-
相比于其他的交通运输方式,铁路运输具有准时性高、连续性强、速度快、运输量大、运输成本低以及安全可靠等优点。同时由于国家高速铁路网络建设的不断推进,铁路运输逐渐成为我国客运与货运的主要运输方式。虽然铁路运输为人们出行和货物运输带来的极大的便利,但铁路网规模的扩大和列车速度的提升同时对列车运行安全带来了更大的挑战,列车运行过程中可能出现的安全隐患亟待解决。其中的铁路异物侵限问题可能会极大的影响列车的安全运行。
-
铁路异物侵入安全限界会对人民的生命财产和国家的经济利益造成极大的威胁,解决异物侵限问题迫在眉睫。传统的防止异物入侵检测的手段主要是人工线路定期巡检,但是使用人工巡检的检测方式需要消耗大量的人力并且实时性能较低,难以实现24 小时全天候的检测。异物在何时何地侵入限界内通常具有很大的不确定性,当有异物不在巡检时间内进入限界就可能会导致异物无法被检测出,从而影响铁路列车的正常运行。
-
为了克服传统检测方式存在的不足,近年来,许多传统的机器视觉方法被引入铁路异物检测领域,传统的机器视觉方法主要依靠人工设计的特征提取算子提取出的图像纹理、颜色或形状等特征完成相应的图像处理任务。但是由于该方法依赖根据经验设计出的特征提取算子,存在一定的主观性,可能无法提取出图片中的潜在特征。
-
当图片中出现遮挡或者光照异常等情况时,将提取出错误的特征信息。而铁路列车的运行环境复杂,因此使用传统的机器视觉方法可能会造成漏检和误检等情况出现,检测的可靠性并不高。这就需要寻找一种更加精确有效的检测算法来实现异物侵限检测。
-
国内外对于如何检测侵限异物保障列车安全运行进行了许多研究,其中主要可以将异物检测方法分为两个大类:第一类是接触式的检测手段,主要包括电网检测、光纤光栅检测、防护网检测等手段;第二类是非接触式检测,主要有红外检测,超声检测和计算机视觉的检测方法。
-
相较与国外,国内的铁路建设起点较晚,因此对于铁路异物侵限检测的研究也相对更晚,但后期发展迅速。考虑到使用接触式的异物检测具有的安装费用和维护费用高的缺点,我国也有学者考虑将智能识别的方法运用到铁路异物检测领域,李丹丹提出了改进的 canny 算子和双背景差分法结合的铁路异物侵限方法。此方法先用改进的 canny 算子检测出图像中存在的物体边缘,作者在传统的 canny 算法中加入了迭代式的阈值分割方法用来寻找最高阈值和最低阈值。该方法能够极大的抑制伪边缘,并提取出图像的真实边缘,之后利用直线边缘提取算法提取出铁路轨道的直线边缘,根据直线边缘就可以确定异物检测的范围。考虑到使用单独的某个图像差分算法检测出的结果容易受到噪声干扰,因此作者将背景差分法和帧间差分法进行结合,此方法能够在异物检测范围内检测出的异物轮廓,并且受到外界环境的干扰较小。随着深度学习技术的兴起,国内出现不少学者将深度学习的方法加入到异物智能识别中。姜峰运用生成对抗网络的特点,利用生成网络生成与输入图像相同的图像,如果当图像中存在异物时生成网络产生的图像与原始图像会产生一定的差异,通过判断差异值的大小就可以判断出检测区域内是否存在侵限物体。此方法可以避免训练深度学习模型需要的训练集数量不足的问题,但是当检测环境发生变化时生成网络产生的图片可能会与原图产生差异从而造成误检现象出现,并且这种方式没有办法对异物具体的侵限位置和异物的类别进行判断。陶慧青将 Faster-RCNN 目标检测算法用在异物检测中,并且使用全局平均池化替代了原算法中的全连接层。此方法不仅能够有效的检测出异物的位置还能预测出异物所属的类别。考虑到 Faster-RCNN 算法实时性不够的问题,于晓英等学者采用 YOLOv1算法进行异物检测,检测的准确度虽然没有 Faster-RCNN 算法高,但是检测实时性很高。基于深度学习的铁路异物侵限检测算法研究
-
许多学者将目光投向了智能检测方向,使用传统的机器视觉或图像差分的方法来进行异物检测。但铁路运营环境复杂多变,依靠根据经验设计的特征提取算子无法适应复杂的检测环境,并不具备良好的泛化能力,容易造成漏检和误检的情况。
-
帧间差分法是当检测环境内有运动目标时候使用的检测方法,其利用的原理是当有移动物体存在于视频中时候,视频中不同帧的图像的像素之间存在一定的差异。因此使用相邻帧之间的图像进行差分运算,就能够得到图像之间的像素的差值,当此差值达到设定的阈值时,就能够确定是否有运动的物体存在于检测场景中。
-
背景差分法是将图像分成前景和背景,前景即需要检测的物体,背景即除了检测物体之外的其他区域,将包含前景与背景的图像与只包含背景的图像进行差分计算,当差分结果大于给定的阈值时,即判断当前的检测场景中存在物体。
-
传统的机器视觉方法主要先将检测图片划分多个检测窗口,之后对每一个检测窗口采用特征描述子提取检测窗口内的特征,之后基于提取出的特征采用分类器判断前景和背景区域。在对图像进行特征提取之前,需要将图片划分成多个检测窗口,每个检测窗口内都包含一定面积的像素区域,在检测前需要预先设定检测区域的大小和检测窗口移动的步长,每个检测窗口可能包含有待检测物体的局部特征。这种按检测窗口逐个对图片特征进行提取的方法速度缓慢并且操作繁琐因此并不适用于实时性高的场合。
-
根据特征的抽象程度和所包含的语义信息的大小可以分为三类:浅层特征、中层特征和深层特征。浅层特征表示使用简单的特征提取方式就能从图像当中提取出的特征,抽象程度较低,包含的信息含义也能够直观理解,比如颜色、纹理、形状等特征;中层特征指的是在浅层特征的基础上通过多种特征融合的方法得到的综合特征,比如将图像的纹理特征和颜色特征进行融合的特征提取方式 LOMO;深层特征指的是利用深度神经网络对图像数据进行挖掘后得到的特征,这类特征受外界环境影响较小,能够适应各种应用场景,缺点是抽象程度较高,无法知道特征具体表示的含义。
-
传统的机器视觉方法对特征的提取采用的是手工设计的特征描述子,提取的是主要是图像的浅层特征和中层特征,现有图像特征研究使用的特征描述子主要有提取图像颜色特征的颜色直方图、颜色矩和颜色集;提取图像纹理特征的 LBP 和灰度共生矩阵;提取图像边缘特征的 Canny 算子和 Sobel 算子。这类特征描述子基于图像本身固有的特征,不需要依靠大量数据进行学习和训练,但易受到诸如光照、图像拍摄角度等外界环境影响,而且特征提取过程复杂,提取时间较长。对于复杂的铁路场景,当异常环境情况出现时,可能会对检测结果造成很大的影响。
-
传统的机器视觉方法最常用的分类器主要是 SVM 分类器,使用HOG 算子提取图像的梯度方向特征,最后使用 SVM 对得到的梯度信息进行分类,区分行人和背景的梯度方向,但对大规模样本进行分类的时候,需要储存和计算大型矩阵,这将会消耗大量的计算资源和计算时间,并且在预测时需要单独训练 SVM 分类器,使网络的训练过程变得更加复杂。
-
深度学习方法与传统计算机视觉方法最大的不同就在于摒弃了手工设计的特征提取器,转而使用足够深的特征卷积神经网络来提取图像中的抽象特征,虽然无法描述出提取出的特征的具体含义,但此类特征相比手工特征描述子提取出的特征具有更加丰富的语义信息,能够表征待检测的物体。
-
一个函数能够作为神经网络的激活函数应当具有以下五个性质:
-
非线性,线性函数对增加神经网络的表达能力并无作用,还会因此增加网络的计算量,因此,选用的激活函数必须满足非线性。
-
连续可微。神经网络通常运用梯度下降法来求解代价函数的最小值,运用反向反向传播算法来计算神经网络每一处参数的梯度,所以必须保证在激活函数的可微性。
-
激活函数必须含有非饱和区段,函数的饱和区段是指对函数求导为零的区段,在饱和区段时,使用反向传播算法的到的梯度大小为零,神经网络将无法进行梯度下降。
-
单调性,当激活函数满足单调性时,激活函数的导数正负性不会发生改变,这会使得梯度的方向不发生改变,有利于梯度下降法的进行(感觉不太对🙅,swish, softmax)。
-
在原点处近为线性,神经网络在训练前需要对网络的每一处参数进行初始化,当初始化参数接近于零时,在原点处近似为线性的激活函数有助于加快神经网络的学习(有些激活函数都不过原点)。
-
激活函数的导函数值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
-
-
知道神经网络模拟了人类神经元的工作机理,激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。在神经元中,输入的input经过一系列加权求和后作用于另一个函数,这个函数就是这里的激活函数。类似于人类大脑中基于神经元的模型,激活函数最终决定了是否传递信号以及要发射给下一个神经元的内容。在人工神经网络中,一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出。标准的计算机芯片电路可以看作是根据输入得到开(1)或关(0)输出的数字电路激活函数。
-
因为神经网络中每一层的输入输出都是一个线性求和的过程,下一层的输出只是承接了上一层输入函数的线性变换,所以如果没有激活函数,那么无论你构造的神经网络多么复杂,有多少层,最后的输出都是输入的线性组合,纯粹的线性组合并不能够解决更为复杂的问题。而引入激活函数之后,我们会发现常见的激活函数都是非线性的,因此也会给神经元引入非线性元素,使得神经网络可以逼近其他的任何非线性函数,这样可以使得神经网络应用到更多非线性模型中。
-
目标检测网络模型一般由三个模块组成,第一个部分是由上一节所述特征提取网络构成的主干网(backbone),第二个部分是用于将主干网络提取出的特征进行处理并输入给检测模块的连接模块(neck),第三个部分是用于定义损失函数以及将连接模块的输出特征处理成物体预测信息的检测模块。现有的目标检测模型,可以根据是否使用区域建议网络(RPN)分为“一阶段”和“二阶段”目标检测模型,两种检测模型的总体框架如图 2-15 所示,其中“二阶段”网络主要包括 RCNN 系列网络,“一阶段”网络主要包括 YOLO 系列网络。
-
在图像处理领域,对于一张采集到的图片,通常由不同的频率分量组成,其中高频部分能够保留比较完整的图片细节信息,而低频部分通常保留着图像中的全局结构。由于图片中的低频部分保存的是图片中的全局结构,所以存在着大量的冗余信息,通过压缩低频部分的图像信息可以达到在保留图像大致结构的基础上,减少信息冗余。相似的,对于卷积层输出的特征图也能够看成是不同频率分量的组合,对于输出特征图的低频部分,每一个位置都独立的储存着自己的特征描述子,而忽略了那些可以共同储存和处理的相邻区域的特征描述子,这就造成了在进行卷积运算时不必要的计算量的产生,因此可以将经过卷积层处理后的特征图分解成不同频率的两个部分,通过对其中低频部分的进行压缩处理,使得特征图中相邻位置的相似特征信息可以同时被储存和处理,这样就可以节省卷积的计算量,节约设备中的计算资源。
-
在卷积神经网络中,传统的卷积方式是使用一定大小的卷积核上的每一个元素乘以原图片或特征图上相应位置的特征值,最后相加,将得到的数值作为经过卷积操作的到的特征图上对应位置的特征值,具体计算公式如式
- Y i , j = ∑ i , j ∈ N k W i + k − 1 2 , j + k − 1 2 T X p + i , q + j Y_{i,j}=\sum_{i,j\in N_k}W^T_{i+\frac{k-1}{2},j+\frac{k-1}{2}}X_{p+i,q+j} Yi,j=i,j∈Nk∑Wi+2k−1,j+2k−1TXp+i,q+j
-
本文对低频部分的特征在空间分辨率上进行了压缩处理,因此在使用上式的卷积方式对不同的频率特征进行处理时,需要先将低频部分的特征图上采样到和高频特征图的大小一致后再沿着通道方向进行拼接,然后将拼接好的特征图输入到卷积神经网络中进行特征提取,这将会给网络带来额外的计算量和存储量,相当于抵消了低频特图压缩给网络带来的计算复杂性的降低,而 Octave 卷积可以解决这个问题。Octave卷积的目的是有效的处理高低频率的特征张量,并且可以完成不同频率特征之间信息的交互,首先将 X 和 Y 作为待分解的输入特征和经过卷积层处理后的输出特征,那么经过分解后,输出特征 Y = { Y H + Y L } Y=\{Y^H+Y^L\} Y={YH+YL},其中 Y H = Y H → H + Y L → H , Y L = Y L → L + Y H → L Y^H=Y^{H→H}+Y^{L→H},Y^L=Y^{L→L}+Y^{H→L} YH=YH→H+YL→H,YL=YL→L+YH→L,式中的 Y H → H Y^{H→H} YH→H 和 Y L → L Y^{L→L} YL→L表示同频率特征图之间的更新, Y L → H Y^{L→H} YL→H和 Y H → L Y^{H→L} YH→L 表示不同频率特征图之间的信息交流。为了能够分别计算不同频率的特征,Octave 卷积将卷积核 W 分为两个部分即 W H = { W H → H , W L → H } W^H=\{W^{H→H},W^{L→H}\} WH={WH→H,WL→H},其中的 W H W^H WH 和 W L W^L WL 同样可以被分解为频率内和频率间两个分即 W H = { W H → H , W L → H } W^H=\{W^{H→H},W^{L→H}\} WH={WH→H,WL→H} 和 W H = { W L → L , W H → L } W^H=\{W^{L→L},W^{H→L}\} WH={WL→L,WH→L},Octave 卷积的计算方式和 k* k 卷积核形状如图示。
-
下表 为 Octave 卷积的不同计算通道的计算复杂度,其中假设输入特征图的通道数等于输出特征图的通道数等于 c,即 c = c i n = c o u t c=c_{in}=c_{out} c=cin=cout ,输入特征图低频特征通道数占总通道数的比率等于输出特征图低频特征通道数占总通道数的比率等于,即 α = α i n = α o u t \alpha=\alpha_{in}=\alpha_{out} α=αin=αout 。
-

-
可知新型卷积的计算复杂度为 ( 1 − 0.75 α ( 2 − α ) ) ∗ h ∗ w ∗ k 2 ∗ c 2 (1-0.75\alpha(2-\alpha))*h*w*k^2*c^2 (1−0.75α(2−α))∗h∗w∗k2∗c2 ,传统卷积得到的计算复杂度为 h ∗ w ∗ k 2 ∗ c 2 h*w*k^2*c^2 h∗w∗k2∗c2 。当 取 0.5 的时,新型卷积的计算复杂度只有传统卷积的 0.44 倍。
-
-
Octave卷积的主题思想来自于图片的分频思想,首先认为图像可进行分频:
-
低频部分:图像低频部分保存图像的大体信息,信息数据量较少
-
高频部分:图像高频部分保留图像的细节信息,信息数据量较大
-
class OctaveConv(pt.nn.Module): def __init__(self,Lin_channel,Hin_channel,Lout_channel,Hout_channel, kernel,stride,padding): super(OctaveConv, self).__init__() if Lout_channel != 0 and Lin_channel != 0: self.convL2L = pt.nn.Conv2d(Lin_channel,Lout_channel, kernel,stride,padding) self.convH2L = pt.nn.Conv2d(Hin_channel,Lout_channel, kernel,stride,padding) self.convL2H = pt.nn.Conv2d(Lin_channel,Hout_channel, kernel,stride,padding) self.convH2H = pt.nn.Conv2d(Hin_channel,Hout_channel, kernel,stride,padding) elif Lout_channel == 0 and Lin_channel != 0: self.convL2L = None self.convH2L = None self.convL2H = pt.nn.Conv2d(Lin_channel,Hout_channel, kernel,stride,padding) self.convH2H = pt.nn.Conv2d(Hin_channel,Hout_channel, kernel,stride,padding) elif Lout_channel != 0 and Lin_channel == 0: self.convL2L = None self.convH2L = pt.nn.Conv2d(Hin_channel,Lout_channel, kernel,stride,padding) self.convL2H = None self.convH2H = pt.nn.Conv2d(Hin_channel,Hout_channel, kernel,stride,padding) else: self.convL2L = None self.convH2L = None self.convL2H = None self.convH2H = pt.nn.Conv2d(Hin_channel,Hout_channel, kernel,stride,padding) self.upsample = pt.nn.Upsample(scale_factor=2) self.pool = pt.nn.AvgPool2d(2) def forward(self,Lx,Hx): if self.convL2L is not None: L2Ly = self.convL2L(Lx) else: L2Ly = 0 if self.convL2H is not None: L2Hy = self.upsample(self.convL2H(Lx)) else: L2Hy = 0 if self.convH2L is not None: H2Ly = self.convH2L(self.pool(Hx)) else: H2Ly = 0 if self.convH2H is not None: H2Hy = self.convH2H(Hx) else: H2Hy = 0 return L2Ly+H2Ly,L2Hy+H2Hy
-
-
OctConv 是一种即插即用的卷积单元,可以直接替代传统的卷积,而无需对网络架构进行任何调整。在自然的图像中,信息以不同的频率传递,其中较高的频率通常以精细的细节编码,较低的频率通常以全局结构编码。
-
在这项工作中,作者提出将混合特征映射根据其频率进行分解,并设计了一种全新的卷积运算:Octave Convolution (OctConv),用以存储和处理在较低空间分辨率下空间变化 “较慢” 的特征图,从而降低了内存和计算成本。
-
通过简单地用 OctConv 替代卷积,我们可以持续提高图像和视频识别任务的精度,同时降低内存和计算成本。
-
卷积神经网络 (CNNs) 在许多计算机视觉任务中都取得了显著的成功,并且随着最近的研究在降低密集模型参数和特征图通道维数的固有冗余,它们的效率不断提高。然而,CNN 生成的特征图在空间维度上也存在大量冗余,其中每个位置独立存储自己的特征描述符,忽略了可以一起存储和处理的相邻位置之间的公共信息。
基于深度学习的铁路异物侵限检测算法研究_整体认知感觉欠点意思,但是有一个新的变形卷积-Octave 卷积
news2026/2/10 17:52:27

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/899807.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
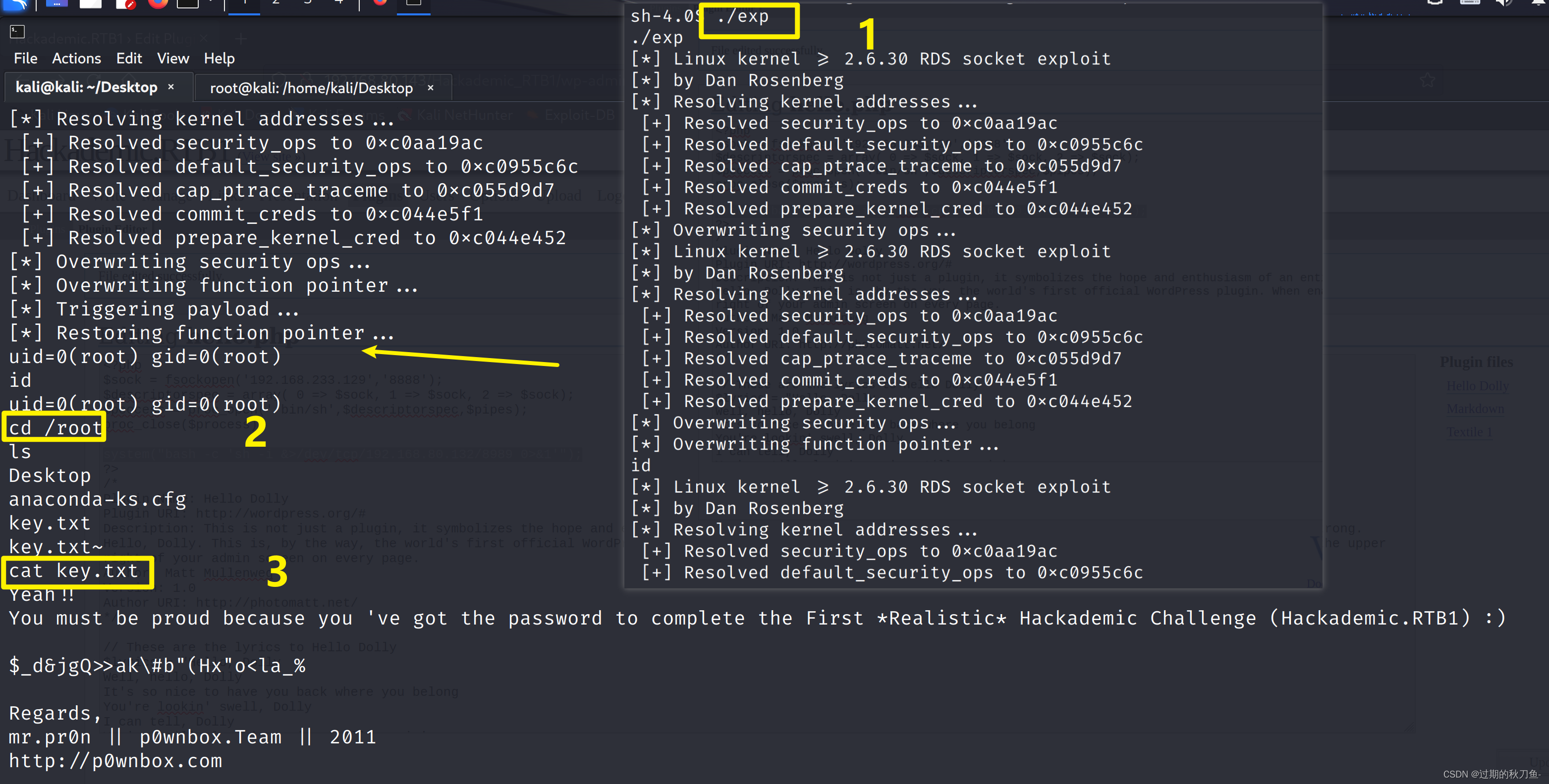
Vulnhub系列靶机 Hackadmeic.RTB1
系列:Hackademic(此系列共2台) 难度:初级 信息收集
主机发现
netdiscover -r 192.168.80.0/24端口扫描
nmap -A -p- 192.168.80.143访问80端口 使用指纹识别插件查看是WordPress 根据首页显示的内容,点击target 点击…
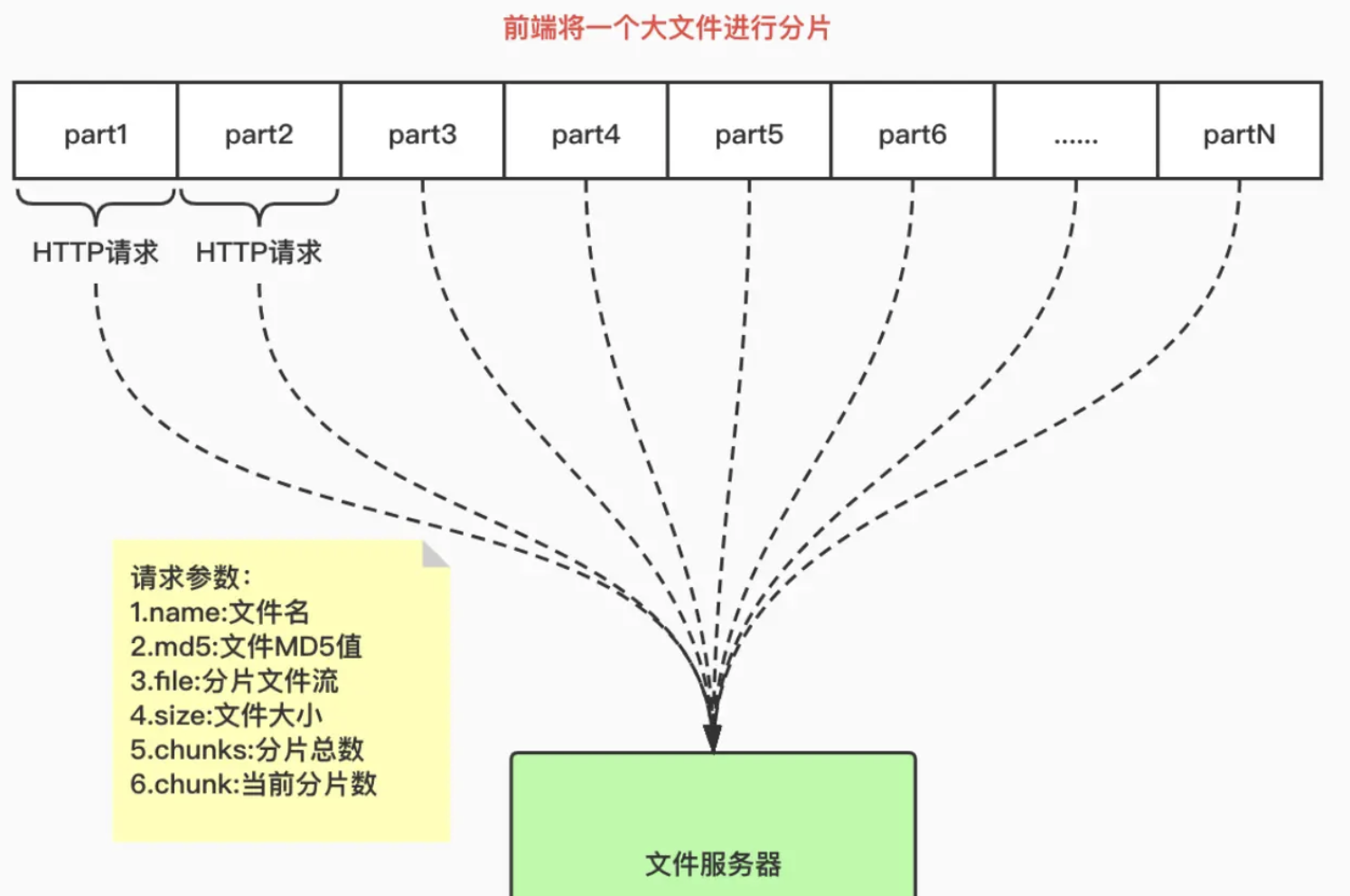
【前端面试】中大文件上传/下载:中等文件代理服务器放行+大文件切片传输+并发请求+localstorage实现断点续传
目录
中等文件代理服务器放行:10MB为单位
proxy
nginx
大文件切片:100MB为单位
断点:存储切片hash
前端方案A
localstorage
后端方案B
服务端
上传
前端
后端
下载
前端
后端
多个大文件传输:spark-md5
哈希碰撞…

002-Nacos 简单集群模式源码解析
目录 介绍架构分析添加实例-同步信息给其他集群服务添加实例-提交同步任务添加实例-执行同步任务实例健康状态监控 介绍 Nacos 启动默认会使用集群模式,也就是没有带有-m standalone 的时候就是用的简单集群模式 另外我们再分析单机模式注册实例的时候最后一部分是把…
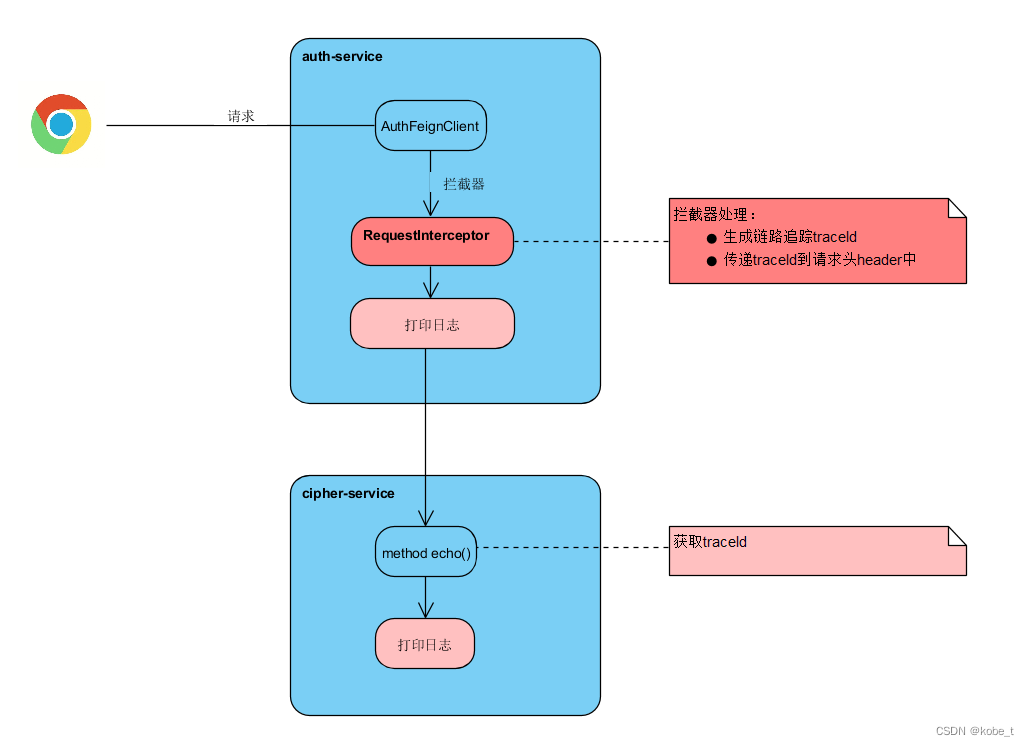
Spring Cloud 系列之OpenFeign:(7)链路追踪zipkin
传送门
Spring Cloud Alibaba系列之nacos:(1)安装
Spring Cloud Alibaba系列之nacos:(2)单机模式支持mysql
Spring Cloud Alibaba系列之nacos:(3)服务注册发现
Spring Cloud 系列之OpenFeign:(4)集成OpenFeign
Spring Cloud …
springboot+Vue--打基础升级--(二)写个主菜单导航界面
1. 华为OD机考题 答案 2023华为OD统一考试(AB卷)题库清单-带答案(持续更新) 2023年华为OD真题机考题库大全-带答案(持续更新) 2. 面试题 一手真实java面试题:2023年各大公司java面试真题汇总--…

ansible(2)-- ansible常用模块
部署ansible:ansible(1)-- 部署ansible连接被控端_luo_guibin的博客-CSDN博客 目录 一、ansible常用模块 1.1 ping 1.2 command 1.3 raw 1.4 shell 1.5 script 1.6 copy 1.7 template 1.8 yum 11.0.1.13 主控端(ansible)11.0.1.12 被控端(k8s…

K8S deployment挂载
挂载到emptyDir
挂载在如下目录,此目录是pod所在的node节点主机的目录,此目录下的data即对应容器里的/usr/share/nginx/html,实现目录挂载 apiVersion: apps/v1
kind: Deployment
metadata:annotations:deployment.kubernetes.io/revision: …
Qt实现简单的漫游器
文章目录 Qt的OpenGL窗口GLSL的实现摄像机类的实现简单的漫游器 Qt的OpenGL窗口 Qt主要是使用QOpenGLWidget来实现opengl的功能。 QOpenGLWidget 提供了三个便捷的虚函数,可以重载,用来重新实现典型的OpenGL任务:
paintGL:渲染…

零基础入门网络安全,收藏这篇不迷茫【2023最新】
前言
最近收到不少关注朋友的私信和留言,大多数都是零基础小友入门网络安全,需要相关资源学习。其实看过的铁粉都知道,之前的文里是有过推荐过的。新来的小友可能不太清楚,这里就系统地叙述一遍。 01.简单了解一下网络安全
说白…

【ARM Linux 系统稳定性分析入门及渐进12 -- GDB内存查看命令 “x“(examine)】
文章目录 gdb 内存查看命令 examine 上篇文章:ARM Linux 系统稳定性分析入门及渐进11 – GDB( print 和 p 的使用| 和 ::的使用|ptype|{<type>} <addr> )
gdb 内存查看命令 examine
examine是…

【C# 基础精讲】LINQ 基础
LINQ(Language Integrated Query)是一项强大的C#语言特性,它使数据查询和操作变得更加简洁、灵活和可读性强。通过使用LINQ,您可以使用类似SQL的语法来查询各种数据源,如集合、数组、数据库等。本文将介绍LINQ的基础概…
Kvm配置ovs网桥
环境:部署在kvm虚拟环境上(让虚拟机和宿主机都可以直接从路由器获取到独立ip)
1、安装ovs软件安装包并启动服务(一般采用源码安装,此处用yum安装)
yum install openvswitch-2.9.0-3.el7.x86_64.rpm
syste…

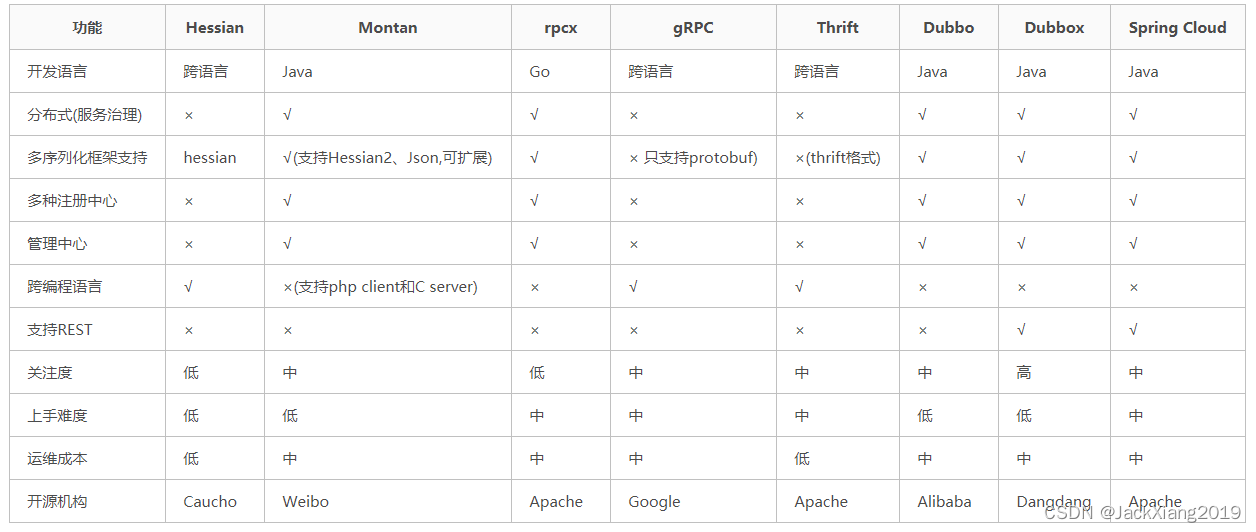
第一节 Dubbo框架的介绍
1. 什么是Dubbo ? 官⽹地址: http://dubbo.apache.org/zh/ ⽬前,官⽹上是这么介绍的:Apache Dubbo 是⼀款⾼性能、轻量级的开源 Java 服务 框架 在⼏个⽉前,官⽹的介绍是:Apache Dubbo 是⼀款⾼性能、轻…
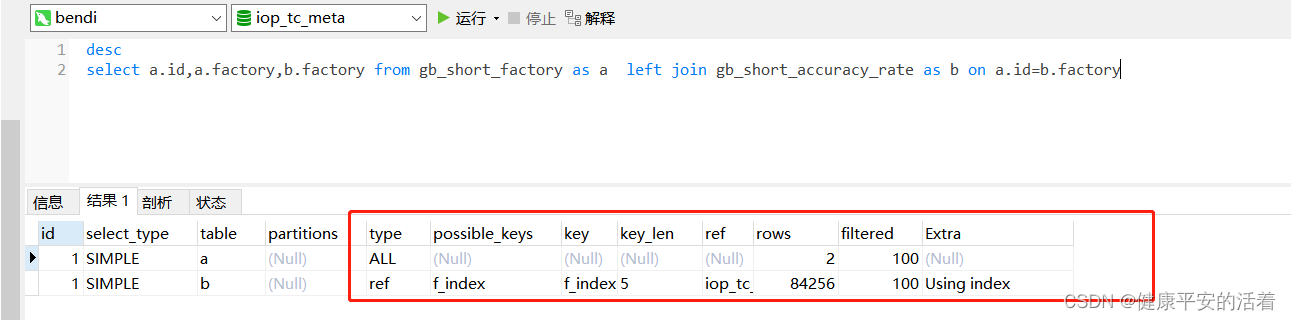
mysql的两张表left join 进行关联后,索引进行优化案例
一 mysql的案例
1.1 不加索引情况
1.表1没加索引 2.表2没加索引
3.查看索引 1.2 添加索引
1.表1添加索引 2.表2添加索引 3.查看
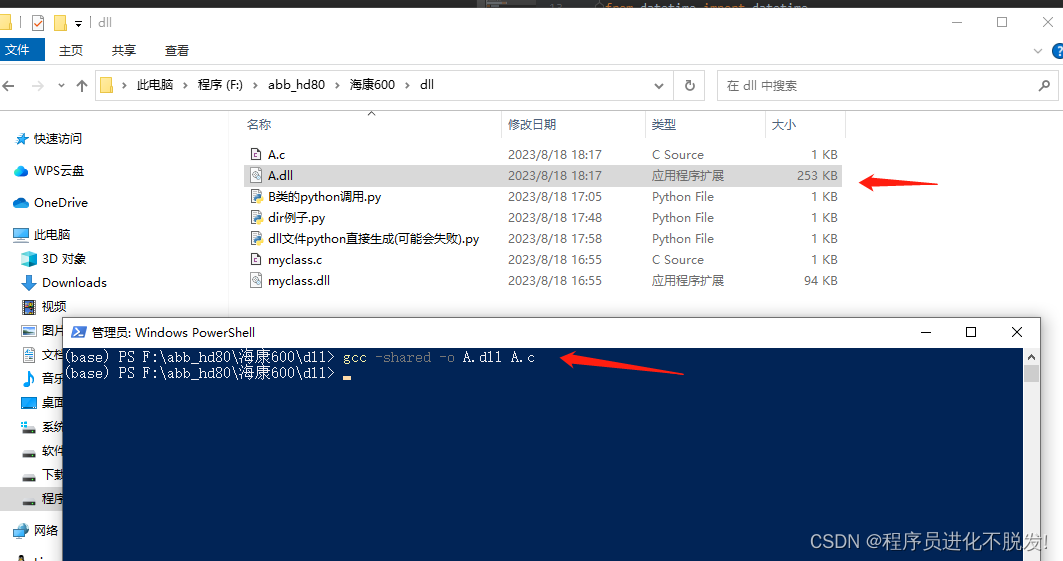
python使用dir()函数获取对象中可用的属性和方法(看不到python源码又想知道怎么调用,DLL调用分析,SDK二次开发技巧)
有时候调用一些SDK,但是人家又是封装成dll文件形式调用的,这时没法看源码,也不想看其对应的开发文档(尤其有些开发文档写得还很难懂,或者你从某个开源社区拿过来,就根本没找到开发文档)…

回归预测 | MATLAB实现IPSO-SVM改进粒子群优化算法优化支持向量机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现IPSO-SVM改进粒子群优化算法优化支持向量机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现IPSO-SVM改进粒子群优化算法优化支持向量机多输入单输出回归预测(多指标,多图…
回归预测 | MATLAB实现WOA-BP鲸鱼优化算法优化BP神经网络多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现WOA-BP鲸鱼优化算法优化BP神经网络多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现WOA-BP鲸鱼优化算法优化BP神经网络多输入单输出回归预测(多指标,多图)效果一览基本…