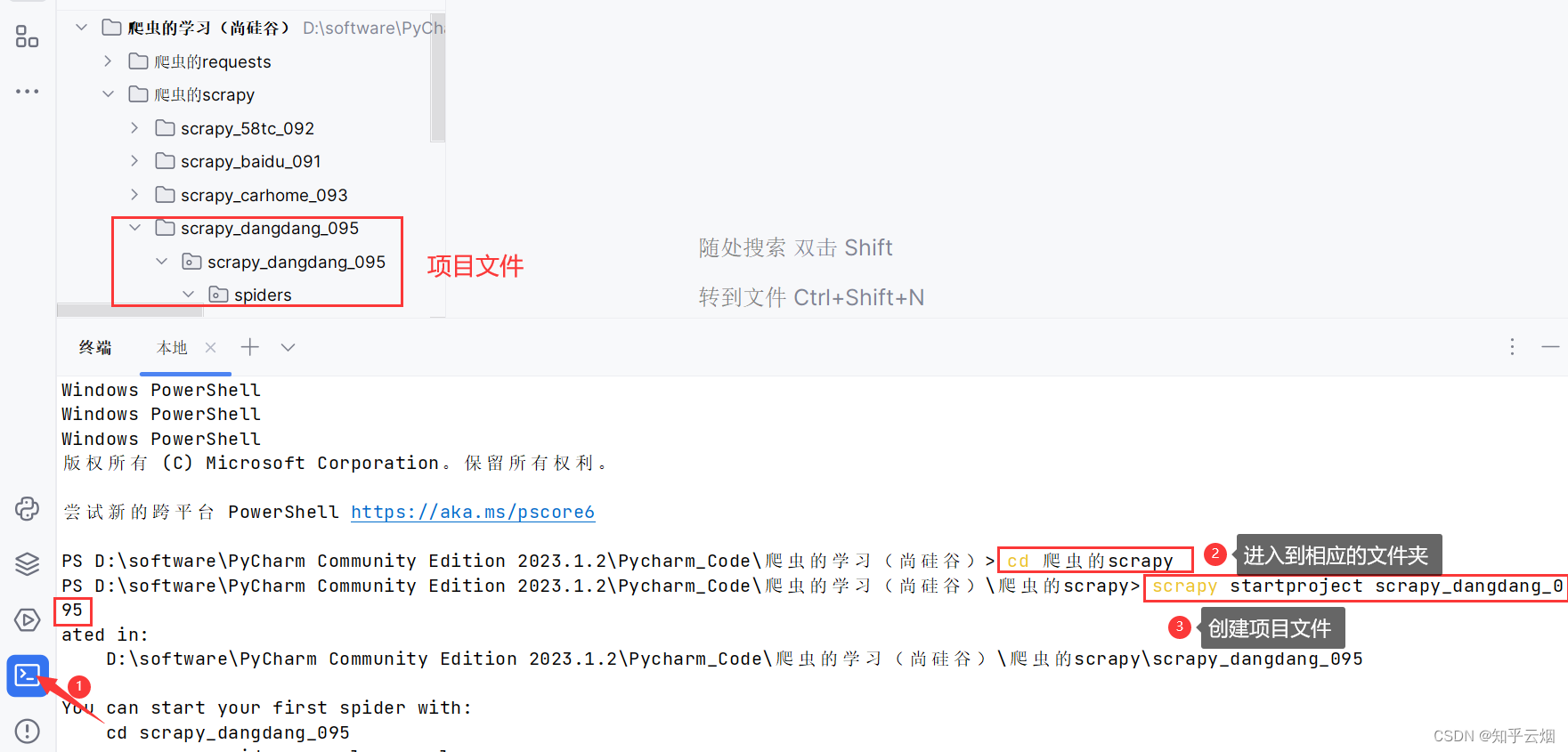
如下图,使用命令“scrapy startproject scrapy_dangdang_095”创建项目文件。
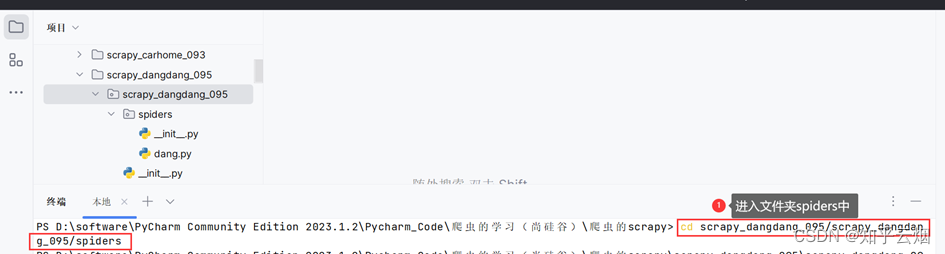
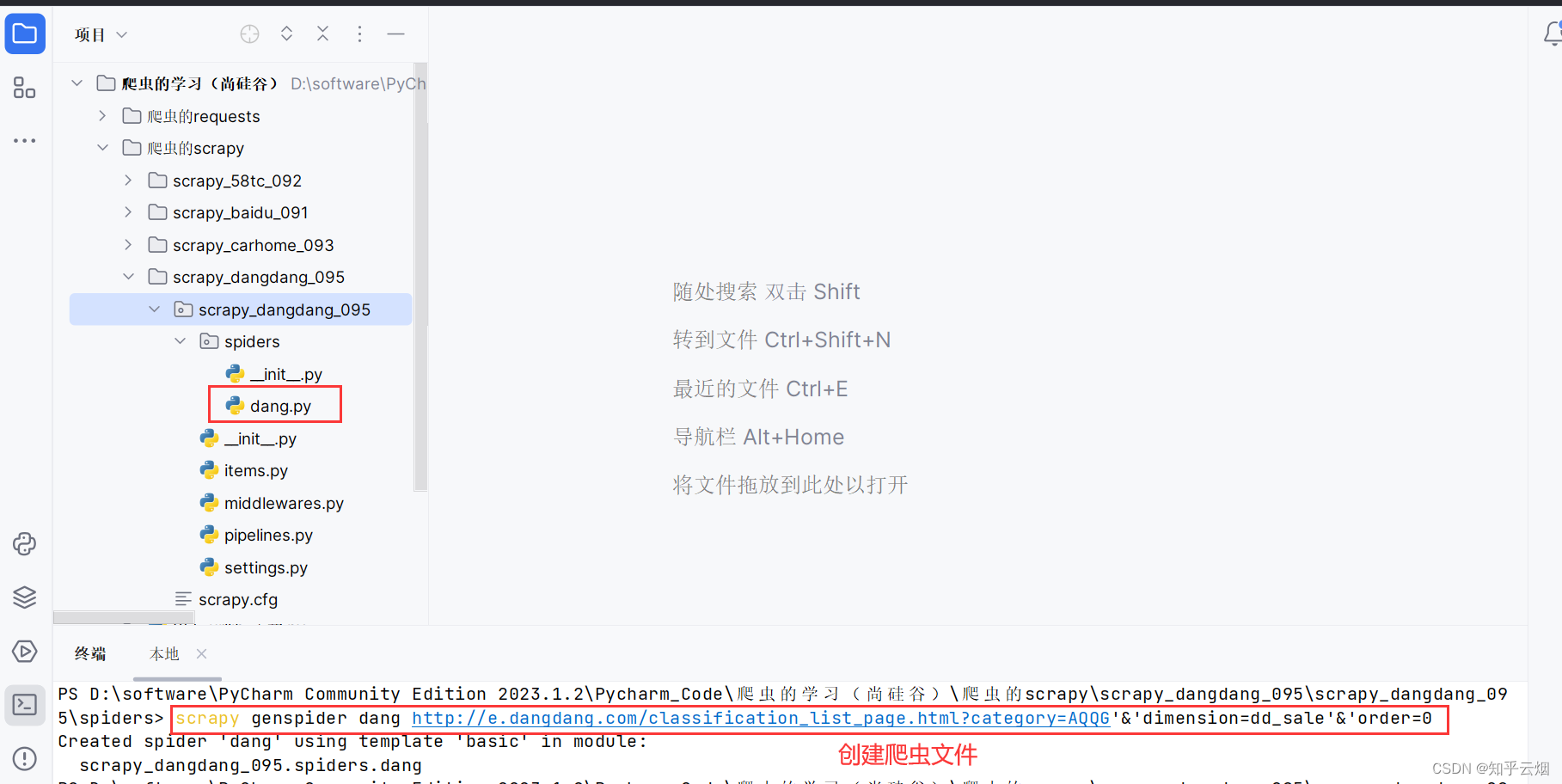
再使用指令“cd scrapy_dangdang_095/scrapy_dangdang_095/spiders”进入文件夹“spiders”中,使用指令“scrapy genspider dang 域名”创建爬虫文件“dang.py”(其中域名为刚刚复制的网址,另外,网址中含有&,需要变成‘&’或”&”)。
然后尝试打印一行数据,判断是否含有反爬手段。结果发现没有。
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyDangdang095Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 数据结构,通俗地说就是你要下载的数据都有什么
# 图片
src = scrapy.Field()
# 名字
name = scrapy.Field()
# 价格
price = scrapy.Field()

然后去文件“items.py”中定义本次演示的数据结构。数据结构,通俗地说就是你要下载的数据都有什么。
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyDangdang095Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 数据结构,通俗地说就是你要下载的数据都有什么
# 图片
src = scrapy.Field()
# 名字
name = scrapy.Field()
# 价格
price = scrapy.Field()
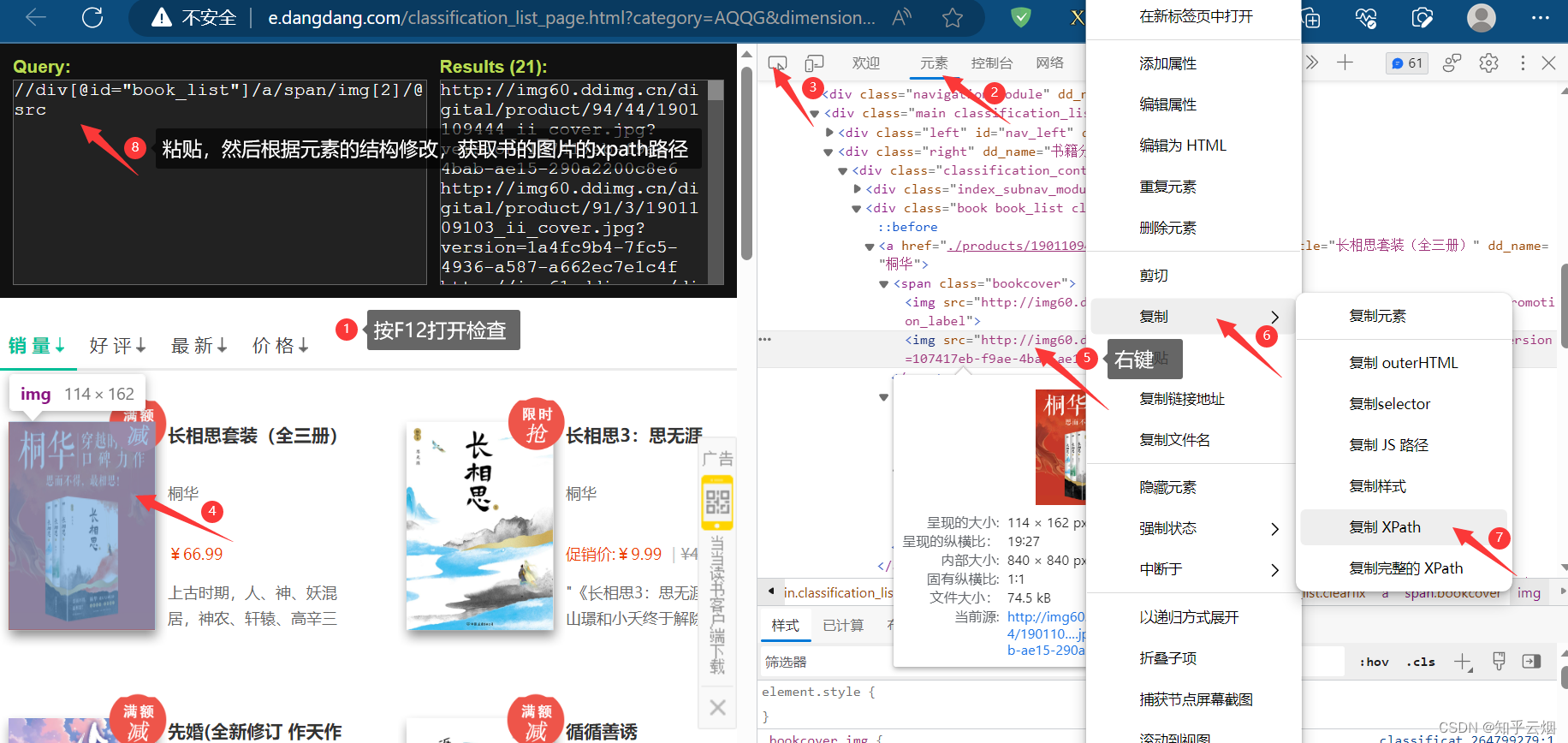
如下图,寻找到图片、书名、价格的xpath路径,然后复制到PyCharm中。
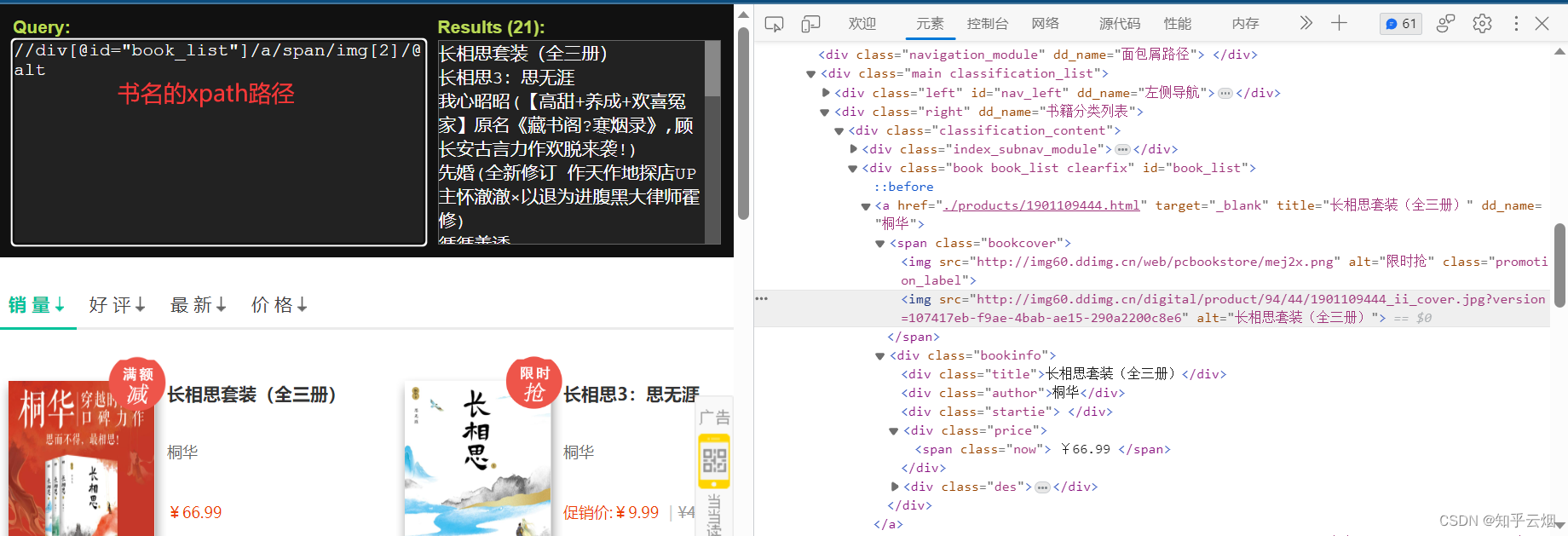
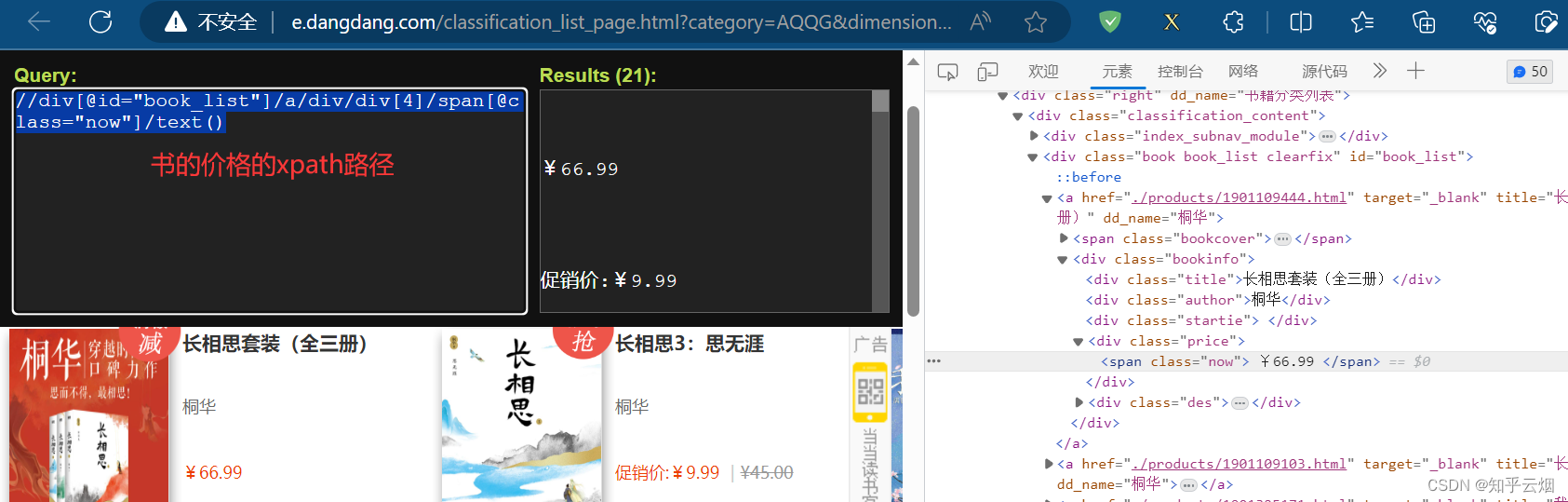
观察这几个数据的xpath路径,发现都在一个a标签下。于是继续编写程序。
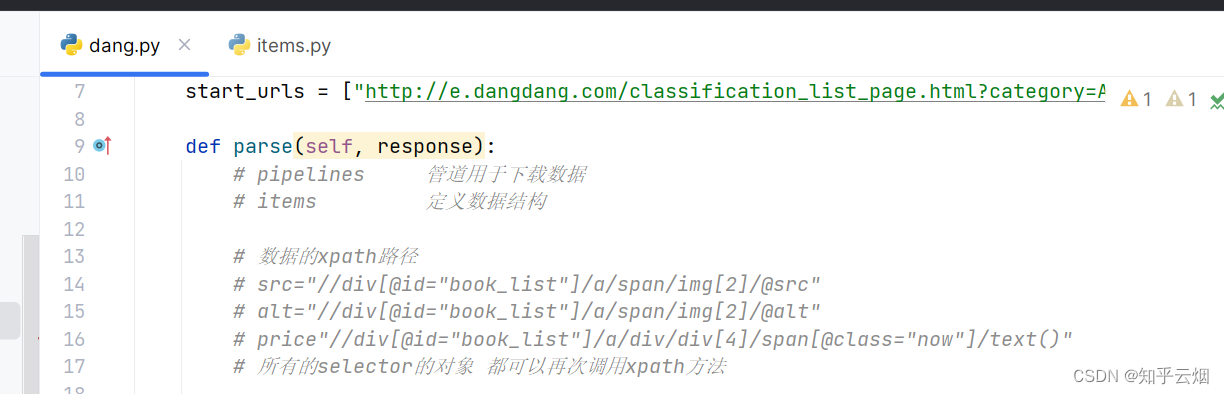
编写程序并执行,猜测当当网可能加入了君子协议(robots协议),得去注释君子协议后在来运行,还是没有返回数据。
import scrapy
class DangSpider(scrapy.Spider):
name = "dang"
allowed_domains = ["e.dangdang.com"]
start_urls = ["http://e.dangdang.com/classification_list_page.html?category=AQQG&dimension=dd_sale&order=0"]
def parse(self, response):
# pipelines 管道用于下载数据
# items 定义数据结构
# 数据的xpath路径
# src="//div[@id="book_list"]/a/span/img[2]/@src"
# alt="//div[@id="book_list"]/a/span/img[2]/@alt"
# price"//div[@id="book_list"]/a/div/div[4]/span[@class="now"]/text()"
# 所有的selector的对象 都可以再次调用xpath方法
a_list = response.xpath('//div[@id="book_list"]/a')
print(a_list)
for a in a_list:
src = a.xpath('.//span/img[2]/@src').extract_first() # 注意“.”表示当前路径下的意思,"./"不能省
name = a.xpath('.//span/img[2]/@alt').extract()
price = a.xpath('.//div/div[4]/span[@class="now"]/text()').extract().strip()
print(src, name, price)




暂时不会了,于是听完视频后发现代码不用变(本次没有发现懒加载导致数据的xpath路径不一样的问题)。注意,在第九节中该问题已经被解决。
7.scrapy_当当网管道封装(本节获取数据失败,已在第9节成功解决,不想再改动本节内容了)
紧接着上一讲的继续。如下代码所示,将爬取的数据交给管道。
import scrapy
from ..items import ScrapyDangdang095Item
class DangSpider(scrapy.Spider):
name = "dang"
allowed_domains = ["e.dangdang.com"]
start_urls = ["http://e.dangdang.com/classification_list_page.html?category=AQQG&dimension=dd_sale&order=0"]
def parse(self, response):
# pipelines 管道用于下载数据
# items 定义数据结构
# 数据的xpath路径
# src="//div[@id="book_list"]/a/span/img[2]/@src"
# alt="//div[@id="book_list"]/a/span/img[2]/@alt"
# price"//div[@id="book_list"]/a/div/div[4]/span[@class="now"]/text()"
# 所有的selector的对象 都可以再次调用xpath方法
print('==========================================')
a_list = response.xpath('//div[@id="book_list"]/a')
print(a_list)
for a in a_list:
src = a.xpath('.//span/img[2]/@src').extract_first() # 注意“.”表示当前路径下的意思,"./"不能省
name = a.xpath('.//span/img[2]/@alt').extract()
price = a.xpath('.//div/div[4]/span[@class="now"]/text()').extract().strip()
# print(src, name, price) 测试代码,验证数据是否获取成功
book = ScrapyDangdang095Item(src=src, name=name, price=price)
# 需要将book(即ScrapyDangdang095Item对象)交给pipeline下载
yield book # 获取一个book就将book交给管道pipeline
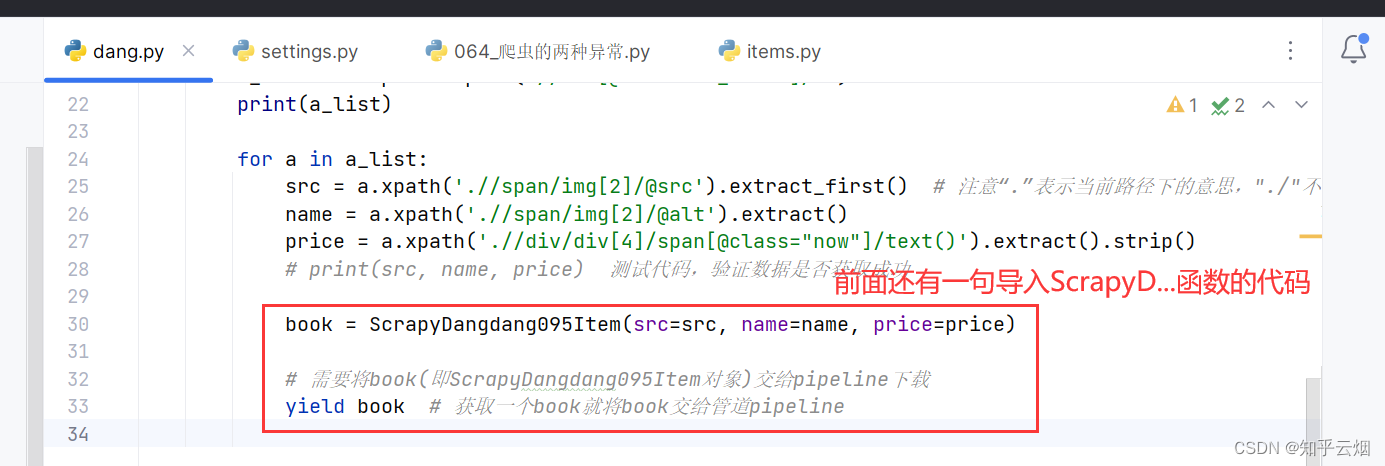
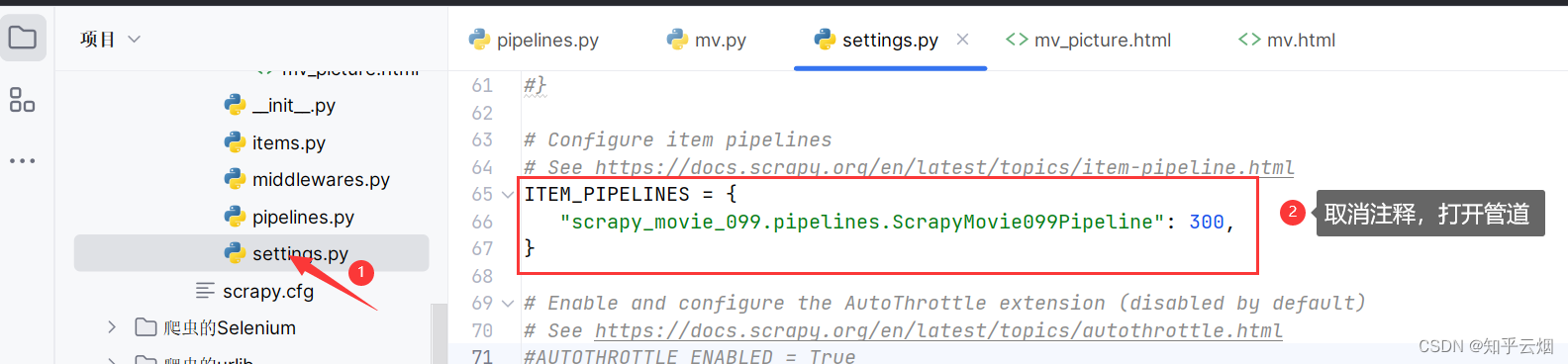
如下图,去文件“settings.py”中开启管道。(注:管道可以有很多个,那么管道是有优先级的。优先级的范围是1-1000,值越小,优先级越高。)
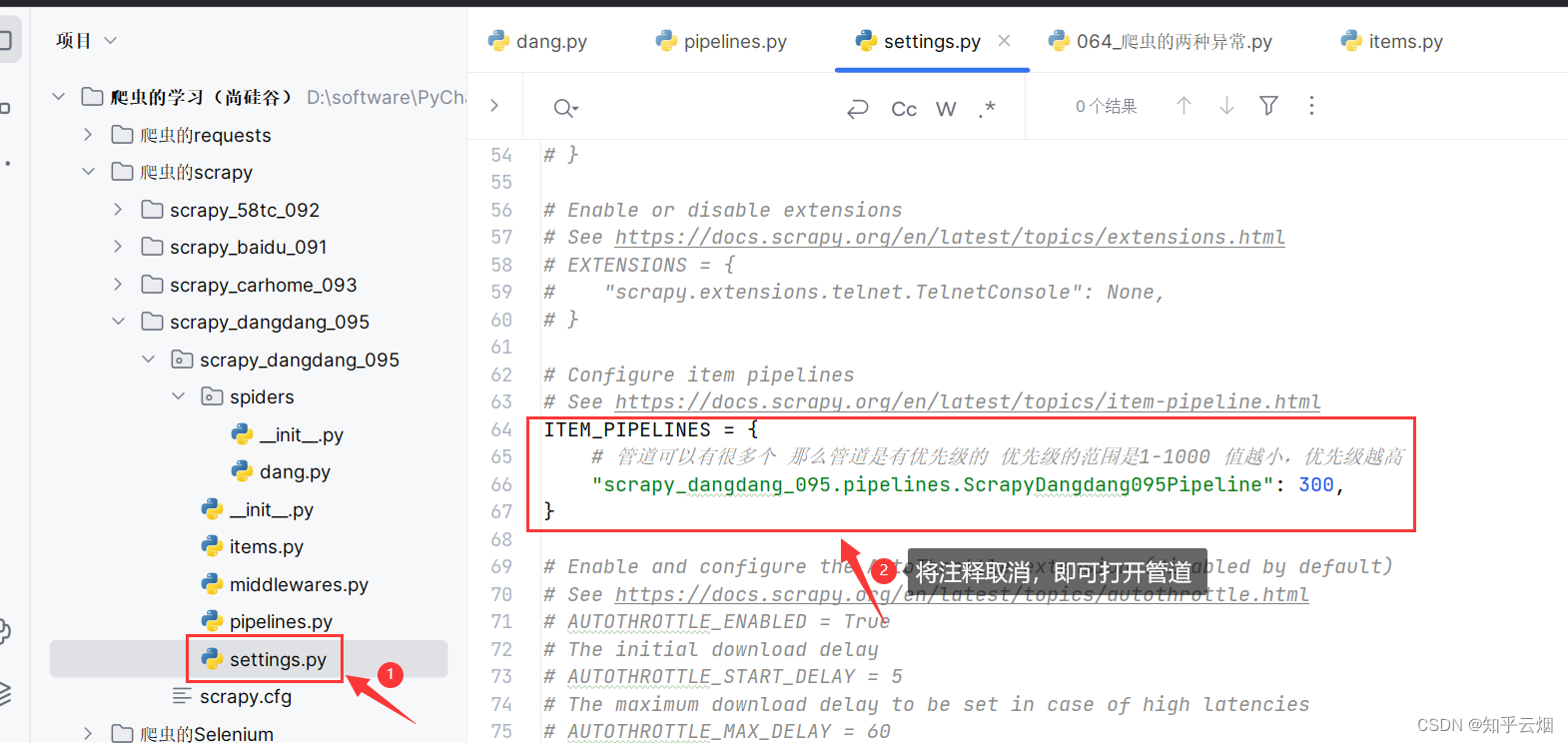
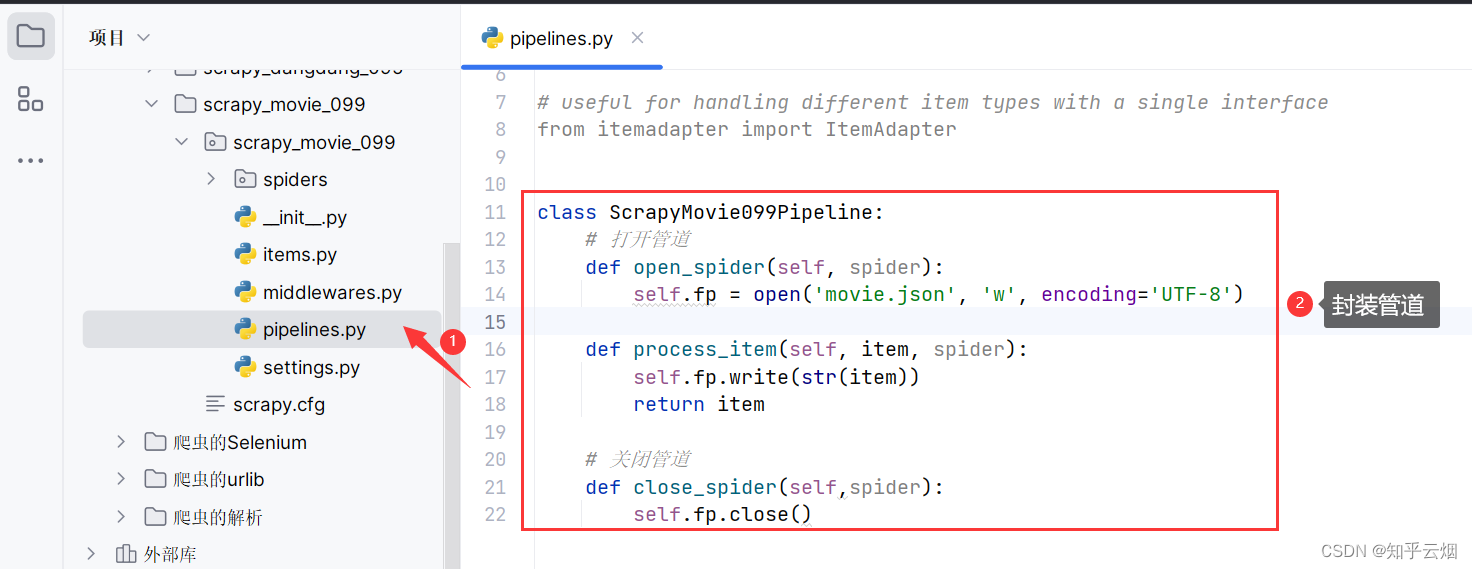
然后去管道文件“pipelines.py”中封装管道。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 如果想使用管道的话 那么必须在settings中开启管道
class ScrapyDangdang095Pipeline:
# 在爬虫文件开始之前 执行的方法
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='UTF-8')
# item就是yield后面的book对象
def process_item(self, item, spider):
# 以下这种模式不推荐 因为每传递过来一个对象就打开一次文件 对文件的操作过于频繁
# 因此定义了方法open_spider()、close_spider()
# with open('book.json', 'a', encoding="UTF-8") as fp:
# # 存在两个坑
# # (1)write方法里的内容必须是字符串
# # (2)w模式下,每个对象都会打开一次文件 会覆盖之前的内容
# # 故改成 a追加模式
# fp.write(item)
self.fp.write(str(item))
return item
# 在爬虫文件执行完成之后 执行的方法
def close_spider(self, spider):
self.fp.close()
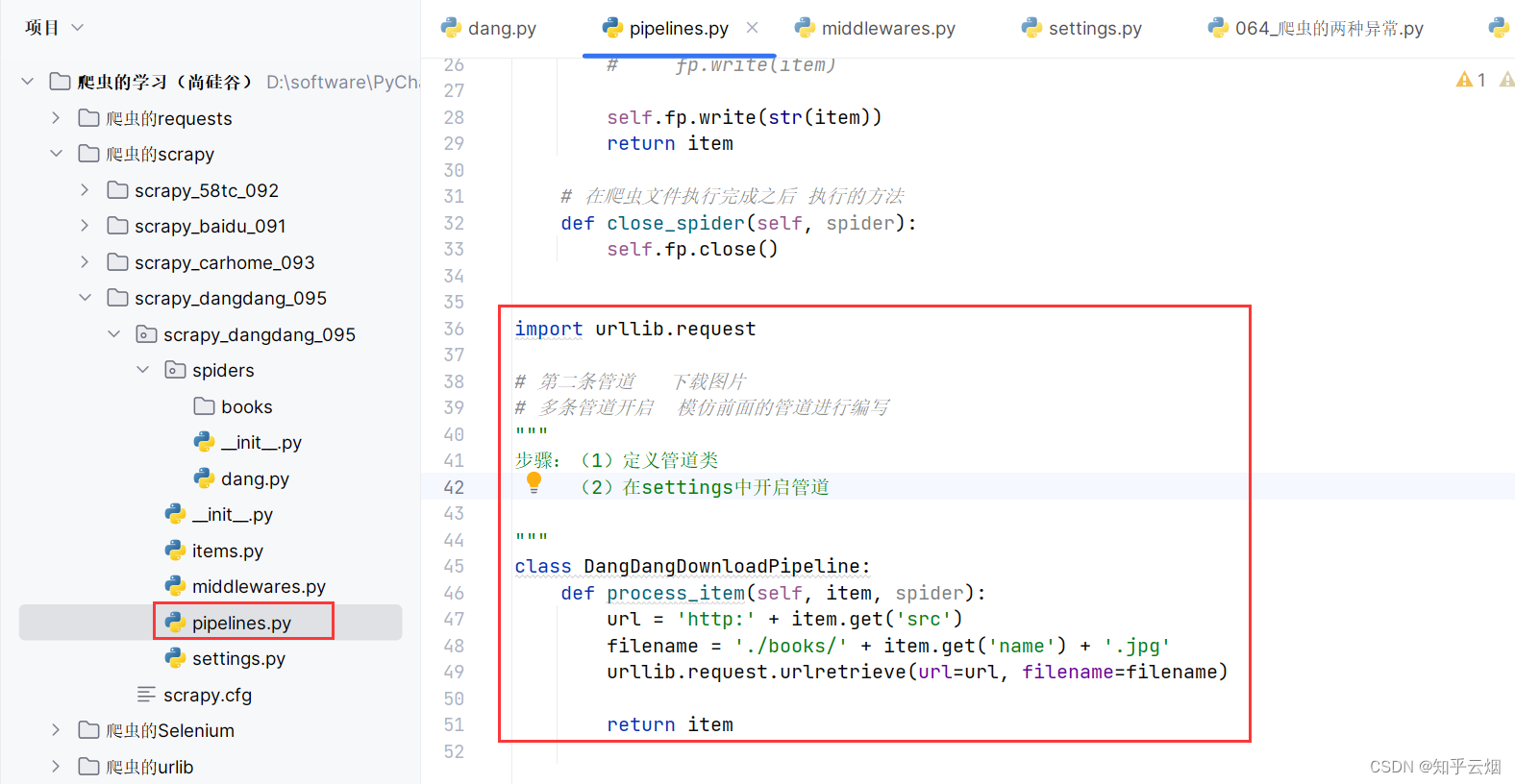
8.scrapy_当当网开启多条管道下载(本节获取数据失败,已在第9节成功解决,不想再改动本节内容了)
紧接着上一节,本节将演示当当网开启多条管道下载,具体为设两条管道,一边下载json数据,一边下载图片。
创建名为“books”的文件夹用来存储图片。
去管道文件“pipelines.py”中定义新的管道类。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 如果想使用管道的话 那么必须在settings中开启管道
class ScrapyDangdang095Pipeline:
# 在爬虫文件开始之前 执行的方法
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='UTF-8')
# item就是yield后面的book对象
def process_item(self, item, spider):
# 以下这种模式不推荐 因为每传递过来一个对象就打开一次文件 对文件的操作过于频繁
# 因此定义了方法open_spider()、close_spider()
# with open('book.json', 'a', encoding="UTF-8") as fp:
# # 存在两个坑
# # (1)write方法里的内容必须是字符串
# # (2)w模式下,每个对象都会打开一次文件 会覆盖之前的内容
# # 故改成 a追加模式
# fp.write(item)
self.fp.write(str(item))
return item
# 在爬虫文件执行完成之后 执行的方法
def close_spider(self, spider):
self.fp.close()
import urllib.request
# 第二条管道 下载图片
# 多条管道开启 模仿前面的管道进行编写
"""
步骤:(1)定义管道类
(2)在settings中开启管道
"""
class DangDangDownloadPipeline:
def process_item(self, item, spider):
url = 'http:' + item.get('src')
filename = './books/' + item.get('name') + '.jpg'
urllib.request.urlretrieve(url=url, filename=filename)
return item
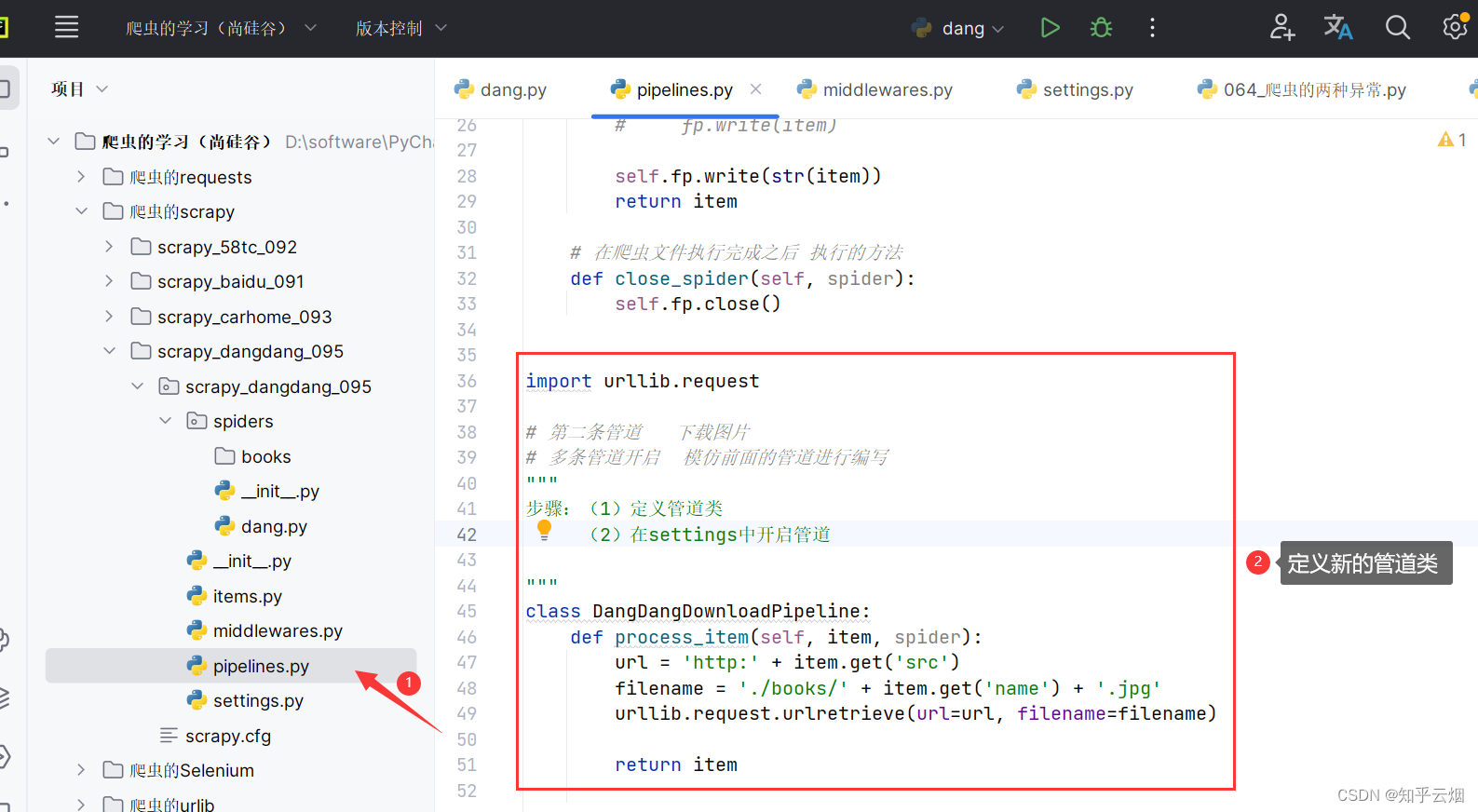
在文件“settings.py”中开启新管道。
ITEM_PIPELINES = {
# 管道可以有很多个 那么管道是有优先级的 优先级的范围是1-1000 值越小,优先级越高
"scrapy_dangdang_095.pipelines.ScrapyDangdang095Pipeline": 300,
# DangDangDownloadPipeline
"scrapy_dangdang_095.pipelines.DangDangDownloadPipeline": 301,
}
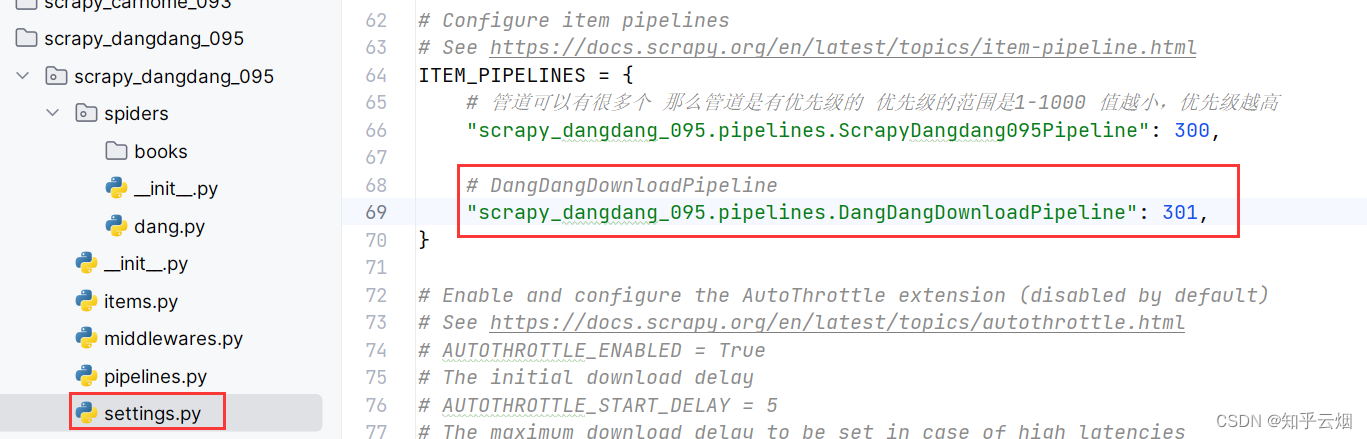
9.scrapy_当当网多页下载
紧接着上一节,本节将演示多页的下载。首先我们需要知道,每一页的爬取的业务逻辑全都是一样的,所以只需要将执行的那个页的请求再次调用parse方法就可以了。
去观察网络的接口,找到了存储数据的接口,并将接口的请求地址复制到PyCharm中,成功解决前面几节没有返回数据的问题。
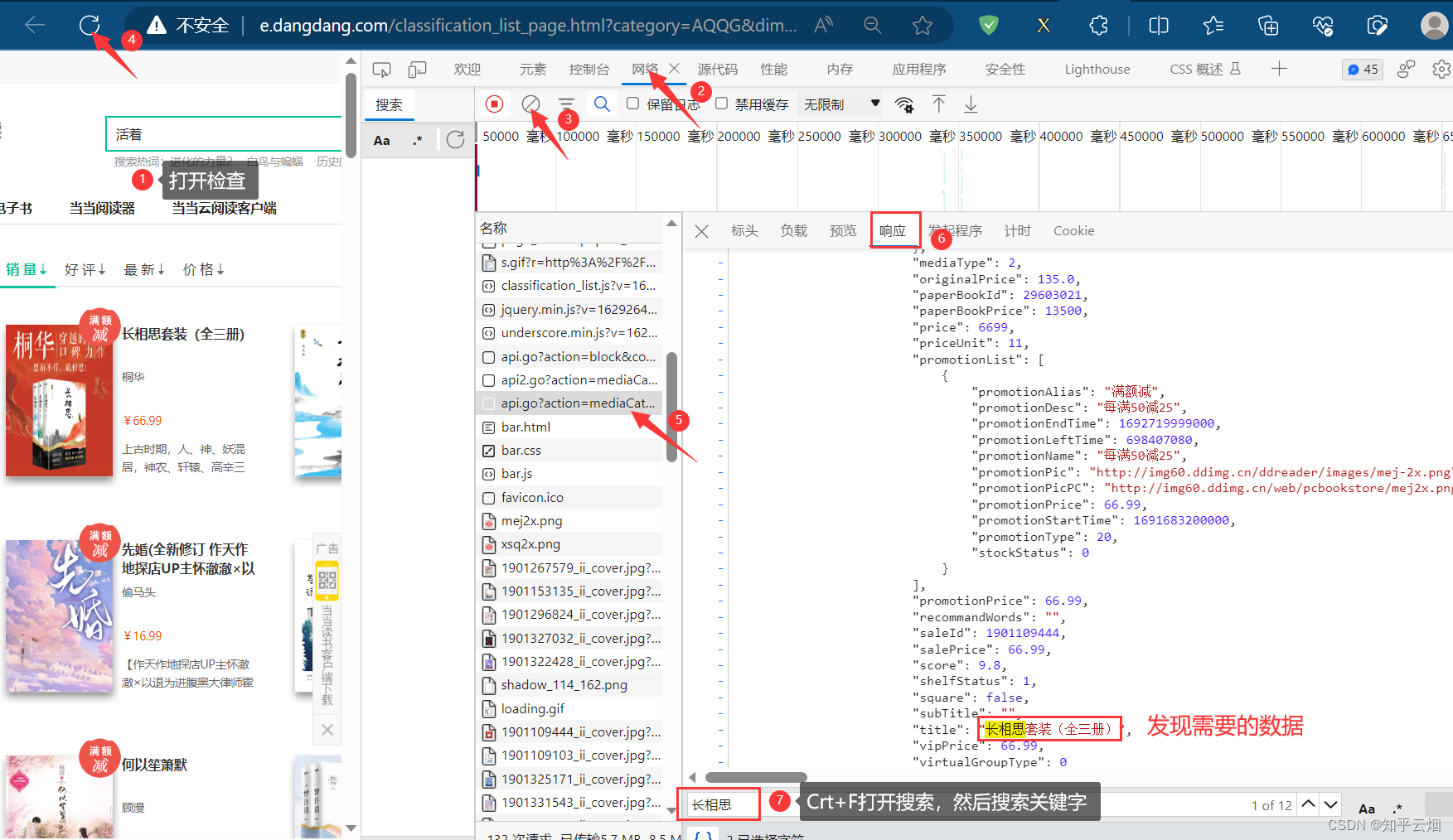
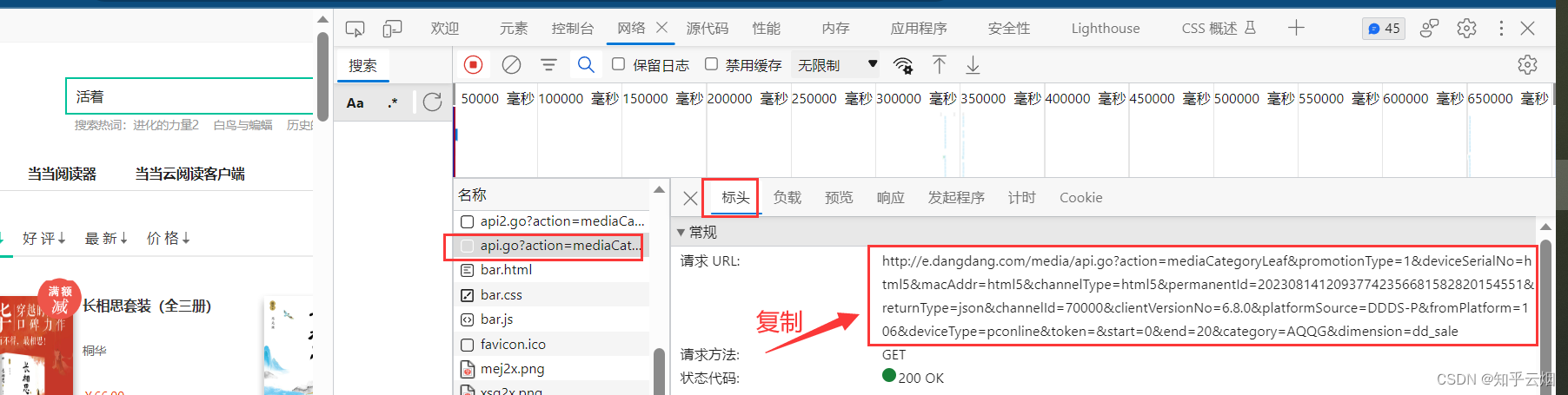
然后编写“dang.py”的代码。
import scrapy
from ..items import ScrapyDangdang095Item
import jsonpath
import json
class DangSpider(scrapy.Spider):
name = "dang"
allowed_domains = ["e.dangdang.com"]
start_urls = [
"http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerial-No=html5&macAddr=html5&channelType=html5&permanentId=20230814120937742356681582820154551&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=0&end=20&category=AQQG&dimension=dd_sale"]
def parse(self, response):
# pipelines 管道用于下载数据
# items 定义数据结构
print('==========================================')
# print(response.text) # 发现获取的是json数据
# with open('网页源码.json','w',encoding='UTF-8') as fp:
# fp.write(response.text)
# 观察数据后直接使用jsonpath进行解析
obj = json.loads(response.text)
# 图片地址的列表
src_list = jsonpath.jsonpath(obj, '$.data.saleList.*.mediaList[0].coverPic')
# 书名的列表
name_list = jsonpath.jsonpath(obj, '$.data.saleList.*.mediaList[0].title')
# 价格的列表
price_list = jsonpath.jsonpath(obj, '$.data.saleList.*.mediaList[0].salePrice')
# print(src_list)
# print(name_list)
# print(price_list)
for i in range(len(src_list)):
src = src_list[i]
# 替换特殊字符为下划线
name = name_list[i].strip().replace('/', '_')\
.replace('\\', '_').replace(':', '_').replace('【','(').replace('】',')')
price = str(price_list[i])+'元'
# print(src, name, price) # 测试代码,验证数据是否获取成功
book = ScrapyDangdang095Item(src=src, name=name, price=price)
# 需要将book(即ScrapyDangdang095Item对象)交给pipeline下载
yield book # 获取一个book就将book交给管道pipeline
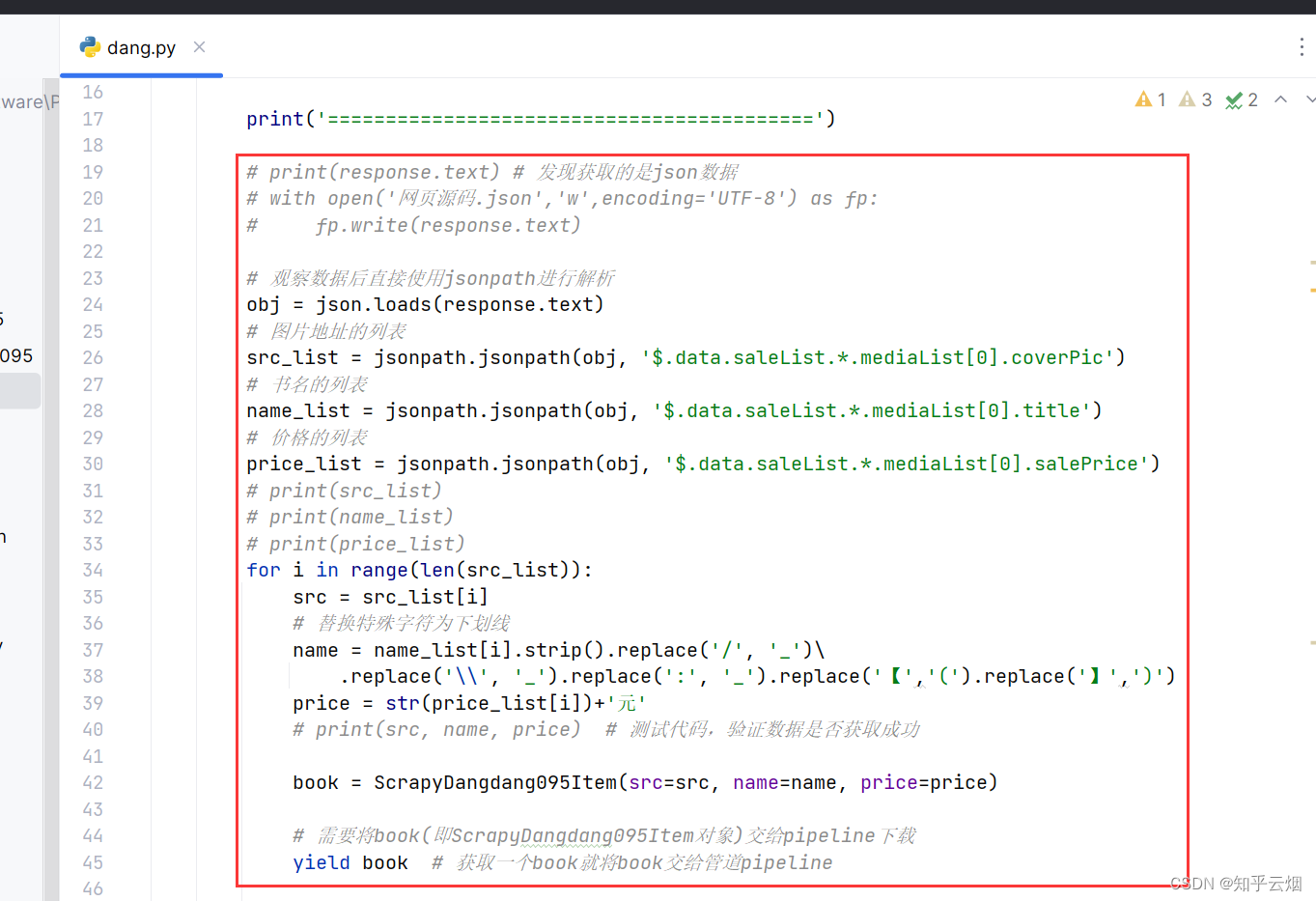
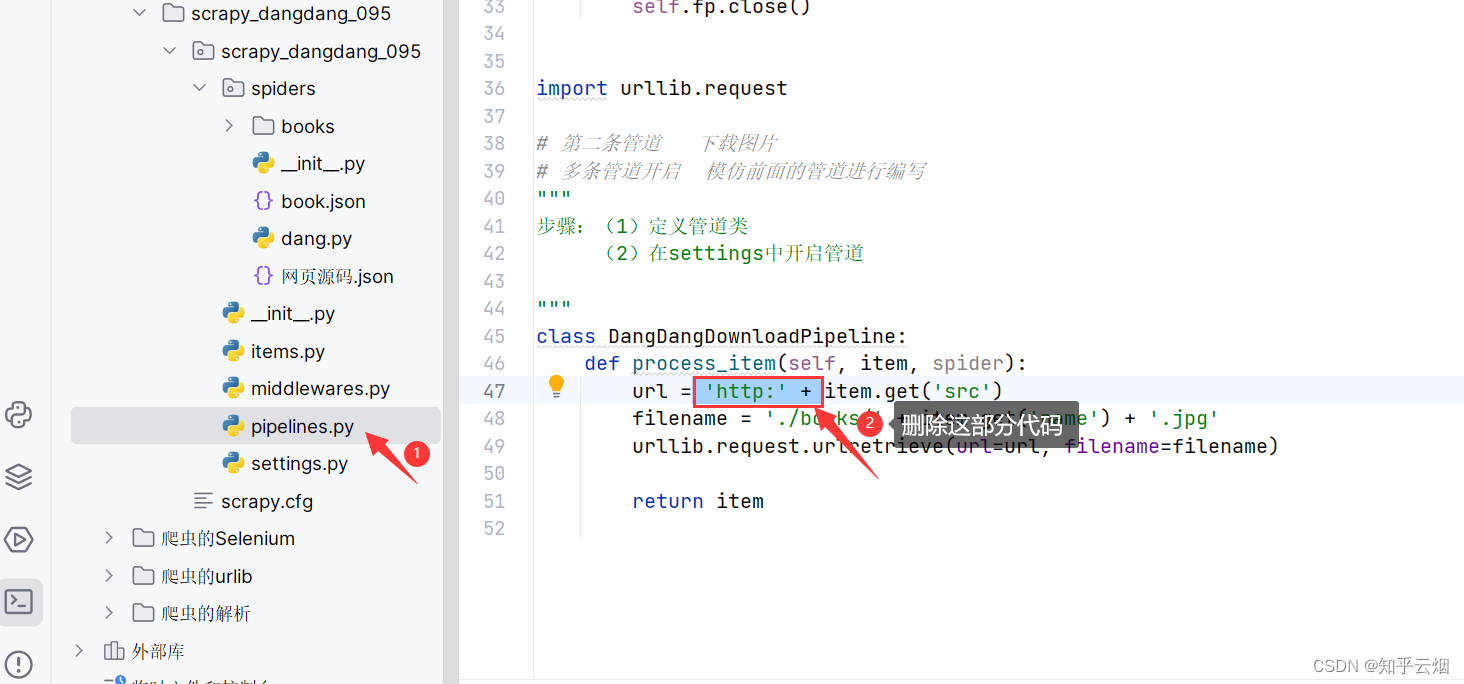
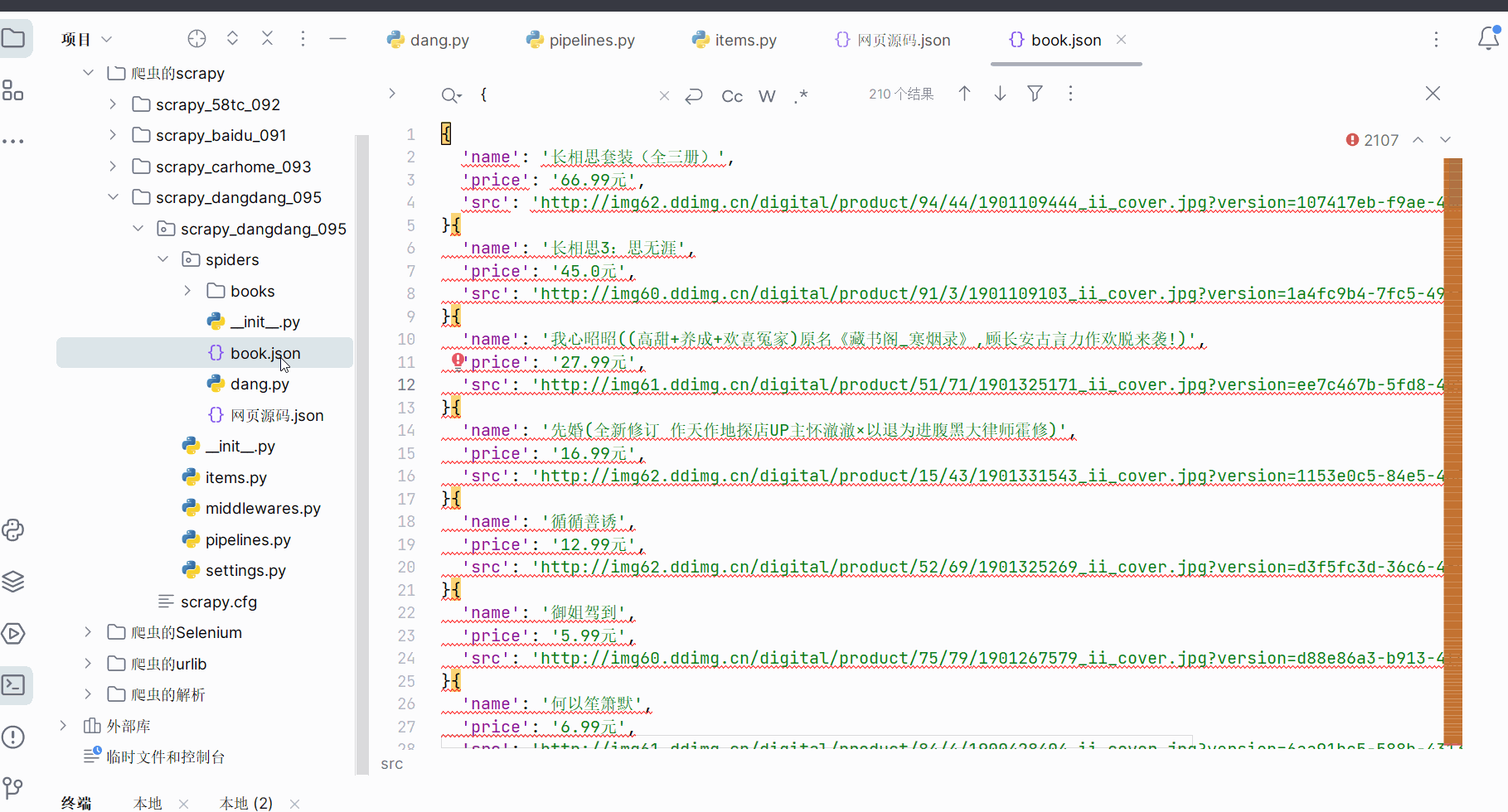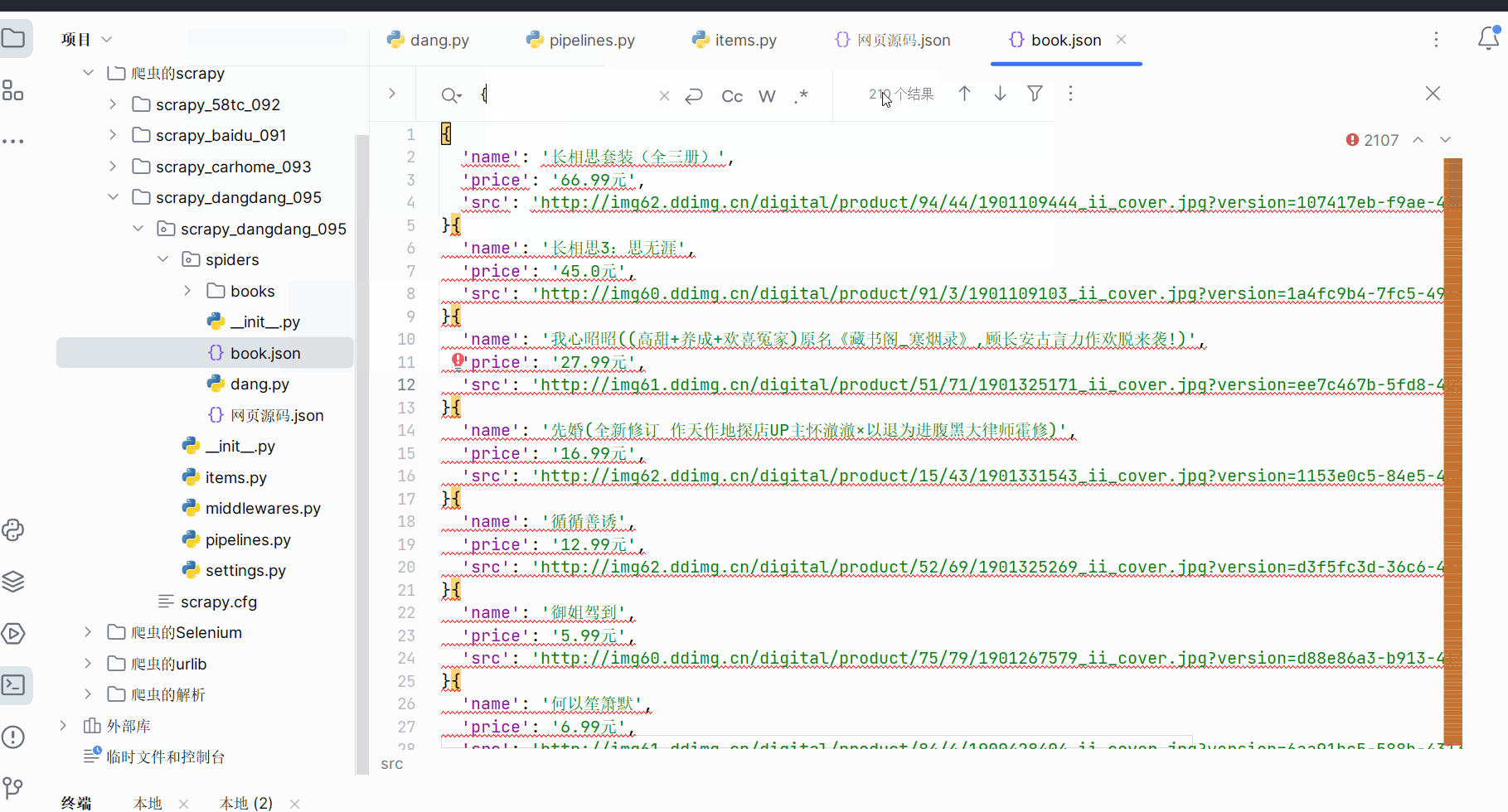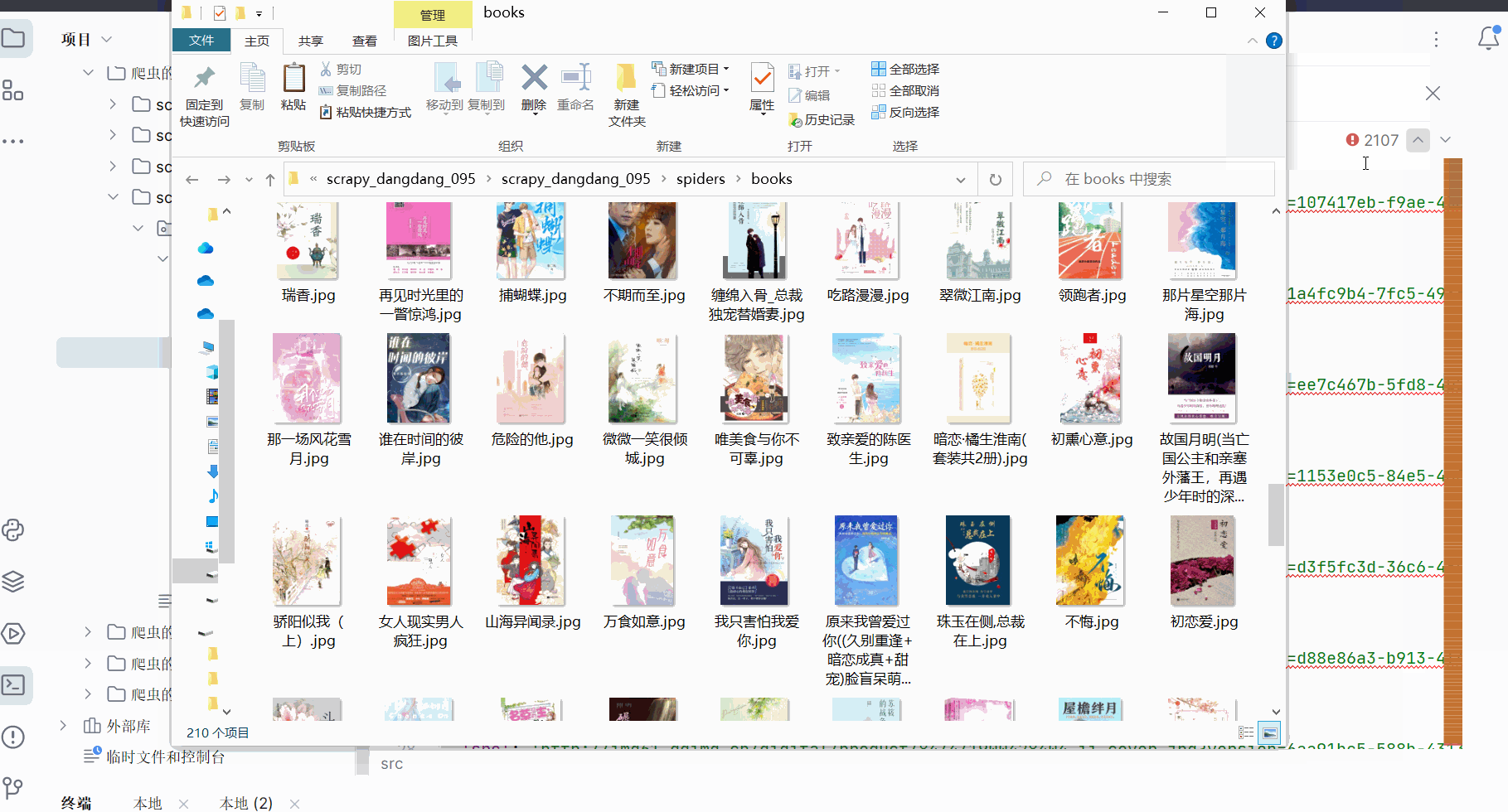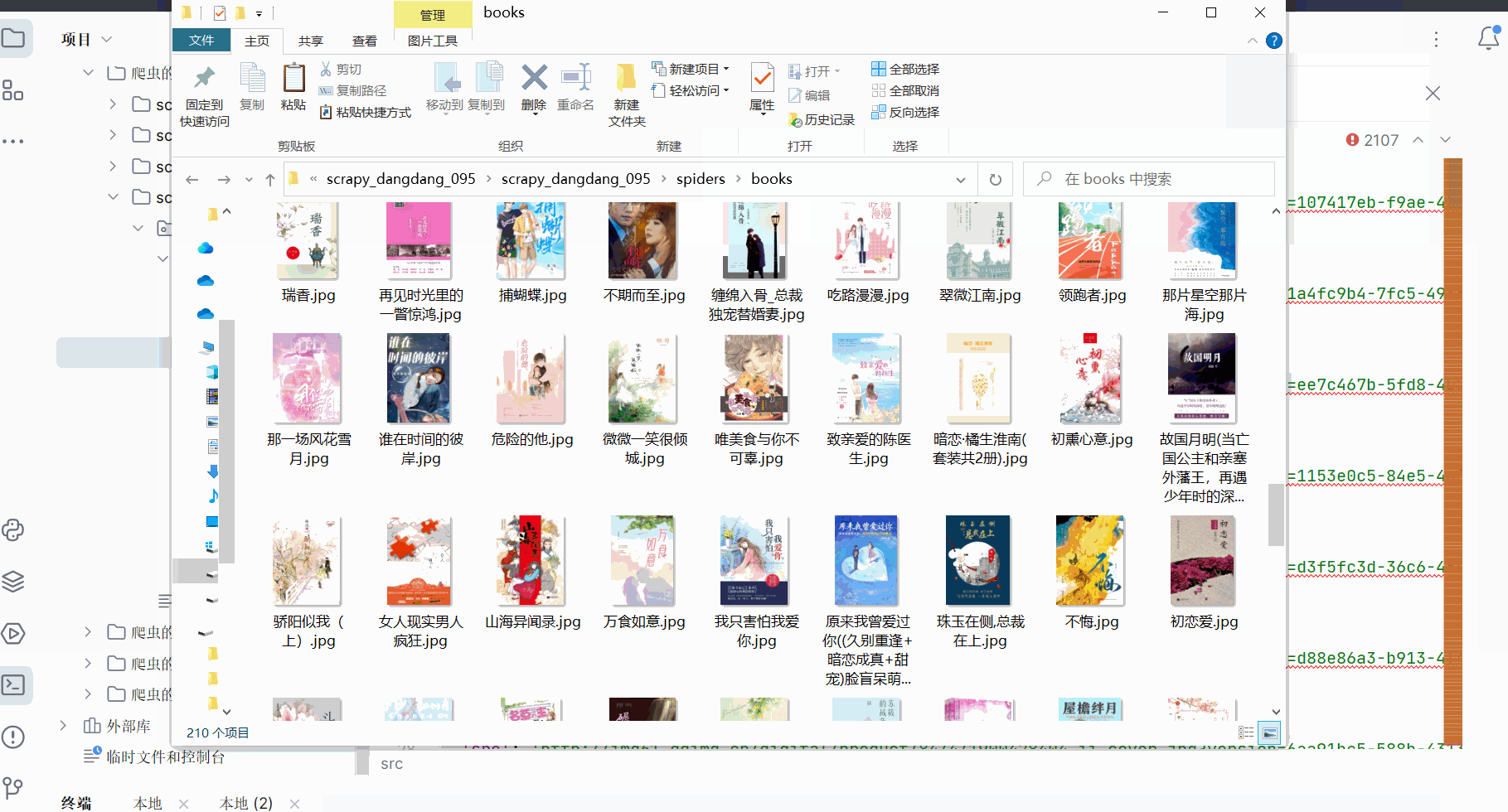
修改文件“pipelines.py”的代码,再次运行,发现第6、7、8节的功能都已实现。
同理,将连续几页接口的请求地址复制到PyCharm中,观察不同页码的请求地址的变化,根据请求地址的不同观察出其中的规律。

如下图所示,继续编写文件“dang.py”的代码(在下载10页图片时具体解决的问题:如何让不规范的文件名字变成合法的文件名字、如何处理相同的文件名字,请自行阅读代码进行理解)。
import scrapy
from ..items import ScrapyDangdang095Item
import jsonpath
import json
# import os # 用于判断哪些文件未成功下载,进而分析原因
class DangSpider(scrapy.Spider):
name = "dang"
# 如果是多页下载,allowed_domains的范围需要调整,‘http://’以及更改的部分不能留
allowed_domains = ["e.dangdang.com"]
start_urls = [
"http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerial-No=html5&macAddr=html5&channelType=html5&permanentId=20230814120937742356681582820154551&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=0&end=20&category=AQQG&dimension=dd_sale"]
# 前三页的接口地址
# http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerial-No=html5&macAddr=html5&channelType=html5&permanentId=20230814120937742356681582820154551&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=0&end=20&category=AQQG&dimension=dd_sale
# http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerial-No=html5&macAddr=html5&channelType=html5&permanentId=20230814120937742356681582820154551&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=21&end=41&category=AQQG&dimension=dd_sale
# http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerial-No=html5&macAddr=html5&channelType=html5&permanentId=20230814120937742356681582820154551&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&start=42&end=62&category=AQQG&dimension=dd_sale
base_url = 'http://e.dangdang.com/media/api.go?action=mediaCategoryLeaf&promotionType=1&deviceSerial-No=html5&macAddr=html5&channelType=html5&permanentId=20230814120937742356681582820154551&returnType=json&channelId=70000&clientVersionNo=6.8.0&platformSource=DDDS-P&fromPlatform=106&deviceType=pconline&token=&'
page = 1
all_name_list = [] # 所有名字的列表,用于判断哪些文件未成功被下载
def parse(self, response):
# pipelines 管道用于下载数据
# items 定义数据结构
print('==========================================')
# print(response.text) # 发现获取的是json数据
# with open('网页源码.json','w',encoding='UTF-8') as fp:
# fp.write(response.text)
# 观察数据后直接使用jsonpath进行解析
obj = json.loads(response.text)
# 图片地址的列表
src_list = jsonpath.jsonpath(obj, '$.data.saleList.*.mediaList[0].coverPic')
# 书名的列表
name_list = jsonpath.jsonpath(obj, '$.data.saleList.*.mediaList[0].title')
# 价格的列表
price_list = jsonpath.jsonpath(obj, '$.data.saleList.*.mediaList[0].salePrice')
# print(src_list)
# print(name_list)
# print(price_list)
for i in range(len(src_list)):
src = src_list[i]
# 替换特殊字符为下划线
name = name_list[i].strip().replace('/', '_') \
.replace('\\', '_').replace(':', '_').replace('【', '(').replace('】', ')') \
.replace('?', '_').replace('*', '_')
# 防止出现相同的名字
name_count = 0
while name in self.all_name_list:
name_count += 1
name = f"{name}_{name_count}" # 在元素后面添加计数
self.all_name_list.append(name)
price = str(price_list[i]) + '元'
# print(src, name, price) # 测试代码,验证数据是否获取成功
book = ScrapyDangdang095Item(src=src, name=name, price=price)
# 需要将book(即ScrapyDangdang095Item对象)交给pipeline下载
yield book # 获取一个book就将book交给管道pipeline
# 每一页的爬取的业务逻辑全都是一样的,所以只需要将执行的那个页的请求再次调用parse方法就可以了
if self.page < 10:
self.page += 1
url = self.base_url + f"start={(self.page - 1) * 21}&end={self.page * 21 - 1}&category=AQQG&dimension=dd_sale"
# 怎么调用parse方法
# scrapy.Request就是scrapy的get请求
# - url就是请求地址、callback就是需要执行的函数、parse不能加括号
yield scrapy.Request(url=url, callback=self.parse)
# # 找到未被下载的图片
# print(len(self.all_name_list))
# print(self.all_name_list)
# for name in self.all_name_list:
# if not os.path.exists(f'./books/{name}.jpg'):
# print(f"未被下载的图片:{name}.jpg")
10.scrapy_电影天堂多页数据下载
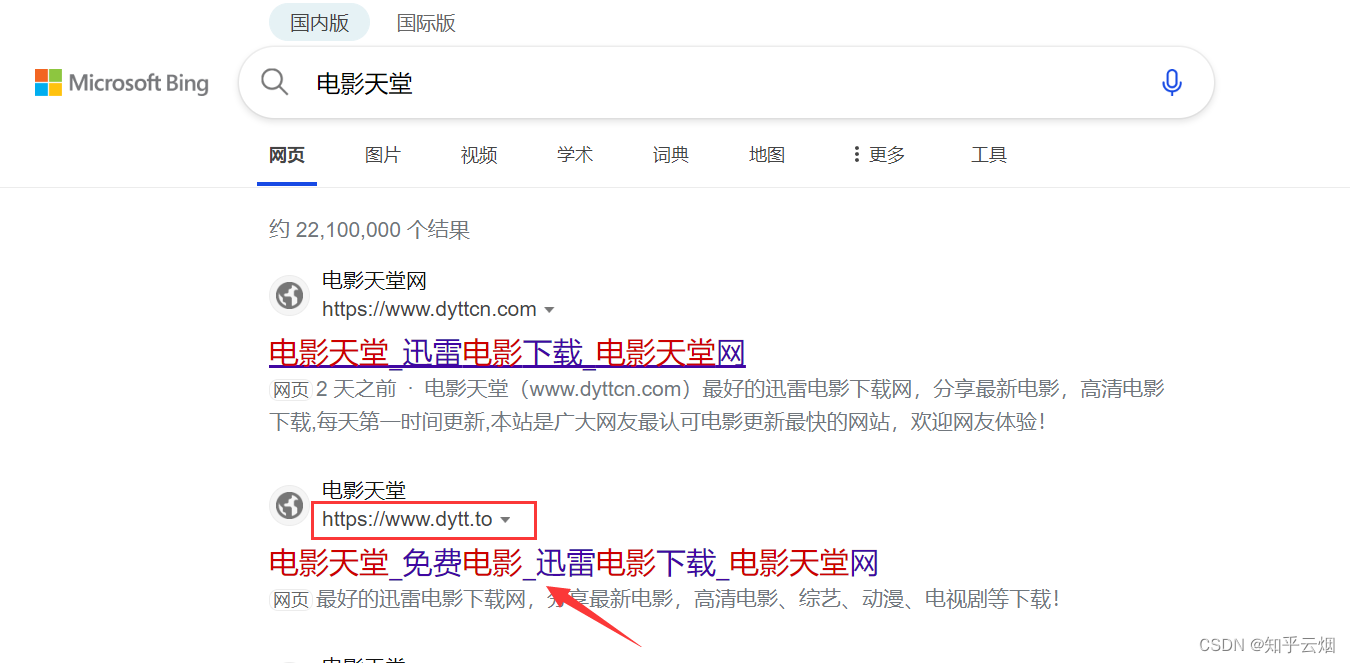
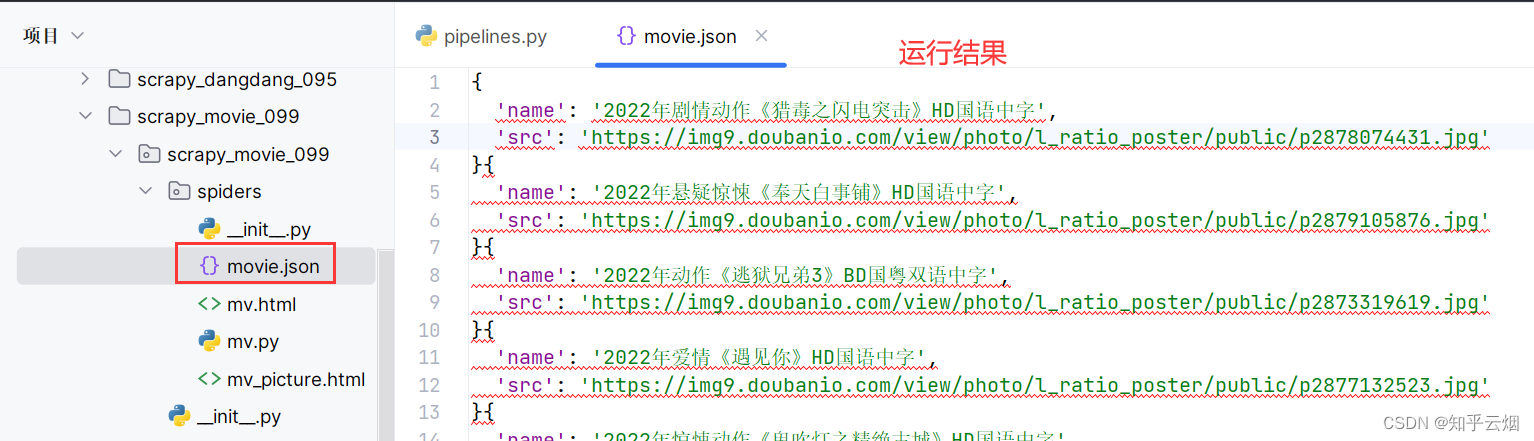
打开电影天堂(网站链接为电影天堂,其实本网站已不再更新,网站已经更换域名,但为了和视频讲解尽量一致,本次演示所选的还是原来的网站),选择国内电影。然后点击“世界上最爱我的人”,发现该电影对应的封面。本次需求是在“items.py”定义本次的数据结构,然后将标题“世界上最爱我的人”和对应图片的地址定义为一个item对象进行下载,最终得到的数据是含标题和图片地址的json文件。如果还想下载图片,请参考上一节的“pipelines.py”的代码。
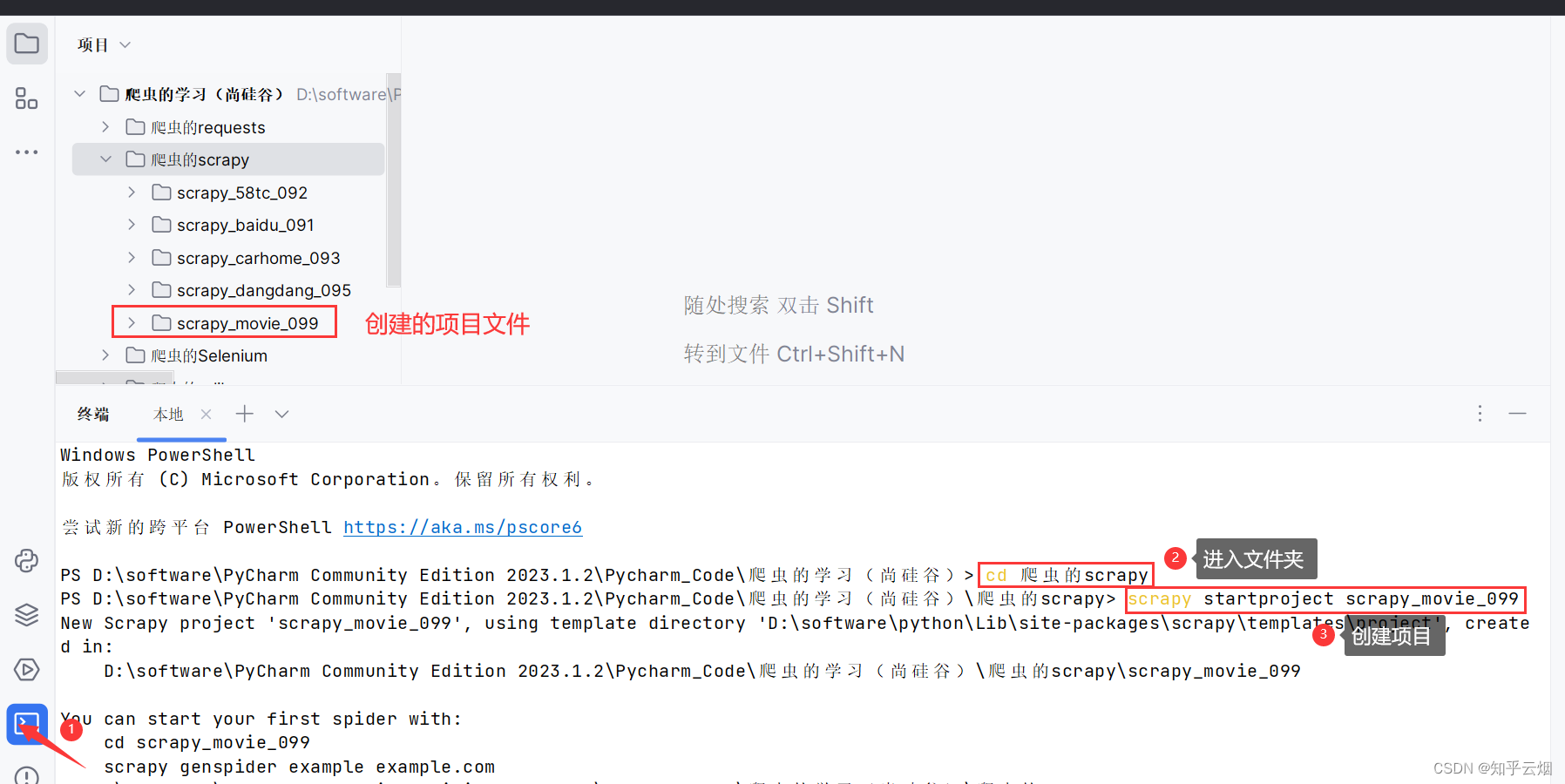
如下图,创建一个名为“scrapy_movie_099”的项目(“scrapy startproject scrapy_movie_099”)。
如下图所示,寻找含有电影名字的接口,并复制其请求地址。
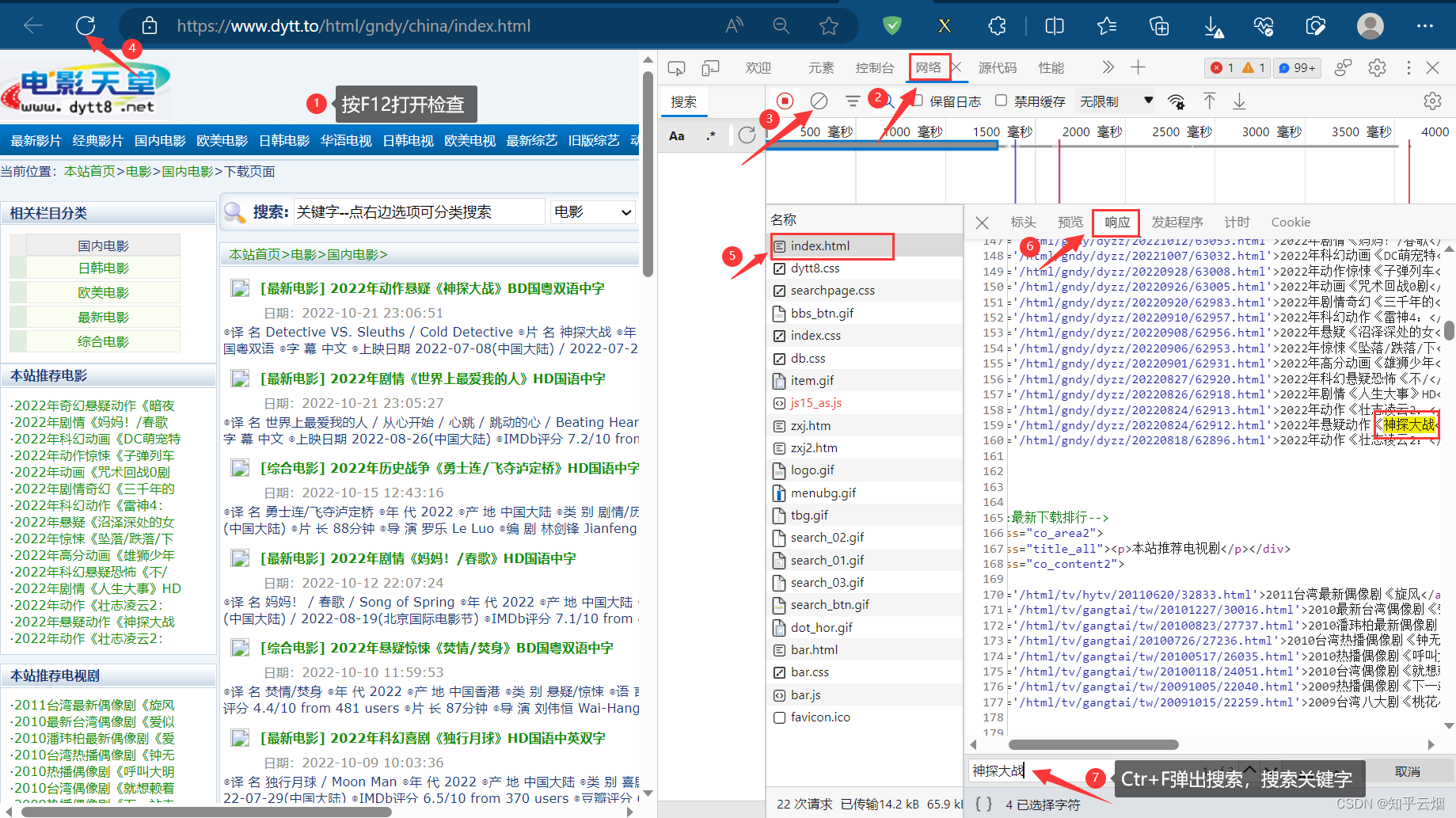

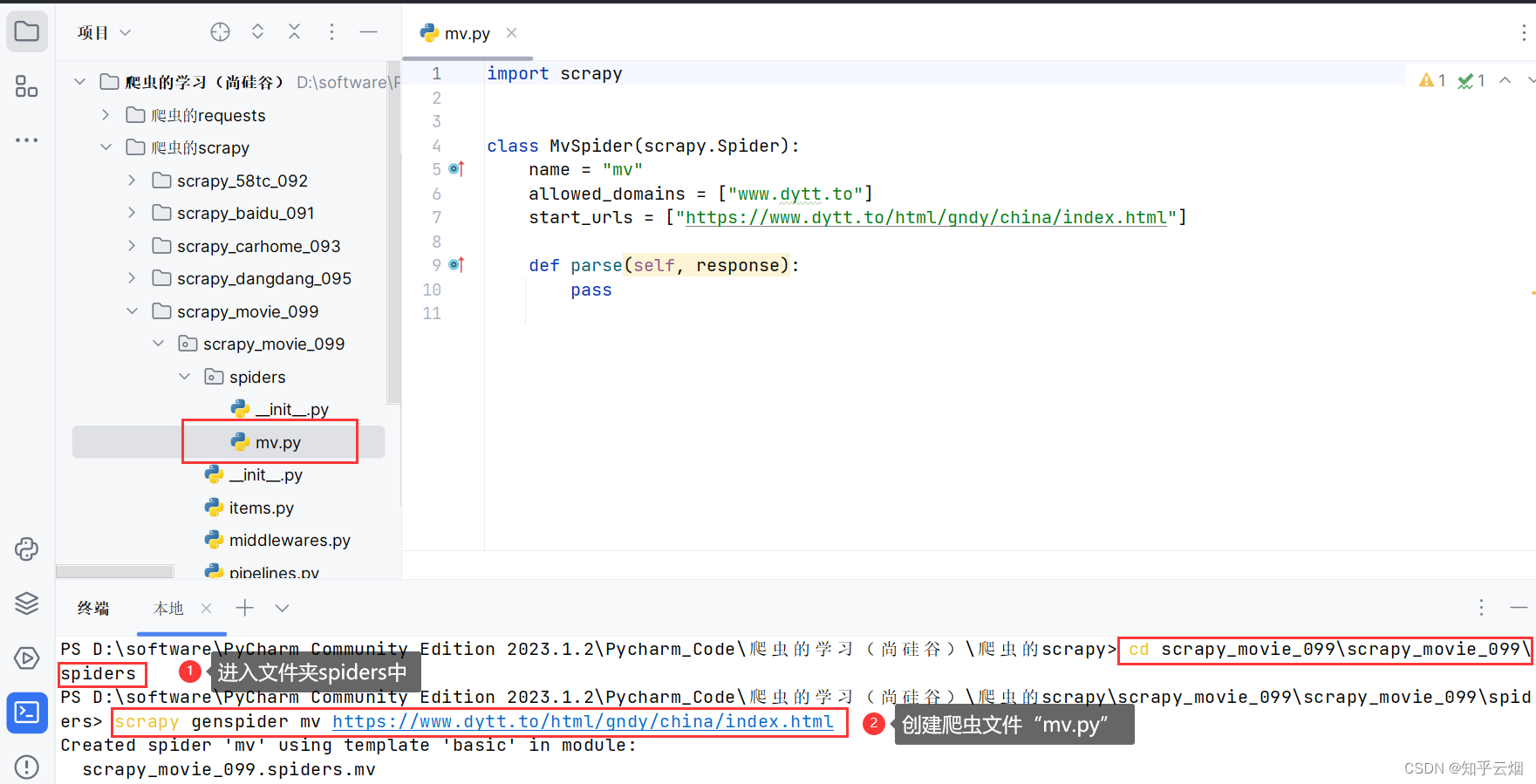
然后进入文件夹spiders中(“cd scrapy_movie_099\scrapy_movie_099\spiders”),创建爬虫文件“mv.py”(“scrapy genspider mv 域名”)。
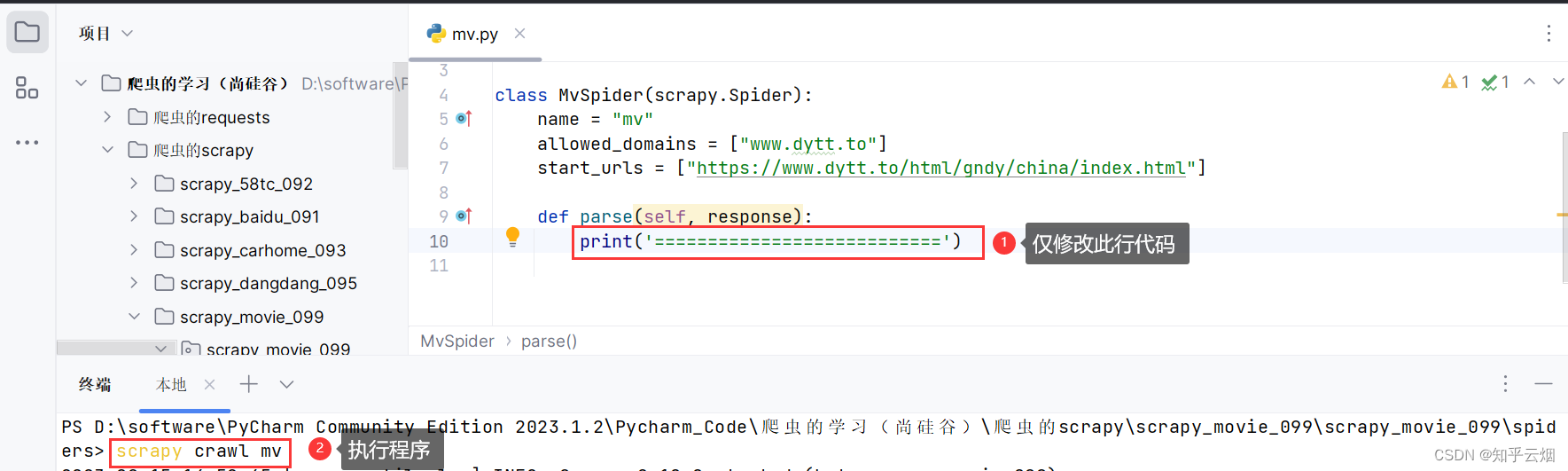
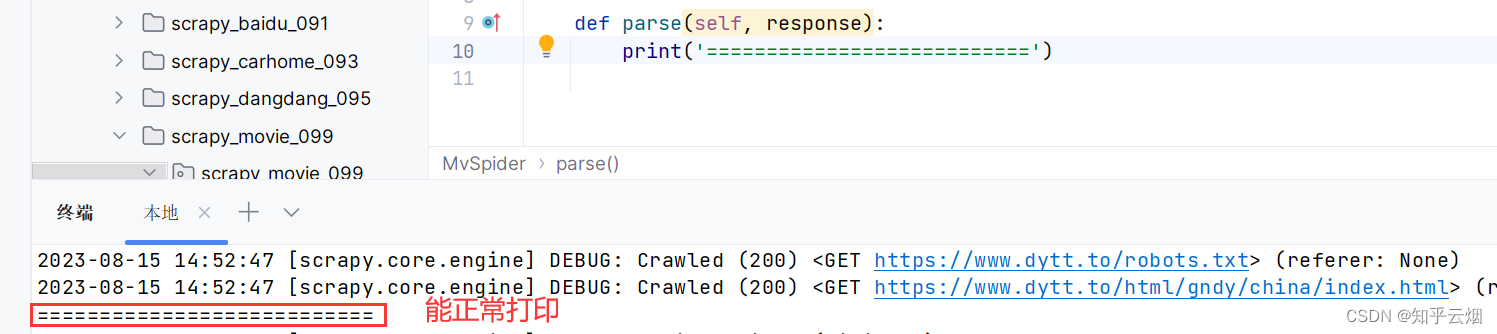
然后看看程序是否能正常打印,如果能正常打印则说明不存在反爬。
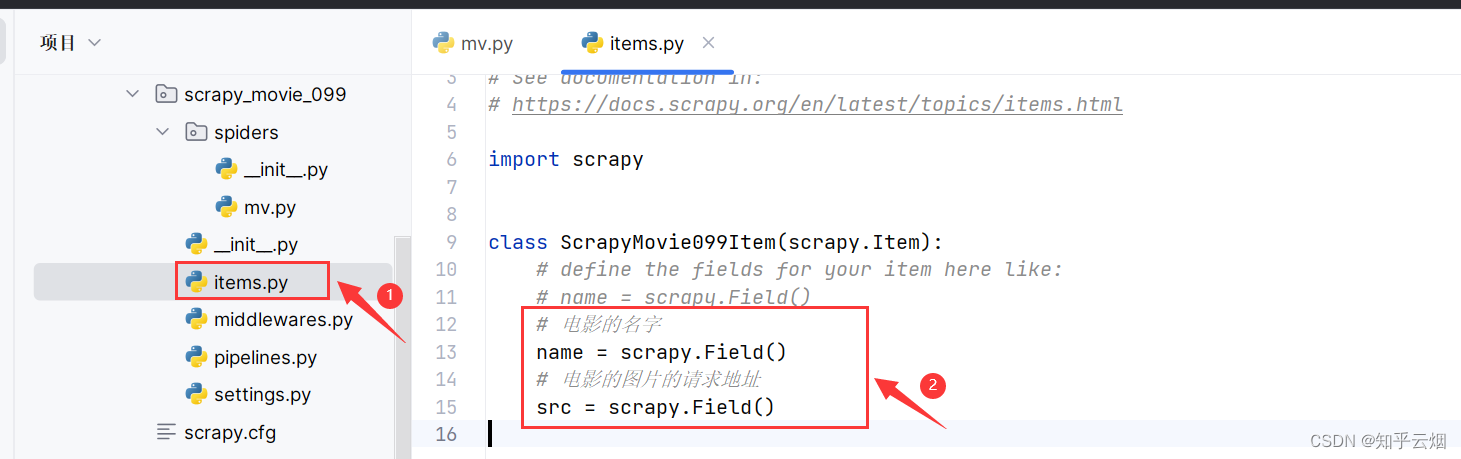
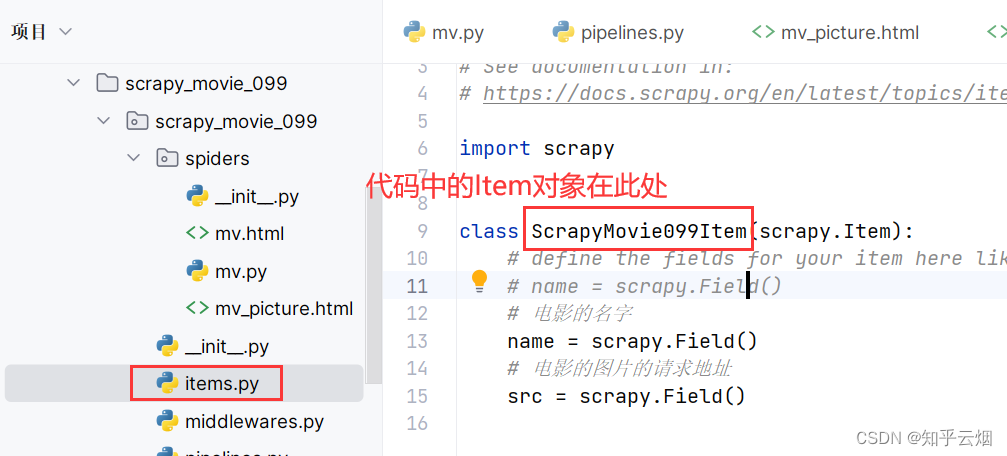
先去“items.py”中定义本次下载的数据结构。
# 电影的名字
name = scrapy.Field()
# 电影的图片的请求地址
src = scrapy.Field()
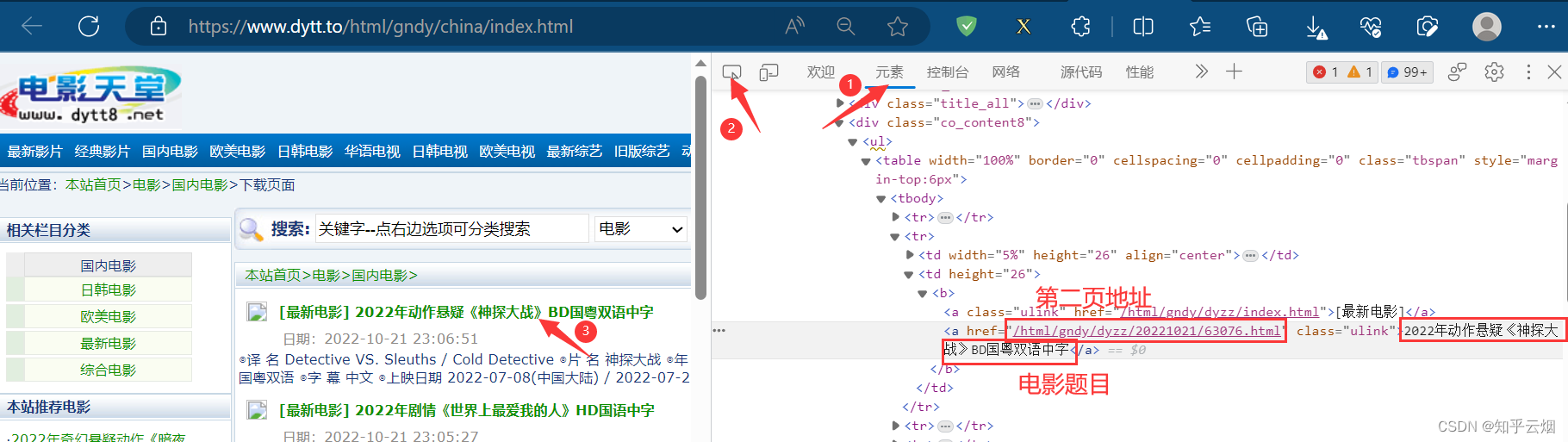
如下图,找到了电影题目的位置和第二页的地址。
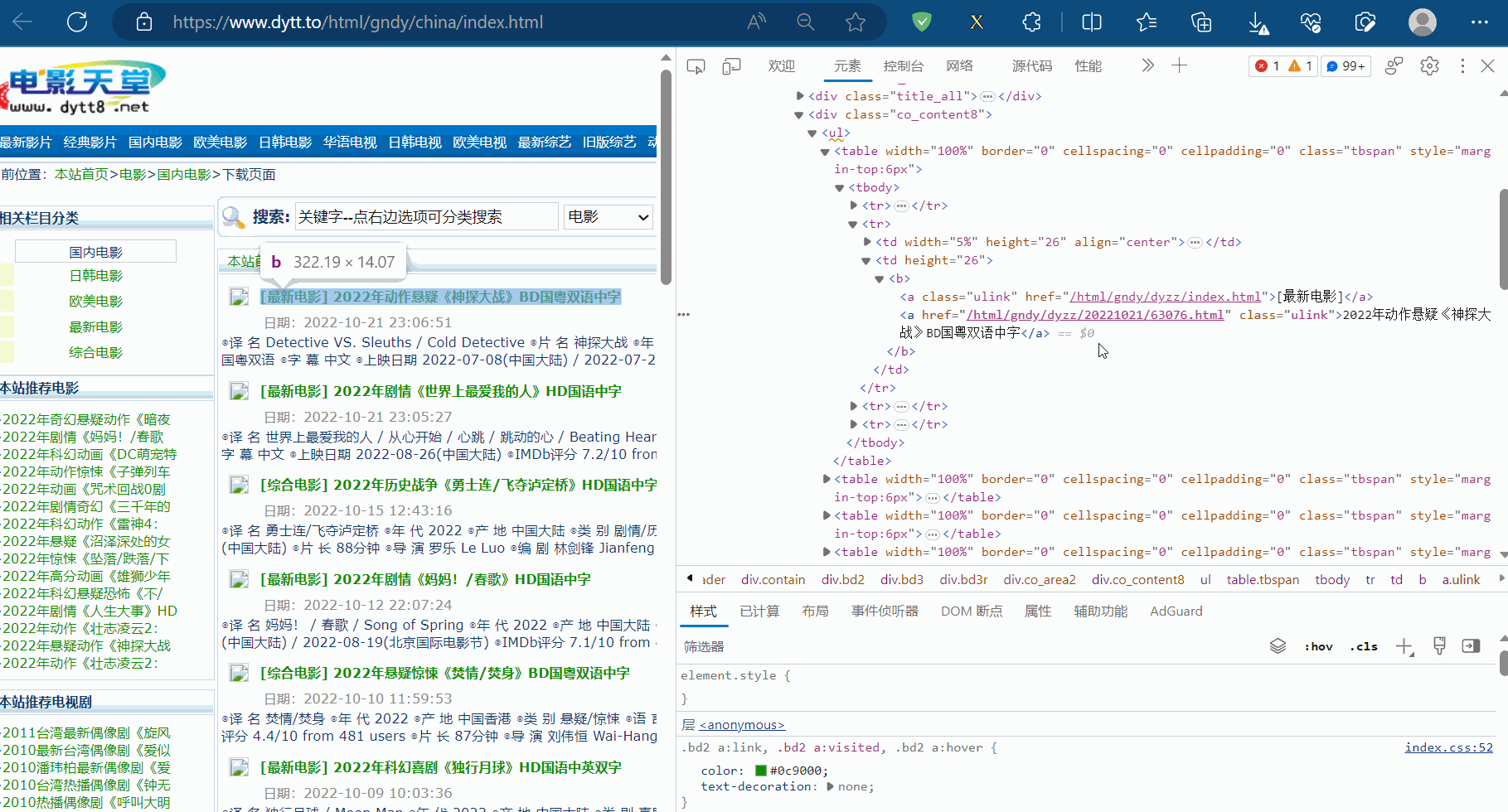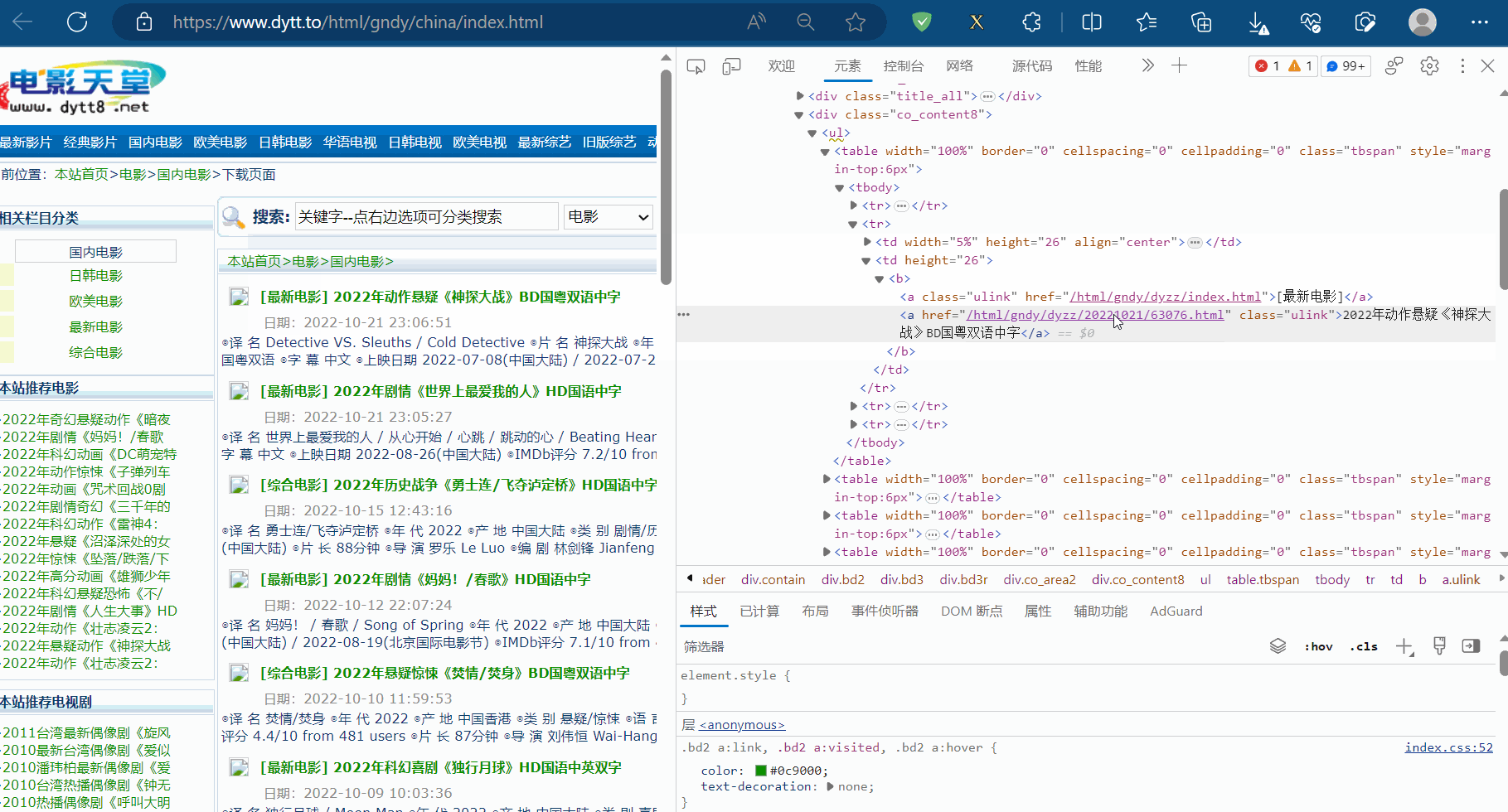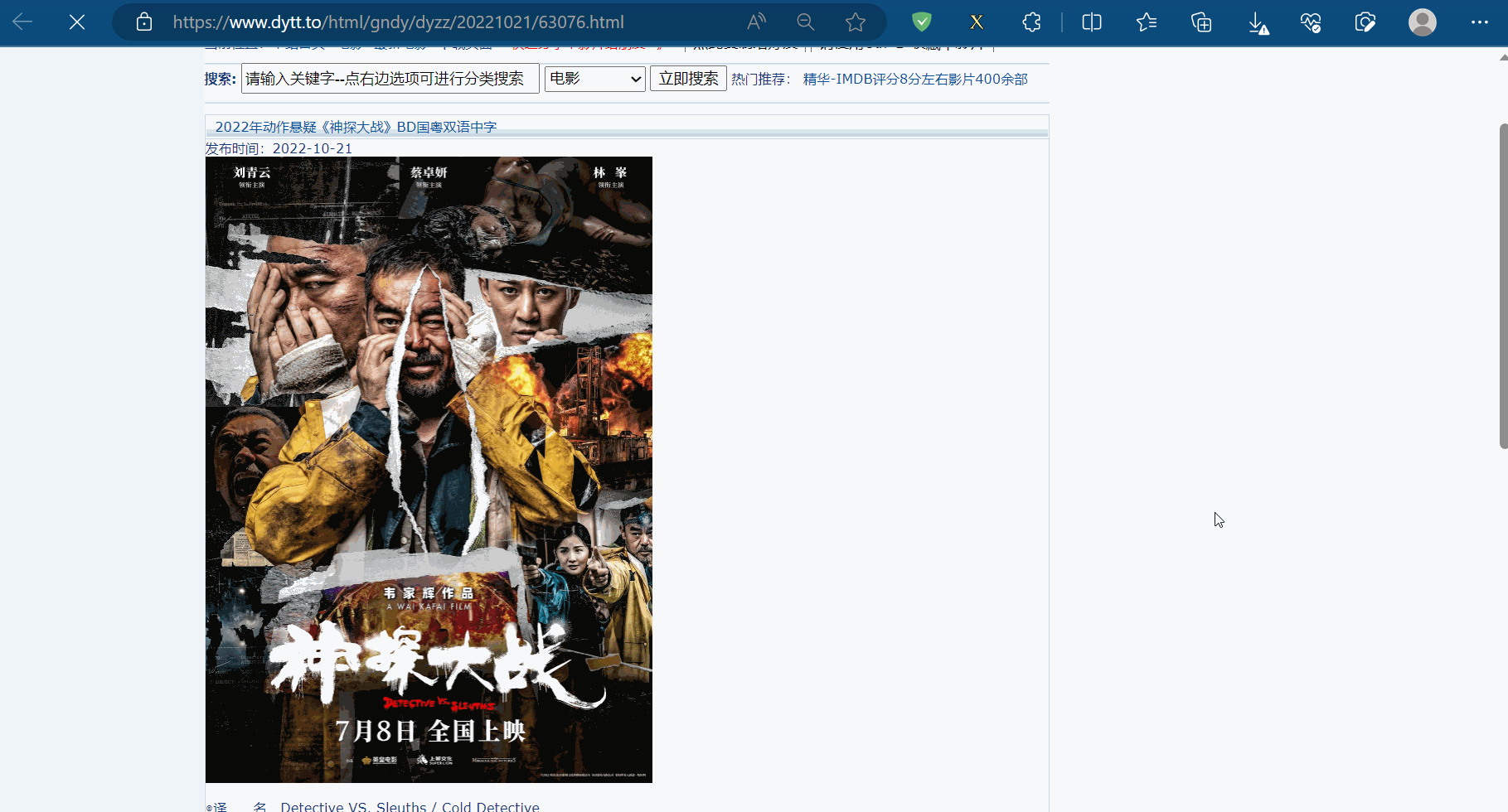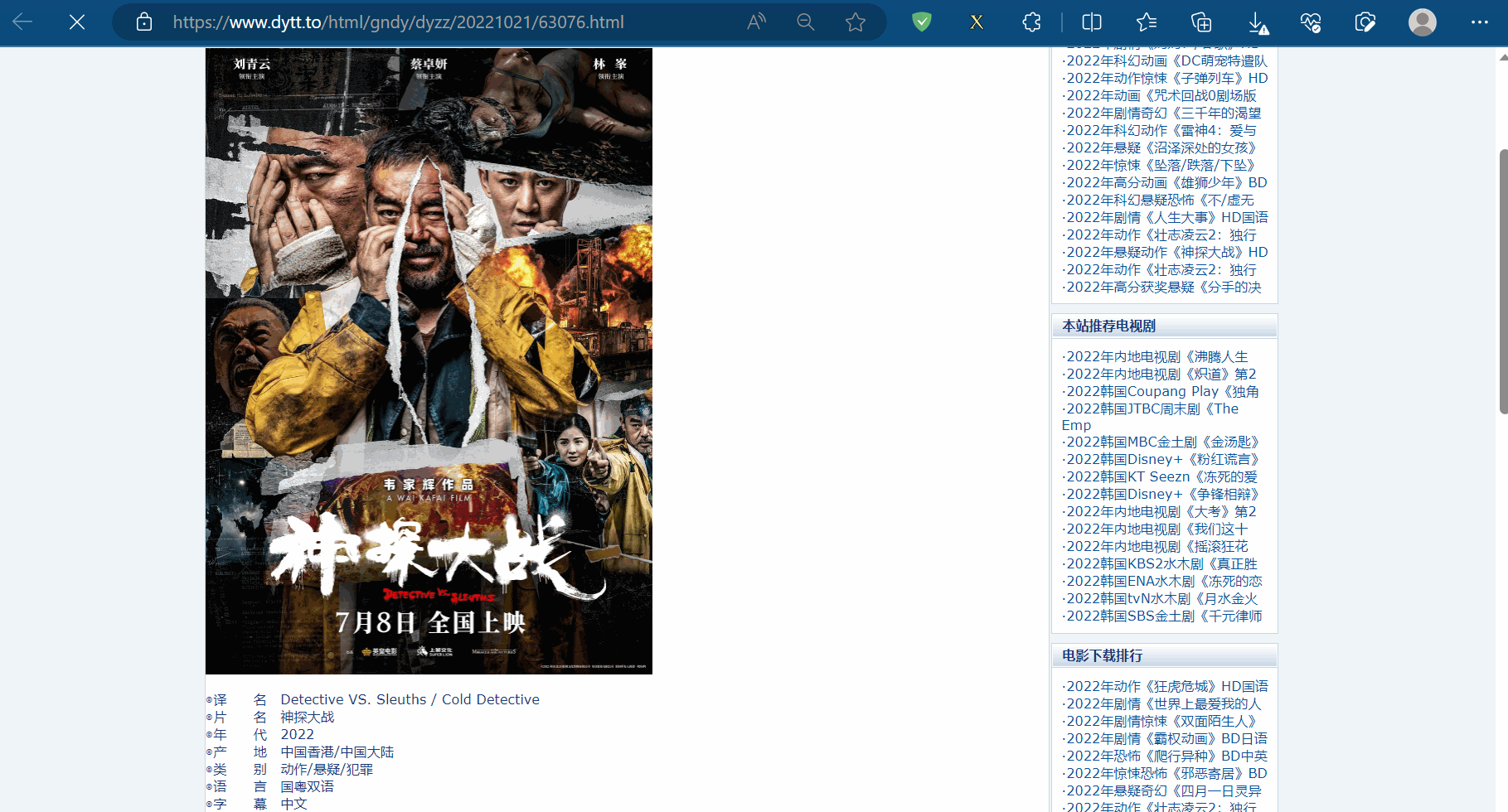
如下图,找到电影电影题目和第二页的地址的xpath路径。
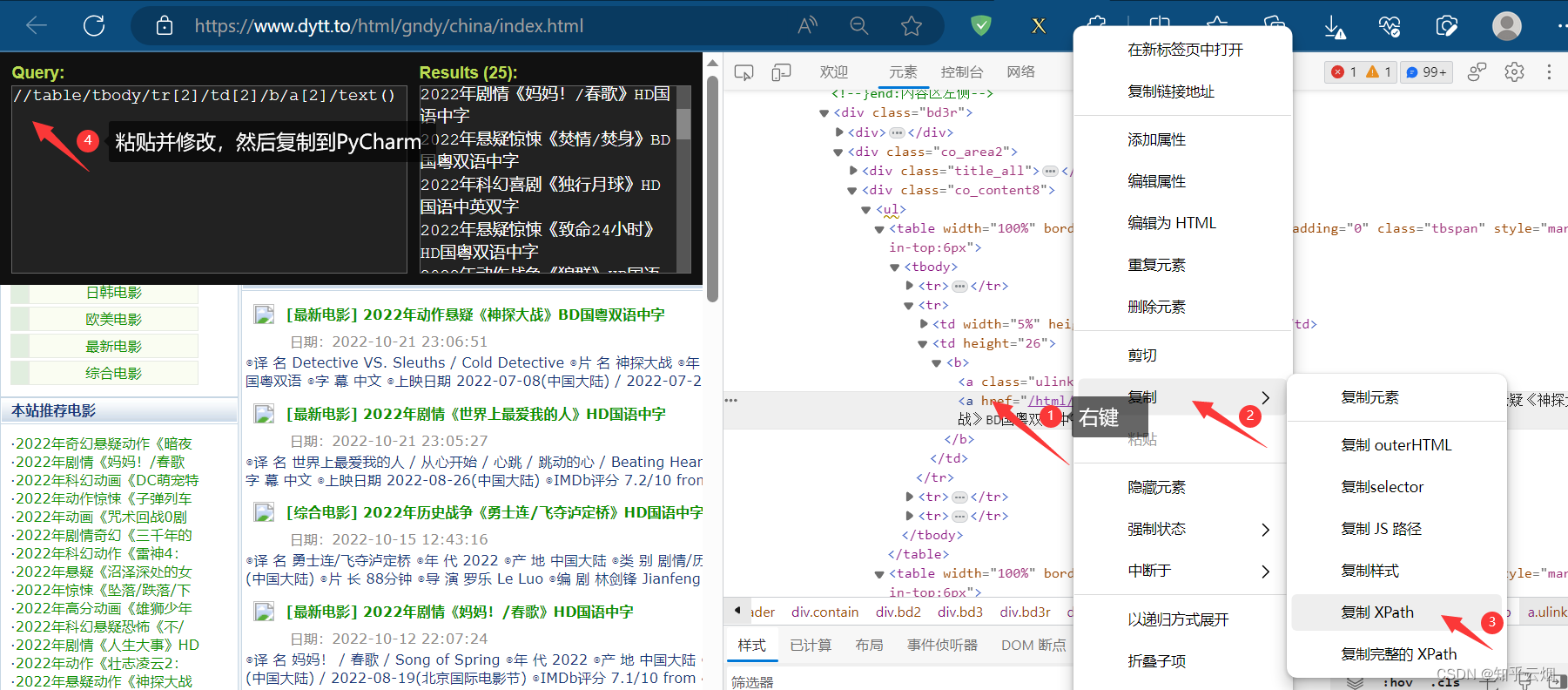
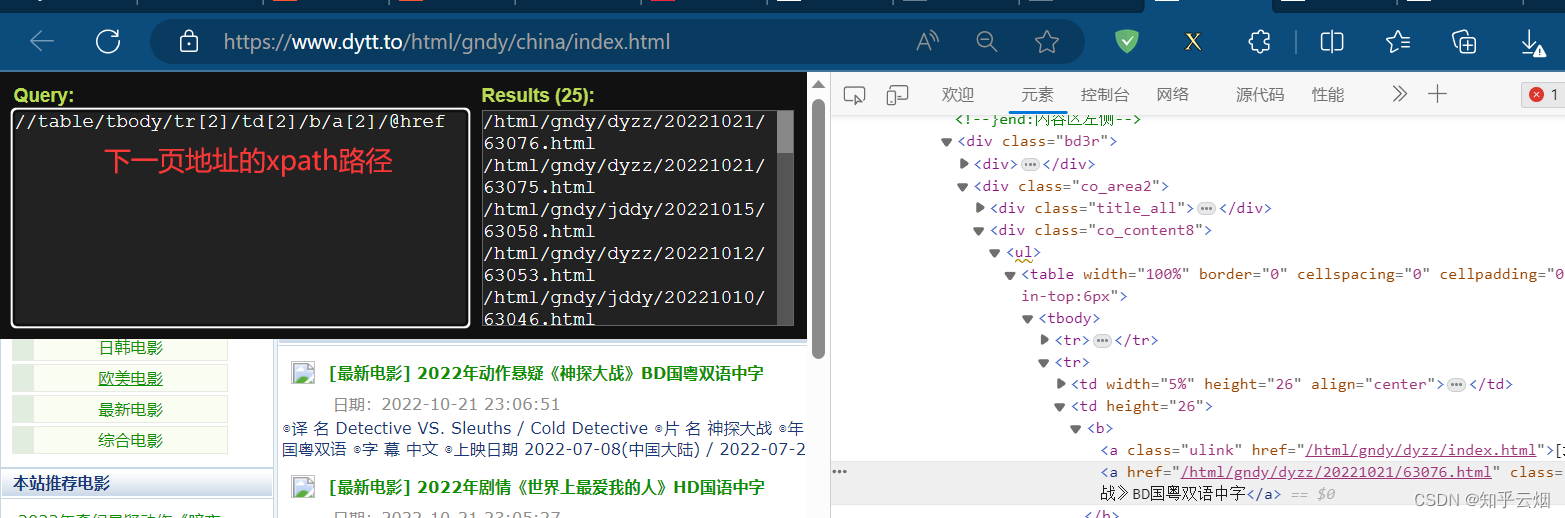
后面发现实际的xpath路径和浏览器里寻找的不一致,故将网页源码写到文件中,根据网页源码手动编写xpath路径,然后运行程序,发现能够获取到电影名字以及第二页的地址。
import scrapy
class MvSpider(scrapy.Spider):
name = "mv"
allowed_domains = ["www.dytt.to"]
start_urls = ["https://www.dytt.to/html/gndy/china/index.html"]
def parse(self, response):
# 要第一页的名字 和 第二页的图片的地址
# 对应的xpath路径
# '//table/tr[2]/td[2]/b/a[2]/text()'
# '//table/tr[2]/td[2]/b/a[2]/@href'
# 将网页源码写进一个文件中
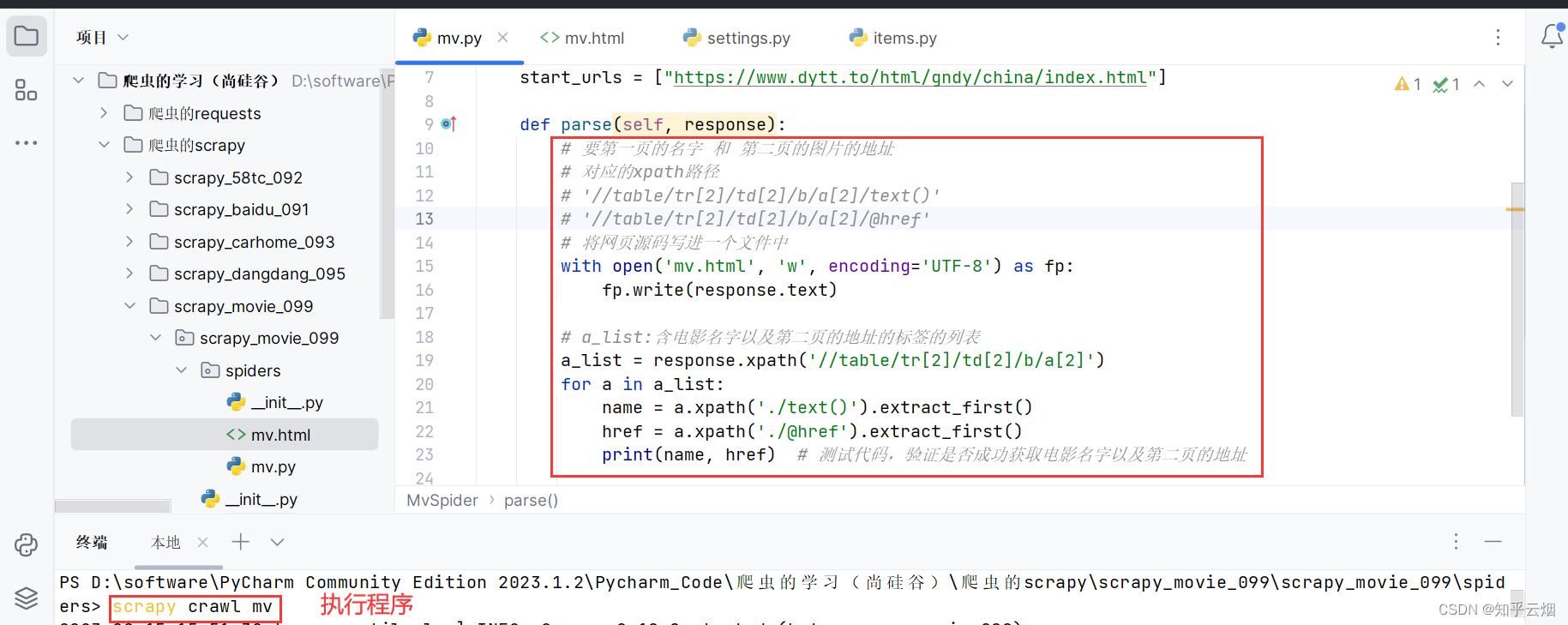
with open('mv.html', 'w', encoding='UTF-8') as fp:
fp.write(response.text)
# a_list:含电影名字以及第二页的地址的标签的列表
a_list = response.xpath('//table/tr[2]/td[2]/b/a[2]')
for a in a_list:
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
print(name, href) # 测试代码,验证是否成功获取电影名字以及第二页的地址
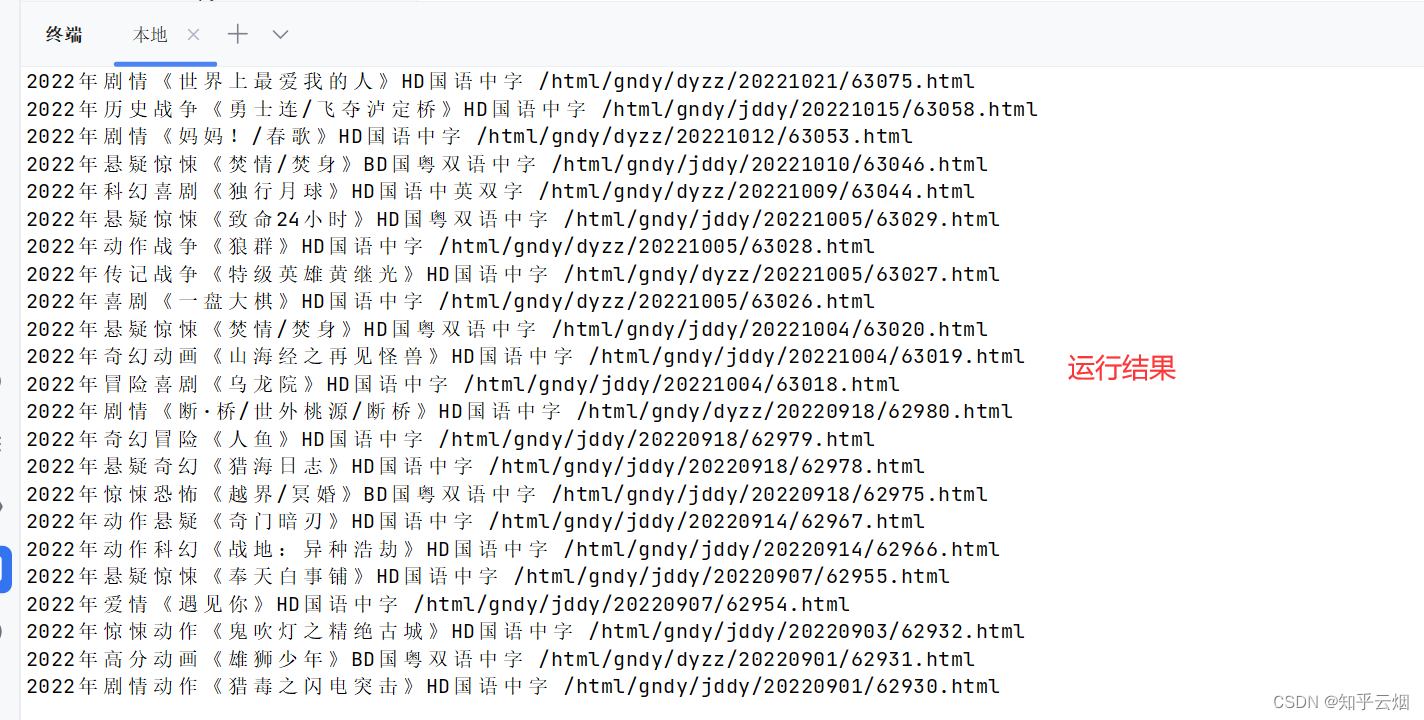
经观察,实际的链接比herf多“https://www.dytt.to/”。
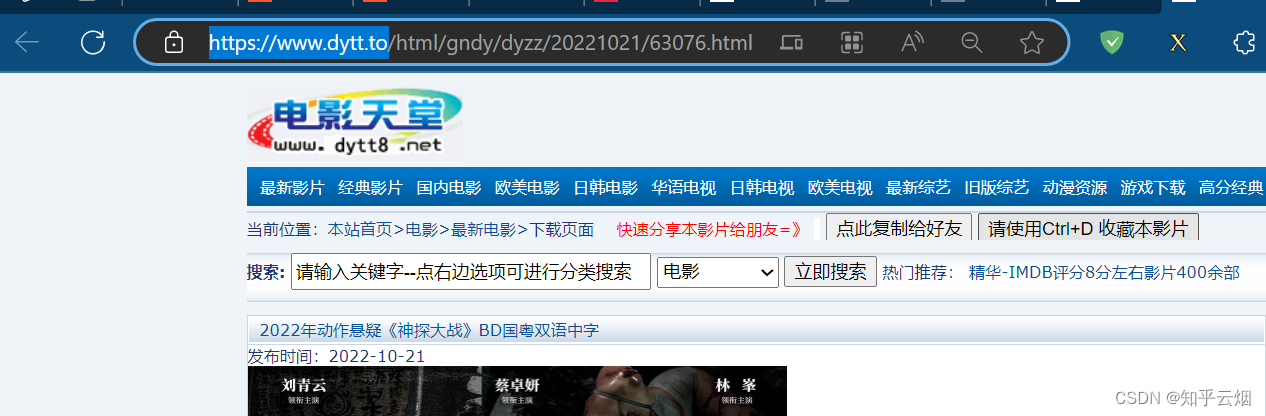
与前面同理,找到第二页图片的请求地址的xpath路径,后面实际上运行后与浏览器找的不一样,是把实际的网页源码写成文件找的,此处是span标签和浏览器中不一样(截图已省)。
编写“mv.py”代码(注意学会:将name传到meta,以便在定义到的parse方法中收到该参数),在“setting.py”中打开管道,在“pipelines.py”中封装管道,然后运行。
import scrapy
from ..items import ScrapyMovie099Item
class MvSpider(scrapy.Spider):
name = "mv"
# 范围可以设大一点
allowed_domains = ["www.dytt.to"]
start_urls = ["https://www.dytt.to/html/gndy/china/index.html"]
def parse(self, response):
# 要第一页的名字 和 第二页的图片的地址
# 对应的xpath路径
# '//table/tr[2]/td[2]/b/a[2]/text()'
# '//table/tr[2]/td[2]/b/a[2]/@href'
# # 将网页源码写进一个文件中
# with open('mv.html', 'w', encoding='UTF-8') as fp:
# fp.write(response.text)
# a_list:含电影名字以及第二页的地址的标签的列表
a_list = response.xpath('//table/tr[2]/td[2]/b/a[2]')
for a in a_list:
# 获取第一页的name和要点击的链接href
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# print(name, href) # 测试代码,验证是否成功获取电影名字以及第二页的地址
# 第二页的地址
# 实际的链接比herf多“https://www.dytt.to/”
url = 'https://www.dytt.to/' + href
# print(name, url) # 测试代码,验证是否是电影名字以及第二页的地址
# 对第二页的链接发起访问 将name传到meta,以便在方法parse_second中收到该参数
yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': name})
def parse_second(self, response):
# print('1234567890') # 验证是否会执行本方法
# # 将网页源码写进一个文件中
# with open('mv_picture.html', 'w', encoding='UTF-8') as fp:
# fp.write(response.text)
# 第二页图片的请求地址
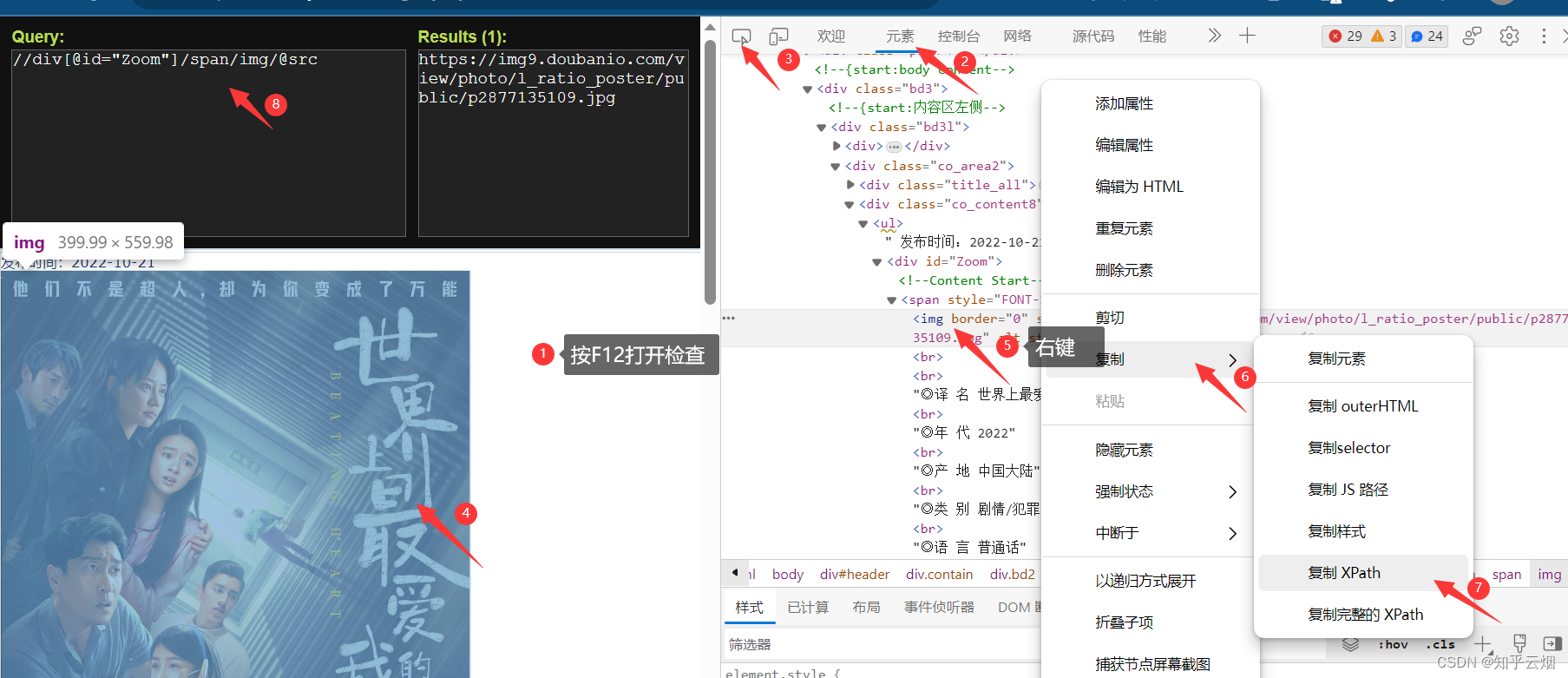
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# print(src) # 测试代码,验证是否获取到第二页图片的请求地址
# 接收到请求的meta参数的值 实际就是电影名字
name = response.meta['name']
movie = ScrapyMovie099Item(src=src, name=name)
# 将movie返回给管道
yield movie
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ScrapyMovie099Pipeline:
# 打开管道
def open_spider(self, spider):
self.fp = open('movie.json', 'w', encoding='UTF-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
# 关闭管道
def close_spider(self,spider):
self.fp.close()

11. scrapy_链接提取器CrawlSpider的使用(含MySql、pymysql的使用)
本节将使用CrawlSpider简单地爬取数据,熟悉CrawlSpider的链接提取器的语法,然后下下一节将使用MySql、pymysql将数据放入数据库中。
(1)MySQL的安装和初级使用
关于MySQL的安装和初级使用,请参考本人的笔记:第二阶段-第二章 SQL入门和实战。
(2)CrawlSpider的作用

比如,我们可以设定一个规则,然后把当前页面所有符合这个规则的链接提取出来,然后对这些链接进行解析就可以了。
(3)CrawlSpider的使用方法

对于链接提取器而言,常用的是正则表达式、xpath、css,即allow=()、restrict_xpaths =()、restrict_css =()。

(4)代码演示
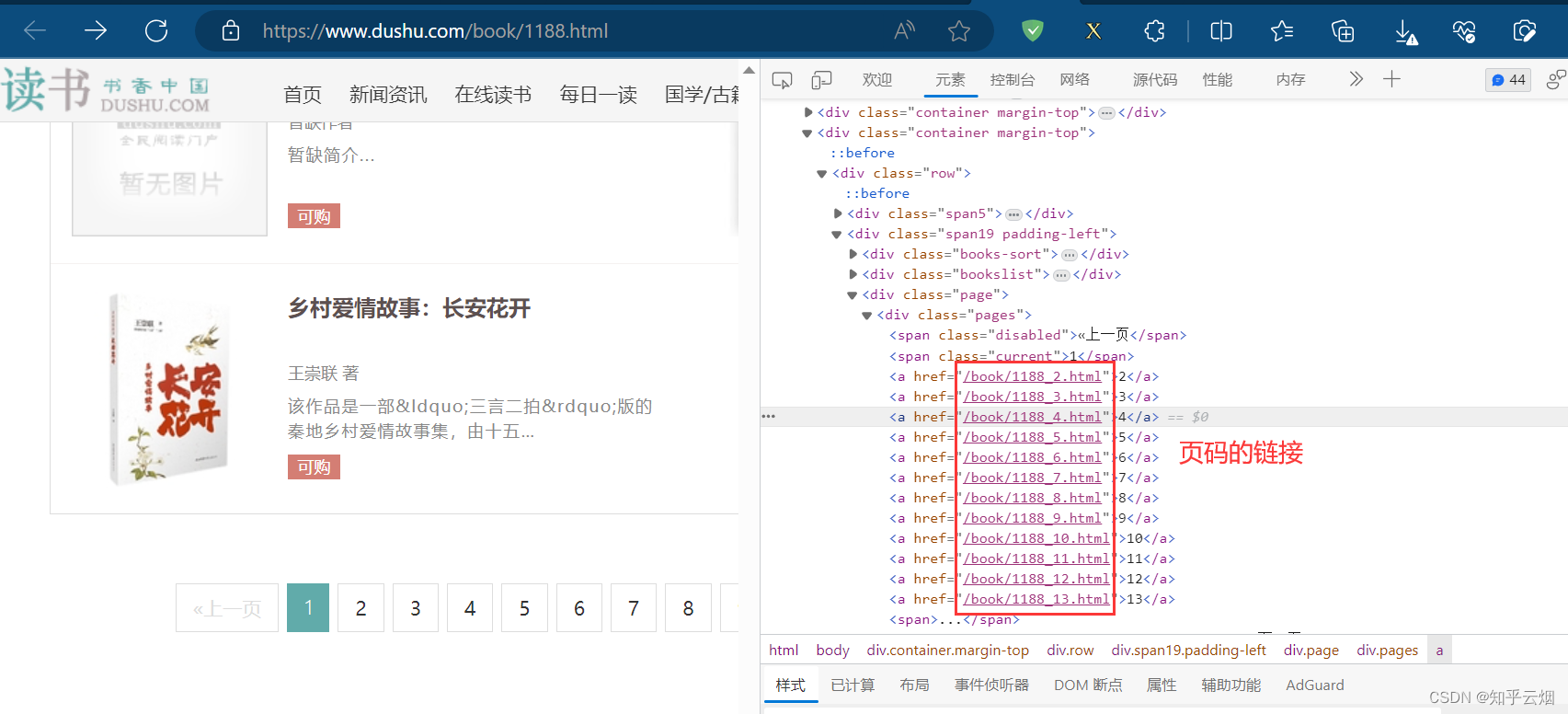
本次将以读书网进行演示,使用正则表达式和xpath来提取页码的链接。如下图,打开读书网,选择“当代小说”,然后在检查中找到页码的链接。然后,复制读书网的当代小说的第一页的链接。
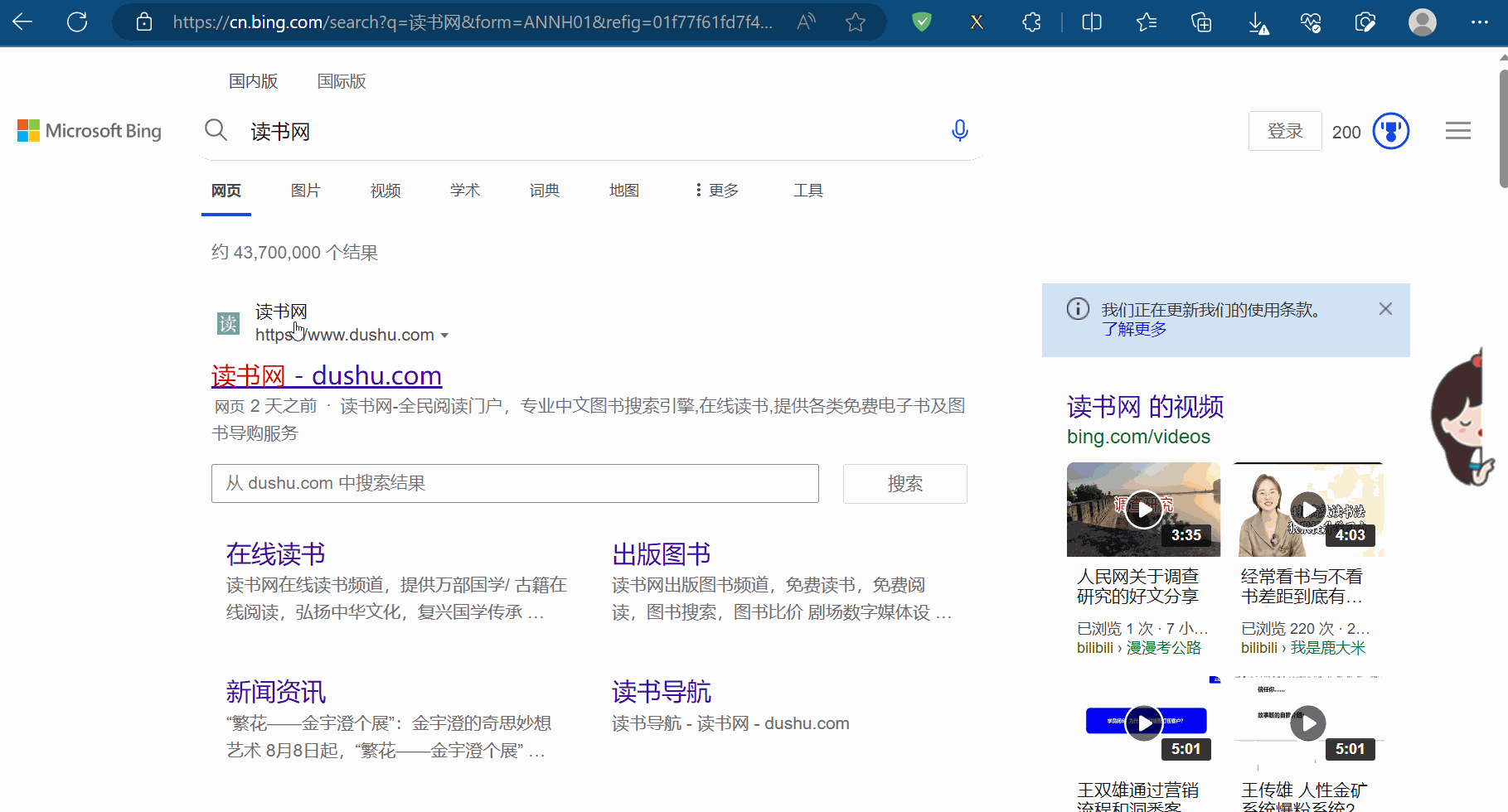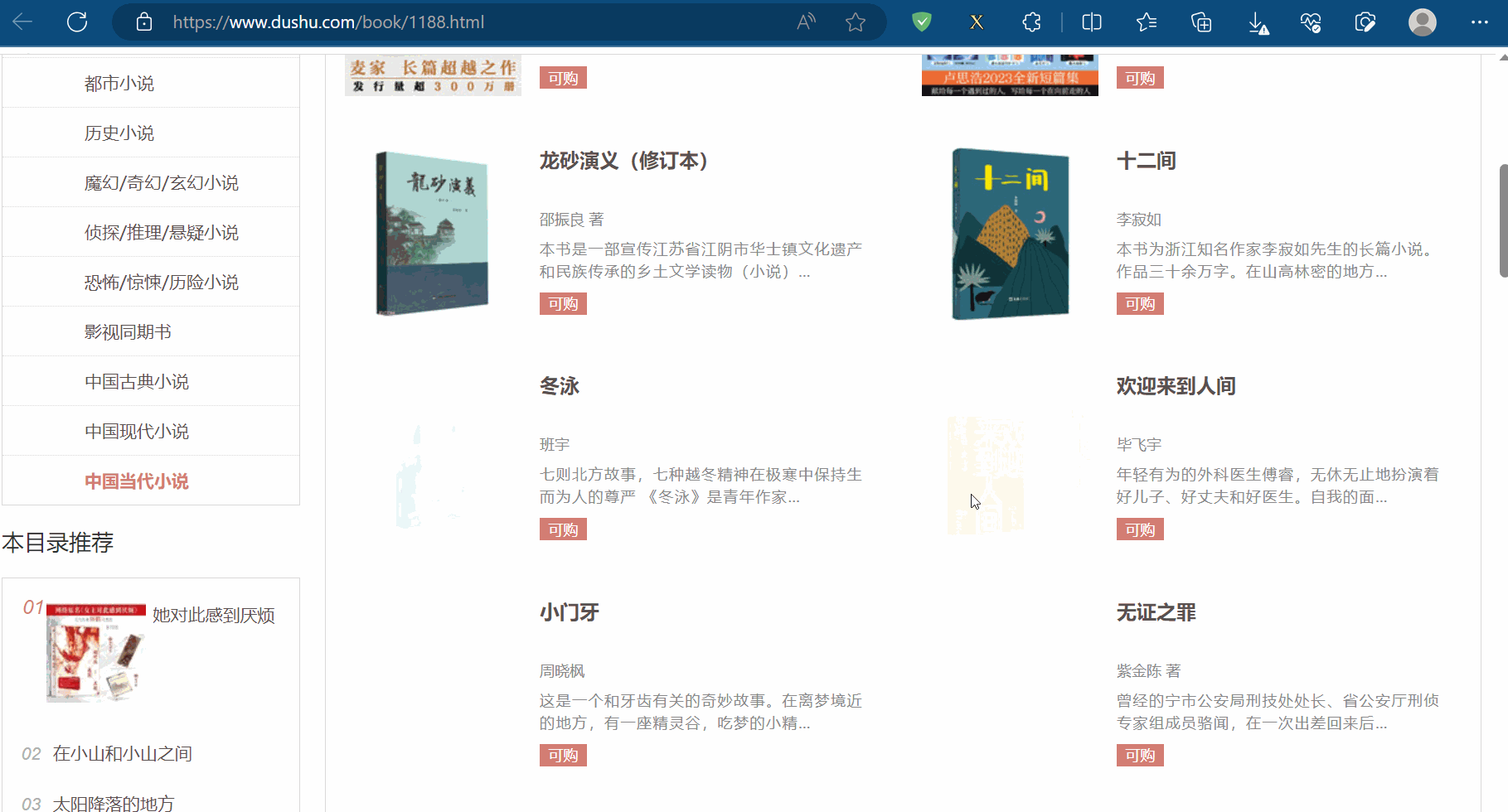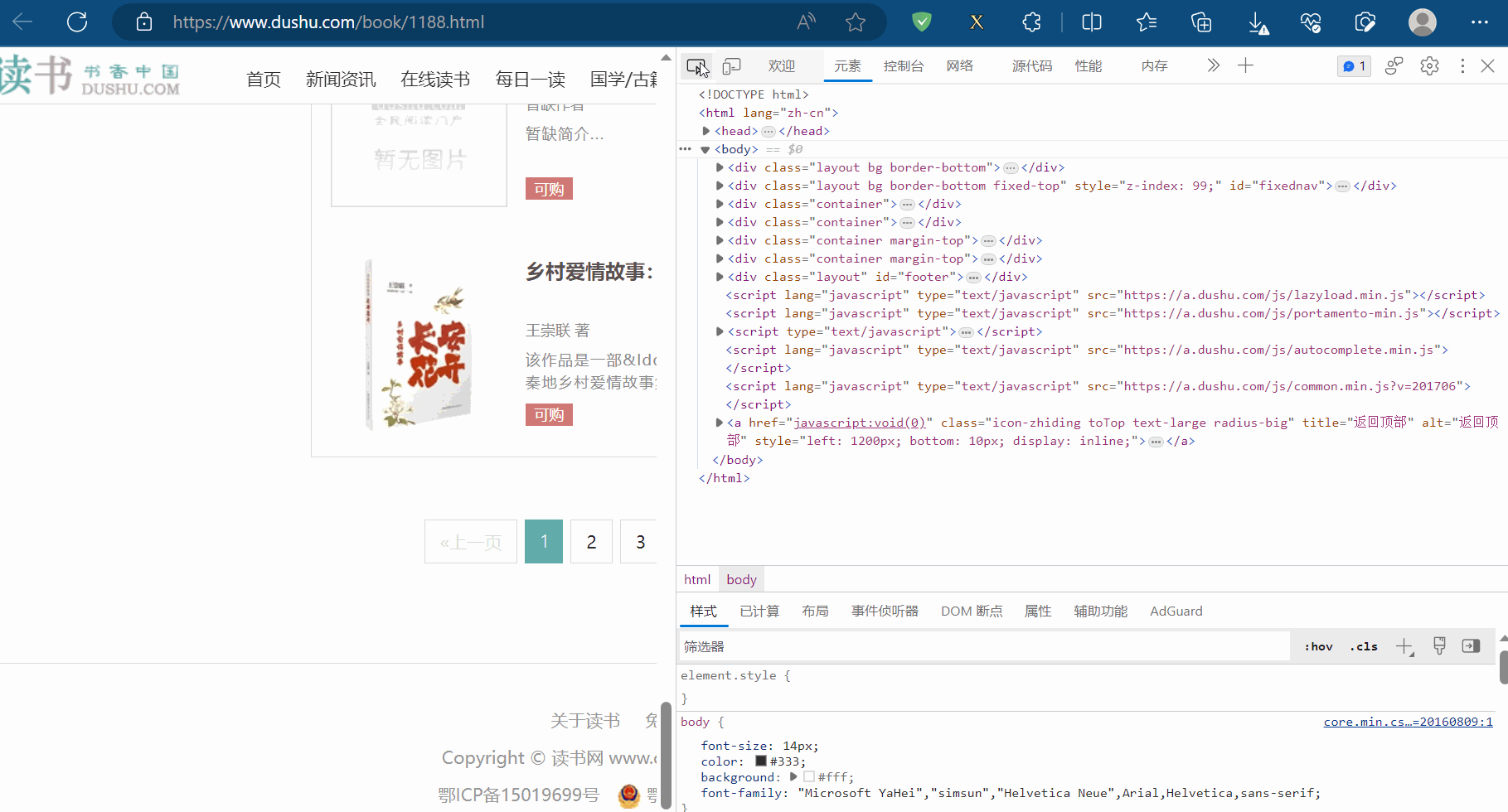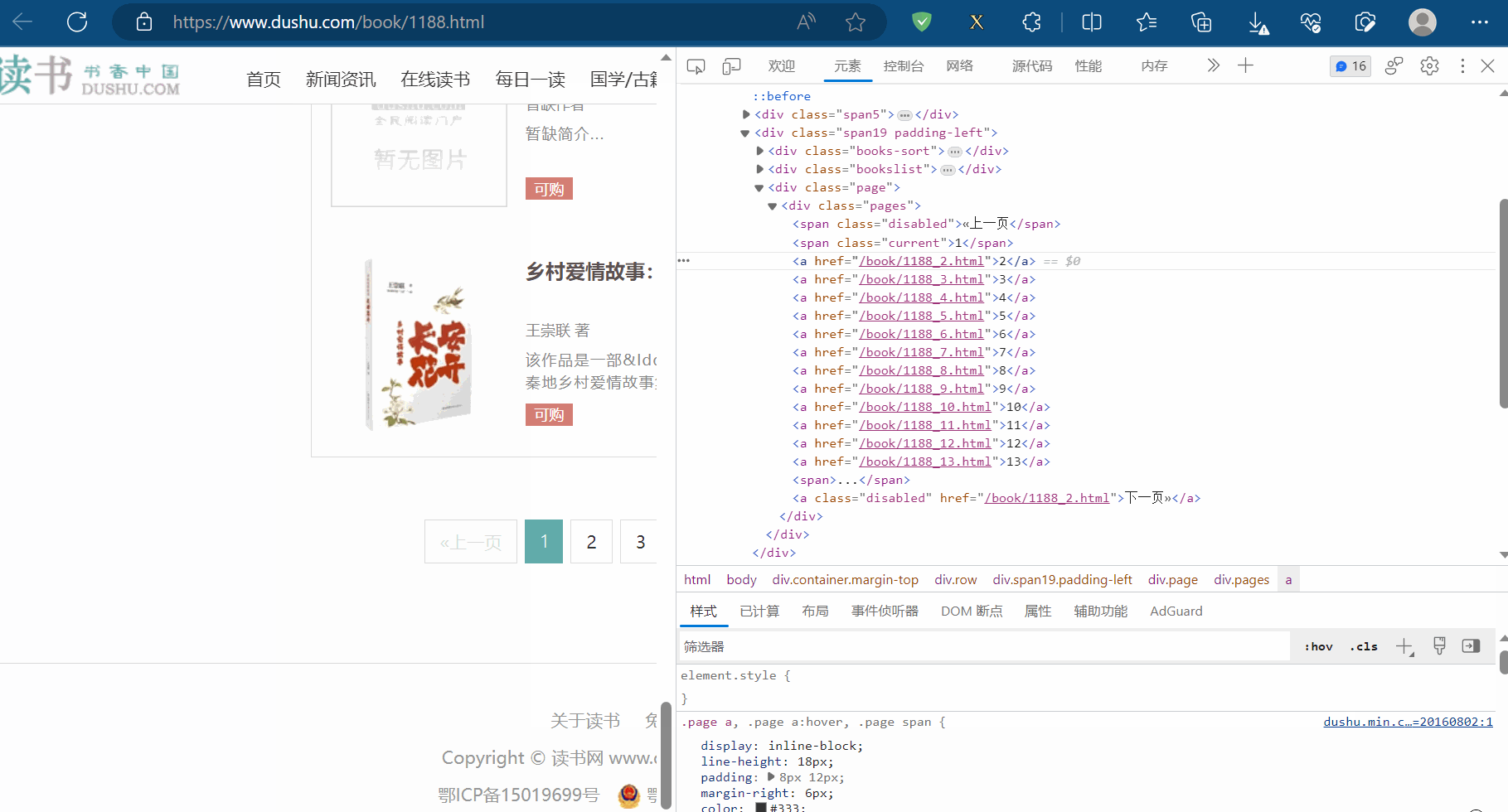
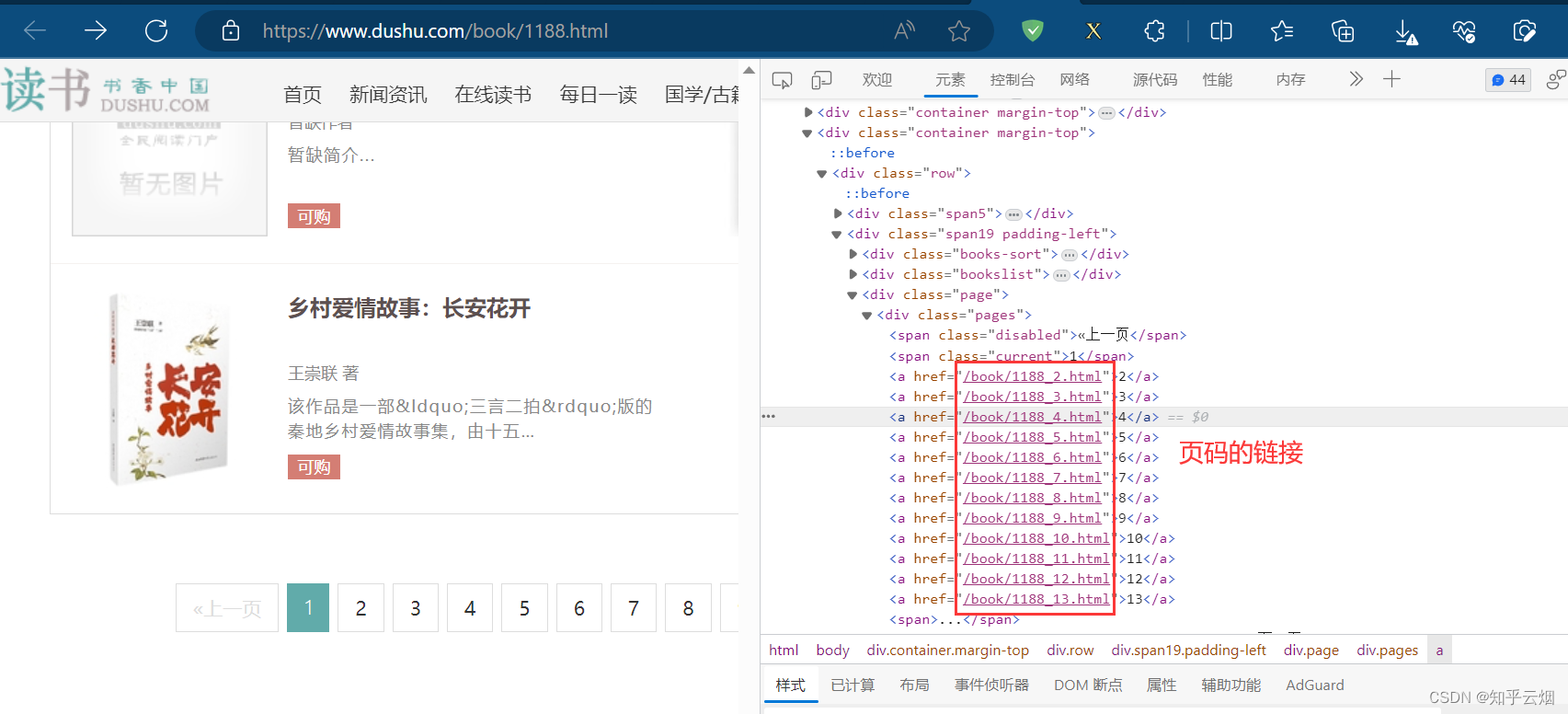

如下图所示,使用scrapy shell进入读书网的当代小说的第一页的页面,输入“from scrapy.linkextractors import LinkExtractor”导入链接提取器。

首先使用正则表达式提取页码的链接(“link = LinkExtrac-tor(allow=r’/book/1188_\d+.html’)”),“\d”表示一个数字,“\d+”表示可以有一到多个数字,然后打印一下验证正则表达式是否书写正确(“link.extract_links(response)”)。

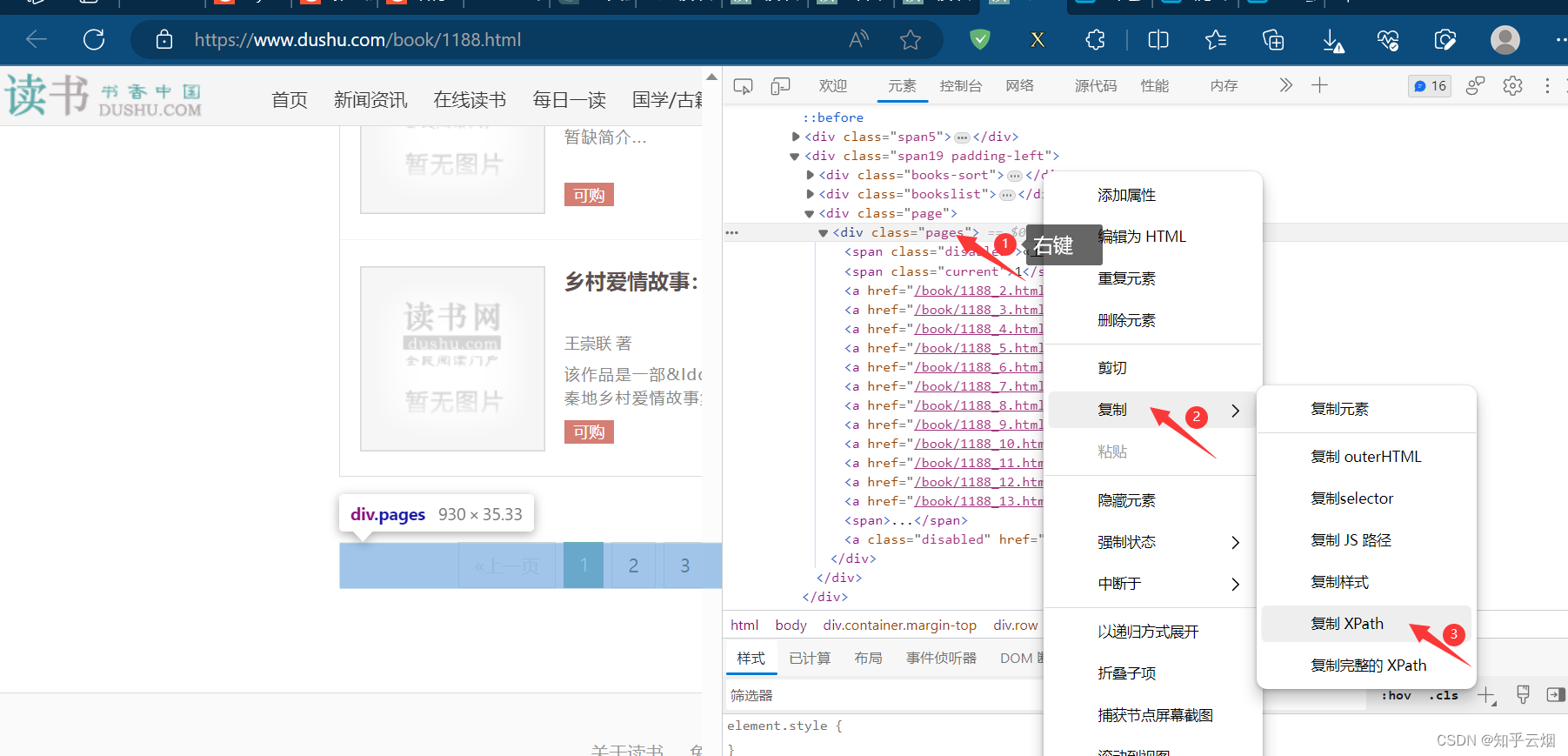
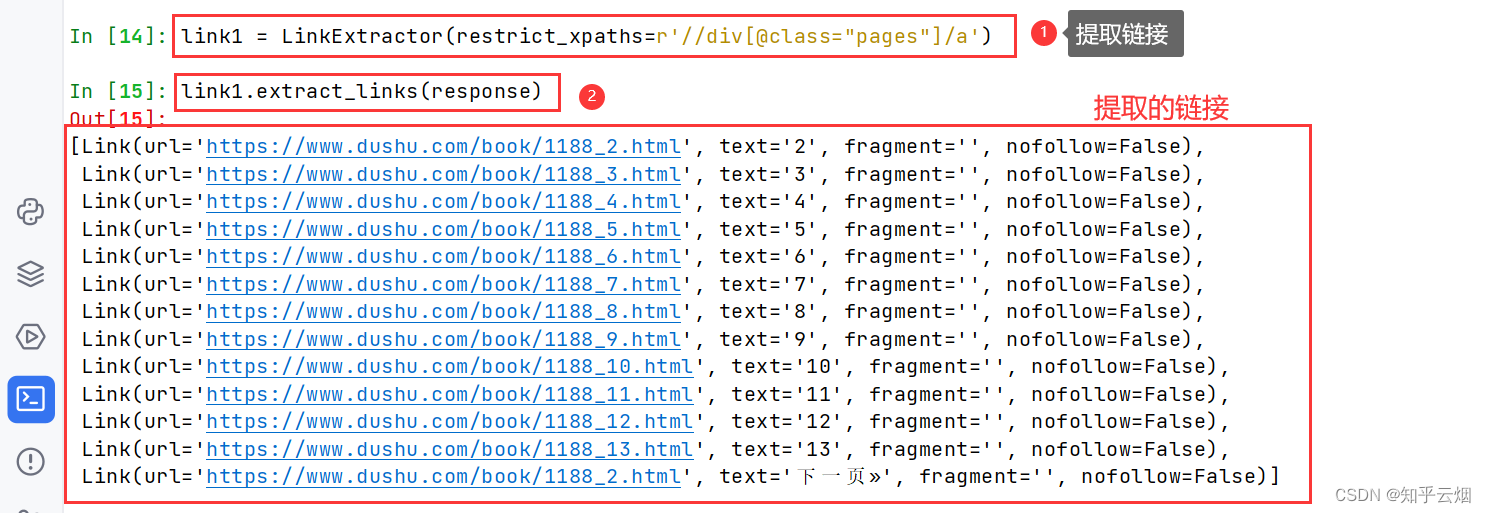
然后再使用xpath路径提取页码的链接(“link1 = LinkExtrac-tor(restrict_xpaths=r’//div[@class=“pages”]/a’)”,别加“@href”,否则提取不了),然后打印一下验证正则表达式是否书写正确(“link1.extract_links(response)”)。
12.scrapy_crawlspider读书网获取图片的封面地址和名字
紧跟着上一节,本节继续。
(1)CrawlSpider的使用步骤

(2)代码演示
本节紧接着上一节,使用CrawlSpider爬取读书网中当代小说的书名和书的封面的地址,下一节使用MySql、pymysql将数据放入数据库中。
首先,创建一个名为“scrapy_readbook_101”的项目(“scrapy startproject scrapy_readbook_101”)。
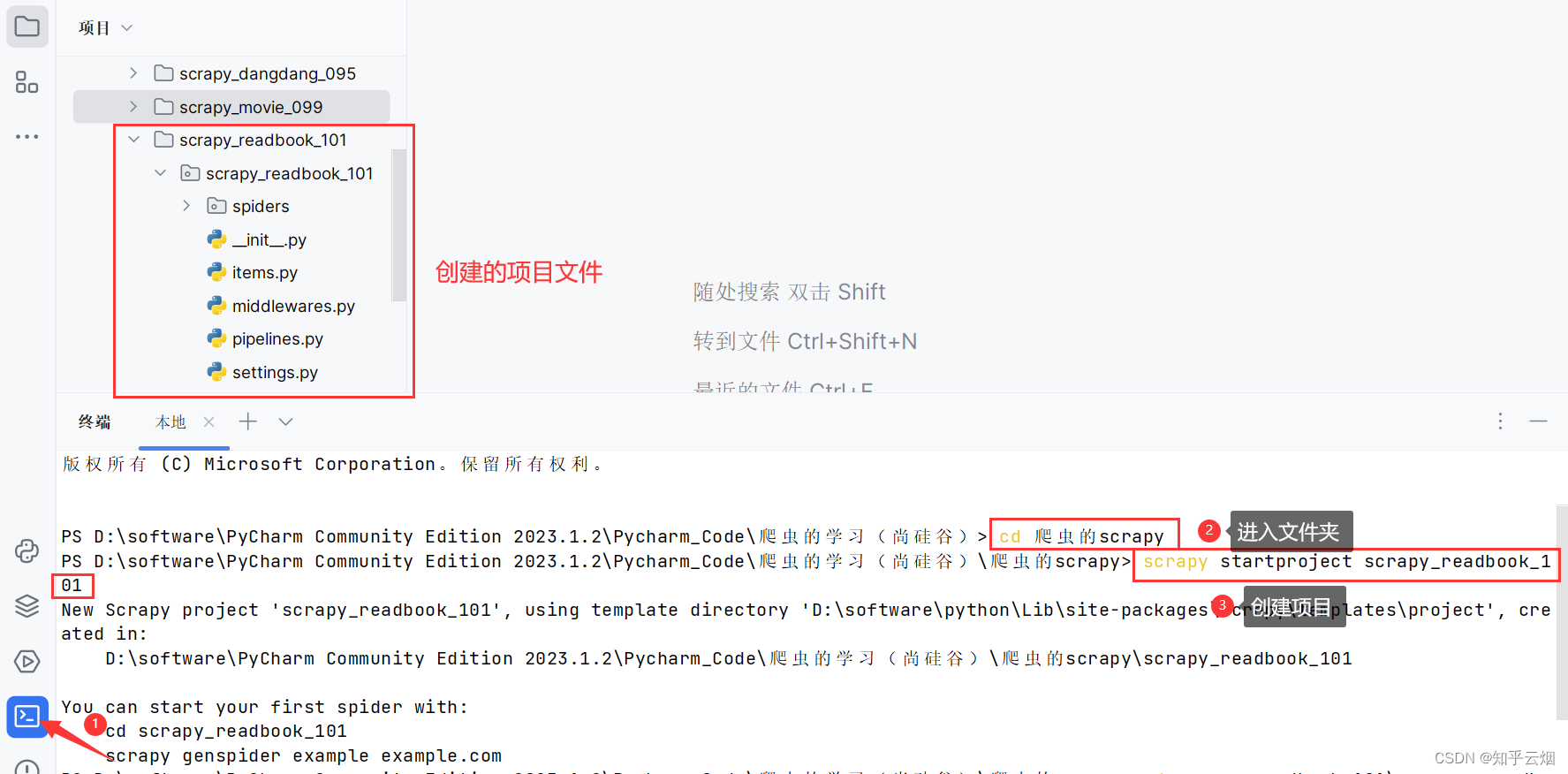
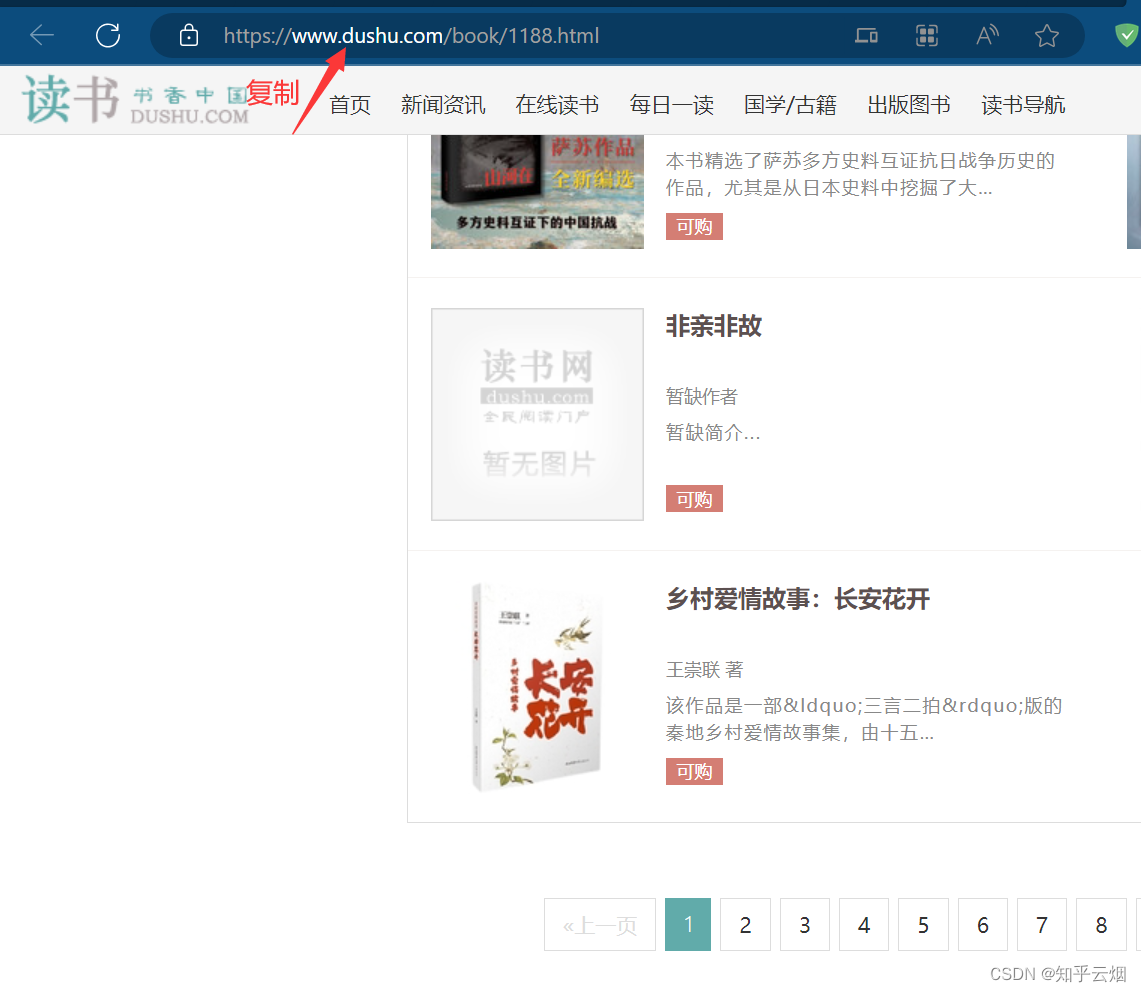
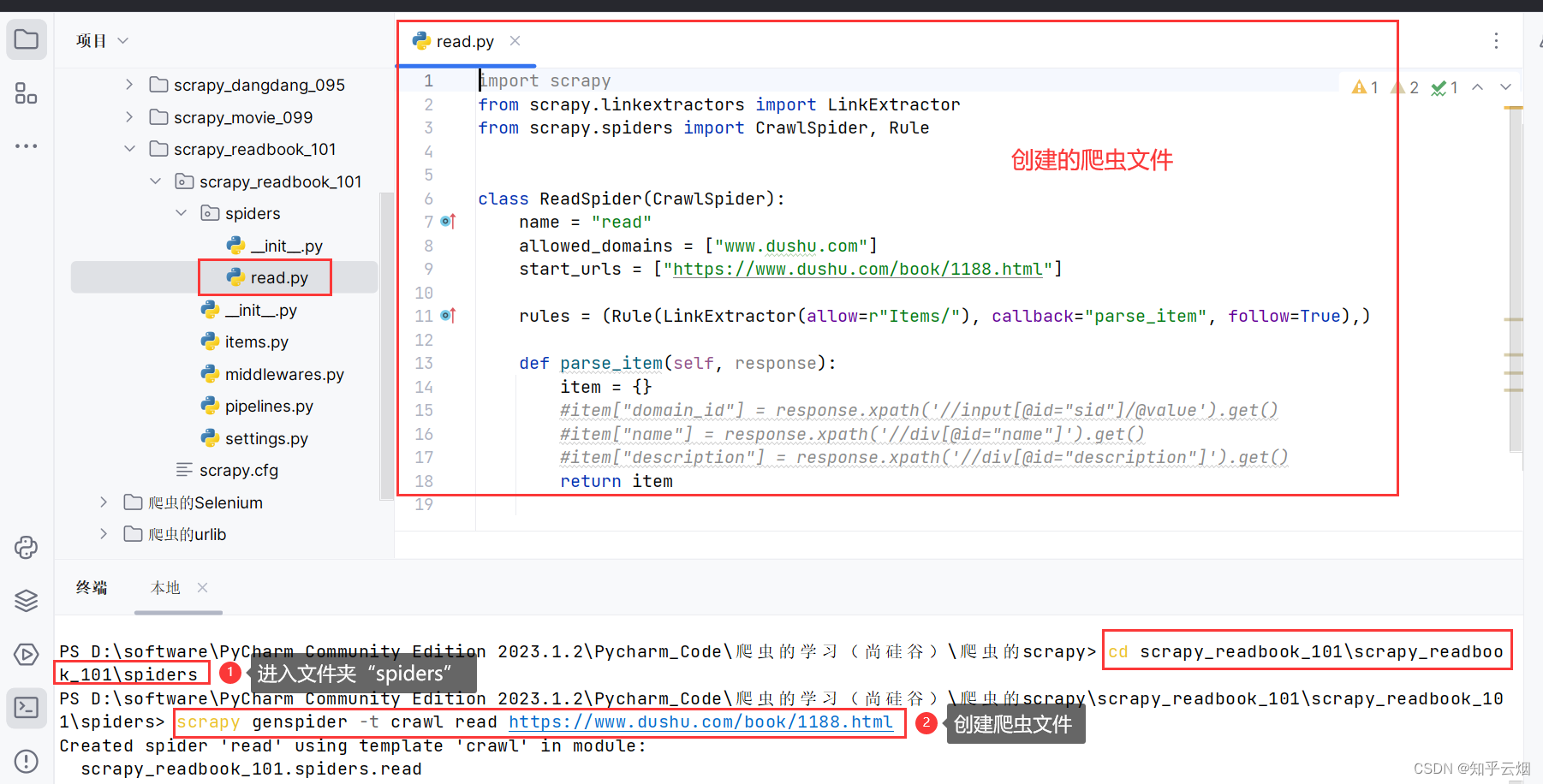
先去复制读书网当代小说第一页的地址,然后回到PyCharm终端,进入文件夹“spiders”(“cd scrapy_readbook_101\scrapy_readbook_101\spiders”),创建爬虫文件”read.py”(指令为“scrapy genspider -t crawl read 域名”,与之前创建的scrapy爬虫文件的指令有所不同)。
创建一个名为“test”的文件,用来记录本次案例的流程。
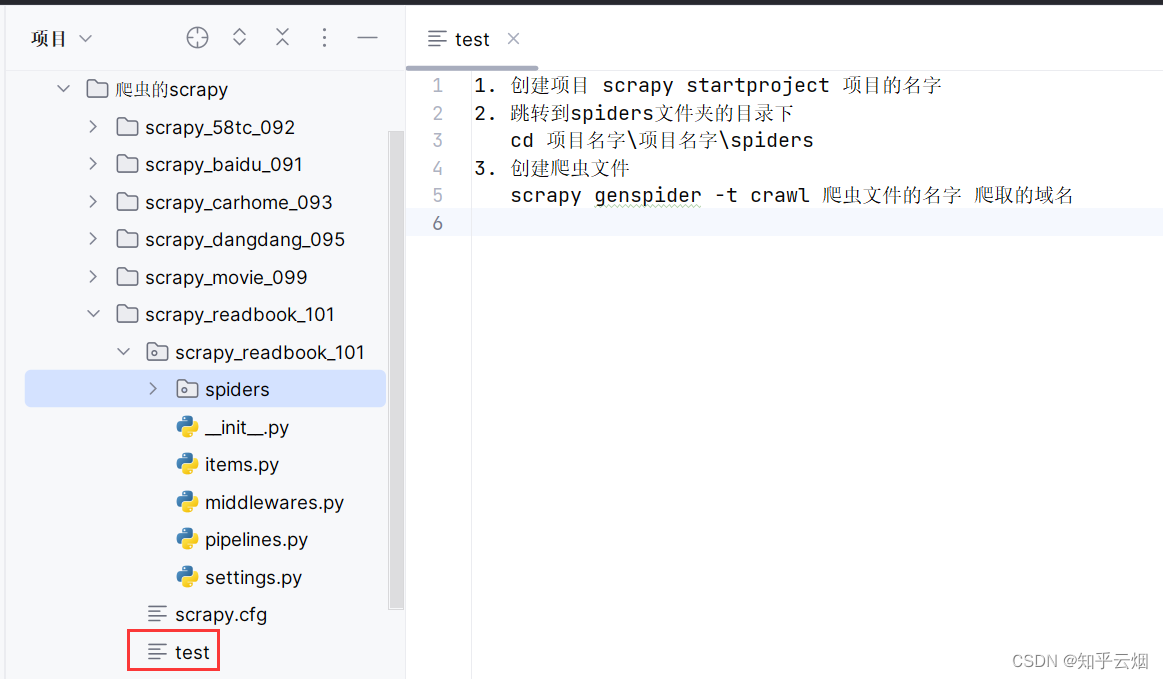
1. 创建项目 scrapy startproject 项目的名字
2. 跳转到spiders文件夹的目录下
cd 项目名字\项目名字\spiders
3. 创建爬虫文件
scrapy genspider -t crawl 爬虫文件的名字 爬取的域名
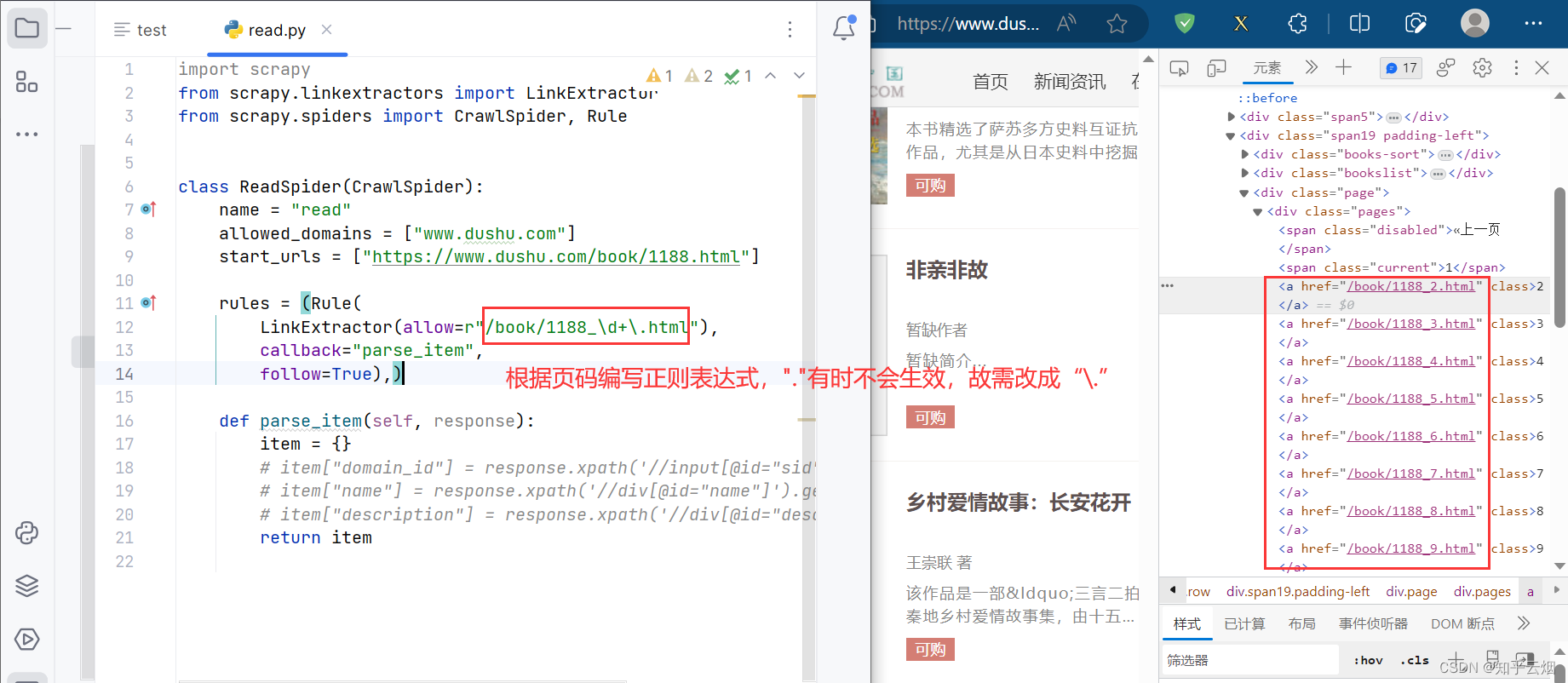
如下图,根据页码的链接的变化规律在代码相应的地方编写正则表达式(注:在正则表达式中,“.”是通配符,故特指点需要使用反斜杠来转义,即“.”)。
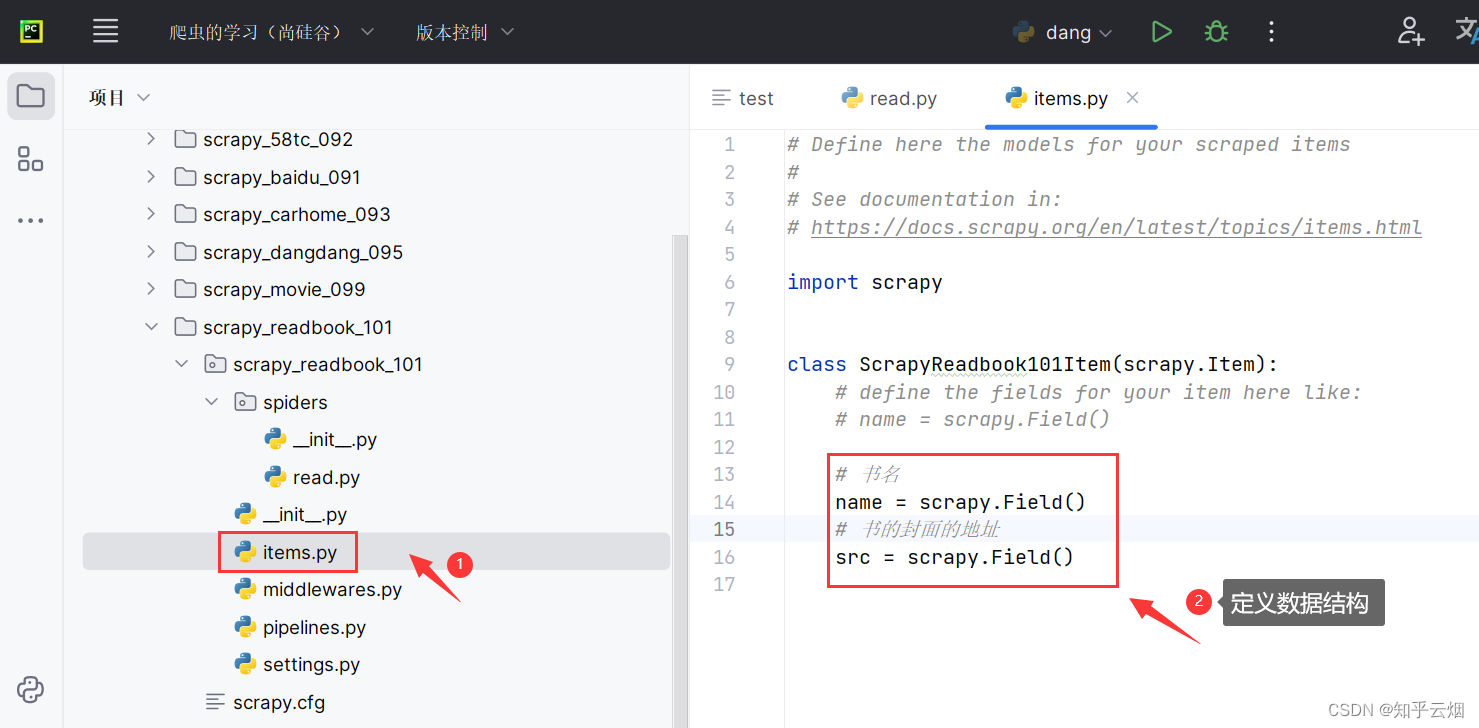
然后去“items.py”中定义本次下载的数据的结构。
# 书名
name = scrapy.Field()
# 书的封面的地址
src = scrapy.Field()
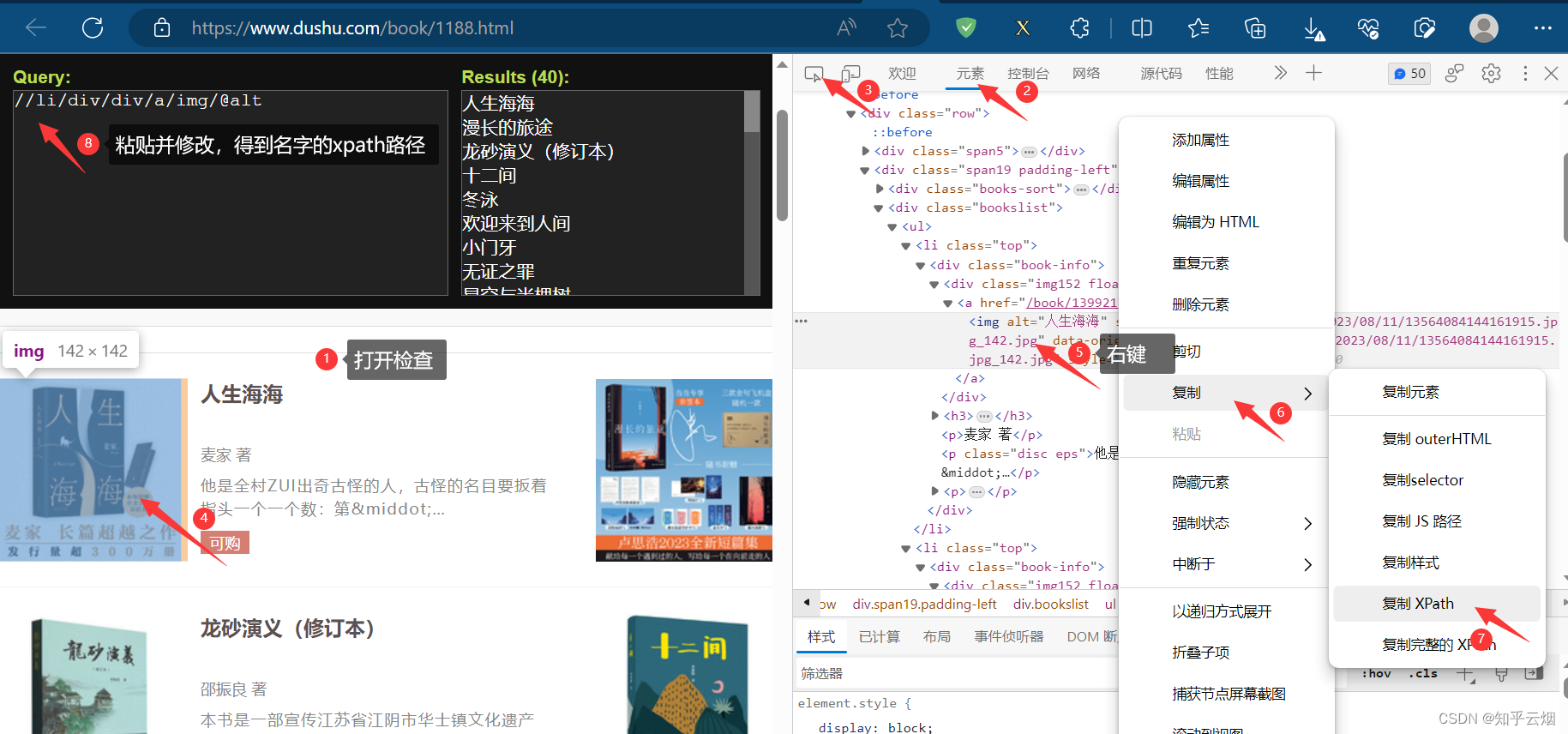
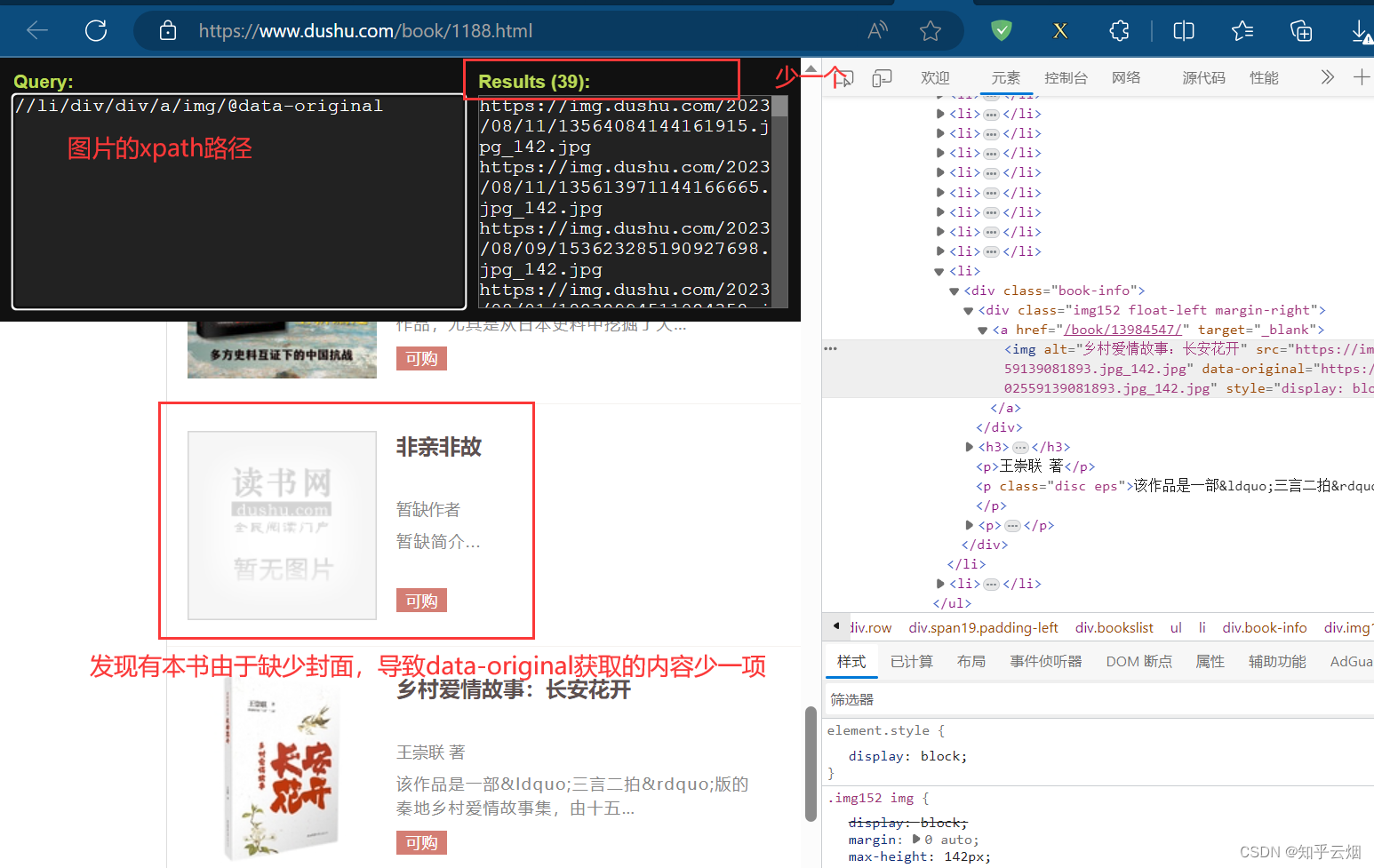
然后去寻找书名和封面地址的xpath路径,看到“data-original”就想到懒加载,即封面地址是属性“data-original”里的内容。发现有本书由于缺少封面,导致data-original获取的内容少一项,少的那一项需要通过属性src来获取标有读书网的图片的地址。
如下编写爬虫文件“read.py”的代码。
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import ScrapyReadbook101Item
class ReadSpider(CrawlSpider):
name = "read"
# 范围设大点,得包含其他页
allowed_domains = ["www.dushu.com"]
start_urls = ["https://www.dushu.com/book/1188.html"]
rules = (Rule(
LinkExtractor(allow=r"/book/1188_\d+\.html"),
callback="parse_item",
follow=False),)
def parse_item(self, response):
# 书名和封面的xpath路径
# //li/div/div/a/img/@alt
# //li/div/div/a/img/@data-original
# 发现有本书由于缺少封面,导致data-original获取的内容少一项,
# 少的那一项需要通过属性src来获取标有读书网的图片的地址。
img_list = response.xpath('//li/div/div/a/img')
for img in img_list:
name = img.xpath('./@alt').extract_first()
src = img.xpath('./@data-original').extract_first()
if not src:
src = img.xpath('./@src').extract_first()
# print(name, src) # 测试代码,验证是否拿到书名和封面链接
book = ScrapyReadbook101Item(name=name, src=src)
yield book
如下去文件“pipelines.py”封装管道。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ScrapyReadbook101Pipeline:
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='UTF-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
去文件“setting.py”中打开管道。
运行代码,发现数据不够。
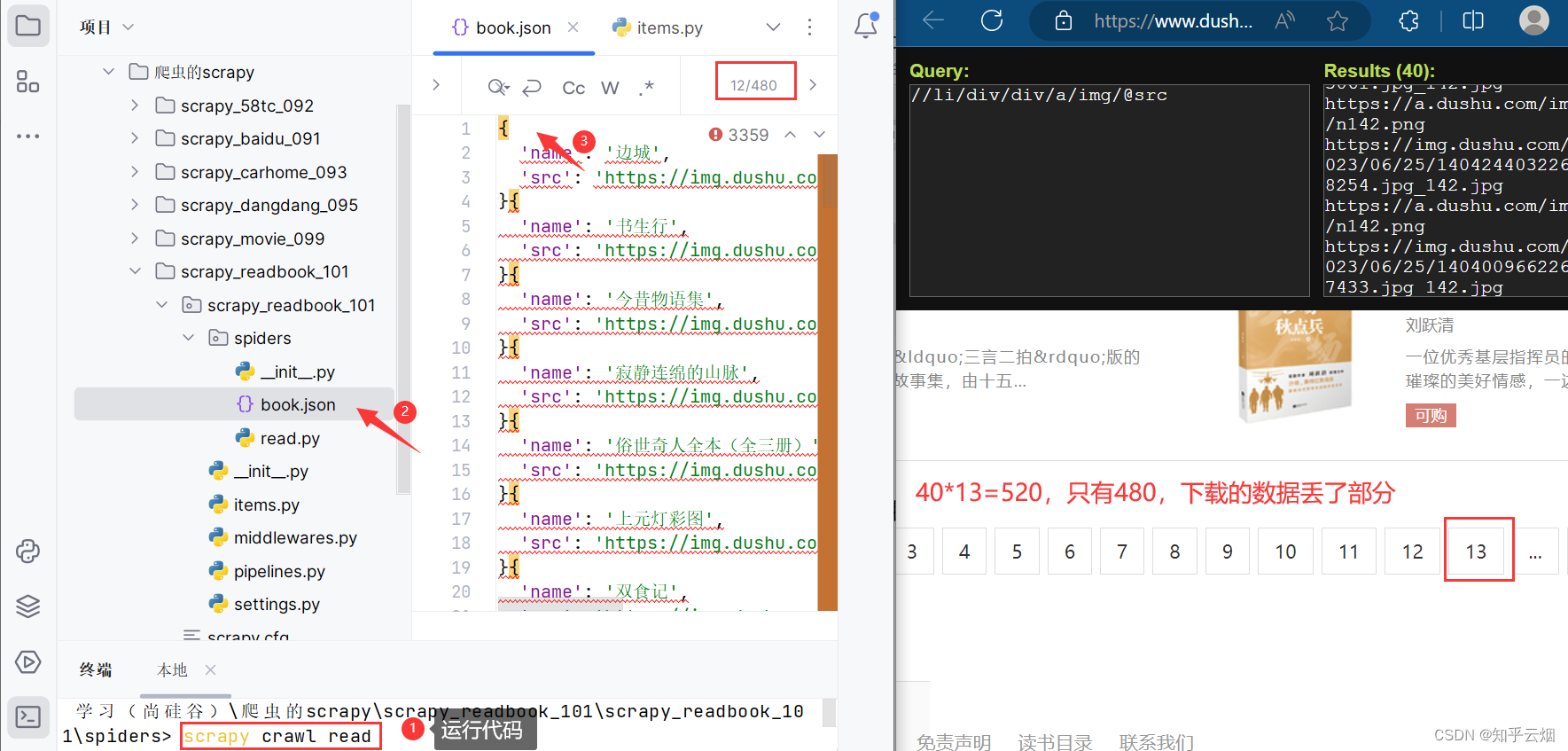
由于520-480=40,猜测少了一页数据。注意此处有一个坑,首页并不在我们所设的正则表达式的规则里。
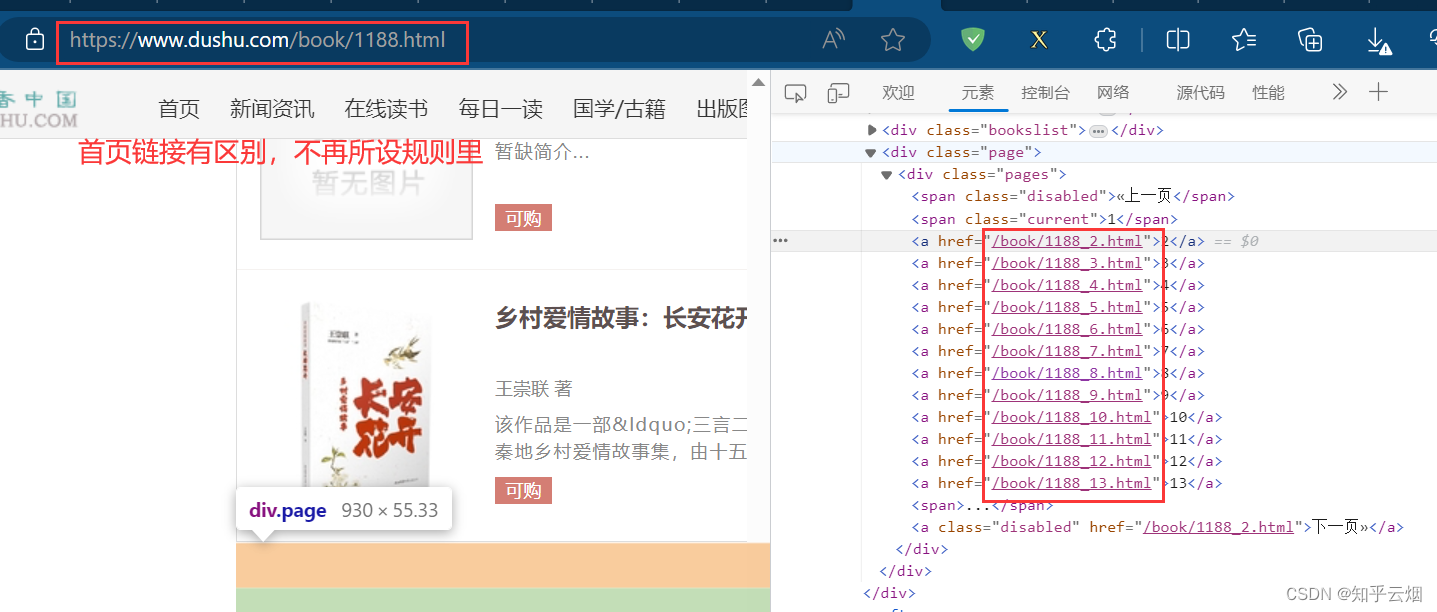
尝试将链接“https://www.dushu.com/book/1188.html”改成“https://www.dushu.com/book/1188_1.html”后发现这还是第一页,故去修改“read.py”的起始链接,然后再运行(“scrapy crawl read”),去文件“book.json”发现数据不再缺少。
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import ScrapyReadbook101Item
class ReadSpider(CrawlSpider):
name = "read"
# 范围设大点,得包含其他页
allowed_domains = ["www.dushu.com"]
start_urls = ["https://www.dushu.com/book/1188_1.html"]
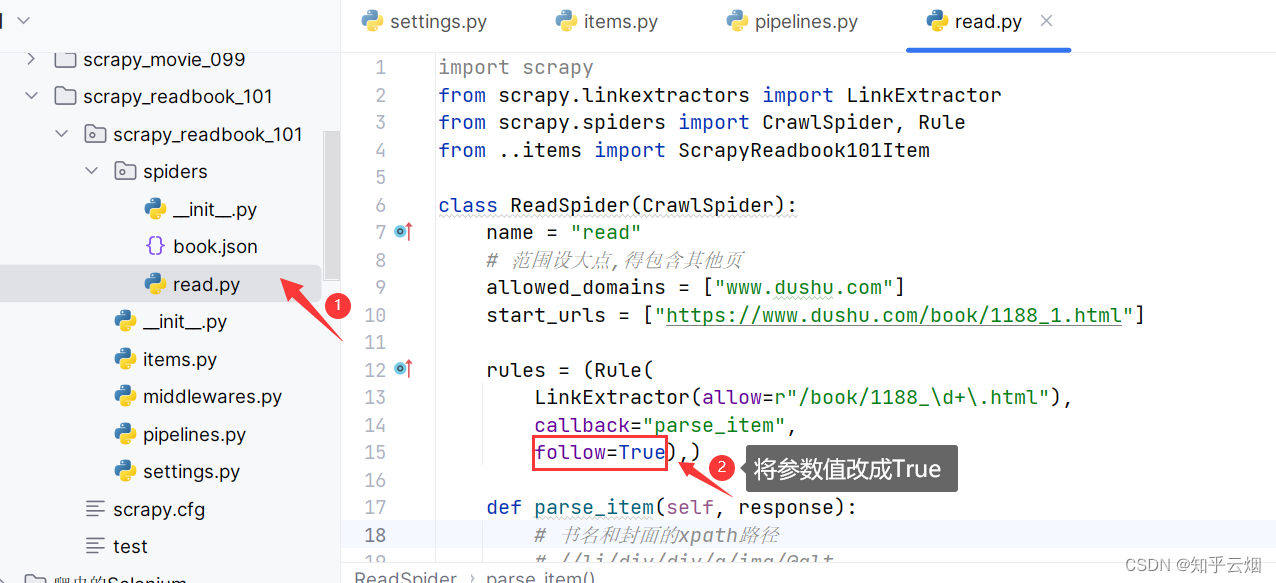
rules = (Rule(
LinkExtractor(allow=r"/book/1188_\d+\.html"),
callback="parse_item",
follow=False),)
def parse_item(self, response):
# 书名和封面的xpath路径
# //li/div/div/a/img/@alt
# //li/div/div/a/img/@data-original
# 发现有本书由于缺少封面,导致data-original获取的内容少一项,
# 少的那一项需要通过属性src来获取标有读书网的图片的地址。
img_list = response.xpath('//li/div/div/a/img')
for img in img_list:
name = img.xpath('./@alt').extract_first()
src = img.xpath('./@data-original').extract_first()
if not src:
src = img.xpath('./@src').extract_first()
# print(name, src) # 测试代码,验证是否拿到书名和封面链接
book = ScrapyReadbook101Item(name=name, src=src)
yield book
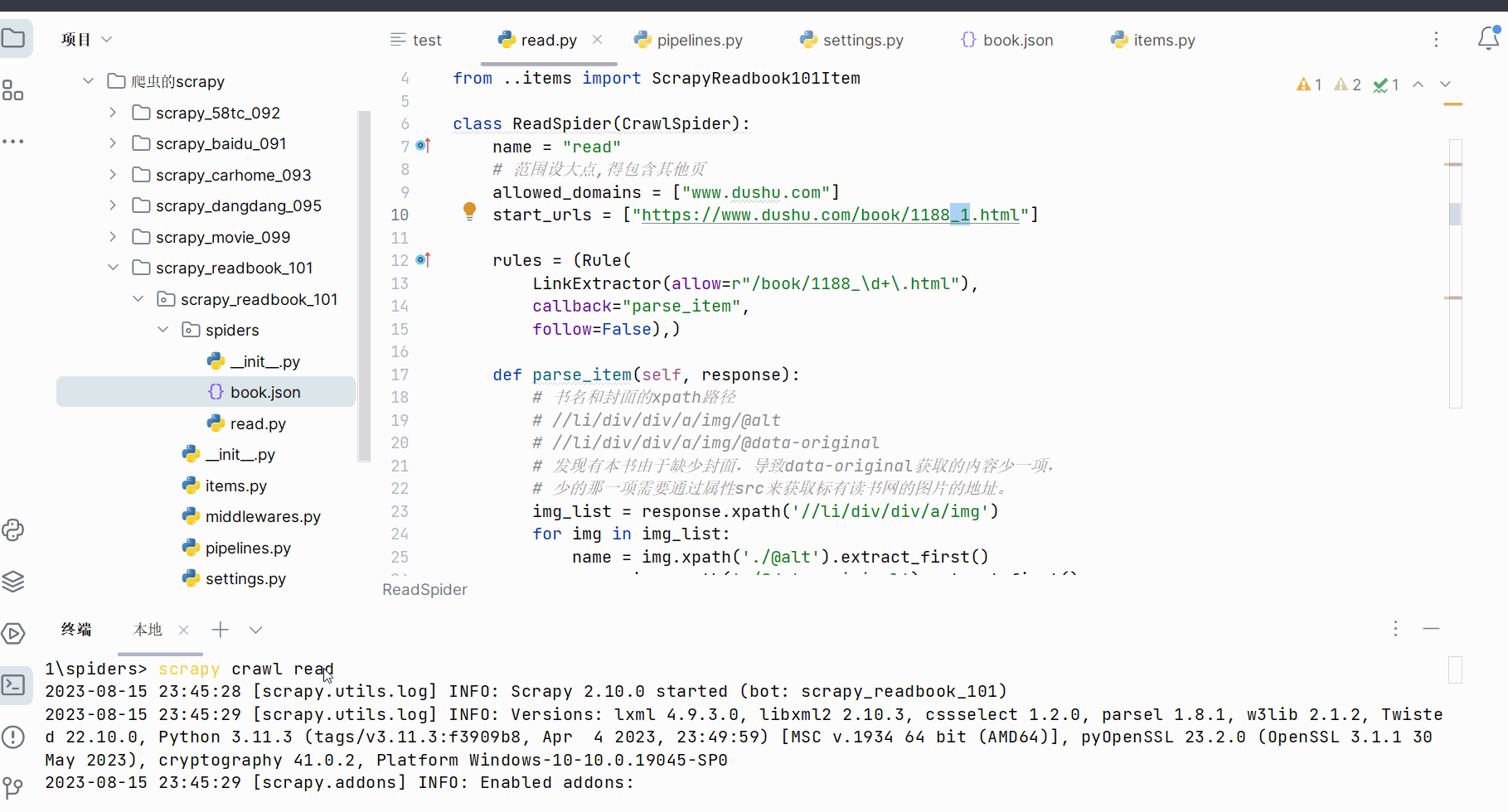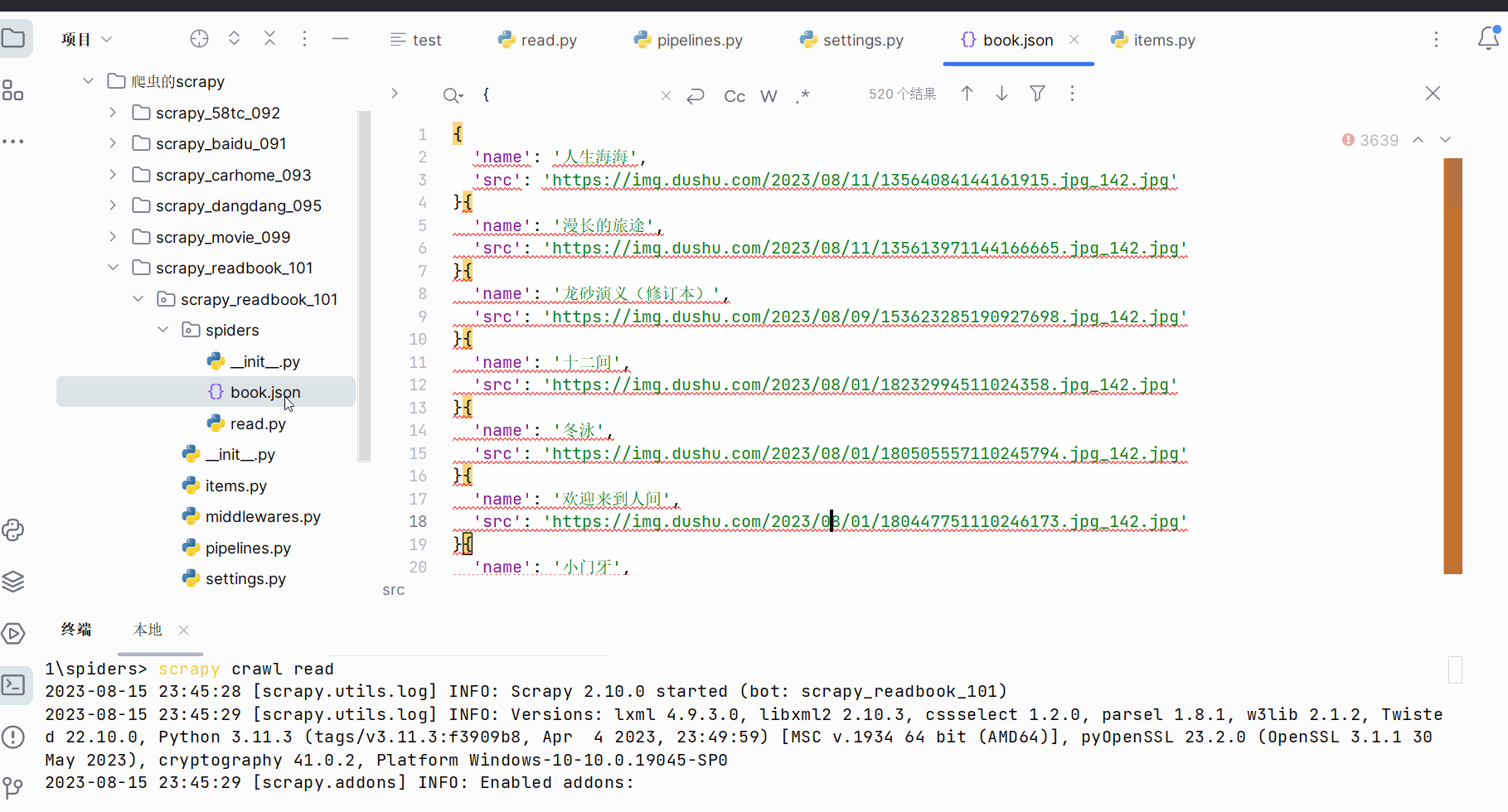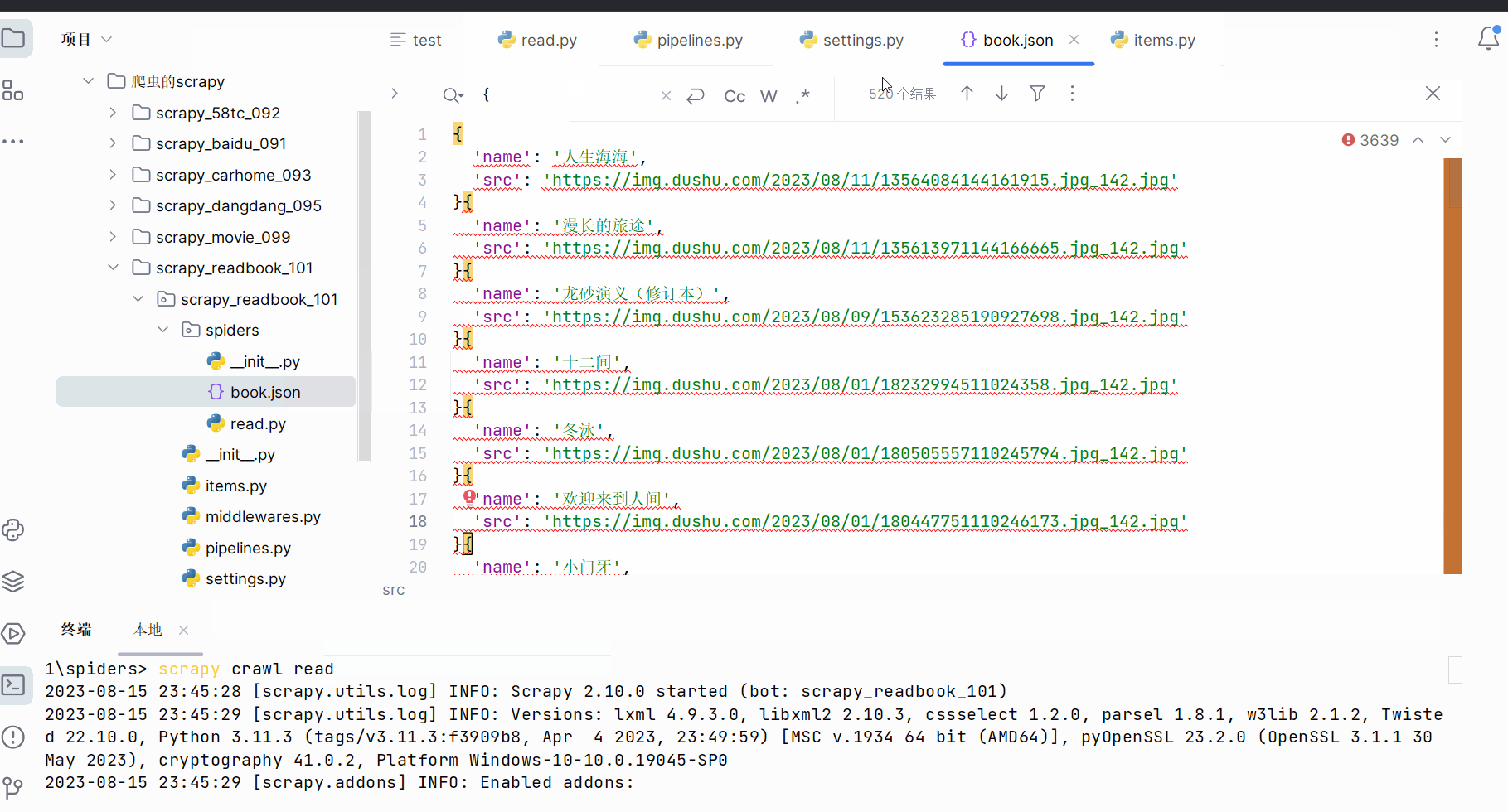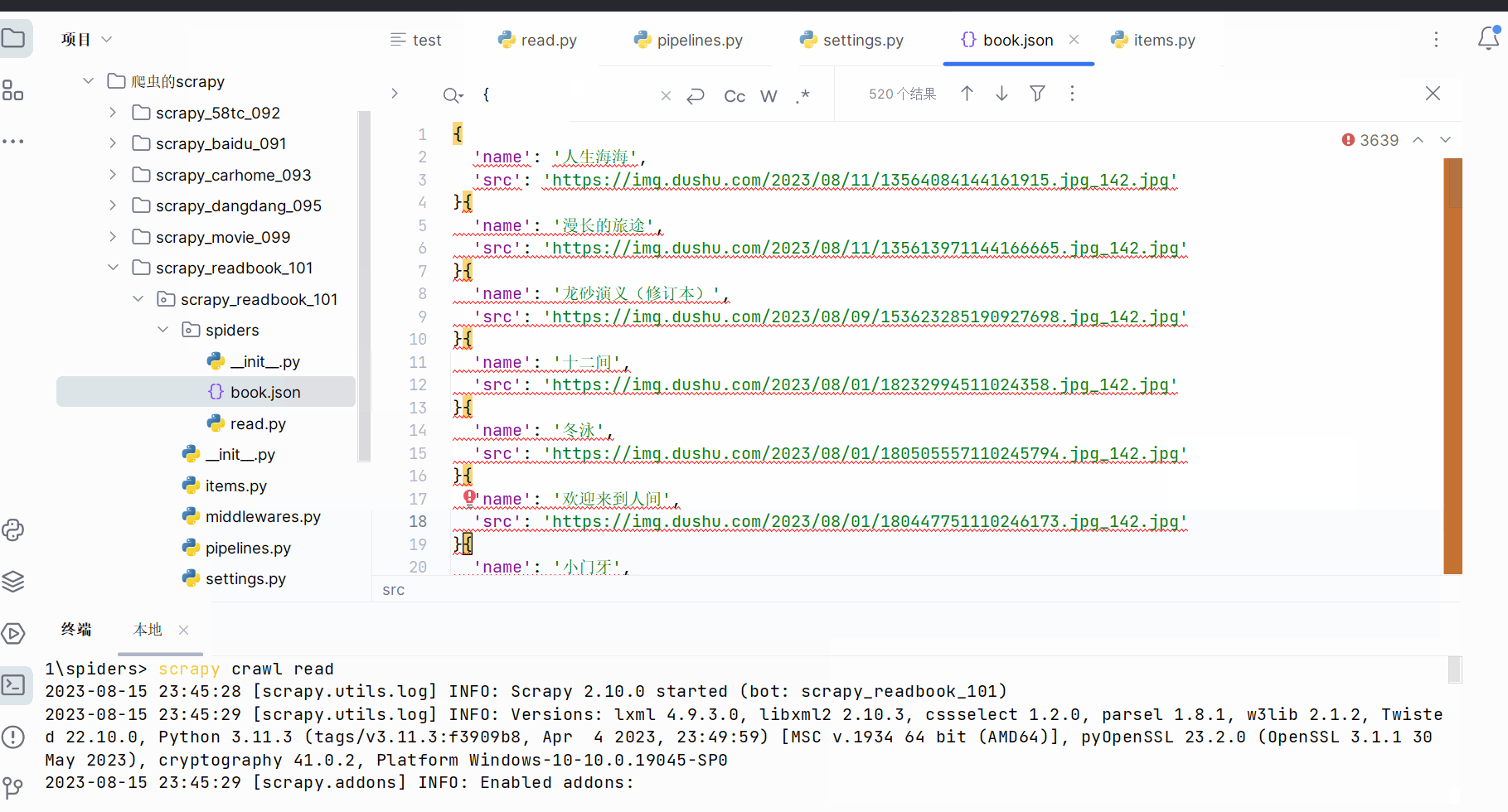
13.scrapy_读书网数据入库和链接跟进(失败,卡在最后的“由于日标计算机积极拒绝”,没有系统学过MySQL,卡住了)
紧跟着上一节,本节继续。接下来我们需要将爬取的数据存储到数据库中。为了模拟干活时使用的数据库,本次使用了VMware上的虚拟机Ubuntu。
(1)准备工作(安装Ubuntu、在Ubuntu上安装mysql中途含出现的两个问题的解决办法、Windows上安装pymysql)
安装带有Ubuntu的VMware虚拟机,而且Ubuntu中还需要安装mysql,在Windows上安装pymysql。
至于如何安装VMware、如何在VMware上安装Ubuntu,请参考本人的笔记“第一章 初识Linux(含VMware安装Ubuntu、CentOS、Windows、快照)”进行安装。
至于MySql的使用方法,对与初级使用而言,本人的CSDN笔记足以应对:第二阶段-第二章 SQL入门和实战。
至于如何在Ubuntu上安装mysql,本人参考如下连接进行安装的:Ubuntu下安装MySQL数据库,具体步骤如下:
在FinalShell(直接在VMware中的Ubuntu界面也是一样)输入命令更新一下软件包,然后安装MySQL数据库。(视频里能正常安装,本人的却出现了问题)
sudo apt update # 更新软件包
sudo apt install mysql-server # 安装MySQL数据库
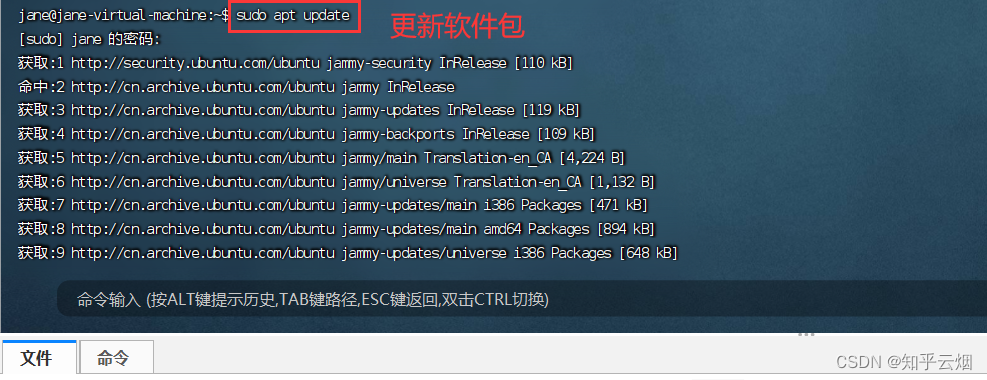
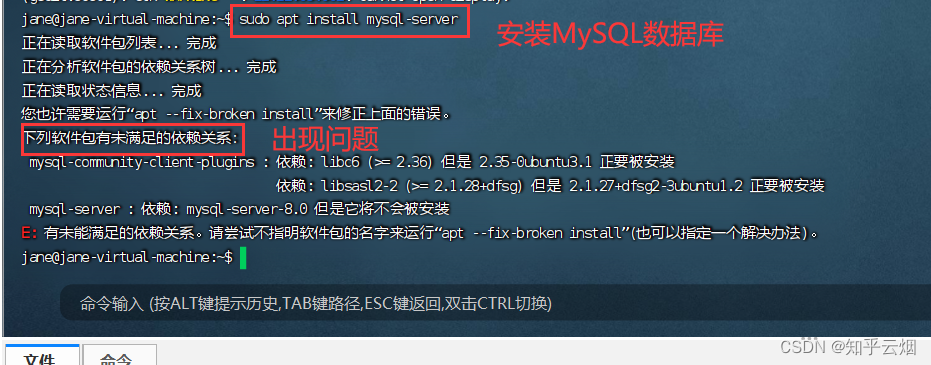
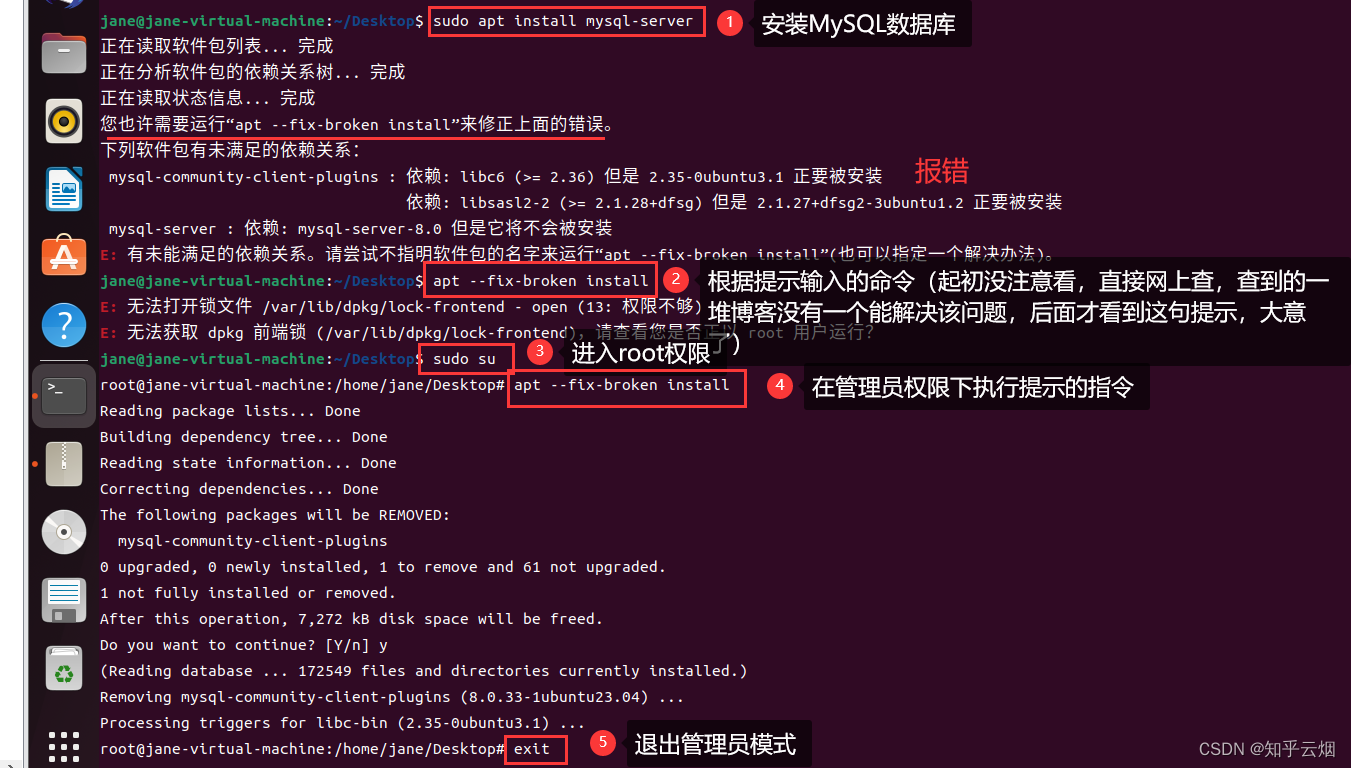
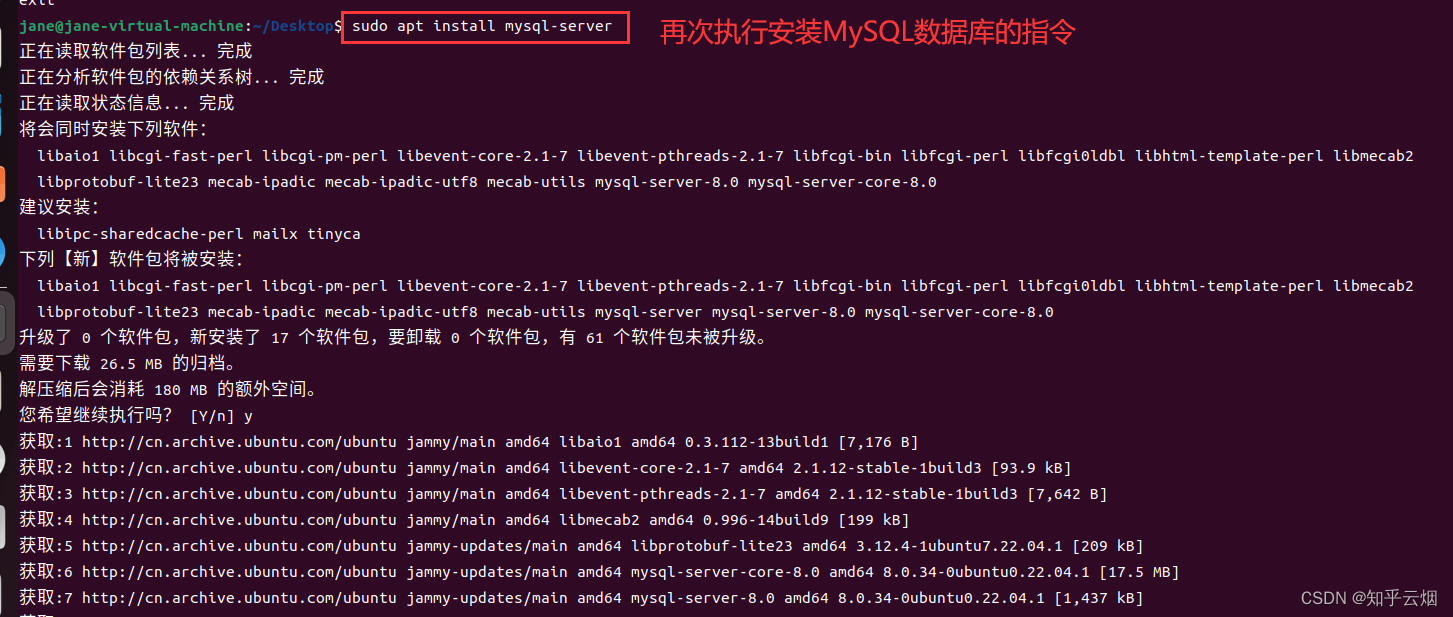
然后如下图所示,输入一堆命令后成功解决该问题。(这个报错需要根据提示解决。起初没注意看,直接网上查,查到的一堆博客没有一个能解决该问题,后面才看到这句提示,大意了)
sudo apt install mysql-server # 安装MySQL数据库
apt --fix-broken install
sudo su # 进入管理员模式
exit # 如果在root状态,退出管理员模式
然后就是配置安全设置。
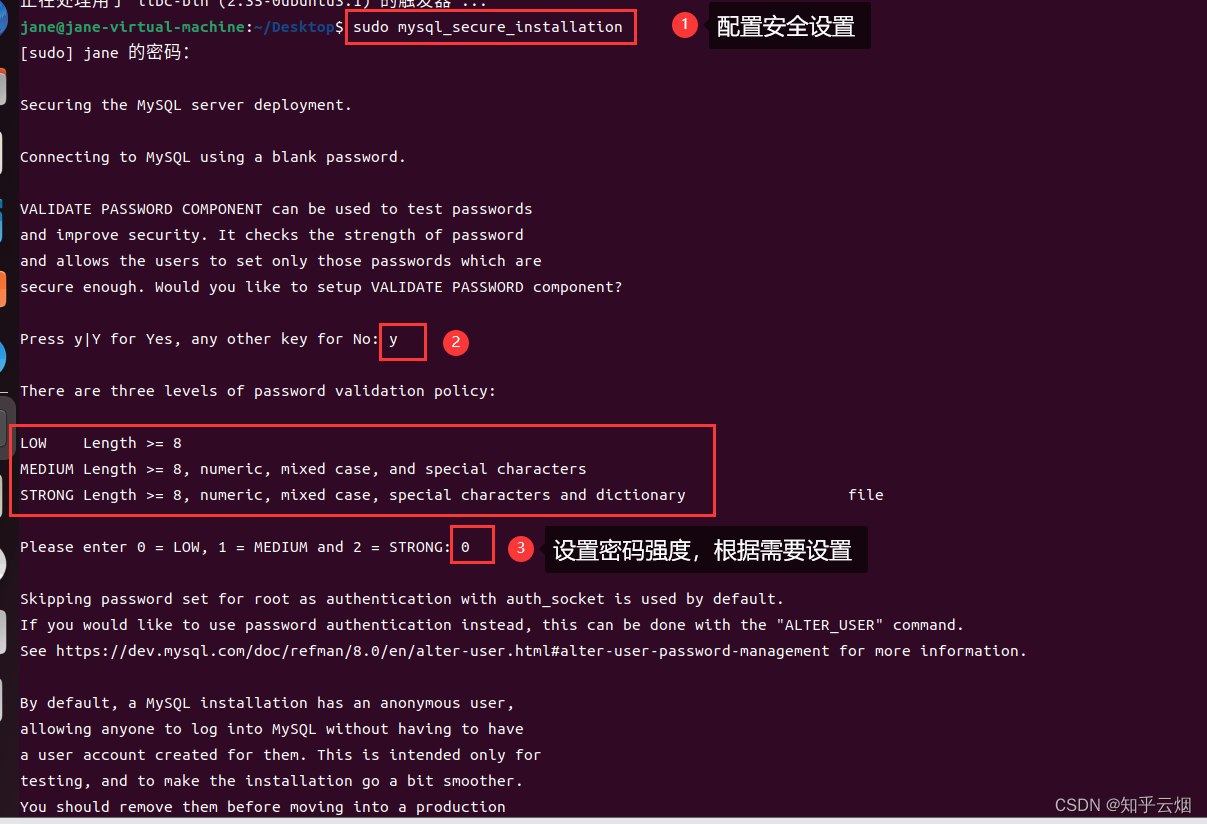
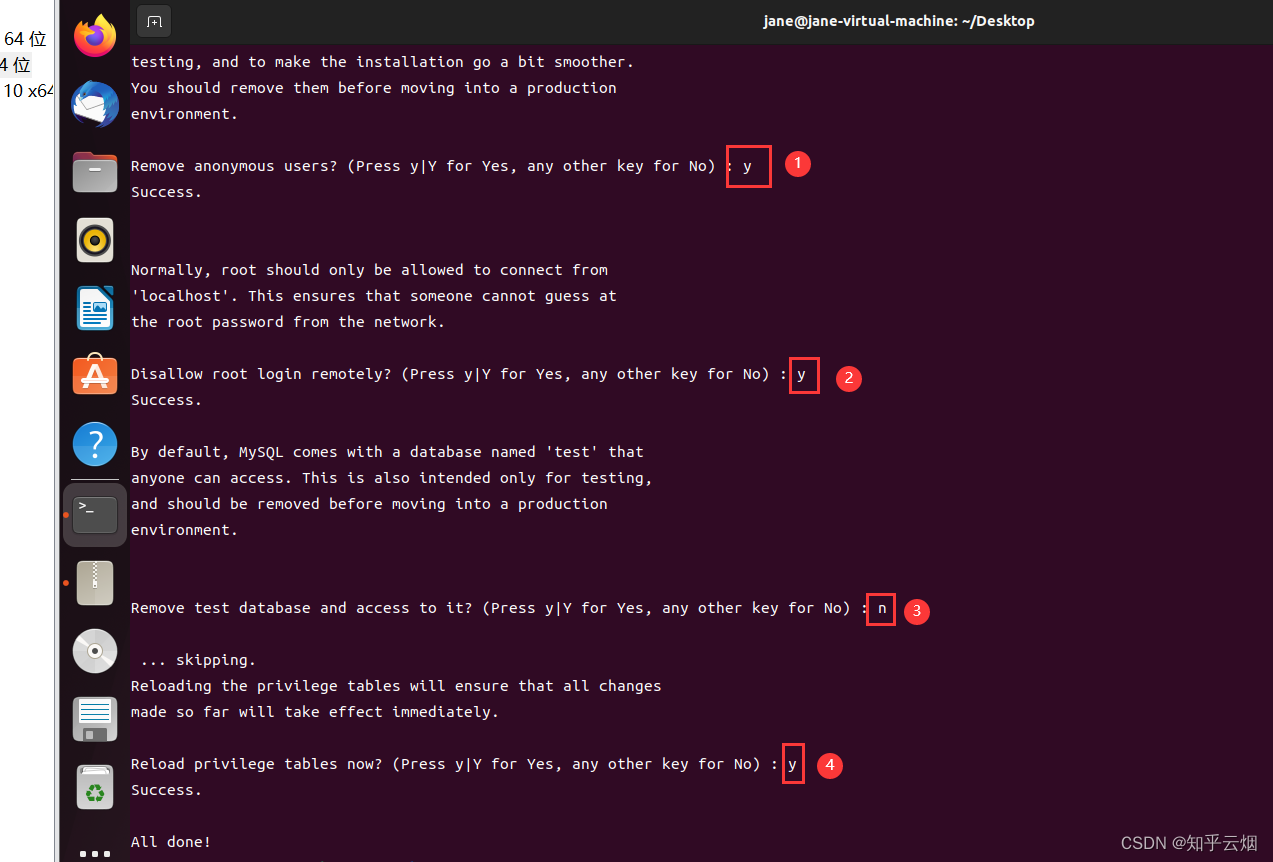
sudo mysql_secure_installation # 配置安全设置
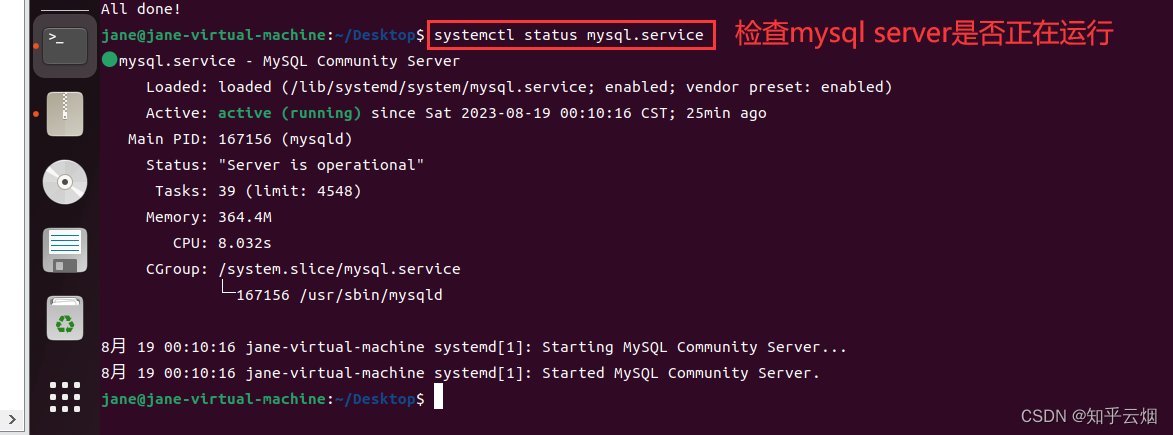
然后检查mysql server是否正在运行(如果出现“lines 1-14/14 (END”,需按Ctr+C结束)。
systemctl status mysql.service # 检查mysql server是否正在运行
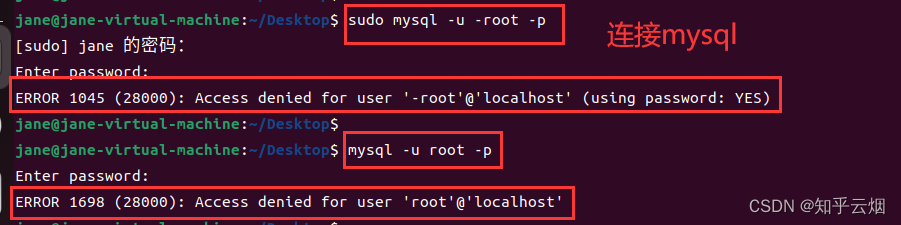
连接mysql时报错“ERROR 1045 (28000): Access denied for user ‘-root’@‘localhost’ (using password: YES)”或者“ERROR 1698 (28000): Access denied for user ‘root’@‘localhost’”,找了半天终于按照链接mysqlERROR1698(28000):Access denied for user root@localhost错误解决方法中的STEP1成功解决问题,如下一堆图所示。到此,Ubuntu上已经成功安装pymysql。
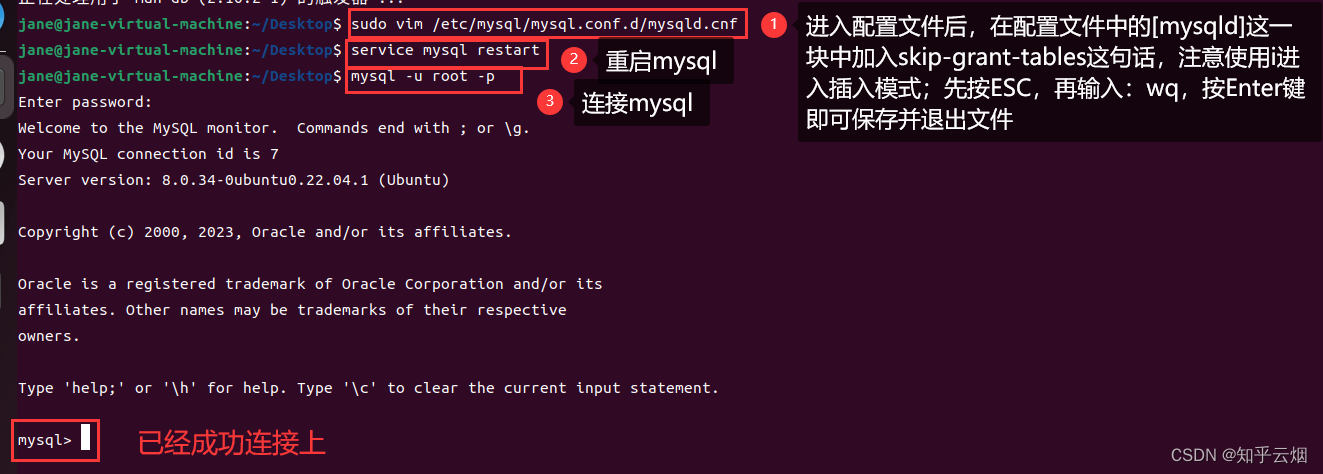
sudo mysql -u -root -p # 连接mysql,sudo是使用root权限的意思,下图中有一处没加sudo一样可以连接mysql
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf # 编辑文件
service mysql restart # 重启mysql
show schemas; # 在mysql里输入表示查询自带的数据库
exit # 在mysql里输入表示退出mysql
至于如何在Windows上安装pymysql,如下图所示,打开命令提示符,然后输入一堆指令完成安装(本人之前装过,就直接截的视频的图)。
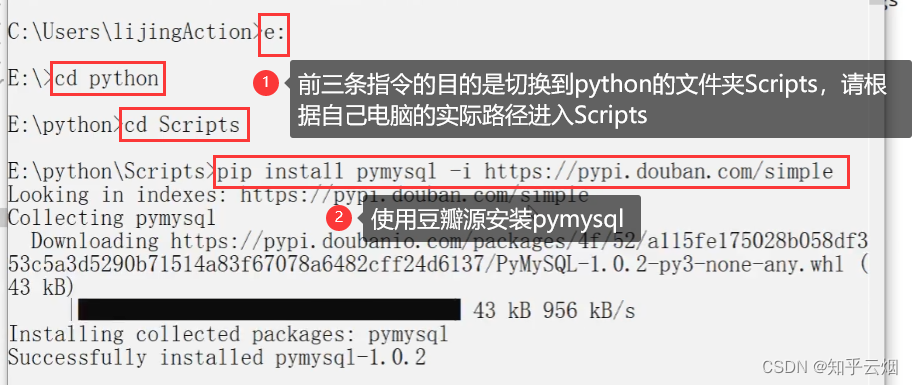
cd python的安装目录/Scripts # 进入python的库文件夹
pip install pymysql # 安装库pymysql 如果安装太慢,在该条指令后面加上“-i 镜像源的网址”
(2)pymysql的使用步骤
# 具体如何使用请看演示
pip install pymysql # 安装pymysql
self.conn=pymysql.connect(host, port, user, password, db, charset) # 连接mysql
self.cursor=self.conn.cursor()
cursor.execute() # 执行mysql代码
(3)本次的演示(失败,卡在最后的“由于日标计算机积极拒绝”)
本次需要使用Ubuntu去数据库中创建一个和上一节爬取到的数据的结构一样的表,然后将爬取的数据插入表中。
双击打开VMware,然后选择Ubuntu进行登录。

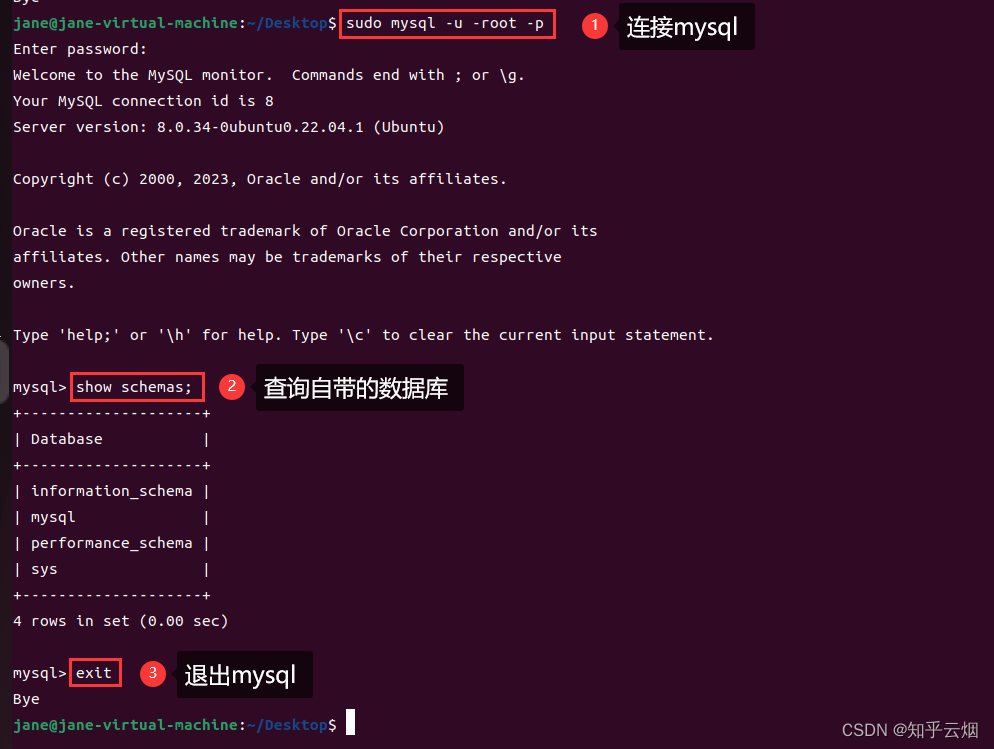
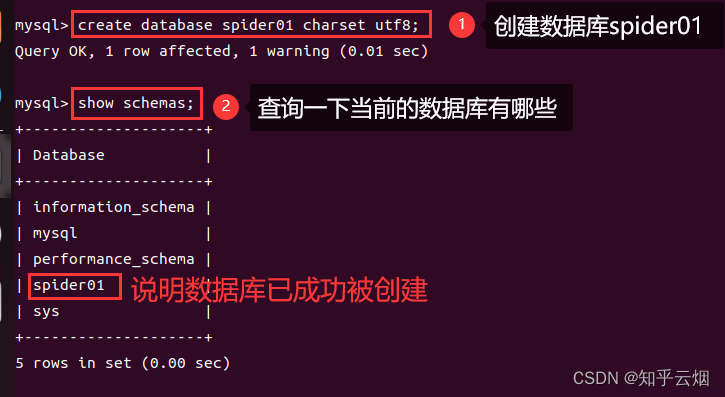
打开终端,连接mysql,创建数据库spider01。
sudo mysql -u -root -p # 连接mysql
create database spider01 charset utf8; # 创建数据库spider01
show schemas; # 在mysql里输入表示查询自带的数据库
然后使用刚刚创建的数据库,创建一张表。
use spider01; # 使用数据库spider01
create table book(id int primary key auto_increment,name varchar(128),src varchar(128)); # 在当前使用的库中创建一张表book,包含id、name和src三列,id列将作为自增的主键,其他两列字符长度最大均为128
select * from book; # 查询表book的内容

表创建成功后,接下来需要将爬取的数据插入这个表中。首先,打开新的终端来查询Ubuntu的ip地址。
ip address show # 查询ip

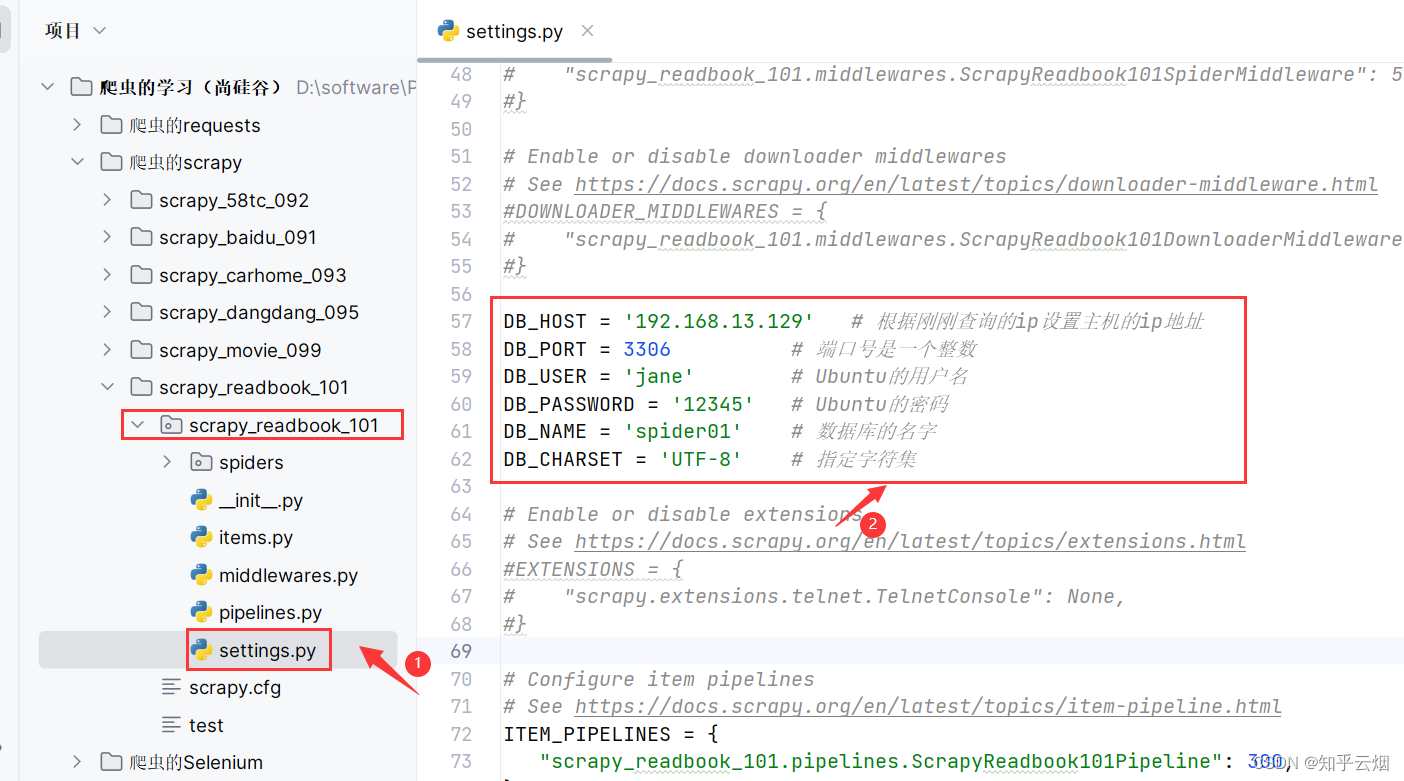
打开PyCharm,在文件“setting.py”中配置几个参数,即随便找个位置输入下面几行代码(参数请根据自己的情况进行修改)。
DB_HOST = '192.168.13.129' # 根据刚刚查询的ip设置主机的ip地址
DB_PORT = 3306 # 端口号是一个整数
DB_USER = 'jane' # Ubuntu的用户名
DB_PASSWORD = '12345' # Ubuntu的密码
DB_NAME = 'spider01' # 数据库的名字
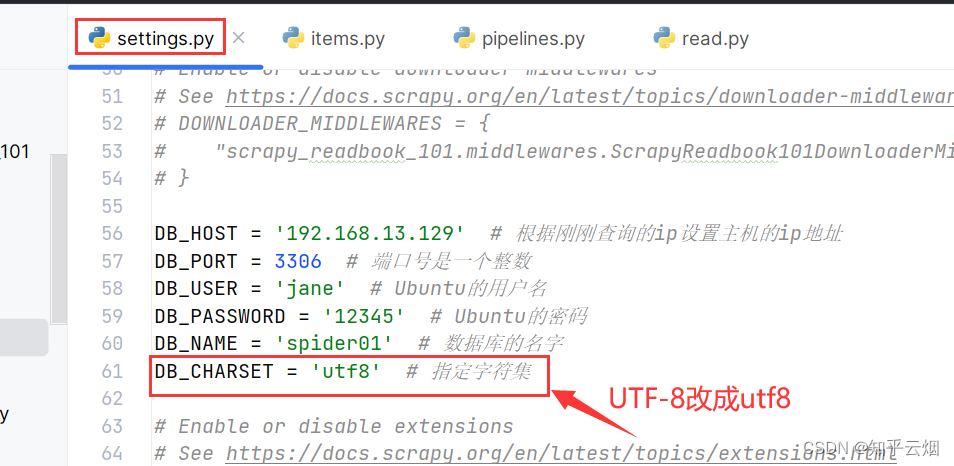
DB_CHARSET = 'UTF-8' # 指定字符集
再去“pipelines.py”中造一个管道,以便传到Ubuntu。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ScrapyReadbook101Pipeline:
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='UTF-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
# 导入setting文件
from scrapy.utils.project import get_project_settings
import pymysql
# 将数据传输给Ubuntu的管道
class MysqlPipeline:
# 连接MySql
def open_spider(self, spider):
settings = get_project_settings() # 加载setting文件
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWORD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
# 调用coonnect()连接musql
self.coonnect()
def coonnect(self):
"""
连接MySql的函数
"""
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# MySQL语句,将数据传入表book中
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'], item['src'])
self.cursor.execute(sql) # 执行mysql语句
self.conn.commit() # 确认提交
return item
# 断开MySql的连接
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
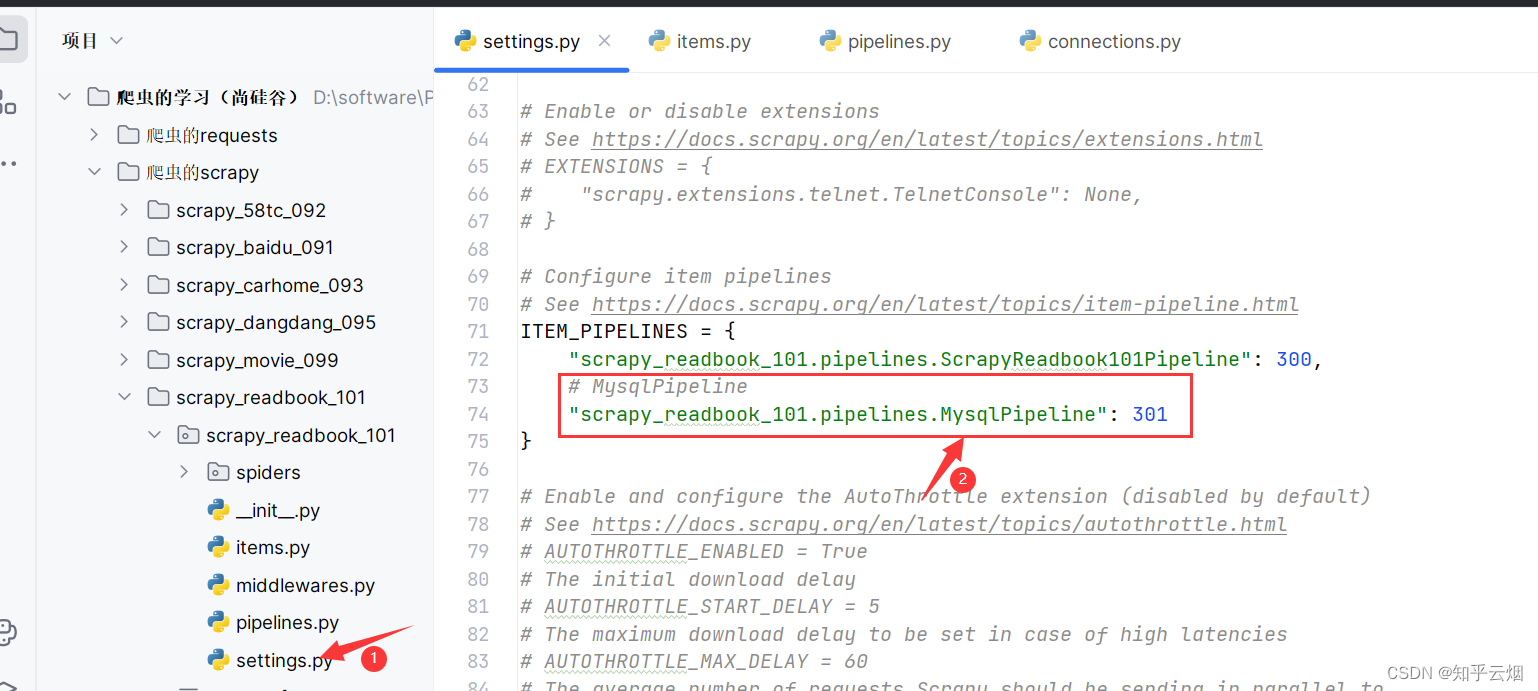
在文件“setting.py”中打开管道。
# MysqlPipeline
"scrapy_readbook_101.pipelines.MysqlPipeline": 301
运行程序,发现有“encoding”报错。
cd 爬虫的scrapy
cd scrapy_readbook_101\scrapy_readbook_101\spiders
scrapy crawl read
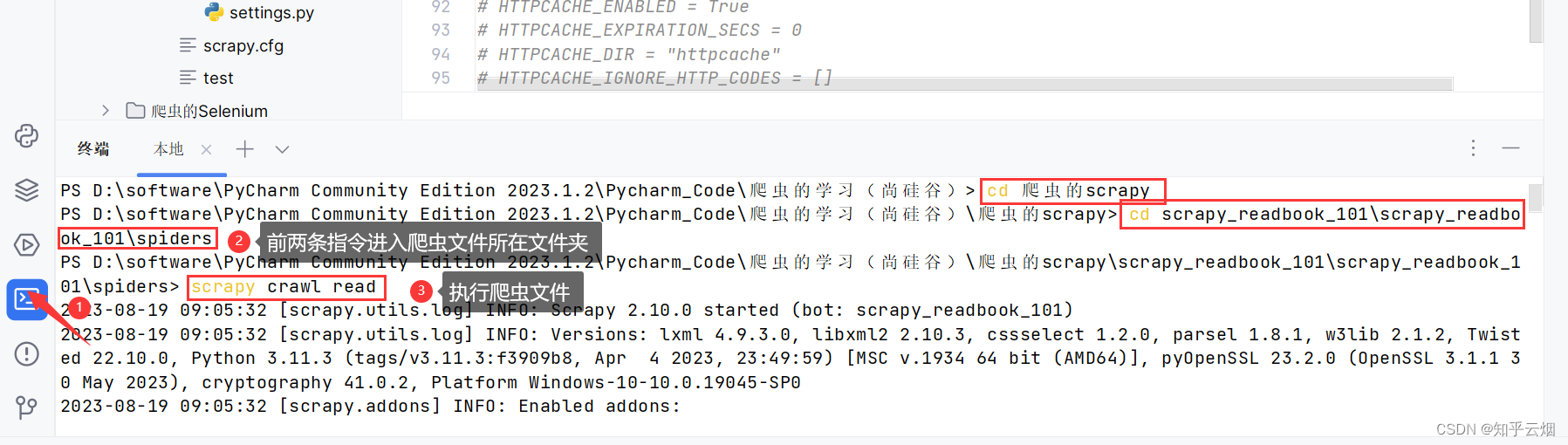

然后进行如下修改,另外为了爬取所有所有数据(页数不局限于13页),故去修改“read.py”中的一个参数,然后再运行程序。
scrapy crawl read

查了一堆还是不会解决这个问题,希望有成功解决的兄弟分享一下方法。
比如下面的方法连个截图都没有,真抽象,没有解决问题。按照“https://blog.csdn.net/wangshuminjava/article/details/79310086”的提示,去ping一下Ubuntu的ip,telnet一下Ubuntu的端口(如果提示’telnet’ 不是内部或外部命令,请参考“https://blog.csdn.net/qq_36292543/article/details/119645130”去打开telnet)。
ping 192.168.13.129 # 验证是否能连通Ubuntu的ip
telnet 192.168.13.129 3306 # 验证是否能使用3306端口连接到Ubuntu
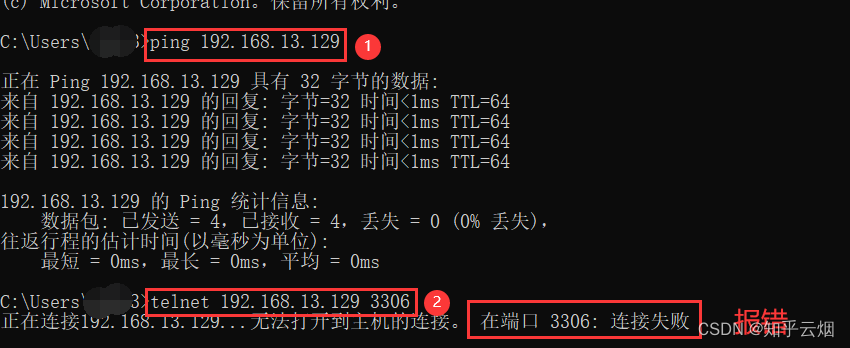
修改防火墙允许3306也不行(方法来源于“https://blog.csdn.net/qq_43567345/article/details/105323795”)。改权限grant还失效,好多给出的解决办法都是针对的5.7,新版的较少。就算有,没有系统学过MySQL的东西暂时看不明白。
已放弃,一时半会是解决不了的。
注:由于本节内容因为卡在最后一步不能正常运行,需要将本节新添的代码注释掉。
14. scrapy_日志信息以及日志级别
(1)日志信息的定义、等级、如何设置日志
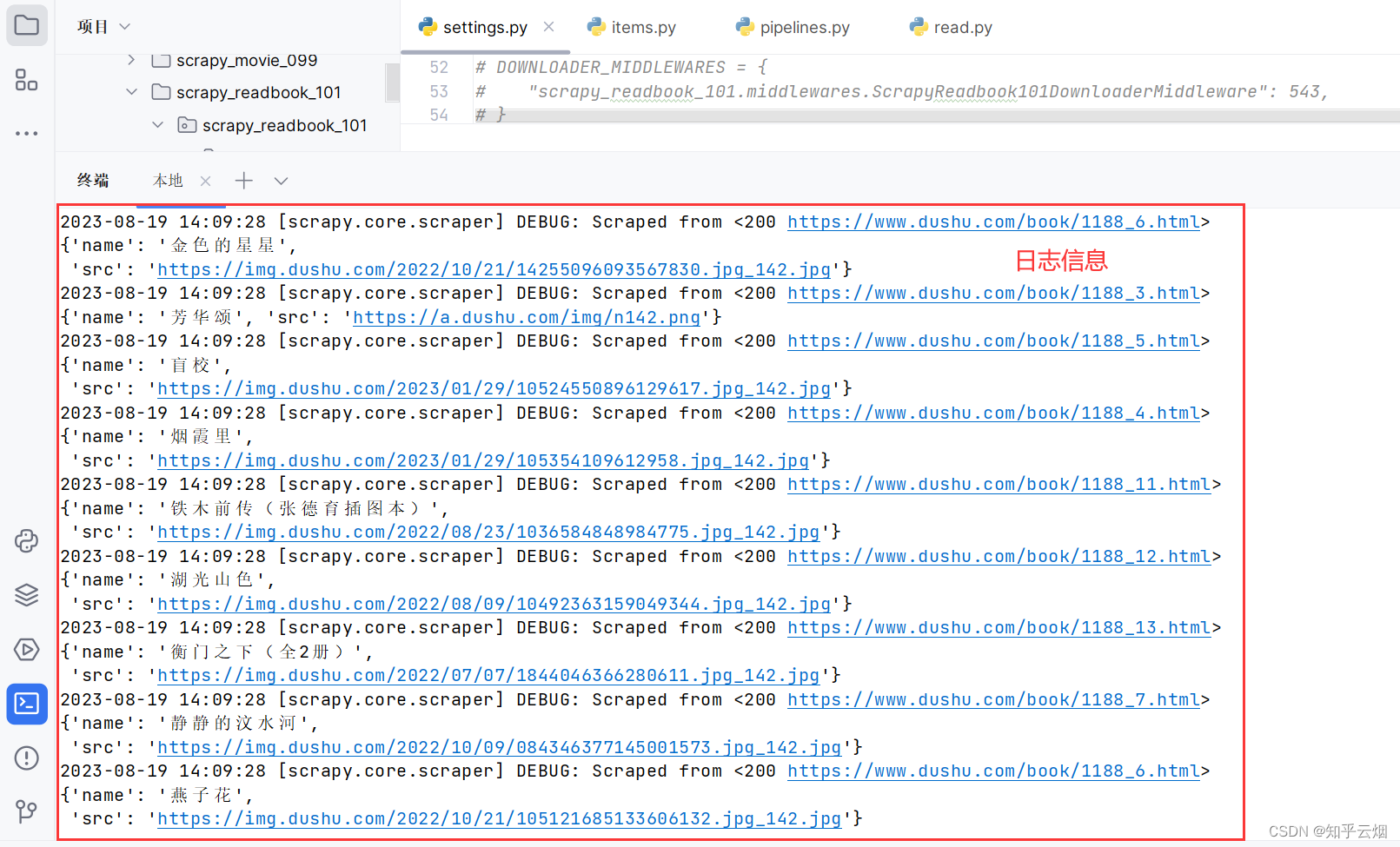
如下图所示,运行第12节的代码后会出现很多信息,这些都是scrapy的日志信息。对我们而言,不需要看浏览这么多信息。

(2)代码演示
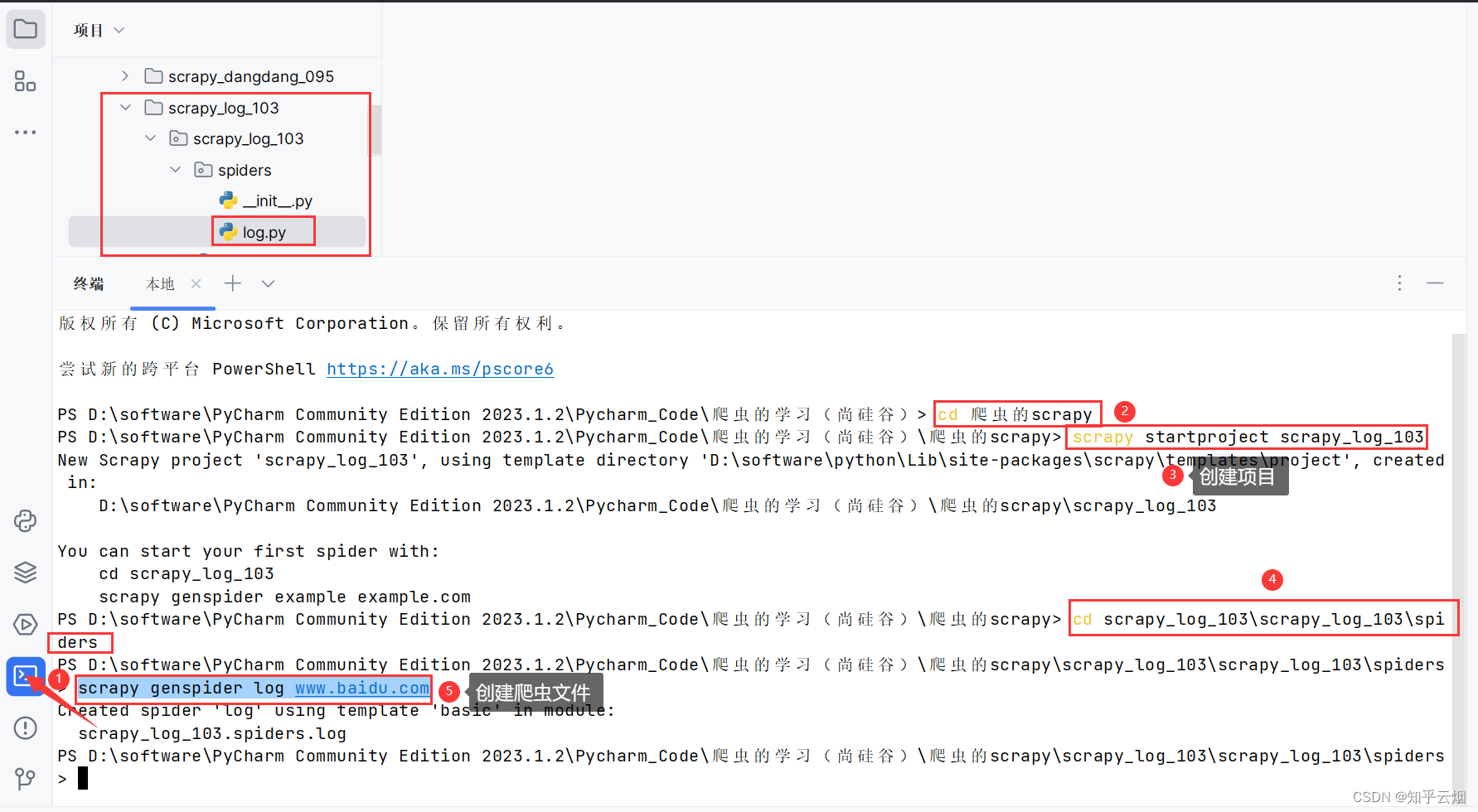
如下图,创建项目和爬虫文件。
cd 爬虫的scrapy # 进入文件夹“爬虫的scrapy”
scrapy startproject scrapy_log_103 # 创建项目“scrapy_log_103”
cd scrapy_log_103\scrapy_log_103\spiders # 进入爬虫文件所在的文件夹
scrapy genspider log www.baidu.com # 创建爬虫文件“log.py”
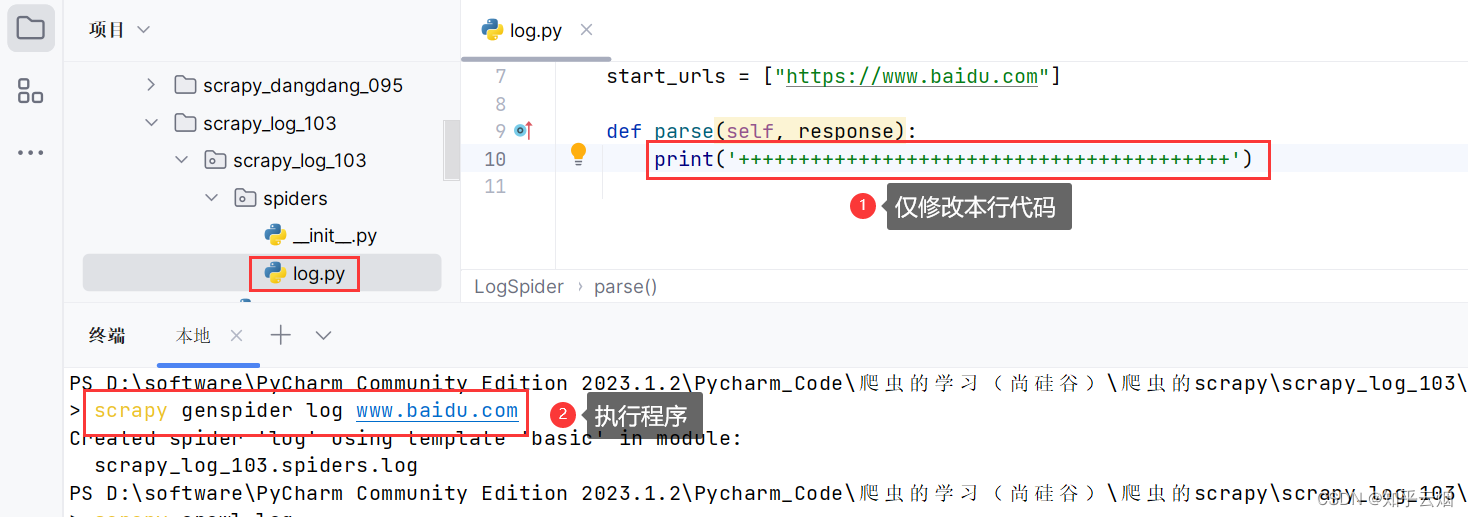
如下图,尝试打印一条信息,结果没有打印。
scrapy crawl log # 执行程序
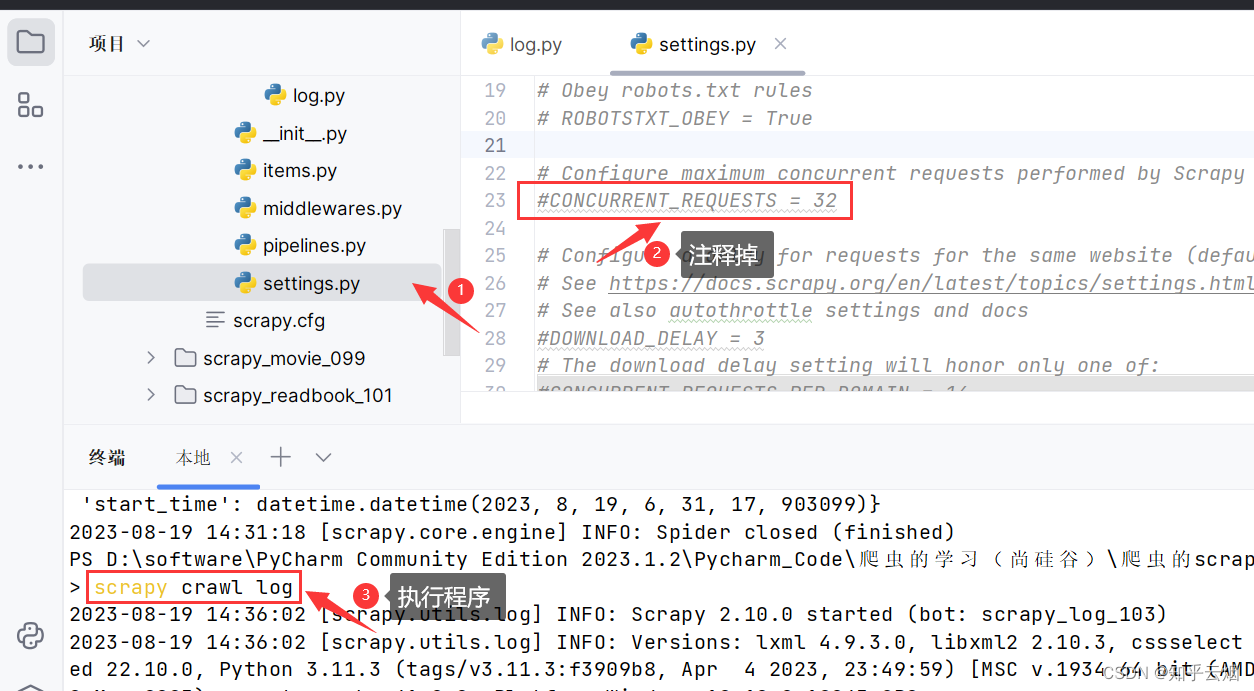
如下图,注释robots协议即可正常打印。
scrapy crawl log # 执行程序

加一行代码后,可以看到日志信息被屏蔽。
# 指定日志的级别
LOG_LEVEL = 'WARNING'
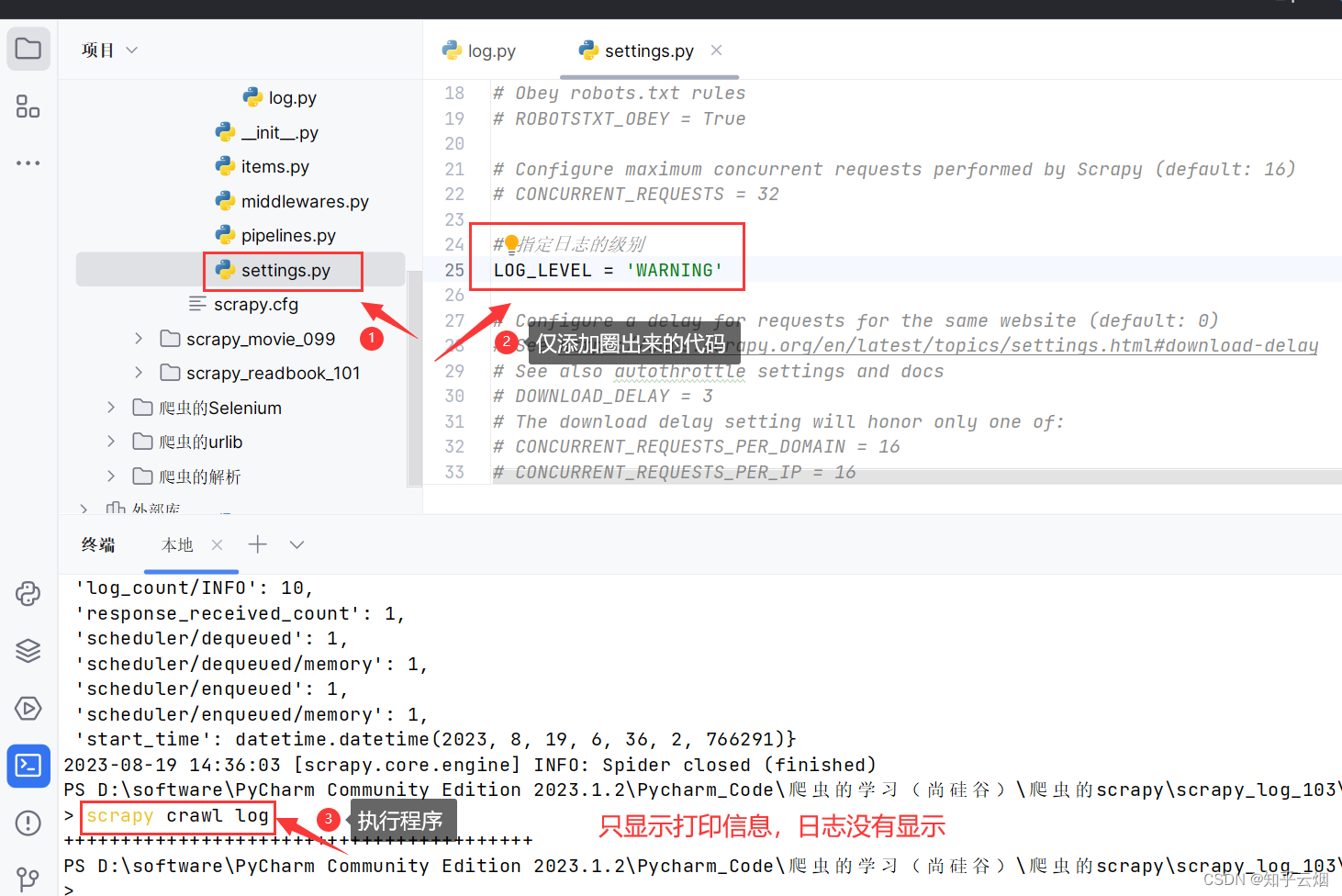
但是如果按照上图来设置后,当报错时,会看不到调试信息。为了规避这个问题,写成如下图所示的代码即可,如果代码报错,去查看日志文件即可。
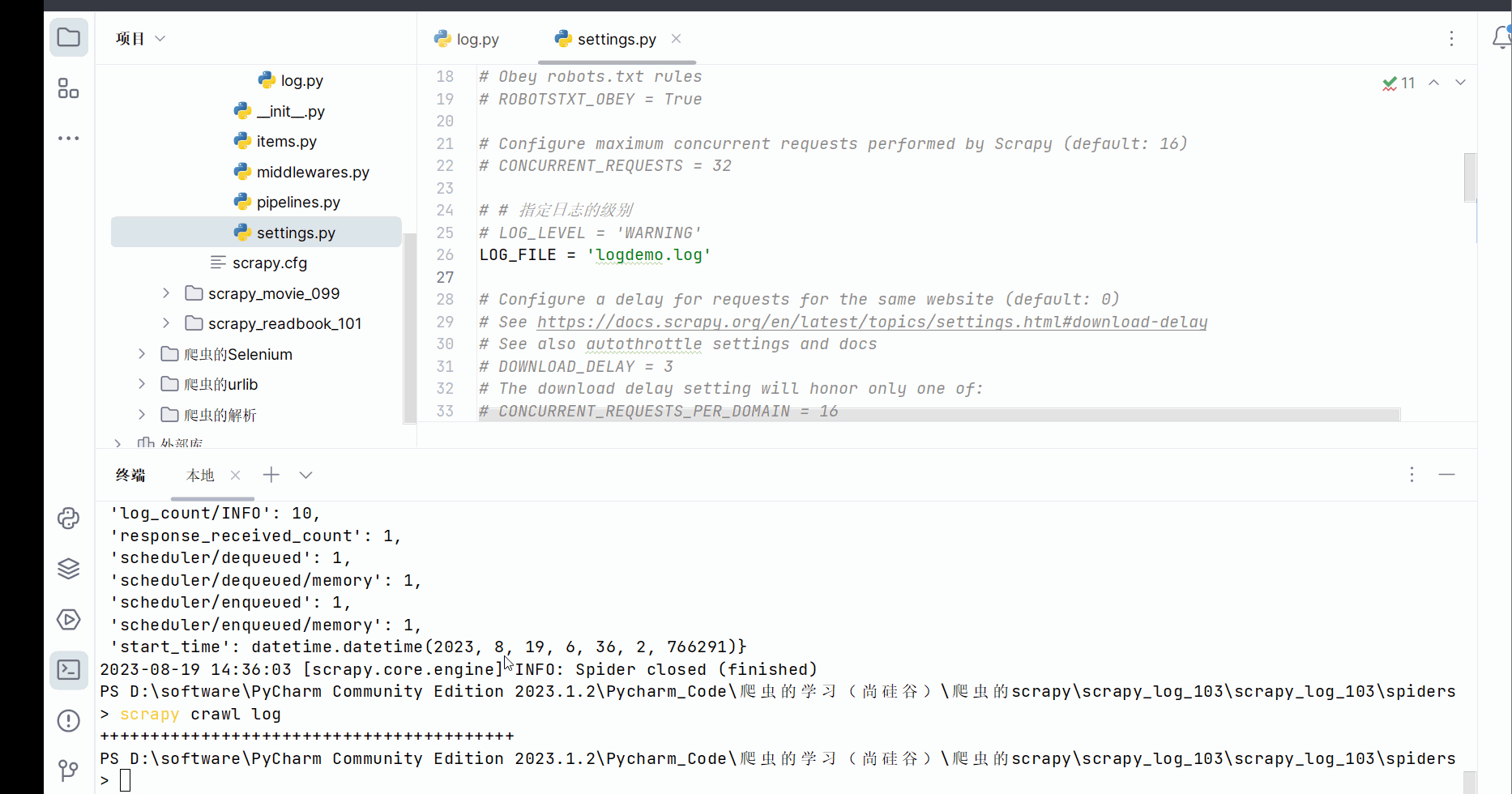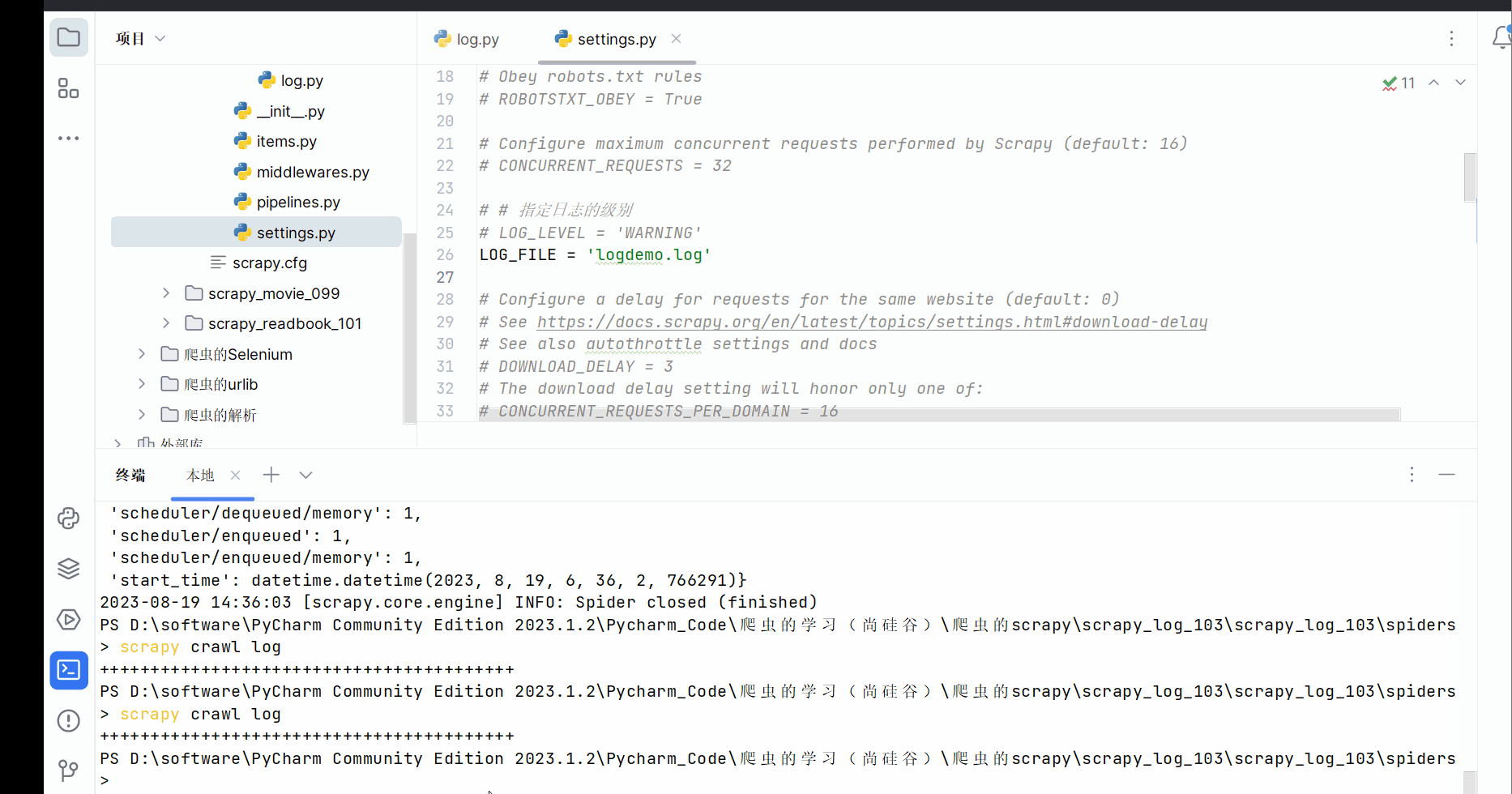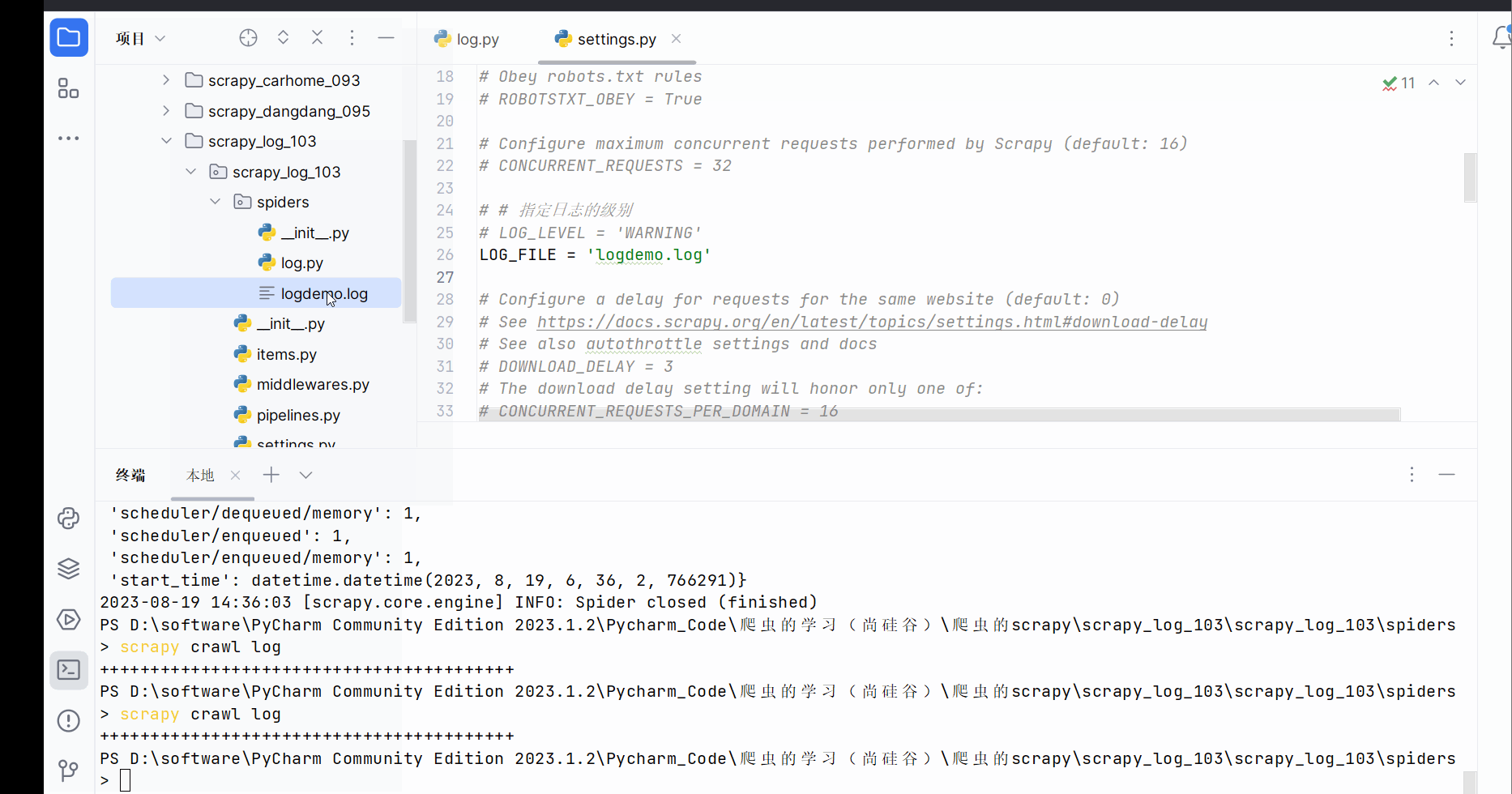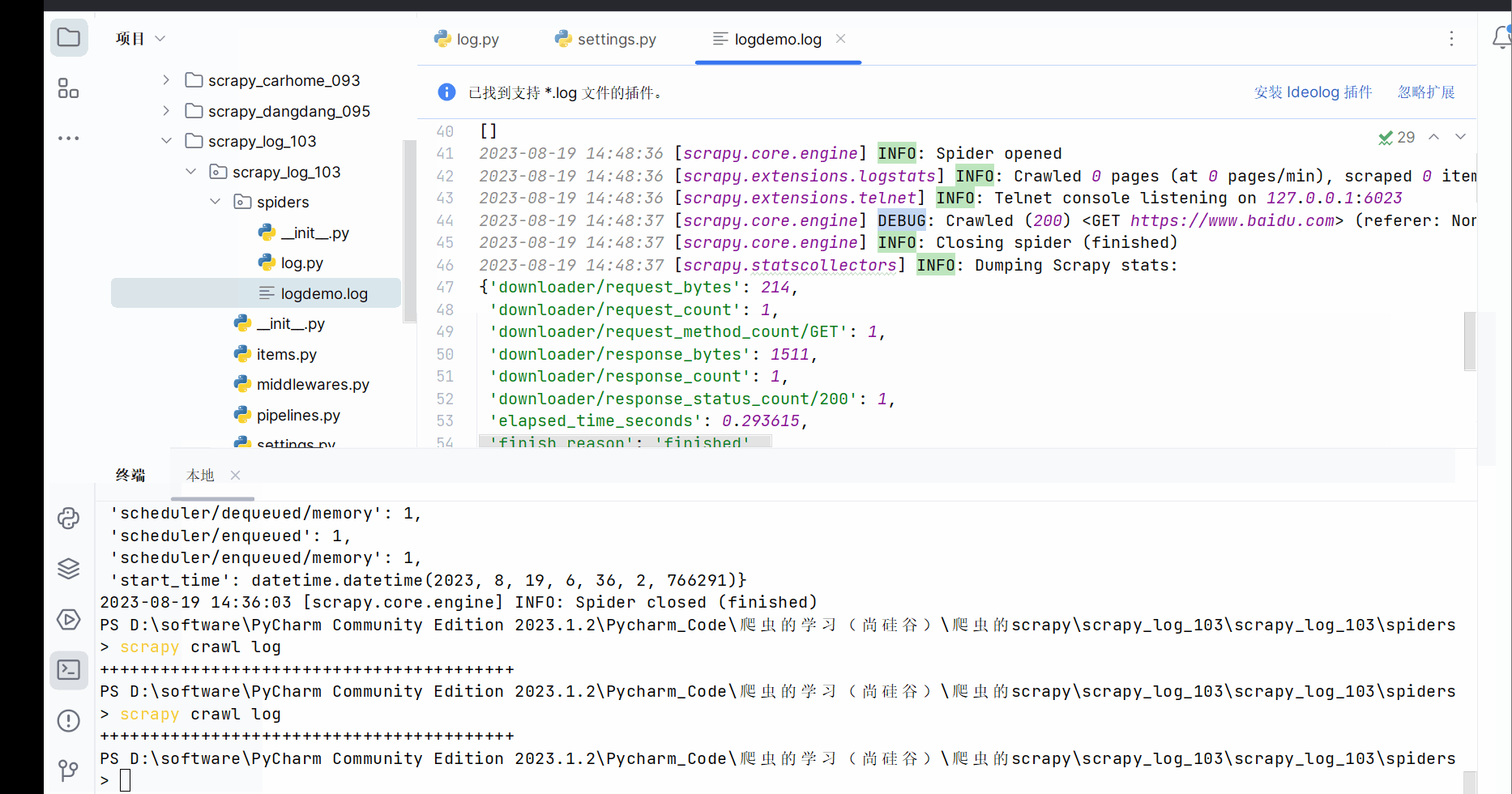
# # 指定日志的级别
# LOG_LEVEL = 'WARNING'
LOG_FILE = 'logdemo.log'
15.scrapy_百度翻译post请求
(1)scrapy 下的post请求的用法

(2)代码演示
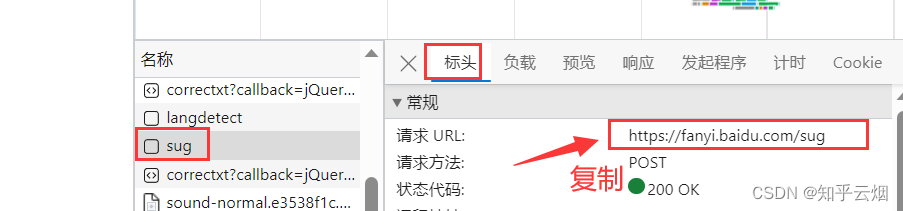
如下图,去百度翻译中打开检查,选择网络,随便输一个英文单词,然后找到它的接口并复制请求地址。
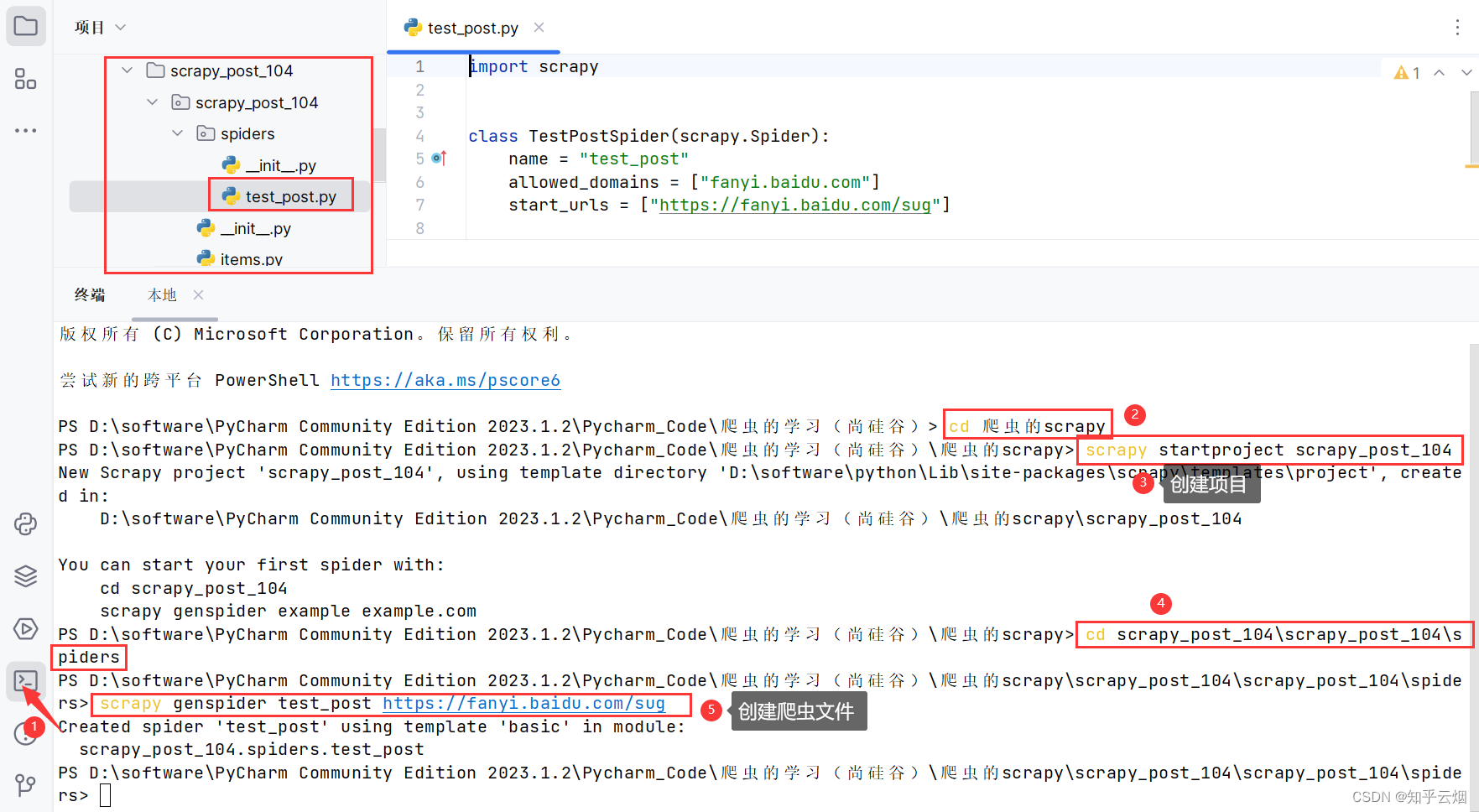
如下图所示,创建项目和爬虫文件。
cd 爬虫的scrapy # 进入文件夹“爬虫的scrapy”
scrapy startproject scrapy_post_104 # 创建项目“scrapy_post_104”
cd scrapy_post_104\scrapy_post_104\spiders # 进入文件夹“spiders”
scrapy genspider test_post https://fanyi.baidu.com/sug # 创建爬虫文件“test_post.py”
目前有一个问题,这个post请求会查询单词,而在代码文件“test_post.py”中看不出来它所携带的参数(即所查的单词)在什么位置。我们要知道,不含参数的post请请求是没有意义的,即start_urls没有用。由于start_urls决定着parse的执行,故方法parse也没有用。
故在文件“test_post.py”如下编写代码。
import scrapy
class TestPostSpider(scrapy.Spider):
name = "test_post"
allowed_domains = ["fanyi.baidu.com"]
# # post请求 如果没有参数 那么这个请求将没有任何意义
# # 所以start_urls 也没有用了
# # parse方法也没有用了
# start_urls = ["https://fanyi.baidu.com/sug"]
#
# def parse(self, response):
# pass
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {
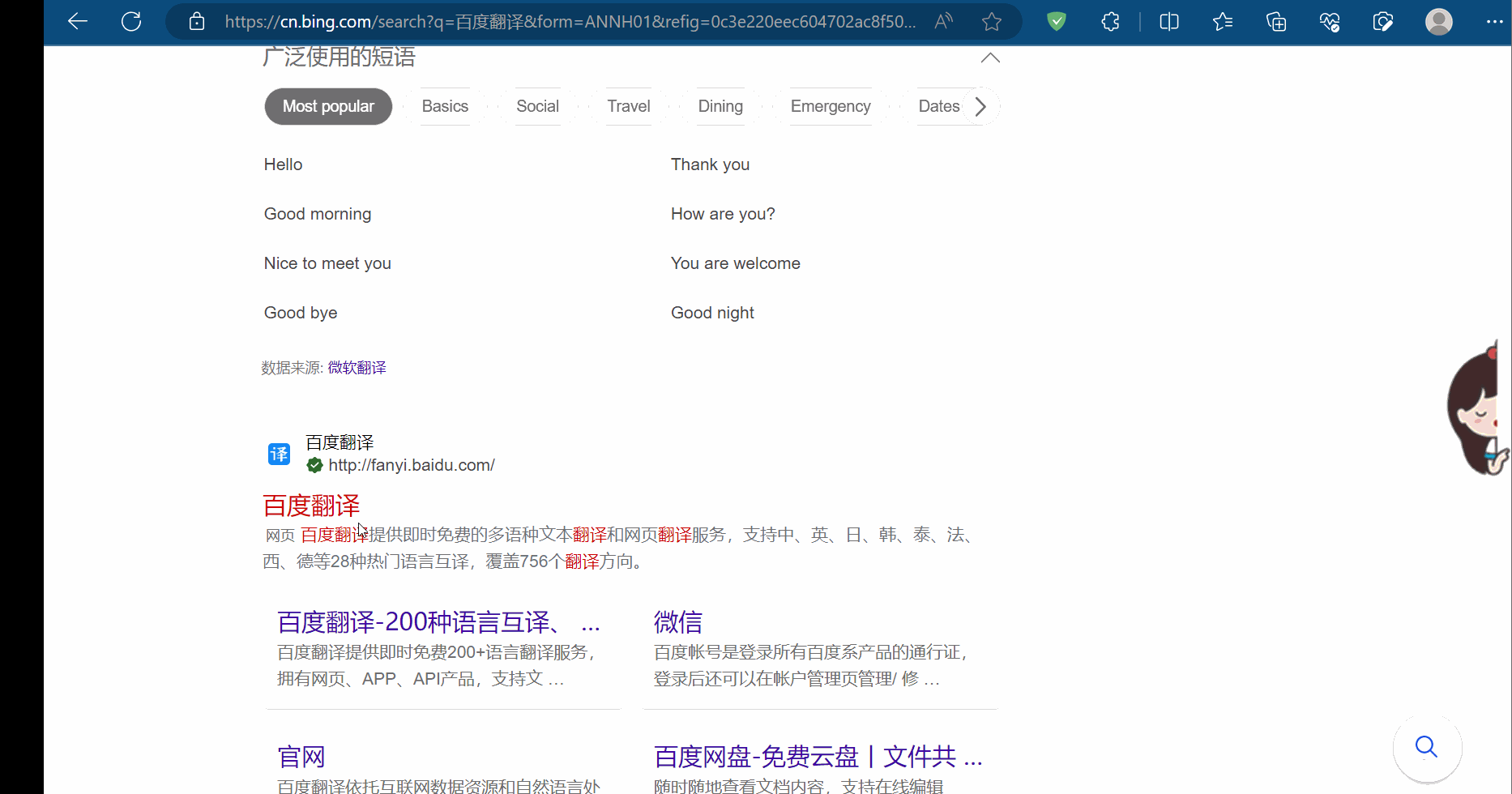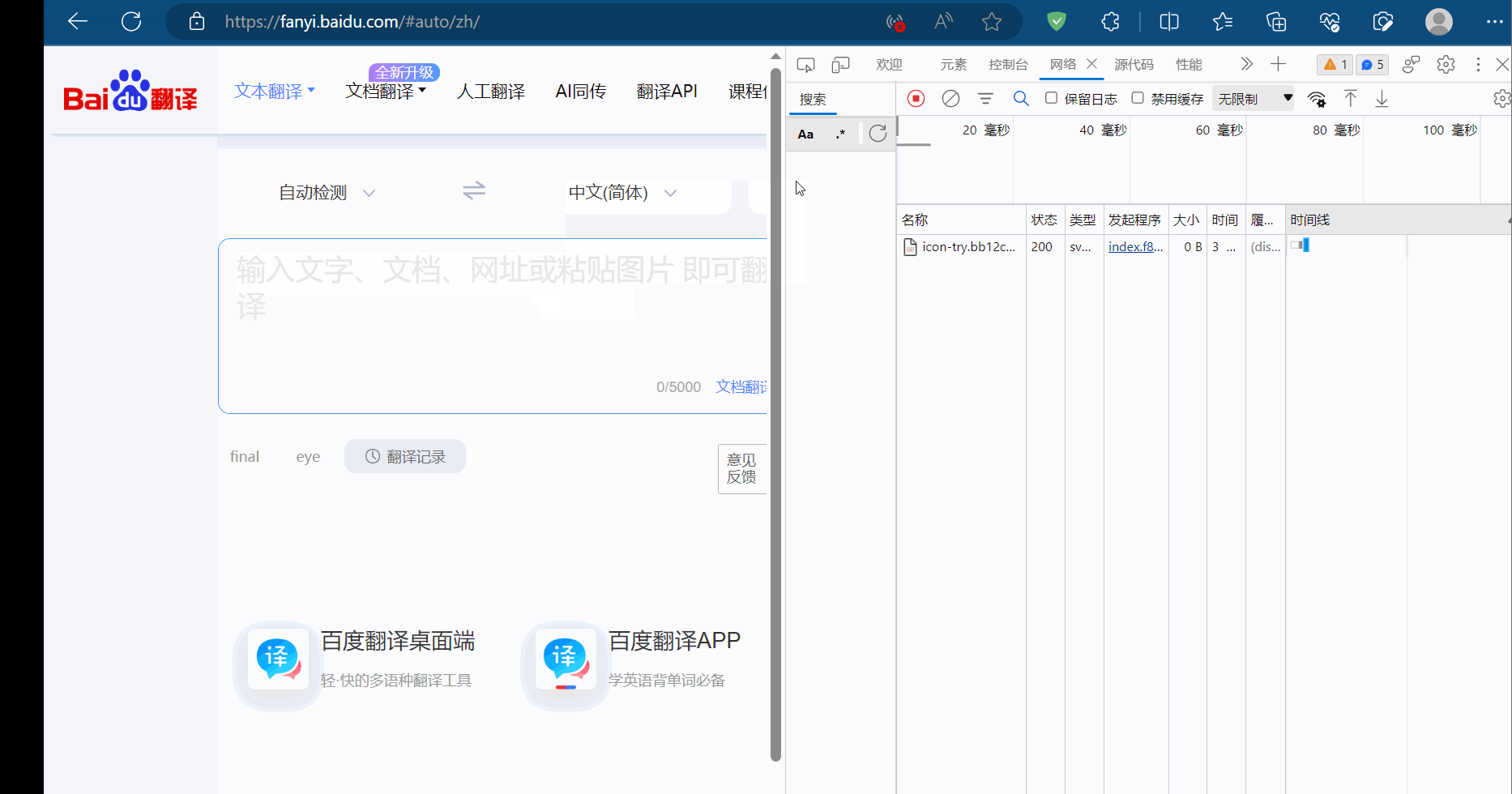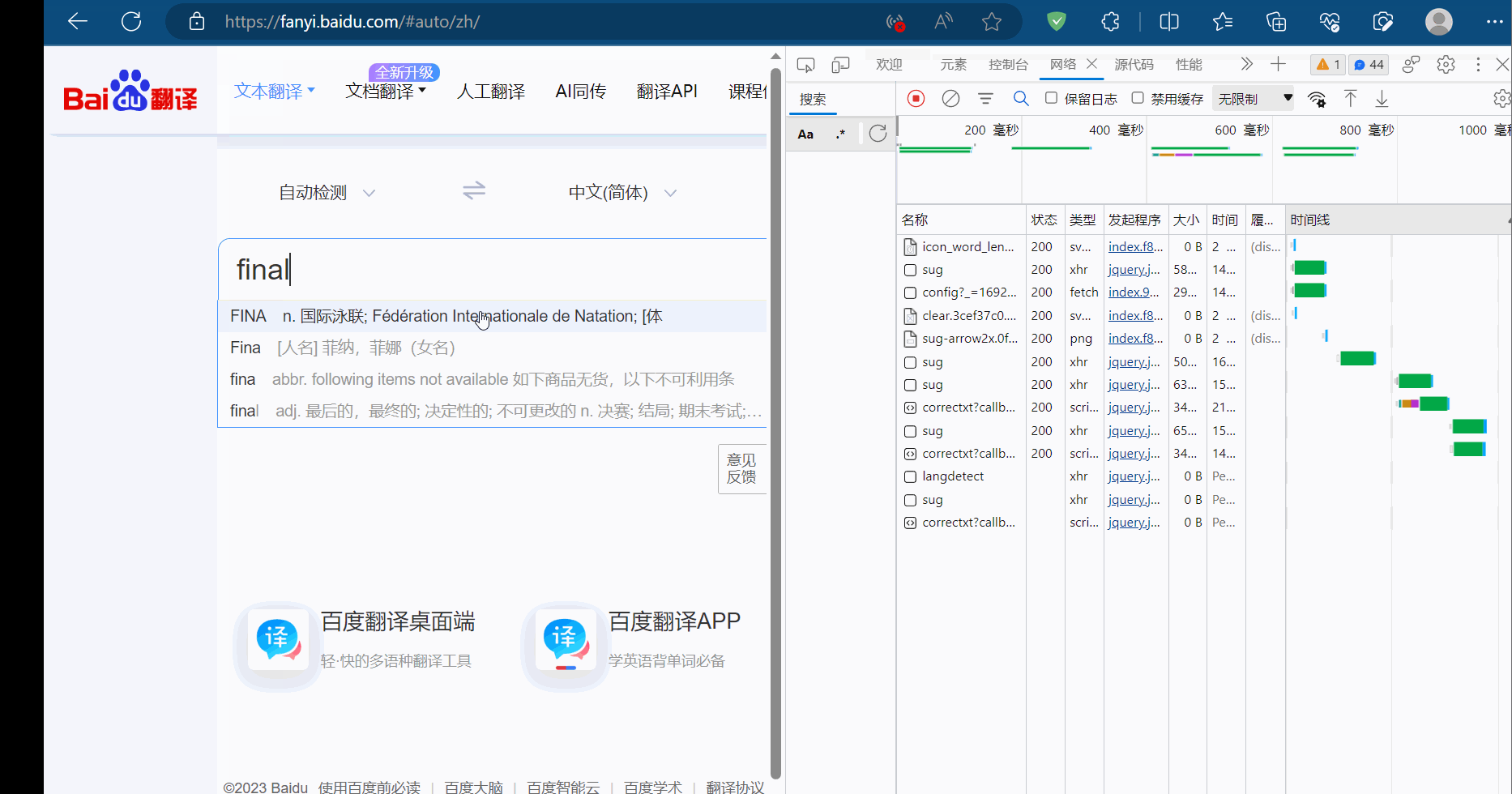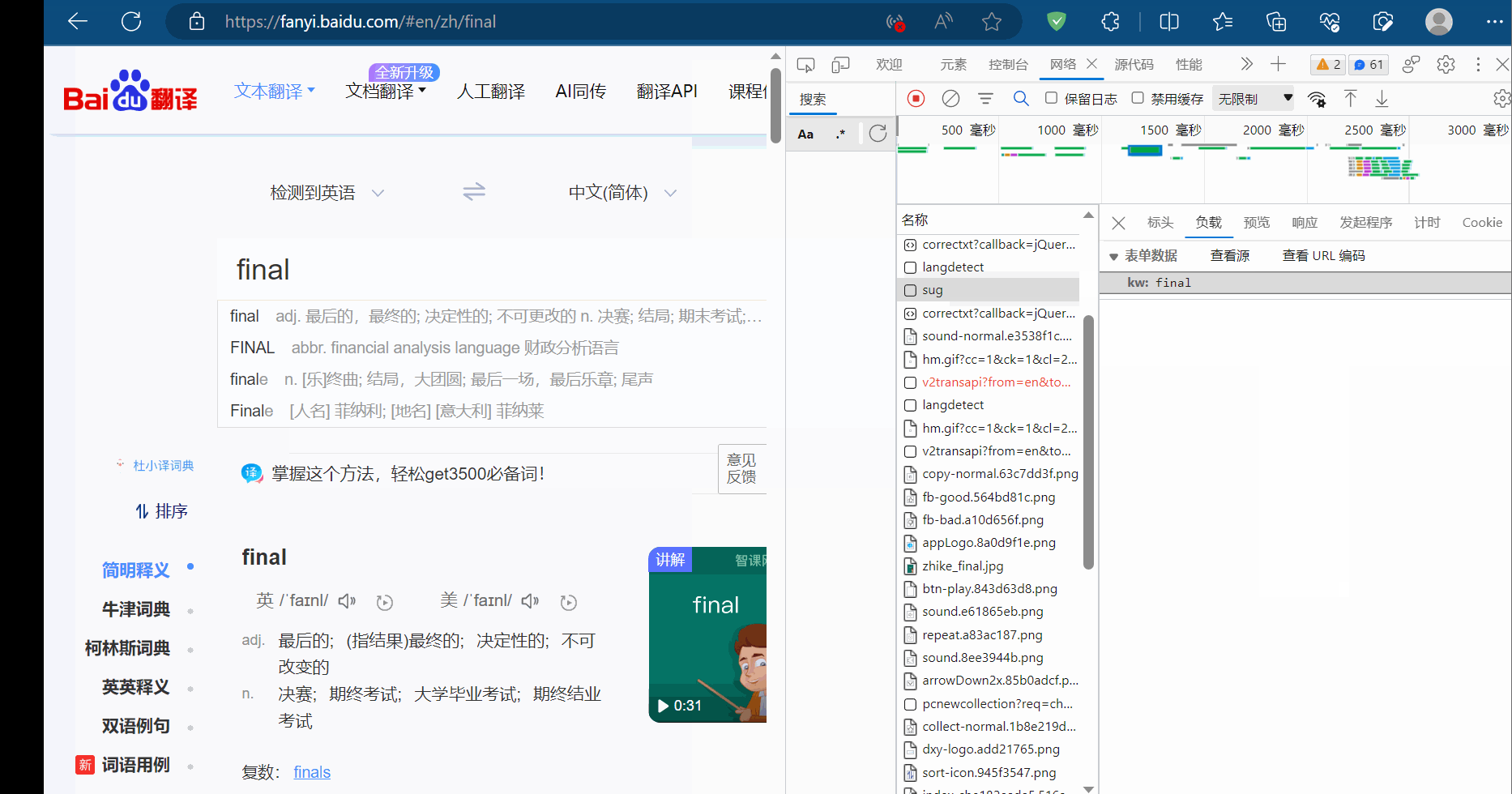
'kw': 'final' # 参数可在浏览器的检查里的接口的负载中查到
}
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)
def parse_second(self, response):
content = response.text
print(content)
去“setting.py”中设置日志信息,然后再运行程序。
# 保存日志文件
LOG_FILE = 'test_post.log'
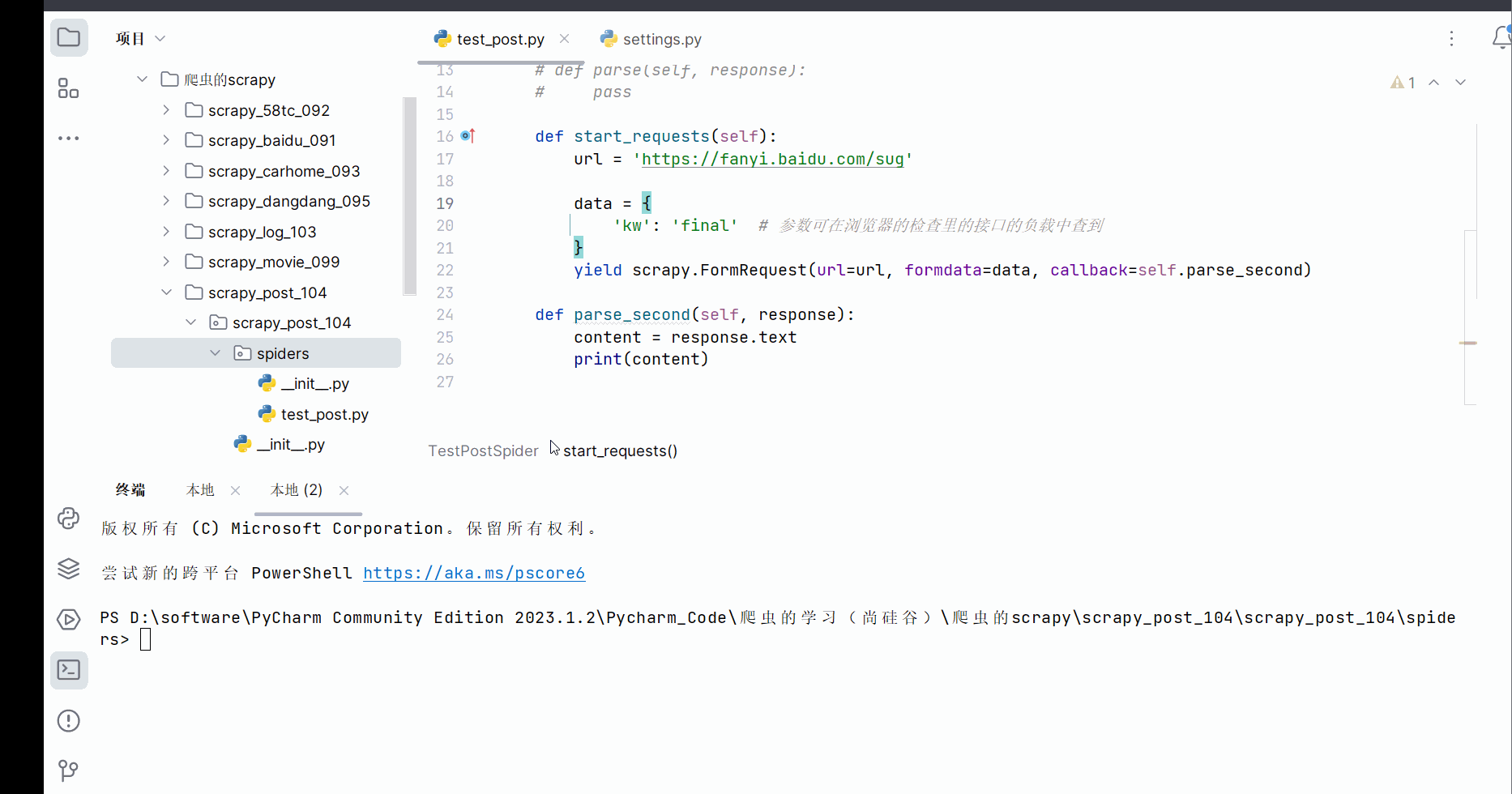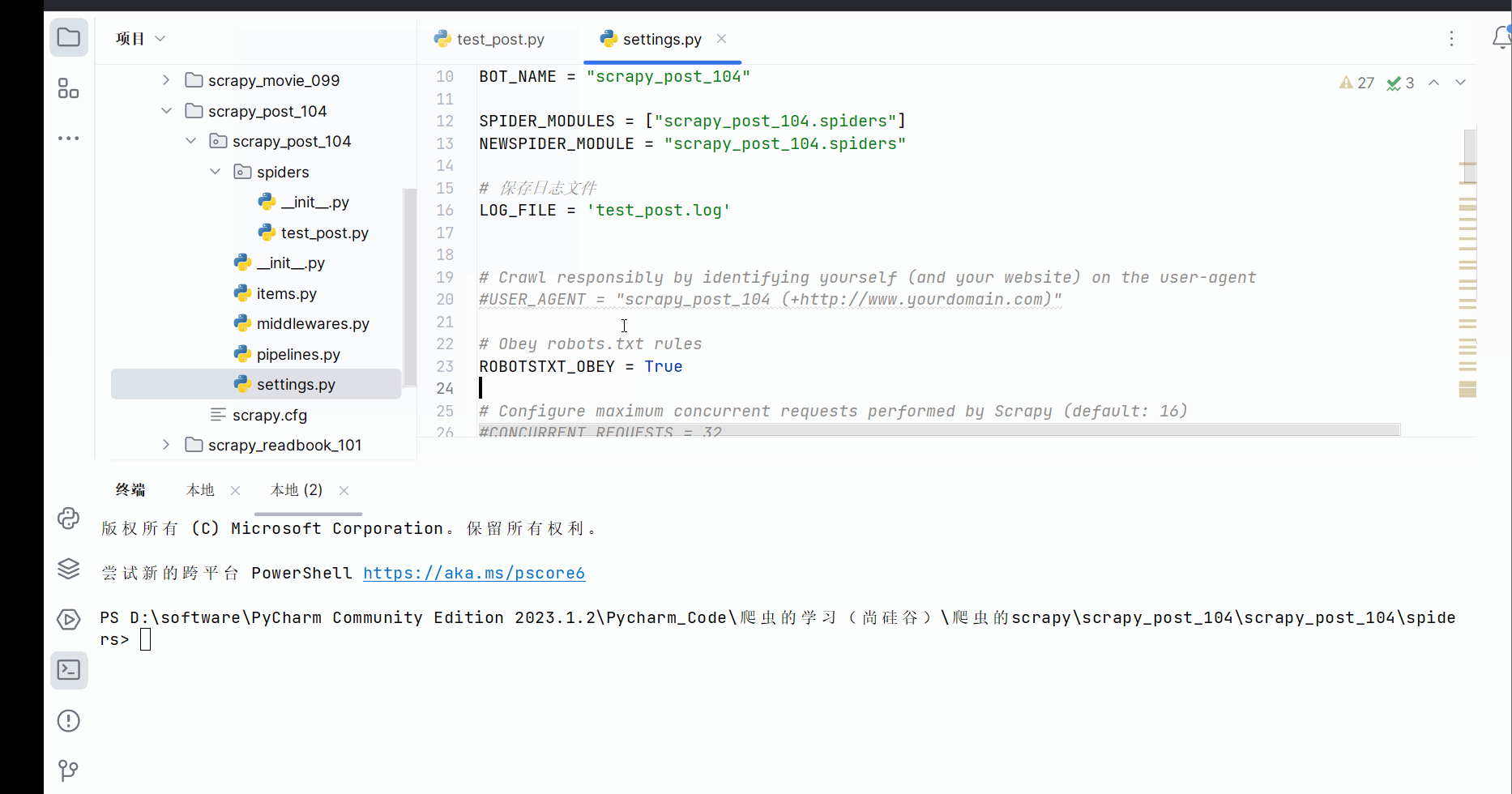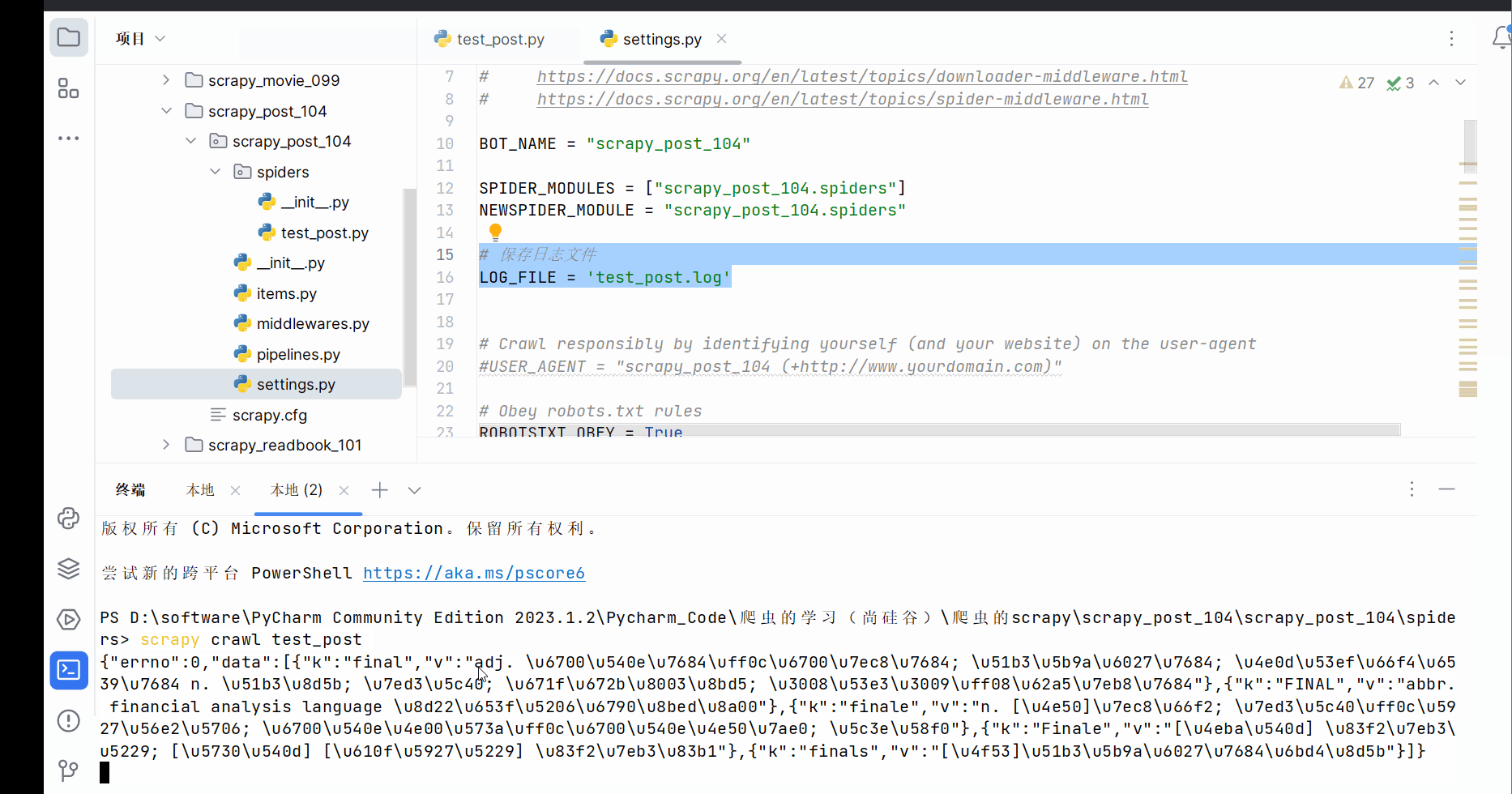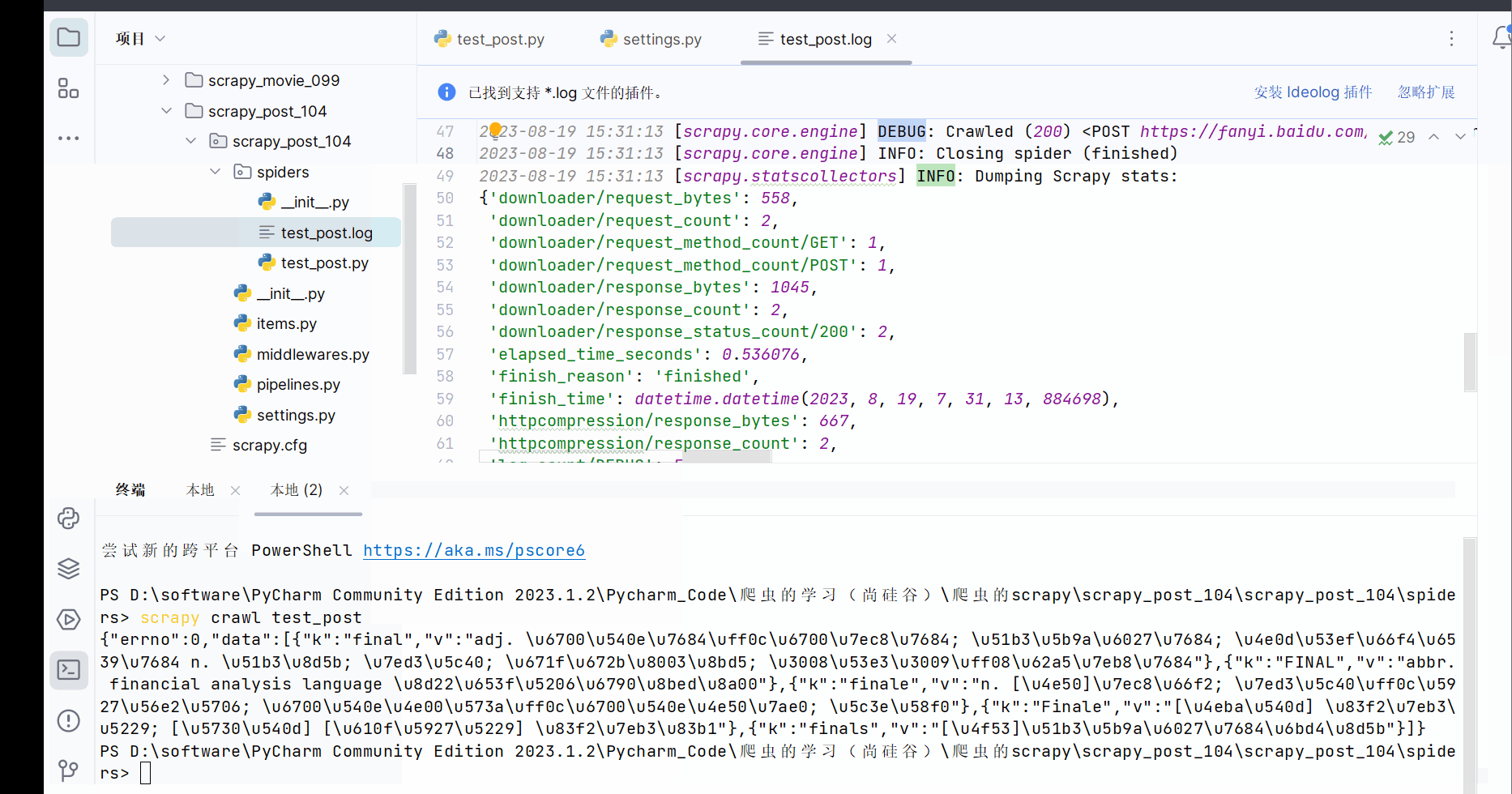
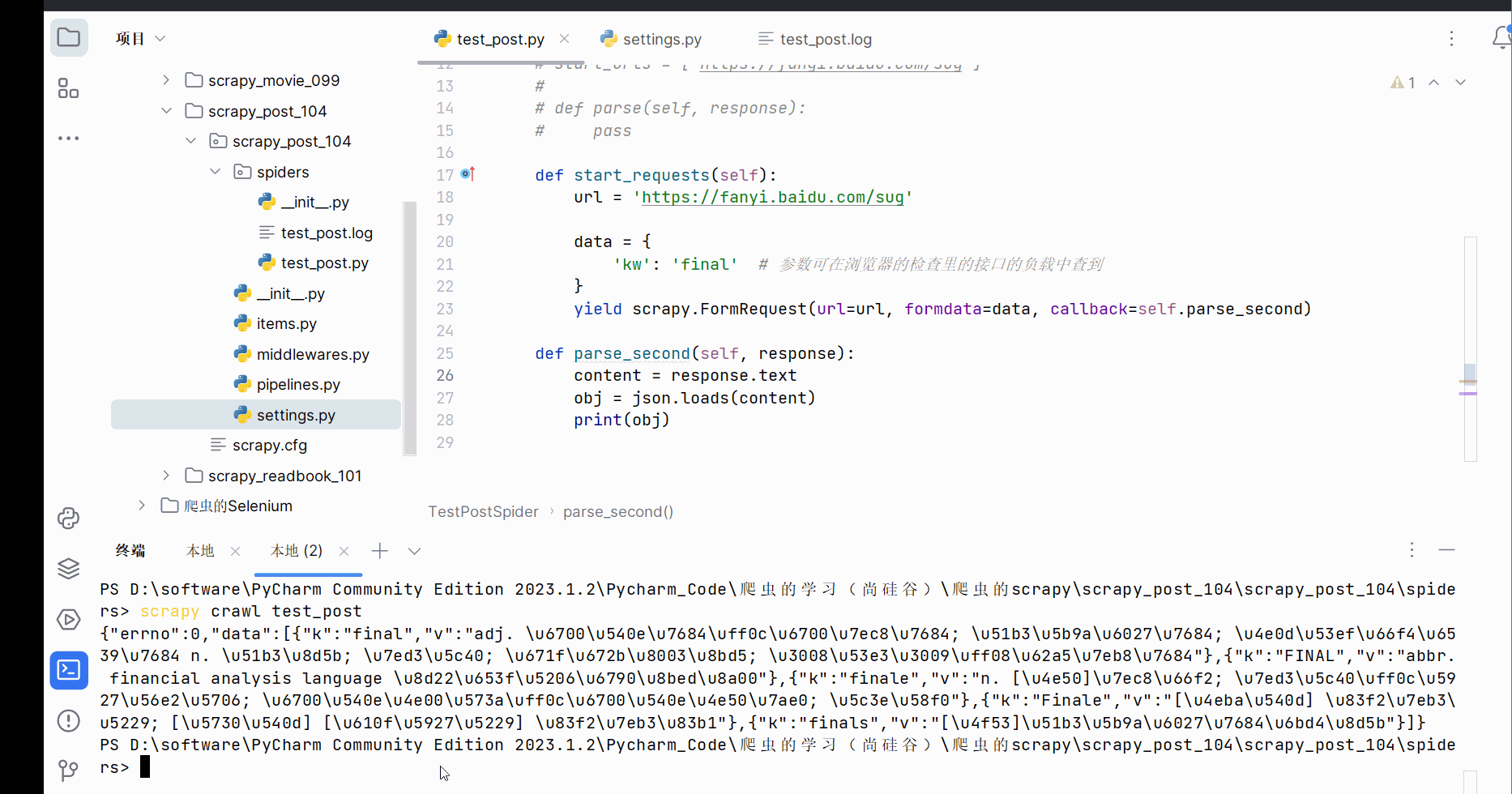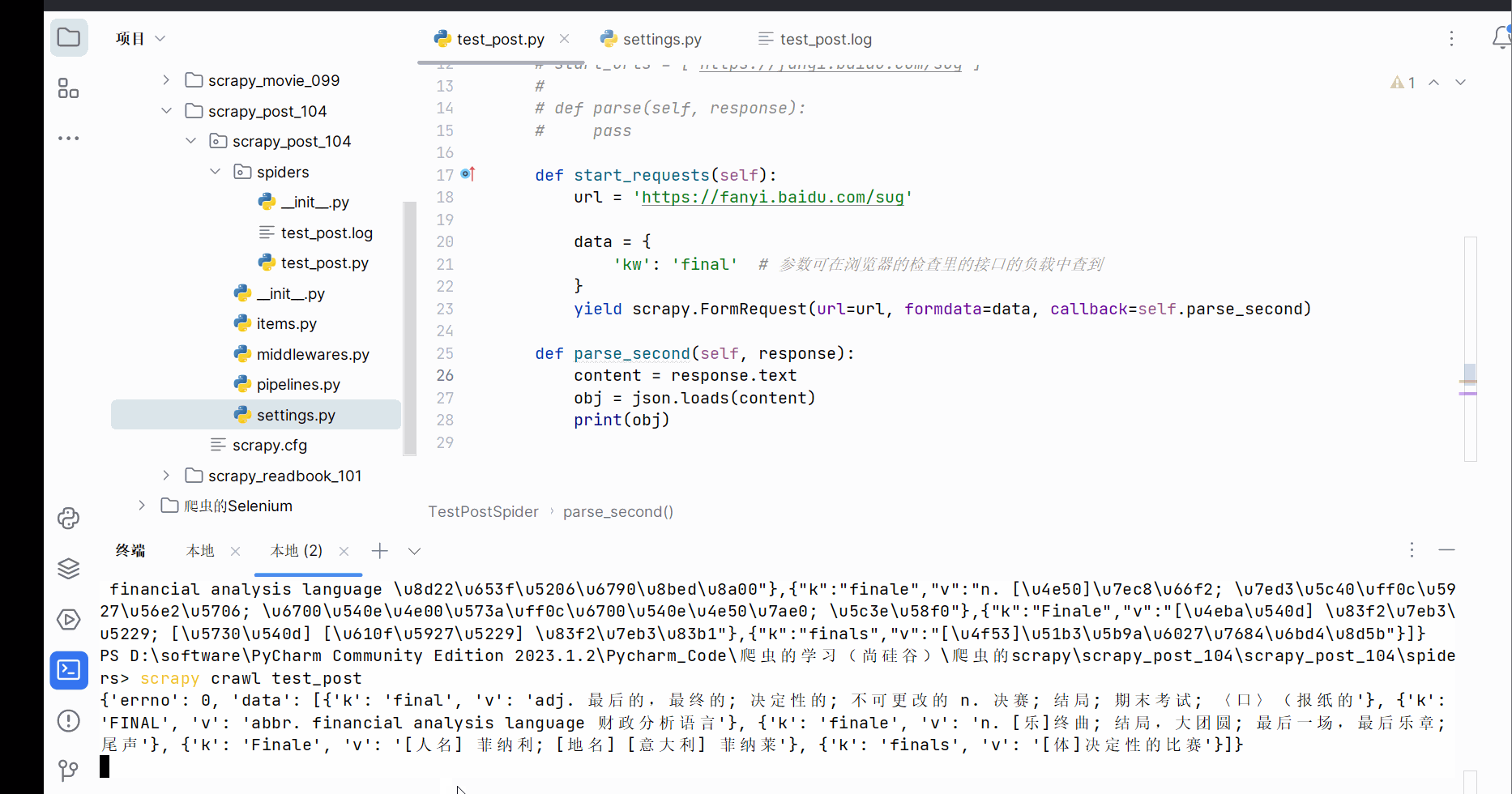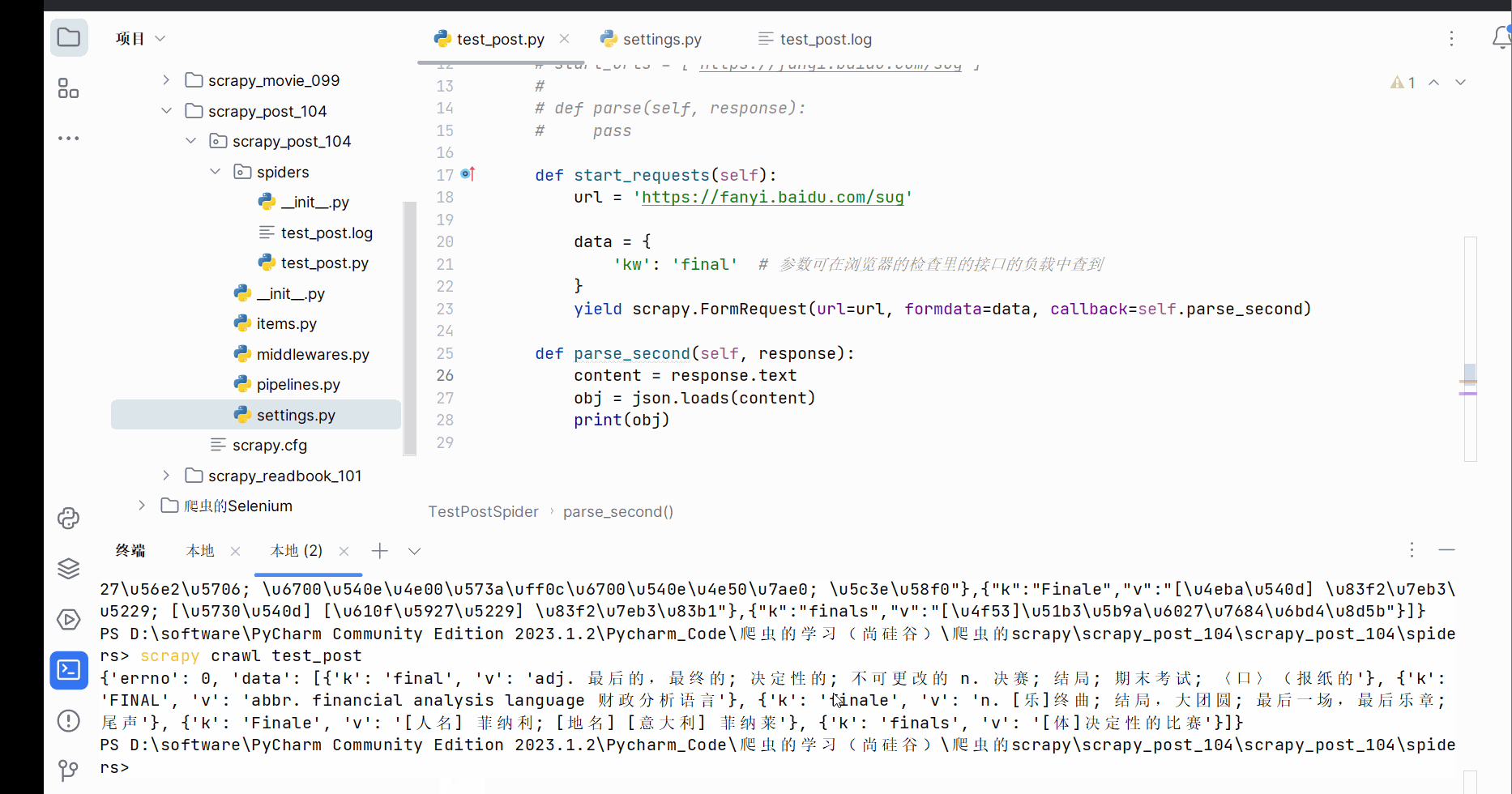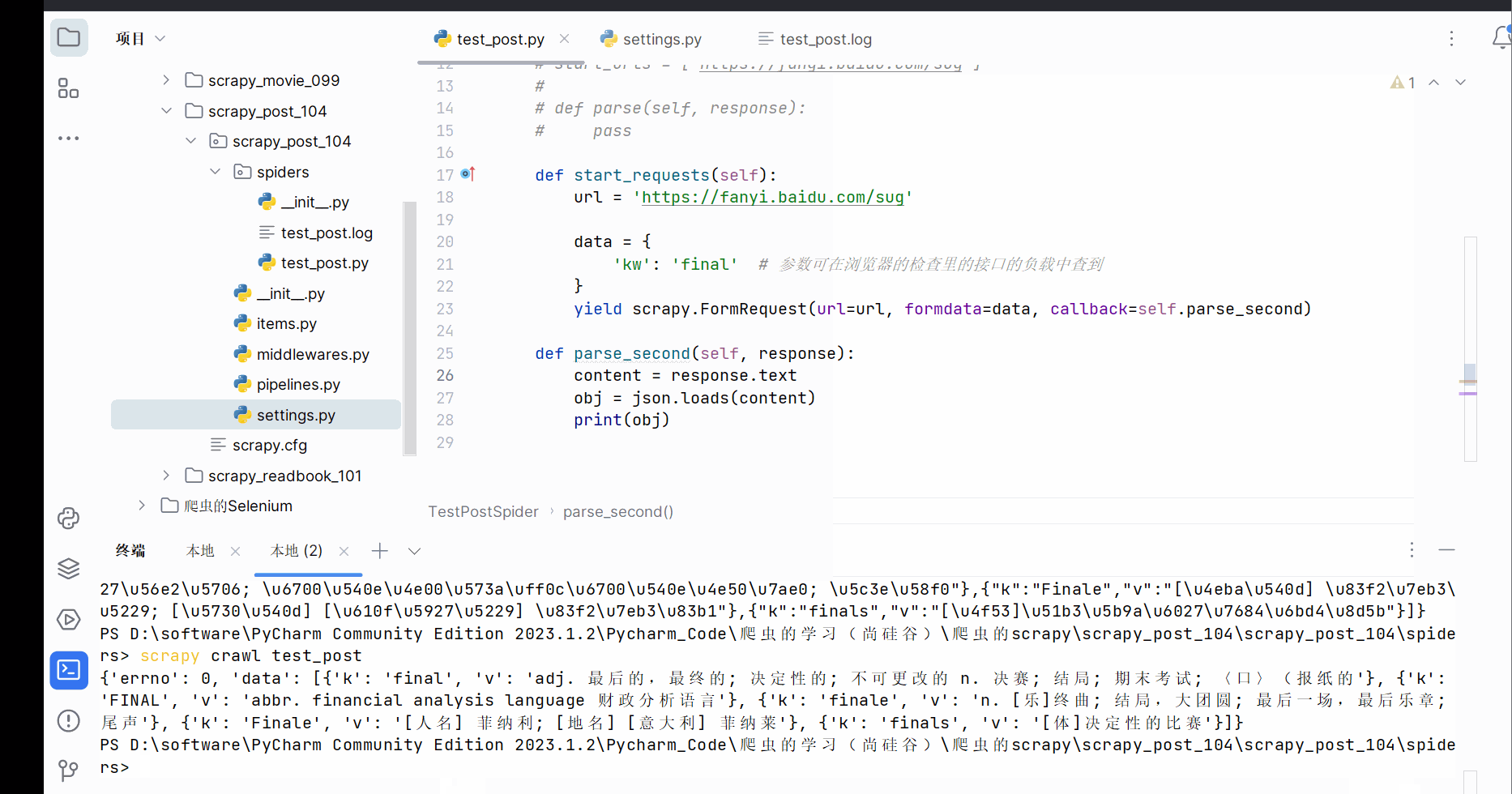
由上图知,存在编码问题。故继续在文件“test_post.py”编写代码,并运行。
import scrapy
import json
class TestPostSpider(scrapy.Spider):
name = "test_post"
allowed_domains = ["fanyi.baidu.com"]
# # post请求 如果没有参数 那么这个请求将没有任何意义
# # 所以start_urls 也没有用了
# # parse方法也没有用了
# start_urls = ["https://fanyi.baidu.com/sug"]
#
# def parse(self, response):
# pass
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': 'final' # 参数可在浏览器的检查里的接口的负载中查到
}
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)
def parse_second(self, response):
content = response.text
obj = json.loads(content)
print(obj)
好了,本章的笔记到此结束,谢谢大家阅读。写完本章博客,人都快废了。