目录
中等文件代理服务器放行:10MB为单位
proxy
nginx
大文件切片:100MB为单位
断点:存储切片hash
前端方案A
localstorage
后端方案B
服务端
上传
前端
后端
下载
前端
后端
多个大文件传输:spark-md5
哈希碰撞
总结
Blob.prototype.slice 切片
web-worker 在 worker 线程中用spark-md5 根据文件内容算hash
promise.allSettled()并发请求
中等文件代理服务器放行:10MB为单位
proxy
proxy_buffering来控制是否启用代理缓冲,
proxy_buffer_size和proxy_buffers来调整缓冲区的大小
nginx
在nginx.conf配置文件中,找到或添加一个 http、server 或 location 块,具体位置取决于希望修改的范围。在该块中,添加或修改 client_max_body_size 指令
http {
...
server {
...
location /upload {
client_max_body_size 100M;
...
}
...
}
...
}
检查配置文件是否有语法错误:
sudo nginx -t
如果没有报告错误,重新加载Nginx以使配置更改生效:
sudo systemctl reload nginx

React版本见:前端文件流、切片下载和上传:优化文件传输效率与用户体验 - 掘金
<pre> 标签可定义预格式化的文本。
<pre> 标签的一个常见应用就是用来表示计算机的源代码
Blob(Binary Large Object)对象:存储二进制数据
ArrayBuffer 对象类型:缓存二进制数据
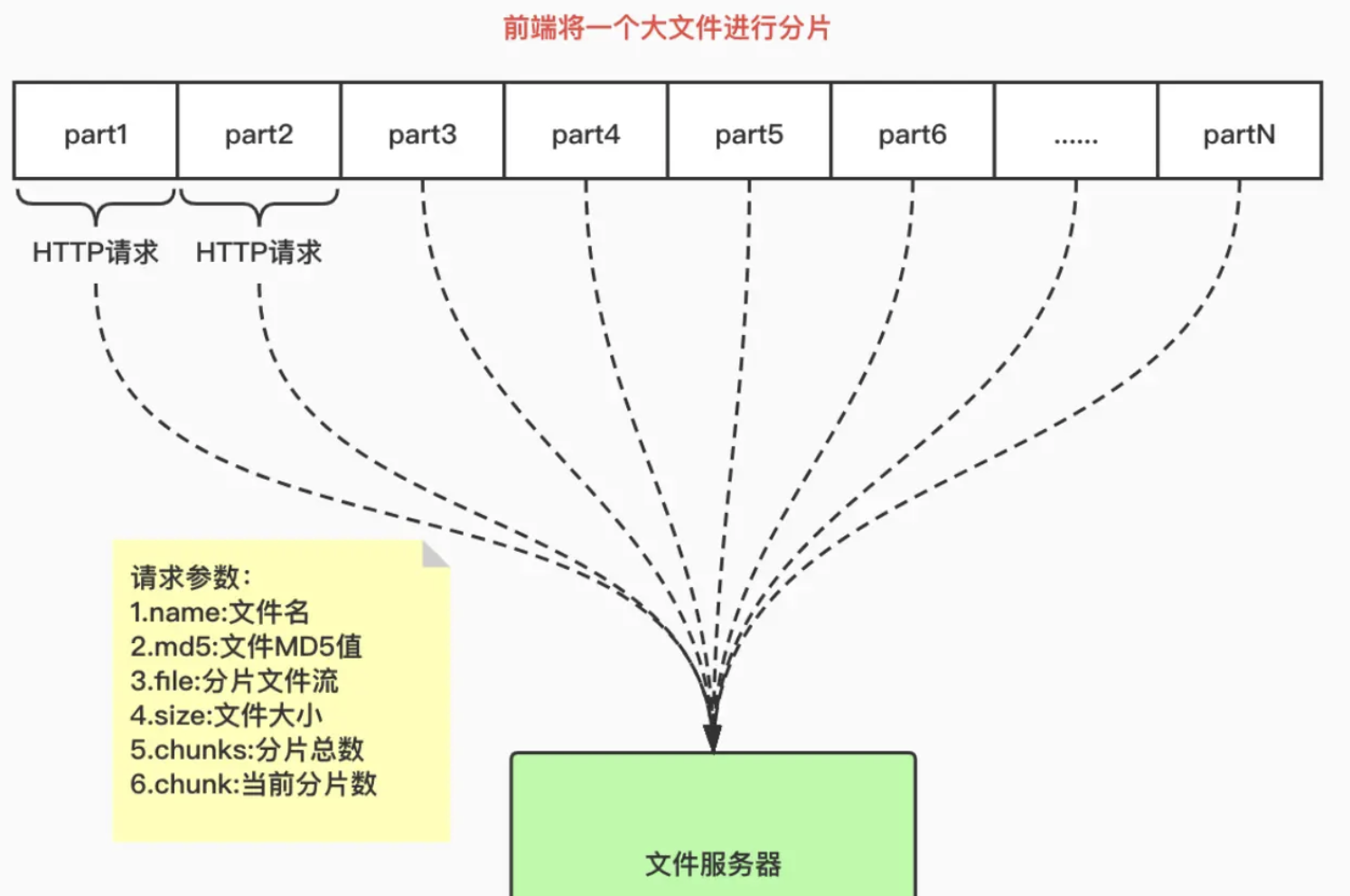
大文件切片:100MB为单位
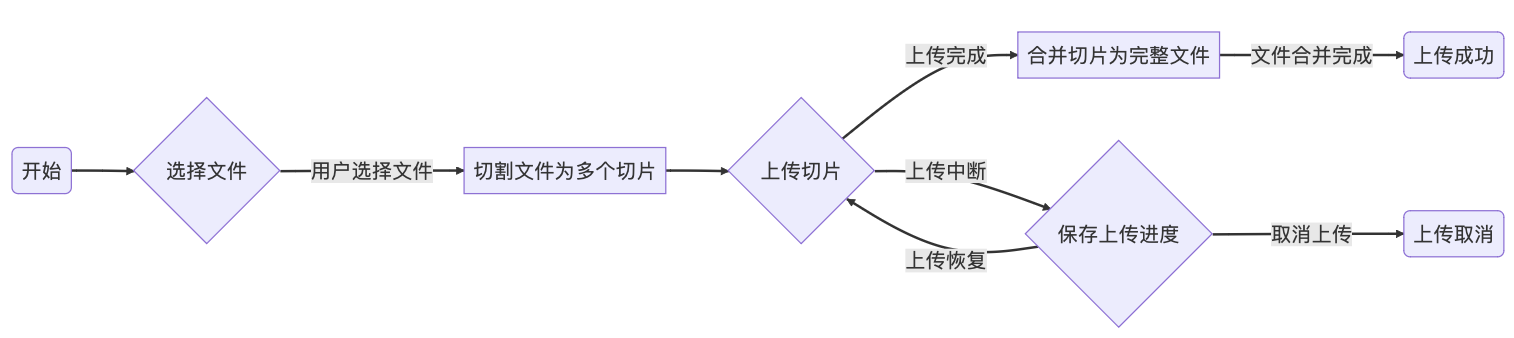
每个片段大小通常在几百KB到几MB之间
断点:存储切片hash
前端方案A
localstorage
-
容量限制: 不同浏览器可能有不同的限制,但通常容量限制在 5MB 到 10MB 之间。用于存储断点下标够用
-
遵循同源策略
-
持久性: 关闭后也存在,只有用户主动清除浏览器缓存或使用代码删除数据,
-
访问同步,在读取或写入大量数据时,可能阻塞
-
数据类型: string
-
适用场景:容量小,非敏感,持久性数据。如果需要处理更大容量的数据,或者需要在不同域之间共享数据,可以考虑 IndexedDB 或服务器端存储。
这样下次上传就可以跳过之前已上传的部分,有两种方案实现记忆的功能
后端方案B
服务端
前端方案有一个缺陷,如果换了个浏览器就localstorage就失效了,所以推荐后者
上传
前端
<template>
<div>
<input type="file" @change="handleFileChange" />
<button @click="startUpload">Start Upload</button>
</div>
</template>
<script>
export default {
data() {
return {
file: null,
chunkSize: 1024 * 1024, // 1MB
totalChunks: 0,
uploadedChunks: [],
};
},
methods: {
handleFileChange(event) {
this.file = event.target.files[0];
},
startUpload() {
if (this.file) {
this.totalChunks = this.getTotalChunks();
this.uploadedChunks = JSON.parse(localStorage.getItem('uploadedChunks')) || [];
this.uploadChunks(0);
}
},
uploadChunks(startChunk) {
if (startChunk >= this.totalChunks) {
console.log('Upload complete');
localStorage.removeItem('uploadedChunks');
return;
}
//模拟每次至多发起5个并发请求,实际开发中根据请求资源的限定决定?
const endChunk = Math.min(startChunk + 5, this.totalChunks);
const uploadPromises = [];
for (let chunkIndex = startChunk; chunkIndex < endChunk; chunkIndex++) {
if (!this.uploadedChunks.includes(chunkIndex)) {
const startByte = chunkIndex * this.chunkSize;
const endByte = Math.min((chunkIndex + 1) * this.chunkSize, this.file.size);
const chunkData = this.file.slice(startByte, endByte);
const formData = new FormData();
formData.append('chunkIndex', chunkIndex);
formData.append('file', chunkData);
uploadPromises.push(
fetch('/upload', {
method: 'POST',
body: formData,
})
);
}
}
Promise.allSettled(uploadPromises)
.then(() => {
const newUploadedChunks = Array.from(
new Set([...this.uploadedChunks, ...Array.from({ length: endChunk - startChunk }, (_, i) => i + startChunk)])
);
this.uploadedChunks = newUploadedChunks;
localStorage.setItem('uploadedChunks', JSON.stringify(this.uploadedChunks));
this.uploadChunks(endChunk);
})
.catch(error => {
console.error('Error uploading chunks:', error);
});
},
getTotalChunks() {
return Math.ceil(this.file.size / this.chunkSize);
},
},
};
</script>后端
const express = require('express');
const path = require('path');
const fs = require('fs');
const multer = require('multer');
const app = express();
const chunkDirectory = path.join(__dirname, 'chunks');
app.use(express.json());
app.use(express.static(chunkDirectory));
const storage = multer.diskStorage({
destination: chunkDirectory,
filename: (req, file, callback) => {
callback(null, `chunk_${req.body.chunkIndex}`);
},
});
const upload = multer({ storage });
app.post('/upload', upload.single('file'), (req, res) => {
const { chunkIndex } = req.body;
console.log(`Uploaded chunk ${chunkIndex}`);
res.sendStatus(200);
});
app.listen(3000, () => {
console.log('Server started on port 3000');
});下载
前端
<template>
<div>
<button @click="startDownload">Start Download</button>
</div>
</template>
<script>
import { saveAs } from 'file-saver';
export default {
data() {
return {
totalChunks: 0,
chunkSize: 1024 * 1024, // 默认1M
fileNm: "file.txt",
downloadedChunks: [],
chunks: [], // 存储切片数据
concurrentDownloads: 5, // 并发下载数量
};
},
methods: {
startDownload() {
this.fetchMetadata();
},
fetchMetadata() {
fetch('/metadata')
.then(response => response.json())
.then(data => {
this.totalChunks = data.totalChunks;
this.chunkSize = data.chunkSize;
this.fileNm = data.fileNm;
this.continueDownload();
})
.catch(error => {
console.error('Error fetching metadata:', error);
});
},
async continueDownload() {
const storedChunks = JSON.parse(localStorage.getItem('downloadedChunks')) || [];
this.downloadedChunks = storedChunks;
const downloadPromises = [];
let chunkIndex = 0;
while (chunkIndex < this.totalChunks) {
const chunkPromises = [];
for (let i = 0; i < this.concurrentDownloads; i++) {
if (chunkIndex < this.totalChunks && !this.downloadedChunks.includes(chunkIndex)) {
chunkPromises.push(this.downloadChunk(chunkIndex));
}
chunkIndex++;
}
await Promise.allSettled(chunkPromises);
}
// 当所有切片都下载完成时 合并切片
this.mergeChunks();
},
downloadChunk(chunkIndex) {
return new Promise((resolve, reject) => {
const startByte = chunkIndex * this.chunkSize;
const endByte = Math.min((chunkIndex + 1) * this.chunkSize, this.totalChunks * this.chunkSize);
//我不太清楚实际开发中切片是靠idx,还是startByte、endByte,还是两者都用....
fetch(`/download/${chunkIndex}?start=${startByte}&end=${endByte}`)
.then(response => response.blob())
.then(chunkBlob => {
this.downloadedChunks.push(chunkIndex);
localStorage.setItem('downloadedChunks', JSON.stringify(this.downloadedChunks));
this.chunks[chunkIndex] = chunkBlob; // 存储切片数据
resolve();
})
.catch(error => {
console.error('Error downloading chunk:', error);
reject();
});
});
},
mergeChunks() {
const mergedBlob = new Blob(this.chunks);
// 保存合并后的 Blob 数据到本地文件
saveAs(mergedBlob, this.fileNm);
// 清空切片数据和已下载切片的 localStorage
this.chunks = [];
localStorage.removeItem('downloadedChunks');
},
},
};
</script>
后端
const express = require('express');
const path = require('path');
const fs = require('fs');
const app = express();
const chunkDirectory = path.join(__dirname, 'chunks');
app.use(express.json());
app.get('/metadata', (req, res) => {
const filePath = path.join(__dirname, 'file.txt');
const chunkSize = 1024 * 1024; // 1MB
const fileNm='file.txt';
const fileStats = fs.statSync(filePath);
const totalChunks = Math.ceil(fileStats.size / chunkSize);
res.json({ totalChunks, chunkSize, fileNm });
});
app.get('/download/:chunkIndex', (req, res) => {
const chunkIndex = parseInt(req.params.chunkIndex);
const chunkSize = 1024 * 1024; // 1MB
const startByte = chunkIndex * chunkSize;
const endByte = (chunkIndex + 1) * chunkSize;
const filePath = path.join(__dirname, 'file.txt');
fs.readFile(filePath, (err, data) => {
if (err) {
res.status(500).send('Error reading file.');
} else {
const chunkData = data.slice(startByte, endByte);
res.send(chunkData);
}
});
});
app.listen(3000, () => {
console.log('Server started on port 3000');
});
多个大文件传输:spark-md5
MD5(Message Digest Algorithm 5):哈希函数
若使用 文件名 + 切片下标 作为切片 hash,这样做文件名一旦修改就失去了效果,
所以应该用spark-md5根据文件内容生成 hash
webpack 的contenthash 也是基于这个思路实现的
另外考虑到如果上传一个超大文件,读取文件内容计算 hash 是非常耗费时间的,并且会引起 UI 的阻塞,导致页面假死状态,所以我们使用 web-worker 在 worker 线程计算 hash,这样用户仍可以在主界面正常的交互
// /public/hash.js
// 导入脚本
self.importScripts("/spark-md5.min.js");
// 生成文件 hash
self.onmessage = e => {
const { fileChunkList } = e.data;
const spark = new self.SparkMD5.ArrayBuffer();
let percentage = 0;
let count = 0;
// 递归加载下一个文件块
const loadNext = index => {
const reader = new FileReader();
reader.readAsArrayBuffer(fileChunkList[index].file);
reader.onload = e => {
count++;
spark.append(e.target.result);
// 检查是否处理完所有文件块
if (count === fileChunkList.length) {
self.postMessage({
percentage: 100,
hash: spark.end()
});
self.close();
} else {
// 更新进度百分比并发送消息
percentage += 100 / fileChunkList.length;
self.postMessage({
percentage
});
// 递归调用以加载下一个文件块
loadNext(count);
}
};
};
// 开始加载第一个文件块
loadNext(0);
};
-
切片hash/传输等目的都是为了
-
内存效率: 对于大文件,一次性将整个文件加载到内存中可能会导致内存占用过高,甚至造成浏览器崩溃。通过将文件切成小块,在处理过程中只需要操作单个块,减小了内存的压力。
-
性能优化: 如果直接将整个文件传递给哈希函数,可能会导致计算时间较长,尤其是对于大文件。分成小块逐个计算哈希值,可以并行处理多个块,提高计算效率。
-
错误恢复: 在上传或下载过程中,网络中断或其他错误可能会导致部分文件块没有传输成功。通过分块计算哈希,你可以轻松检测到哪些块没有正确传输,从而有机会恢复或重新传输这些块。
-
// 生成文件 hash(web-worker) calculateHash(fileChunkList) { return new Promise(resolve => { // 创建一个新的 Web Worker,并加载指向 "hash.js" 的脚本 this.container.worker = new Worker("/hash.js"); // 向 Web Worker 发送文件块列表 this.container.worker.postMessage({ fileChunkList }); // 当 Web Worker 发送消息回来时触发的事件处理程序 this.container.worker.onmessage = e => { const { percentage, hash } = e.data; // 更新 hash 计算进度 this.hashPercentage = percentage; if (hash) { // 如果计算完成,解析最终的 hash 值 resolve(hash); } }; }); }, // 处理文件上传的函数 async handleUpload() { if (!this.container.file) return; // 将文件划分为文件块列表 const fileChunkList = this.createFileChunk(this.container.file); // 计算文件 hash,并将结果存储在容器中 this.container.hash = await this.calculateHash(fileChunkList); // 根据文件块列表创建上传数据对象 this.data = fileChunkList.map(({ file, index }) => ({ fileHash: this.container.hash, chunk: file, hash: this.container.file.name + "-" + index, percentage: 0 })); // 上传文件块 await this.uploadChunks(); }
哈希碰撞
输入空间通常大于输出空间,无法完全避免碰撞
哈希(A) = 21 % 10 = 1
哈希(B) = 31 % 10 = 1
所以spark-md5 文档中要求传入所有切片并算出 hash 值,不能直接将整个文件放入计算,否则即使不同文件也会有相同的 hash
总结
Blob.prototype.slice 切片
web-worker 在 worker 线程中用spark-md5 根据文件内容算hash
promise.allSettled()并发请求
面试官桀桀一笑:你没做过大文件上传功能?那你回去等通知吧! - 掘金