| 『论文精读』Data-efficient image Transformers(DeiT)论文解读 |
文章目录
- 一. DeiT简介
- 二. 知识蒸馏(knowledge distillation)
- 2.1. KLDivloss
- 2.2. 蒸馏温度 τ \tau τ
- 2.3. distillation in transformer
- 三. better hyperparameter
- 四. data augmentation
- 五. label smoothing
- 参考文献
- 论文下载链接:https://arxiv.org/pdf/2012.12877.pdf
- 论文代码链接:https://github.com/facebookresearch/deit
- 关于VIT论文的解读可以关注我之前的文章:『论文精读』Vision Transformer(VIT)论文解读
一. DeiT简介
- 现有的基于Transformer的分类模型ViT需要在海量数据上(JFT-300M,3亿张图片)进行预训练,再在ImageNet数据集上进行fune-tuning,才能达到与CNN方法相当的性能,这需要非常大量的计算资源,这限制了ViT方法的进一步应用。


- DeiT的模型和VIT的模型几乎是相同的,可以理解为本质上是在训一个VIT。
- better hyperparameter:指的是模型初始化、learning-rate等设置。
- data augmentation:在只有120万张图片的Imagenet,使用数据增广模拟更多数据。
- Distillation:知识蒸馏。
- 三部分的作用分别为:保证模型更好的收敛、可以使用小的数据训练、进一步提升性能。还有一些其他的方式,如:warmup、label smoothing、droppath等。

- Data-efficient image transformers (DeiT) 无需海量预训练数据,只依靠ImageNet数据,便可以达到SOTA的结果,同时依赖的训练资源更少(4 GPUs in three days)。

- 文章贡献如下:
- 仅使用Transformer,不引入Conv的情况下也能达到SOTA效果。
- 提出了基于token蒸馏的策略,这种针对transformer的蒸馏方法可以超越原始的蒸馏方法。
- Deit发现使用Convnet作为教师网络能够比使用Transformer架构取得更好的效果。
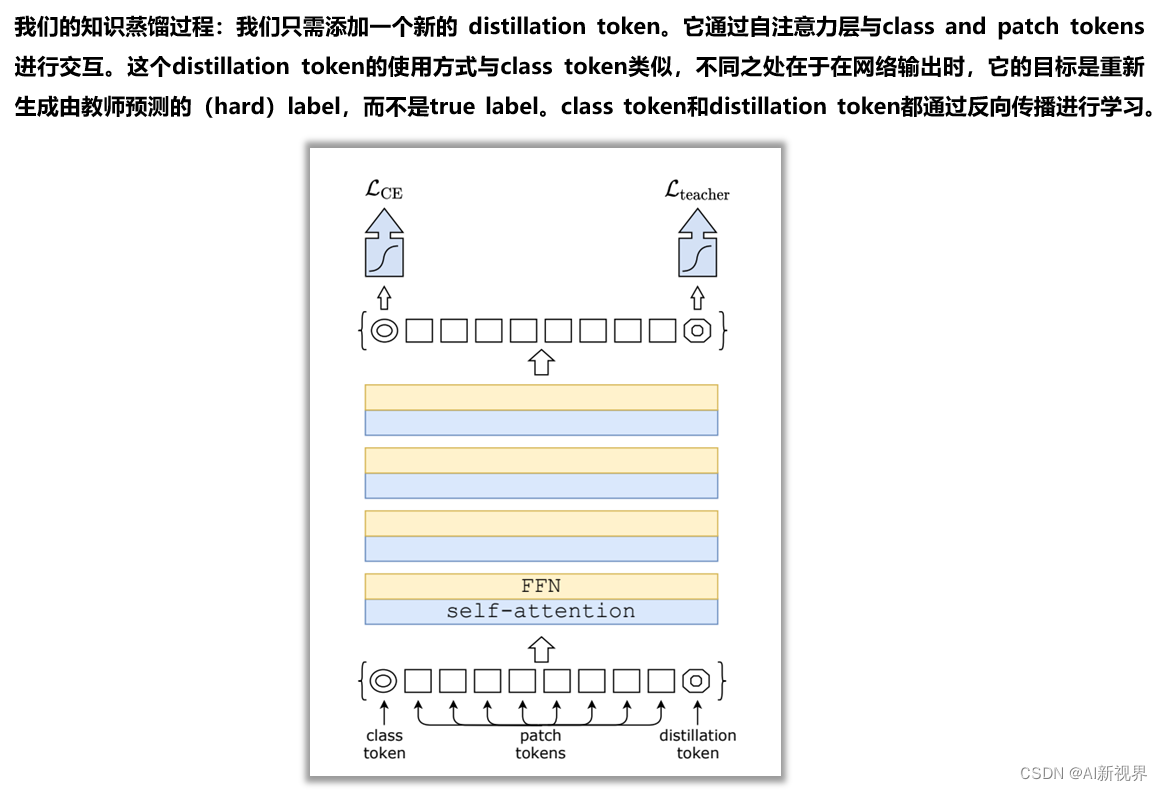
二. 知识蒸馏(knowledge distillation)
- Knowledge Distillation(KD)最初被Hinton提出,与Label smoothing动机类似,但是KD生成soft label的方式是通过教师网络得到的。
- KD可以视为将教师网络学到的信息压缩到学生网络中。还有一些工作“Circumventing outlier of autoaugment with knowledge distillation”则将KD视为数据增强方法的一种。
- KD能够以soft的方式将归纳偏置传递给学生模型,Deit中使用Conv-Based架构作为教师网络,将局部性的假设通过蒸馏方式引入Transformer中,取得了不错的效果。
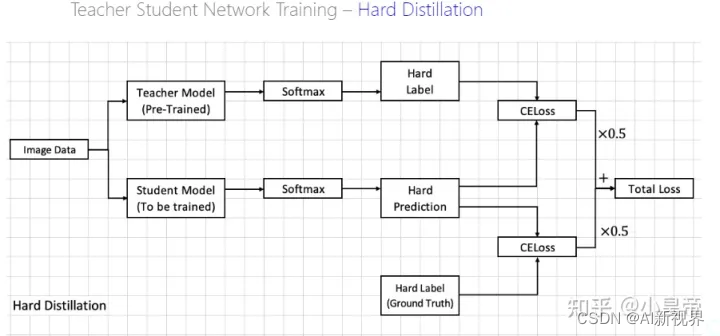
- 简单来说就是用teacher模型去训练student模型,通常teacher模型更大而且已经训练好了,student模型是我们当前需要训练的模型。在这个过程中,teacher模型是不训练的。

- 当teacher模型和student模型拿到相同的图片时,都进行各自的前向,这时teacher模型就拿到了具有分类信息的feature,在进行softmax之前先除以一个参数 τ \tau τ,叫做temperature(蒸馏温度),然后softmax得到soft labels(区别于one-hot形式的hard-label)。
- student模型也是除以同一个 τ \tau τ,然后softmax得到一个soft-prediction,我们希望student模型的soft-prediction和teacher模型的soft labels尽量接近,使用KLDivLoss进行两者之间的差距度量,计算一个对应的损失teacher loss。
- 在训练的时候,我们是可以拿的到训练图片的真实的ground truth(hard label)的,可以看到上面图中student模型下面一路,就是预测结果和真是标签之间计算交叉熵crossentropy。
- 链接:损失函数|交叉熵损失函数
- 然后两路计算的损失:KLDivLoss和CELoss,按照一个加权关系计算得到一个总损失total loss,反向修改参数的时候这个teacher模型是不做训练的,只依据total loss训练student模型。
- 还可以使用硬蒸馏,对比上面的结构图,哪种更好没有定论。
2.1. KLDivloss
- 这里可以参考下我之前的文章:〖ML笔记〗信息量、信息熵、交叉熵、KL散度(相对熵)、JS散度以及逻辑损失+面试知识点!
- KL divergence(KL散度又叫相对熵): 它表示用分布 q ( x ) q(x) q(x) 模拟真实分布 p ( x ) p(x) p(x) 所需要的额外信息。同时也叫KL距离,就是是两个随机分布间距离的度量。
- 取值范围: [ 0 , + ∞ ] [0, +\infty ] [0,+∞],当两个分布接近相同的时候KL散度取值为0,当两个分布差异越来越大的时候KL散度值就会越来越大。
D K L ( p ∣ q ) = H ( p , q ) ⏟ 交叉熵 − H ( p ) ⏟ 信息熵 = − ∑ i = 1 n p ( x i ) log q ( x i ) + ∑ i = 1 n p ( x i ) log p ( x i ) = ∑ i = 1 n p ( x i ) log p ( x i ) q ( x i ) (1) \begin{aligned} {D}_{K L}({p} | {q})&=\underbrace{H(p, q)}_{\text {交叉熵}}-\underbrace{H(p)}_{\text {信息熵}}\\&=-\sum_{i=1}^{n}{p}(x_i) \log {q}(x_i)+\sum_{i=1}^{n} {p}(x_i) \log {p}(x_i) \\ &=\sum_{i=1}^{n} {p}(x_i) \log \frac{{p}(x_i)}{{q}(x_i)}\tag{1} \end{aligned} DKL(p∣q)=交叉熵 H(p,q)−信息熵 H(p)=−i=1∑np(xi)logq(xi)+i=1∑np(xi)logp(xi)=i=1∑np(xi)logq(xi)p(xi)(1) 注意: 直观来说,由于 p ( x ) p(x) p(x) 是已知的分布(真实分布), H ( p ) H(p) H(p) 是个常数,交叉熵和KL散度之间相差一个这样的常数(信息熵)。
- 当两个分布完全一致时候,KL散度就等于0。KLDivloss定义和使用方式为:

2.2. 蒸馏温度 τ \tau τ
- 蒸馏温度 τ \tau τ 的作用,回想之前VIT中在self-attention里面计算 q , k \mathbf {q,k} q,k间的加权因子的时候,计算完了要scale(除以 k k k 的维度),然后再做softmax,然后用它们对 v \mathbf v v 加权相加得到对应的表示向量。
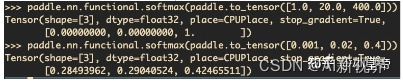
- 如果是
[1.0,20.0,400.0]直接做softamx,那结果是[0.0,0.0,1.0],可见结果完全借鉴第三个引子。而先进行处理(比如除以1000)后变为[0.001,0.02,0.4]时,在做softamx结果为[0.28,0.29,0.42]结果总综合考虑了三部分,这显然是更合理的结果。实际中,看我是更希望结果偏向于更大的值,还是偏向于综合考虑来决定是否使用softmax前输入的预处理。
2.3. distillation in transformer
这一节主要弄清楚,如何在transformer中进行蒸馏操作。
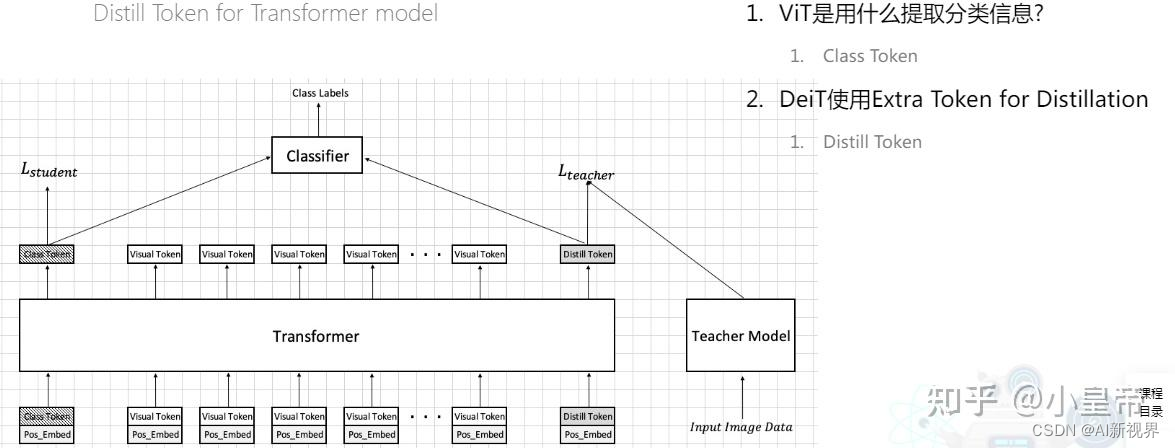
- 先说一下,在这DeiT篇论文出来的时候,teacher model使用的是Regnet(一个CNN)。
- 在VIT中时使用class tokens去做分类的,相当于是一个额外的patch,这个patch去学习和别的patch之间的关系,然后连classifier,计算CELoss。在DeiT中为了做蒸馏,又额外加一个distill token,这个distill token也是去学和其他tokens之间的关系,然后连接teacher model计算KLDivLoss,那CELoss和KLDivLoss共同加权组合成一个新的loss取指导student model训练(知识蒸馏中teacher model不训练)。
- 在预测阶段,class token和distill token分别产生一个结果,然后将其加权(分别0.5),再加在一起,得到最终的结果做预测。

L global = ( 1 − λ ) L C E ( ψ ( Z s ) , y ) + λ τ 2 K L ( ψ ( Z s / τ ) , ψ ( Z t / τ ) ) (2) \mathcal{L}_{\text {global }}=(1-\lambda) \mathcal{L}_{\mathrm{CE}}\left(\psi\left(Z_{\mathrm{s}}\right), y\right)+\lambda \tau^2 \mathrm{KL}\left(\psi\left(Z_{\mathrm{s}} / \tau\right), \psi\left(Z_{\mathrm{t}} / \tau\right)\right)\tag{2} Lglobal =(1−λ)LCE(ψ(Zs),y)+λτ2KL(ψ(Zs/τ),ψ(Zt/τ))(2)

L global hardill = 1 2 L C E ( ψ ( Z s ) , y ) + 1 2 L C E ( ψ ( Z s ) , y t ) (3) \mathcal{L}_{\text {global }}^{\text {hardill }}=\frac{1}{2} \mathcal{L}_{\mathrm{CE}}\left(\psi\left(Z_s\right), y\right)+\frac{1}{2} \mathcal{L}_{\mathrm{CE}}\left(\psi\left(Z_s\right), y_{\mathrm{t}}\right)\tag{3} Lglobal hardill =21LCE(ψ(Zs),y)+21LCE(ψ(Zs),yt)(3)
三. better hyperparameter
- DeiT中第二个优化点在于better hyperparameter,也就是更好的参数配置,看看其都包含哪些部分。
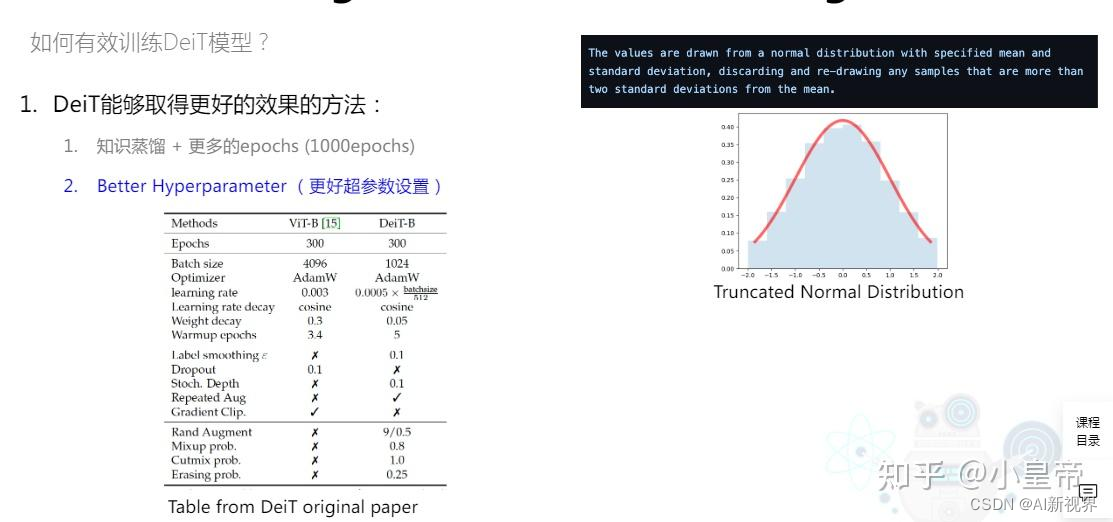
- 参数初始化方式:truncated normal distribution(截断标准分布)。
- learning-rate:CNN中的结论:当batch size越大的时候,learning rate设置的越大。
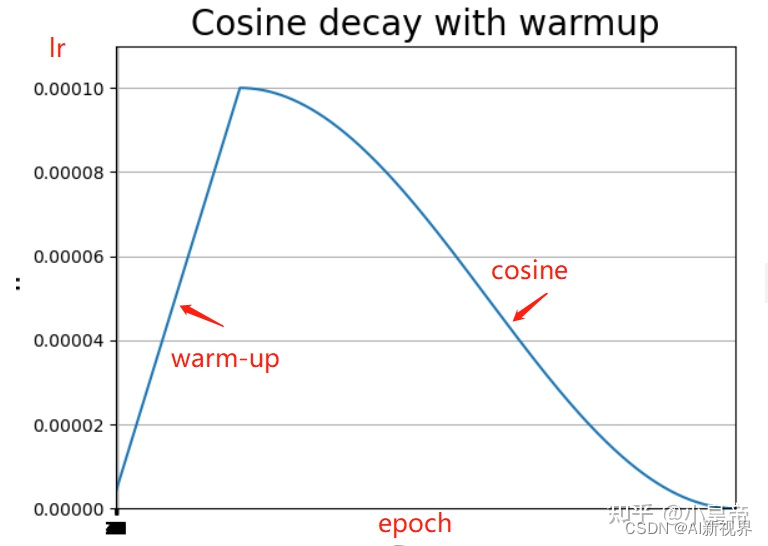
- learning rate decay:cosine,在warm-up阶段lr先线性升上去,然后通过余弦方式lr降下来。
四. data augmentation

- mixup之后的图片的label不再是单一的label,而是soft-label,比如
[cat,dog]=[0.5,0.5]- cutmix之后的图片label是按所占据的比例给的,比如
[cat,dog]=[0.3,0.7]

- randomaug其实是由autoaug来的,autoaug是选取了25中增强策略,每种策略中有两个操作,这两种操作都要被执行。每次为一张图随机从25中策略中选取一种,将这两种操作对该图执行。至于这25中策略是怎么组成的,每种里面的操作的概率是如何确立的,这些是由搜索算法的实现的,总之认为这么搭配有效就行了。对于randomaug,相当于对于autoaug的简化,它是13种增强策略,然后从中一次选取6种策略依次对图片进行操作,完成增强操作。
- model EMA(Exponential Moving Average)指数滑动平均,使得模型权重更新与一段时间内的历史取值有关。 m t m_{t} mt 是当前的模型权重, m t − 1 m_{t-1} mt−1 是上一轮模型权重, θ t \theta_{t} θt为模型当前权重的值,举一个例子:

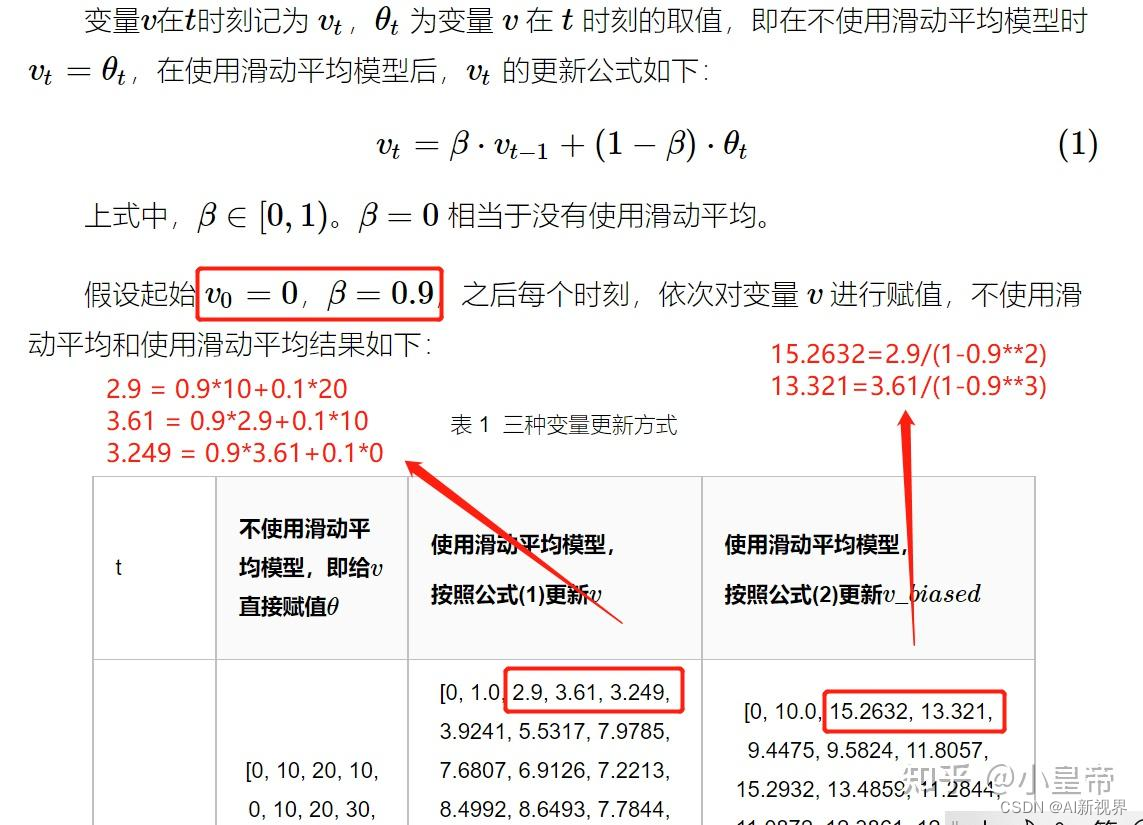
- 三种更新参数方式的更新参数结果曲线:


- 实际使用的时候,设置上面例子中的 β \beta β 值例如为0.99996,保证模型的参数值不会乱动。
五. label smoothing
label smoothing:原本hard-label变成soft-label,设置参数,给其余非标签平均一些label概率。
Label one hot = [ 1 , 0 , 0 , 0 , 0 , 0 ] Label smoothing = [ 0.9 , 0.02 , 0.02 , 0.02 , 0.02 , 0.02 ] , α = 0.1 \begin{aligned} & \text { Label }_{\text {one hot }}=[1,0,0,0,0,0] \\ & \text { Label }_{\text {smoothing }}=[0.9,0.02,0.02,0.02,0.02,0.02], \alpha=0.1 \end{aligned} Label one hot =[1,0,0,0,0,0] Label smoothing =[0.9,0.02,0.02,0.02,0.02,0.02],α=0.1


- 上图来自论文:When Does Label Smoothing Help
参考文献
- 以上内容主要参考自大神:Transformer学习(四)—DeiT
- DeiT | Training data-efficient image transformers & distillation through attention
- DeiT:使用Attention蒸馏Transformer



![【傅里叶级数与傅里叶变换】数学推导——2、[Part2:T = 2 π的周期函数的傅里叶级数展开] 及 [Part3:周期为2L的函数展开]](https://img-blog.csdnimg.cn/fee7327716bc4879a8d502a6c50363b1.png)