1.什么是索引覆盖
索引覆盖是指在一个查询语句中,某个索引已经 "覆盖了" 需要被查询出来的列,此时就不需要进行回表查询了,这就叫做索引覆盖!!(索引覆盖它是非聚簇索引中的一个特殊情况)
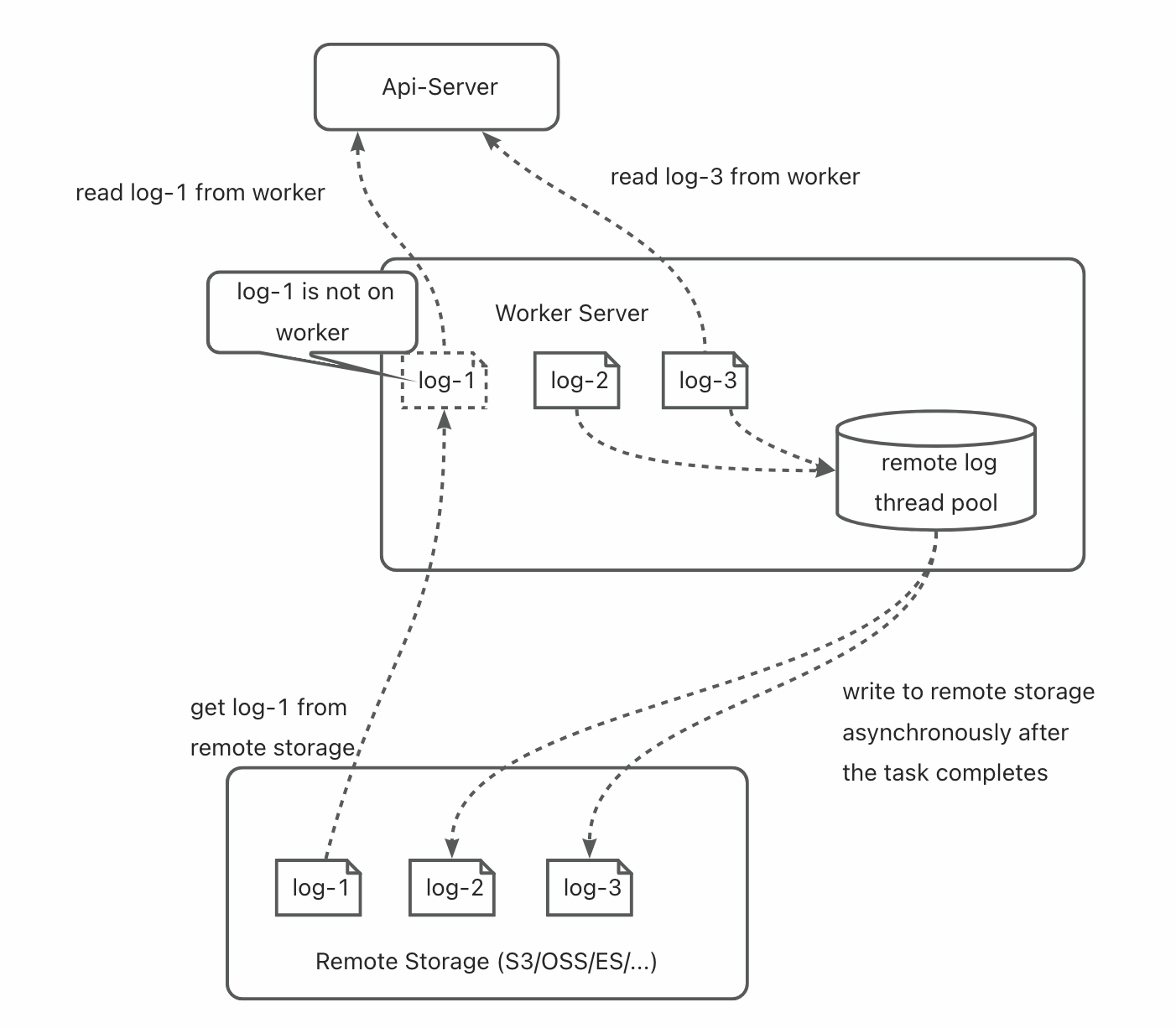
【案例】当我们写了这样一个 SQL,实际上它走的是辅助索引,结构如下图:
select id from student where name = 'Bob';
- 辅助索引(非聚簇索引)中的查询,一般是需要查询两次,第一次查询出聚簇索引,然后根据聚簇索引回表查询,最终拿到行数据。
- 但是此处我的查询需求刚好就是聚簇索引,因此一次查询就可以拿到需要的列,不需要进行回表,这就是索引覆盖~
【加强理解】以下四种情况都属于索引覆盖 >>
// 联合索引 (name,age)
select name from student where.....
select age from student where.....
select name,age from student where.....
select address,name,age from student where address = '深圳';最后一个 SQL 因为 where 条件后面可以知道 address,所以也不需要回表查询!!
2.什么是索引下推
索引下推是指在查询非聚簇索时,拿到了叶子结点的聚簇索引,然后对聚簇索引中包含的字段先做判断,直接过滤吊不满足条件的记录,从而减少回表次数,这就是索引下推!!(索引下推是在 MySQL 5.6 之后才引入的,它属于非聚簇索引中功能)
以 user 表中的联合索引(name,age)为例:
select * from user where name='张%' and age='10';
// 表中有四条数据
// 1 张三 10
// 2 张四 11
// 3 张五 12
// 4 老六 13🍁MySQL 5.6 之前没有索引下推,它的执行流程如下:
① 在非聚簇索引中根据 name='张%' 查到聚簇索引中匹配的 id

② 使用匹配的 id 进行回表查询

此时会进行三次回表操作,而联合索引中的 age 字段就没用上。
🍁MySQl 5.6 之后引入索引下推,它会根据 name='张%' 和 age 一起过滤数据:
【好处】:它的第二步操作就可以节省回表的次数
② 使用匹配的 id 进行回表查询

引入索引下推后,只执行了一次回表查询,这就是索引下推的好处。
3.什么是最左匹配原则
【定义和规则】
- 最左匹配原则是指索引以最左边的为起点,任何连续的索引都能匹配上,
- 当遇到范围查询 (>、<、between、like) 就会停止匹配。
什么意思呢 ??
比如联合索引 index(a,b,c),以下 SQL 来理解什么是最左匹配原则:
select * from user where a=1; // 只使用索引 a
select * from user where b=2; // 不使用索引
select * from user where c=3; // 不使用索引
select * from user where a=1 and b=2; // 只使用索引 a,b
select * from user where a=1 and c=3; // 只是用索引 a
select * from user where b=2 and c=3; // 不使用索引
select * from user where a=1 and b=2 and c=3; // 使用索引 a,b,c
select * from user where a=1 and b like '%xxx' and c=3; // 只使用索引 a,b通过上面的例子,我相信大家已经大概理解了什么是最左匹配原则~
【疑惑一】
不是说使用了 like,就停止匹配了吗,为什么前面的索引下推使用了 name='张%' 还能再拿 age 进行过滤呢 ?
对于 like 查询,它的常见写法有三种:
- 模糊匹配后面任意字符:like '张%'
- 模糊匹配前面任意字符:like '%张'
- 模糊匹配前后任意字符:like '%张%'
这三种情况,只有第一种情况是会走索引的,其他的都会导致索引失效,所以前面索引下推例子中的 name='张%' 是不会停止匹配的~
【疑惑二】
当我们写出这样的条件语句 where a=1 and c=3 and b=2 时,引擎为什么不把它调整为 a,b,c 的顺序呢?
MySQL 8.0 之后才涉及到这样的调优,但是具体会不会调优,是不一定的,因为索引调优的主动权在索引的优化器里面的,而优化器这个东西,它很玄学,所以不知道它会不会进行调优。