文章目录
- 前言
- 1. Common Join
- 2. Map Join
- 介绍:
- 使用方法:
- 限制:
- 3. Bucket Map Join
- 介绍:
- 好处:
- 使用条件:
- 使用方法:
- 4. Sort Merge Bucket Map Join
- 介绍:
- 如何使用:
- 5. Skew Join
- 介绍:
- 如何使用:
- 如何处理倾斜:
- 6. Left Semi Join
- 7. common join 的内部join
- 准备数据
- CUSTOMERS 数据
- 建表
- orders 表
- 建表
- 1. 内连接(Inner join)
- 2. 左外连接(Left Outer Join)
- 3. 右外连接(RIGHT OUTER JOIN)
- 4. 全外连接(FULL OUTER JOIN)
- 5. 笛卡尔积(CROSS JOIN)
- 特殊点
前言
- common join 主要是针对数据/业务逻辑的join。
Map join,Bucket Map Join,SMB Map Join,Skew Join是hive 针对特殊数据、场景 进行的优化。Left Semi Join则是Sql语句的优化,并且也可以应用上面的优化方案。
1. Common Join
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成join.
整个过程包含Map、Shuffle、Reduce阶段。
- Map阶段
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
按照key进行排序
- Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
- Reduce阶段
根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
以下面的HQL为例,图解其过程:
SELECT
a.id,a.dept,b.age
FROM a join b
ON (a.id = b.id);
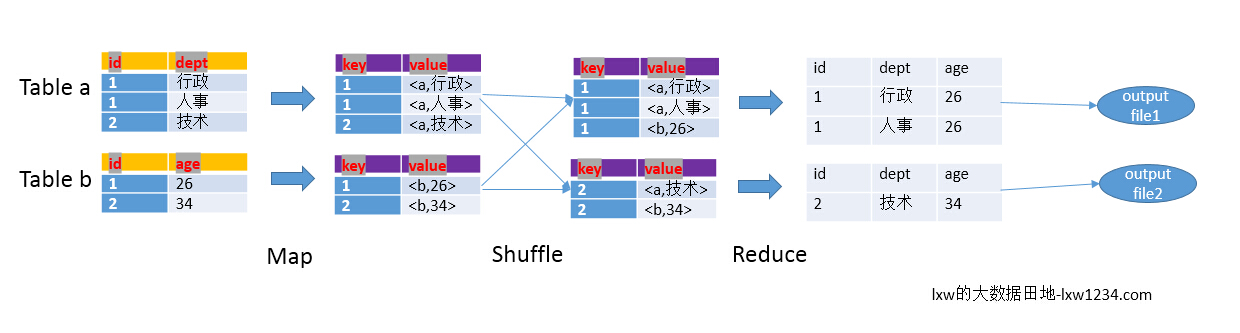
最为普通的join策略,不受数据量的大小影响,也可以叫做reduce side join ,最没效率的一种join 方式. 它由一个mapreduce job 完成.
首先将大表和小表分别进行map 操作, 在map shuffle 的阶段每一个map output key 变成了table_name_tag_prefix + join_column_value , 但是在进行partition 的时候它仍然只使用join_column_value 进行hash.
每一个reduce 接受所有的map 传过来的split , 在reducce 的shuffle 阶段,它将map output key 前面的table_name_tag_prefix 给舍弃掉进行比较. 因为reduce 的个数可以由小表的大小进行决定,所以对于每一个节点的reduce 一定可以将小表的split 放入内存变成hashtable. 然后将大表的每一条记录进行一条一条的比较.
2. Map Join
介绍:
MAP JION会把小表全部加载到内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配,由于在map端是进行了join操作,省去了reduce运行的时间,算是hive中的一种优化。
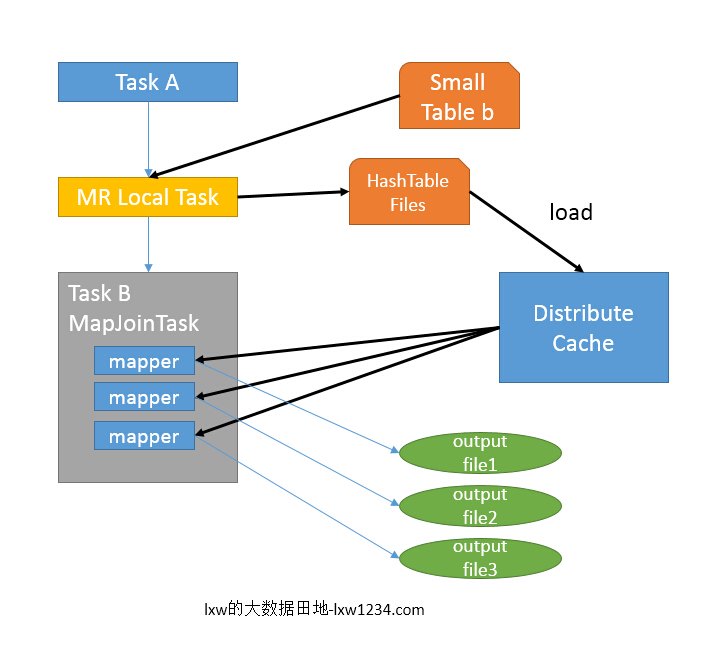
如上图中的流程,首先Task A在客户端本地执行,负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到DistributeCache中。
接下来的Task B任务是一个没有Reduce的MapReduce,启动MapTasks扫描大表a,在Map阶段,根据a的每一条记录去和DistributeCache中b表对应的HashTable关联,并直接输出结果,因为没有Reduce,所以有多少个Map Task,就有多少个结果文件。
使用方法:
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a JOIN b ON a.key = b.key;
前提b表是一张小表,具体小表有多小,由参数hive.mapjoin.smalltable.filesize来决定,默认值是25M。开启hive.auto.convert.join=true参数时,默认值是false,满足条件的话Hive在执行时候会自动转化为MapJoin,或使用hint提示 /*+ mapjoin(table) */执行MapJoin。
具体参数:
1、小表自动选择Mapjoin
set hive.auto.convert.join=true;
默认值:false。该参数为true时,Hive自动对左边的表统计量,若是小表就加入内存,即对小表使用Map join
2、小表阀值
set hive.mapjoin.smalltable.filesize=25000000;
默认值:25M
hive.smalltable.filesize (replaced by hive.mapjoin.smalltable.filesize in Hive 0.8.1)
限制:
- 不支持以下内容。
unoin后跟一个MapJoinLateral View后跟MapJoinReduce Sink(Group By/Join/Sort By/Cluster By/Distribute By)后跟MapJoin`MapJoin``,然后是``UnionMapJoin`` 后跟JoinMapJoin其次是MapJoin
3. Bucket Map Join
介绍:
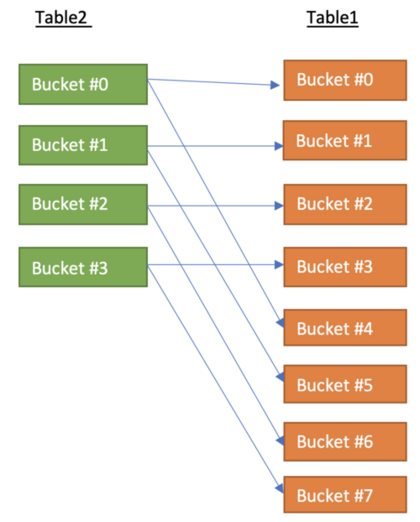
Bucket Map Join 也属于是一个 map join。 是hive join的一个优化方案。主要是针对分桶表的优化。
在common join中,如果表很大,MapReduce 中的Reducer端就会负载过大。 因为从join键和值接收所有数据,并且随着更多数据shuffle,性能也会下降。 因此,当我们join在分桶列上分桶和连接的表时,我们可以使用 Hive Bucket Map Join 功能。
好处:
在分桶表中,数据是以桶的形式组织的。每个存储桶都根据存储桶键/列保存/包含某些行。因此这意味着当我们join时仅获取所需的存储桶,而不是在完整的表上获取。
只有匹配的小表桶才会复制到每个mapper上。
使用条件:
- 当我们
join的两个表的join key是bucket column的时候,就可以使用。 - 一个表中的存储桶数应是另一个表中的存储桶数的倍数。
假设如果一个表有 2 个存储桶,那么另一个表必须有 2 个存储桶或 2 个存储桶的倍数(2、4、6 等)。否则,将执行正常的内部 join。
- 开启
set hive.optimize.bucketmapjoin = true;配置。
使用方法:
假设有两个表,table1 和 table2,并且两个表的数据都使用emp_id作为分桶键,存储桶个数为 8 和 4 个。如果我们对这两张表的 emp_id 列执行join 操作,并且如果可以将两个表的 bucket1 发送到单个mapper,我们可以实现大量的优化。这完全是通过执行 Hive 作业中的Bucket Map Join完成的。
-- 创建 table1 表
hive> CREATE TABLE IF NOT EXISTS table1 (emp_id int, emp_name string, emp_city string, gender String) clustered by(emp_id) into 8 buckets row format delimited fields terminated BY ‘,’;
-- 创建 table2 表
hive> CREATE TABLE IF NOT EXISTS table2 (emp_id int, job_title string) clustered by(emp_id) into 4 buckets row format delimited fields terminated BY ‘,’;
-- 加载数据
hive> load data local inpath '/relativePath/data1.csv' into table table1;
-- 加载数据
hive> load data local inpath '/relativePath/data2.csv' into table table2;
-- 开启优化
hive> set hive.optimize.bucketmapjoin=true;
-- 查询
hive> SELECT /*+ MAPJOIN(table2) */ table1.emp_id, table1.emp_name, table2.job_title FROM table1 JOIN table2 ON table1.emp_id = table2.emp_id;
- table1 是张大表,table2 远小于 table1.
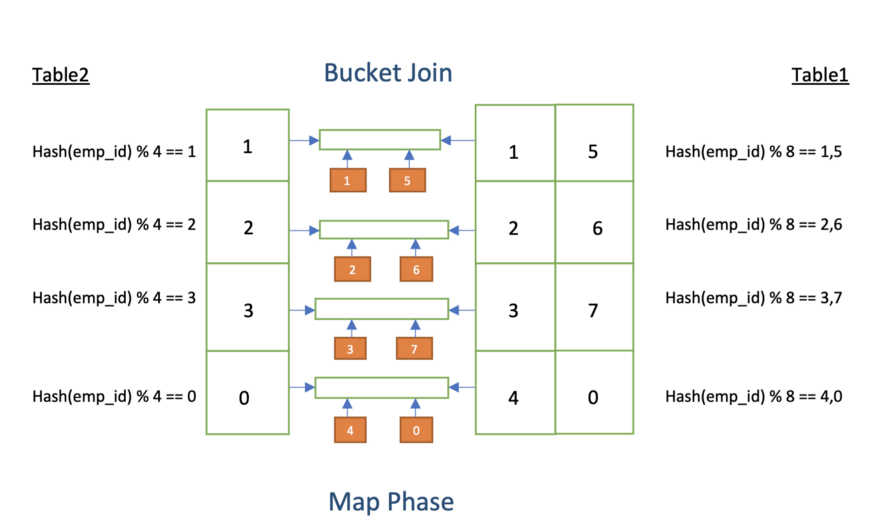
每个 Mapper 进程从 Table2(较大的表)中拆分的文件时,都会检索 Table1(较小的表)中唯一对应的存储桶来完成join任务。
4. Sort Merge Bucket Map Join
介绍:
Bucket Map Join 并没有解决 map join 在小表必须完全装载进内存的限制, 如果想要在一个reduce 节点的大表和小表都不用装载进内存,必须使两个表都在join key 上有序才行,你可以在建表的时候就指定 sorted by join key 或者使用index 的方式.
使用 SMB Map join 就要保证两张表都是已经sort 过的。
如何使用:
开启如下配置进行 SMB Map join:
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
有一个选项可以使用以下配置设置大表选择策略:
set hive.auto.convert.sortmerge.join.bigtable.selection.policy
= org.apache.hadoop.hive.ql.optimizer.TableSizeBasedBigTableSelectorForAutoSMJ;
默认情况下,选择策略为平均分区大小。与哈希和流式处理相比,大表选择策略有助于确定仅为流式处理选择哪个表。
可用的选择策略包括:
org.apache.hadoop.hive.ql.optimizer.AvgPartitionSizeBasedBigTableSelectorForAutoSMJ (default)
org.apache.hadoop.hive.ql.optimizer.LeftmostBigTableSelectorForAutoSMJ
org.apache.hadoop.hive.ql.optimizer.TableSizeBasedBigTableSelectorForAutoSMJ
5. Skew Join
介绍:
如何定义一张倾斜表:这张表的一个value 值于其他数据相比,其值在表中大量存在。
在 Hive 中,当表中一个或多个键的值明显多于其他键时,就会发生倾斜联接。这可能会导致性能问题,因为由于数据分布不均匀,联接操作会变慢得多。为了解决此问题,Hive 提供了几种可用于减少倾斜联接和提高查询性能的技术。
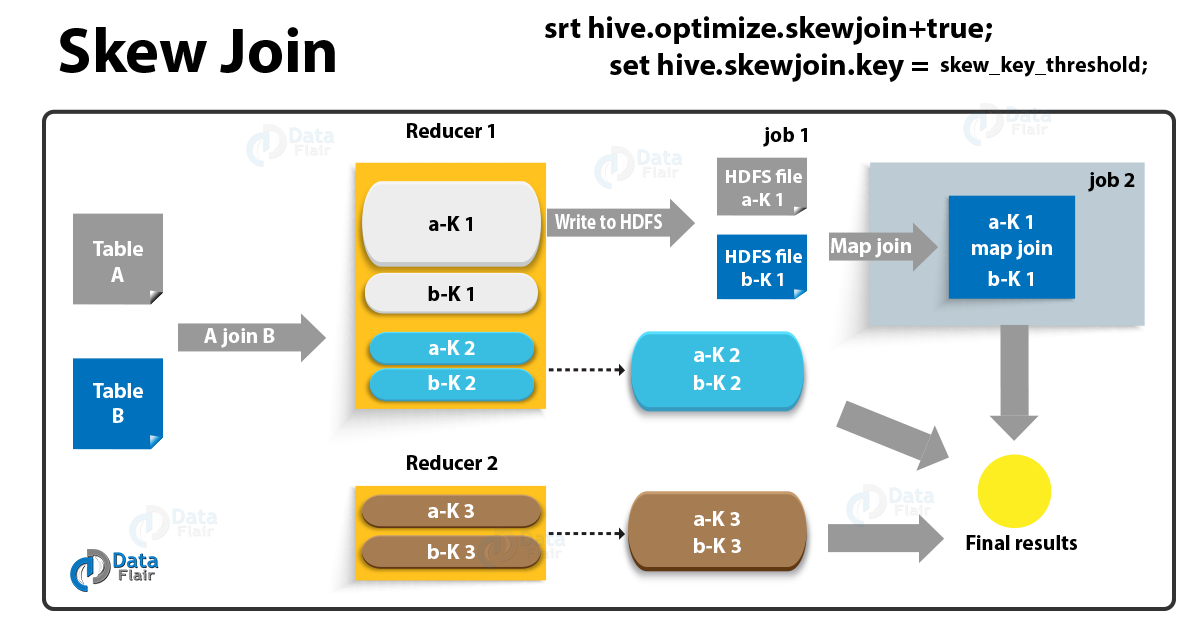
当我们join的列中有一个包含倾斜数据的表时,我们可以使用倾斜连接功能。
如何使用:
hadoop 中默认的 Reducer 处理的数据大小为:
hive.exec.reducers.bytes.per.reducer = 1000000000
也就是每个节点的reduce 默认是处理1G大小的数据,如果你的join 操作也产生了数据倾斜,那么你可以在hive 中设定
set hive.optimize.skewjoin = true;
set hive.skewjoin.key = skew_key_threshold (default = 100000)
如何处理倾斜:
在运行时,会对数据进行扫描并检测哪个key会出现倾斜,对于会倾斜的key,用map join做处理,不倾斜的key正常处理。
举个栗子:
表 A 和表 B join,并且在 ID 为12345 时发生了数据倾斜,假设在表 B 中倾斜的数据量比表 A 少,则把 B 中所有的倾斜了的数据拿出来,存到内存中(可以用一个哈希表来存)。
对于表 A ,如果是倾斜的数据,则通过 B 存放在内存中的哈希表来 join;如果不是倾斜的 key,则按正常的 reduce 端 join 流程进行。
这样就在map端完成了倾斜数据的处理,不会让某一个reducer中数据量爆炸,从而拖累处理速度。
要查看语句是否用到了 Skew Join,可以 explain 一下你的 SQL,如果在 Join Operator 和 Reduce Operator Tree 下的 handleSkewJoin 为 true,那就是用了Skew Join啦。
6. Left Semi Join
hive 中没有in/exist 这样的子句,所以需要将这种类型的子句转成left semi join. left semi join 是只传递表的join key给map 阶段 , 如果key 足够小还是执行map join, 如果不是则还是common join.
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b ON (a.key = b.key)
如果被连接的表都很小,则可以将join作为map join作业来执行。如:
SELECT /*+ MAPJOIN(b) */ a.key, a.value
FROM a JOIN b ON a.key = b.key
不需要Reducer。对于 A 的每个Mapper,B 被完全读取。限制是不能执行全/右外连接 b 表。
同样当我们的 join 的key 如果满足 map join, bucket Map join, SMB Map join 条件,只需要我们开启对应的配置,就可以自动进行优化。
7. common join 的内部join
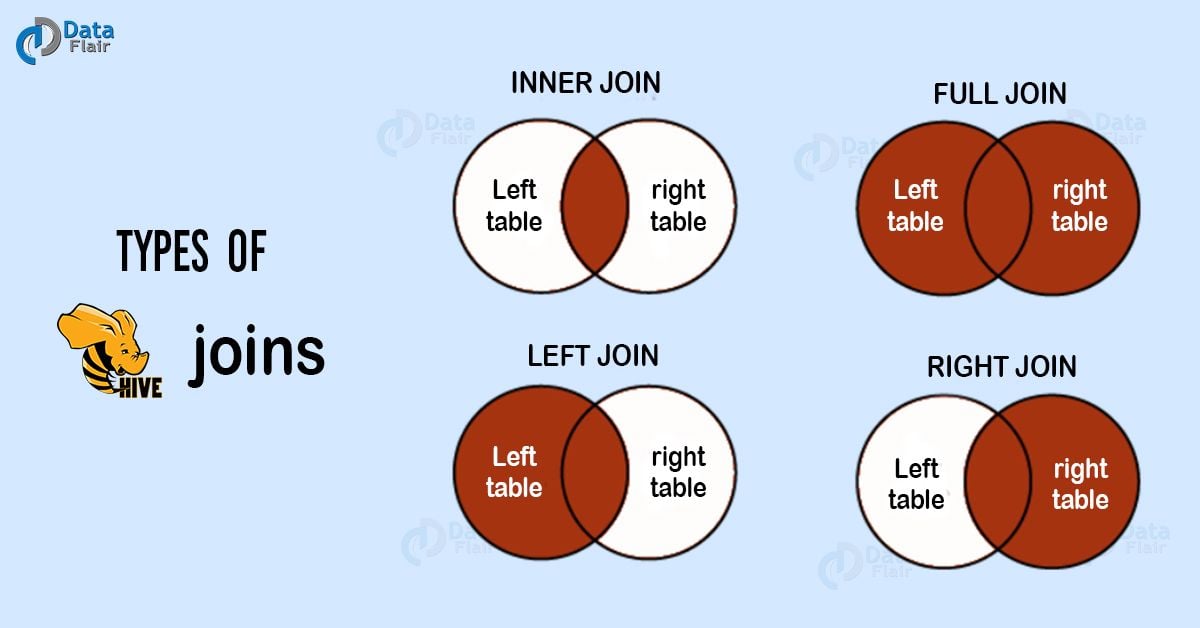
常见的 common join 有如下几种:
- Inner join
- Left Outer Join
- Right Outer Join
- Full Outer Join
- CROSS JOIN
准备数据
CUSTOMERS 数据
ID Name Age Address Salary
1 Ross 32 Ahmedabad 2000
2 Rachel 25 Delhi 1500
3 Chandler 23 Kota 2000
4 Monika 25 Mumbai 6500
5 Mike 27 Bhopal 8500
6 Phoebe 22 MP 4500
7 Joey 24 Indore 10000
建表
CREATE TABLE CUSTOMERS (
ID INT PRIMARY KEY,
Name VARCHAR(255),
Age INT,
Address VARCHAR(255),
Salary INT
);
-- 导入数据
INSERT INTO CUSTOMERS (ID, Name, Age, Address, Salary)
VALUES
(1, 'Ross', 32, 'Ahmedabad', 2000),
(2, 'Rachel', 25, 'Delhi', 1500),
(3, 'Chandler', 23, 'Kota', 2000),
(4, 'Monika', 25, 'Mumbai', 6500),
(5, 'Mike', 27, 'Bhopal', 8500),
(6, 'Phoebe', 22, 'MP', 4500),
(7, 'Joey', 24, 'Indore', 10000);
orders 表
OID Date Customer_ID Amount
102 2016-10-08 00:00:00 3 3000
100 2016-10-08 00:00:00 3 1500
101 2016-11-20 00:00:00 2 1560
103 2015-05-20 00:00:00 4 2060
建表
-- 创建表
CREATE TABLE ORDERS (
OID INT PRIMARY KEY,
Date DATETIME,
Customer_ID INT,
Amount INT
);
-- 插入数据
INSERT INTO ORDERS (OID, Date, Customer_ID, Amount)
VALUES
(102, '2016-10-08 00:00:00', 3, 3000),
(100, '2016-10-08 00:00:00', 3, 1500),
(101, '2016-11-20 00:00:00', 2, 1560),
(103, '2015-05-20 00:00:00', 4, 2060);
1. 内连接(Inner join)
内连接返回两个表中满足连接条件的行,丢弃不匹配的行
查询语句:
SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
FROM CUSTOMERS c JOIN ORDERS o
ON (c.ID = o.CUSTOMER_ID);
结果如下:
+----+----------+------+--------+
| ID | NAME | AGE | AMOUNT |
+----+----------+------+--------+
| 3 | Chandler | 23 | 1500 |
| 2 | Rachel | 25 | 1560 |
| 3 | Chandler | 23 | 3000 |
| 4 | Monika | 25 | 2060 |
+----+----------+------+--------+
2. 左外连接(Left Outer Join)
左外连接返回左表中所有行,以及满足连接条件的右表中的匹配行。如果右表中没有匹配行,则右表的结果为 NULL
查询语句:
SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
FROM CUSTOMERS c
LEFT OUTER JOIN ORDERS o
ON (c.ID = o.CUSTOMER_ID);
结果如下:
+----+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+----+----------+--------+---------------------+
| 3 | Chandler | 1500 | 2016-10-08 00:00:00 |
| 2 | Rachel | 1560 | 2016-11-20 00:00:00 |
| 3 | Chandler | 3000 | 2016-10-08 00:00:00 |
| 4 | Monika | 2060 | 2015-05-20 00:00:00 |
| 1 | Ross | NULL | NULL |
| 5 | Mike | NULL | NULL |
| 6 | Phoebe | NULL | NULL |
| 7 | Joey | NULL | NULL |
+----+----------+--------+---------------------+
3. 右外连接(RIGHT OUTER JOIN)
右外连接与左外连接类似,但是返回右表中所有行,以及满足连接条件的左表中的匹配行。如果左表中没有匹配行,则左表的结果为 NULL。
查询语句:
SELECT c.ID, c.NAME, o.AMOUNT, o.DATE FROM CUSTOMERS c RIGHT OUTER JOIN ORDERS o ON (c.ID = o.CUSTOMER_ID);
结果如下:
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 3 | Chandler | 1500 | 2016-10-08 00:00:00 |
| 2 | Rachel | 1560 | 2016-11-20 00:00:00 |
| 3 | Chandler | 3000 | 2016-10-08 00:00:00 |
| 4 | Monika | 2060 | 2015-05-20 00:00:00 |
+------+----------+--------+---------------------+
4. 全外连接(FULL OUTER JOIN)
全外连接返回左表和右表中所有行,同时在任何一方没有匹配行的地方填充 NULL。
查询语句:
SELECT c.ID, c.NAME, o.AMOUNT, o.DATE
FROM CUSTOMERS c
FULL OUTER JOIN ORDERS o
ON (c.ID = o.CUSTOMER_ID);
结果如下:
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 1 | Ross | NULL | NULL |
| 2 | Rachel | 1560 | 2016-11-20 00:00:00 |
| 3 | Chandler | 1500 | 2016-10-08 00:00:00 |
| 3 | Chandler | 3000 | 2016-10-08 00:00:00 |
| 4 | Monika | 2060 | 2015-05-20 00:00:00 |
| 5 | Mike | NULL | NULL |
| 6 | Phoebe | NULL | NULL |
| 7 | Joey | NULL | NULL |
+------+----------+--------+---------------------+
5. 笛卡尔积(CROSS JOIN)
这个查询会返回 “employees” 表中的每一行与 “ORDERS” 表中的每一行的组合,从而产生两个表的笛卡尔积。
请注意,笛卡尔积可能会产生非常大的结果集,因此在使用 CROSS JOIN 时需要谨慎。在实际使用中,应确保只在需要时使用笛卡尔积操作,以避免性能问题。
查询语句:
SELECT c.*, o.*
FROM CUSTOMERS c
CROSS JOIN ORDERS o;
c.ID | c.Name | c.Age | c.Address | c.Salary | o.OID | o.Date | o.Customer_ID | o.Amount
-----|---------|-------|-------------|----------|-------|---------------------|--------------|----------
1 | Ross | 32 | Ahmedabad | 2000.00 | 102 | 2016-10-08 00:00:00 | 3 | 3000
1 | Ross | 32 | Ahmedabad | 2000.00 | 100 | 2016-10-08 00:00:00 | 3 | 1500
1 | Ross | 32 | Ahmedabad | 2000.00 | 101 | 2016-11-20 00:00:00 | 2 | 1560
1 | Ross | 32 | Ahmedabad | 2000.00 | 103 | 2015-05-20 00:00:00 | 4 | 2060
... ... ... ... ... ... ... ... ...
特殊点
对于inner join 左表和右表 当有非等值过滤条件时,可以按照过滤条件进行过滤。
-
左表有过滤条件,只过滤左表,右表不过滤
-
右表有过滤条件,只过滤右表,左表不过滤
-
左右表有过滤条件,同时过滤
案例如下:
explain dependency select * from student_part a inner join student_part_parquet b
on a.s_name = b.s_name and a.s_age <23;

左4 右7
explain dependency select * from student_part a inner join student_part_parquet b
on a.s_name = b.s_name and b.s_age <23;

左7 右4
explain dependency select * from student_part a inner join student_part_parquet b
on a.s_name = b.s_name and b.s_age <23 and a.s_age >24;

左2 右3
对于 left join
-
只过滤左表 左表无过滤 右表有过滤
-
只过滤右表 左表无过滤 右表有过滤
-
同时过滤左右表 左表无过滤 右表有过滤
只过滤左表 —结果 左7 右 7 无过滤
explain dependency select * from student_part a left outer join student_part_parquet b
on a.s_name = b.s_name and a.s_age <23;

只过滤右表 —结果 左7 右 3 左表无过滤,右表有过滤
explain dependency select * from student_part a left outer join student_part_parquet b
on a.s_name = b.s_name and b.s_age <23;

同时过滤左右表 —结果 左7 右 3 左表无过滤,右表有过滤
explain dependency select * from student_part a left outer join student_part_parquet b
on a.s_name = b.s_name and b.s_age <23 and a.s_age >25;

所以建议尽早在子查询中,提前过滤数据。