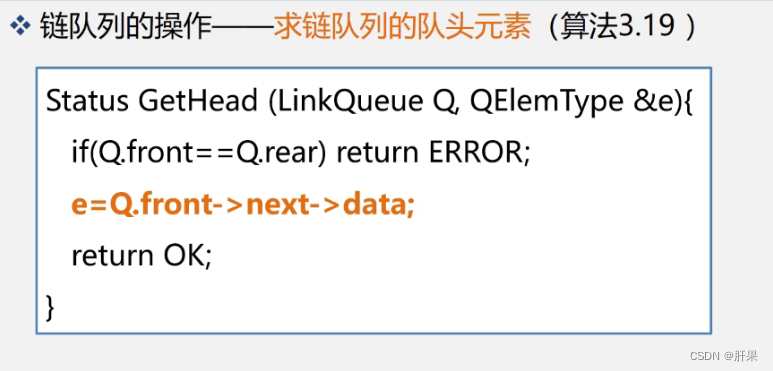
机器学习编译系列---张量程序抽象
- 1. 张量函数概念的引入与抽象的必要性
1. 张量函数概念的引入与抽象的必要性
在文章机器学习编译系列—概述中提到,机器学习编译的一个很重要操作是做等价变换来减少内存或者提高运行效率。变换是以“元张量函数”(private tensor function)为单元进行。直观地,图中的linear、add、relu、linear、softmax均为元张量函数。

机器学习编译的目的并不仅仅是转换而是尽可能自动的转换,为此需要抽象。例如,典型的元张量函数可以抽象为:存储数据的多维数组,驱动张量计算的循环嵌套以及计算部分本身。
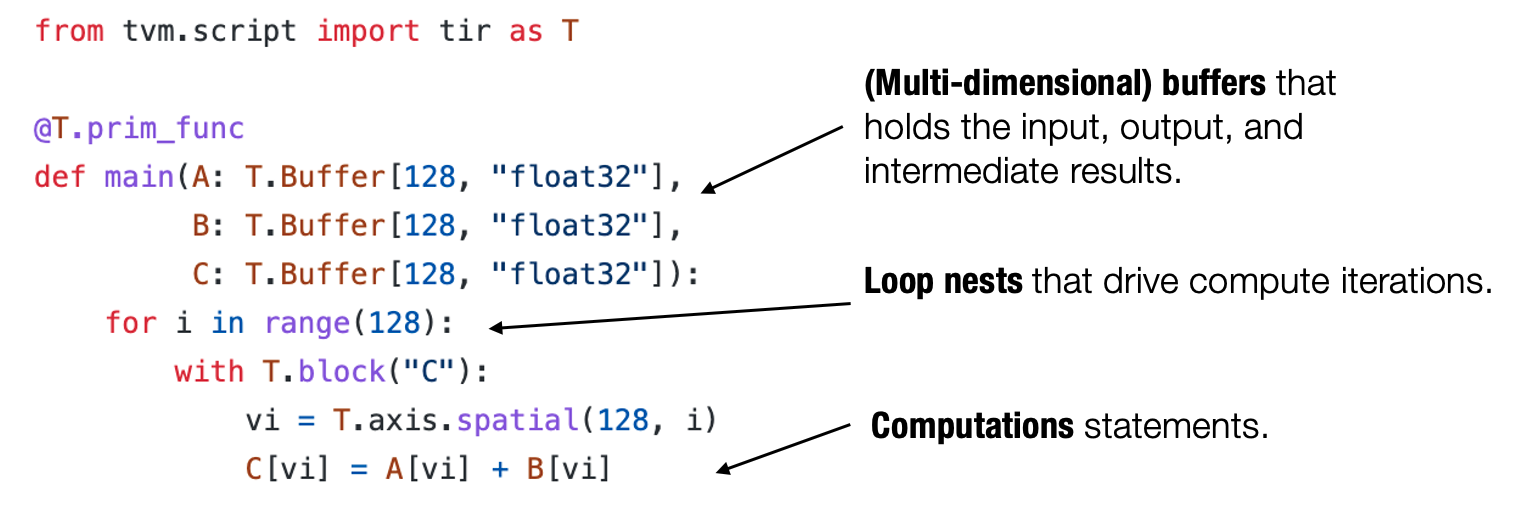
有了抽象,就离自动转换近了一步,例如对于循环嵌套操作,一个较成熟的转换做法是“循环拆分”—》“并行”—》“向量化”,整个过程是可以自动进行的。
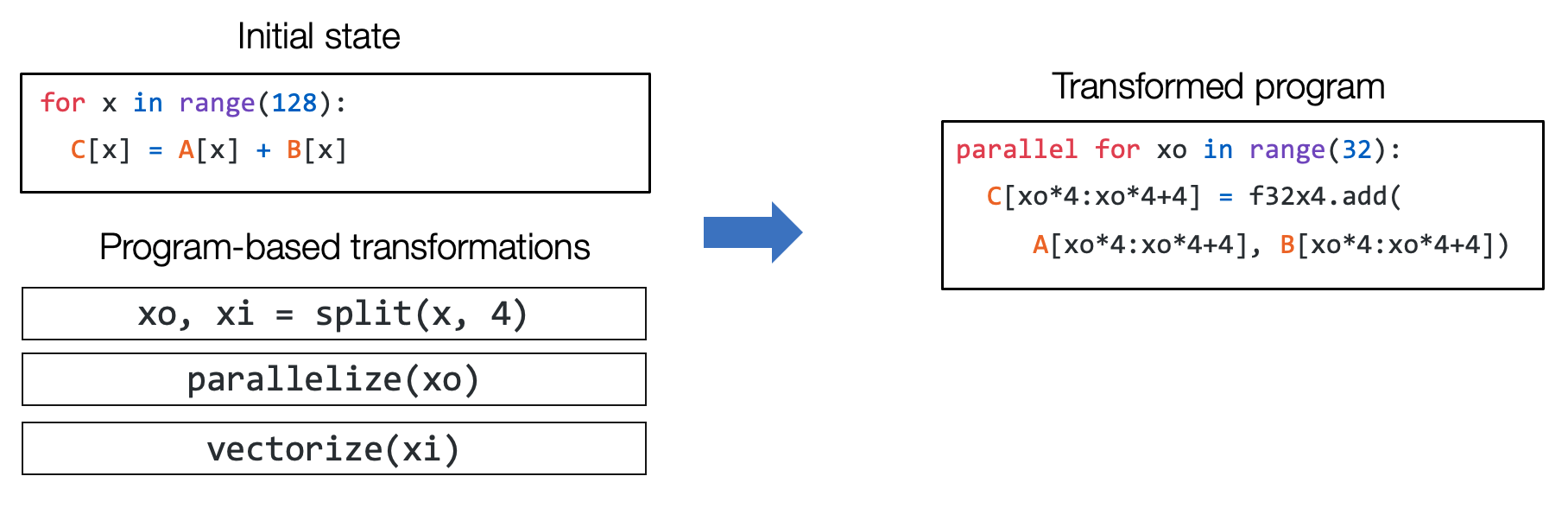
在抽象的基础上再进一步,可以增加Extra information来发挥“编译”的最大效率。仍旧是以循环嵌套操作为例,我们可以通过“Extra information”来告诉深度学习编译器,循环迭代之间的独立性,让“编译器”可以放心的高效自动化转换。

回想c++, 在这一个语言中有各种看似“繁琐”的说明符,例如const, const &等,想必也是为了让编译器发挥最大的功效,起的作用和这里的“Extra information”相同的作用。从这个角度看,机器学习编译和传统的软件编译的确是相通的。