JVM——引言+JVM内存结构_北岭山脚鼠鼠的博客-CSDN博客
书接上回内存结构——方法区。
这里常量池是运行时常量池。
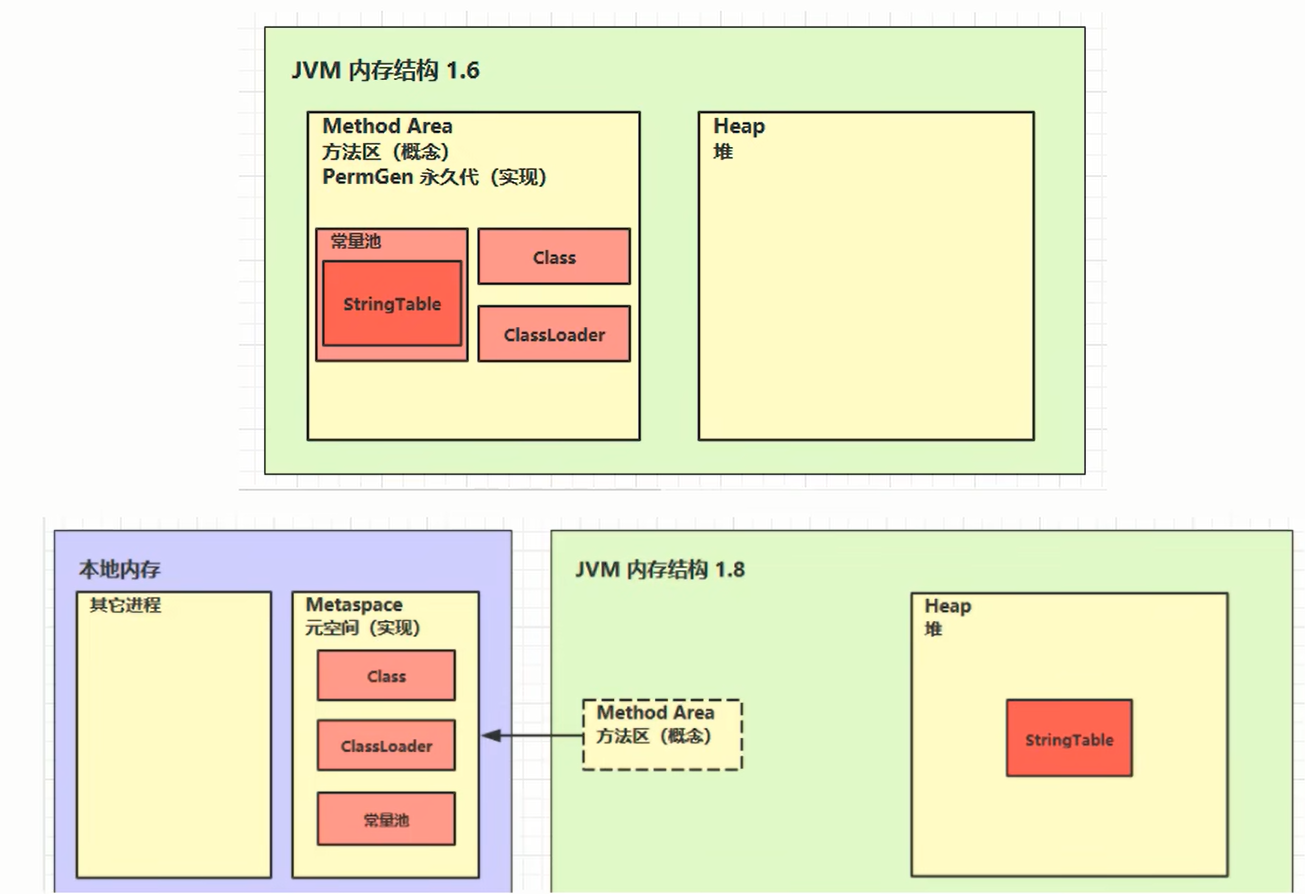
方法区
面试题

intern()方法
intern() 方法用于在运行时将字符串添加到内部的字符串池stringtable中,并返回字符串池stringtable中的引用。
返回值
当调用 intern() 方法时,如果字符串池中已经存在相同内容的字符串,则返回字符串池中的引用;否则,将该字符串添加到字符串池中,并返回对字符串池中的新引用。
StringTable_常量池与串池的关系
从字节码和常量池角度看。
准备如下一个类
package test;
public class test {
public static void main(String args[]) {
String s1="a";
String s2="b";
String s3="ab";
}
}
在命令行先用javac test.java编译出字节码文件,然后用javap -v test.class显示反编译内容
如果没有生成LocalVariableTable,可以通过这条命令 javac -g:vars xxxxxx.java

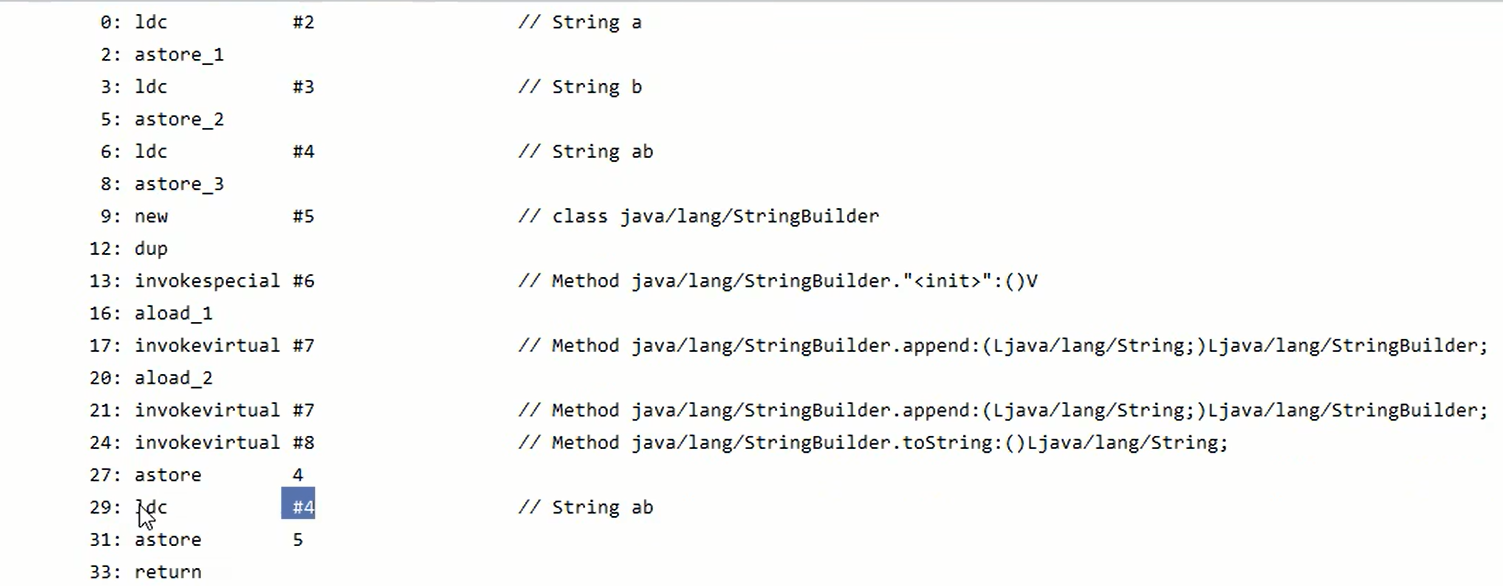
看见main方法部分的指令中第一条是ldc #2,到常量池中2号位置加载一个信息,该信息有可能是常量,也有可能是对象的引用。这里加载了一个字符串对象a。
 astroe_1将a存入局部变量表中的1号位置,astore将b存入2,astore将ab存入3。
astroe_1将a存入局部变量表中的1号位置,astore将b存入2,astore将ab存入3。
局部变量表是栈帧的东西。
常量池最初存在于字节码文件,运行时会被加载到运行时常量池,Constant Pool中的符号会被加载到运行时常量池。
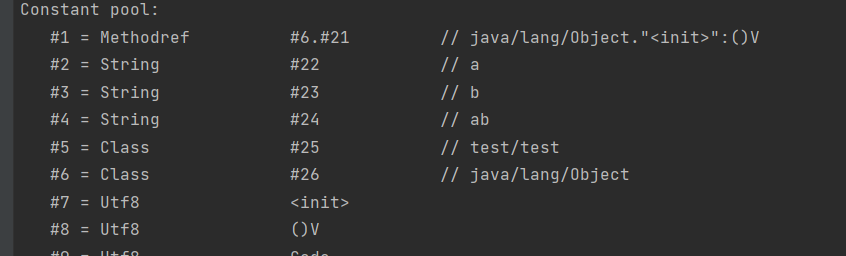
//常量池中的信息,都会被加载到运行时常量池中,这时a,b,ab都是常量池中的符号,还没有变为java 字符串对象,也还没有加入到stringtable中。
ldc #2会把a符号变为“a”字符串对象,然后会拿着“a”去StringTable串池里面找有没有取值相同的key,没有的话会把“a”放入stringtable并返回引用,有的话会使用串池中的a对象的引用。
每个字符串对象都不是事先放在串池里面,而是用到的时候才开始创建,懒加载。
这里容易混淆,stringtable=字符串常量池=串池,是在堆中的一块区域,常量池是另一个东西,是内存元空间中的一块区域.(1.8)
StringTable_字符串变量拼接
public class test {
public static void main(String args[]) {
String s1="a";
String s2="b";
String s3="ab";
String s4=s1+s2;
}
}加上这个字符串拼接的代码之后再次反编译后。
s4那里创建一个StringBuilder对象并调用其init方法,()V表示调用无参构造。
aload_1表示准备好了s1这个参数,astore_1是存入了局部变量表。
然后调用了append方法,最后那里调用了一个toString方法。
s1+s2 = new StringBuild().append("a").append("b").toString();
astore 4是将上面toString得到的新的String对象("ab")存入s4.

然后在这里
输出一个false,s3是在串池中的,s4是引用一个新的字符串对象,值一样,s3在串池,s4在堆里面,位置不同,是两个对象,输出false.

StringTable_编译期优化
public class test {
public static void main(String args[]) {
String s1="a";
String s2="b";
String s3="ab";
String s4=s1+s2; //new StringBuild().append("a").append("b").toString()
String s5="a"+"b"; //这就是javac找编译期的优化,结果已经在编译期确定为ab
System.out.println(s3==s5);
}
}编译之后如下
s5="a"+"b"对应的是ldc #4,直接在字符串常量池找到已经拼接好的“ab”,并存入了局部变量表5号中
String s3="ab"也是到常量池中找“ab”.
区别就是s3没有找到ab对象并加了进去,s5找到并获取了s3存入的ab对象,因此两个获得的是同一个对象。
因此s3==s5结果为true.
简单说,就是**new出来的放在堆里**,**直接赋值的放在串池里**,**虽然串池也在堆里**,**但是区域不同(地址不同)**,而==比较的是地址,因此false(s3==s4时)。

StringTable特性
- 常量池中的字符串仅是符号,第一次用到时才变为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是 StringBuilder (1.8)
- 字符串常量拼接的原理是编译期优化
- 可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
intern_1.8
public class test {
//["a","b"]
public static void main(String args[]) {
String s=new String("a")+new String("b");//new String("ab")=new StringBuild().append(a).append(b).toString()
//堆中 new String("a") new String("b") new String("ab")
String s2=s.intern(); //将字符串对象尝试放入串池,如果有则不会放入,并将串池中的对象返回给s2。
System.out.println(s2=="ab"); //true
System.out.println(s=="ab"); //true
}
}上面这段代码中s=new ....已经在堆里放了a,b,ab,在串池放了a,b.
s.intern()则是把s在堆中的地址也放入了串池,因此s2在串池取到的“ab”和堆中的“ab”地址是相等的。
public class test {
//["a","b"]
public static void main(String args[]) {
String x="ab";
String s=new String("a")+new String("b");//new String("ab")=new StringBuild().append(a).append(b).toString()
//堆中 new String("a") new String("b") new String("ab")
String s2=s.intern(); //将字符串对象尝试放入串池,如果有则不会放入,并将串池中的对象返回给s2。
System.out.println(s2==x); //true
System.out.println(s==x); //false
}
}这一段代码里面,ab早已在串池,s.intern()没有放进去,于是s2取到了串池中的“ab”,而不是堆中的“ab”.
intern_1.6
- 1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
- 1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份创建个新的,放入串池,并会把串池中的对象返回
下面的代码在1.8是true,true,在1.6是true,false
public class test {
//["a","b"]
public static void main(String args[]) {
String s=new String("a")+new String("b");//new String("ab")=new StringBuild().append(a).append(b).toString()
//堆中 new String("a") new String("b") new String("ab")
String s2=s.intern(); //将字符串对象尝试放入串池,如果有则不会放入,并将串池中的对象返回给s2。
String x="ab";
System.out.println(s2==x); //
System.out.println(s==x); //
}
}面试题
public class test {
public static void main(String args[]) {
String s1="a";
String s2="b";
String s3="a"+"b";//串池中ab
String s4=s1+s2;//堆里new String("ab")
String s5="ab"; //应用串池ab
String s6=s4.intern(); //串池已有,获得串池ab
//问
System.out.println(s3==s4); //false
System.out.println(s3==s5); //true
System.out.println(s3==s6); //true
String x2=new String("c")+new String("d"); //堆中cd
String x1="cd"; //串池中cd
x2.intern(); //尝试入池失败
//问 ,如果调换了x1,x2位置呢?如果是jdk1.6呢?
System.out.println(x1==x2); // false
}
}String x1=“cd”和x2.intern调换之后就是true,x1直接用串池中的ab.
调换之后换成jdk1.6的话,也是false,串池中是x2的副本,不是x2故x1从串池取到的不是x2.
StringTable_位置
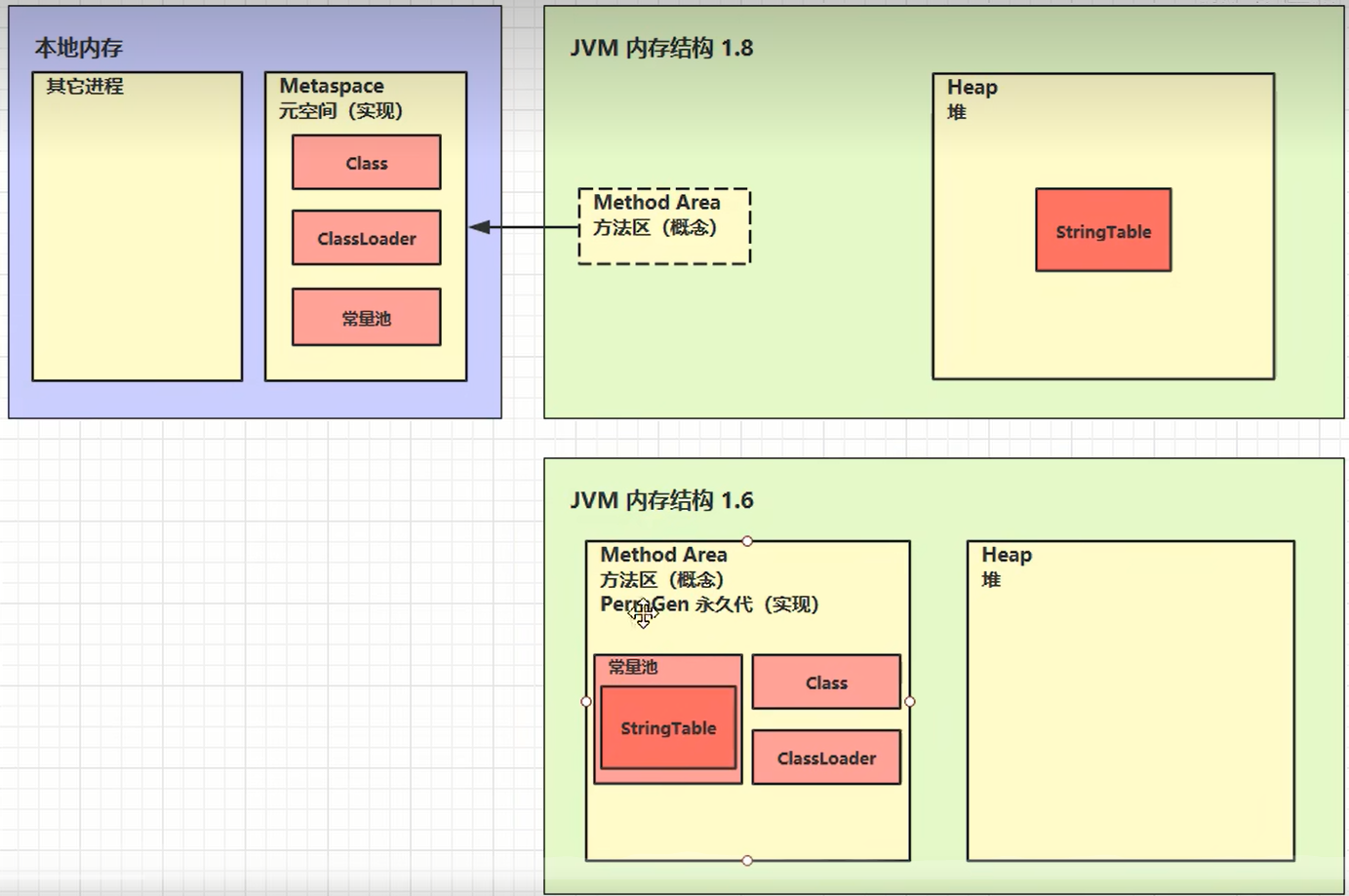
1.6串池在常量池中,1.8串池去到了堆中。
原因:
永久代内存回收效率很低,永久代需要fullGC时才会触发永久代的垃圾回收,而fullGC只有在老年代空间不足时才会触发,触发时间晚,间接导致串池回收效率不高。
1.8在堆中只要Minor GC就会触发StringTable串池的垃圾回收。
案例

1.6下报错

1.8下报错
并不是堆内存不足报错

原因:
-XX:+UseGCOverheadLimit是打开
-XX:-UseGCOverheadLimit是关闭
1.8中,如果98%的时间花在垃圾回收上但只回收了2%的堆空间,则jvm已经无药可救,便不会再尝试垃圾回收,会报错OverHead Limit。
关闭后1.8报错
堆空间不足
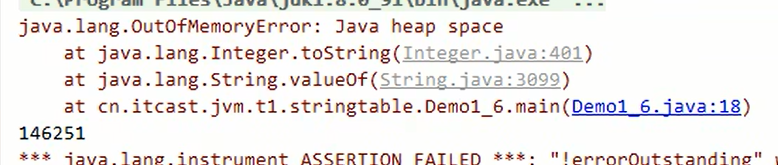
证明了1.8串池用的堆空间,1.6串池用的永久代。
StringTable_垃圾回收
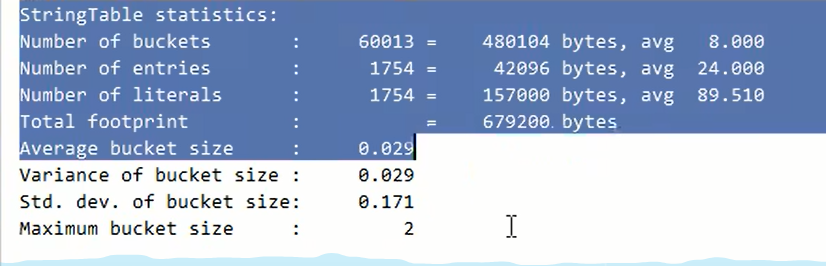
两个参数,一个是打印字符串表的统计信息,可以看见串池中字符串实例个数以及占用大小
一个是打印垃圾回收详细信息,次数和回收时间。
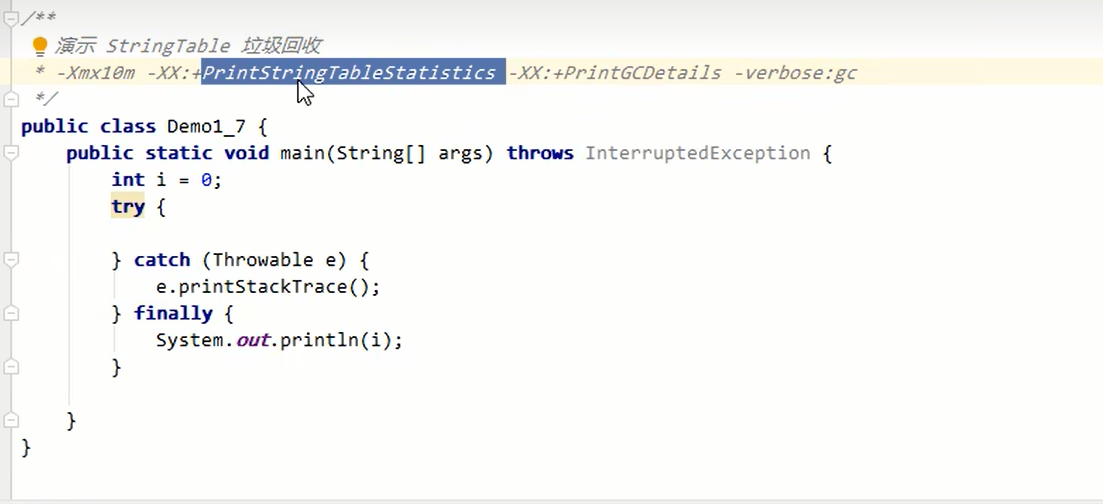
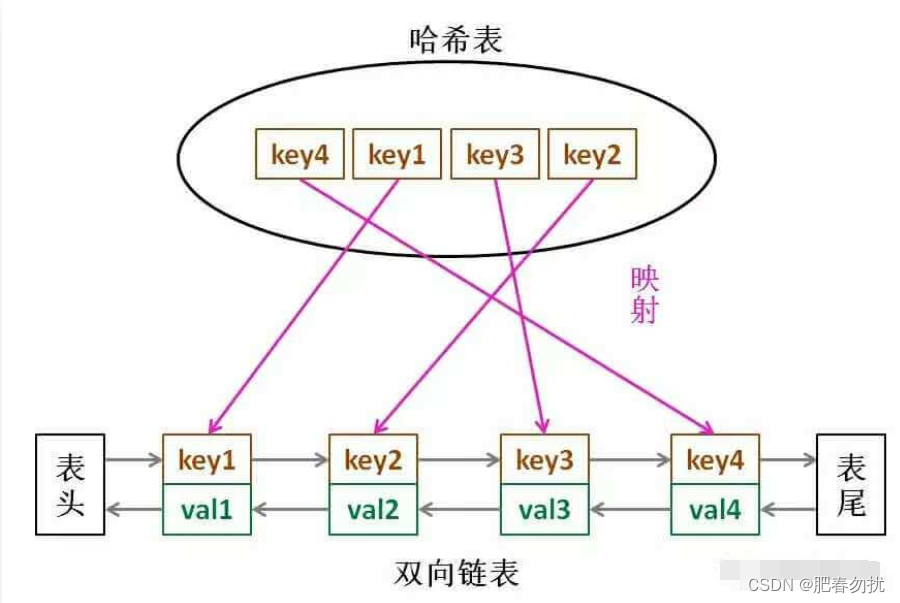
串池统计信息,底层采用哈希表实现,数组加链表结构。
数组个数成为桶buckets,下图默认是60013个,entries键值对个数是1754个,literals字符串常量也是1754个。总占用Total footprint.
修改代码如下
在try中加个循环不断往串池加入新对象。
运行后可以看见多了100个字符串对象进StringTable

加多循环次数
此时只有7000多个。
由于内存空间分配失败触发了一次垃圾回收。
minorGc新生代垃圾回收。
这里证明了StringTable也是会发生垃圾回收的。
StringTable性能调优
- 调整-xx:StringTableSize=桶个数
串池底层是哈希表,性能跟大小相关,桶的个数多,碰撞几率低,查找速度快,桶的个数较少的话,碰撞几率更高,导致链表较长,查找速度变慢。
这里调优就是调整桶的个数,下图中使用参数设定了桶的个数为20万个。


上面是用BufferReader读取了单词表48万个单词,然后全部放入串池中。上面输出了入池所花费的时间。
花费时间0.4s.

统计信息可以看见桶个数有20万个。平均每个桶两个单词多。因此效率较高。
在去除20w的参数后花费时间变多,默认桶个数是6万


桶的个数最小是1009,设置为1009后再次测试变得更慢了。
系统里字符串常量个数较多就可以调整桶的个数变大,使其有更好的分布,减少冲突,使串池效率提升。
StringTable_性能调优案例
- 调整-xx:StringTableSize=桶个数
- 考虑将字符串对象是否入池
网络段子:
推特要存储用户地址在内存中,但是堆内存不够大并且很多内存重复,解决方法就是采用了字符串的intern()方法,可以去除重复地址。
在上面的代码基础上改动。

循环读取10次48w个单词,使其出现10次重复的情况。
使用一个生命周期更长的List<String>中防止被垃圾回收。这里先不入池。并且在开始前和结束后都有一个输入。
使用Java VisualVM查看信息
读取文件前
char和String有个11mb左右

读取后char和String有300mb,占了80%多。
 修改代码
修改代码
在添加到list集合之前先入池,然后返回值是串池中的字符串对象。串池外的会被垃圾回收。
这一次的内存占用只剩30%多,一共也就30多mb.与之前的内存差异明显。
案例证明如果引用里面有大量的字符串且字符串可能存在重复问题可以让字符串入池减少字符串对象个数,减少堆内存的使用。
直接内存
直接内存不属于java虚拟机内存管理,而是属于系统内存,是操作系统的内存。
定义
- 常见于 NIO 操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受JM 内存回收管理
基本使用
NIO的 directByteBuffer
使用directBuffer比用传统阻塞IO 传输效率快很多。

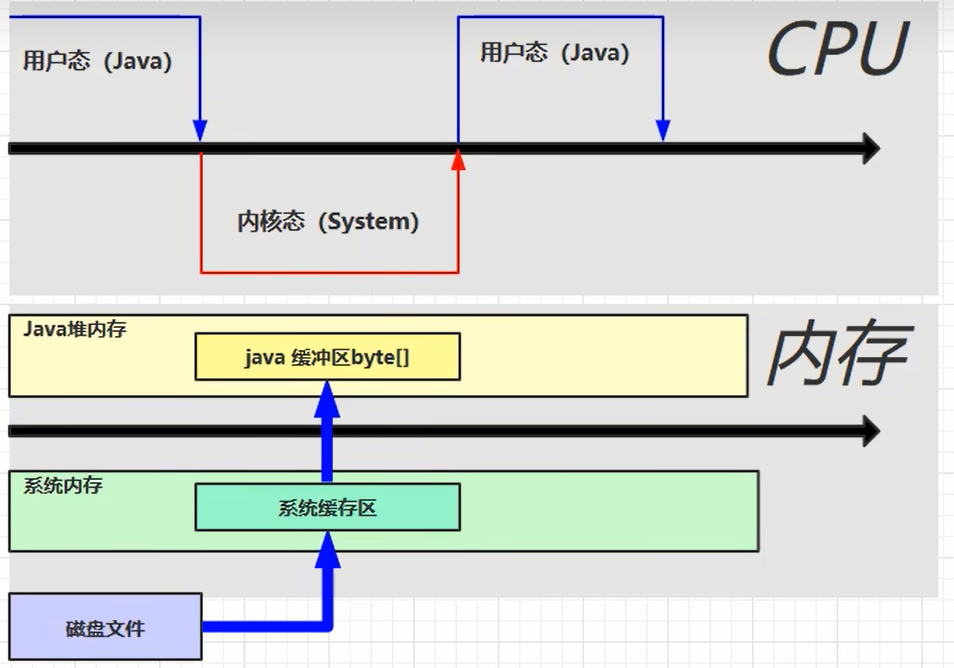
传统IO操作的过程。
java本身没有磁盘读写能力,需要调用操作系统提供的函数。
切换到内核态之后就可以有cpu函数读取磁盘文件内容,读取进来后会在系统内存中划出一块系统缓冲区,系统缓冲区java代码不能运行,因此java代码会在堆内存分配一块java缓冲区,对应代码里new的byte[]数组,要读取数据还要将其从系统缓冲区读入到java缓冲区。
然后到了下一个用户态再去调用输入流的写操作,反复进行读写。
这里数据经过了两次复制,造成效率较低。
directByteBuffer的过程
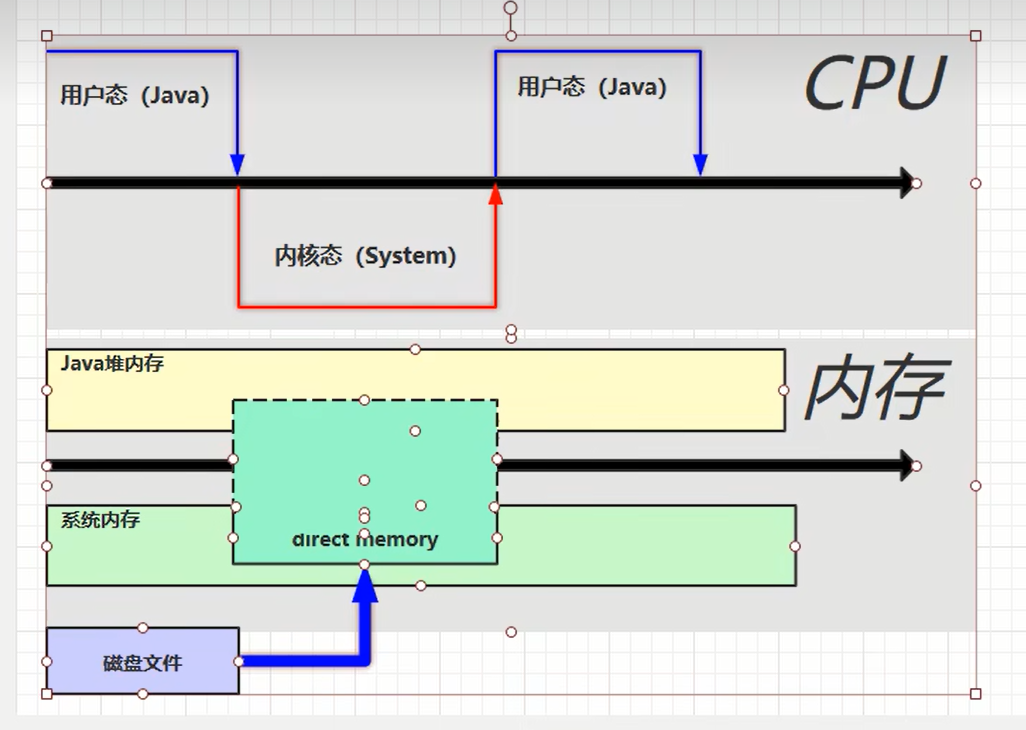
这里直接在操作系统划出了一块缓冲区,这里java代码可以直接访问。两边的代码共享的一个区域。复制次数少了一次,效率提高。
内存溢出
这个直接内存的特点还有不受JVM内存回收管理。

上面这个代码每次分配100mb内存。
然后就把报错了直接内存溢出,循环了36次,3.6G.

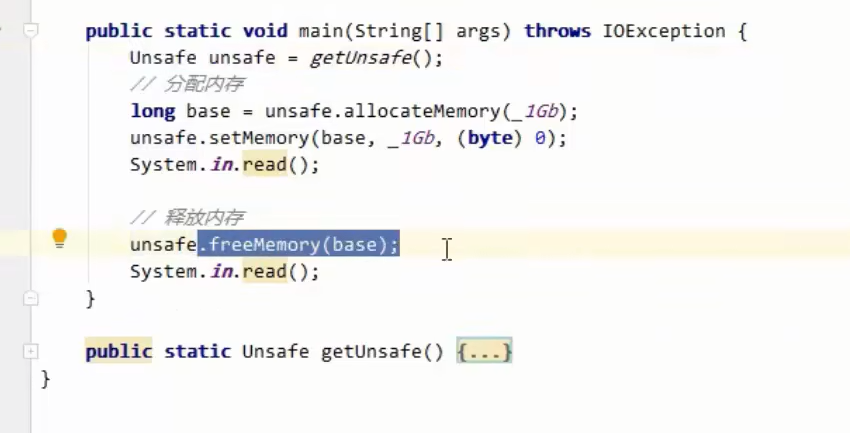
分配和释放原理
- 使用了Unsafe 对象完成直接内存的分配回收,并且回收需要主动调用 freeMemory 方法
- BvteBuffer 的实现类内部,使用了 Cleaner (虚引用)来监测 BvteBuffer 对象,一旦 BteBuffer 对象被垃圾回收,那么就会由 ReferenceHandler 线程通过 Cleaner 的 clean 方法调用 freeMemory 来释放直接内存
通过一个Unsafe对象进行管理的,而不是垃圾回收

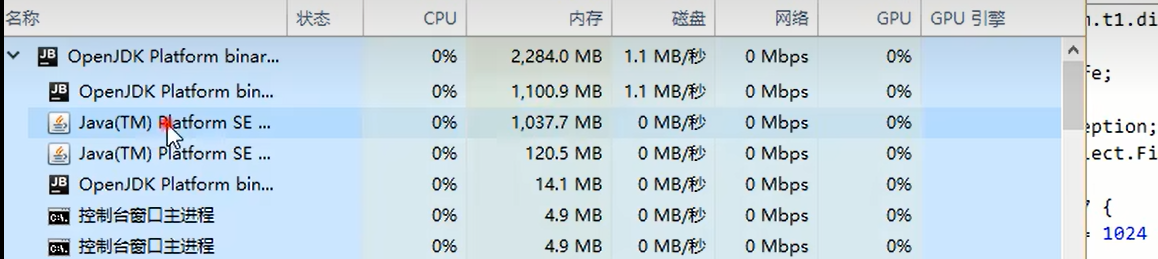
运行之后可以看见进程占用了一个G的内存。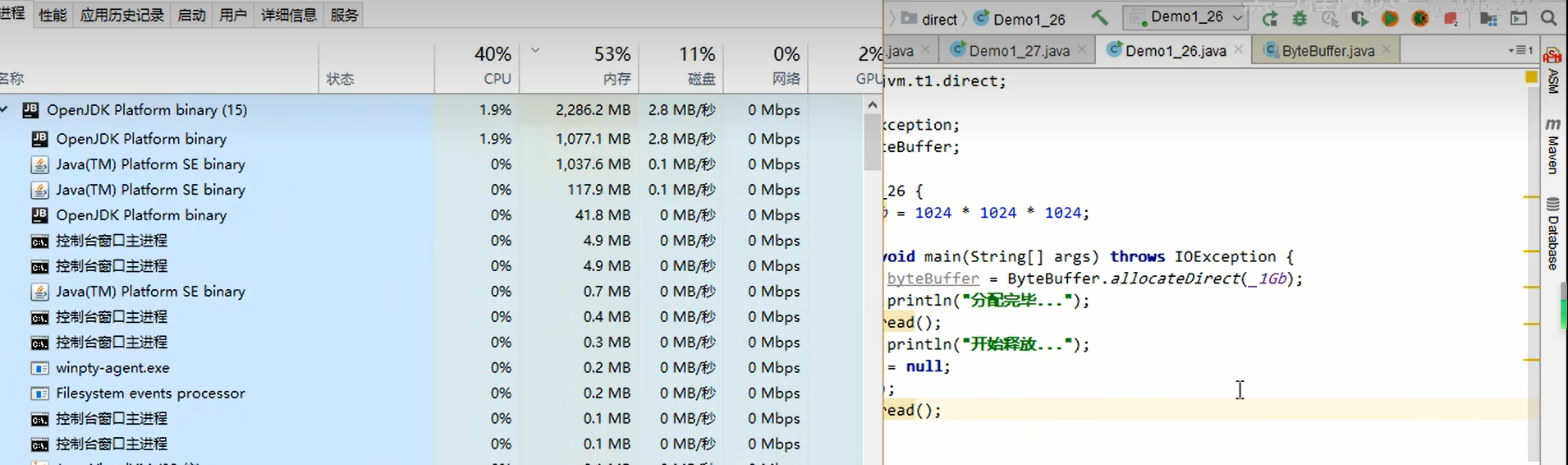
然后置为null之后,1个G的内存被回收

原理说明
在java较为底层的一个Unsafe类可以做到分配直接内存和释放直接内存。一般都是jdk内部自己使用的

分配内存那个方法返回了一个long类型的地址,下面就可以用这个地址来进行内存的释放。
分配之后
 释放之后
释放之后

上面说明了直接内存的分配和释放是通过一个Unsafe对象进行管理的,而不是垃圾回收。
源码分析


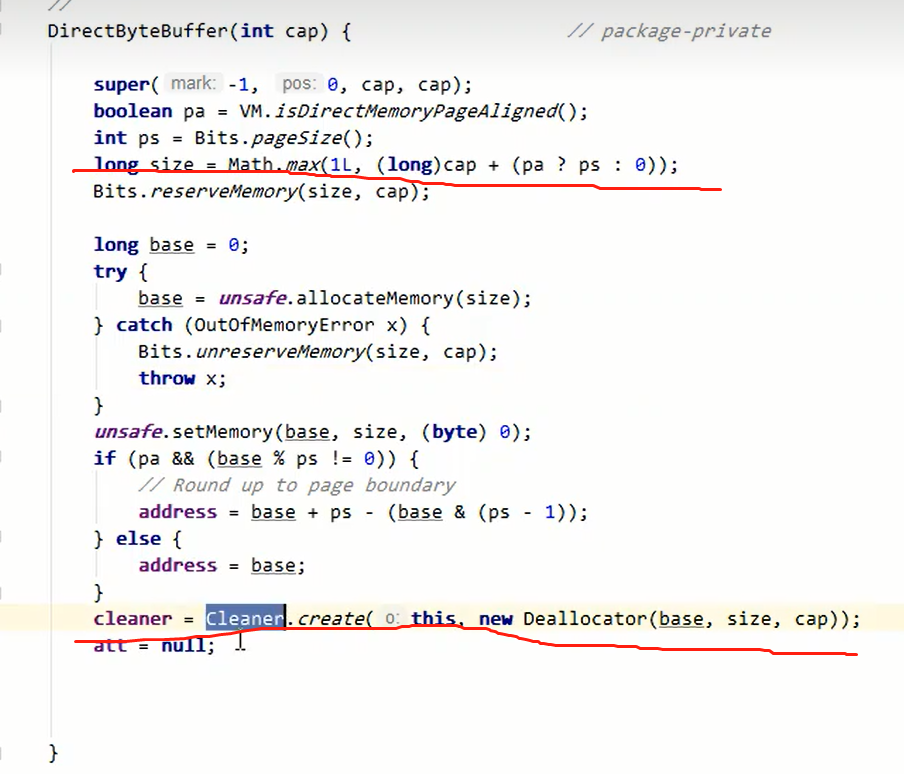
在源码里面可以看见调用了分配内存的方法。
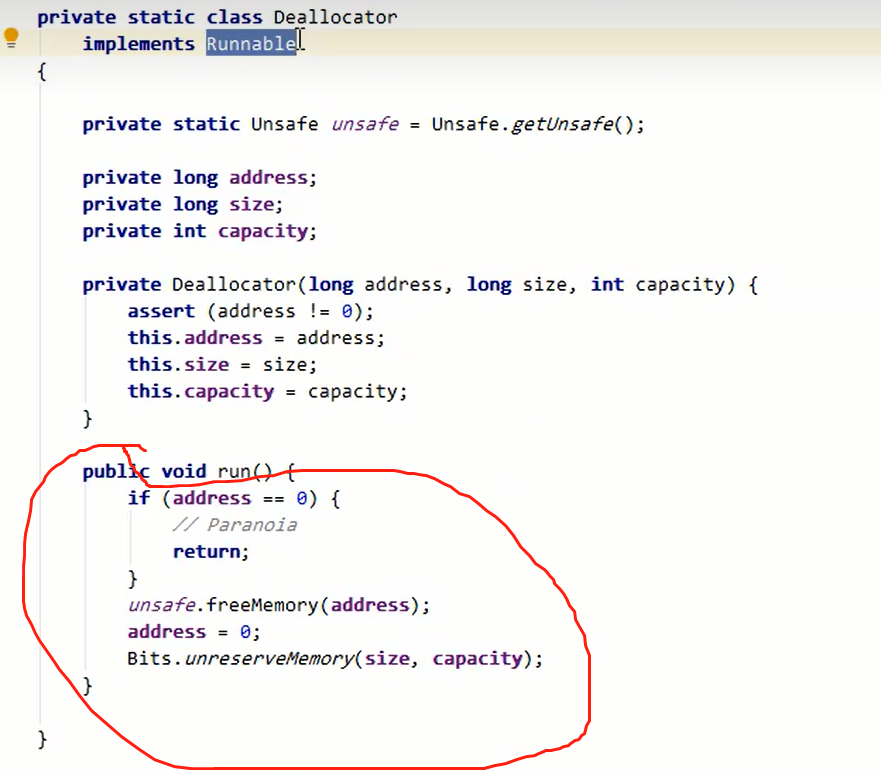
在cleaner的create方法参数中的一个回调任务对象Deallocator。
在该方法中可以看见Unsafe释放内存的方法。
直接内存的释放借助了虚引用的机制。
意思就是JAVA对象被回收,触发直接内存回收
禁用显式回收对直接内存的影响
- 使用了Unsafe 对象完成直接内存的分配回收,并且回收需要主动调用 freeMemory 方法
- BvteBuffer 的实现类内部,使用了 Cleaner (虚引用)来监测 BvteBuffer 对象,一旦 BteBuffer 对象被垃圾回收,那么就会由 ReferenceHandler 线程通过 Cleaner 的 clean 方法调用 freeMemory 来释放直接内存
在做jvm调优时经常会用的一个参数
-XX:+DisableExplicitGC 禁用显式垃圾回收
systemgc()触发的是fullGC,对新生代和老年代都会回收,造成程序暂停时间较长。

然后运行之后System.gc()会失效,直接内存无法被回收,ByteBuffer只能等到真正的垃圾回收才会被清理。造成直接内存长时间占用较大。 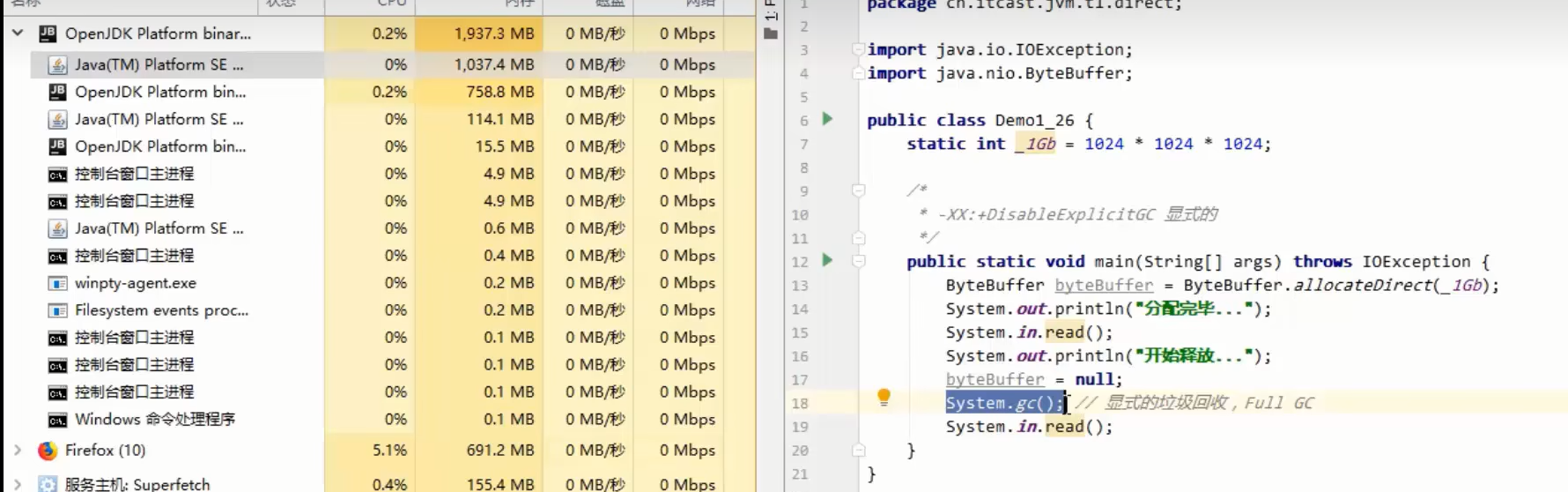
解决方案
直接使用unsafe对象进行直接内存的释放。
手动管理