经常遇到这种情况:某些项目的文件中不可避免地包含有中文,在Windows系统中没有任何问题,拷到Linux系统中就出问题了。
1. Linux系统设置
$echo $LANG
en_US.iso885915朋友建议我设置为:
export LANG=zh_CN.utf8但我这样设置之后,python 代码 os.listdir() 的结果还是会发生编码错误,于是在Linux系统设置了一个最宽泛的字符集:
export LANG=zh_CN.gb180302.终端软件字符集设置
Linux系统的编码方式选择了‘gb18030’, 则终端软件的字符集也应该选择‘gb18030’。
xshell的设置界面如下:
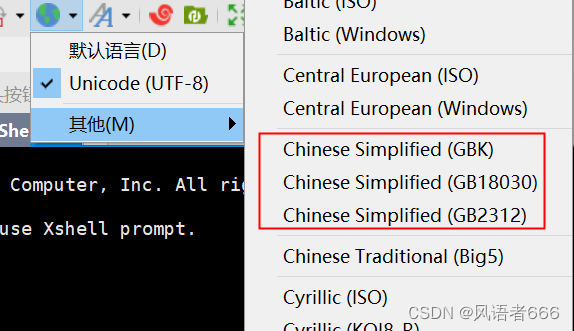
我用的终端软件是putty,但我发现putty的字符集选项中居然没有‘gb18030’这个选项。
朋友建议选择“Use font encoding”这个选项。
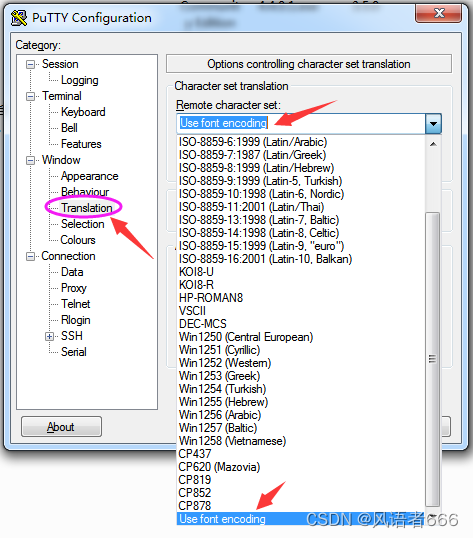
这样是没问题了,运行Python代码,截图如下:

可以看出,标准输入的中文显示是没有问题了。
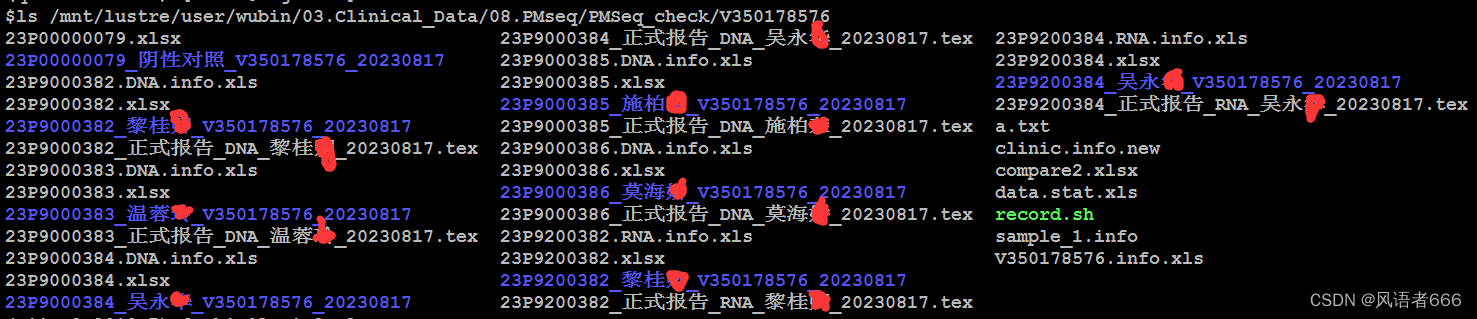
但如果vi进入某个包含中文的文件,仍然会有乱码。
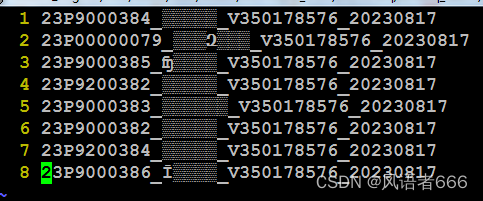
这个时候就应该找vim设置方面的原因。
3.VIM设置
关于vim设置以适应中文显示,很多博文已经写得足够详细,比如:
vim编辑器中文输入乱码问题_vim中文乱码_.Lance的博客-CSDN博客
vim ~/.vimrc 在其中输入:
set fileencodings=utf-8,gb2312,gbk,gb18030
set termencoding=utf-8
set fileformats=unix
set encoding=prc我自己的设置如下:
set fileencodings=ucs-bom,utf-8,cp936,big5,euc-jp,euc-kr,latin1,gbk,gb18030反正不嫌多,都加在里面。
然后就没有问题了
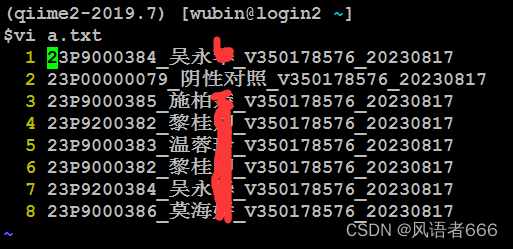
总结:中文乱码主要是注意服务器和字符终端的字符集设置问题,保持一致,支持中文。
解决了以上的问题之后,我其实可以在Python代码里面直接匹配中文字符的。
# -*- coding: utf-8 -*-
import re
import os, sys
import numpy as np
import pandas as pd
from collections import defaultdict
from optparse import OptionParser
import joblib
import chardet
import glob
in_dir = '/mnt/lustre/user/wubin/03.Clinical_Data/08.PMseq/PMSeq_check/V350178576'
for sample_dir in os.listdir(in_dir):
path = os.path.join(in_dir, sample_dir)
if not re.search(r'^[0-9]{2}P[0-9]+', sample_dir):
continue
if not os.path.isdir(path):
continue
if re.search(r'阴性对照', sample_dir):
print(sample_dir)运行的结果:

以上使用的Python解释器是Python 3.6.7。
而使用Python 2.7,使用这段代码却无法匹配出来
在Python2 下,我目录下面命名有“23P00000079_阴性对照_V350178576_20230817” 但我读出来的值,无论怎么encode,decode,都绝不可能 == “23P00000079_阴性对照_V350178576_20230817”,因为后者是bytes格式的 在python3下面由于代码中显示写出的“23P00000079_阴性对照_V350178576_20230817”是字符串,可以直接匹配
目前无法理解,也不知道怎么匹配(在python 2.7条件下)









![linux学习(文件描述符)[11]](https://img-blog.csdnimg.cn/0c769e914642451ba66db0c9a4fe5baa.png)