多目标跟踪 FairMOT
Abstract
Multi-object tracking (MOT) is an important prob-lem in computer vision which has a wide range of applica-tions. Formulating MOT as multi-task learning of object de-tection and re-ID in a single network is appealing since itallows joint optimization of the two tasks and enjoys highcomputation efficiency. However, we find that the two taskstend to compete with each other which need to be carefullyaddressed. In particular, previous works usually treat re-IDas a secondary task whose accuracy is heavily affected bythe primary detection task. As a result, the network is bi-ased to the primary detection task which is notfairto there-ID task. To solve the problem, we present a simple yeteffective approach termed asFairMOTbased on the anchor-free object detection architecture CenterNet. Note that it isnot a naive combination of CenterNet and re-ID. Instead,we present a bunch of detailed designs which are critical toachieve good tracking results by thorough empirical studies.The resulting approach achieves high accuracy for both de-tection and tracking. The approach outperforms the state-of-the-art methods by a large margin on several public datasets.
摘要:
多目标跟踪是计算机视觉中的一个重要问题,有着广泛的应用。将MOT定义为在单个网络中进行对象检测和重新识别的多任务学习很有吸引力,因为它可以实现两个任务的联合优化,并具有较高的计算效率。然而,我们发现这两个任务是相互竞争的,需要小心处理。特别是,以前的工作通常将重新识别视为次要任务,其准确性受到主要检测任务的严重影响。因此,网络基于主检测任务,而主检测任务对ID任务不公平。为了解决这个问题,我们提出了一种简单有效的方法,称为基于无锚对象检测架构CenterNet的FairMOT。请注意,它不是CenterNet和re-ID的天真组合。相反,我们提出了一系列详细的设计,这些设计对于通过彻底的实证研究获得良好的跟踪结果至关重要
1 Introduction
Multi-Object Tracking (MOT) has been a longstanding goalin computer vision (Bewley et al., 2016; Wojke et al., 2017;Chen et al., 2018a; Yu et al., 2016). The goal is to esti-mate trajectories for objects of interest presented in videos.The successful resolution of the problem can immediatelybenefit many applications such as intelligent video analy-sis, human computer interaction, human activity recognition(Wang et al., 2013; Luo et al., 2017), and even social com-puting
多目标跟踪(MOT)一直是计算机视觉的一个长期目标(Bewley等人,2016;Wojke等人,2017;Chen等人,2018a;Yu等人,2016)。目标是估计视频中感兴趣对象的轨迹。该问题的成功解决可以立即应用于许多应用,如智能视频分析、人机交互、人类活动识别(Wang et al.,2013;Luo et al.,2017),甚至社交计算
Most of the existing methods such as (Mahmoudi et al.,2019; Zhou et al., 2018; Fang et al., 2018; Bewley et al.,2016; Wojke et al., 2017; Chen et al., 2018a; Yu et al., 2016)attempt to address the problem by two separate models: thedetectionmodel firstly detects objects of interest by bound-ing boxes in each frame, then theassociationmodel extractsre-identification (re-ID) features from the image regions cor-responding to each bounding box, links the detection to oneof the existing tracks or creates a new track according tocertain metrics defined on features.
大多数现有方法,如(Mahmoudi等人,2019;Zhou等人,2018;Fang等人,2018年;Bewley等人,2016年;Wojke等人,2017年;Chen等人,2018a;Yu等人,2016)试图通过两个单独的模型解决问题:检测模型首先通过每个帧中的绑定框检测感兴趣的对象,然后关联模型提取图像区域的特征COR-响应每个绑定盒子,将检测链接到现有轨迹之一,或根据功能定义的某些度量创建新轨迹。
There has been remarkable progress on object detection(Ren et al., 2015; He et al., 2017; Zhou et al., 2019a; Red-mon and Farhadi, 2018; Fu et al., 2020; Sun et al., 2021b,a)and re-ID (Zheng et al., 2017a; Chen et al., 2018a) respec-tively recently which in turn boosts the overall tracking ac-curacy. However, these two-step methods suffer from scala-bility issues. They cannot achieve real-time inference speedwhen there are a large number of objects in the environmentbecause the two models do not share features and they need
to apply the re-ID models for every bounding box indepen-dently in the video.
最近,在目标检测方面取得了显著进展(Ren等人,2015;何等人,2017;周等人,2019a;Red mon和Farhadi,2018;傅等人,2020;孙等人,2021b,a)和re-ID(Zheng等人,2017a;Chen等人,2018a),这反过来又提高了整体跟踪精度。然而,这些两步方法存在可伸缩性问题。当环境中有大量对象时,它们无法实现实时推理速度,因为这两个模型没有共享功能并且她们需要独立地将re-ID模型应用于视频中的每个边界框。
With the maturity of multi-task learning (Kokkinos, 2017;Chen et al., 2018b), one-shot trackers which estimate ob-jects and learn re-ID features using a single network haveattracted more attention (Wang et al., 2020b; Voigtlaenderet al., 2019). For example, Voigtlaenderet al. (Voigtlaenderet al., 2019) add a re-ID branch to Mask R-CNN to extract are-ID feature for each proposal (He et al., 2017). It reducesinference time by re-using backbone features for the re-IDnetwork. But the performance drops remarkably comparedto the two-step models. In fact, the detection accuracy is stillgood but the tracking performance drops a lot. For example,the number of ID switches increases by a large margin. Theresult suggests that combining the two tasks is a non-trivialtask and should be treated carefully.
随着多任务学习的成熟(Kokkinos,2017;Chen等人,2018b),使用单个网络估计目标并学习re-ID特征的一次性跟踪器引起了更多的关注(Wang等人,2020b;Voigtlaender等人,2019)。例如,Voigtlaenderet al.(Voigtleenderet al.,2019)在Mask R-CNN中添加了一个re-ID分支,以提取每个提案的are-ID特征(He et al.,2017)。它通过重新使用re-ID网络的主干功能来减少会议时间。但与两步模型相比,性能明显下降。事实上,检测精度仍然很好,但跟踪性能下降了很多。例如,ID开关的数量大幅度增加。Theresult建议,将这两项任务结合起来是一项不平凡的任务,应该谨慎对待。
In this paper, we investigate the reasons behind the fail-ure, and present a simple yet effective solution. Three fac-tors are identified to account for the failure. The first issueis caused by anchors. Anchors are originally designed forobject detection (Ren et al., 2015). However, we show thatanchors are not suitable for extracting re-ID features for tworeasons. First, anchor-based one-shot trackers such as TrackR-CNN (Voigtlaender et al., 2019) overlook the re-ID taskbecause they need anchors to first detect objects (i.e. , us-ing RPN (Ren et al., 2015)) and then extract the re-ID fea-tures based on the detection results (re-ID features are use-less when detection results are incorrect). So when competi-tion occurs between the two tasks, it will favor the detectiontask. Anchors also introduce a lot of ambiguity during train-ing the re-ID features because one anchor may correspondto multiple identities and multiple anchors may correspondto one identity, especially in crowded scenes.
在本文中,我们调查了失败背后的原因,并提出了一个简单而有效的解决方案。确定了三个因素来解释故障。第一个问题是由锚引起的。锚最初是为物体检测而设计的(Ren等人,2015)。然而,我们发现锚不适合提取re-ID特征,原因有两个。首先,基于锚的一次性跟踪器,如TrackR-CNN(Voigtlander et al.,2019)忽略了re-ID任务,因为它们需要锚首先检测对象(即使用RPN(Ren et al.,2015)),然后基于检测结果提取re-ID特征(当检测结果不正确时,re-ID特征使用较少)。因此,当两个任务之间发生竞争时,将有利于检测任务。在训练re-ID特征的过程中,主播也引入了很多歧义,因为一个主播可能对应多个身份,而多个主播也可能对应一个身份,尤其是在拥挤的场景中。
The second issue is caused by feature sharing betweenthe two tasks. Detection task and re-ID task are two totallydifferent tasks and they need different features. In general,re-ID features need more low-level features to discriminatedifferent instances of the same class while detection featuresneed to be similar for different instances. The shared fea-tures in one-shot trackers will lead to feature conflict andthus reduce the performance of each task
第二个问题是由两个任务之间的功能共享引起的。检测任务和重新识别任务是两个完全不同的任务,它们需要不同的功能。一般来说,re-ID特征需要更多的低级特征来区分同一类的不同实例,而不同实例的检测特征需要相似。一次性跟踪器中的共享特征将导致特征冲突,从而降低每个任务的性能
The third issue is caused by feature dimension. The di-mension of re-ID features is usually as high as512(Wanget al., 2020b) or1024(Zheng et al., 2017a) which is muchhigher than that of object detection. We find that the hugedifference between dimensions will harm the performanceof the two tasks. More importantly, our experiments suggestthat it is a generic rule that learning low-dimensional re-IDfeatures for “joint detection and re-ID” networks achievesboth higher tracking accuracy and efficiency. This also re-veals the difference between the MOT task and the re-IDtask, which is overlooked in the field of MOT
第三个问题是由特征尺寸引起的。re-ID特征的维数通常高达512(Wang et al.,2020b)或1024(Zheng et al.,2017a),这比物体检测的维数高得多。我们发现维度之间的巨大差异会损害这两项任务的执行。更重要的是,我们的实验表明,学习“联合检测和重新识别”网络的低维重新识别特征可以获得更高的跟踪精度和效率,这是一个普遍的规则。这也揭示了MOT任务和重新IDtask之间的区别,后者在MOT领域被忽视了
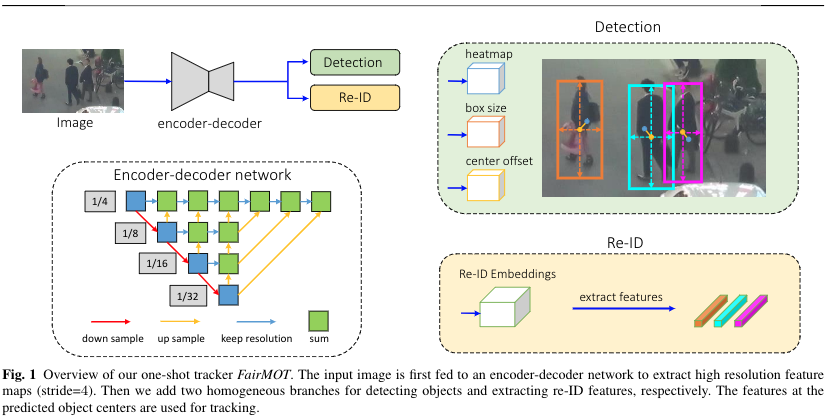
In this work, we present a simple approach termed asFairMOTwhich elegantly address the three issues as illus-trated in Figure 1.FairMOTis built on top of CenterNet(Zhou et al., 2019a). In particular, the detection and re-IDtasks are treated equally inFairMOTwhich essentially dif-fers from the previous “detection first, re-ID secondary” frame-work. It is worth noting that it is not a naive combination ofCenterNet and re-ID. Instead, we present a bunch of detaileddesigns which are critical to achieve good tracking results bythorough empirical studies.
在这项工作中,我们提出了一种称为FairMOT的简单方法,它优雅地解决了图1所示的三个问题。FairMOT建立在CenterNet之上(Zhou et al.,2019a)。特别是,在FairMOT中,检测和重新标识任务被同等对待,这与之前的“检测优先,重新标识次要”框架工作基本不同。值得注意的是,它并不是centernet和re-ID的天真结合。相反,我们提出了一系列详细的设计,这些设计对于通过彻底的实证研究获得良好的跟踪结果至关重要。
Figure 1 shows an overview ofFairMOT. It has a sim-ple network structure which consists of twohomogeneousbranches for detecting objects and extracting re-ID features,respectively. Inspired by (Zhou et al., 2019a; Law and Deng,2018; Zhou et al., 2019b; Duan et al., 2019), the detectionbranch is implemented in ananchor-freestyle which esti-mates object centers and sizes represented as position-awaremeasurement maps. Similarly, the re-ID branch estimates are-ID feature for each pixel to characterize the object cen-tered at the pixel. Note that the two branches are completelyhomogeneous which essentially differs from the previousmethods which perform detection and re-ID in a two-stagecascaded style. SoFairMOTeliminates the unfair disadvan-tage of the detection branch as reflected in Table 1, effec-tively learns high-quality re-ID features and obtains a goodtrade-off between detection and re-ID
图1显示了飞行交通部的概况。它具有简单的网络结构,由两个同质分支组成,分别用于检测对象和提取re-ID特征。受(Zhou et al.,2019a;Law and Deng,2018;周等人,2019b;Duan et al.,2019)的启发,检测分支是在ananchor freestyle中实现的,它估计了以位置-距离测量图表示的对象中心和大小。类似地,re-ID分支估计是每个像素的ID特征,以表征在该像素处测量的对象。请注意,这两个分支是完全同质的,这与以前以两阶段级联方式执行检测和重新ID的方法有本质不同。SoFairMOT消除了表1中反映的检测分支的不公平劣势,有效地学习了高质量的re-ID特征,并在检测和re-ID之间获得了良好的折衷
We evaluateFairMOTon the MOT Challenge bench-mark via the evaluation server. It ranks first among all track-ers on the 2DMOT15 (Leal-Taix ́e et al., 2015), MOT16 (Mi-lan et al., 2016), MOT17 (Milan et al., 2016) and MOT20(Dendorfer et al., 2020) datasets. When we further pre-trainour model using our proposed single image training method,it achieves additional gains on all datasets. In spite of thestrong results, the approach is very simple and runs at 30FPS on a single RTX 2080Ti GPU. It sheds light on the rela-tionship between detection and re-ID in MOT and providesguidance for designing one-shot video tracking networks.Our contributions are as follows:
我们通过评估服务器对FairMOT的MOT挑战基准进行评估。在2DMOT15(Leal-Taix́e等人,2015)、MOT16(Mi-lan等人,2016)、MOT17(Milan等人,2016年)和MOT20(Dendorfer等人,2020)数据集中,它在所有追踪者中排名第一。当我们使用我们提出的单图像训练方法进一步预训练我们的模型时,它在所有数据集上都获得了额外的增益。尽管结果很糟糕,但该方法非常简单,在单个RTX 2080Ti GPU上以30FPS的速度运行。它揭示了MOT中检测和re-ID之间的关系,并为设计一次性视频跟踪网络提供了指导。我们的贡献如下:
We empirically demonstrate that the prevalent anchor-based one-shot MOT architectures have limitations interms of learning effective re-ID features which has beenoverlooked. The issues severely limit the tracking per-formance of those methods.–We presentFairMOTto address the fairness issue.Fair-MOTis built on top of CenterNet. Although the adoptedtechniques are mostly not novel by themselves, we havenew discoveries which are important to MOT. These areboth novel and valuable.–We show that the achieved fairness allows ourFairMOTto obtain high levels of detection and tracking accuracyand outperform the previous state-of-the-art methods bya large margin on multiple datasets such as 2DMOT15,MOT16, MOT17 and MOT20.
我们实证证明,流行的基于锚的一次性MOT架构在学习被忽视的有效重新识别特征方面存在局限性。这些问题严重限制了这些方法的跟踪性能我们提出FairMOT是为了解决公平问题。Fair-MOT建立在CenterNet之上。尽管所采用的技术本身大多并不新颖,但我们有新的发现,这些发现对MOT很重要。这些既新颖又有价值我们表明,所实现的公平性使我们的FairMOT能够获得高水平的检测和跟踪精度,并在多个数据集(如2DMOT15、MOT16、MOT17和MOT20)上大幅度优于以前最先进的方法。
2 Related Work
The best-performing MOT methods (Bergmann et al., 2019;Bras ́o and Leal-Taix ́e, 2020; Hornakova et al., 2020; Yu et al.,2016; Mahmoudi et al., 2019; Zhou et al., 2018; Wojke et al.,2017; Chen et al., 2018a; Wang et al., 2020b; Voigtlaenderet al., 2019; Zhang et al., 2021a) usually follow the tracking-by-detection paradigm, which first detect objects in eachframe and then associate them over time. We classify theexisting works into two categories based on whether theyuse a single model or separate models to detect objects andextract association features. We discuss the pros and cons ofthe methods and compare them to our approach
表现最好的MOT方法(Bergmann等人,2019;Braśo和Leal-Taix́e,2020;Hornakova等人,2020;Yu等人,2016;Mahmoudi等人,2019年;周等人,2018;Wojke等人,2017;Chen等人,2018a;王等人,2020b;Voigtlaender等人,2019,张等人,2021a)通常遵循检测跟踪范式,其首先检测每个帧中的对象,然后随着时间的推移将它们关联。我们根据现有作品是使用单个模型还是单独的模型来检测对象并提取关联特征,将其分为两类。我们讨论了这些方法的优缺点,并将它们与我们的方法进行了比较
2.1 Detection and Tracking by Separate Models
2.1.1 Detection Methods
Most benchmark datasets such as MOT17 (Milan et al., 2016)provide detection results obtained by popular methods suchas DPM (Felzenszwalb et al., 2008), Faster R-CNN (Renet al., 2015) and SDP (Yang et al., 2016) such that the worksthat focus on the tracking part can be fairly compared on thesame object detections. Some works such as (Yu et al., 2016;Wojke et al., 2017; Zhou et al., 2018; Mahmoudi et al., 2019)use a large private pedestrian detection dataset to train theFaster R-CNN detector with VGG-16 (Simonyan and Zis-serman, 2014) as backbone, which obtain better detectionperformance. A small number of works such as (Han et al.,2020) use more powerful detectors which are developed re-cently such as Cascade R-CNN (Cai and Vasconcelos, 2018)to boost the detection performance
大多数基准数据集,如MOT17(Milan et al.,2016),提供了通过DPM(Felzenszwalb et al.,2008)、Faster R-CNN(Renet et al.,2015)和SDP(Yang et al.,2011)等流行方法获得的检测结果,因此,专注于跟踪部分的工作可以在相同的对象检测上进行公平的比较。一些工作如(Yu et al.,2016;Wojke et al.,2017;周等人,2018;Mahmoudi et al.,2019)使用大型私人行人检测数据集来训练以VGG-16(Simonyan和Zis-serman,2014)为骨干的主R-CNN检测器,获得了更好的检测性能。少数工作,如(Han et al.,2020)使用了更强大的检测器,这些检测器是最近开发的,如Cascade R-CNN(Cai和Vasconcelos,2018),以提高检测性能
Location and Motion Cues based MethodsSORT (Bew-ley et al., 2016) first uses Kalman Filter (Kalman, 1960)to predict future locations of the tracklets, computes theiroverlap with the detections, and uses Hungarian algorithm(Kuhn, 1955) to assign detections to tracklets. IOU-Tracker(Bochinski et al., 2017) directly computes the overlap be-tween the tracklets (of the previous frame) and the detec-tions without using using Kalman filter to predict future lo-cations. The approach achieves100K fps inference speed(detection time not counted) and works well when objectmotion is small. Both SORT and IOU-Tracker are widelyused in practice due to their simplicity.
基于位置和运动线索的方法SORT(Bew-ley et al.,2016)首先使用卡尔曼滤波器(Kalman,1960)来预测轨迹的未来位置,计算它们与检测的重叠,并使用匈牙利算法(Kuhn,1955)将检测分配给轨迹。IOU Tracker(Bochinski等人,2017)直接计算(前一帧的)轨迹和检测之间的重叠,而不使用卡尔曼滤波器来预测未来的位置。该方法实现了100K fps的推理速度(不计算检测时间),并且在物体运动较小时效果良好。SORT和IOU Tracker由于其简单性而在实践中得到广泛使用。
However, they may fail in challenging cases of crowdedscenes and fast motion. Some works such as (Xiang et al.,2015; Zhu et al., 2018; Chu and Ling, 2019; Chu et al.,2019) leverage sophisticated single object tracking methodsto get accurate object locations and reduce false negatives.However, these methods are extremely slow especially whenthere are a large number of people in the scene. To solve theproblem of trajectory fragments, Zhanget al. (Zhang et al.,2020) propose a motion evaluation network to learn long-range features of tracklets for association. MAT (Han et al.,2020) is an enhanced SORT, which additionally models thecamera motion and uses dynamic windows for long-rangere-association.
然而,在拥挤场景和快速动作的挑战性案例中,它们可能会失败。一些工作,如(Xiang et al.,2015;朱等人,2018;Chu和Ling,2019;Chu et al.,2019)利用复杂的单目标跟踪方法来获得准确的目标位置并减少假阴性。然而,这些方法非常缓慢,尤其是当场景中有大量人时。为了解决轨迹碎片的问题,Zhang等人(Zhang et al.,2020)提出了一种运动评估网络来学习用于关联的轨迹的长程特征。MAT(Han et al.,2020)是一种增强的SORT,它对相机运动进行了额外建模,并使用动态窗口进行长距离联想。
Appearance Cues based MethodsSome recent works (Yuet al., 2016; Mahmoudi et al., 2019; Zhou et al., 2018; Wojkeet al., 2017) propose to crop the image regions of the detec-tions and feed them to re-ID networks (Zheng et al., 2017b;Hermans et al., 2017; Luo et al., 2019a) to extract imagefeatures. Then they compute the similarity between track-lets and detections based on re-ID features and use Hungar-ian algorithm (Kuhn, 1955) to accomplish assignment. Themethod is robust to fast motion and occlusion. In particular,it can re-initialize lost tracks because appearance featuresare relatively stable over time
基于外观线索的方法最近的一些工作(Yuet等人,2016;Mahmoudi等人,2019;周等人,2018;Wojkeet等人,2017)提出对检测的图像区域进行裁剪,并将其提供给re-ID网络(Zheng等人,2017b;Hermans等人,2017;Luo等人,2019a)来提取图像特征。然后,他们基于re-ID特征计算轨迹let和检测之间的相似性,并使用Hungar算法(Kuhn,1955)来完成分配。该方法对快速运动和遮挡具有鲁棒性。特别是,它可以重新初始化丢失的轨迹,因为随着时间的推移,外观特征相对稳定
There are also some works (Bae and Yoon, 2014; Tanget al., 2017; Sadeghian et al., 2017; Chen et al., 2018a; Xuet al., 2019) focusing on enhancing appearance features. Forexample, Baeet al. (Bae and Yoon, 2014) propose an on-line appearance learning method to handle appearance vari-ations. Tanget al. (Tang et al., 2017) leverage body posefeatures to enhance the appearance features. Some meth-ods (Sadeghian et al., 2017; Xu et al., 2019; Shan et al.,2020) propose to fuse multiple cues (i.e. motion, appearanceand location) to get more reliable similarity. MOTDT (Chenet al., 2018a) proposes a hierarchical data association strat-egy which uses IoU to associate objects when appearancefeatures are not reliable. A small number of works such as(Mahmoudi et al., 2019; Zhou et al., 2018; Fang et al., 2018)also propose to use more complicated association strategiessuch as group models and RNNs.
也有一些作品(Bae和Yoon,2014;Tang等人,2017;Sadeghian等人,2017年;Chen等人,2018a;Xuet等人,2019)专注于增强外观特征。例如,Bae等人(Bae和Yoon,2014)提出了一种在线外观学习方法来处理外观变化。Tang等人(Tang et al.,2017)利用身体姿态特征来增强外观特征。一些方法(Sadeghian et al.,2017;Xu et al.,2019;Shan et al.,2020)提出融合多个线索(即运动、外观和位置)以获得更可靠的相似性。MOTDT(Chenet al.,2018a)提出了一种分层数据关联策略,当外观特征不可靠时,该策略使用IoU来关联对象。少数工作如(Mahmoudi et al.,2019;周等人,2018;方等人,2018)也提出使用更复杂的关联策略,如群模型和RNN。
Offline MethodsThe offline methods (or batch methods)(Zhang et al., 2008; Wen et al., 2014; Berclaz et al., 2011;Zamir et al., 2012; Milan et al., 2013; Choi, 2015; Bras ́o andLeal-Taix ́e, 2020; Hornakova et al., 2020) often achieve bet-ter results by performing global optimization in the wholesequence. For example, Zhanget al. (Zhang et al., 2008)build a graphical model with nodes representing detectionsin all frames. The optimal assignment is searched using amin-cost flow algorithm, which exploits the specific struc-ture of the graph to reach the optimum faster than LinearProgramming. Berclazet al. (Berclaz et al., 2011) also treatdata association as a flow optimization task and use the K-shortest paths algorithm to solve it, which significantly speedsup computation and reduces parameters that need to be tuned.Milanet al. (Milan et al., 2013) formulate multi-object track-ing as minimization of a continuous energy and focus ondesigning the energy function. The energy depends on loca-tions and motion of all targets in all frames as well as phys-ical constraints. MPNTrack (Bras ́o and Leal-Taix ́e, 2020)proposes trainable graph neural networks to perform a globalassociation of the entire set of detections and make MOTfully differentiable. LifT (Hornakova et al., 2020) formu-lates MOT as a lifted disjoint path problem and introduceslifted edges for long range temporal interactions, which sig-nificantly reduces id switches and re-identify lost
离线方法离线方法(或批处理方法)(Zhang等人,2008;Wen等人,2014;Berclaz等人,2011;Zamir等人,2012;Milan等人,2013;Choi,2015;Braśo和Leal-Taix́e,2020;Hornakova等人,2020)通常通过在整个序列中进行全局优化来获得更好的结果。例如,Zhang等人(Zhang et al.,2008)构建了一个图形模型,其中节点表示所有帧中的检测。最优分配使用最小代价流算法进行搜索,该算法利用图的特定结构比线性规划更快地达到最优。Berclazet等人(Berclaz等人,2011)还将数据关联视为一项流优化任务,并使用K最短路径算法进行求解,这大大加快了计算速度,减少了需要调整的参数。Milan等人(Milan等人,2013)将多目标跟踪公式化为连续能量的最小化,并专注于设计能量函数。这个
Advantages and LimitationsFor the methods which per-form detection and tracking by separate models, the mainadvantage is that they can develop the most suitable modelfor each task separately without making compromise. In ad-dition, they can crop the image patches according to thedetected bounding boxes and resize them to the same sizebefore estimating re-ID features. This helps to handle thescale variations of objects. As a result, these approaches (Yuet al., 2016; Henschel et al., 2019) have achieved the bestperformance on the public datasets. However, they are usu-ally very slow because the two tasks need to be done sep-arately without sharing. So it is hard to achieve video rateinference which is required in many applications.
优点和局限性对于通过单独的模型进行表单检测和跟踪的方法,主要优点是它们可以为每个任务单独开发最合适的模型,而不会做出妥协。此外,他们可以根据检测到的边界框裁剪图像块,并在估计重新识别特征之前将其调整为相同的大小。这有助于处理对象的比例变化。因此,这些方法(Yuet等人,2016;Henschel等人,2019)在公共数据集上取得了最佳性能。然而,它们通常非常慢,因为这两项任务需要单独完成,而不需要共享。因此,很难实现视频速率推断,这在许多应用中都是必需的。
2.2 Detection and Tracking by a Single Model
With the quick maturity of multi-task learning (Kokkinos,2017; Ranjan et al., 2017; Sener and Koltun, 2018) in deeplearning, joint detection and tracking using a single networkhas begun to attract more research attention. We classifythem into two classes as discussed in the following
随着多任务学习在深度学习中的快速成熟(Kokkinos,2017;Ranjan et al.,2017;Sener和Koltun,2018),使用单个网络的联合检测和跟踪开始引起更多的研究关注。我们把它们分为两类,如下所述
Joint Detection and Re-IDThe first class of methods (Voigt-laender et al., 2019; Wang et al., 2020b; Liang et al., 2020;Pang et al., 2021; Lu et al., 2020) perform object detectionand re-ID feature extraction in a single network in order toreduce inference time. For example, Track-RCNN (Voigt-laender et al., 2019) adds a re-ID head on top of Mask R-CNN (He et al., 2017) and regresses a bounding box and are-ID feature for each proposal. Similarly, JDE (Wang et al.,2020b) is built on top of YOLOv3 (Redmon and Farhadi,2018) which achieves near video rate inference. However,the accuracy of these one-shot trackers is usually lower thanthat of the two-step ones
联合检测和Re-ID第一类方法(Voigt-laender等人,2019;王等人,2020b;梁等人,2020;Pang等人,2021;Lu等人,2020)在单个网络中进行对象检测和Re-ID特征提取,以减少推理时间。例如,Track RCNN(Voigt-laender等人,2019)在Mask R-CNN(He等人,2017)的顶部添加了一个re-ID头,并回归了每个提案的边界框和are ID特征。类似地,JDE(Wang et al.,2020b)建立在YOLOv3(Redmon和Farhadi,2018)之上,实现了近视频速率推断。然而,这些一次性跟踪器的精度通常低于两步跟踪器
Joint Detection and Motion PredictionThe second class ofmethods (Feichtenhofer et al., 2017; Zhou et al., 2020; Panget al., 2020; Peng et al., 2020; Sun et al., 2020) learn detec-tion and motion features in a single network. D&T (Feicht-enhofer et al., 2017) propose a Siamese network which takesinput of adjacent frames and predicts inter-frame displace-ments between bounding boxes. Tracktor (Bergmann et al.,2019) directly exploits the bounding box regression head topropagate identities of region proposals and thus removesbox association. Chained-Tracker (Peng et al., 2020) pro-poses an end-to-end model using adjacent frame pair as in-put and generating the box pair representing the same target.These box-based methods assume that bounding boxes havea large overlap between frames, which is not true in low-frame rate videos. Different from these methods, Center-Track (Zhou et al., 2020) predicts the object center displace-ments with pair-wise inputs and associate by these point dis-tances. It also provides the tracklets as an additional point-based heatmap input to the network and is then able to matchobjects anywhere even if the boxes have no overlap at all.However, these methods only associate objects in adjacentframes without re-initializing lost tracks and thus have diffi-culty handling occlusion cases
联合检测和运动预测第二类方法(Feichtenhofer et al.,2017;周等人,2020;Pang et al.,2020;彭等人,2020年;孙等人,2020)在单个网络中学习检测和运动特征。D&T(Feicht-enhofer等人,2017)提出了一种暹罗网络,该网络获取相邻帧的输入并预测边界框之间的帧间位移。Trackor(Bergmann et al.,2019)直接利用区域建议的边界框回归头-顶传播身份,从而消除了sbox关联。Chained Tracker(Peng et al.,2020)提出了一个端到端模型,使用相邻的帧对作为输入,并生成代表同一目标的框对。这些基于框的方法假设边界框在帧之间有很大的重叠,这在低帧率视频中是不正确的。与这些方法不同的是,中心轨迹(Zhou et al.,2020)预测了具有成对输入的物体中心位移,并通过这些输入进行关联基于热图输入到网络,然后能够在任何地方匹配对象,即使盒子根本没有重叠。然而,这些方法只关联相邻帧中的对象,而不重新初始化丢失的轨迹,因此难以处理遮挡情况
Our work belongs to the first class. We investigate thereasons why one-shot trackers get degraded association per-formance and propose a simple approach to address the prob-lems. We show that the tracking accuracy is improved sig-nificantly without heavy engineering efforts. A concurrentwork CSTrack (Liang et al., 2020) also aims to alleviate theconflicts between the two tasks from the perspective of fea-tures, and propose a cross-correlation network module toenable the model to learn task-dependent representations.Different from CSTrack, our method tries to address theproblem from three perspectives in a systematic way andobtains notably better performances than CSTrack. Center-Track (Zhou et al., 2020) is also related to our work sinceit also uses center-based object detection framework. ButCenterTrack does not extract appearance features and onlylinks objects in adjacent frames. In contrast,FairMOTcanperform long-range association with the appearance featuresand handle occlusion cases.
我们的工作属于一流的。我们研究了单次跟踪器的关联性能下降的原因,并提出了一种简单的方法来解决这个问题。我们表明,在不付出大量工程努力的情况下,跟踪精度得到了显著提高。协同工作CSTrack(Liang et al.,2020)也旨在从特征的角度缓解两个任务之间的冲突,并提出了一个互相关网络模块,使模型能够学习任务相关的表示,我们的方法试图从三个角度系统地解决这个问题,并获得了比CSTrack明显更好的性能。中心轨迹(Zhou et al.,2020)也与我们的工作有关,因为它也使用了基于中心的对象检测框架。ButCenterTrack不提取外观特征,只链接相邻帧中的对象。相比之下,FairMOT可以与外观进行长期关联
Multi-task LearningThere is a large body of literature (Liuet al., 2019; Kendall et al., 2018; Chen et al., 2018b; Guoet al., 2018; Sener and Koltun, 2018) on multi-task learn-ing which may be used to balance the object detection andre-ID feature extraction tasks. Uncertainty (Kendall et al.,2018) uses task-dependent uncertainty to automatically bal-ance the single-task losses. MGDA is proposed in (Senerand Koltun, 2018) to update the shared network weights byfinding a common direction among the task-specific gradi-ents. GradNorm (Chen et al., 2018b) controls the training ofmulti-task networks by simulating the task-specific gradi-ents to be of similar magnitude. We evaluate these methodsin the experimental sections.
多任务学习有大量关于多任务学习的文献(Liu et al.,2019;Kendall等人,2018;Chen等人,2018b;Guo et al.,2018;Sener和Koltun,2018),这些文献可以用来平衡对象检测和特征提取任务。不确定性(Kendall et al.,2018)使用任务相关的不确定性来自动平衡单个任务的损失。MGDA在(Senerand Koltun,2018)中提出,通过在特定任务的梯度之间找到共同的方向来更新共享网络权重。GradNorm(Chen et al.,2018b)通过将特定任务的等级模拟为相似的等级来控制多任务网络的训练。我们在实验部分对这些方法进行了评估。
2.3 Video Object Detection
Video Object Detection (VOD) (Feichtenhofer et al., 2017;Luo et al., 2019b) is related to MOT in the sense that it lever-ages tracking to improve object detection performances inchallenging frames. Although these methods were not eval-uated on MOT datasets, some of the ideas may be valuablefor the field. So we briefly review them in this section. Tanget al. (Tang et al., 2019) detect object tubes in videos whichaims to enhance classification scores in challenging framesbased on their neighboring frames. The detection rate forsmall objects increases by a large margin on the benchmarkdataset. Similar ideas have also been explored in (Han et al.,2016; Kang et al., 2016, 2017; Tang et al., 2019; Pang et al.,2020). One main limitation of these tube-based methods isthat they are extremely slow especially when there are alarge number of objects in videos
视频对象检测(VOD)(Feichtenhofer等人,2017;Luo等人,2019b)与MOT有关,因为它利用年龄跟踪来提高帧中的对象检测性能。尽管这些方法没有在MOT数据集上进行评估,但其中一些想法可能对该领域有价值。因此,我们在本节中简要回顾一下它们。Tang等人(Tang等人,2019)检测视频中的对象管,旨在基于其相邻帧提高具有挑战性的帧中的分类分数。在基准数据集上,小对象的检测率大大提高。类似的想法也在中进行了探索(Han et al.,2016;Kang等人,20162017;Tang等人,2019;Pang等人,2020)尤其是当视频中有大量对象时它们非常慢
3 Unfairness Issues in One-shot Trackers
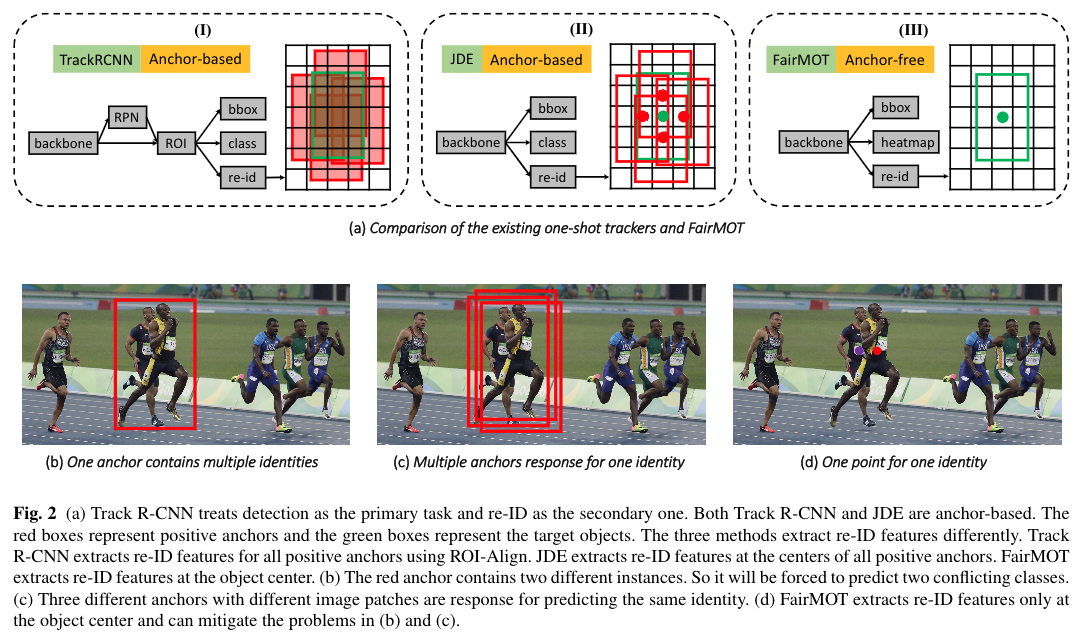
3.1 Unfairness Caused by Anchors【描框】
The existing one-shot trackers such as Track R-CNN (Voigt-laender et al., 2019) and JDE (Wang et al., 2020b) are mostlyanchor-based since they are directly modified from anchor-based object detectors such as YOLO (Redmon and Farhadi,2018) and Mask R-CNN (He et al., 2017). However, we findthat the anchor-based design is not suitable for learning re-ID features which result in a large number of ID switches inspite of the good detection results. We explain the problemfrom three perspectives in the following.
现有的一次性跟踪器,如Track R-CNN(Voigt-laender et al.,2019)和JDE(Wang et al.,2020b),大多是基于锚的,因为它们是从基于锚的对象检测器(如YOLO(Redmon和Farhadi,2018)和Mask R-CNN(He et al.,2017))直接修改而来的。然而,我们发现基于锚的设计不适合学习re-ID特征,尽管检测结果良好,但这会导致大量的ID切换。下面我们从三个角度来解释这个问题。
Overlooked re-ID taskTrack R-CNN (Voigtlaender et al.,2019) operates in a cascaded style which first estimates ob-ject proposals (boxes) and then pools features from themto estimate the corresponding re-ID features. The quality ofre-ID features heavily depends on the quality of proposalsduring training (re-ID features are useless if proposals arenot accurate). As a result, in the training stage, the model isseriously biased to estimate accurate object proposals ratherthan high quality re-ID features. So the standard “detectionfirst, re-ID secondary” design of the existing one-shot track-ers makes the re-ID network not fairly learned.
Overlooked re-ID task
Track R-CNN(Voigtlander et al.,2019)以级联方式运行,该级联方式首先估计对象提案(框),然后从中汇集特征以估计相应的re-ID特征。re-ID特征的质量在很大程度上取决于训练期间提议的质量(如果提议不准确,re-ID特性是无用的)。因此,在训练阶段,该模型在估计准确的对象建议方面存在严重偏差,而不是高质量的重新识别特征。因此,现有一次性跟踪器的标准“检测第一,重新识别第二”设计使得重新识别网络没有得到充分的学习。
One anchor corresponds to multiple identities
The anchor-based methods usually use ROI-Align to extract featuresfrom proposals. Most sampling locations in ROI-Align maybelong to other disturbing instances or background as shownin Figure 2. As a result, the extracted features are not opti-mal in terms of accurately and discriminatively representingthe target objects. Instead, we find in this work that it is sig-nificantly better to only extract features at a single point,i.e., the estimated object centers
一个锚点对应多个标识基于锚点的方法通常使用ROI Align从提案中提取特征。ROI Align中的大多数采样位置可能属于其他干扰实例或背景,如图2所示。因此,提取的特征在准确和有区别地表示目标对象方面不是最优的。相反,我们在这项工作中发现,只提取单个点的特征(即估计的对象中心)要好得多
Multiple anchors correspond to one identity
In both (Voigt-laender et al., 2019) and (Wang et al., 2020b), multiple adja-cent anchors, which correspond to different image patches,may be forced to estimate the same identity as long as theirIOU is sufficiently large. This introduces severe ambigu-ity for training. See Figure 2 for illustration. On the otherhand, when an image undergoes small perturbation,e.g.,due to data augmentation, it is possible that the same an-chor is forced to estimate different identities. In addition,feature maps in object detection are usually down-sampledby8/16/32times to balance accuracy and speed. This is ac-ceptable for object detection but it is too coarse for learningre-ID features because features extracted at coarse anchorsmay not be aligned with object centers
多个锚对应于一个身份。在(Voigt-laender et al.,2019)和(Wang et al.,2020b)中,对应于不同图像补丁的多个相邻锚可能被迫估计相同的身份,只要它们的IOU足够大。这给训练带来了严峻的环境。见图2。另一方面,当图像经历小扰动时,例如,由于数据增强,可能会迫使同一个chor估计不同的身份。此外目标检测中的特征图通常被向下采样8/16/32次,以平衡准确性和速度。这对于对象检测来说是可以接受的,但对于学习其他ID特征来说太粗糙了,因为在粗糙锚点提取的特征可能与对象中心不对齐
3.2 Unfairness Caused by Features【特征】
For one-shot trackers, most features are shared between theobject detection and re-ID tasks. But it is well known thatthey actually require features from different layers to achievethe best results. In particular, object detection requires deepfeatures to estimate object classes and positions but re-IDrequires low-level appearance features to distinguish differ-ent instances of the same class. From the perspective of themulti-task loss optimization, the optimization objectives ofdetection and re-ID have conflicts. Thus, it is important tobalance the loss optimization strategy of the two tasks
对于一次性跟踪器,大多数功能在对象检测和重新识别任务之间共享。但众所周知,它们实际上需要来自不同层的特征才能获得最佳结果。特别地,对象检测需要深度特征来估计对象类别和位置,但重新ID需要低级外观特征来区分同一类别的不同实例。从多任务损失优化的角度来看,检测和re-ID的优化目标存在冲突。因此,平衡这两项任务的损失优化策略非常重要
3.3 Unfairness Caused by Feature Dimension【特征尺寸】
The previous re-ID works usually learn very high dimen-sional features and have achieved promising results on thebenchmarks of their field. However, we find that learninglower-dimensional features is actually better for one-shotMOT for three reasons: (1) high-dimensional re-ID features notably harms the object detection accuracy due to the com-petition of the two tasks which in turn also has negative im-pact to the final tracking accuracy. So considering that thefeature dimension in object detection is usually very low(class numbers + box locations), we propose to learn low-dimensional re-ID features to balance the two tasks; (2) theMOT task is different from the re-ID task. The MOT taskonly performs a small number of one-to-one matchings be-tween two consecutive frames. The re-ID task needs to matchthe query to a large number of candidates and thus requiresmore discriminative and high-dimensional re-ID features.So in MOT we do not need that high-dimensional features;(3) learning low dimensional re-ID features improves the in-ference speed as will be shown in our experiments
以前的re-ID工作通常学习到非常高的维度特征,并在其领域的基准上取得了有希望的结果。然而,我们发现,学习低维特征实际上对一次性MOT更好,原因有三:(1)高维re-ID特征由于这两个任务的共同作用,显著地损害了目标检测的准确性,这反过来也对最终的跟踪精度产生了负面影响。因此,考虑到对象检测中的特征维数通常很低(类数+框位置),我们建议学习低维的re-ID特征来平衡这两项任务;(2) MOT任务不同于re-ID任务。MOT任务仅在两个连续帧之间执行少量一对一匹配。re-ID任务需要将查询与大量候选匹配,因此需要更具鉴别性和高维的re-ID特征。因此,在MOT中,我们不需要高维特征;(3) 如我们的实验所示,学习低维re-ID特征可以提高参考速度
4 FairMOT
4.1 Backbone Network
We adopt ResNet-34 as backbone in order to strike a goodbalance between accuracy and speed. An enhanced versionof Deep Layer Aggregation (DLA) (Zhou et al., 2019a) isapplied to the backbone to fuse multi-layer features as shown in Figure 1. Different from original DLA (Yu et al., 2018), ithas more skip connections between low-level and high-levelfeatures which is similar to the Feature Pyramid Network(FPN) (Lin et al., 2017a). In addition, convolution layers inall up-sampling modules are replaced by deformable con-volution such that they can dynamically adjust the receptivefield according to object scales and poses. These modifica-tions are also helpful to alleviate the alignment issue. Theresulting model is named DLA-34. Denote the size of in-put image asHimage×Wimage, then the output feature maphas the shape ofC×H×WwhereH=Himage/4andW=Wimage/4. Besides DLA, other deep networks thatprovide multi-scale convolutional features, such as HigherHRNet (Cheng et al., 2020), can be used in our frameworkto provide fair features for both detection and re-ID
如图1所示。与最初的DLA(Yu et al.,2018)不同,它在低级和高级特征之间有更多的跳跃连接,这类似于特征金字塔网络(FPN)(Lin et al.(2017a))。此外,所有上采样模块中的卷积层都被可变形卷积所取代,这样它们可以根据对象的尺度和姿态动态调整接收场。这些修改也有助于缓解对齐问题。该模型命名为DLA-34。将输入图像的大小表示为Himage×Wimage,则输出特征图的形状为C×H×W,其中H=Himage/4,W=Wimage/4。除了DLA,其他提供多尺度卷积特征的深度网络,如HigherHRNet(Cheng et al.,2020),可以在我们的框架中使用,为检测和重新识别提供公平的特征
4.2 Detection Branch
Our detection branch is built on top of CenterNet (Zhouet al., 2019a) but other anchor-free methods such as (Duanet al., 2019; Law and Deng, 2018; Dong et al., 2020; Yanget al., 2019) can also be used. We briefly describe the ap-proach to make this work self-contained. In particular, threeparallel heads are appended to DLA-34 to estimate heatmaps,object center offsets and bounding box sizes, respectively.Each head is implemented by applying a3×3convolution(with256channels) to the output features of DLA-34, fol-lowed by a1×1convolutional layer which generates thefinal targets
我们的检测分支建立在CenterNet之上(Zhou等人,2019a),但也可以使用其他无锚方法,如(Duanet等人,2019;劳和邓,2018;董等人,2020;Yang等人,2019)。我们简要描述了使这项工作独立的方法。特别是,在DLA-34上添加了三个并行头部,分别用于估计热图、对象中心偏移和边界框大小。每个头部通过对DLA-34的输出特征应用3×3卷积(256通道)来实现,然后是生成最终目标的a1×1卷积层
4.2.1 Heatmap Head

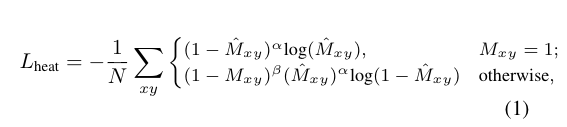
4.2.2 Box Offset and Size Heads

4.3 Re-ID Branch
Re-ID branch aims to generate features that can distinguishobjects. Ideally, affinity among different objects should besmaller than that between same objects. To achieve this goal,we apply a convolution layer with128kernels on top ofbackbone features to extract re-ID features for each location.Denote the resulting feature map asE∈R128×H×W. There-ID featureEx,y∈R128of an object centered at(x,y)can be extracted from the feature map
Re-ID分支旨在生成能够区分对象的特征。理想情况下,不同对象之间的亲和力应该比相同对象之间的更大。为了实现这一目标,我们在骨干特征之上应用了一个128核的卷积层来提取每个位置的re-ID特征。将得到的特征图表示为E∈R128×H×W。可以从特征图中提取以(x,y)为中心的对象的ID featureEx,y∈R128
4.3.1 Re-ID Loss
We learn re-ID features through a classification task. Allobject instances of the same identity in the training set aretreated as the same class. For each GT boxbi= (xi1,yi1,xi2,yi2)in the image, we obtain the object center on the heatmap( ̃cix, ̃ciy). We extract the re-ID feature vectorE ̃cix, ̃ciyand usea fully connected layer and a softmax operation to map it toa class distribution vectorP={p(k),k∈[1,K]}. Denote
我们通过分类任务学习re-ID特征。训练集中具有相同标识的所有对象实例都被创建为同一类。对于图像中的每个GT boxbi=(xi1,yi1,xi2,yi2),我们获得热图上的对象中心(ξcix,ξciy)。我们提取了re-ID特征向量Eõcix,ci,并使用全连通层和softmax运算将其映射到类分布向量p={p(k),k∈[1,k]}。标志
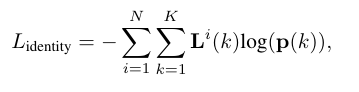
4.4 Training FairMOT
We jointly train the detection and re-ID branches by addingthe losses (i.e., Eq. (1), Eq. (2) and Eq. (3)) together. Inparticular, we use the uncertainty loss proposed in (Kendallet al., 2018) to automatically balance the detection and re-IDtasks

其中w1和w2是平衡这两项任务的可学习参数。具体来说,给定一个具有几个对象及其相应ID的图像,我们生成热图、框偏移和大小图,以及对象的一个热类表示。将这些与估计的测量值进行比较,以获得训练整个网络的损失
In addition to the standard training strategy presentedabove, we propose a single image training method to trainFairMOTon image-level object detection datasets such asCOCO (Lin et al., 2014) and CrowdHuman (Shao et al.,2018). Different from CenterTrack (Zhou et al., 2020) thattakes two simulated consecutive frames as input, we onlytake a single image as input. We assign each bounding boxa unique identity and thus regard each object instance in thedataset as a separate class. We apply different transforma-tions to the whole image including HSV augmentation, ro-tation, scaling, translation and shearing. The single imagetraining method has significant empirical values. First, thepre-trained model on the CrowdHuman dataset can be di-rectly used as a tracker and get acceptable results on MOTdatasets such as MOT17 (Milan et al., 2016). This is be-cause the CrowdHuman dataset can boost the human detec-tion performance and also has strong domain generalizationability. Our training of the re-ID features further enhancesthe association ability of the tracker. Second, we can fine-tune it on other MOT datasets and further improve the finalperformance
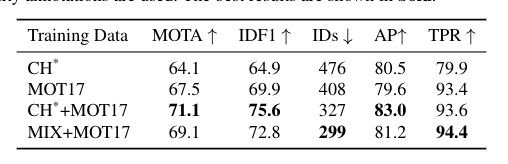
除了上面提出的标准训练策略外,我们还提出了一种单图像训练方法来训练FairMOTon图像级目标检测数据集,如COCO(Lin et al.,2014)和CrowdHuman(Shao et al.,2018)。与以两个模拟连续帧为输入的CenterTrack(Zhou et al.,2020)不同,我们只以单个图像为输入。我们为每个边界框分配一个唯一的标识,从而将数据集中的每个对象实例视为一个单独的类。我们将不同的变换应用于整个图像,包括HSV增强、平移、缩放、平移和剪切。单一图像训练方法具有显著的经验价值。首先,CrowdHuman数据集上预先训练的模型可以直接用作跟踪器,并在MOT17等MOT数据集(Milan et al.,2016)上获得可接受的结果。这是因为CrowdHuman数据集可以提高人类的检测性能,并且具有较强的领域泛化能力。
4.5 Online Inference
4.5.1 Network Inference
The network takes a frame of size1088×608as input whichis the same as the previous work JDE (Wang et al., 2020b).On top of the predicted heatmap, we perform non-maximumsuppression (NMS) based on the heatmap scores to extractthe peak keypoints. The NMS is implemented by a simple3×3max pooling operation as in (Zhou et al., 2019a). Wekeep the locations of the keypoints whose heatmap scoresare larger than a threshold. Then, we compute the corre-sponding bounding boxes based on the estimated offsets andbox sizes. We also extract the identity embeddings at the es-timated object centers. In the next section, we discuss howwe associate the detected boxes over time using the re-IDfeatures
该网络以大小为1088×608的帧作为输入,这与之前的工作JDE(Wang et al.,2020b)相同。在预测的热图之上,我们基于热图分数执行非最大值压缩(NMS)以提取峰值关键点。NMS通过简单的3×3max池操作来实现,如(Zhou et al.,2019a)所示。我们保留热图得分大于阈值的关键点的位置。然后,我们根据估计的偏移量和框大小计算相应的边界框。我们还提取了在估计的对象中心的身份嵌入。在下一节中,我们将讨论如何使用re-ID特性随时间关联检测到的盒子
4.5.2 Online Association
We follow MOTDT (Chen et al., 2018a) and use a hierarchi-cal online data association method. We first initialize a num-ber of tracklets based on the detected boxes in the first frame.Then in the subsequent frame, we link the detected boxes tothe existing tracklets using a two-stage matching strategy.In the first stage, we use Kalman Filter (Kalman, 1960) andre-ID features to obtain initial tracking results. In particu-lar, we use Kalman Filter to predict tracklet locations in thefollowing frame and compute the Mahalanobis distanceDmbetween the predicted and detected boxes following Deep-SORT (Wojke et al., 2017). We fuse the Mahalanobis dis-tance with the cosine distance computed on re-ID features:D=λDr+ (1−λ)Dmwhereλis a weighting parame-ter and is set to be0.98in our experiments. Following JDE(Wang et al., 2020b), we set Mahalanobis distance to infin-ity if it is larger than a threshold to avoid getting trajecto-ries with large motion. We use Hungarian algorithm (Kuhn,1955) with a matching thresholdτ1= 0.4to complete thefirst stage matching
我们遵循MOTDT(Chen et al.,2018a),并使用分层在线数据关联方法。我们首先根据第一帧中检测到的盒子初始化一定数量的轨迹。然后在下一帧中,我们使用两阶段匹配策略将检测到的盒与现有轨迹链接。在第一阶段,我们使用卡尔曼滤波器(Kalman,1960)和ID特征来获得初始跟踪结果。特别是,我们使用卡尔曼滤波器来预测下一帧中的轨迹点位置,并在深度SORT之后计算预测框和检测框之间的Mahalanobis距离Dmbe(Wojke等人,2017)。我们将马氏距离与根据re-ID特征计算的余弦距离进行融合:D=λDr+(1-λ)Dm这里λ是一个加权参数,在我们的实验中设置为0.98。根据JDE(Wang et al.,2020b),如果Mahalanobis距离大于阈值,我们将其设置为infinity,以避免获得具有大运动的目标。我们使用匈牙利算法(Kuhn,1955)
In the second stage, for unmatched detections and track-lets, we try to match them according to the overlap betweentheir boxes. In particular, we set the matching thresholdτ2=0.5. We update the appearance features of the tracklets ineach time step to handle appearance variations as in (Bolmeet al., 2010; Henriques et al., 2014). Finally, we initialize theunmatched detections as new tracks and save the unmatchedtracklets for 30 frames in case they reappear in the future
在第二阶段,对于不匹配的检测和跟踪,我们尝试根据它们方框之间的重叠进行匹配。特别地,我们设置了匹配阈值τ2=0.5。我们在每个时间步长更新轨迹的外观特征,以处理外观变化,如(Bolmet等人,2010;Henriques等人,2014)。最后,我们将未匹配的检测初始化为新的轨迹,并将未匹配轨迹保存30帧,以备将来再次出现
5 Experiments
5.1 Datasets and Metrics
There are six training datasets briefly introduced as follows:the ETH (Ess et al., 2008) and CityPerson (Zhang et al.,2017) datasets only provide box annotations so we only trainthe detection branch on them. The CalTech (Doll ́ar et al.,2009), MOT17 (Milan et al., 2016), CUHK-SYSU (Xiaoet al., 2017) and PRW (Zheng et al., 2017a) datasets provideboth box and identity annotations which allows us to trainboth branches. Some videos in ETH also appear in the test-ing set of the MOT17 which are removed from the trainingdataset for fair comparison. The overall training strategy isdescribed in Section 4.4, which is the same as (Wang et al.,2020b). For the self-supervised training of our method, weuse the CrowdHuman dataset (Shao et al., 2018) which onlycontains object bounding box annotations.We evaluate our approach on the testing sets of fourbenchmarks: 2DMOT15, MOT16, MOT17 and MOT20. Weuse Average Precision (AP) to evaluate detection results.Following (Wang et al., 2020b), we use True Positive Rate(TPR) at a false accept rate of0.1for evaluating re-ID fea-tures. In particular, we extract re-ID features which corre-spond to ground truth boxes and use each feature to retrieveNmost similar candidates. We report the true positive rate atfalse accept rate 0.1 (TPR@FAR=0.1). Note thatTPRis notaffected by detection results and faithfully reflects the qual-ity of re-ID features. We use the CLEAR metric (Bernardinand Stiefelhagen, 2008) (i.e.MOTA,IDs) andIDF1(Ristaniet al., 2016) to evaluate overall tracking accuracy.
有六个训练数据集简要介绍如下:ETH(Ess et al.,2008)和CityPerson(Zhang et al.,2017)数据集只提供框注释,因此我们只在它们上训练检测分支。加州理工学院(Dolĺar et al.,2009)、MOT17(Milan et al.,2016)、香港中文大学-西安理工大学(Xiaoet al.,2017)和PRW(Zheng et al.,2017a)数据集提供了框和身份注释,使我们能够训练这两个分支。ETH中的一些视频也出现在MOT17的测试集中,这些视频从训练数据集中删除以进行公平比较。整体训练策略如第4.4节所述,与(Wang et al.,2020b)相同。对于我们方法的自监督训练,我们使用仅包含对象边界框注释的CrowdHuman数据集(Shao et al.,2018)。我们在四个基准测试集上评估了我们的方法:2DMOT15、MOT16、MOT17和MOT20。我们使用平均精度(AP)来评估检测结果
5.2 Implementation Details
We use a variant of DLA-34 proposed in (Zhou et al., 2019a)as our default backbone. The model parameters pre-trainedon the COCO dataset (Lin et al., 2014) are used to initial-ize our model. We train our model with the Adam opti-mizer (Kingma and Ba, 2014) for30epochs with a start-ing learning rate of10−4. The learning rate decays to10−5at20epochs. The batch size is set to be12. We use stan-dard data augmentation techniques including rotation, scal-ing and color jittering. The input image is resized to1088×608and the feature map resolution is272×152. The trainingstep takes about 30 hours on two RTX 2080 Ti GPUs.
我们使用(Zhou et al.,2019a)中提出的DLA-34的变体作为我们的默认主干。在COCO数据集(Lin et al.,2014)上预先训练的模型参数用于初始化我们的模型。我们用Adam optimizer(Kingma和Ba,2014)训练我们的模型30个时期,开始学习率为10-4。学习率下降到10−5at20个时期。批量大小设置为12。我们使用标准数据增强技术,包括旋转、缩放和颜色抖动。输入图像的大小调整为1088×608,特征图的分辨率为272×152。在两个RTX 2080 Ti GPU上,培训步骤大约需要30个小时。
5.3 Ablative Studies
In this section, we present rigorous studies of the three crit-ical factors inFairMOTincluding anchor-less re-ID featureextraction, feature fusion and feature dimensions by care-fully designing a number of baseline methods.
在本节中,我们通过精心设计一些基线方法,对FairMOT中的三个关键因素进行了严格的研究,包括无锚re-ID特征提取、特征融合和特征维度。
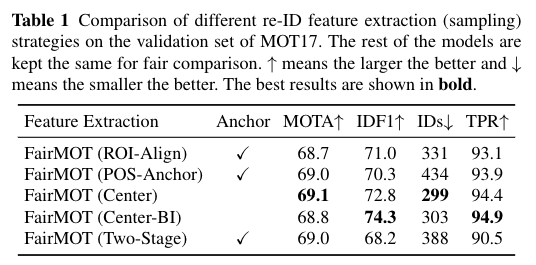
5.3.1 Anchors
We evaluate four strategies for sampling re-ID features fromthe detected boxes which are frequently used by previousworks (Wang et al., 2020b) (Voigtlaender et al., 2019). Thefirst strategy is ROI-Align used in Track R-CNN (Voigt-laender et al., 2019). It samples features from the detectedproposals using ROI-Align. As discussed previously, manysampling locations deviate from object centers. The secondstrategy is POS-Anchor used in JDE (Wang et al., 2020b). Itsamples features from positive anchors which may also de-viate from object centers. The third strategy is “Center” usedinFairMOT. It only samples features at object centers. Re-call that, in our approach, re-ID features are extracted fromdiscretized low-resolution maps. In order to sample featuresat accurate object locations, we also try to apply Bi-linearInterpolation (Center-BI) to extract more accurate features.
我们评估了从先前工作中经常使用的检测框中采样re-ID特征的四种策略(Wang et al.,2020b)(Voigtlander et al.,2019)。第一种策略是Track R-CNN中使用的ROI Align(Voigt-laender等人,2019)。它使用ROI Align对检测到的提案中的功能进行采样。如前所述,许多采样位置偏离对象中心。第二种策略是JDE中使用的POS锚点(Wang et al.,2020b)。它对正锚点的特征进行采样,正锚点也可能从对象中心偏移。第三种策略是FairMOT中使用的“中心”。它只对对象中心的特征进行采样。再次调用,在我们的方法中,Re-ID特征是从离散的低分辨率地图中提取的。为了在精确的物体位置上对特征进行采样,我们还尝试应用双线性插值(中心Bi)来提取更精确的特征。
We also evaluate a two-stage approach to first detect ob-ject bounding boxes and then extract re-ID features. In thefirst stage, the detection part is the same as ourFairMOT. Inthe second stage, we use ROI-Align (He et al., 2017) to ex-tract the backbone features based on the detected boundingboxes and then use a re-ID head (a fully connected layer)to get re-ID features. The main difference between the two-stage approach and the one-stage “ROI-Align” approach isthat the re-ID features of the two-stage approach rely on thedetection results while those of the one-stage approach donot during training.
我们还评估了一种两阶段方法,首先检测对象边界框,然后提取re-ID特征。在第一阶段,检测部分与我们的FairMOT相同。在第二阶段,我们使用ROI Align(He et al.,2017)基于检测到的边界框来提取主干特征,然后使用re-ID头(完全连接的层)来获得re-ID特征。两阶段方法和一阶段“ROI Align”方法之间的主要区别在于,两阶段方法的re-ID特征依赖于检测结果,而一阶段方法的re-ID特征在训练过程中不依赖。
The results are shown in Table 1. Note that the five ap-proaches are all built on top ofFairMOT. The only differ-ence lies in how they sample re-ID features from detectedboxes. First, we can see that our approach (Center) obtainsnotably higherIDF1score and True Positive Rate (TPR)than ROI-Align, POS-Anchor and the two-stage approach.This metric is independent of object detection results andfaithfully reflects the quality of re-ID features. In addition,the number of ID switches (IDs) of our approach is also sig-nificantly smaller than the two baselines. The results vali-date that sampling features at object centers is more effectivethan the strategies used in the previous works. Bi-linear In-terpolation (Center-BI) achieves even higherTPRthan Cen-ter because it samples features at more accurate locations.The two-stage approach harms the quality of the re-ID fea-tures
结果如表1所示。请注意,这五种方法都是建立在FEMOT之上的。唯一的区别在于他们如何从检测到的盒子中采样re-ID特征。首先,我们可以看到,与ROI Align、POS Anchor和两阶段方法相比,我们的方法(Center)获得了显著更高的IDF1分数和真阳性率(TPR)。该指标独立于对象检测结果,忠实地反映了re-ID特征的质量。此外,我们的方法的ID开关(ID)的数量也明显小于两个基线。结果表明,在对象中心的采样特征比以前的工作中使用的策略更有效。双线性插值(中心Bi)实现了比Cen更高的ter,因为它在更准确的位置对特征进行采样。两阶段方法损害了re-ID特征的质量
5.3.2 Balancing Multi-task Losses
We evaluate different methods for balancing the losses ofdifferent tasks including Uncertainty (Kendall et al., 2018),GradNorm (Chen et al., 2018b) and MGDA-UB (Sener andKoltun, 2018). We also evaluate a baseline with fixed weightsobtained by grid search. We implement two versions for theuncertainty-based method. The first is “Uncertainty-task” whichlearns two parameters for the detection loss and re-ID loss,respectively. The second is “Uncertainty-branch” which learnsfour parameters for the heatmap loss, box size loss, offsetloss and re-ID losses, respectively
我们评估了平衡不同任务损失的不同方法,包括不确定性(Kendall et al.,2018)、GradNorm(Chen et al.,2018b)和MGDA-UB(Sener和Koltun,2018)。我们还评估了通过网格搜索获得的具有固定权重的基线。我们实现了基于不确定性的方法的两个版本。第一个是“不确定性任务”,它分别学习检测损失和重新识别损失的两个参数。第二个是“不确定性分支”,它分别学习热图损失、盒子大小损失、偏移损失和重新ID损失的四个参数
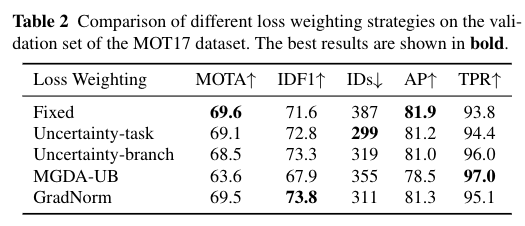
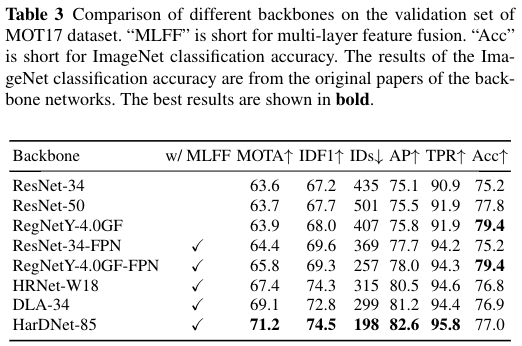
The results are shown in Table 2. We can see that the“Fixed” method gets the bestMOTAandAPbut the worstIDsandTPR. It means that the model is biased to the de-tection task. MGDA-UB has the highestTPRbut the lowestMOTAandAP, which indicates that the model is biased tothe re-ID task. Similar results can be found in (Wang et al.,2020b; Vandenhende et al., 2021). GradNorm gets the bestoverall tracking accuracy (highestIDF1and second highest MOTA), meaning that ensuring different tasks to have simi-lar gradient magnitude is helpful to handle feature conflicts.However, GradNorm takes longer training time. So we usethe simpler Uncertainty method which is slightly worse thanGradNorm in the rest of our experiments
结果如表2所示。我们可以看到,“Fixed”方法得到了最好的MOTA和AP,但得到了最差的IDs和TPR。这意味着该模型偏向于检测任务。MGDA-UB具有最高的TPR,但最低的MOTA和AP,这表明该模型偏向于re-ID任务。类似的结果可以在(Wang等人,2020b;Vandenhende等人,2021)中找到。GradNorm获得了最高的跟踪精度(IDF1最高,第二高MOTA),这意味着确保不同任务具有相似的梯度大小有助于处理特征冲突。然而,GradNorm需要更长的训练时间。因此,我们使用了更简单的不确定度方法,该方法在其他实验中比GradNorm稍差
5.3.3 Multi-layer Feature Fusion
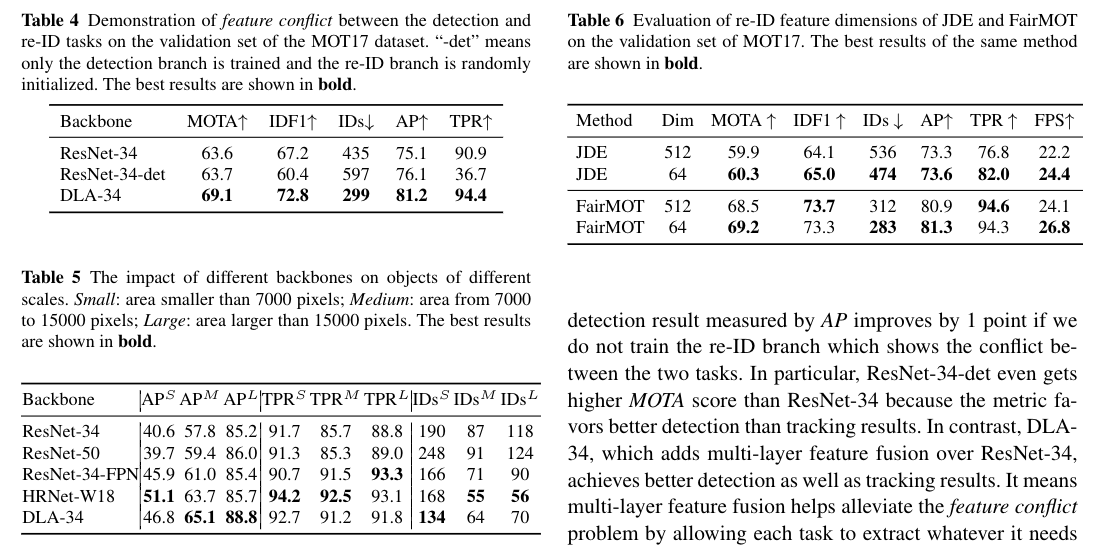
We compare a number of backbones such as vanilla ResNet(He et al., 2016), Feature Pyramid Network (FPN) (Lin et al.,2017a), High-Resolution Network (HRNet) (Wang et al.,2020a), DLA (Zhou et al., 2019a), HarDNet (Chao et al.,2019) and RegNet (Radosavovic et al., 2020). Note that therest of the factors of these approaches such as training datasetsare all controlled to be the same for fair comparison. In par-ticular, the stride of the final feature map is four for all meth-ods. We add three up-sampling operations for vanilla ResNetand RegNet to obtain feature maps of stride four. We dividethese backbones into two categories, one without multi-layerfusion (i.e. ResNet and RegNet) and one with (i.e. FPN, HR-Net, DLA and HarDNet)
我们比较了一些骨干,如香草ResNet(He等人,2016)、特征金字塔网络(FPN)(Lin等人,2017a)、高分辨率网络(HRNet)(Wang等人,2020a)、DLA(Zhou等人,2019a)、HarDNet(Chao等人,2019)和RegNet(Radosavovic等人,2020)。注意,为了公平比较,这些方法的一些因素(如训练数据集)都被控制为相同。特别是,所有方法的最终特征图的步长都是4。我们为vanilla ResNet和RegNet添加了三个上采样操作,以获得第四步的特征图。我们将这些骨干分为两类,一类没有多层融合(即ResNet和RegNet),另一类有(即FPN、HR-Net、DLA和HarDNet)
The results are shown in Table 3. We also list the Ima-geNet (Russakovsky et al., 2015) classification accuracyAccin order to demonstrate that a strong backbone in one taskdoes not mean it will also get good results in MOT. So de-tailed studies for MOT are necessary and useful.
结果如表3所示。我们还列出了Ima-geNet(Russakovsky et al.,2015)的分类精度Accin,以证明在一项任务中有强大的骨干并不意味着它也会在MOT中获得良好的结果。因此,对MOT的深入研究是必要和有用的。
By comparing the results of ResNet-34 and ResNet-50,we find that blindly using a larger network does not notablyimprove the overall tracking result measured byMOTA. Inparticular, the quality of re-ID features barely benefits fromthe larger network. For example,IDF1only improves from67.2%to67.7%andTPRimproves from90.9%to91.9%,respectively. In addition, the number ofID switchesevenincreases from435to501. By comparing ResNet-50 andRegNetY-4.0GF, we can find that using a even more power-ful backbone also achieves very limited gain. The re-ID met-ricTPRof RegNetY-4.0GF is the same as ResNet-50 (91.9)while the ImageNet classification accuracy improves a lot(79.4 vs 77.8). All these results suggest that directly usinga larger or a more powerful network cannot always improvethe final tracking accuracy
通过比较ResNet-34和ResNet-50的结果,我们发现盲目使用更大的网络并不能显著改善MOTA测量的整体跟踪结果。特别是,re-ID特征的质量几乎没有从更大的网络中受益。例如,IDF1仅从67.2%提高到67.7%,TPRI分别从90.9%提高到91.9%。此外,ID转换的数量从435增加到501。通过比较ResNet-50和RegNetY-4.0GF,我们可以发现使用更强大的主干网也可以获得非常有限的增益。RegNetY-4.0GF的re-ID满足ricTPRof与ResNet-50(91.9)相同,而ImageNet的分类精度提高了很多(79.4比77.8)。所有这些结果表明,直接使用更大或更强大的网络并不总能提高最终的跟踪精度
In contrast, ResNet-34-FPN, which actually has fewerparameters than ResNet-50, achieves a largerMOTAscorethan ResNet-50. More importantly,TPRimproves signifi-cantly from90.9%to94.2%. By comparing RegNetY-4.0GF-FPN with RegNetY-4.0GF, we can see that adding multi-layer feature fusion structure (Lin et al., 2017a) to RegNetbrings considerable gains (+1.9 MOTA, +1.3 IDF1, -36.9%IDs, +2.2 AP, +2.3 TPR), which suggests that multi-layerfeature fusion has clear advantages over simply using largeror more powerful networks
相比之下,ResNet-34-FPN的参数实际上比ResNet-50少,它实现了比ResNet50更大的OTA分数。更重要的是,TPRim在90.9%到94.2%之间得到了显著的证明。通过比较RegNetY-4.0GF-FPN和RegNetY-4.0 GF,我们可以看到,在RegNet中添加多层特征融合结构(Lin et al.,2017a)带来了可观的收益(+1.9 MOTA,+1.3 IDF1,-36.9%ID,+2.2 AP,+2.3 TPR),这表明,与简单地使用更大或更强大的网络相比,多层特征融合具有明显的优势
In particular,TPRincreases significantlyfrom90.9%to94.4%which in turn decreases the number ofID switches (IDs) from435to299. Similar conclusions canbe obtained from the results of HRNet-W18. The results val-idate that feature fusion (FPN, DLA and HRNet) effectivelyimproves the discriminative ability of re-ID features. On theother hand, although ResNet-34-FPN obtains equally goodre-ID features (TPR) as DLA-34, its detection results (AP)are significantly worse than DLA-34. We think the use ofdeformable convolution in DLA-34 is the main reason be-cause it enables more flexible receptive fields for objects ofdifferent sizes - it is very important for our method sinceFairMOTonly extracts features from object centers with-out using any region features. We can only get 65.0MOTAand 78.1APwhen replacing all the deformable convolutionswith normal convolutions in DLA-34. As shown in Table 5,we can see that DLA-34 mainly outperforms HRNet-W18on middle and large size objects. When we further use amore powerful backbone HarDNet-85 with more multi-layerfeature fusion structures, we achieve even better results thanDLA-34 (+2.1 MOTA, +1.7 IDF1, -33.8% IDs, +1.4 AP,+1.4 TPR). Although HRNet-W18, DLA-34 and HarDNet-85 get lower ImageNet classification accuracy than ResNet-50 and RegNetY-4.0GF, they achieve much higher trackingaccuracy. Based on the experimental results above, we be-lieve that multi-layer feature fusion is the key to solve the“feature” issue
特别是,TPRin从90.9%显著增加到94.4%,这反过来又将ID开关的数量从435个减少到99个。从HRNet-W18的结果中可以得到类似的结论。结果表明,特征融合(FPN、DLA和HRNet)有效地提高了re-ID特征的识别能力。另一方面,尽管ResNet-34-FPN获得了与DLA-34同样好的ID特征(TPR),但其检测结果(AP)明显不如DLA-34。我们认为在DLA-34中使用可变形卷积是主要原因,因为它为不同大小的物体提供了更灵活的感受野——这对我们的方法非常重要,因为FairMOT只从物体中心提取特征,而不使用任何区域特征。当用DLA-34中的正常卷积替换所有可变形卷积时,我们只能得到65.0MOTA和78.1AP。如表5所示,我们可以看到,DLA-34主要在中大型对象上优于HRNet-W18。
多层次融合是特征提取 以及 平衡两个任务之间的关键
5.3.4 Feature Dimension
以前的一次性跟踪器,如JDE(Wang et al.,2020b),通常在没有消融研究的情况下,通过两步方法学习512维re-ID特征。然而,我们在实验中发现,特征在维度上对平衡检测和跟踪精度起着重要作用。学习低维re-ID特征对检测精度的危害较小,提高了推理速度。我们在不同的一次性跟踪器上进行了实验,发现低维(即64个)re-ID特征比高维(即512个)re-ID特征具有更好的性能是一个普遍的规律。我们在表6中评估了JDE和FairMOT的re-ID特征尺寸的多种选择。对于JDE,我们可以看到64在所有度量上都比512实现了更好的性能。对于FairMOT,我们可以看到512获得了更高的IDF1和TPR分数,这表明更高维度的re-ID特征导致更强的辨别能力。然而,
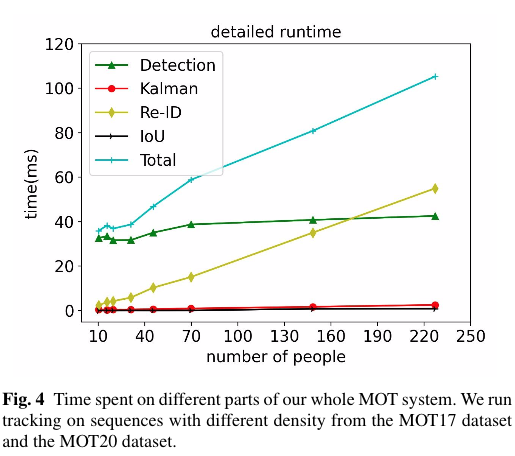
5.3.5 Data Association Methods
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-05nH6bhH-1692263250301)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230817164209122.png)]
5.3.6 Visualization of Re-ID Similarity
5.4 Single Image Training
5.5 Results on MOTChallenge
5.5.1 Comparing with One-Shot SOTA MOT Methods
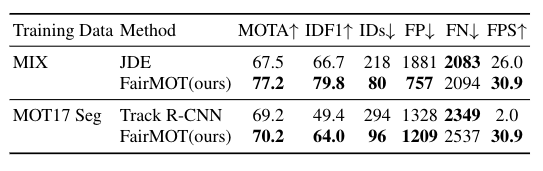
6 Summary and Future Work
Start from studying why the previous one-shot methods (Wanget al., 2020b) fail to achieve comparable results as the two-step methods, we find that the use of anchors in object de-tection and identity embedding is the main reason for the de-graded results. In particular, multiple nearby anchors, whichcorrespond to different parts of an object, may be responsi-ble for estimating the same identity which causes ambigui-ties for network training. Further, we find the feature unfair-ness issue and feature dimension issue between the detec-tion and re-ID tasks in previous MOT frameworks. By ad-dressing these problems in an anchor-free single-shot deepnetwork, we proposeFairMOT. It outperforms the previousstate-of-the-art methods on several benchmark datasets by alarge margin in terms of both tracking accuracy and infer-ence speed. Besides, FairMOT is inherently training data-efficient and we propose single image training of multi-objecttrackers only using bounding box annotated images, whichboth make our method more appealing in real applications(Zhang et al., 2021b)
从研究为什么以前的一次性方法(Wang et al.,2020b)无法获得与两步方法相当的结果开始,我们发现锚在对象检测和身份嵌入中的使用是导致结果降级的主要原因。特别地,对应于对象的不同部分的多个邻近锚可以负责估计相同的身份,这导致网络训练的模糊性。此外,我们发现在以前的MOT框架中,检测和重新识别任务之间存在特征不公平问题和特征维度问题。通过在一个无主播的单次深度网络中对这些问题进行广告处理,我们提出了FairMOT。在跟踪精度和推断速度方面,它在几个基准数据集上以警报幅度优于现有技术。此外,FairMOT本质上训练数据是有效的,我们提出了仅使用边界框注释图像对多对象跟踪器进行单图像训练