一、目标
Kettle9.2.0在Linux上安装好后,需要与Hive3.1.2数据库建立连接
之前已经在本地上用kettle9.2.0连上Hive3.1.2
二、各工具版本
(一)kettle9.2.0
kettle9.2.0安装包网盘链接
链接:https://pan.baidu.com/s/15Zq9wNDwyMnc3qFVxYOMXw?pwd=zwae
提取码:zwae

(二)Hive3.1.2
(三)Hadoop3.1.3
三、前提准备
(一)Kettle9.2.0已在Linux上安装好
(二)注意Kettle9.2里MySQL驱动包的版本以及Hive312里MySQL驱动包的版本
1、Hive312的lib里面MySQL驱动包的版本是mysql-connector-java-5.1.37.jar
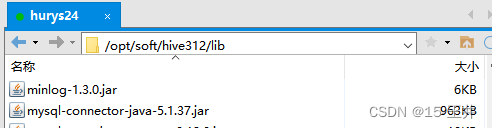
2、Kettle9.2里MySQL驱动包的版本
mysql-connector-java-5.1.37.jar ; mysql-connector-java-8.0.30.jar

四、安装步骤
(一)根据Hadoop版本在选择对应的文件(千万不要随便选!)
1、文件路径
/opt/install/kettle9.2/data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations

2、Hadoop版本与文件夹对应规则

3、选择文件,复制文件名(Hadoop版本与文件夹一定要匹配!)
因为我的Hadoop版本是Hadoop3.1.3,所以我选择的文件夹是hdp30
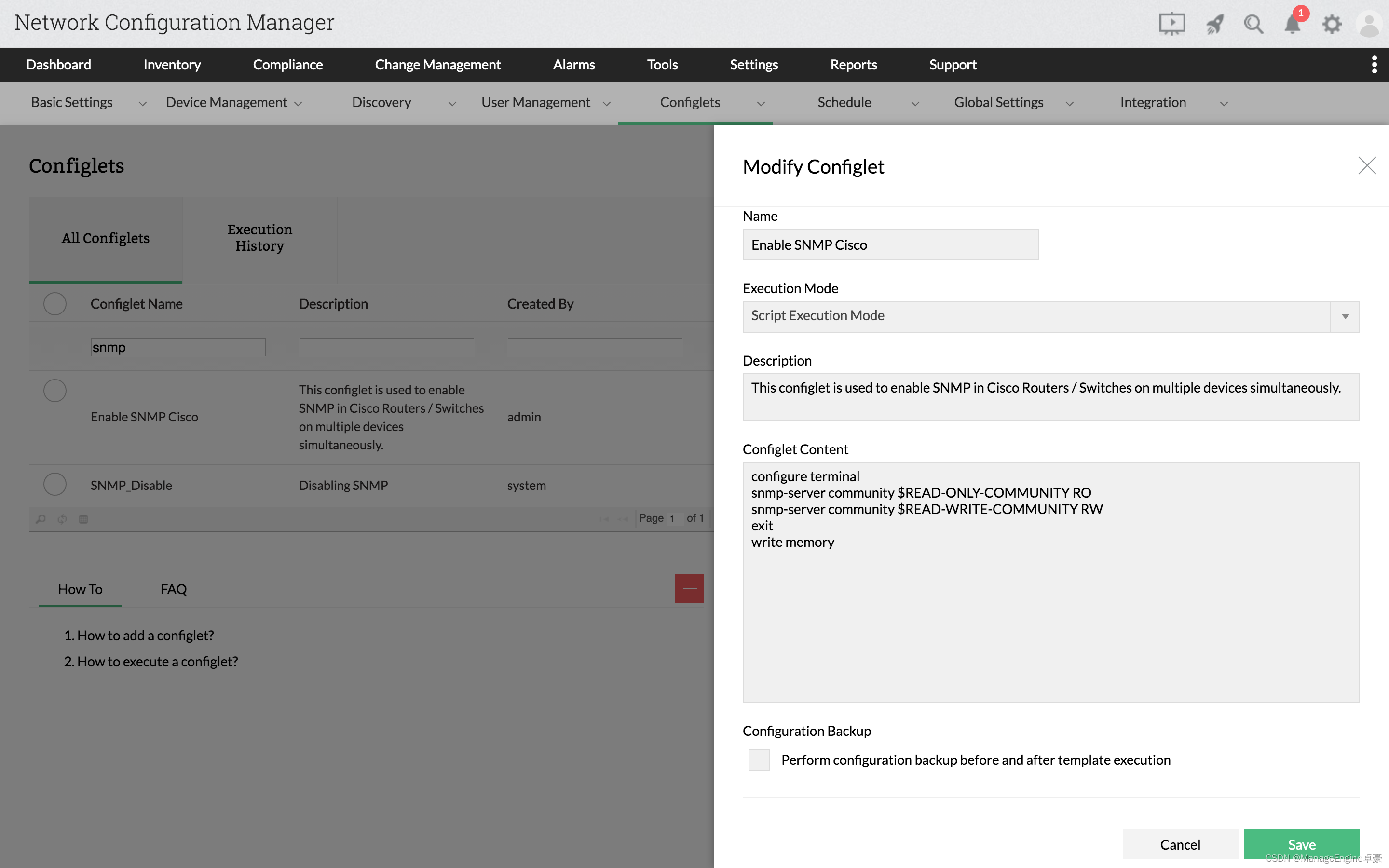
(二)修改kettle里pentaho-big-data-plugin文件夹里的源文件plugin.properties
1、文件路径
/opt/install/kettle9.2/data-integration/plugins/pentaho-big-data-plugin

2、 只要设置 active.hadoop.configuration=hdp30

(三)从我们安装的Hadoop、Hive里拉取需要的文件复制到hdp30的文件夹下(如需要HBase则拉取HBase的 hbase-site.xml)
1、文件路径
/opt/install/kettle9.2/data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations/hdp30
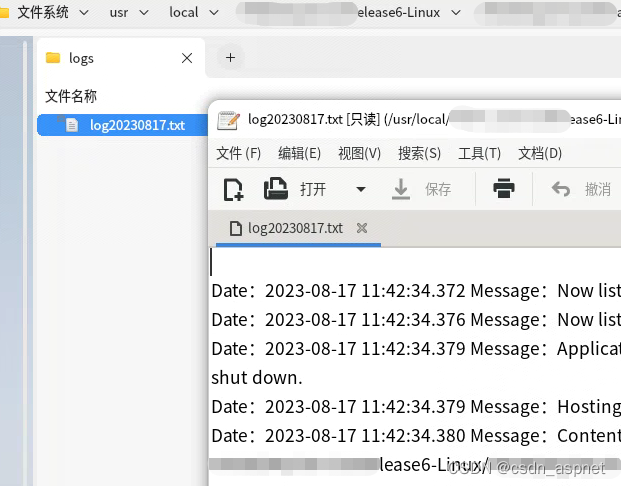
2、主要替换5个文件
Hadoop4个文件: yarn-site.xml、mapred-site.xml、hdfs-site.xml、core-site.xml
Hive1个文件: hive-site.xml
结果如下所示
(四)复制需要的jar包
1、从Hive安装路径的lib目录复制以hive开头的jar包,复制到hdp30\lib文件夹
文件路径:/opt/install/kettle9.2/data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations/hdp30/lib

2、复制Hadoop安装目录下的 hadoop-common-3.1.3.jar到hdp30\lib里
文件路径:/opt/install/kettle9.2/data-integration/plugins/pentaho-big-data-plugin/hadoop-configurations/hdp30/lib

3、把hive的安装路径hive312/jdbc里的驱动包复制到 kettle9.2的data-integration\lib文件下
(1)hive312/jdbc里的驱动包文件路径
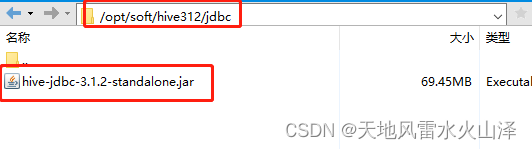
(2)目标文件路径:/opt/install/kettle9.2/data-integration/lib

(五)启动Hadoop和Hive服务,打开kettle9.2,连接Hive数据库

kettle9.2连接hive312,连接成功!
(六)执行从Hive到ClickHouse的kettle任务,测试一下

kettle任务运行成功!
(七)注意Hive数据库的中文乱码问题
解决方法:kettle9.2在配置Hive数据库时在高级模块添加set names utf8; 配置好后测试一下

到这里,Linux上安装的Kettle9.2.0连接Hive3.1.2数据库就结束了!
乐于奉献共享,帮助你我他!!!

![linux鲁班猫代码初尝试[编译镜像][修改根文件系统重编译][修改设备树改屏幕为MIPI][修改屏幕和TP方向]](https://img-blog.csdnimg.cn/625fa74898f84a52b8366e8cd4e00f6b.png)