transformer在计算机视觉任务中显示出了巨大的潜力。人们普遍认为,他们基于注意力的token混合器模块对他们的能力贡献最大。然而,最近的工作表明,transformer中基于注意力的模块可以被空间mlp取代,得到的模型仍然表现相当好。基于这一观察,本文假设transformer的通用架构,而不是特定的token mixer模块,对模型的性能更重要。为验证这一点,故意用一个简单得令人尴尬的空间池化操作符取代transformer中的注意力模块,以只进行基本的token混合。提出的模型称为PoolFormer,在多个计算机视觉任务上实现了有竞争力的性能。例如,在ImageNet-1K上,PoolFormer实现了82.1%的top-1精度,比经过良好调整的视觉Transformer/类mlp基线DeiT-B/ResMLP-B24提高了0.3%/1.1%的精度,参数减少了35%/52%,mac减少了50%/62%。PoolFormer的有效性验证了我们的假设,并敦促我们发起" MetaFormer "的概念,一种从transformer抽象出来的通用架构,而不指定token混合器。MetaFormer是在最近的Transformer和类mlp模型在视觉任务上取得优越结果的关键角色。这项工作呼吁未来进行更多致力于改进MetaFormer的研究,而不是专注于token mixer模块。所提出的PoolFormer可以作为未来MetaFormer架构设计的起始基线。
1. 介绍
transformer在计算机视觉领域获得了极大的兴趣和成功[3,8,44,55]。自从视觉Transformer (ViT)[17]将纯Transformer适应于图像分类任务的开创性工作以来,人们开发了许多后续模型,以进一步改进并在各种计算机视觉任务中取得了有希望的性能[36,53,63]。
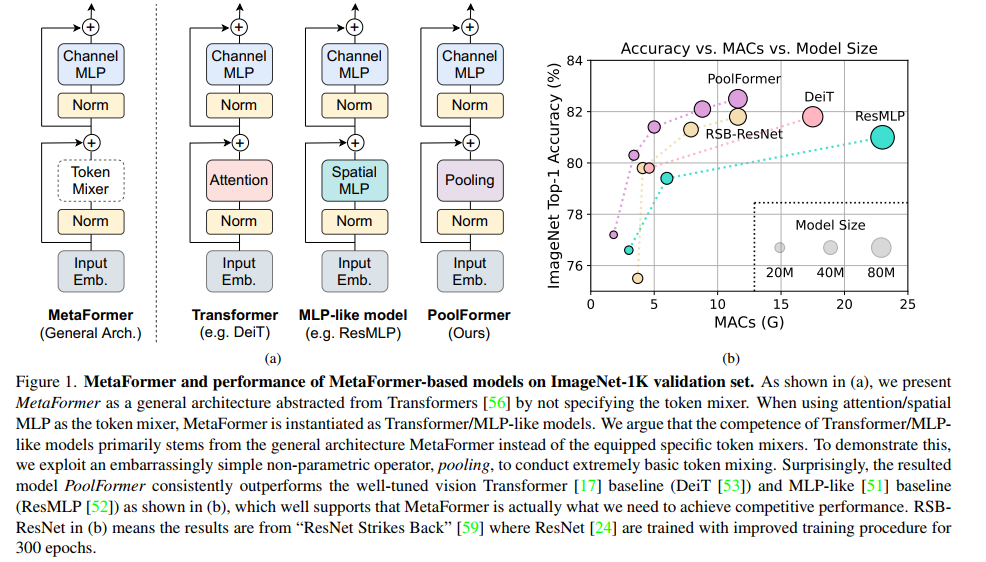
Transformer编码器如图1(a)所示,由两部分组成。一个是注意力模块,用于在token之间混合信息,我们将其称为token mixer。另一个组件包含剩余的模块,如通道mlp和残差连接。通过将注意力模块视为特定的token mixer,进一步将整体Transformer抽象为未指定token mixer的通用架构MetaFormer,如图1(a)所示。
transformer的成功长期以来归功于基于注意力的token混合器[56]。基于这一共识,已经开发了许多注意力模块[13,22,57,68]的变体,以改进视觉Transformer。然而,最近的一项工作[51]将注意力模块完全替换为空间mlp作为token mixers,并发现派生的类mlp模型可以很容易地在图像分类基准上获得有竞争力的性能。后续工作[26,35,52]通过数据高效的训练和特定的MLP模块设计进一步改进类MLP模型,逐渐缩小与ViT的性能差距,并挑战注意力作为token mixers的主导地位。
最近的一些方法[32,39,40,45]在MetaFormer架构中探索了其他类型的token mixers,并展示了令人鼓舞的性能。例如,[32]用傅里叶变换取代了注意力,仍然达到了普通transformer的约97%的精度。综合所有这些结果,似乎只要模型采用MetaFormer作为通用架构,就可以获得有希望的结果。因此,本文假设与特定的token mixers相比,MetaFormer对模型实现有竞争力的性能更重要。
为了验证这一假设,我们应用一个极其简单的非参数操作符pooling作为令牌混合器,只进行基本的令牌混合。令人惊讶的是,这个被称为PoolFormer的派生模型实现了具有竞争力的性能,甚至始终优于经过良好调优的Transformer和类mlp模型,包括DeiT[53]和ResMLP[52],如图1(b)所示。更具体地说,PoolFormer-M36在ImageNet-1K分类基准上达到82.1%的top-1精度,超过调优的视觉变压器/ mlp样基准DeiTB/ResMLP-B24 0.3%/1.1%的精度,参数减少35%/52%,mac减少50%/62%。这些结果表明,即使使用简单的令牌混合器,MetaFormer仍然可以提供有希望的性能。因此,我们认为MetaFormer是我们对视觉模型的实际需求,它对实现有竞争力的性能更重要,而不是特定的令牌混合器。注意,这并不意味着令牌混合器不重要。MetaFormer仍然有这个抽象组件。这意味着令牌混合器不局限于特定类型,例如注意力。
我们的论文有两方面的贡献。将Transformer抽象为一个通用架构的MetaFormer,并通过经验证明Transformer/ mlp类模型的成功在很大程度上归功于MetaFormer架构。通过仅采用简单的非参数算子pooling作为MetaFormer的极弱token混合器,构建了一个名为PoolFormer的简单模型,发现它仍然可以实现具有高度竞争力的性能。希望本文的发现能启发更多致力于改进MetaFormer的未来研究,而不是专注于token mixer模块。在多个视觉任务上评估了所提出的池化器,包括图像分类[14]、目标检测[34]、实例分割[34]和语义分割[67],与使用token mixer的复杂设计的SOTA模型相比,取得了有竞争力的性能。PoolFormer可以很容易地作为未来MetaFormer架构设计的良好起始基线。
2. 相关工作
transformer首先由[56]提出用于翻译任务,然后迅速在各种NLP任务中流行起来。在语言预训练任务中,transformer在大规模无标签文本语料库上进行训练,并取得了惊人的性能[2,15]。受transformer在NLP中成功的启发,许多研究人员将注意力机制和transformer应用于视觉任务[3,8,44,55]。值得注意的是,Chen等人引入了iGPT[6],其中Transformer被训练为自回归预测图像上的像素以进行自监督学习。Dosovitskiy等人提出了以硬贴片嵌入作为输入[17]的视觉Transformer (ViT)。他们表明,在监督图像分类任务上,在一个大型分集(3亿张图像的JFT数据集)上预训练的ViT可以取得优异的性能。DeiT[53]和T2T-ViT[63]进一步证明,仅在ImageNet-1K(~ 130万张图像)上从头进行预训练的ViT可以取得很好的性能。许多工作一直致力于通过移位的windows[36]改进transformer的token混合方法,相对位置编码[61],细化注意力图[68],或合并卷积[12,21,60]等。除了类似注意力的token mixers之外,[51,52]令人惊讶地发现,仅仅采用mlp作为token mixers仍然可以实现有竞争力的性能。这一发现挑战了基于注意力的token mixer的主导地位,并在研究界引发了关于哪种token mixer更好的热烈讨论[7,26]。然而,这项工作的目标既不是参与这场辩论,也不是设计新的复杂的token mixers来实现新的技术水平。相反,我们要研究一个基本问题:是什么真正促成了变形金刚及其变种的成功?我们的答案是通用架构,即MetaFormer。我们只是利用池化作为基本的token mixers来探测MetaFormer的能力。
与此同时,一些作品也在回答同样的问题。Dong等人证明,在没有残差连接或mlp的情况下,输出双指数收敛到秩为1的矩阵[16]。Raghu et al.[43]比较了ViT和cnn之间的特征差异,发现自注意力允许早期收集全局信息,而残差连接将特征从较低的层传播到较高的层。Park et al.[42]表明,多头自注意力通过扁平化损失景观来提高准确性和泛化性。遗憾的是,他们没有将transformer抽象为通用架构,并从通用框架的角度进行研究。
3.方法
3.1. MetaFormer
提出了MetaFormer的核心概念。如图1所示,从transformer[56]抽象而来,MetaFormer是一种通用架构,其中没有指定令牌混合器,而其他组件与transformer保持相同。输入I首先通过输入嵌入处理,例如vit[17]的patch embedding,
X
=
Input
Emb
(
I
)
,
(1)
X=\operatorname{Input} \operatorname{Emb}(I), \tag{1}
X=InputEmb(I),(1)
其中 X ∈ R N × C X \in \mathbb{R}^{N \times C} X∈RN×C表示序列长度为N、嵌入维度为C的嵌入词例。
然后,将嵌入标记馈送到重复的元former块,每个元former块包含两个残差子块。具体来说,第一个子块主要包含一个token mixer,用于token之间的信息通信,该子块可以表示为
Y = TokenMixer ( Norm ( X ) ) + X , (2) Y=\text { TokenMixer }(\operatorname{Norm}(X))+X, \tag{2} Y= TokenMixer (Norm(X))+X,(2)
其中Norm(·)表示层规范化[1]或批规范化[28]等规范化;TokenMixer(·)是一个主要用于混合token信息的模块。它是通过最近的视觉Transformer模型[17,63,68]中的各种注意力机制或类MLP模型中的空间MLP实现的[51,52]。请注意,令牌混合器的主要功能是传播令牌信息,尽管一些令牌混合器也可以混合通道,如attention。
第二个子块主要由一个非线性激活的两层MLP组成,
Z
=
σ
(
Norm
(
Y
)
W
1
)
W
2
+
Y
(2)
Z=\sigma\left(\operatorname{Norm}(Y) W_{1}\right) W_{2}+Y \tag{2}
Z=σ(Norm(Y)W1)W2+Y(2)
其中 W 1 ∈ R C × r C W_{1} \in \mathbb{R}^{C \times r C} W1∈RC×rC、 W 2 ∈ R r C × C W_{2} \in \mathbb{R}^{r C \times C} W2∈RrC×C为MLP膨胀比r的可学习参数; σ ( ⋅ ) \sigma(\cdot) σ(⋅)是一个非线性激活函数,如GELU[25]或ReLU[41]。
MetaFormer的实例化。 MetaFormer描述了一种通用架构,通过指定token mixer的具体设计,可以立即获得不同的模型。如图1(a)所示,如果将token mixer指定为attention或spatial MLP,则MetaFormer将分别成为Transformer或类似MLP的模型
3.2. PoolFormer
从transformer[56]的介绍开始,大量工作都非常重视和关注设计各种基于注意力的token mixer组件。相比之下,这些工作很少关注通用架构,即MetaFormer。
本文认为,这种MetaFormer通用架构在很大程度上有助于最近的Transformer和mlp模型的成功。为了演示这一点,我们故意使用一个非常简单的操作符pooling作为token mixer。该操作符没有可学习的参数,它只是使每个标记平均地聚合其附近的标记特征。
由于这项工作是针对视觉任务的,假设输入是通道优先的数据格式,即
T
∈
R
C
×
H
×
W
T \in \mathbb{R}^{C \times H \times W}
T∈RC×H×W
T : , i , j ′ = 1 K × K ∑ p , q = 1 K T : , i + p − K + 1 2 , i + q − K + 1 2 − T : , i , j T_{:, i, j}^{\prime}=\frac{1}{K \times K} \sum_{p, q=1}^{K} T_{:, i+p-\frac{K+1}{2}, i+q-\frac{K+1}{2}}-T_{:, i, j} T:,i,j′=K×K1p,q=1∑KT:,i+p−2K+1,i+q−2K+1−T:,i,j
其中K是池化大小。由于MetaFormer块已经具有残差连接,因此在公式(4)中添加对输入本身的减法。池化的类似pytorch的代码如算法1所示。
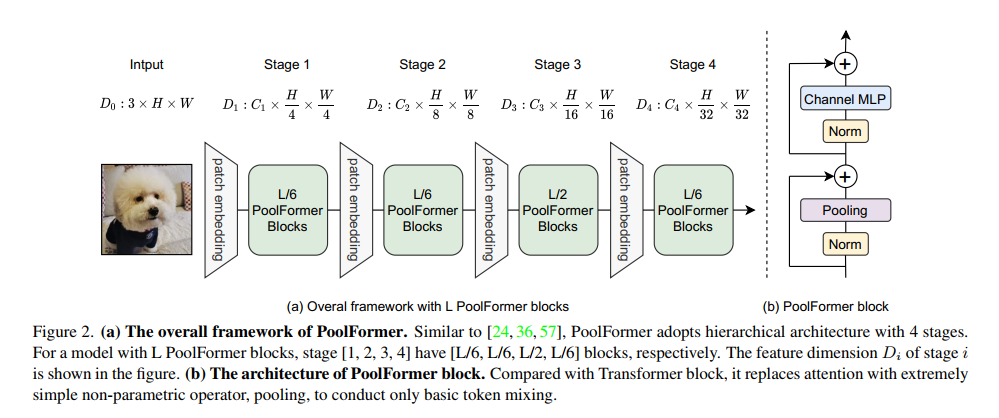
众所周知,自注意力和空间MLP的计算复杂度是要混合的token数量的二次。更糟糕的是,空间mlp在处理较长的序列时带来了更多的参数。因此,自注意力和空间mlp通常只能处理数百个标记。相比之下,池化需要与序列长度线性的计算复杂度,而无需任何可学习的参数。因此,我们通过采用类似于传统cnn[24,31,49]和最近的分层Transformer变体[36,57]的分层结构来利用池化。图2显示了PoolFormer的整体框架。具体来说,PoolFormer有4个阶段,分别为
H
4
×
W
4
\frac{H}{4} \times \frac{W}{4}
4H×4W、
H
8
×
W
8
\frac{H}{8} \times \frac{W}{8}
8H×8W、
H
16
×
W
16
\frac{H}{16} \times \frac{W}{16}
16H×16W和
H
32
×
W
32
\frac{H}{32} \times \frac{W}{32}
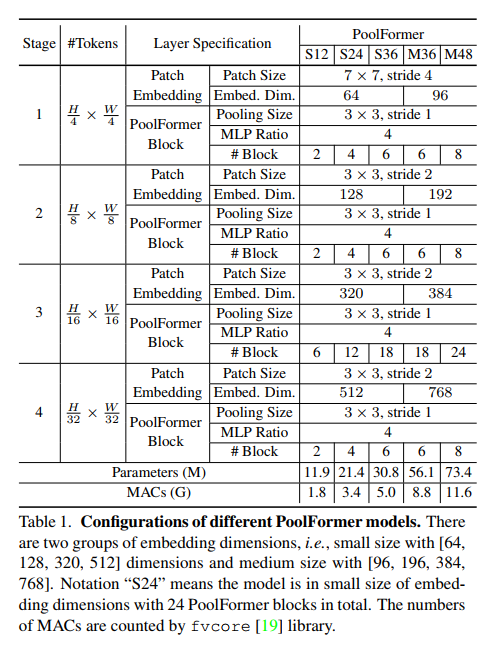
32H×32W token,其中H和W表示输入图像的宽度和高度。有两组嵌入大小:1)小型模型,嵌入维度分别为64、128、320和512;2)嵌入尺寸为96、192、384和768的中型模型。假设总共有L个PoolFormer块,阶段1、2、3和4将分别包含L/6、L/6、L/2和L/6个PoolFormer块。设置MLP膨胀率为4。根据上述简单的模型缩放规则,我们得到了5种不同模型大小的PoolFormer,其超参数如表1所示。
4. 实验
4.1. 图像分类
设置。 ImageNet-1K[14]是计算机视觉中使用最广泛的数据集之一。它包含大约130万张训练图像和50K张验证图像,涵盖了常见的1K类。我们的培训方案主要遵循[53]和[54]。具体来说,MixUp [65], CutMix [64], CutOut[66]和RandAugment[11]用于数据增强。使用AdamW优化器[29,37]对模型进行300 epoch的训练,权重衰减0.05,峰值学习率lr = 1e−3·batch size/1024(本文使用批量大小4096和学习率4e−3)。预热epoch的数量为5,使用余弦计划来衰减学习率。标签平滑[50]设置为0.1。Dropout被禁用,但使用随机深度[27]和LayerScale[54]来帮助训练深度模型。我们修改了层归一化[1],以计算沿着token和通道维度的均值和方差,而不是仅在普通层归一化中的通道维度。通过指定组编号为1,可以使用PyTorch中的GroupNorm API实现通道优先数据格式的修改层规范化(MLN)。如4.4节所示,PoolFormer首选MLN。有关超参数的更多细节,请参阅附录。实验基于Timm代码库[58]实现,并在tpu上进行。
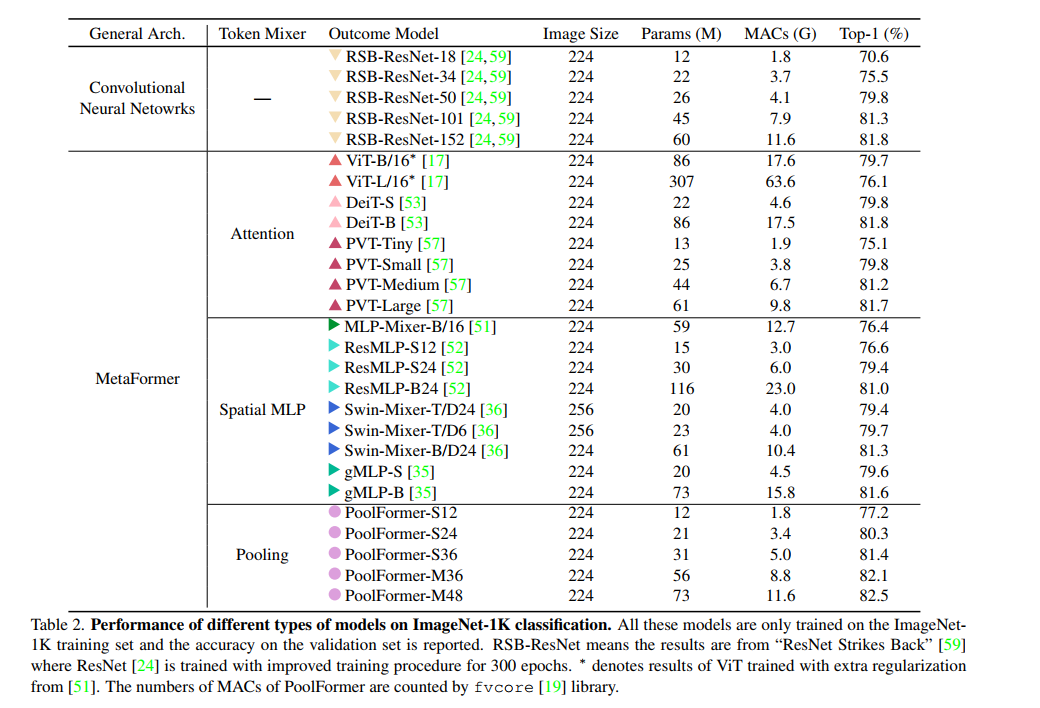
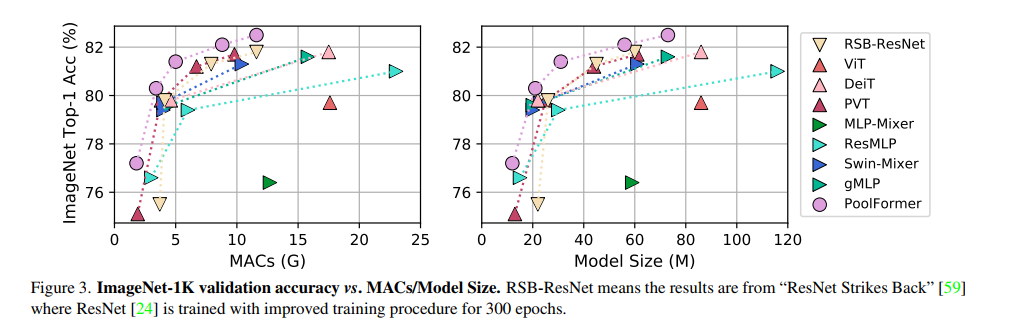
结果。 表2显示了poolformer在ImageNet分类上的性能。定性结果见附录。令人惊讶的是,尽管使用了简单的池化令牌混合器,但与cnn和其他类metaformer模型相比,poolformer仍然可以实现极具竞争力的性能。例如,PoolFormer-S24在只需要21M参数和3.4G mac的情况下,达到了80以上的top-1精度。相比之下,建立良好的ViT基线DeiT-S[53]的精度略差,为79.8,需要更多35%的mac (4.6G)。为了获得类似的精度,类mlp模型ResMLP-S24[52]需要多43%的参数(30M)和76%的计算量(6.0G),而精度仅为79.4。即使与更改进的ViT和MLPlike变体相比[35,57],PoolFormer仍然表现出更好的性能。具体来说,金字塔变压器PVTMedium在44M参数和6.7G MACs下获得81.2的top-1精度,而PoolFormer-S36在比PVT-Medium少30%的参数(31M)和25%的MACs (5.0G)下达到81.4。
此外,与RSB-ResNet (" ResNet Strikes Back ")[59]相比,PoolFormer仍然表现更好,其中ResNet[24]使用改进的训练程序训练相同的300 epoch。通过约22M个参数/3.7G mac, RSB-ResNet-34[59]获得了75.5的精度,而PoolFormerS24可以获得80.3的精度。由于池化层的局部空间建模能力远不如神经卷积层,因此池化器的竞争性能只能归功于其通用架构元former。
使用池化操作符,每个标记均匀地聚合其附近标记的特征。因此,这是一个极其基本的token混合操作。然而,实验结果表明,即使使用这个非常简单的token mixer, MetaFormer仍然可以获得非常有竞争力的性能。图3清楚地显示,PoolFormer比其他模型具有更少的mac和参数。这一发现表明,通用架构MetaFormer实际上是我们在设计视觉模型时需要的。通过采用MetaFormer,可以保证导出的模型具有达到合理性能的潜力。
4.2. 目标检测与实例分割
设置。在具有挑战性的COCO基准[34]上评估了PoolFormer,其中包括118K训练图像(train2017)和5K验证图像(val2017)。在训练集上对模型进行训练,并在验证集上进行性能测试。PoolFormer被用作两个标准检测器的主干,即RetinaNet[33]和Mask R-CNN[23]。利用ImageNet预训练权重来初始化主干,Xavier[20]来初始化添加的层。采用AdamW[29,37]进行训练,初始学习率为1×10−4,批量大小为16。接下来[23,33],我们采用1×训练时间表,即训练12个周期的检测模型。训练图像被调整为短边800像素,长边不超过1333像素。为了测试,图像较短的一侧也被调整为800像素。基于mmdetection[4]代码库,在8张NVIDIA A100 gpu上进行了实验。
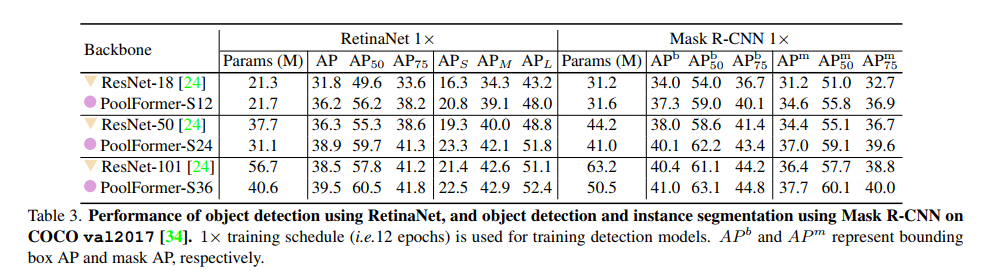
结果。如表3所示,基于poolformer的模型配备了用于对象检测的RetinaNet,其性能始终优于类似的ResNet模型。例如,PoolFormer-S12达到了36.2 AP,大大超过了ResNet-18的31.8 AP。基于maskR-CNN的模型在目标检测和实例分割上也有相似的结果。例如,PoolFormer-S12在很大程度上超过了ResNet-18(边界框AP 37.3比34.0,mask AP 34.6比31.2)。总的来说,在COCO对象检测和实例分割方面,PoolForemrs取得了具有竞争力的性能,始终优于ResNet。
4.3. 语义分割
设置。选择具有挑战性的场景解析基准ADE20K[67]来评估语义分割模型。该数据集在训练集和验证集中分别包含20K和2K图像,涵盖150个细粒度语义类别。poolformer被评估为配备语义FPN[30]的骨干。ImageNet-1K训练的检查点用于初始化主干,而Xavier[20]用于初始化其他新添加的层。常用实践[5,30]训练模型80K次迭代,批大小为16。为了加快训练速度,我们将批大小增加一倍至32,并将迭代次数减少至40K。采用AdamW[29,37],初始学习率为2 × 10−4,将在多项式衰减计划中以0.9的幂衰减。将图像调整大小并裁剪为512 × 512用于训练,将图像调整为512像素的较短一侧用于测试。我们的实现基于mmsegmentation[10]代码库,实验在8个NVIDIA A100 gpu上进行。
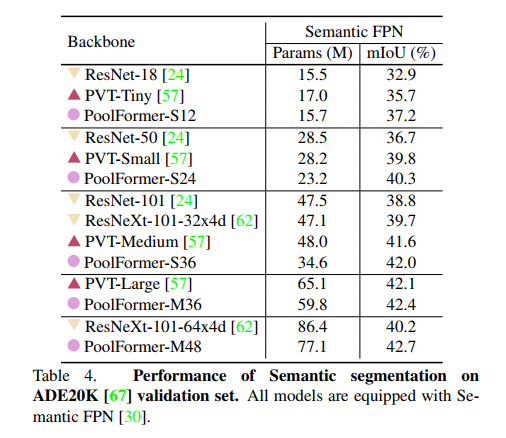
结果。表4显示了使用FPN[30]对不同骨干网的ADE20K语义分割性能。基于poolformer的模型的性能始终优于以基于cnn的ResNet[24]和ResNeXt[62]为骨干的模型以及基于transformer的pvm。例如,PoolFormer-12的mIoU分别比ResNet-18和pvm - tiny更好,达到37.1,分别高了4.3和1.5。
这些结果表明,作为主干的PoorFormer在语义分割上可以获得具有竞争力的性能,尽管它只是利用池来实现token之间的基本信息通信。这进一步表明了MetaFormer的巨大潜力,并支持了我们的断言,即MetaFormer正是我们所需要的。
4.4. 消融研究
消融实验在ImageNet-1K[14]数据集上进行。表5报告了PoolFormer的消融研究。我们将从以下几个方面讨论消融。
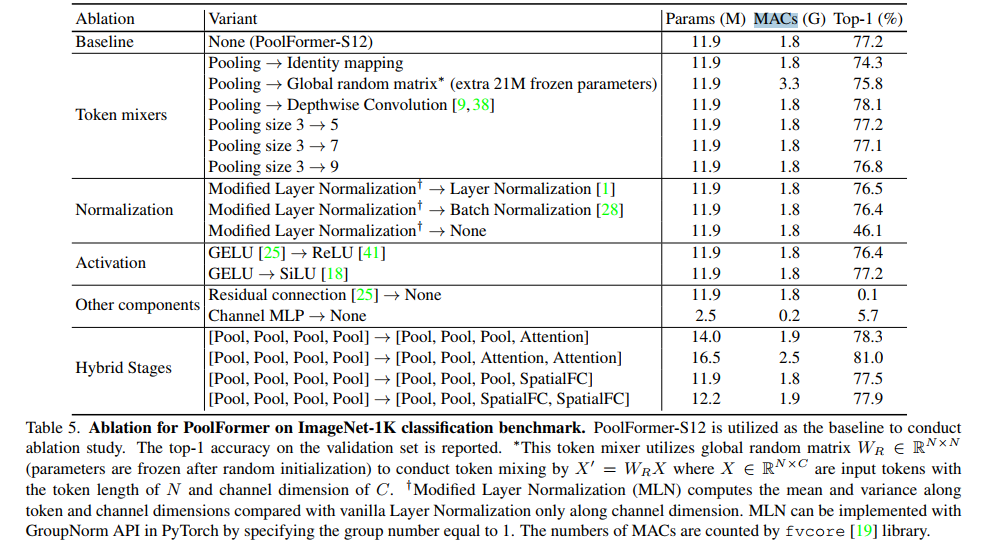
令牌混合器。与transformer相比,PoolFormer所做的主要改变是使用简单池化作为令牌混合器。首先通过直接将池化替换为身份映射来对该算子进行消融。令人惊讶的是,具有身份映射的MetaFormer仍然可以达到74.3%的top-1精度,这支持了MetaFormer实际上是我们需要保证合理性能的说法。
然后将每个块的池化替换为全局随机矩阵 W R ∈ R N × N W_{R} \in \mathbb{R}^{\mathbb{N} \times \mathbb{N}} WR∈RN×N。矩阵用区间[0,1)上均匀分布的随机值初始化,然后利用Softmax对每行进行归一化。经过随机初始化后,矩阵参数被冻结,并通过 X ′ = W R X X^{\prime}=W_{R} X X′=WRX进行token混合,其中 X ∈ R N × C X \in \mathbb{R}^{\mathbb{N} \times \mathbb{C}} X∈RN×C是输入token特征,token长度为N,通道维度为c。由于第一阶段token长度非常大,随机矩阵的token混合器为S12模型引入了额外的21M冻结参数。即使采用这种随机token混合方法,该模型仍然可以达到75.8%的准确率,比身份映射提高1.5%。它表明,即使在随机token混合的情况下,MetaFormer仍然可以很好地工作,更不用说与其他精心设计的token混合器一起工作。
此外,池化被深度卷积[9,38]取代,该卷积具有用于空间建模的可学习参数。不足为奇的是,派生模型仍然取得了极具竞争力的性能,top-1精度为78.1%,比PoolFormer-S12高出0.9%,因为它具有更好的局部空间建模能力。到目前为止,我们在Metaformer中指定了多个token mixers,所有产生的模型都保持着很好的结果,很好地支持了Metaformer是保证模型竞争力的关键的说法。由于池化的简单性,它主要用作演示MetaFormer的工具。
测试了池化大小对PoolFormer的影响。当池化大小为3、5和7时,我们观察到类似的性能。然而,当池化大小增加到9时,性能明显下降0.5%。因此,我们为PoolFormer采用默认的池化大小3。
归一化。将层归一化[1]修改为修改的层归一化(MLN),与仅计算普通层归一化中的通道维度相比,沿token和通道维度计算均值和方差。MLN的可学习仿射参数的形状与层归一化保持一致,即RC。通过将组号设置为1,可以在PyTorch中使用GroupNorm API实现MLN。详情参见附录。PoolFormer更倾向于MLN,比层规范化或批规范化高0.7%或0.8%。因此,MLN被设置为PoolFormer的默认值。去除归一化后,模型不能很好地训练收敛,性能急剧下降到仅46.1%。
激活函数。我们将GELU[25]改为ReLU[41]或SiLU[18]。当采用ReLU激活时,性能明显下降0.8%。对于四路而言,其性能几乎与格路相同。因此,我们仍然使用GELU作为默认激活。
其他组件。除了上述讨论的token混合器和归一化之外,残差连接[24]和通道MLP[46,47]是MetaFormer中的另外两个重要组件。如果没有残差连接或通道MLP,模型无法收敛,只能达到0.1%/5.7%的精度,证明了这些部分的不可缺少性。
混合阶段。在基于池化、注意力和空间MLP的token mixers中,基于池化的token mixers可以处理更长的输入序列,而注意力和空间MLP擅长捕捉全局信息。因此,考虑到序列已大大缩短,在底部阶段堆叠具有池化的元转换器来处理长序列,并在顶部阶段使用注意力或基于空间mlp的混合器是很直观的。因此,在PoolFormer的前一或两个阶段,将token混合器池化替换为注意力或空间FC1。从表5可以看出,混合模型表现相当好。在底部两个阶段使用池化,在顶部两个阶段使用注意力的变体提供了具有高度竞争力的性能。在仅16.5M参数和2.5G mac的情况下,达到了81.0%的准确率。作为对比,ResMLP-B24需要7.0× parameters (116M)和9.2× MACs (23.0G)才能达到相同的精度。这些结果表明,将MetaFormer的池化与其他token mixers相结合,可能是进一步提高性能的一个有希望的方向。
5. 结论及未来工作展望
本文将Transformer中的注意力抽象为token mixer,将整个Transformer抽象为称为MetaFormer的通用架构,其中没有指定token mixer。本文指出,MetaFormer实际上是我们需要保证实现合理性能的东西,而不是专注于特定的token mixers。为了验证这一点,我们故意将token mixer指定为MetaFormer的极其简单的池化。发现导出的PoolFormer模型可以在不同的视觉任务上取得有竞争力的性能,很好地支持了" MetaFormer实际上是你视觉所需的"这一观点。
未来,我们将在更多不同的学习环境下进一步评估PoolFormer,如自监督学习和迁移学习。此外,有趣的是,看看PoolFormer是否仍然适用于NLP任务,以进一步支持“MetaFormer实际上是你在NLP领域所需要的”的说法。希望这项工作可以启发更多致力于改进基本架构MetaFormer的未来研究,而不是过度关注token mixer模块。
缩写解释
MACs(Multiply–Accumulate Operations):乘加累积操作数,常常被人们与FLOPs概念混淆实际上1MACs包含一个乘法操作与一个加法操作,大约包含2FLOPs。通常MACs与FLOPs存在一个2倍的关系。