opencv 中 K 近邻模块的基本使用说明及示例
在 OpenCV 中,不需要自己编写复杂的函数实现 K 近邻算法,直接调用其自带的模块函数即可。本节通过一个简单的例子介绍如何使用 OpenCV 自带的 K 近邻模块。
本例中有两组位于不同位置的用于训练的数据集,如图 20-14 所示。两组数据集中,一组位于左下角;另一组位于右上角。随机生成一个数值,用 OpenCV 中的 K 近邻模块判断该随机数属于哪一个分组。
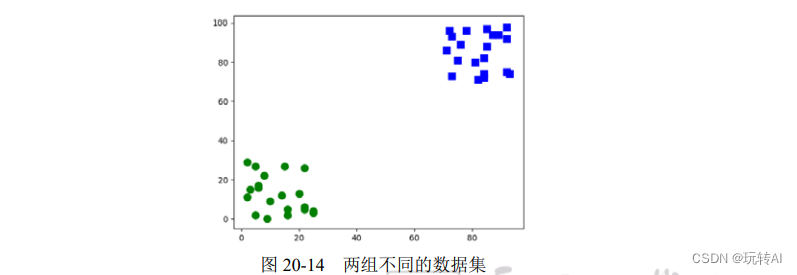
上述两组数据中,位于左下角的一组数据,其 x、y 坐标值都在(0, 30)范围内。位于右上角的数据,其 x、y 坐标值都在(70, 100)范围内。
根据上述分析,创建两组数据,每组包含 20 对随机数(20 个随机数据点):
rand1 = np.random.randint(0, 30, (20, 2)).astype(np.float32)
rand2 = np.random.randint(70, 100, (20, 2)).astype(np.float32)
- 第 1 组随机数 rand1 中,其 x、y 坐标值均位于(0, 30)区间内。
- 第 2 组随机数 rand2 中,其 x、y 坐标值均位于(70, 100)区间内。
接下来,为两组随机数分配标签: - 将第 1 组随机数对划分为类型 0,标签为 0。
- 将第 2 组随机数对划分为类型 1,标签为 1。
然后,生成一对值在(0, 100)内的随机数对:
test = np.random.randint(0, 100, (1, 2)).astype(np.float32)
示例:使用 OpenCV 自带的 K 近邻模块判断生成的随机数对 test 是属于 rand1 所在的类型0,还是属于 rand2 所在的类型 1。
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 用于训练的数据
# rand1 数据位于(0,30)
rand1 = np.random.randint(0, 30, (20, 2)).astype(np.float32)
# rand2 数据位于(70,100)
rand2 = np.random.randint(70, 100, (20, 2)).astype(np.float32)
# 将 rand1 和 rand2 拼接为训练数据
trainData = np.vstack((rand1, rand2))
# 数据标签,共两类:0 和 1
# r1Label 对应着 rand1 的标签,为类型 0
r1Label=np.zeros((20,1)).astype(np.float32)
# r2Label 对应着 rand2 的标签,为类型 1
r2Label=np.ones((20,1)).astype(np.float32)
tdLable = np.vstack((r1Label, r2Label))
# 使用绿色标注类型 0
g = trainData[tdLable.ravel() == 0]
plt.scatter(g[:,0], g[:,1], 80, 'g', 'o')
# 使用蓝色标注类型 1
b = trainData[tdLable.ravel() == 1]
plt.scatter(b[:,0], b[:,1], 80, 'b', 's')
# plt.show()
# test 为用于测试的随机数,该数在 0 到 100 之间
test = np.random.randint(0, 100, (1, 2)).astype(np.float32)
plt.scatter(test[:,0], test[:,1], 80, 'r', '*')
# 调用 OpenCV 内的 K 近邻模块,并进行训练
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, tdLable)
# 使用 K 近邻算法分类
ret, results, neighbours, dist = knn.findNearest(test, 5)
# 显示处理结果
print("当前随机数可以判定为类型:", results)
print("距离当前点最近的 5 个邻居是:", neighbours)
print("5 个最近邻居的距离: ", dist)
# 可以观察一下显示,对比上述输出
plt.show()
运行结果:
当前随机数可以判定为类型: [[1.]]
距离当前点最近的 5 个邻居是: [[1. 1. 1. 1. 1.]]
5 个最近邻居的距离: [[ 5. 17. 113. 136. 178.]]
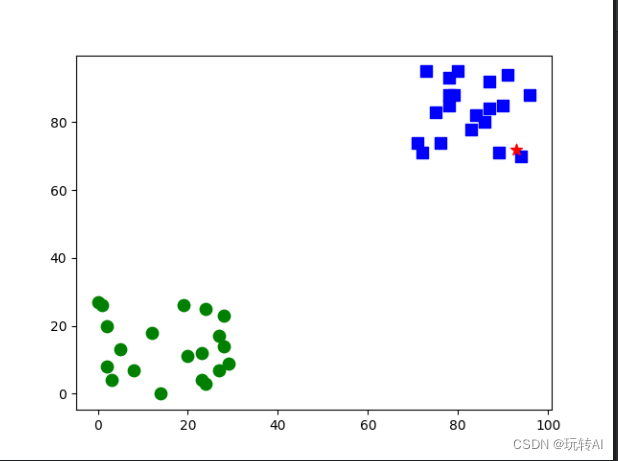
从图中可以看出,随机点(星号点)距离右侧小方块(类型为 1)的点更近,因此被判定为属于小方块的类型 1。
示例:使用 OpenCV 自带的函数完成对手写数字的识别
图片集在05 节中有下载地址
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取样本(特征)图像的值
s='image_number\\' # 图像所在的路径
num=100 # 共有的样本数量
row=240 # 特征图像的行数
col=240 # 特征图像的列数
a=np.zeros((num,row,col)) # 存储所有样本的数值
n=0 # 用来存储当前图像的编号
for i in range(0,10):
for j in range(1,11):
a[n,:,:]=cv2.imread(s+str(i)+'\\'+str(i)+'-'+str(j)+'.bmp',0)
n=n+1
# 提取样本图像的特征
feature=np.zeros((num,round(row/5),round(col/5))) # 用来存储所有样本的特征值
#print(feature.shape) # 看看特征值的形状是什么样子
#print(row) # 看看 row 的值,有多少个特征值(100)
# 从 0 开始,到 num-1 结束,每次加 1,
for ni in range(0,num):
for nr in range(0,row):
for nc in range(0,col):
if a[ni,nr,nc]==255:
feature[ni,int(nr/5),int(nc/5)]+=1
f = feature #简化变量名称
# 将 feature 处理为单行形式,并转换为 float32 类型,以便后面的 kNN 算法使用
train = feature[:,:].reshape(-1,round(row/5)*round(col/5)).astype(np.float32)
print(train.shape)
# 贴标签,要注意,是 range(0,100)而非 range(0,101)
train_labels = [int(i/10) for i in range(0,100)]
train_labels = np.asarray(train_labels)
test_labels = train_labels.copy()
#print(*trainLabels) # 打印测试看看标签值
##读取图像值,并提取特征,以便后面的 kNN 算法使用,这里只读取一个图像,即待识别图像,所以只有一个特征值,即 test
o=cv2.imread('image_number\\test\\5.bmp',0) # 读取待识别图像
of=np.zeros((round(row/5),round(col/5))) # 用来存储待识别图像的特征值
for nr in range(0,row):
for nc in range(0,col):
if o[nr,nc]==255:
of[int(nr/5),int(nc/5)]+=1
# 将 of 处理为单行形式,并转换为 float32 类型,以便后面的 kNN 算法使用
test=of.reshape(-1,round(row/5)*round(col/5)).astype(np.float32)
# 调用函数识别图像
knn=cv2.ml.KNearest_create()
knn.train(train,cv2.ml.ROW_SAMPLE, train_labels)
ret,result,neighbours,dist = knn.findNearest(test,k=5)
print("当前随机数可以判定结果是:", str(result[0][0]))
print("距离当前点最近的 5 个邻居是:", neighbours)
print("5 个最近邻居的距离: ", dist)
运行结果:
当前随机数可以判定结果是: 5.0
距离当前点最近的 5 个邻居是: [[5. 3. 5. 3. 5.]]
5 个最近邻居的距离: [[77185. 78375. 79073. 79948. 82151.]]
咂一看,哎呦!结果还挺准,然后再测试下其他的数字图片呢?
o=cv2.imread('image_number\\test\\6.bmp',0) # 读取待识别图像
再看下效果,
当前随机数可以判定结果是: 1.0
距离当前点最近的 5 个邻居是: [[6. 1. 1. 1. 1.]]
5 个最近邻居的距离: [[90739. 92107. 92312. 92652. 93016.]]
连续改了几个,发现识别准备度还是很低的。
示例:接下来我们借用MNIST数据集再次来验证下。
第一步:下载数据集,训练模型,保存模型到本地
代码如下:
import cv2
import numpy as np
from keras.datasets import mnist
if __name__ == '__main__':
# 直接使用Keras载入的训练数据(60000, 28, 28) (60000,)
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 变换数据的形状并归一化
train_images = train_images.reshape(train_images.shape[0], -1) # (60000, 784)
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape(test_images.shape[0], -1)
test_images = test_images.astype('float32') / 255
print(test_images)
# 将标签数据转为float32
train_labels = train_labels.astype(np.float32)
test_labels = test_labels.astype(np.float32)
# 传入knn的训练数据形状为(60000, 784) 训练标签为(60000,)
# 创建knn对象
knn = cv2.ml.KNearest_create()
# 设置k值 默认的k=10
knn.setDefaultK(5)
# 设置是分类还是回归
knn.setIsClassifier(True)
# 开始训练,训练数据的形状为(60000, 784) 训练标签为(60000,),训练数据必须是float32类型,标签必须是int32类型,并且标签必须是单通道,不能是多通道,否则会报错
knn.train(train_images, cv2.ml.ROW_SAMPLE, train_labels)
# 手写数字识别保存的knn模型非常大 有两百多兆
knn.save('mnist_knn.xml')
# 进行模型准确率的测试 结果是一个元组 第一个值为数据1的结果
test_pre = knn.predict(test_images)
test_ret = test_pre[1]
# 计算准确率
test_ret = test_ret.reshape(-1, )
test_sum = (test_ret == test_labels)
print(test_sum)
acc = test_sum.mean()
print(acc)
验证模型:
import cv2
import numpy as np
if __name__=='__main__':
#读取图片
img=cv2.imread('D:\\ai\\test\\6.png', 0) # 读取待识别图像
#重新设置图片大小
img=cv2.resize(img,(28,28))
cv2.imshow('img',img)
img_sw=img.copy()
#将数据类型由uint8转为float32
img=img.astype(np.float32)
#图片形状由(28,28)转为(784,)
img=img.reshape(-1,)
#增加一个维度变为(1,784)
img=img.reshape(1,-1)
#图片数据归一化
img=img/255
#载入knn模型
knn=cv2.ml.KNearest_load('mnist_knn.xml')
#进行预测
img_pre=knn.predict(img)
print('img_pre:',img_pre)
print(img_pre[0])
cv2.waitKey()
cv2.destroyAllWindows()
运行结果:
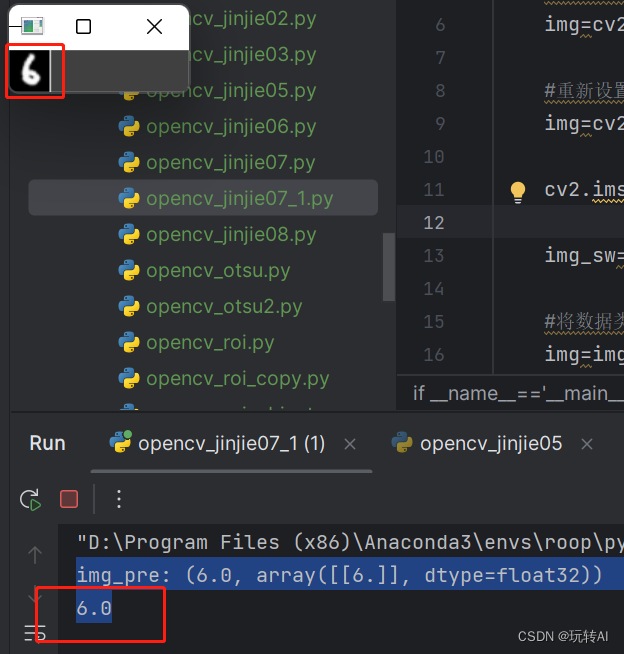
这里测试的图片是mnist 数据集中的,这个数据集下载的是压缩的,如要验证需要从下面的图片中去截图单独保存下来自己验证。总体准确率还是比较高的。**但是如果是自己随便画个数字再来验证 准备率就比较低了。**感兴趣的朋友可以自己多试试。
显示下面图片的代码
import cv2
import numpy as np
from keras.datasets import mnist
from matplotlib import pyplot as plt
# 加载数据
(train_dataset, train_labels), (test_dataset, test_labels) = mnist.load_data()
train_labels = np.array(train_labels, dtype=np.int32)
# 打印数据集形状
print(train_dataset.shape, test_dataset.shape)
# 图像预览
for i in range(40):
plt.subplot(4, 10, i+1)
plt.imshow(train_dataset[i], cmap='gray')
plt.title(train_labels[i], fontsize=10)
plt.axis('off')
plt.show()

缺点:模型文件大,识别速度慢