目录
一.引言
二.ROUGE-简介
1.ROUGE-N
2.ROUGE-L
3.ROUGE-W
4.ROUGE-S
三.ROUGE-实现
1.How To Use
2.Inputs
3.Outputs
四.总结
一.引言
ROUGE 代表面向召回的研究,用于 Gisting 评估。它包括通过将摘要与人类创建的其他摘要进行比较来自动确定摘要质量的措施。度量计算要评估的计算机生成的摘要之间的 n-gram、单词序列和词对等重叠单元的数量以及人类创建的理想摘要。本文主要介绍四种不同的 ROUGE 度量:
◆ ROUGE-N
◆ ROUGE-L
◆ ROUGE-W
◆ ROUGE-S
二.ROUGE-简介
1.ROUGE-N
形式上,ROUGE-N 是候选摘要和一组参考摘要之间的 n-gram 召回率。而 LEU 则是一种基于精度的度量。ROUGE-N 计算如下:

其中 n 代表 n-gram,分子 Count Match 的长度是候选输出和一组参考输出中同时出现的 n-gram 的最大数量,分母是参考输出侧出现的 n-gram 数量的总和。

以 ROUGE-1 为例:

分母为参考输出侧出现的 n-gram 总和,这里共出现 6+7 = 13
分子为候选输出与每个参考输出的匹配,这里和为 4+5 = 9
所以 ROUGE-1 = 9 / 13 = 0.6923076923076923,ROUGE-2 的计算同理:

分母参考输出和 R1+R2 = 11,分子匹配数 R1+R2 = 6
所以 ROUGE-2 = 6 / 11 = 0.5454545454545。
2.ROUGE-L
ROUGE-L 代表 Longest Common Subsequence,其计算输出与参考输出之间的最长公共子序列 (LCS) 。为了将 LCS 应用于摘要评估,我们将摘要句子视为单词序列。直觉是两个摘要句子的 LCS 越长,两个摘要越相似。我们建议使用基于 LCS 的 F-measure 来估计长度为 m 和 Y 的两个摘要 X 之间的相似度,假设 X 是参考摘要句子,Y 是候选摘要句子,如下所示:

其中 LCS(X,Y) 是 X 和 Y 的最长公共子序列的长度,在 DUC 中,β 设置为非常大的数字 ∞,此时只考虑 Rlcs。等式 4 称为基于 LCS 的 F 度量,当 X=Y 时 ROUGE-L = 1,而当 LCS(X, Y) = 0 时,ROUGE-L = 0。
X 代表参考输出即 Reference,这里 X = the cat is on the mat,m = 6 即 X 的长度
Y 代表生成的输出即 Output,这里 Y = the cat the cat on the mat,n = 7 即输出对应的长度
将 LCS(X, Y) = 5 即 "the cat on the mat",m = 7,n = 6 代入公式:
β 可以看作是在 Recall 和 Prection 之间的度量,一般 Flcs 的计算中设置偏大,符合 ROUGE 偏向于 Recall 的初衷。 当有多个候选时,采用求和的方式计算:


3.ROUGE-W
ROUGE-W 代表 Weighted Longest Common Subsequence 即加权最长公共子序列。LCS 具有许多不错的属性,不幸的是,基本的 LCS 还有一个问题,即它不区分其嵌入序列中不同空间关系的 LCS。以下面为例:
![]()

给定候选 X 与输出 Y1、Y2 如果按照 ROUGE-L 计算得到的分数是相同的,但是从句子通顺的角度上看 Y1 是优于 Y2 的,因为 Y1 更加连贯。所以 ROGUE-W 的 W 就是给与连续的匹配更多地权重,从而在 LCS 相同的情况下,连贯性更好的输出可以获得更高的分数。ROUGE-W 的计算公式如下:

在形式上与 ROUGE-L 相似,权衡了 Recall 与 Precision,但是 WLCS 的计算相对复杂,其采用动态规划的方式计算,论文中给出了计算的伪代码:

其中 c 是动态规划表,c(i,j) 存储以 Y 的 X 和 yj 的单词 xi 结尾的 WLCS 分数,w 是存储以 c 表位置 i 和 j 结束的连续匹配长度的表,f 是表位置 c(i,j) 处连续匹配的函数。请注意,通过提供不同的加权函数 f,我们可以参数化 WLCS 算法以将不同的信用分配给连续的序列匹配。
权重函数 f 必须具有 f(x+y) > f(x) + f(y) 对于任何正整数 x 和 y 的性质。换句话说,连续匹配比非连续匹配获得更多的分数。例如,当 k >=0 和 α,β > 0 时,f(k)-=-αk-β。该函数为每个不连续的 n-gram 序列收取 -β 的差距惩罚。另一个可能的函数族是 k^α 形式的多项式族,其中 α > 1。然而,为了归一化最终的 ROUGE-W 分数,我们也更喜欢具有接近形式逆函数的函数。例如,f(k) = k^2 其具有封闭形式的逆函数 f(k)^-1 = sqrt(k)。
4.ROUGE-S
ROUGE-S 的 S 代表 Skip,全称为 Skip-Bigram Co-Occurrence Statistics,Skip-bigram 是其句子顺序中的任何一对单词,允许任意间隙。Skip-bigram 共现统计测量候选翻译和一组参考翻译之间的 skip-bigrams 重叠。

以 S1-S4 为例,对于每个 Sample 我们可以获取 个排列,基于这些排列的计算公式如下:

其中 SKIP2(X,Y) 是 X 和 Y 之间的 skip-bigram 匹配数,β 控制 Pskip2 和 Rskip2 的相对重要性,C 是组合函数。我们 F-skip2 为 skip-bigram 的 F-measure,即 ROUGE-S。
三.ROUGE-实现
基于 python evaluate 库可以计算 candicat 和 reference 的 ROUGE 分数。
1.How To Use
import evaluate
rouge = evaluate.load('rouge')
predictions = ["hello there", "general kenobi"]
references = [["hello", "there"], ["general kenobi", "general yoda"]]
results = rouge.compute(predictions=predictions,
references=references)
print(results){'rouge1': 0.8333333333333333, 'rouge2': 0.5, 'rougeL': 0.8333333333333333, 'rougeLsum': 0.8333333333333333}2.Inputs
◆ predictions (list)
要评分的预测列表。每个预测都应该是一个字符串,其中用空格分隔标记。
◆ references (list| list[lsit])
每个预测的参考列表或每个预测的几个参考的列表。每个引用都应该是一个字符串,其中标记由空格分隔。
◆ rouge_types (list)
Rouge 计算类型,default = ['rouge1','rouge2','groupL','groupLSum']。

◆ use_aggregator (boolean)
如果为True,则返回聚合。默认值为True。
◆ use_stemmer (boolean)
如果为True,则使用Porter-stemmer去除单词后缀。默认为False。
3.Outputs
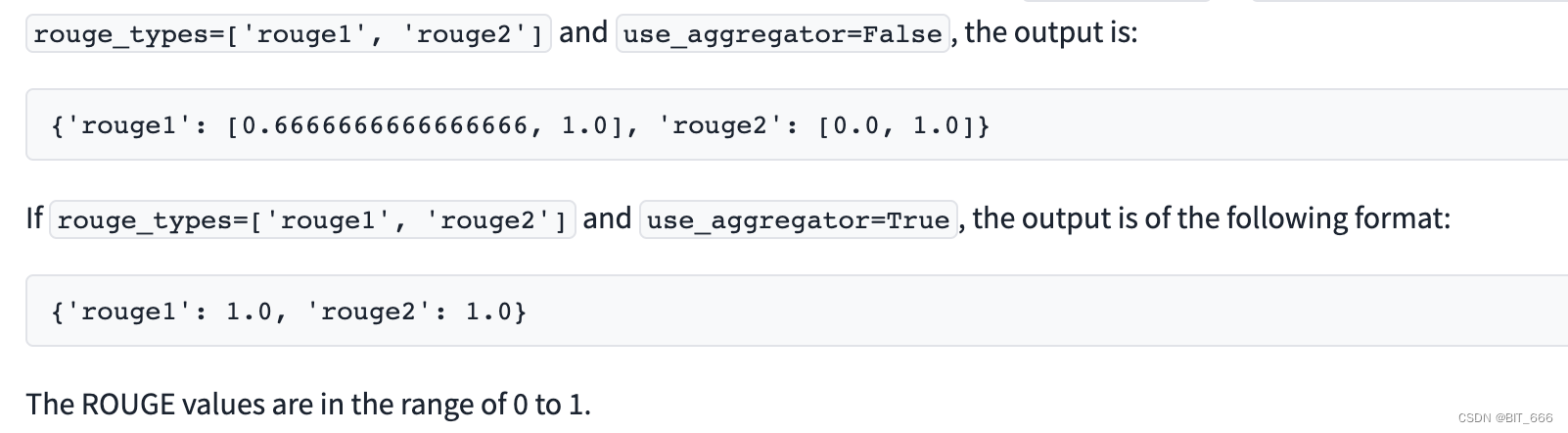
输出是一个字典,输入列表 group_types 中的每个 Rouge 类型都有一个条目。如果use_aggregator = False,则每个字典条目都是一个分数列表,每个句子一个分数。
又有 ROUGE 计算采取了归一化,所以其值的范围为 0-1。
import evaluate
rouge = evaluate.load('rouge')
predictions = ["hello there", "general kenobi"]
references = [["hello", "there"], ["general kenobi", "general yoda"]]
results = rouge.compute(predictions=predictions,references=references, use_aggregator=False)
print(results)当 use_aggregator = False 时:
{'rouge1': [0.6666666666666666, 1.0],
'rouge2': [0.0, 1.0],
'rougeL': [0.6666666666666666, 1.0],
'rougeLsum': [0.6666666666666666, 1.0]}当 use_aggregator = True 时:
{'rouge1': 0.8333333333333333,
'rouge2': 0.5,
'rougeL': 0.8333333333333333,
'rougeLsum': 0.8333333333333333}可以看出 use_aggregator = True 会对多个样本的 Rouge 值取平均,就像 BLEU 的 Wn 一样。
四.总结
与 BLEU 一样,ROUGE 整体简洁易用,且可解释性强,缺点也同样明显,ROUGE 只能从单词、短语的角度衡量相似度。不能从语义的角度去衡量,对于中文输出比对,我们可以使用分词将句子拆分为不同的词组,而不是单一的汉字评估。后续有机会我们看看能不能借助 GPT 帮我们实现自动评分的功能。
参考:
ROUGE 计算: ROUGE - a Hugging Face Space by evaluate-metric
ROUGE 论文: ROUGE: A Package for Automatic Evaluation of Summaries - ACL Anthology