一、说明
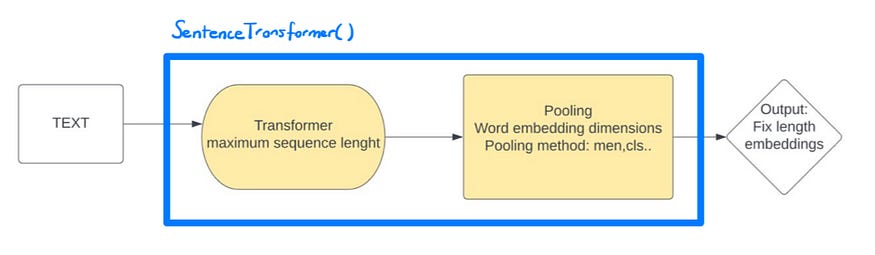
转换器和池化组件,它们来自 Bert 在 SentenceTransformer 对象中预先训练的模型。
在我之前的文章中,我用拥抱面转换器介绍了预训练模型来计算句子之间的余弦相似性分数。在这篇文章中,我们将深入研究变压器模型的参数。句子转换器对象允许我们加载预先训练的模型,我们可以观察模型参数,例如最大序列长度和池化方法。但是这些参数意味着什么,我们如何修改它们以满足我们的需求?这篇文章解决了这些问题,并提供了对这些参数的更深入理解。
使用转换器模型,可以使用相同的内核架构,而无需重新训练内核。预先训练的转换器模型是使用大量训练数据开发的,通常会由Google或OpenAI等组织产生大量成本。我们很幸运,这些模型随后免费供公众使用。在这些预训练模型中最受欢迎的是由Google AI开发的BERT(来自变压器的双向编码器表示)。在本文中,我使用“bert-base-uncased”模型。让我们加载模型:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("bert-base-uncased")
model
"""output:
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
) """ 我们在这里可以看到的输出是包含转换器和池化组件的对象:SentenceTransformer
- 在 Transformer 中,我们可以看到最大序列长度为 512 个标记,小写参数为 false。变压器模型是BertModel。
- 在将一系列嵌入转换为句子嵌入的过程的池化操作中,池化操作使用平均池化方法创建 768 维句子嵌入。
现在,我将深入解释变压器和池化的这些参数,以及如何修改它们以满足我们的目标。
二、最大序列长度
对于 BERT 预训练模型,最大序列长度参数为 512 个令牌作为默认值。BERT模型通常限制为512个代币。变压器模型,如BERT,RoBERTa,DistilBERT等,具有运行时和内存要求,该要求随着输入的长度呈指数级增长。这限制了变压器的使用限于有限长度的输入。BERT和类似模型的典型值是512个单词,相当于大约300-400个英语单词。比这更长的文本被缩短为第一个 x 字片段。
您可以使用以下代码更改最大序列长度:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("bert-base-uncased")
model
"""output:
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
) """三、做小写转化
通过将do_lower_case设置为 true 或 false,可以将 BERT 模型的预训练作为“无大小写”或“大小写”版本完成。我使用了模型“bert-base-uncased”,它不做小写的单词。
“不大小写”版本表示文本在标记化之前已转换为小写,例如,“Gulsum Bu”变为“gulsum bu”。另一方面,“大小写”表示保留原始大小写和重音符号,例如“Gulsum Bu”。
设置为 表示输入文本在标记化之前将转换为小写,例如,“Gulsum Bu”将变为“gulsum bu”。设置为 to 表示在标记化过程中将保留输入文本的原始大小写,例如“Gulsum Bu”。do_lower_caseTruedo_lower_caseFalse
四、词嵌入维度:“word_embedding_dimension”
NLP 中的单词嵌入是数字格式的单词表示。令牌嵌入层将单词转换为固定维向量表示。在BERT的情况下,每个单词都表示为768维向量。
例如,我们有一个 8 个代币示例。令牌嵌入层会将每个字段标记转换为 768 维矢量表示。如果我们包含批处理轴,这会导致我们的 6 个输入标记被转换为形状的矩阵 (8, 768) 或形状的张量 (1, 8, 768)。
五、池化方法
- CLS 池化
它被使用得很常见。此方法涉及在每个句子的开头添加一个特殊的 <CLS> 标记。此特殊令牌的目的是在句子级别捕获信息。因此,池化层只需选择 CLS 令牌嵌入作为句子嵌入即可聚合。
- 平均池化
这是一种简单的池化方法。均值池涉及平均BERT产生的所有上下文化词嵌入。
- 最大池化
最大池化利用令牌嵌入随时间推移的最大值。它涉及在每个时间步长获取令牌嵌入的最大值以生成句子嵌入。
- 均方池
它涉及平均BERT产生的所有上下文化单词嵌入的平方。
例如,我们有“伯特基无壳”模型。在该模型中,我们将平均池化方法作为默认值。我们可以更改所有变压器模型的池化方法。我给出了两种方法来更改池化类型。
#First way to change pooling method. Mean pooling to CLS pooling
from sentence_transformers import SentenceTransformer, models
model = SentenceTransformer('bert-base-uncased')
model = models.Pooling(model[0].get_word_embedding_dimension(),
pooling_mode_mean_tokens=False,
pooling_mode_cls_token=True,
pooling_mode_max_tokens=False)
#Second way to change pooling method. Mean pooling to CLS pooling
model1 = SentenceTransformer('bert-base-uncased')
model1[1].pooling_mode_mean_tokens = False
model1[1].pooling_mode_cls_token = True总之,本文介绍了变压器模型的参数,特别关注最大序列长度、小写参数和池化方法。通过提供全面的解释和一些基本代码示例,它旨在让读者更好地了解如何操作他们的转换器模型。这些参数对于自定义模型以最好地满足特定任务或应用程序的需求至关重要。有了从本文获得的知识,读者应该能够修改模型,以便在他们自己的NLP项目中取得更好的结果。
请随时在下面留下任何问题或建议。
参考资料和引用
Computing Sentence Embeddings — Sentence-Transformers documentation。
居尔苏姆·布达科奥卢