一、说明
二、什么是FifthOne?
FiftyOne 是一个开源机器学习工具集,使数据科学团队能够通过帮助他们策划高质量数据集、评估模型、查找错误、可视化嵌入并更快地投入生产来提高其计算机视觉模型的性能。
- 如果你喜欢在GitHub上看到的内容,给这个项目加一颗星。
- 开始吧!我们使几分钟内启动和运行变得容易。
- 加入 FiftyOne Slack 社区,我们总是很乐意提供帮助。
好的,让我们深入了解本周的提示和技巧!
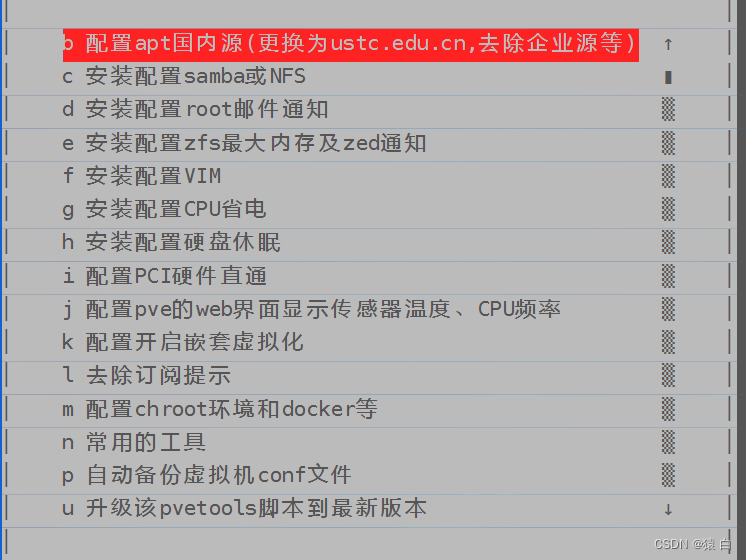
三、省略检测实例很少的类
社区松弛成员西尔维娅施密特问道:
“当按特定字段中的值对样本进行分组时,我想省略具有数据集中很少出现的值的样本。怎么能做到这一点呢?
实现此目的的一种方法是使用来获取整个 or 对象中给定字段中每个唯一值的出现次数的计数,获取比所需截止值更频繁出现的值,并使用该方法获取包含这些值的样本。count_values()DatasetDatasetViewmatch()
例如,如果要从“野生家庭”数据集的测试拆分中获取值在数据集中出现十次以上的样本,则可以执行以下操作:name
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
## load the dataset
dataset = foz.load_zoo_dataset("fiw", split="test")
counts = dataset.count_values("name")
keep_names = [name for name, count in counts.items() if count > 10]
## filter for samples with these names
view = dataset.match(F("name").is_in(keep_names))
session = fo.launch_app(view)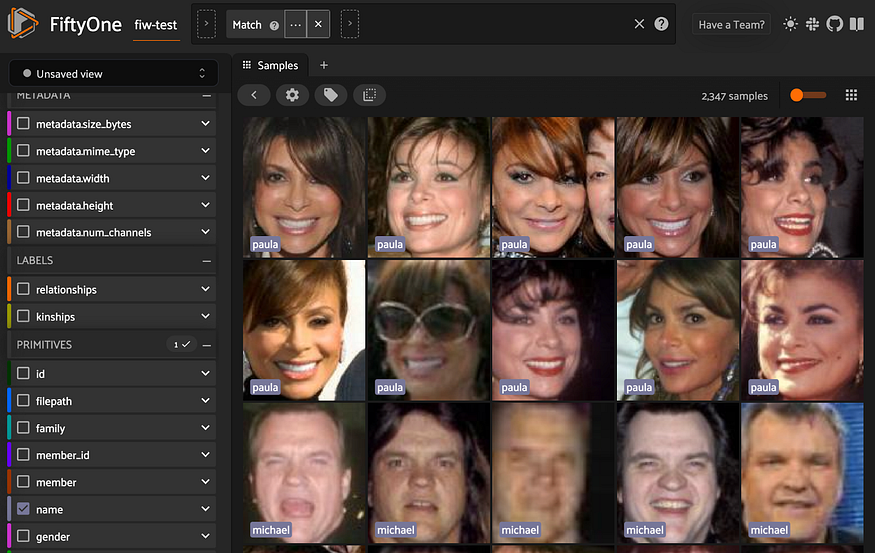
名称在“野生家庭”数据集中出现十次以上的图像。
然后,您可以将此生成的视图传递到按字段中的值或所需的任何其他聚合进行分组。group_by()
在 FiftyOne 文档中了解有关 count_values()、is_in() 和使用聚合的更多信息。
四、保存对示例字段所做的更改
社区松弛成员西尔维娅施密特问道:
“在添加示例字段以及稍后在视图中更改这些值时,是否必须通过调用'数据集'对象来持久进行更改,或者如果数据集已经持久化,是否会保存这些更改?”save()
好问题,西尔维娅!通常,当对 or 中的单个样本进行更改时,需要通过调用样本而不是数据集来保存更改。即使数据集是持久性的,情况也是如此,即如果DatasetDatasetViewsave()
dataset.persistent = True例如,可以更改快速入门数据集中第一个样本的首次检测的类标签,如下所示:
import fiftyone as fo
import fiftyone.zoo as foz
## load dataset
dataset = foz.load_zoo_dataset("quickstart")
## get sample
sample = dataset.first()
## change label
sample.ground_truth.detections[0].label = "bear"
## save changes to dataset
sample.save() 仅在编辑数据集级元数据(如 .save()dataset.info
但是,在某些情况下,无需显式运行即可将更改传播回数据集。其中包括方法(该方法接收值列表并将这些值写入视图中示例的字段)以及将标记添加到视图中所有示例的方法。sample.save()view.set_values(field_name, field_vals)field_valsfield_nameview.tag_samples(tags)tags
如果您知道需要循环访问 or 并对每个示例进行更改,而不是调用每个示例,则传递 to 对操作进行批处理会更有效。例如,要为数据集中的每个样本设置一个带有随机数的字段,我们可以运行:DatasetDatasetViewsave()autosave=Trueiter_samples()random
import random
import fiftyone as fo
import fiftyone.zoo as foz
## load dataset
dataset = foz.load_zoo_dataset("quickstart")
## Automatically saves sample edits in efficient batches
for sample in dataset.select_fields().iter_samples(autosave=True):
sample["random"] = random.random()在 FiftyOne 文档中了解有关 set_values() 和标记示例的更多信息。
五、预测齐次图像中的类标签
社区松弛成员乔治·皮尔斯问道:
“处理对象的标签与示例中其他对象的标签紧密交织的应用程序的最佳方法是什么?例如,我可能有一些图像,通常是所有猫的人群,或者所有狗的人群,但不是同时包含猫和狗的人群。
好问题,乔治!有很多方法可以处理这样的数据。一种方法是积累大量这样的示例,并根据这些数据训练模型。给定足够高质量的示例,模型应该(理论上)能够学习这些关系。
作为仅使用现有数据的替代方法,您可以根据模型预测的输出对样本中的标签执行后处理。例如,如果模型的预测存储在样本的字段中,则可以创建新的标签字段,并根据该样本的内容填充此新字段的内容。model_rawmodel_processedmodel_raw
对于每个样本,检查是否有三个或更多具有相同类标签的对象。为了简单起见,我们假设就是这个类。如果有,则对于未标记为 s in 的所有对象,如果其类置信度分数低于某个阈值,则将其类标签设置为 in 。dogdogmodel_rawdogmodel_processed
这可能是这样的:
import numpy as np
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
## create or load your dataset
dataset = fo.Dataset(..)
## clone predictions into new field
dataset.clone_sample_field(
"model_raw",
"model_processed"
)
## set a class confidence threshold
conf_thresh = 0.3
## iterate through samples in dataset
for sample in dataset.iter_samples(autosave=True):
dets = sample.model_processed.detections
labels = [det.label for det in dets]
unique_labels, label_counts = np.unique(labels, return_counts=True)
## find samples with at least 3 labels of same class
if max(label_counts) > 2:
crowd_label = unique_labels[np.argmax(label_counts)]
for det in dets:
if (det.label != crowd_label) and
(det.confidence < conf_thresh):
det.label = crowd_label
det.confidence = None
## tag samples to look at later
sample.tags.append("possible homogeneous crowd")然后,您可以比较这些已处理模型预测与原始预测不同的标记样本,并在 FiftyOne 应用程序中对其进行检查。
在 FiftyOne 文档中了解有关保存、保留和克隆示例字段的更多信息。
六、匹配分类结果
社区松弛成员纳达夫问道:
“我有一个有两种分类的数据集。在代码或应用中创建仅包含两个分类一致的示例的视图的最佳方法是什么?
在代码中执行此操作的一种方法是使用 FiftyOne 的内置筛选和匹配功能。该方法将返回一个视图,其中包含条件为 true 的所有样本。dataset.match(my_condition)my_condition
在您的情况下,您可以使用 ViewField 在两个分类之间创建协议条件。下面是它的外观:
import fiftyone as fo
import fiftyone.zoo as foz
from fiftyone import ViewField as F
# create or load your dataset with
# classifications in field1 and field2
dataset = fo.Dataset(...)
view = dataset.match(
F("field1.label") == F("field2.label")
)
session = fo.launch_app(view) 如果您想要一个包含两个分类不对齐的所有样本的视图,则可以将相等运算符替换为不等式运算符。==!=
在 FiftyOne 文档中了解有关筛选的更多信息。
七、关闭会话
社区松弛成员斯科特问道:“如何断开启动的会话?”
在 FiftyOne 中,会话是连接到特定或 的 FiftyOne 应用程序的实例。您可以使用以下方法启动特定数据集或视图的会话:DatasetDatasetViewlaunch_app()
import fiftyone as fo
import fiftyone.zoo as foz
## load dataset
dataset = foz.load_zoo_dataset("quickstart")
## launch one session
session1 = fo.launch_app(dataset)
## create a view
view = dataset.take(20)
## launch another session
session2 = fo.launch_app(view) 您还可以通过以下方式查看所有已注册的会话:fo.core.session.session._subscribed_sessions
defaultdict(set,
{5151: {Dataset: quickstart
Media type: image
Num samples: 20
Selected samples: 0
Selected labels: 0
Session URL: http://localhost:5151/
View stages:
1. Take(size=20, seed=None),
Dataset: quickstart
Media type: image
Num samples: 20
Selected samples: 0
Selected labels: 0
Session URL: http://localhost:5151/
View stages:
1. Take(size=20, seed=None)}})当您终止运行 FiftyOne 的 Python 进程时,所有会话都将关闭,因此通常不需要显式关闭会话。
但是,如果您想随时终止会话,则可以使用私有方法执行此操作:_unregister_session()
from fiftyone.core.session.session import _unregister_session
_unregister_session(session1)在 FiftyOne 文档中了解有关会话的更多信息,包括如何在远程计算机上启动多个应用程序实例。
八、加入五十一社区!
加入已经使用FiftyOne解决当今计算机视觉中一些最具挑战性问题的数千名工程师和数据科学家的行列!
- 1,350+ FiftyOne Slack members
- 2,550+ stars on GitHub
- 3,200+ Meetup members
- Used by 246+ repositories
- 56+ contributors
九、下一步是什么?
- 如果你喜欢在GitHub上看到的内容,给这个项目加一颗星。
- 开始吧!我们使几分钟内启动和运行变得容易。
- 加入 FiftyOne Slack 社区,我们总是很乐意提供帮助。
雅各布·马克斯






![[ MySQL ] — 基础增删查改的使用](https://img-blog.csdnimg.cn/f584cd2d7e1e47c8a95db4f8c26b2dbc.png)