1.GPT1
无监督预训练+有监督的子任务finetuning
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
1.1 Unsupervised pre-training

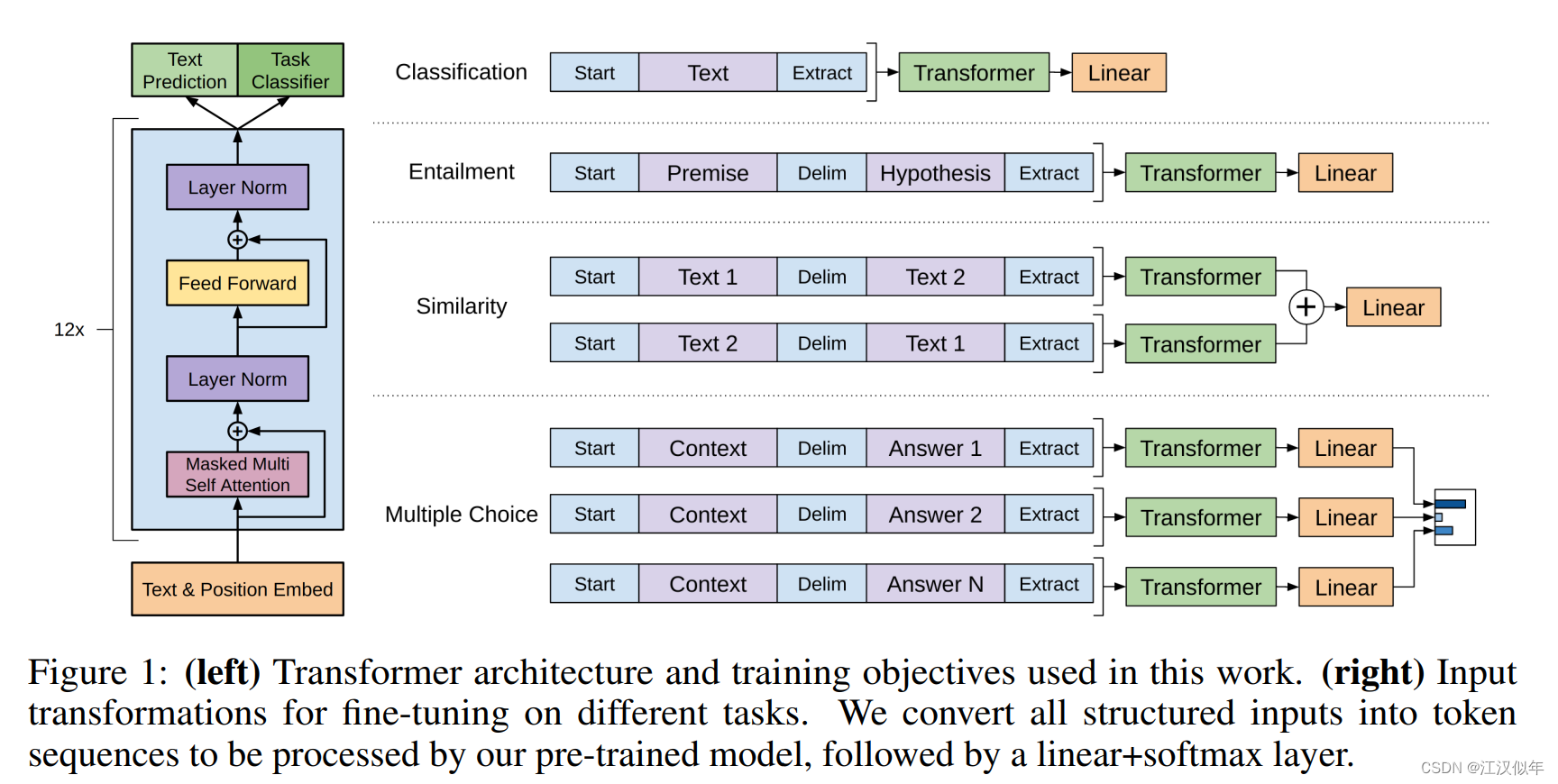
(1)通过一个窗口的输入得到下一个token在目标token上的一个概率分布,方法是基于一个transformer decoder,其中窗口大小是k。
(2)针对一个预料库,不断滑动窗口k,每次最大化下一个token的概率作为loss,相加得到总的loss
1.2 Supervised fine-tuning

(1)将transformer的输出经过一个线性层后,经softmax后得到对目标token的预测结果,最大化预测结果与真值作为loss
(2)同时增加预训练loss作为辅助loss,有助于模型泛化、提升训练速度
2.GPT2
GPT2
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
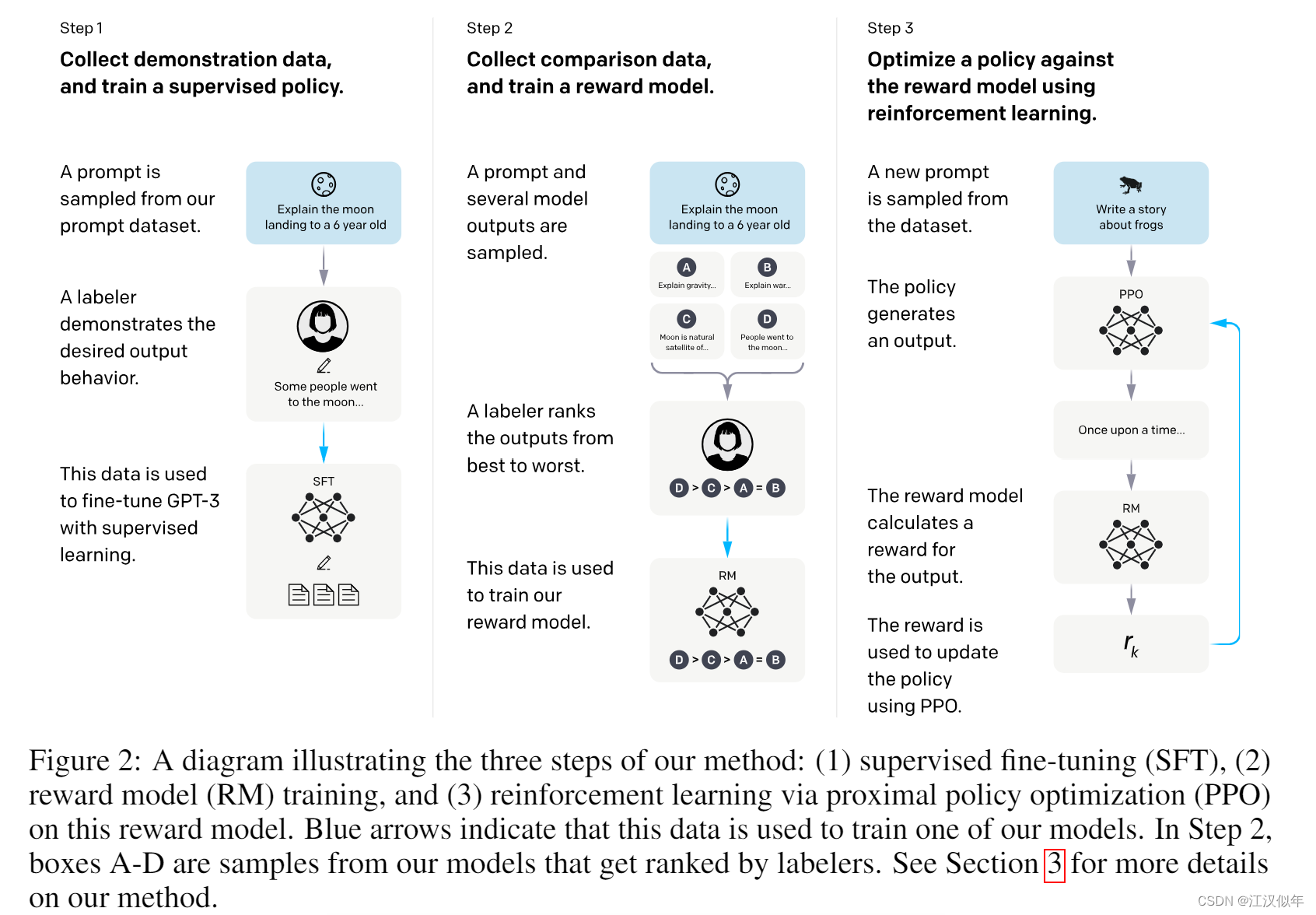
4.InstuctGPT