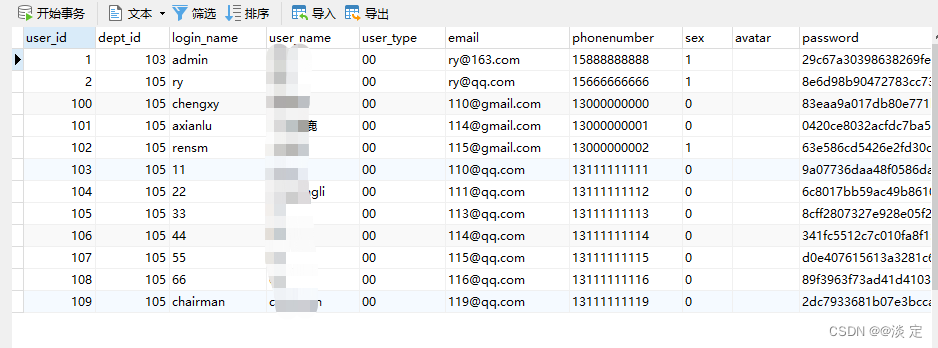
假设模型表是:
1. 根据单字段过滤:
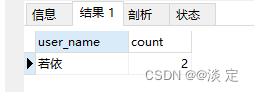
SELECT user_name, COUNT(*) as count
FROM sys_user
GROUP BY user_name
HAVING count > 1;
结果:
2. 根据多个字段查询重复数据
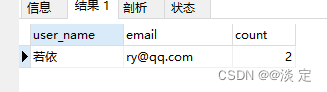
SELECT user_name, email, COUNT(*) as count
FROM sys_user
GROUP BY user_name, email
HAVING count > 1;
结果:
3. 对一个字段查找重复记录
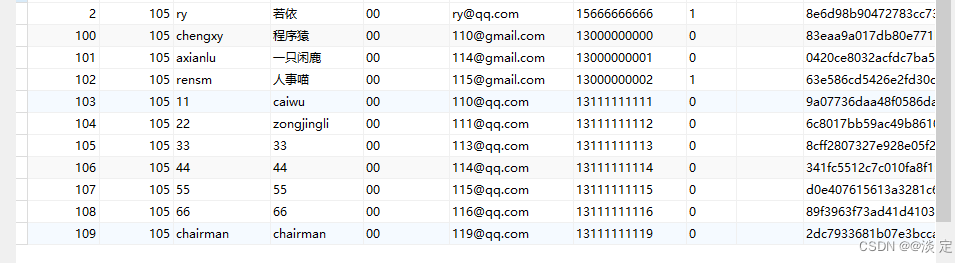
SELECT * FROM sys_user WHERE user_name IN(
SELECT user_name FROM sys_user GROUP BY user_name HAVING COUNT(user_name) > 1
);
结果:

4. 删除重复记录,只保留user_id字段值最大的记录
delete from sys_user where user_id not in (select maxid from (select max(user_id) as maxid from sys_user group by user_name) b);
结果:
5. 对多个字段查找重复记录
SELECT
*
FROM
( SELECT *, CONCAT( user_name, email ) AS nameAndEmail FROM sys_user ) t
WHERE
t.nameAndEmail IN (
SELECT
nameAndEmail
FROM
( SELECT CONCAT( user_name, email ) AS nameAndEmail FROM sys_user ) tt
GROUP BY
nameAndEmail
HAVING
count( nameAndEmail ) > 1
)
结果:

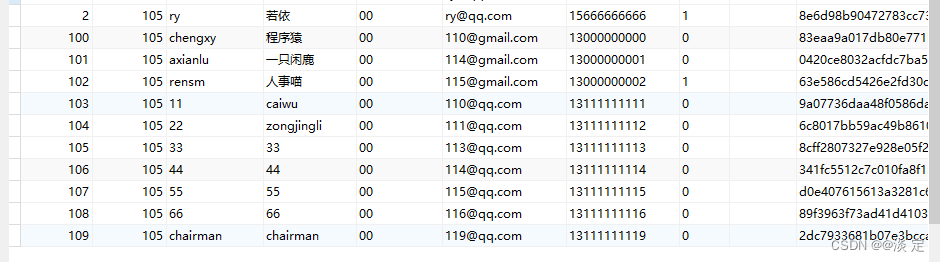
6. 删除重复记录,只保留user_id字段值最大的记录
DELETE
FROM
sys_user
WHERE
user_id NOT IN (
SELECT
maxid
FROM
( SELECT MAX( user_id ) AS maxid, CONCAT( user_name, email ) AS nameAndEmail FROM sys_user GROUP BY nameAndEmail ) t
)
结果:
7. 完全重复数据删除
1.查询表完全重复的纪录,即表行数据是完全重复
select distinct * from sys_user;
2. 如果该表需要删除重复的记录(重复记录保留1条)
select distinct * into sys_user1 from sys_user;
drop table sys_user;
select * into sys_user1 from sys_user1;
drop table sys_user1;
8. 关键字段重复删除
1 创建一个临时表,用于存储要删除的重复数据。
CREATE TABLE sys_user1 as(SELECT MIN(user_id) as userid from sys_user GROUP BY user_name );
SELECT * from sys_user1;
DELETE from sys_user where user_id not in(SELECT * from sys_user1);
DROP TABLE sys_user1;