添加SE注意力机制
- 1. SE注意力机制论文
- 2. SE注意力机制原理
- 3. SE注意力机制的配置
- 3.1common.py配置
- 3.2yolo.py配置
- 3.3yaml文件配置
1. SE注意力机制论文
论文题目:Squeeze-and-Excitation Networks
论文链接:Squeeze-and-Excitation Networks
2. SE注意力机制原理

3. SE注意力机制的配置
3.1common.py配置
./models/common.py文件增加以下模块
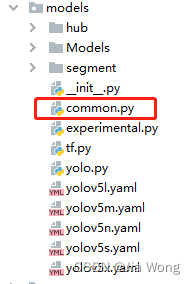
在最后添加如下代码块:
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
def __init__(self, channel=512,reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
# # AIEAGNY
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
3.2yolo.py配置
在 models/yolo.py文件夹下加入SEAttention
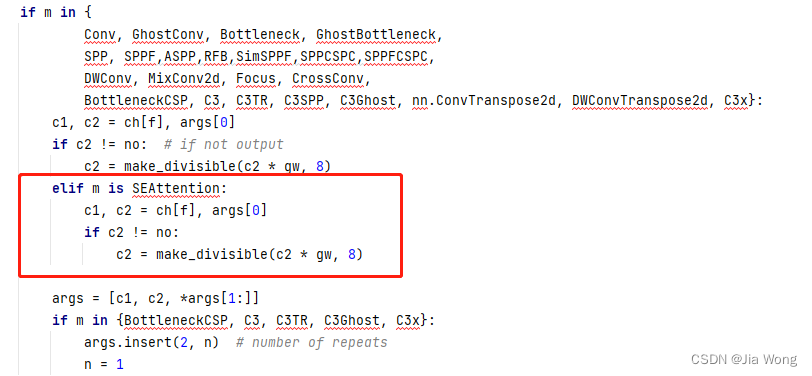
首先定位到parse_model函数中
for i, (f, n, m, args) in enumerate(d[‘backbone’] + d[‘head’])模块:

插入如下代码:
elif m is SEAttention:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
如图为:
3.3yaml文件配置
这里以YOLOv5的6.0版本为例:
可以在骨架网络当中添加:
# YOLOv5 v6.0 backbone
backbone:
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SEAttention,[1024]], #add SEAttention
[-1, 1, SPPF, [1024, 5]], # 9
]
可以在head当中添加:
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, SEAttention, [1024]],
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
添加的位置可以任意,就像搭积木一样,但是要注意通道数是否正确。
持续更新🔥🔥🔥