文章目录
- 一、RNN介绍
- 1.1 RNN为什么能处理有序数据?
- 1.2 RNNCell内部剖析
- 二、How to use RNNCell In PyTorch
- 2.1 参数分析
- 2.2 PyTorch代码实现
- 三、How to use RNN In PyTorch
- 3.1 参数分析
- 3.2 NumLayers
- 3.3 PyTorch代码实现
- 3.4 其他参数
- 四、Example1:Using RNNCell
- 4.1 问题描述
- 4.2 字符向量化
- 4.3 RNNCell 结构描述
- 4.4 PyTorch代码实现
- 五、Example2:Using RNN Module
- 5.1 题目描述
- 5.2 PyTorch代码实现
- 六、Embedding
- 6.1 Embedding引入
- 6.2 Embedding Layer
- 6.3 Using Embedding and Linear Layer
- 6.4 PyTorch代码
- 七、课后练习1:使用LSTM
- 7.1 初识LSTM
- 7.2 PyTorch代码
- 八、课后练习2:使用GRU
- 8.1 初识GRU
- 8.2 PyTorch代码
一、RNN介绍
1.1 RNN为什么能处理有序数据?
RNN的特点在于其可以用来处理有顺序要求的分类任务,例如自然语言处理、时间序列预测等。
Q:那么RNN为什么可以处理有序数据呢?
A:因为其具有一个特殊结构,称之为RNNCell。
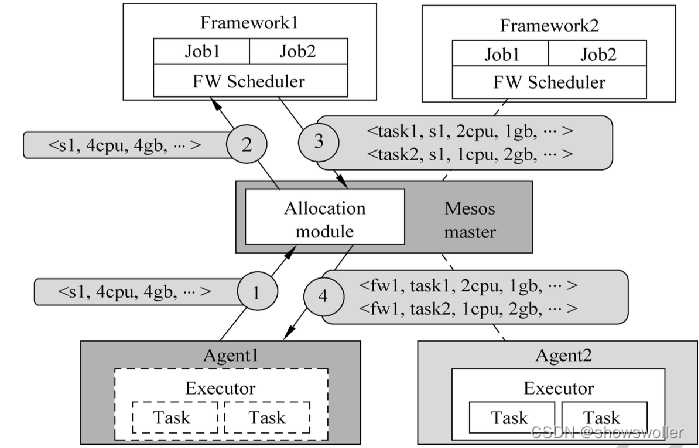
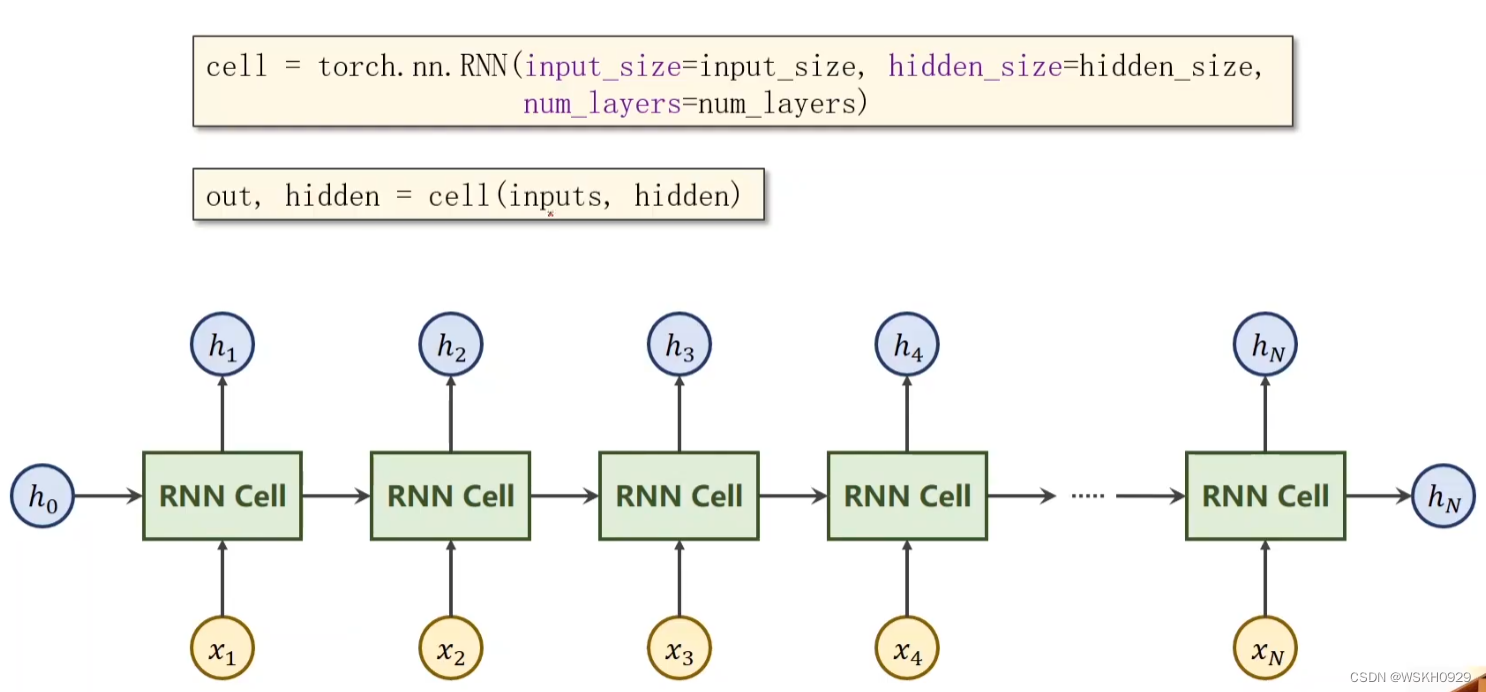
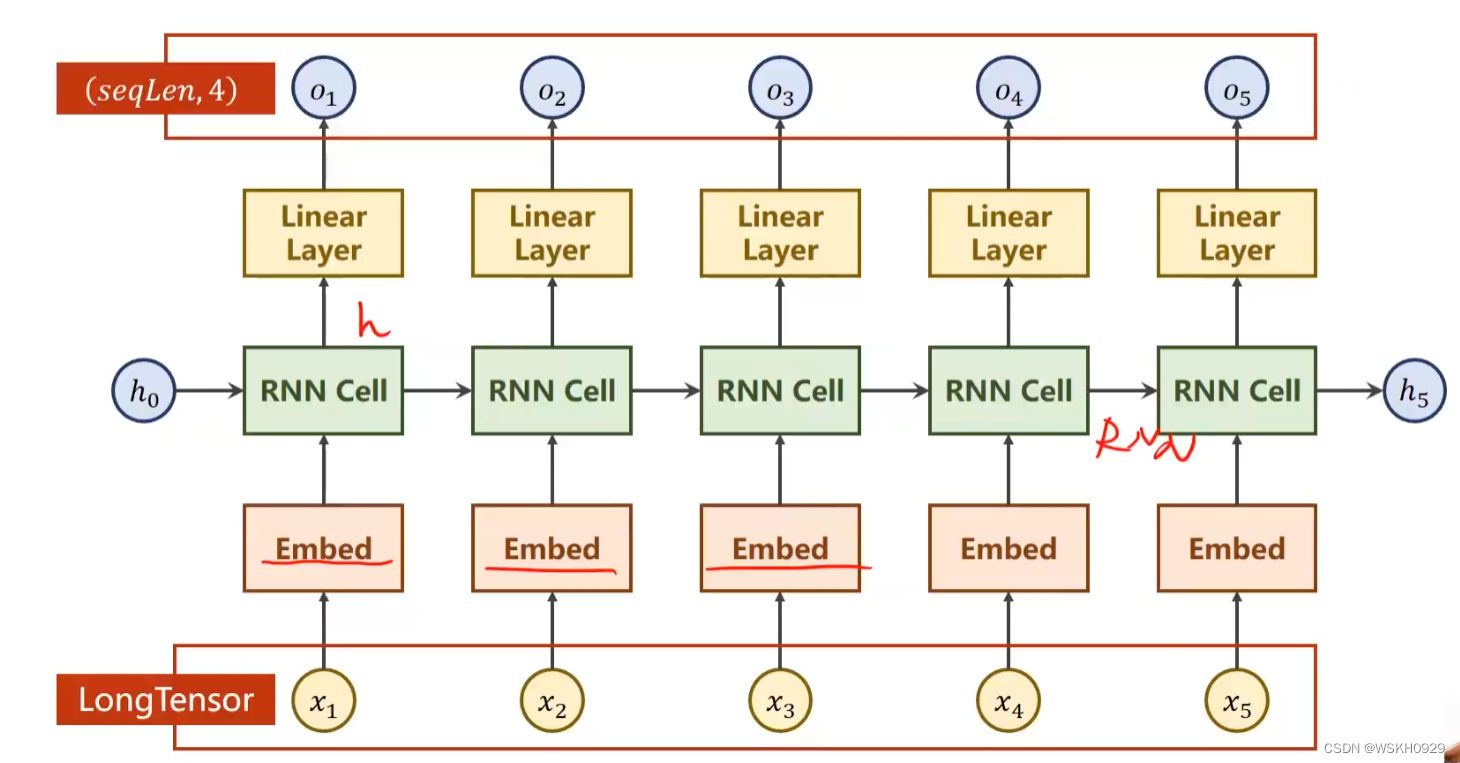
如下图所示,在RNNCell最左端输入是h0,h0可以看作是先验知识,例如我们希望根据图片和要求的主题来输出对应文字,那么我们可以在最左端加一个CNN提取图片特征,然后加一个LinearLayer将其转化为一维张量h0传入最左边的RNNCell,而要求的主题就通过一定编码方式(如OneHot编码)转化为x1、x2、x3等数值型数据依次传入每个RNNCell。
观察下图,我们不难发现,h0和x1在第一个RNNCell的转化后输出为h1,h1又作为第二个RNNCell的输入与x2一起被转化输出为h2,以此类推…
所以,由于RNNCell的这种串联结构,x1、x2、x3、x4的输入顺序不同,会导致最右端的RNNCell输出不同,这样就使得RNN可以有效处理有序的数据啦!
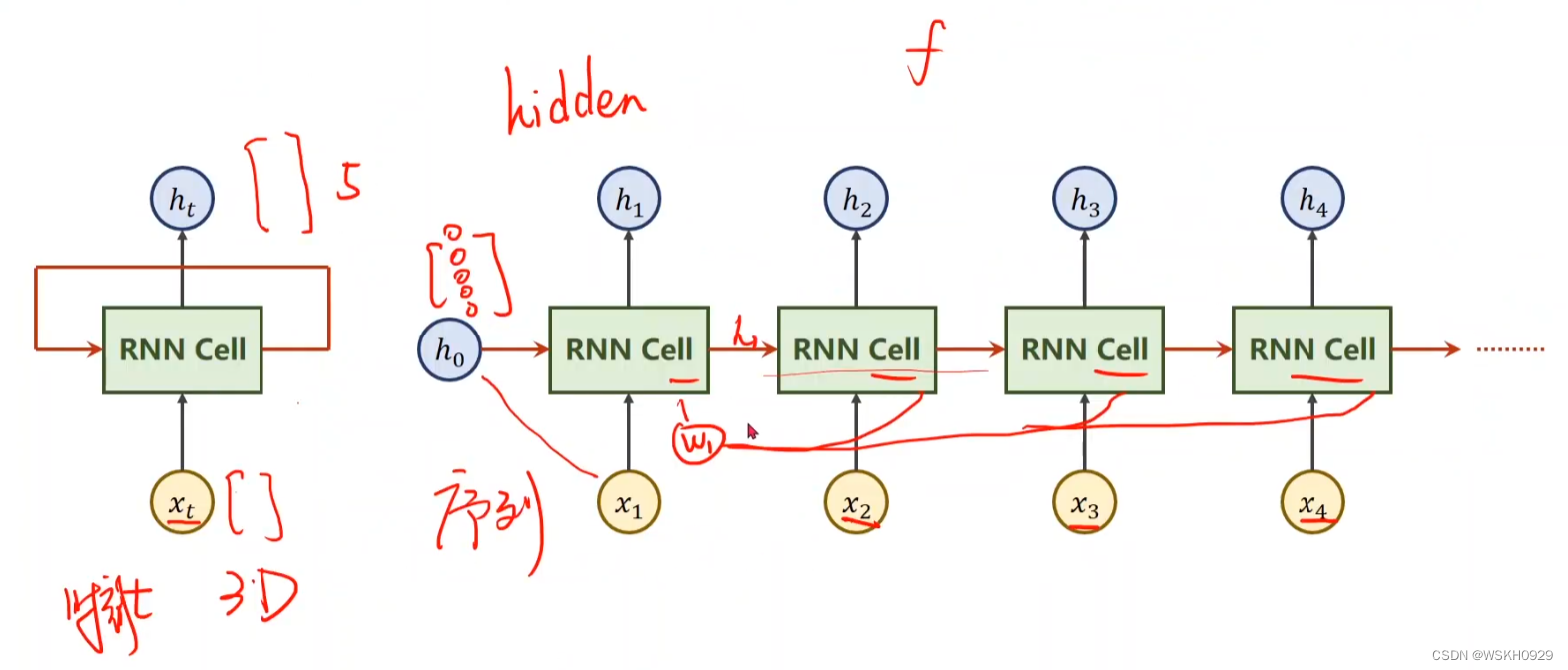
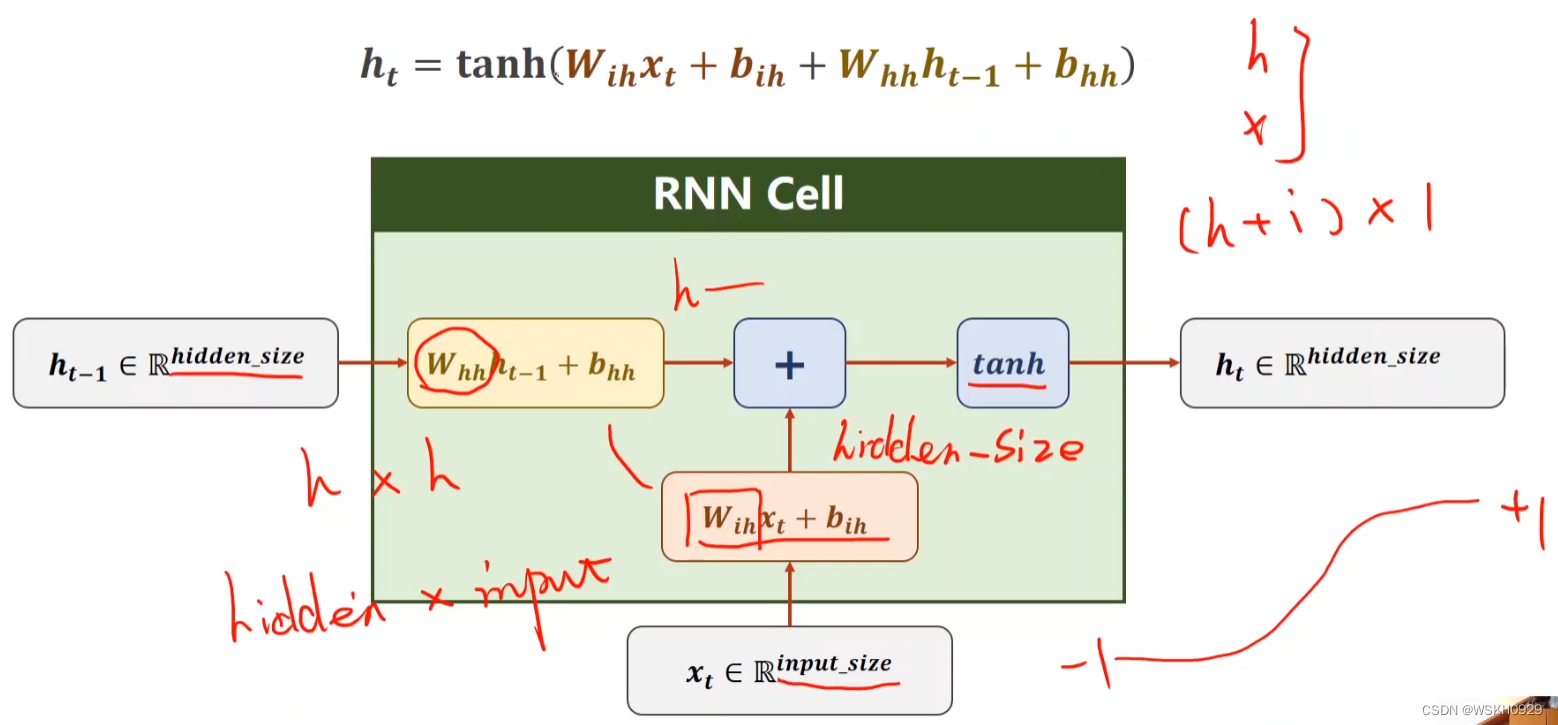
1.2 RNNCell内部剖析
通过1.1节的学习,大家一定很好奇h0和x1被输入第一个RNNCell后发生了什么?输出的h1是通过怎样的运算得到的?RNNCell内部是什么?这一节,我就带大家剖析一下RNNCell的内部!
我们以h0、x1作为输入,h1作为输出来进行讲解
很明显,通常情况下,h0和x1的尺寸是不一样的,然而他们后面却需要进行相加的操作(相加操作的前提是两个张量的尺寸一样),为了让他们尺寸一样,我们可以固定h0的尺寸不变,对x1进行左乘或者右乘的操作改变它的尺寸,假设x1尺寸为(1,4),h0尺寸为(1,2),那么我们可以让x1右乘一个尺寸为(4,2)的矩阵,这样就可以将x1的尺寸转化为(1,2)啦
同时,h0也需要乘上一个和自身最大维度值相同的方阵,然后还要加上一个偏置b,类似于LinearLayer中做的wx+b的线性变换
最后,两个调整后的张量进行相加,送入tanh激活函数进行激活,从RNNCell输出
二、How to use RNNCell In PyTorch
2.1 参数分析
batchSize:每条输入数据的行数(相当于图片的高)
inputSize:每条输入数据的列数(相当于图片的宽)
seqLen:输入数据总条数(相当于图片的数量)
hiddenSize:输出的隐藏层的列数


2.2 PyTorch代码实现

import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
rnn_cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
dataset = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(batch_size, hidden_size)
for idx, input in enumerate(dataset):
print('=' * 20, idx, input.shape, '=' * 20)
print('inputs size: ', input.shape, input)
hidden = rnn_cell(input, hidden)
print('outputs size: ', hidden.shape)
print('hidden: ', hidden)
输出:
==================== 0 torch.Size([1, 4]) ====================
inputs size: torch.Size([1, 4]) tensor([[ 0.2541, -1.2645, 0.7802, 0.6456]])
outputs size: torch.Size([1, 2])
hidden: tensor([[-0.6157, -0.8336]], grad_fn=<TanhBackward>)
==================== 1 torch.Size([1, 4]) ====================
inputs size: torch.Size([1, 4]) tensor([[ 0.1633, -2.2329, -1.4008, 0.8531]])
outputs size: torch.Size([1, 2])
hidden: tensor([[-0.7916, -0.9344]], grad_fn=<TanhBackward>)
==================== 2 torch.Size([1, 4]) ====================
inputs size: torch.Size([1, 4]) tensor([[-0.3875, -0.1787, 0.1510, 0.3284]])
outputs size: torch.Size([1, 2])
hidden: tensor([[-0.6885, -0.9451]], grad_fn=<TanhBackward>)
三、How to use RNN In PyTorch
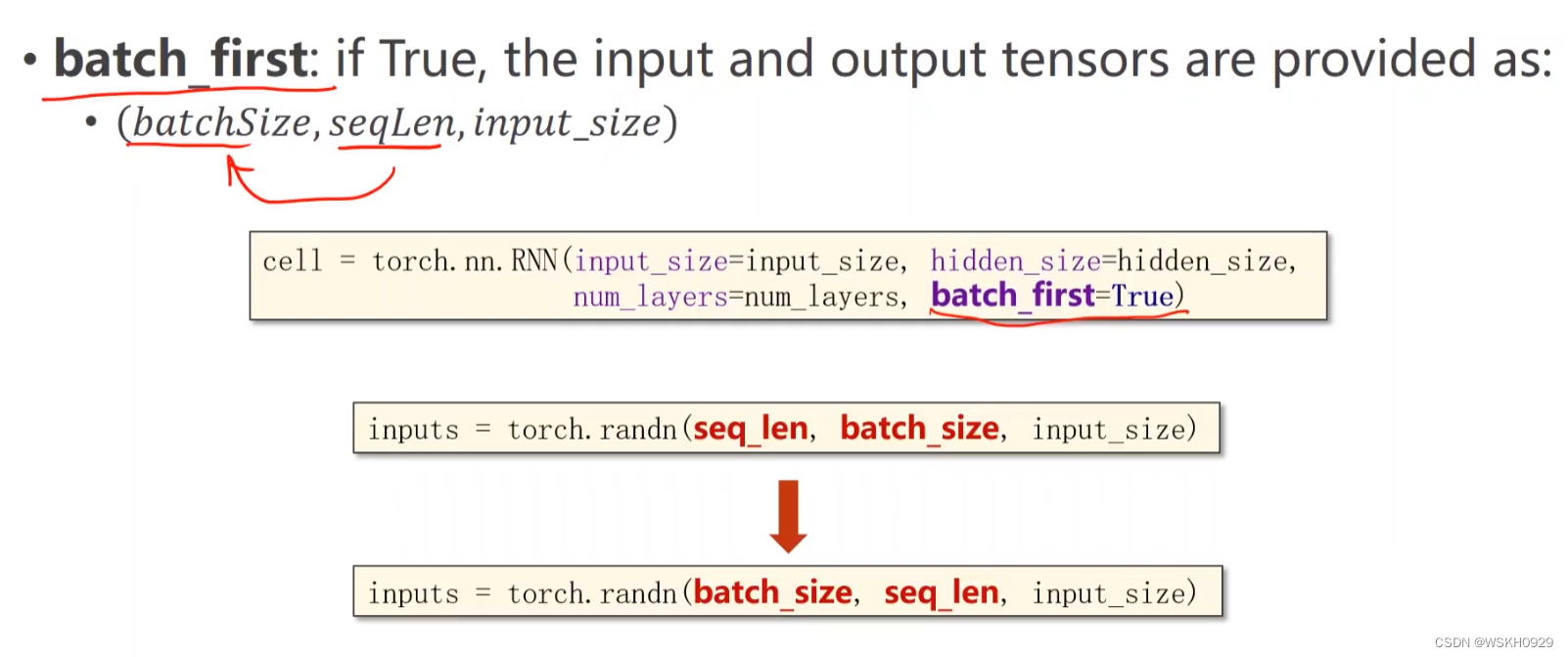
3.1 参数分析

3.2 NumLayers
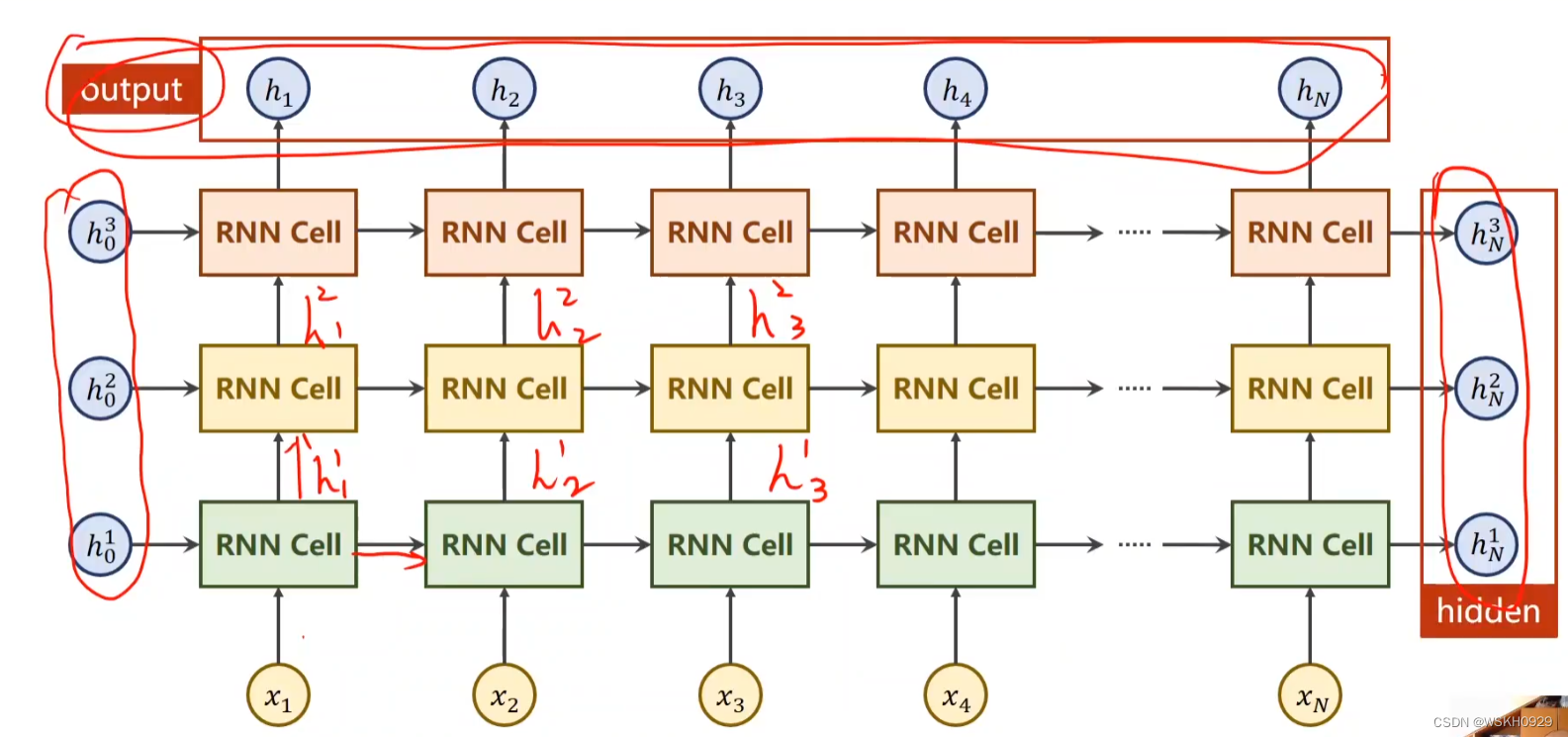
下图所示 NumLayers = 3,RNN纵向的层数
注意:在1.1节示例图中的NumLayers=1
3.3 PyTorch代码实现

import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
rnn = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
output, hidden = rnn(inputs, hidden)
print('output size: ', output.shape)
print('output: ', output)
print('hidden size: ', hidden.shape)
print('hidden: ', hidden)
输出:
output size: torch.Size([3, 1, 2])
output: tensor([[[-0.5995, -0.6150]],
[[-0.7170, 0.6757]],
[[-0.5708, -0.6134]]], grad_fn=<StackBackward>)
hidden size: torch.Size([1, 1, 2])
hidden: tensor([[[-0.5708, -0.6134]]], grad_fn=<StackBackward>)
3.4 其他参数
四、Example1:Using RNNCell
4.1 问题描述
训练一个模型,实现序列到序列的转化,如"hello" 转化为 “ohlol”
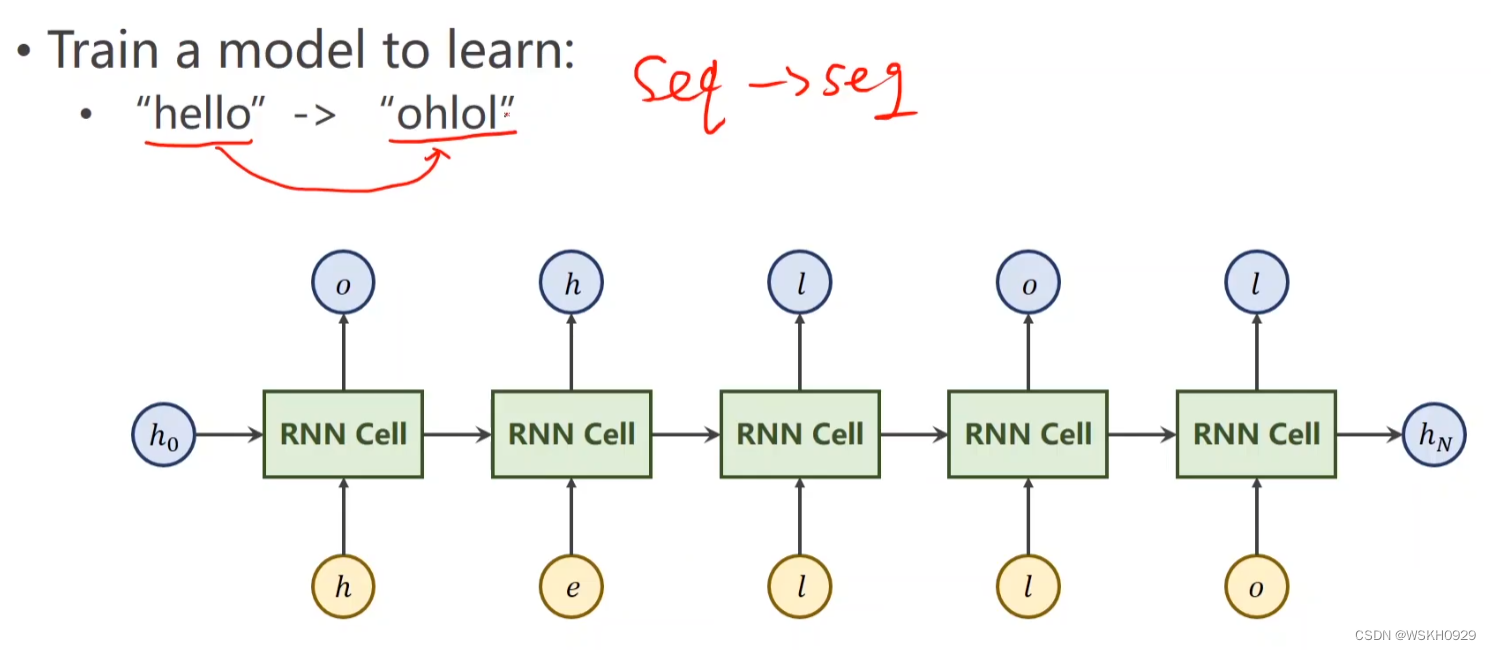
4.2 字符向量化
由于"hello"是字符型数据,不能直接进行计算,所以我们首先需要对其进行向量化
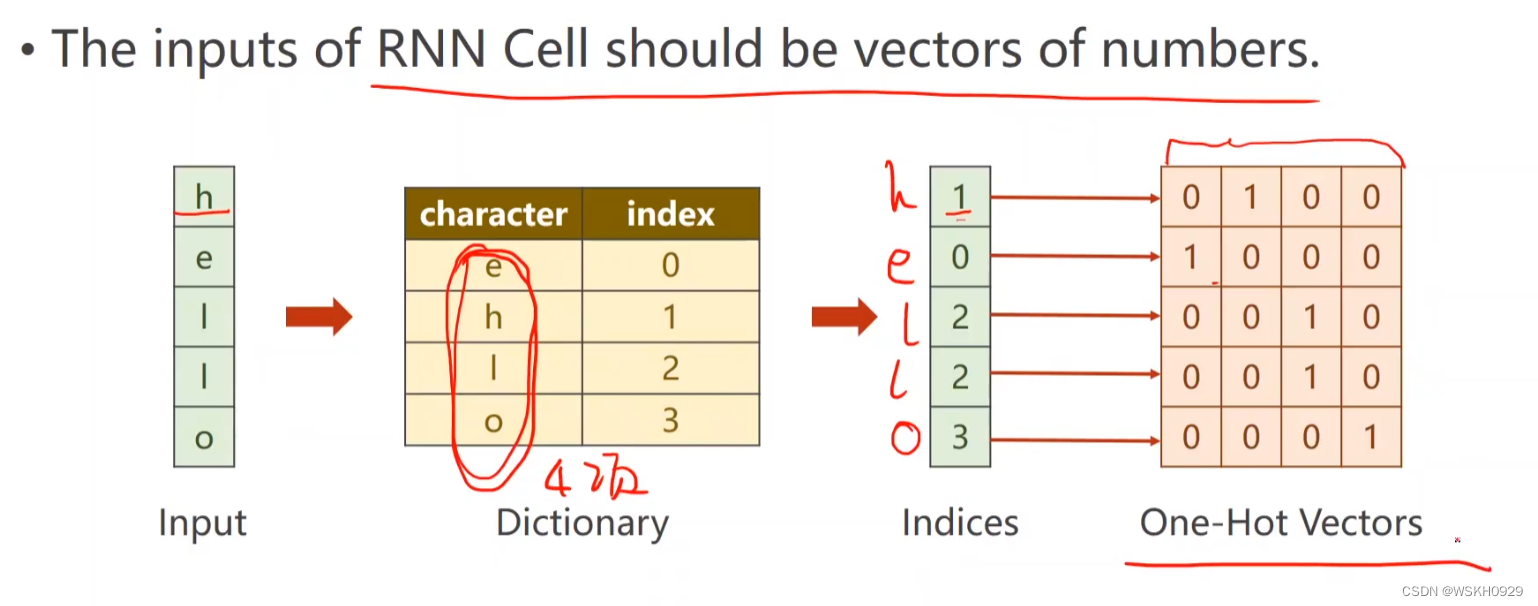
由上图可以看出,InputSize = 4
4.3 RNNCell 结构描述
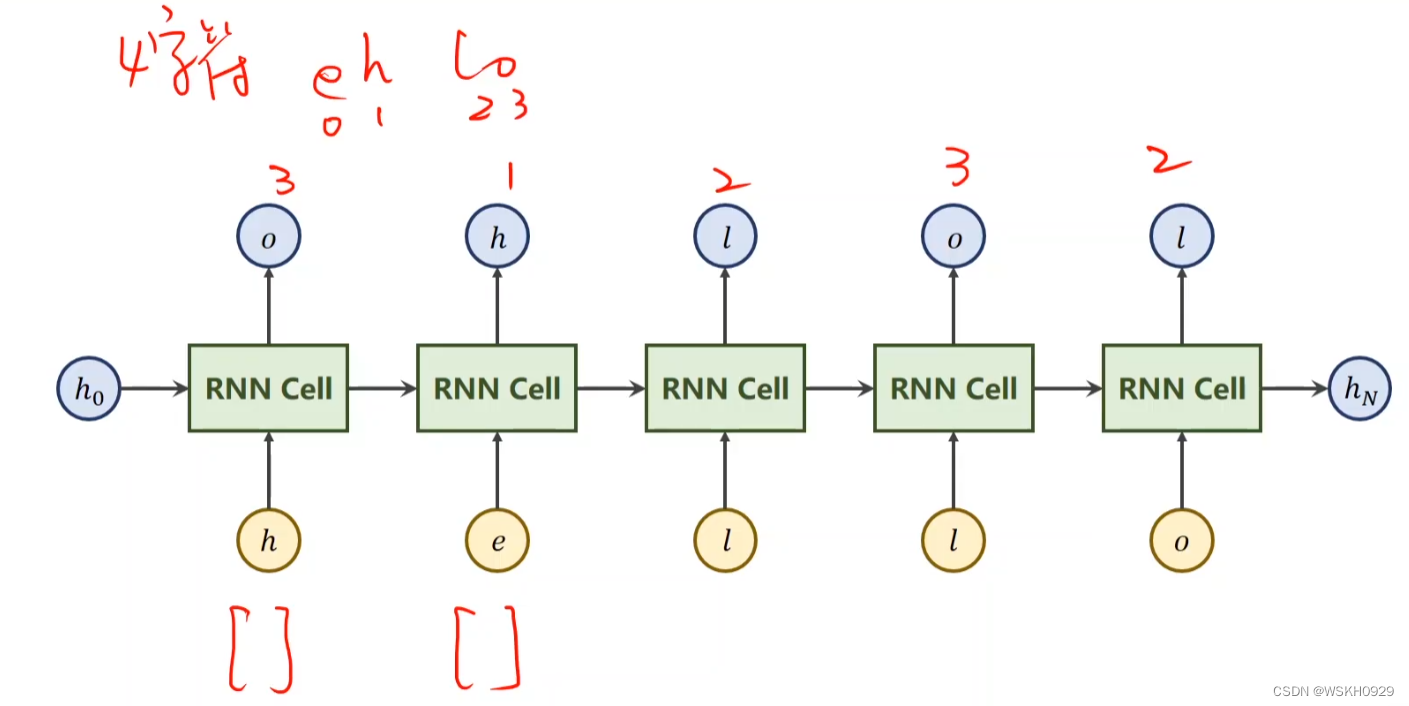
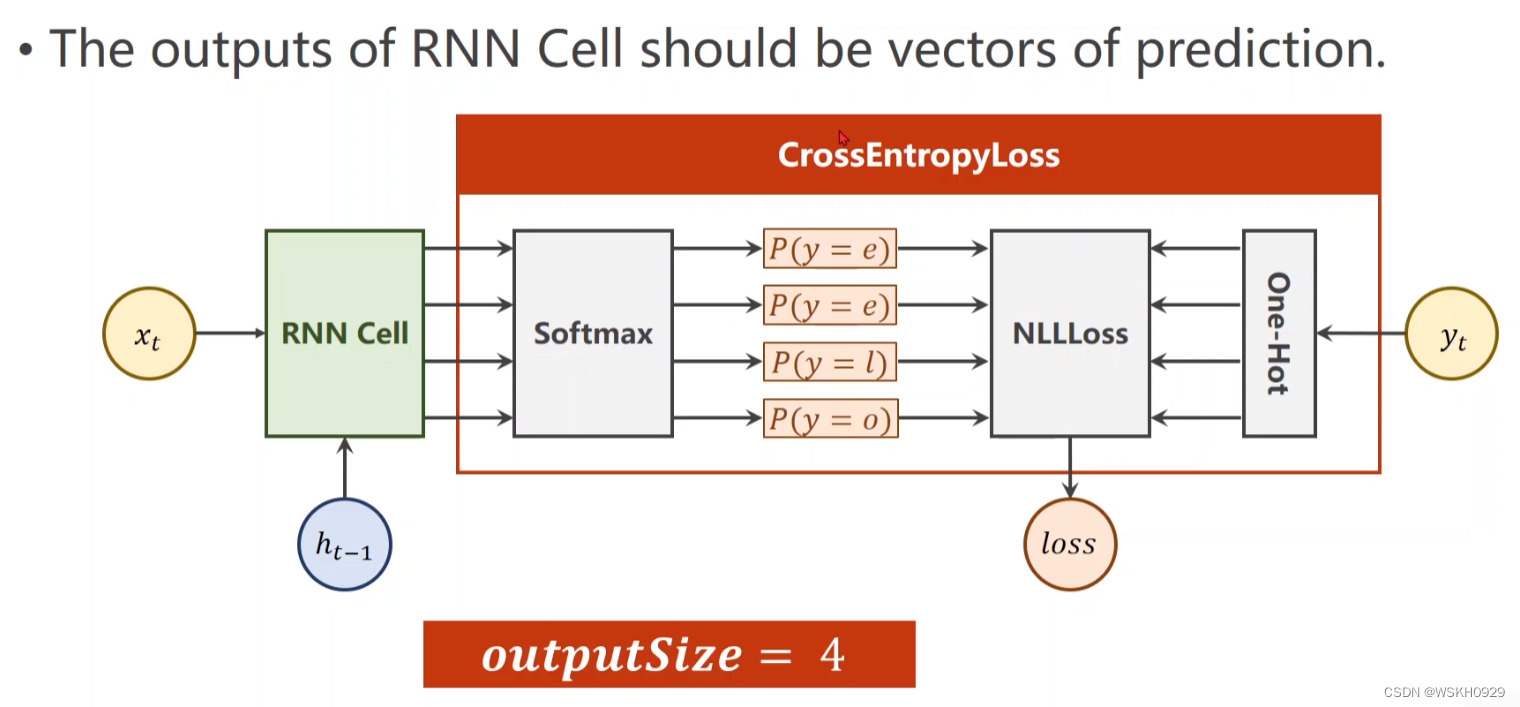
4.4 PyTorch代码实现
import torch
class RNNModel(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(RNNModel, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.batch_size = batch_size
self.rnn_cell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size)
def forward(self, input, hidden):
hidden = self.rnn_cell(input, hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
if __name__ == '__main__':
input_size = 4
hidden_size = 4
batch_size = 1
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [
[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]
]
x_one_hot = [one_hot_lookup[i] for i in x_data]
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
labels = torch.LongTensor(y_data).view(-1, 1)
# 声明RNN模型
rnn = RNNModel(input_size, hidden_size, batch_size)
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(rnn.parameters(), lr=0.05)
# 开始循环迭代训练
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = rnn.init_hidden()
print("Predicted String: ", end='')
for input, label in zip(inputs, labels):
hidden = rnn(input, hidden)
loss += criterion(hidden, label)
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(' , Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))
输出:
Predicted String: hhool , Epoch [1/15] loss=6.7361
Predicted String: hhooo , Epoch [2/15] loss=6.0646
Predicted String: hhooo , Epoch [3/15] loss=5.5975
Predicted String: ohooo , Epoch [4/15] loss=5.2145
Predicted String: ohooo , Epoch [5/15] loss=4.9139
Predicted String: ohool , Epoch [6/15] loss=4.6862
Predicted String: ohool , Epoch [7/15] loss=4.4854
Predicted String: ohool , Epoch [8/15] loss=4.2690
Predicted String: ohlol , Epoch [9/15] loss=4.0282
Predicted String: ohlol , Epoch [10/15] loss=3.7796
Predicted String: ohlol , Epoch [11/15] loss=3.5468
Predicted String: ohlol , Epoch [12/15] loss=3.3460
Predicted String: ohlol , Epoch [13/15] loss=3.1812
Predicted String: ohlol , Epoch [14/15] loss=3.0479
Predicted String: ohlol , Epoch [15/15] loss=2.9385
可以看出,从第9代开始,预测出的字符串就已经正确了(ohlol)
五、Example2:Using RNN Module
5.1 题目描述
题目和4.1节的一样
5.2 PyTorch代码实现
import torch
class RNNModel(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(RNNModel, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.batch_size = batch_size
self.num_layers = num_layers
self.rnn = torch.nn.RNN(input_size=self.input_size, hidden_size=self.hidden_size, num_layers=self.num_layers)
def forward(self, input):
hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
out, _ = self.rnn(input, hidden)
return out.view(-1, self.hidden_size)
if __name__ == '__main__':
input_size = 4
hidden_size = 4
batch_size = 1
num_layers = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [
[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]
]
x_one_hot = [one_hot_lookup[i] for i in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
labels = torch.LongTensor(y_data)
# 声明RNN模型
rnn_model = RNNModel(input_size, hidden_size, batch_size, num_layers)
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(rnn_model.parameters(), lr=0.05)
# 开始循环迭代训练
for epoch in range(15):
optimizer.zero_grad()
outputs = rnn_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print("Predicted String: ", ''.join([idx2char[x] for x in idx]), end='')
print(' , Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))
输出:
Predicted String: hhhhh , Epoch [1/15] loss=1.5084
Predicted String: hhhhl , Epoch [2/15] loss=1.3756
Predicted String: lhhhl , Epoch [3/15] loss=1.2340
Predicted String: lhlhl , Epoch [4/15] loss=1.0910
Predicted String: lhlhl , Epoch [5/15] loss=0.9662
Predicted String: lhlhl , Epoch [6/15] loss=0.8737
Predicted String: ohlhl , Epoch [7/15] loss=0.8107
Predicted String: ohlol , Epoch [8/15] loss=0.7672
Predicted String: ohlol , Epoch [9/15] loss=0.7348
Predicted String: ohlol , Epoch [10/15] loss=0.7087
Predicted String: ohlol , Epoch [11/15] loss=0.6867
Predicted String: ohlol , Epoch [12/15] loss=0.6677
Predicted String: ohlol , Epoch [13/15] loss=0.6505
Predicted String: ohlol , Epoch [14/15] loss=0.6340
Predicted String: ohlol , Epoch [15/15] loss=0.6170
六、Embedding
6.1 Embedding引入
让我们先来聊聊OneHot编码的缺点:
- One-Hot一般是高维度的(维度灾难)
- One-Hot是稀疏的
- One-Hot是硬编码(hard-coded),是依照规则确定的,不是学习出来的
我们希望有一种编码方式,可以具有以下优点:
- 低纬度的
- 稠密的
- 是从data中学习出来的
符合以上优点的 一个流行的有效的编码方式叫做 Embedding(嵌入式的)

6.2 Embedding Layer
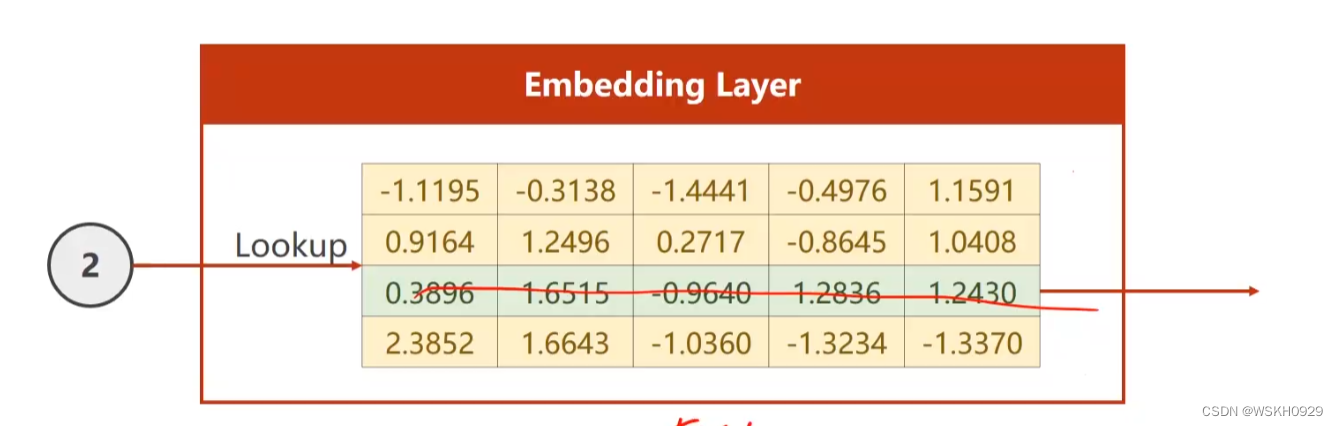
6.3 Using Embedding and Linear Layer



6.4 PyTorch代码
import torch
class RNNModel(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1, embedding_size=1):
super(RNNModel, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.batch_size = batch_size
self.num_layers = num_layers
self.embedding_size = embedding_size
self.emb = torch.nn.Embedding(self.input_size, self.embedding_size)
self.rnn = torch.nn.RNN(input_size=self.embedding_size, hidden_size=self.hidden_size, num_layers=self.num_layers,
batch_first=True)
self.fc = torch.nn.Linear(self.hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
x = self.emb(x)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class)
if __name__ == '__main__':
input_size = 4
hidden_size = 8
batch_size = 1
num_layers = 2
seq_len = 5
embedding_size = 10
num_class = 4 # 类别数
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [
[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]
]
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
# 声明RNN模型
rnn_model = RNNModel(input_size, hidden_size, batch_size, num_layers, embedding_size)
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(rnn_model.parameters(), lr=0.05)
# 开始循环迭代训练
for epoch in range(15):
optimizer.zero_grad()
outputs = rnn_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print("Predicted String: ", ''.join([idx2char[x] for x in idx]), end='')
print(' , Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))
输出:
Predicted String: lllll , Epoch [1/15] loss=1.3103
Predicted String: lllll , Epoch [2/15] loss=1.0623
Predicted String: ohlll , Epoch [3/15] loss=0.8335
Predicted String: ohlol , Epoch [4/15] loss=0.6188
Predicted String: ohlol , Epoch [5/15] loss=0.4204
Predicted String: ohlol , Epoch [6/15] loss=0.2688
Predicted String: ohlol , Epoch [7/15] loss=0.1727
Predicted String: ohlol , Epoch [8/15] loss=0.1132
Predicted String: ohlol , Epoch [9/15] loss=0.0757
Predicted String: ohlol , Epoch [10/15] loss=0.0518
Predicted String: ohlol , Epoch [11/15] loss=0.0362
Predicted String: ohlol , Epoch [12/15] loss=0.0259
Predicted String: ohlol , Epoch [13/15] loss=0.0190
Predicted String: ohlol , Epoch [14/15] loss=0.0142
Predicted String: ohlol , Epoch [15/15] loss=0.0109
七、课后练习1:使用LSTM
7.1 初识LSTM
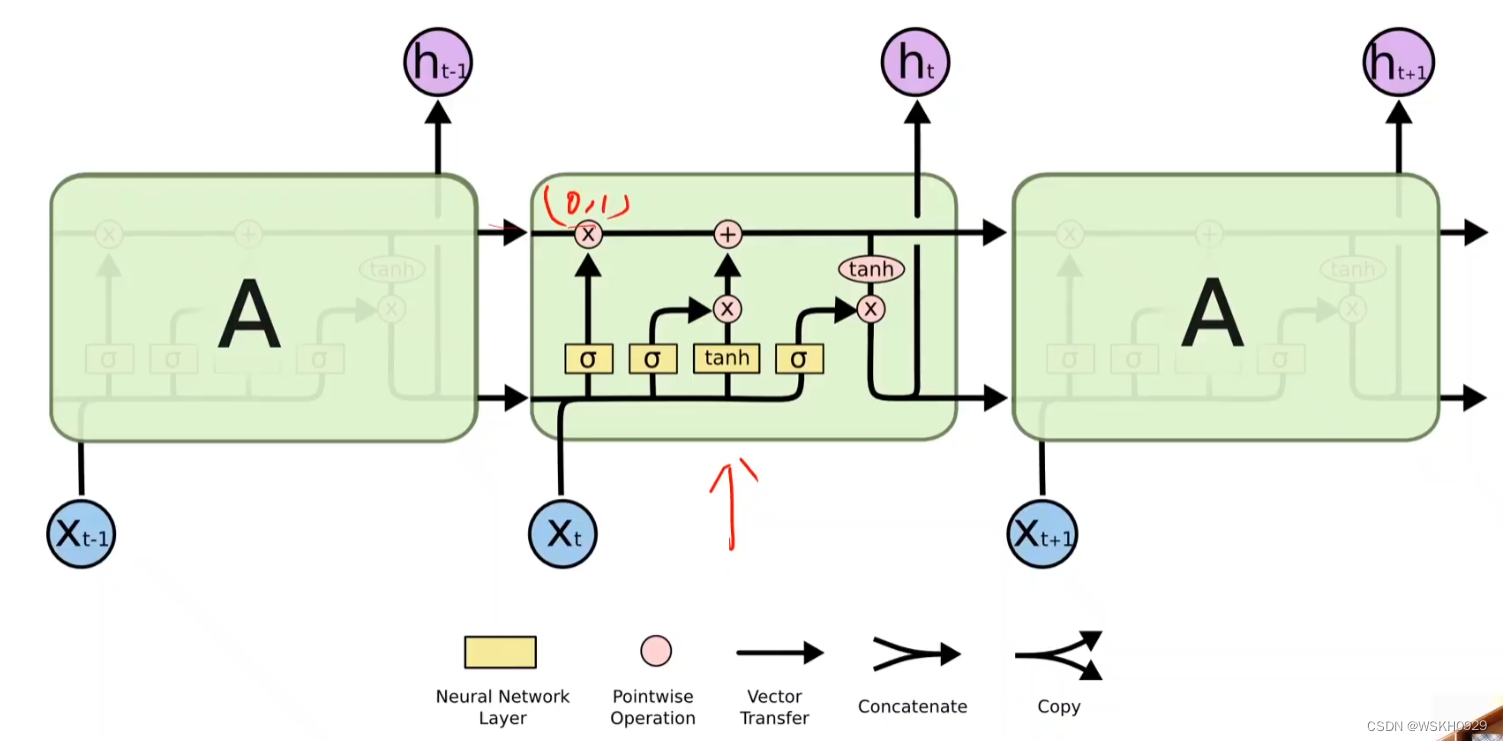


7.2 PyTorch代码
import torch
class RNNModel(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(RNNModel, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.batch_size = batch_size
self.num_layers = num_layers
self.rnn = torch.nn.LSTM(input_size=self.input_size, hidden_size=self.hidden_size, num_layers=self.num_layers)
def forward(self, input):
hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
c0 = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
out, _ = self.rnn(input, (hidden, c0))
return out.view(-1, self.hidden_size)
if __name__ == '__main__':
input_size = 4
hidden_size = 4
batch_size = 1
num_layers = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [
[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]
]
x_one_hot = [one_hot_lookup[i] for i in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
labels = torch.LongTensor(y_data)
# 声明RNN模型
rnn_model = RNNModel(input_size, hidden_size, batch_size, num_layers)
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(rnn_model.parameters(), lr=0.05)
# 开始循环迭代训练
for epoch in range(60):
optimizer.zero_grad()
outputs = rnn_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print("Predicted String: ", ''.join([idx2char[x] for x in idx]), end='')
print(' , Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))
输出:
Predicted String: ooooo , Epoch [1/15] loss=1.4331
Predicted String: ooooo , Epoch [2/15] loss=1.3742
Predicted String: ooooo , Epoch [3/15] loss=1.3251
Predicted String: ooooo , Epoch [4/15] loss=1.2809
Predicted String: ooooo , Epoch [5/15] loss=1.2427
Predicted String: ooooo , Epoch [6/15] loss=1.2102
Predicted String: ooooo , Epoch [7/15] loss=1.1820
Predicted String: ooooo , Epoch [8/15] loss=1.1564
Predicted String: ooooo , Epoch [9/15] loss=1.1316
Predicted String: ooooo , Epoch [10/15] loss=1.1060
Predicted String: ooooo , Epoch [11/15] loss=1.0784
Predicted String: ooool , Epoch [12/15] loss=1.0484
Predicted String: ooool , Epoch [13/15] loss=1.0172
Predicted String: ohool , Epoch [14/15] loss=0.9869
Predicted String: ohool , Epoch [15/15] loss=0.9592
Predicted String: ohool , Epoch [16/15] loss=0.9343
Predicted String: ohool , Epoch [17/15] loss=0.9114
Predicted String: oholl , Epoch [18/15] loss=0.8901
Predicted String: oholl , Epoch [19/15] loss=0.8702
Predicted String: oholl , Epoch [20/15] loss=0.8517
Predicted String: oholl , Epoch [21/15] loss=0.8344
Predicted String: oholl , Epoch [22/15] loss=0.8181
Predicted String: oholl , Epoch [23/15] loss=0.8028
Predicted String: oholl , Epoch [24/15] loss=0.7885
Predicted String: oholl , Epoch [25/15] loss=0.7754
Predicted String: ohlll , Epoch [26/15] loss=0.7639
Predicted String: ohlll , Epoch [27/15] loss=0.7539
Predicted String: ohlll , Epoch [28/15] loss=0.7454
Predicted String: ohlll , Epoch [29/15] loss=0.7382
Predicted String: ohlll , Epoch [30/15] loss=0.7317
Predicted String: ohlll , Epoch [31/15] loss=0.7251
Predicted String: ohlll , Epoch [32/15] loss=0.7182
Predicted String: ohlll , Epoch [33/15] loss=0.7112
Predicted String: ohlll , Epoch [34/15] loss=0.7043
Predicted String: ohlll , Epoch [35/15] loss=0.6978
Predicted String: ohlll , Epoch [36/15] loss=0.6916
Predicted String: ohlll , Epoch [37/15] loss=0.6857
Predicted String: ohlll , Epoch [38/15] loss=0.6800
Predicted String: ohlll , Epoch [39/15] loss=0.6747
Predicted String: ohlll , Epoch [40/15] loss=0.6697
Predicted String: ohlll , Epoch [41/15] loss=0.6651
Predicted String: ohlll , Epoch [42/15] loss=0.6609
Predicted String: ohlll , Epoch [43/15] loss=0.6570
Predicted String: ohlll , Epoch [44/15] loss=0.6535
Predicted String: ohlll , Epoch [45/15] loss=0.6503
Predicted String: ohlll , Epoch [46/15] loss=0.6473
Predicted String: ohlll , Epoch [47/15] loss=0.6445
Predicted String: ohlll , Epoch [48/15] loss=0.6418
Predicted String: ohlll , Epoch [49/15] loss=0.6392
Predicted String: ohlll , Epoch [50/15] loss=0.6366
Predicted String: ohlll , Epoch [51/15] loss=0.6339
Predicted String: ohlll , Epoch [52/15] loss=0.6312
Predicted String: ohlll , Epoch [53/15] loss=0.6284
Predicted String: ohlll , Epoch [54/15] loss=0.6255
Predicted String: ohlll , Epoch [55/15] loss=0.6225
Predicted String: ohlll , Epoch [56/15] loss=0.6193
Predicted String: ohlol , Epoch [57/15] loss=0.6161
Predicted String: ohlol , Epoch [58/15] loss=0.6129
Predicted String: ohlol , Epoch [59/15] loss=0.6097
Predicted String: ohlol , Epoch [60/15] loss=0.6067
八、课后练习2:使用GRU
8.1 初识GRU
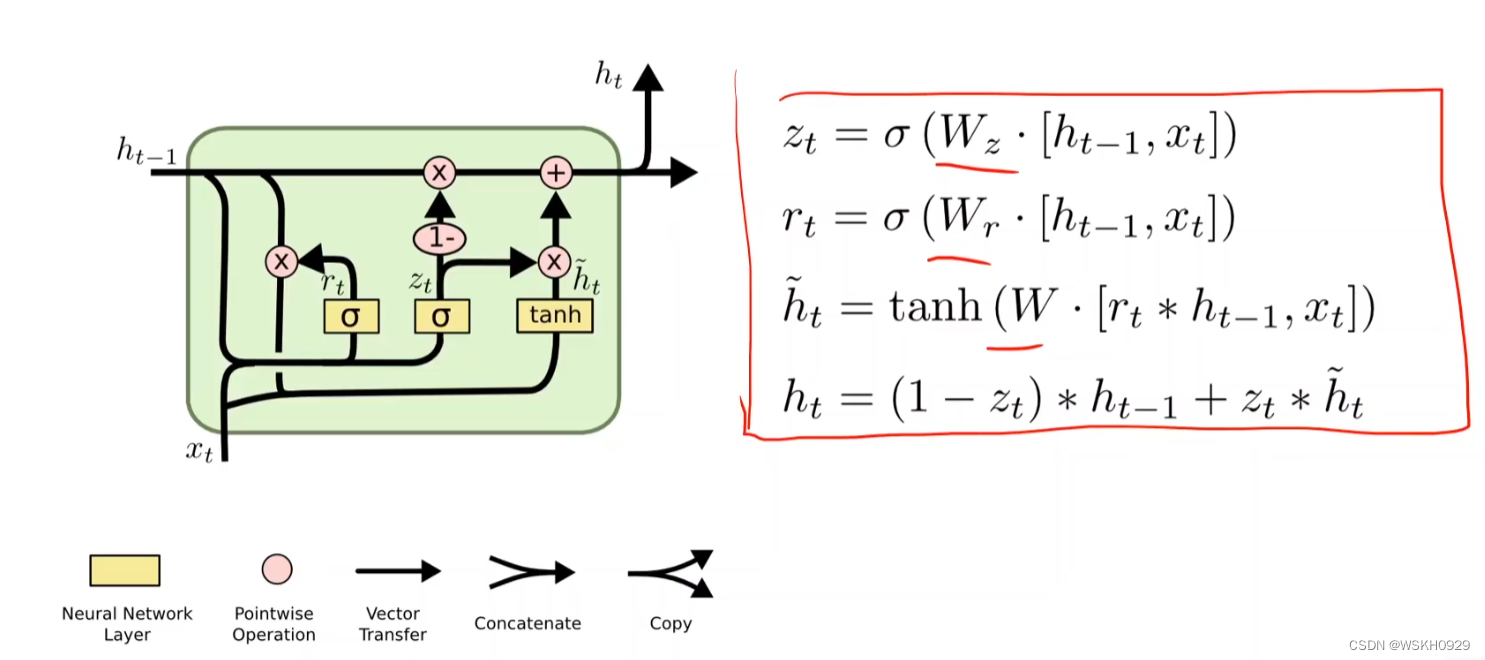
8.2 PyTorch代码
import torch
class RNNModel(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(RNNModel, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.batch_size = batch_size
self.num_layers = num_layers
self.rnn = torch.nn.GRU(input_size=self.input_size, hidden_size=self.hidden_size, num_layers=self.num_layers)
def forward(self, input):
hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
out, _ = self.rnn(input, hidden)
return out.view(-1, self.hidden_size)
if __name__ == '__main__':
input_size = 4
hidden_size = 4
batch_size = 1
num_layers = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [
[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]
]
x_one_hot = [one_hot_lookup[i] for i in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
labels = torch.LongTensor(y_data)
# 声明RNN模型
rnn_model = RNNModel(input_size, hidden_size, batch_size, num_layers)
# 损失函数
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(rnn_model.parameters(), lr=0.05)
# 开始循环迭代训练
for epoch in range(40):
optimizer.zero_grad()
outputs = rnn_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print("Predicted String: ", ''.join([idx2char[x] for x in idx]), end='')
print(' , Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))
输出:
Predicted String: eehhe , Epoch [1/15] loss=1.4254
Predicted String: ehool , Epoch [2/15] loss=1.3263
Predicted String: lhool , Epoch [3/15] loss=1.2477
Predicted String: lhool , Epoch [4/15] loss=1.1825
Predicted String: lhool , Epoch [5/15] loss=1.1252
Predicted String: lhool , Epoch [6/15] loss=1.0737
Predicted String: lhool , Epoch [7/15] loss=1.0279
Predicted String: lhool , Epoch [8/15] loss=0.9880
Predicted String: lhool , Epoch [9/15] loss=0.9532
Predicted String: ohlll , Epoch [10/15] loss=0.9225
Predicted String: ohlll , Epoch [11/15] loss=0.8949
Predicted String: ohlll , Epoch [12/15] loss=0.8695
Predicted String: ohlll , Epoch [13/15] loss=0.8457
Predicted String: ohlll , Epoch [14/15] loss=0.8229
Predicted String: ohlll , Epoch [15/15] loss=0.8005
Predicted String: ohlll , Epoch [16/15] loss=0.7783
Predicted String: ohlll , Epoch [17/15] loss=0.7564
Predicted String: ohlll , Epoch [18/15] loss=0.7349
Predicted String: ohlll , Epoch [19/15] loss=0.7138
Predicted String: ohlll , Epoch [20/15] loss=0.6932
Predicted String: ohlll , Epoch [21/15] loss=0.6733
Predicted String: ohlll , Epoch [22/15] loss=0.6545
Predicted String: ohlll , Epoch [23/15] loss=0.6372
Predicted String: ohlll , Epoch [24/15] loss=0.6219
Predicted String: ohlll , Epoch [25/15] loss=0.6086
Predicted String: ohlll , Epoch [26/15] loss=0.5968
Predicted String: ohlll , Epoch [27/15] loss=0.5859
Predicted String: ohlll , Epoch [28/15] loss=0.5757
Predicted String: ohlol , Epoch [29/15] loss=0.5660
Predicted String: ohlol , Epoch [30/15] loss=0.5572
Predicted String: ohlol , Epoch [31/15] loss=0.5492
Predicted String: ohlol , Epoch [32/15] loss=0.5419
Predicted String: ohlol , Epoch [33/15] loss=0.5350
Predicted String: ohlol , Epoch [34/15] loss=0.5284
Predicted String: ohlol , Epoch [35/15] loss=0.5219
Predicted String: ohlol , Epoch [36/15] loss=0.5156
Predicted String: ohlol , Epoch [37/15] loss=0.5094
Predicted String: ohlol , Epoch [38/15] loss=0.5035
Predicted String: ohlol , Epoch [39/15] loss=0.4977
Predicted String: ohlol , Epoch [40/15] loss=0.4921