目录
- 概述
- 传统score-based generative modeling介绍
- score matching
- Langevin dynamics
- 传统score-based generative modeling存在的问题
- 流型假设上的问题
- 低密度区域的问题
- Noise Conditional Score Network
- 噪声条件分数网络(Noise Conditional Score Networks)
- annealed Langevin dynamics
- 参考
概述
论文提出了一种生成模型,并将其用于图像生成任务。
论文先介绍了传统score-based generative modeling方法,然后分析传统score-based generative modeling存在的问题,最后提出解决问题的算法noise conditional score network。
传统score-based generative modeling介绍
假设数据集中的数据服从
p
d
a
t
a
(
x
)
p_{data}(\mathbf{x})
pdata(x)分布。
generative modeling的目标是学习一个生成模型来生成服从
p
d
a
t
a
(
x
)
p_{data}(\mathbf{x})
pdata(x)分布的新样本。
定义score function为对概率密度函数
p
(
x
)
p(\mathbf{x})
p(x)求导
∇
x
log
p
(
x
)
\nabla_\mathbf{x}\log p(\mathbf{x})
∇xlogp(x)。
定义score network是一个参数为
θ
\theta
θ的神经网络
s
θ
s_\theta
sθ,其试图近似score function。
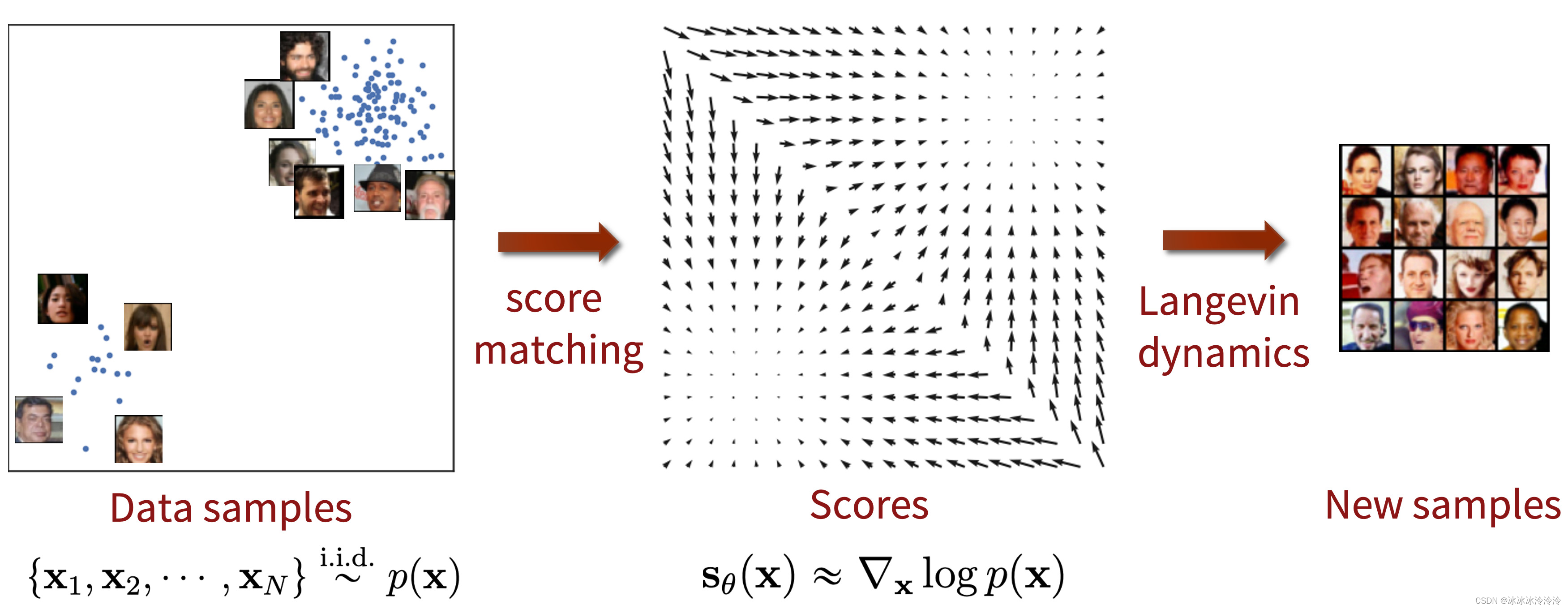
score-based generative modeling通过学习score function,加上Langevin dynamics采样,来生成符合分布的新样本,步骤如下图所示:
score matching
使用score matching算法,我们可以直接训练一个分数网络
s
θ
(
x
)
s_\theta(\mathbf{x})
sθ(x)来估计
∇
x
log
p
d
a
t
a
(
x
)
\nabla_\mathbf{x}\log p_{data}(\mathbf{x})
∇xlogpdata(x)而无需训练模型估计
p
d
a
t
a
(
x
)
p_{data}(\mathbf{x})
pdata(x)。好处是可以避免概率密度函数中的归一化常数,详见score matching算法介绍。
score matching算法的优化目标如下:
1
2
E
p
d
a
t
a
[
∥
s
θ
(
x
)
−
∇
x
log
p
d
a
t
a
(
x
)
∥
2
2
]
\frac{1}{2}\mathbb{E}_{p_{data}}[\|\mathbf{s}_\theta(\mathbf{x})-\nabla_\mathbf{x}\log p_{data}(\mathbf{x})\|^2_2]
21Epdata[∥sθ(x)−∇xlogpdata(x)∥22]上面的公式需要计算
∇
x
log
p
d
a
t
a
(
x
)
\nabla_\mathbf{x}\log p_{data}(\mathbf{x})
∇xlogpdata(x),这是一个非参数估计问题,并不好计算。值得高兴的是,上面的公式在相差常数上等价为
E
p
d
a
t
a
[
tr
(
∇
x
s
θ
(
x
)
)
+
1
2
∥
s
θ
(
x
)
∥
2
2
]
\mathbb{E}_{p_{data}}[\text{tr}(\nabla_\mathbf{x}\mathbf{s}_\theta(\mathbf{x}))+\frac{1}{2}\|\mathbf{s}_\theta(\mathbf{x})\|^2_2]
Epdata[tr(∇xsθ(x))+21∥sθ(x)∥22]最小化上面的公式可以求出
s
θ
(
x
)
\mathbf{s}_\theta(\mathbf{x})
sθ(x)。在现实中,期望可以用样本的平均代替。
但是,高维数据计算
tr
(
∇
x
s
θ
(
x
)
)
\text{tr}(\nabla_\mathbf{x}\mathbf{s}_\theta(\mathbf{x}))
tr(∇xsθ(x))复杂度很高。Denoising score matching和Sliced score matching是针对高维大数据的两种常用的改进方法。
Langevin dynamics
Langevin dynamics是一种只需要score function
∇
x
log
p
(
x
)
\nabla_\mathbf{x}\log p(\mathbf{x})
∇xlogp(x)就可以从概率密度函数
p
d
a
t
a
(
x
)
p_{data}(\mathbf{x})
pdata(x)中采样的方法,它是一种Markov chain Monte Carlo (MCMC)方法。
给一个初始分布
x
~
0
∼
π
(
x
)
\tilde{\mathbf{x}}_0\sim \pi(\mathbf{x})
x~0∼π(x),和固定的步长
ϵ
>
0
\epsilon>0
ϵ>0,Langevin方法循环地重复下面的步骤:
x
~
t
=
x
~
t
−
1
+
ϵ
2
∇
x
log
p
(
x
~
t
−
1
)
+
ϵ
z
t
\tilde{\mathbf{x}}_t=\tilde{\mathbf{x}}_{t-1}+\frac{\epsilon}{2}\nabla_\mathbf{x}\log p(\tilde{\mathbf{x}}_{t-1})+\sqrt{\epsilon}\mathbf{z}_t
x~t=x~t−1+2ϵ∇xlogp(x~t−1)+ϵzt其中
z
t
∼
N
(
0
,
I
)
\mathbf{z}_t\sim\mathcal{N}(0,\mathbf{I})
zt∼N(0,I)。当
ϵ
→
0
\epsilon\rightarrow0
ϵ→0,
T
→
∞
T\rightarrow\infin
T→∞时,
x
~
T
\tilde{\mathbf{x}}_T
x~T的分布是
p
d
a
t
a
(
x
)
p_{data}(\mathbf{x})
pdata(x)。
传统score-based generative modeling存在的问题
流型假设上的问题
流型假设指出,现实世界中的数据倾向于集中在嵌入高维空间(也称为环境空间)中的低维流形上。
The manifold hypothesis states that data in the real world tend to concentrate on low dimensional manifolds embedded in a high dimensional space (a.k.a., the ambient space).
在流型假设下,score-based generative models存在两个问题:
- ∇ x log p d a t a ( x ) \nabla_\mathbf{x}\log p_{data}(\mathbf{x}) ∇xlogpdata(x)在低维流型上没有定义。
- 只有在数据分布是整个空间时,score估计量才具有一致性(consistent)。
低密度区域的问题
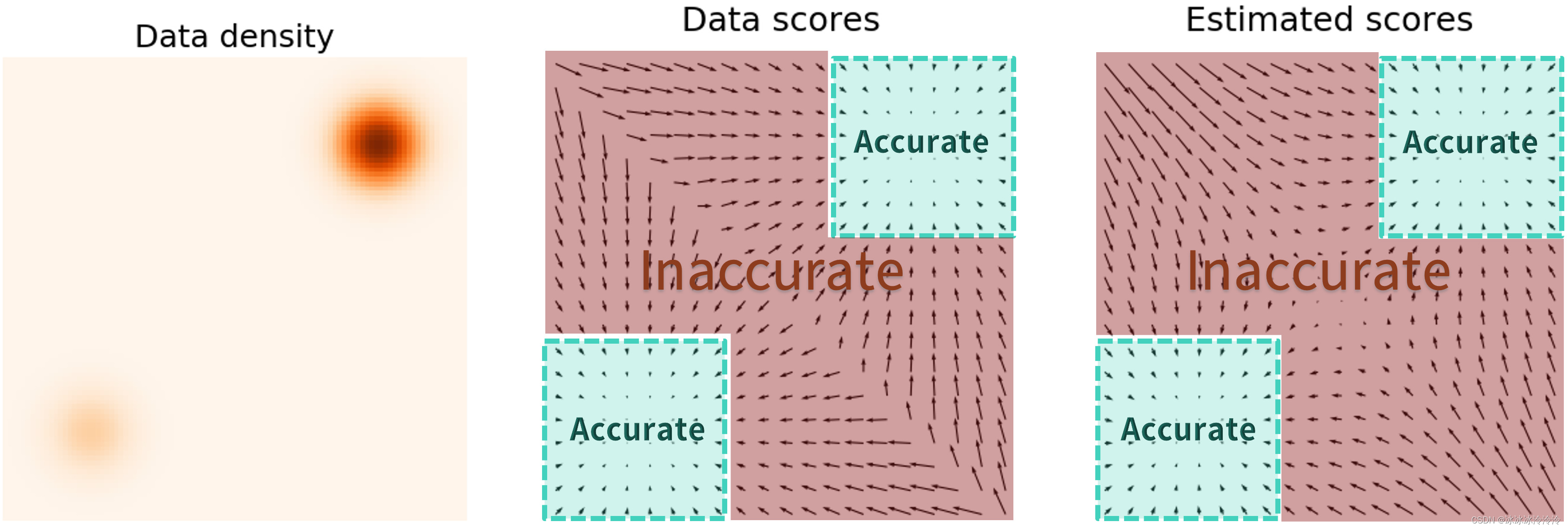
- 在数据的低密度区域,并没有足够的数据样本去准确地学习score function。
- 当数据分布的两个峰(mode)被低密度区域分隔时,Langevin dynamics将无法在合理的时间内正确恢复这两个峰的相对权重,并且可能不会收敛到真实分布。例如,假设 p d a t a ( x ) = π p 1 ( x ) + ( 1 − π ) p 2 ( x ) p_{data}(\mathbf{x})=\pi p_{1}(\mathbf{x})+(1-\pi)p_{2}(\mathbf{x}) pdata(x)=πp1(x)+(1−π)p2(x),并且 p 1 p_{1} p1和 p 2 p_{2} p2没有相交的支撑集,在求导后,权重 π \pi π将不会影响score function。
Noise Conditional Score Network
为了解决上面的问题,作者对传统score-based generative modeling进行了改进。
作者提出通过 1) 使用各种噪声水平来扰动数据;2)用一个条件分数网络(conditional score network)同时估计所有噪声水平对应的分数。
在条件分数网络训练结束后,使用Langevin dynamics来生成样本时,最开始使用高噪声对应的分数,然后逐渐降低噪音。 这有助于将高噪声的好处平稳地转移到低噪声。而低噪声干扰的数据与原始数据几乎无法区分。
噪声条件分数网络(Noise Conditional Score Networks)
{
σ
i
}
i
=
1
L
\{\sigma_i\}_{i=1}^L
{σi}i=1L是一系列噪声水平,满足条件
σ
1
σ
2
=
⋯
=
σ
L
−
1
σ
L
>
1
\frac{\sigma_{1}}{\sigma_{2}}=\cdots=\frac{\sigma_{L-1}}{\sigma_{L}}>1
σ2σ1=⋯=σLσL−1>1,
q
σ
(
x
)
q_\sigma(\mathbf{x})
qσ(x)是噪声扰动后的数据分布。我们要学习一个噪声条件分数网络
s
θ
(
x
,
σ
)
s_\theta(\mathbf{x},\sigma)
sθ(x,σ)来估计噪声数据的分数,也就是
s
θ
(
x
,
σ
)
≈
∇
x
log
q
σ
(
x
)
s_\theta(\mathbf{x},\sigma)\approx\nabla_\mathbf{x}\log q_\sigma(\mathbf{x})
sθ(x,σ)≈∇xlogqσ(x)。注意这里的分数网络是条件分数网络,输入相较于传统的
s
θ
(
x
)
s_\theta(\mathbf{x})
sθ(x)多了一个
σ
\sigma
σ。
作者考虑的是图像生成的问题,所以
s
θ
(
x
,
σ
)
s_\theta(\mathbf{x},\sigma)
sθ(x,σ)的结构作者选择的是U-Net。
对于噪声条件分数网络的训练,作者选择的噪声分布是
q
σ
(
x
~
∣
x
)
=
N
(
x
~
∣
x
,
σ
2
I
)
q_\sigma( \tilde {x} |x)=\mathcal{N}( \tilde{x} |x, \sigma^{2}\mathbf{I})
qσ(x~∣x)=N(x~∣x,σ2I)。
对于一个给定的噪声
σ
\sigma
σ,优化的目标是:
l
(
θ
,
σ
)
=
1
2
E
p
d
a
t
a
E
x
~
∼
N
(
x
,
σ
2
I
)
[
∥
s
θ
(
x
~
,
σ
)
+
x
~
−
x
σ
2
∥
2
2
]
\mathcal{l}(\theta,\sigma)=\frac{1}{2}\mathbb{E}_{p_{data}}\mathbb{E}_{\tilde\mathbf{x} \sim \mathcal{N}(x, \sigma^{2}\mathbf{I})}[\| s_\theta(\tilde\mathbf{x},\sigma) + \frac{\tilde\mathbf{x}-\mathbf{x}}{\sigma^2} \|_2^2]
l(θ,σ)=21EpdataEx~∼N(x,σ2I)[∥sθ(x~,σ)+σ2x~−x∥22]将所有的噪声融合在一个式子中有:
L
(
θ
;
{
σ
i
}
i
=
1
L
)
≜
1
L
∑
i
=
1
L
λ
(
σ
i
)
l
(
θ
,
σ
i
)
\mathcal{L}(\theta;\{\sigma_i\}_{i=1}^L)\triangleq\frac{1}{L}\sum_{i=1}^L\lambda(\sigma_i)\mathcal{l}(\theta,\sigma_i)
L(θ;{σi}i=1L)≜L1i=1∑Lλ(σi)l(θ,σi)
annealed Langevin dynamics
在噪声条件分数网络
s
θ
(
x
;
σ
)
s_\theta(\mathbf{x};\sigma)
sθ(x;σ)训练完成之后,作者提出annealed Langevin dynamics算法来生成样本, 如算法1所示。

参考
Yang Song’s blog《Generative Modeling by Estimating Gradients of the Data Distribution》
NIPS 2019《Generative Modeling by Estimating Gradients of the Data Distribution》





![[附源码]计算机毕业设计的实验填报管理系统Springboot程序](https://img-blog.csdnimg.cn/d9077275bfe147dcadfdcce26f769fd0.png)



![[附源码]Python计算机毕业设计房屋租赁管理系统设计Django(程序+LW)](https://img-blog.csdnimg.cn/ffe5616f2cba4066a94e1ab63536c2c0.png)