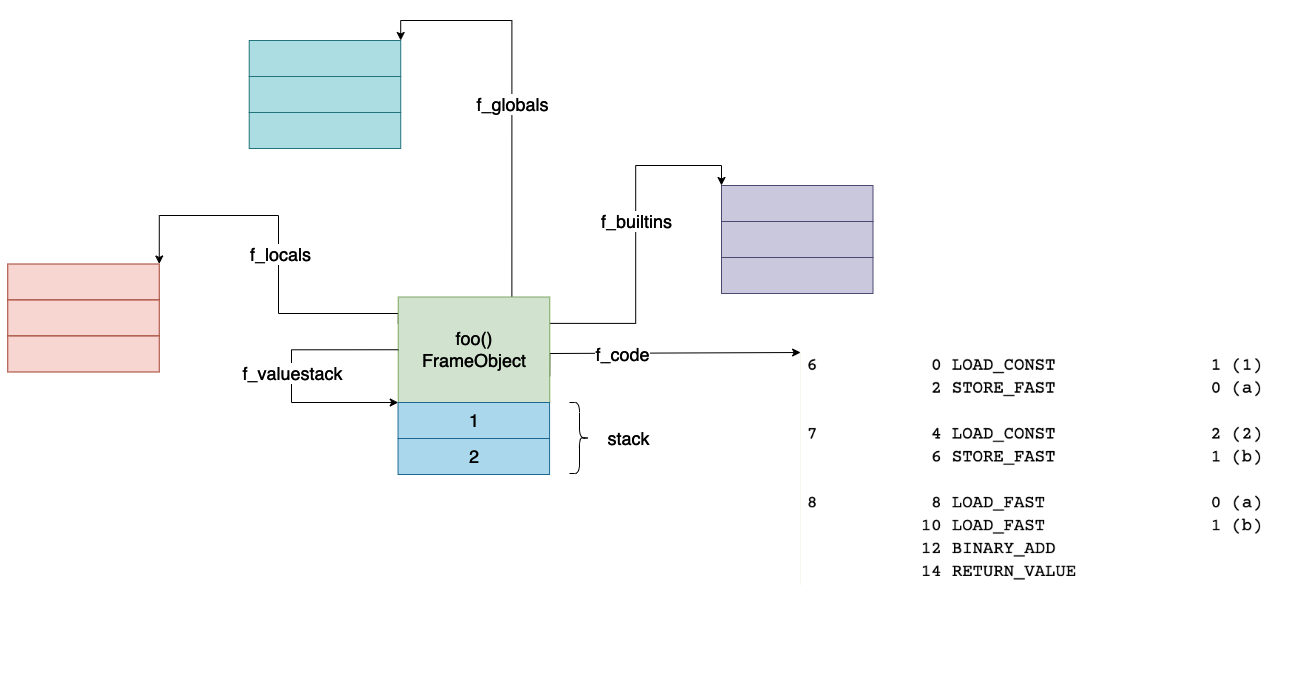
YOLOX是在YOLOv3基础上改进而来,具有与YOLOv5相媲美的性能,其模型结构如下:
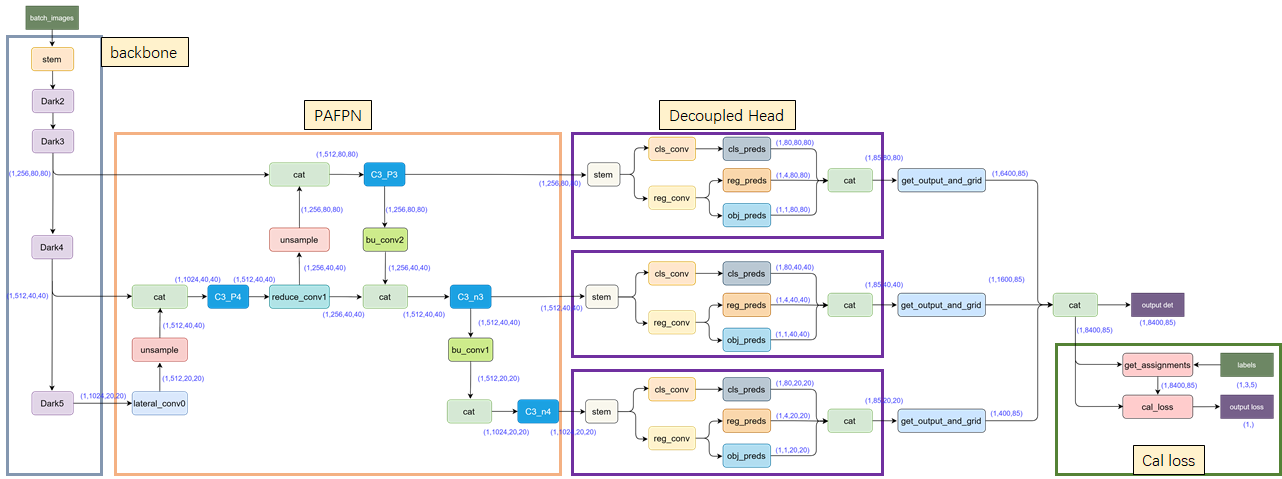
由于博主只是要用YOLOX做对比试验,因此并不需要对模型的结构太过了解。
先前博主调试过YOLOv5,YOLOv7,YOLOv8,相比而言,YOLOX的环境配置是类似的,但其参数设置太过分散,改动比较麻烦,就比如epoch这些参数竟然要放到yolox_base.py文件中去继承,而不是直接在train.py中指定。话不多说,我们开始调试过程。
环境配置
YOLOX的调试过程基本与YOLOv5类似,不同之处在于需要进行一个安装过程。
即执行:
python setup.py develop
否则在运行是会提示找不到yolox文件

运行成功后结果如下,值得注意的是,博主在本地很难成功,但在服务器上却很容易。
随后便是conda环境配置过程,基本与YOLOv5一致,可以直接使用命令配置:
conda create -n yolox python=3.8
source activate yolox
pip install -r requirements.txt
数据集配置
YOLOX使用的数据集是COCO,但不同在于其训练与测试中没有给出参数进行指定,而是直接写在了数据集读取文件中,我们只需要按照其要求修改目录即可,将数据集放到datasets/COCO文件夹下即可,当然也可以像博主这样创建软连接:
ln -s /data/datasets/coco/ /home/ubuntu/outputs/yolox/YOLOX-main/datasets/COCO/
但这种方法却一直报错:
File "/home/ubuntu/outputs/yolox/YOLOX-main/yolox/data/datasets/datasets_wrapper.py", line 177, in __del__
if self.cache and self.cache_type == "ram":
AttributeError: 'COCODataset' object has no attribute 'cache'
没办法,只能把数据集复制一份到这个目录了。
随后运行报错:
assert img is not None, f"file named {img_file} not found"
AssertionError: file named /home/ubuntu/outputs/yolox/YOLOX-main/datasets/COCO/val2017/000000567197.jpg not found
仔细一看原来是目录结构出了问题,没有images这级目录,去掉该目录即可。
训练模型
<class 'torch.autograd.variable.Variable'>
RuntimeError: FIND was unable to find an engine to execute this computation
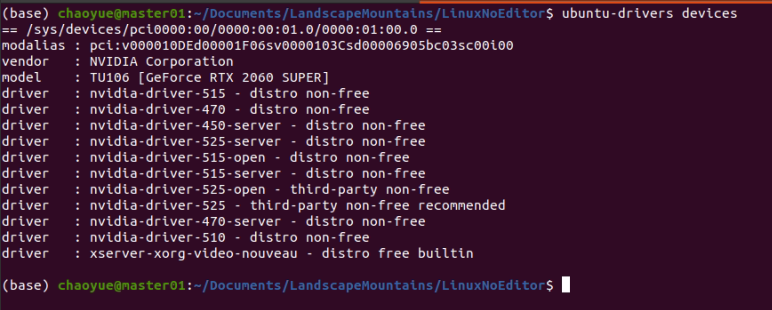
这是因为博主安装环境时默认安装torch为2.0,导致出错。换个torch版本即可:
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.6 -c pytorch -c conda-forge
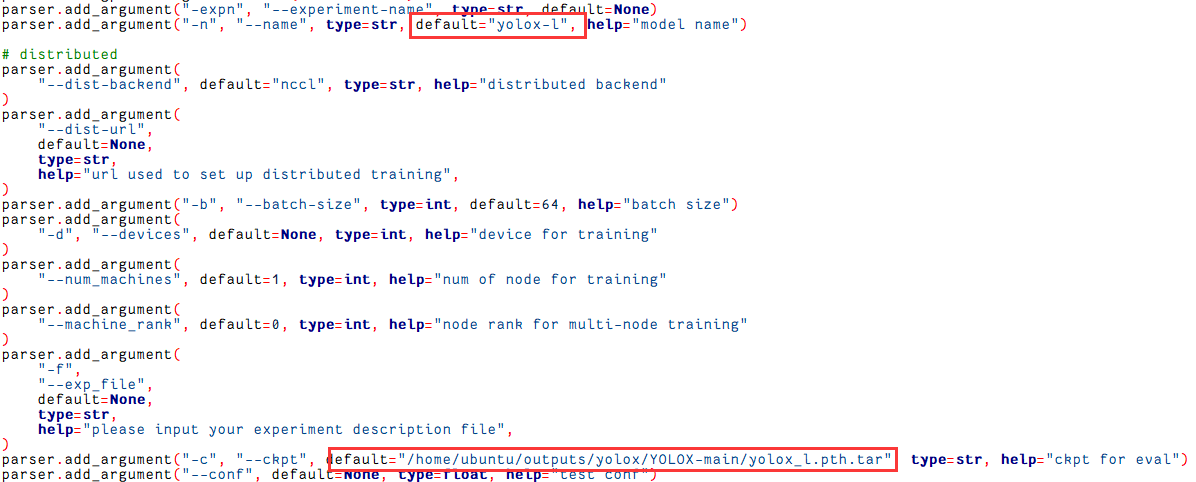
随后需要修改几个参数,首先是指定模型名称,博主使用的是yolox-l
parser.add_argument("-n", "--name", type=str, default="yolox-l", help="model name")
随后设置yolox-l的配置文件,–f代表从该文件读取,然后修改对应文件中的参数:
parser.add_argument(
"-f",
"--exp_file",
default="/home/ubuntu/outputs/yolox/YOLOX-main/exps/default/yolox_l.py",
type=str,
help="plz input your experiment description file",
)
修改/home/ubuntu/outputs/yolox/YOLOX-main/exps/default/yolox_l.py,num_class设置错了,博主习惯了DETR类模型,加上了背景类,实际上应该只有3类。
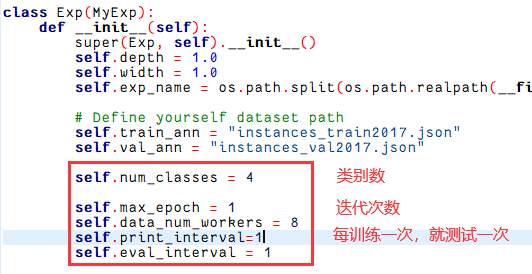
class Exp(MyExp):
def __init__(self):
super(Exp, self).__init__()
self.depth = 1.0
self.width = 1.0
self.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]
# Define yourself dataset path
self.train_ann = "instances_train2017.json"
self.val_ann = "instances_val2017.json"
self.num_classes = 4
self.max_epoch = 1
self.data_num_workers = 8
self.print_interval=1
self.eval_interval = 1
随后便是batch-szie参数了,YOLOX所占用显存还是比较大的,batch-size设置为6。
训练时间还是蛮快的,1个epoch大概45分钟左右。训练1个epoch的结果,由于没有使用预训练模型,值很低。还有一个问题,便是num_class设置错了,博主习惯了DETR类模型,加上了背景类,实际上应该只有3类。
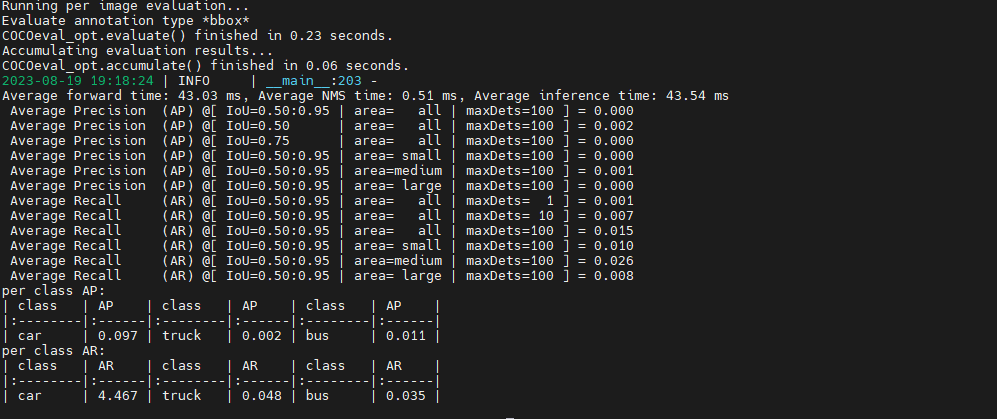
预训练模型微调
我们可以使用YOLOX-L训练好的模型当作预训练模型,在该模型上面进行微调,从而能够快速收敛,训练好的num_class=80,我们保持原样即可,即num_class=3,模型会自动处理类别不一致的问题。使用预训练模型后,迭代速度明显加快。
parser.add_argument("-c", "--ckpt", default="/home/ubuntu/outputs/yolox/YOLOX-main/yolox_l.pth.tar", type=str, help="checkpoint file")
此时训练代码便完成了。
评估模型
完成eval.py的参数配置:
python -m yolox.tools.eval -n yolox-s -c yolox_s.pth -b 64 -d 8 --conf 0.001 [--fp16] [--fuse]
当然也可以使用参数,主要修改这两个参数即可
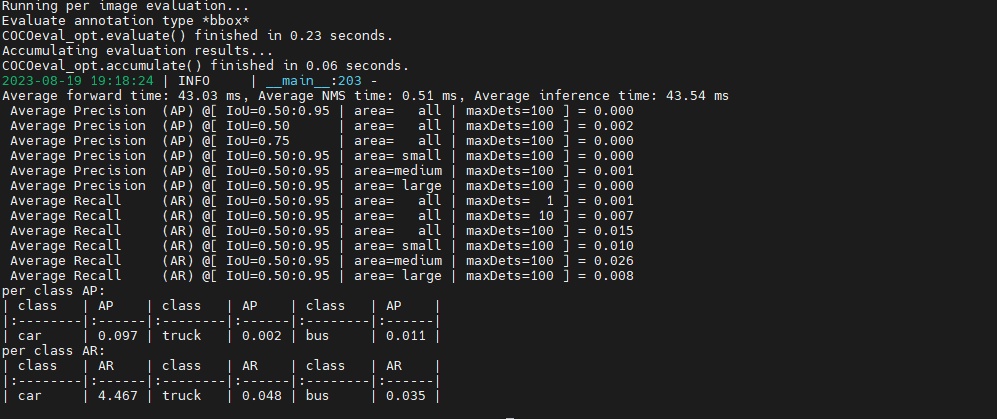
随后运行python eval.py命令即可,这里发现使用下载的权重文件会报错,于是博主自己训练了1个epoch并保存权重结果,使用这个则是没有问题的,文件保存在YOLOX_outputs中。但似乎发现了一个问题,那就是值好低呀。
模型推理
首先我们下载已经训练完成的模型,博主这里选择的是YOLOX-L,值得注意的是,下载这个文件需要翻墙。下载的权重文件为tar文件,因此需要解压:
tar -xvf yolox_l.pth.tar
但没想到却报错了:
tar: This does not look like a tar archive
tar: Skipping to next header
tar: Exiting with failure status due to previous errors
这是个BUG
解决办法:
gzip -d xxxx.tar.gz (对于.tar.gz文件的处理方式)
tar -xf xxxx.tar (对于.tar文件处理方式)
依旧不行,没办法,博主只能把其后缀名改为zip,然后使用unzip的方式解压该文件。但解压后却是一个文件夹,这与博主先前所见到的pth文件不同,果然在运行时报错:
super().init(open(name, mode)) IsADirectoryError: [Errno 21] Is a
directory: ‘/home/ubuntu/outputs/yolox/YOLOX-main/yolox_l.pth’
原来YOLOX的权重文件是不需要解压的,直接用即可,即在指定文件时为:
parser.add_argument("-c", "--ckpt", default="/home/ubuntu/outputs/yolox/YOLOX-main/yolox_l.pth.tar", type=str, help="ckpt for eval")
,指定size=224,Demo.py中给出了其参数量与计算量,

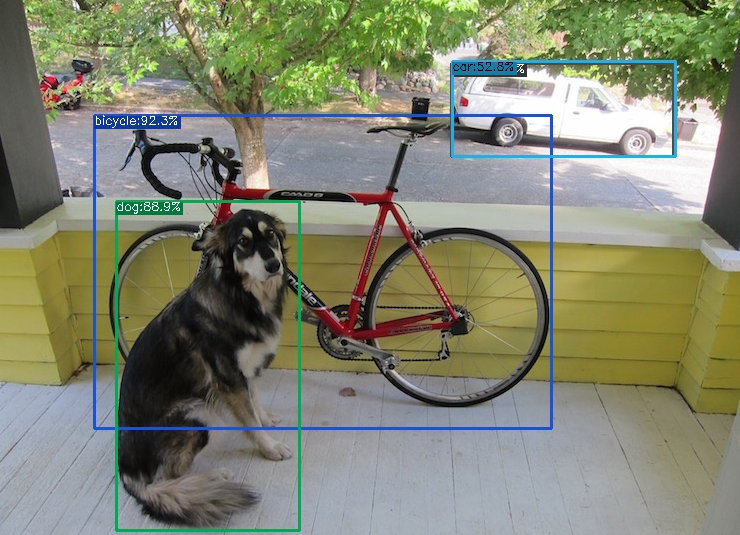
推理结果如下: