摘要
本文主要针对NLP任务中经典的Transformer模型的来源、用途、网络结构进行了详细描述,对后续NLP研究、注意力机制理解、大模型研究有一定帮助。
1. 引言
在上一篇《Text-to-SQL小白入门(一)》中,我们介绍了Text-to-SQL研究的定义、意义、研究方法以及未来展望,其中在介绍研究方法时,多次提到了Seq2Seq框架以及相应的Encoder-Decoder方法。而今天提到的模型Transformer,是人工智能领域,尤其是NLP领域和CV领域的杰出代表,也是目前最先进的模型之一!
在步入正式学习前,我们先对Seq2Seq方法、Encoder-Decoder方法、Transformer模型做一个简单的区分。
- Encoder-Decoder是一种架构,一种通用的模型结构,只要用到了编码器和解码器就可以称为Encoder-Decoder方法。
- Seq2Seq方法解决的是两个序列之间的映射问题,是Encoder-Decoder方法的一种特殊形式。主要类别有以下几种:
-
- 基于LSTM的Seq2Seq模型
- 基于CNN的Seq2Seq模型
- 基于RNN的Seq2Seq模型
- 基于Attention的Seq2Seq模型
- Transformer方法是基于自注意力机制self-attention的Seq2Seq模型。
2. Transformer是什么?
2.1. 来源
Transformer模型来源于2017年NIPS(CCF-A)谷歌团队发表的论文《Attention Is All You Need》。目前最火的大模型,比如BERT、GPT系列等都离不开Transformer模型。目前改论文的谷歌学术的被引用次数已经达到84986,如图1所示,这个数据已经可以载入史册了!

图1 论文Attention Is All You Need谷歌学术引用数
插个题外话,Transformer的作者谷歌8子,已经全部离职,arxiv上v6版本也删除了划掉了所有作者的谷歌邮箱,如图2所示。(今年8月初又重新更新了v7版本)

图2 论文Attention Is All You Need作者名单
2.2. 概述
Transformer也是【变形金刚】的英语,台大李宏毅老师也喜欢用变形金刚举例子)
Transformer是一种非常流行的神经网络结构,已经被用于多种自然语言处理任务的大规模预训练模型,如语言模型、机器翻译、文本摘要、问答系统等。
Transformer的主要优点是其并行计算能力,能够处理长文本,同时通过自我注意力机制可以有效地捕捉上下文信息。
3. Transformer有什么用?
在前面的概述中,已经简单介绍了Transformer可以在多个场景广泛应用,接下来举几个例子,更直观感受一下。
- 1 -> N:生成任务,比如输入为一张图片,输出图片的文本描述。
- N -> 1:分类任务,比如输入为一句话,输出这句话的情感分类。
- N -> N:序列标注任务,比如输入一句话,输出该句话的词性标注。
- N -> M:机器翻译任务,比如输入一句中文,输出英文翻译。
3.1. 序列关系为1 vs N
比如生成任务中,图片生成自动描述,就是序列关系1 vs N,如图3所示。
- 输入:长度为1,一张图片
- 输出:长度为N,图片的文本描述

图3 图像生成文本描述例子
3.2. 序列关系为N vs 1
比如分类任务中,序列关系为N vs 1,以文本情感分类sentimental analysis为例。
- 输入:长度为N,一段文本。比如教师评价本文中“今天老师上课非常有趣,我很喜欢”
- 输出:长度为1,文本的情感正/负面倾向,比如得到“正面positive”。
3.3. 序列关系为N vs N
比如有序列标注任务,比如文本词性标注syntactic parsing
- 输入:长度为N,一段文本。
- 输出:长度为N,这段文本每个单词的词性说明(比如最基础的是名词n,动词v,形容词adj等等,实际标注中,比如图4中deep是NP,名词短语;is是VP,动词短语;)
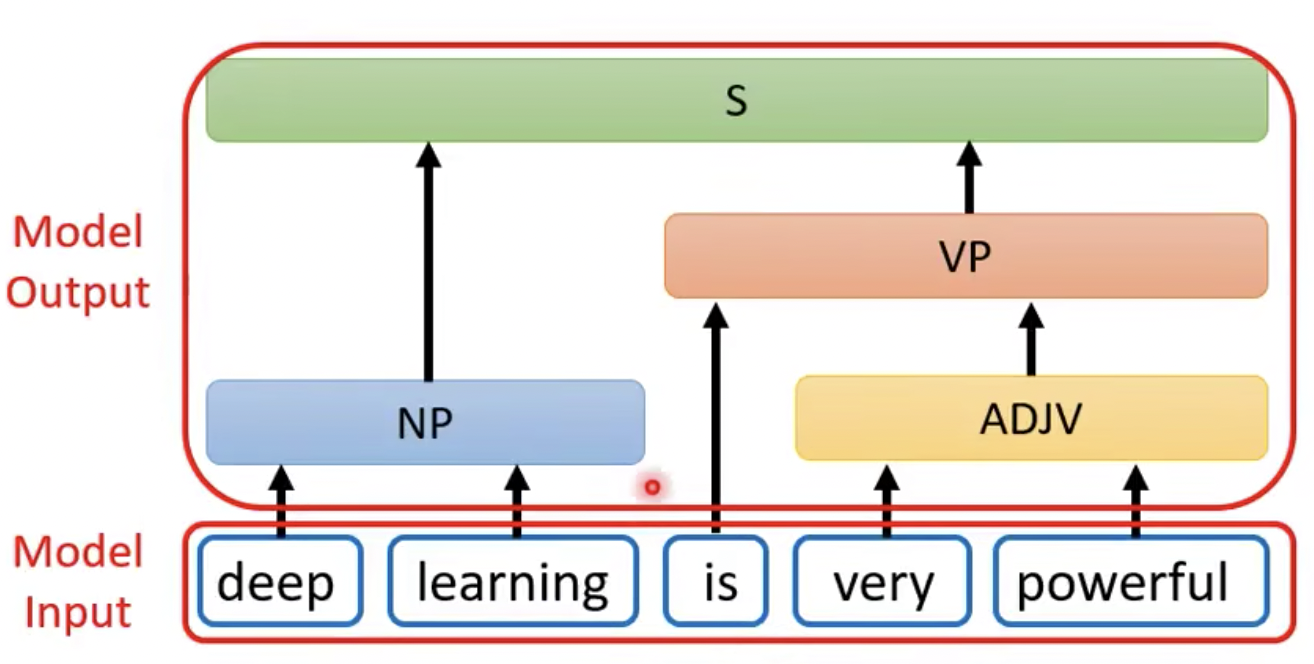
图4 文本词性标注例子
3.4. 序列关系为N vs M
语音识别Speech Recognition任务输入输出如图5所示:
- 输入序列:长度为N,一段语音序列
- 输出序列:长度为M,一段文字“你好吗”

图5 语音识别例子
机器翻译Machine Translation任务的输入输出如图6所示:
- 输入序列:长度为N,一段中文“机器学习”
- 输出序列:长度为M,一段翻译“machine learning”

图6 机器翻译例子
语音翻译Speech Translation任务的输入输出入图7所示:
- 输入序列:长度为N,一段语音“machine learning”
- 输出序列:长度为M,一段翻译“机器学习”
(这个任务也可以用语音识别+机器翻译结合来完成,但是有的语言没有文字,就很难办,但是Transformer模型直接从语音到文字翻译是可以胜任的)

图7 语言翻译例子
4. Transformer具体结构
话不多说,直接上Transformer结构“世界名画”,如图8所示,核心部分主要可以分为Embedding、Positional Encoding、Encoder、Decoder,接下来就分别介绍一下。

图8 transformer结构
4.1. 输入部分
在这里,我们把Input -> Input Embedding -> Positional Encoding 当作输入部分,这部分处理完后,会作为Encoder编码器的输入,如图9所示。
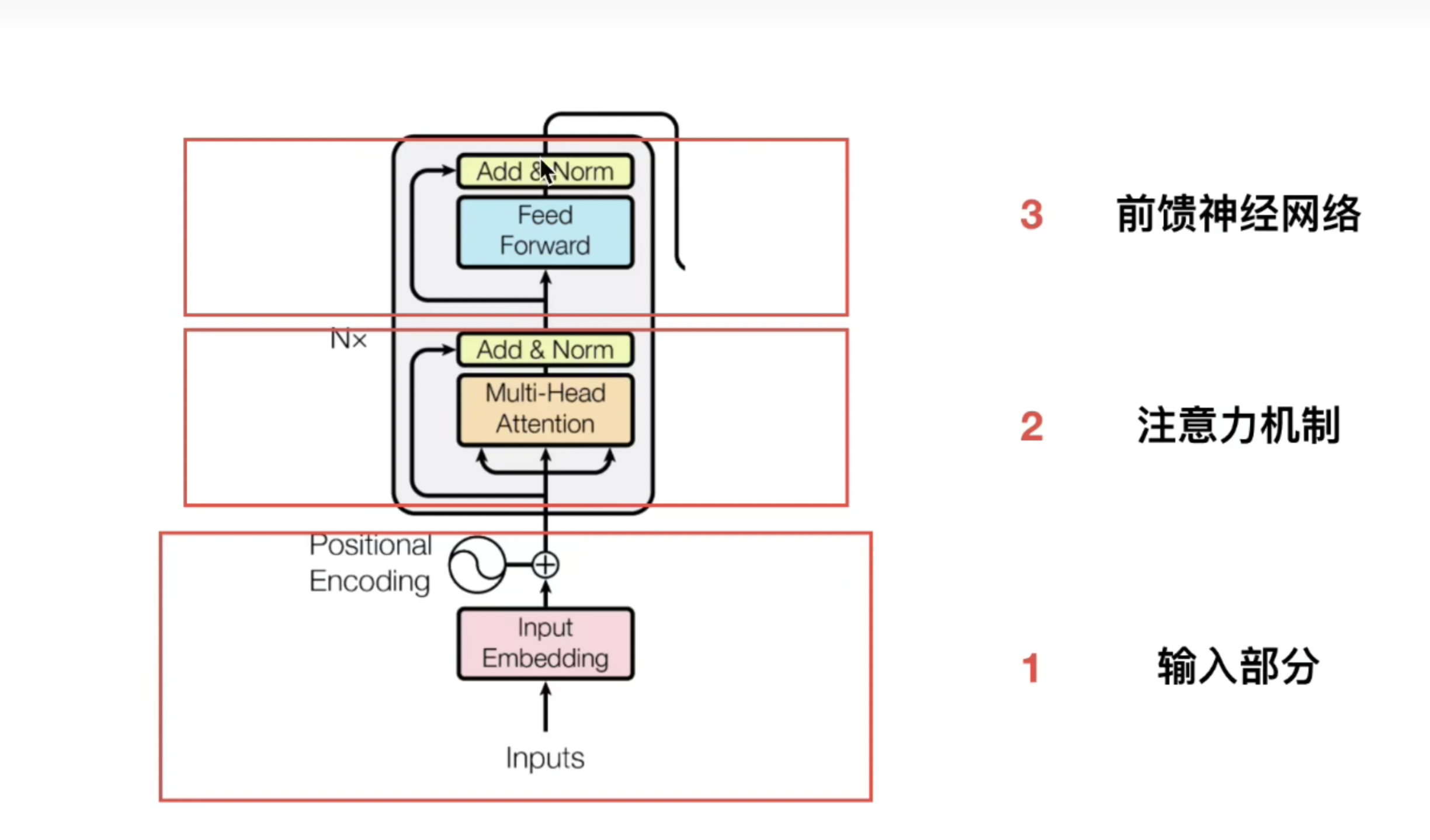
图9 Transformer结构中Encoder和输入部分
4.1.1. Input
在Transformer论文中,作者以机器翻译这个领域为切入点来介绍模型,所以该模型在论文里面的输入输出就对应前面提到的序列关系N vs M。
- 输入:一段文本:比如说“我爱你”
- 输出:一段英语翻译:比如说“I LOVE YOU”
4.1.2. Input Embedding
输入文本信息后,怎么才能让模型获取这个输入呢?所以需要对文本进行编码,让模型可以读取输入。模型读取的一般是向量,所以需要让文本转化为向量,这就是Input Embedding做的事情。
更学术一点的话语是,文本是一种非结构化的数据信息,是不可以直接被计算的。我们需要将这些非结构化的信息转化为结构化的信息,也就是这里的Input embedding。
常用的方法主要用one-hot编码(翻译为独热编码,看起来怪怪的)、整数编码、word embedding(词嵌入)。
4.1.2.1. one-hot
用通俗的话来解释就是:把每一个单词都用某个位为1,其余位全是0的二进制向量来表示,比如如图10所示。
- apple:只有第1位为1,其余都是0,[1 0 0 0 0 ...]
- bag:只有第2位为1,其余都是0,[0 1 0 0 0 ...]
- cat:只有第3位为1,其余都是0,[0 0 1 0 0 ...]
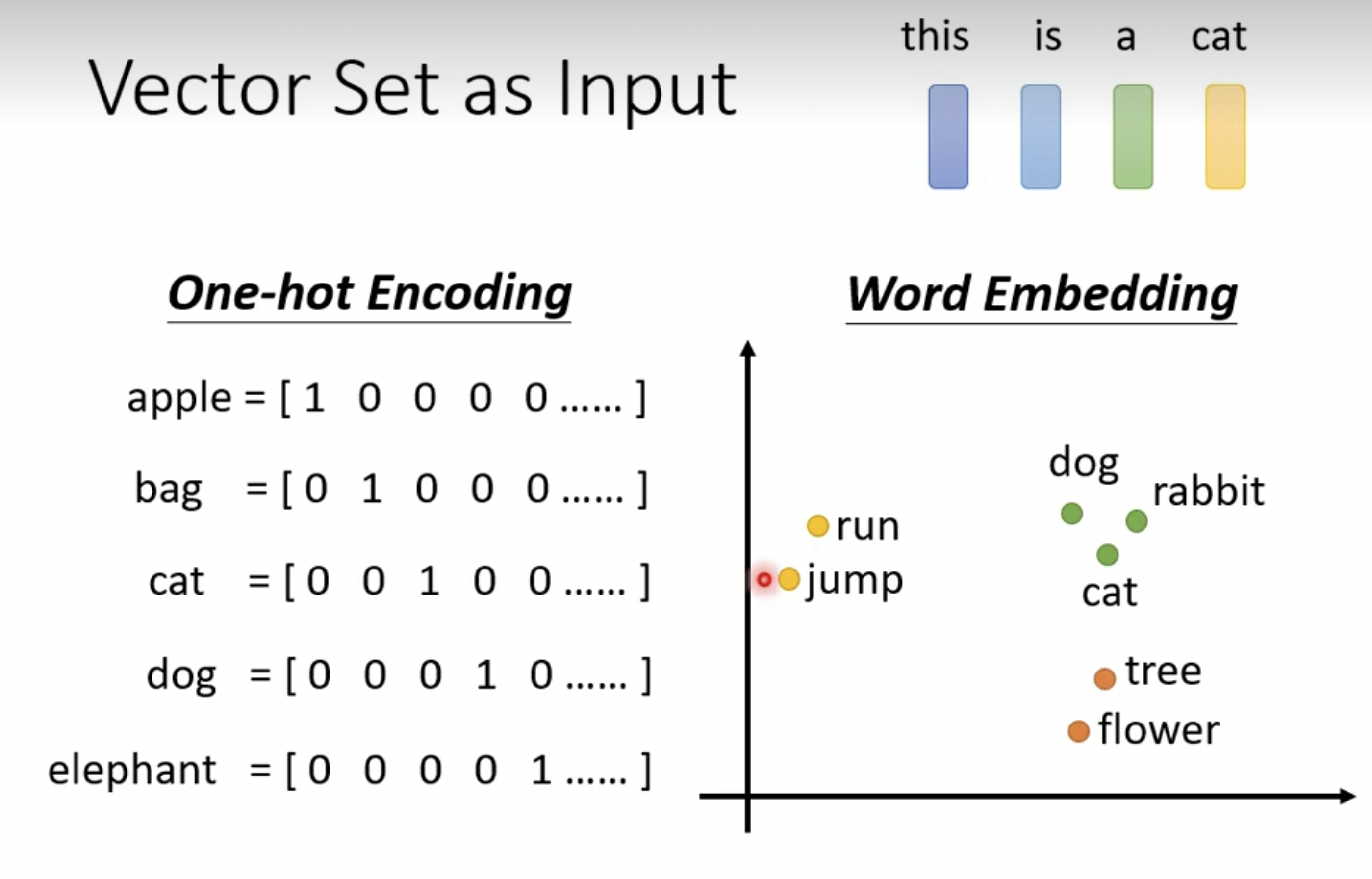
图10 one-hot 和 word embedding编码
one-hot编码优点:
- 存储非常方便
- 计算效率高
缺点也很明显,在实际情况中,文本中很可能出现成千上万个不同的词,这时候向量就会非常长。其中99%以上都是 0。
- 向量如果过于悉数,存储空间浪费严重
- 更重要的是,one-hot编码没有语义信息,无法看出两者单词之间的相似性。
4.1.2.2. 整数编码
通俗解释:把每一个单词都用1个整数来表示,跟one-hot有点类似。
- apple:用数字1表示
- bag:用数字2表示
- cat:用数字3表示
优点:
- 容易实现
- 适用于大量数据
缺点:
- 存储空间利用率低下
- 无法表达词语之间的关系
4.1.2.3. word embedding
前面铺垫了这么多,前面两种方式都无法表达语义关系,那么词嵌入方法就肯定可以了。
word embedding 是文本表示的一类方法。跟 one-hot 编码和整数编码的目的一样。同时词嵌入并不特指某个具体的算法,跟上面2种方式相比,这种方法有几个明显的优势:
- 语义相似的词在向量空间上也会比较相近,如上面的图10所示。
- 可以将文本通过一个低维向量来表达,不像 one-hot 那么长,比如图11中,把“我”编码为一个512维的向量;“你”也是一个512维的向量;“你”也是一个512维的向量。【论文中也是512维】
- 通用性很强,可以用在不同的任务中。
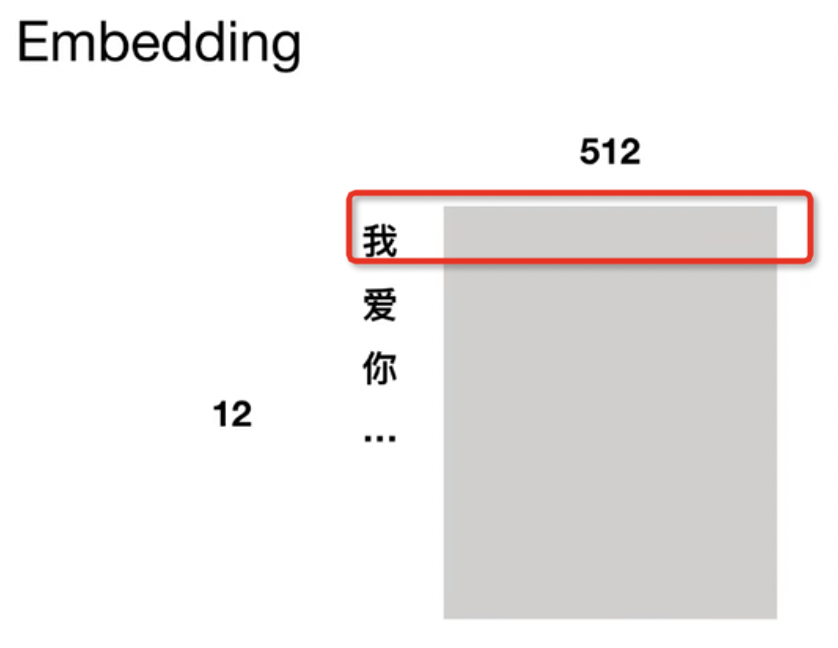
图11 word embedding 示例
word embedding主流的方法有word2vec 和 GloVe。
- word2vec:这是一种基于统计方法来获得词向量的方法。
- GloV: 是对 word2vec 方法的扩展,它将全局统计和 Word2vec 的基于上下文的学习结合了起来。
4.1.3. positional embedding
需要明白为什么有这个positional embedding的存在?
因为在transformer机构中,输入是并行处理的,这样计算效率更高了,但是忽略了文字的先后顺序的重要性。
论文中公式如图12所示,偶数(2i)位置用sin表示,奇数(2i+1)位置用cos表示。
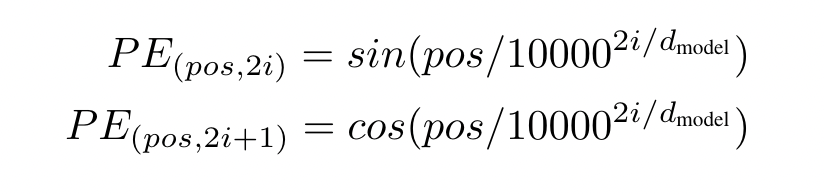
图12 位置编码公示
举个例子,比如“我爱你”中的“爱”这个字, 位置编码可以大概写成[sin,cos,sin,cos...,cos],对应总共512维情况,如图13所示。
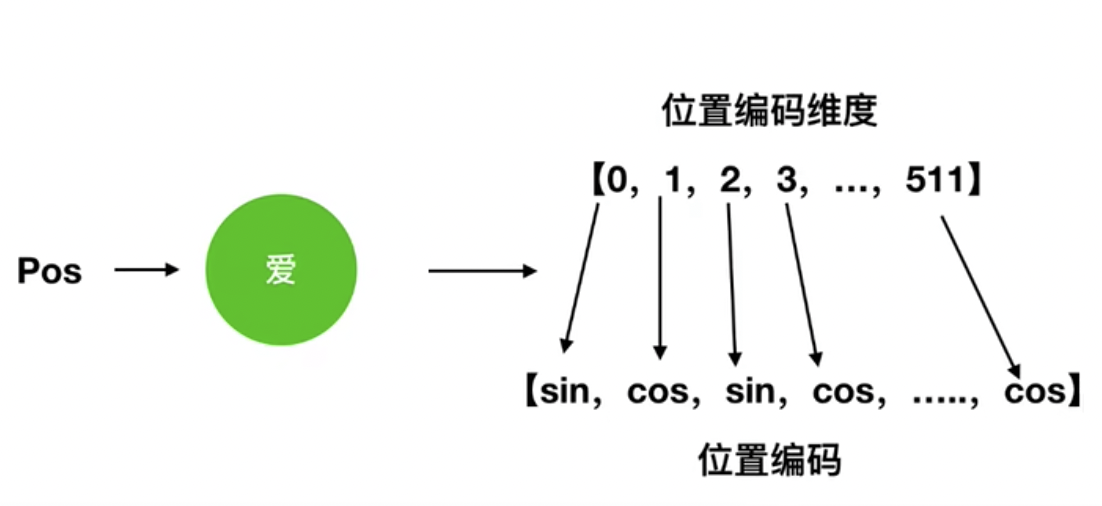
图 13 位置编码举例
把word embedding 和 positional embedding之后的输入加起来,作为编码器Encoder最终的输入,如图14所示。
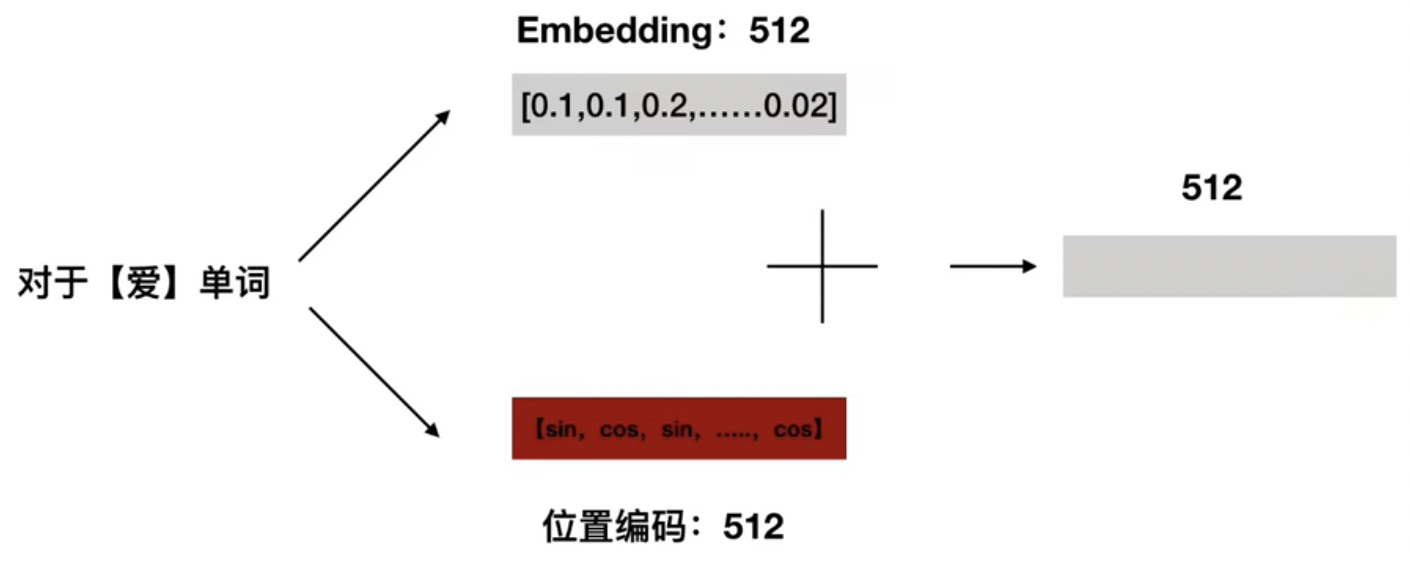
图14 输入编码后相加
这里有个拓展,就是为什么位置编码是有效的?参考图15
本质上还是数学:三角函数的性质+线性代数
更通俗的解释就是: 对于后续某一个位置比如pos+k位置,都可以被前面pos位置和k位置线性组合,这样就说明了相关位置信息

图15 推理位置编码有效
4.2. Encoder编码器
终于,终于,终于到了论文最核心的部分了
论文里面提到的是“We propose a new simple network architecture, the Transformer”,感觉一点也不simple啊
我们先明确一件事情,就是Encoder编码器做了一件什么事情?输入输出的边界是什么?简化版本如图16所示。
- 输入:一堆向量[x1,x2,x3,x4]
- 输出:一堆处理后的向量[h1,h2,h3,h4],长度保持一致。
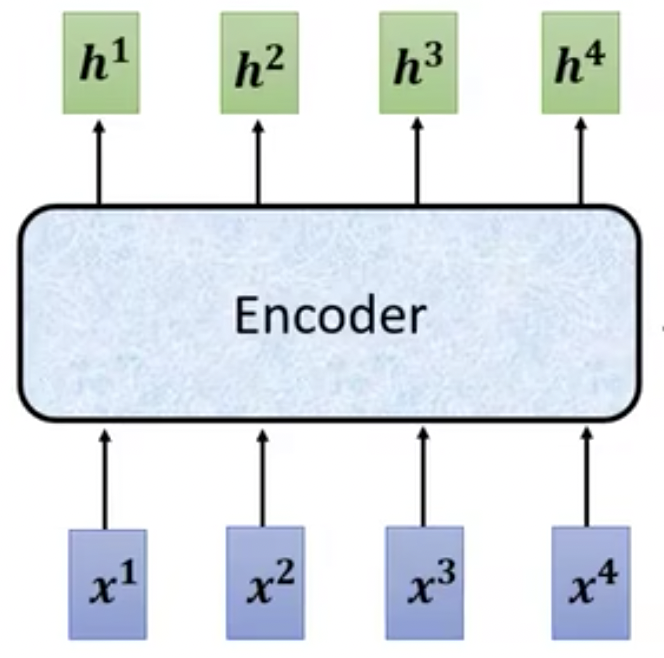
图16 Encoder编码器输入输出示意图
4.2.1. Attention Mechanism注意力机制
Transformer里面最核心的部分是基本注意力机制的,论文标题也直接是Attention is all you need,那么我们需要了解一下什么注意力机制?
注意力机制(Attention Mechanism)的研究最早受到了人类视觉系统研究的启发。由于人类视网膜不同部位的信息处理能力不同,人们会选择性关注所有信息中的部分信息,同时忽略掉其他信息。为了高效利用视觉信息,人类需要选择视觉区域中的某个部分重点关注,比如图17所示,颜色越深,代表越关注。
比如人们在用电脑观看视频时,会重点关注电脑屏幕上的内容,选择性忽略电脑背景和鼠标键盘等等。

图17 注意力机制可视化
在深度学习领域,注意力机制的本质在于模拟人类视觉效果,关注重要特征,丢弃用处不大的特征。注意力机制在许多任务上取得了巨大的成功,除了在自然语言处理NLP任务应用外,还在计算机视觉CV任务广泛应用(比如图像分类、目标检测、语义分割、视频理解、图像生成、三维视觉、多模态任务和自监督学习等)。
4.2.2. Self-Attention自我注意力机制
前面介绍了基本的注意力机制原理,那么回到论文中,Transformer中的注意力机制是什么样子的?
确实挺“简单”的,计算注意力权重就只有一个公式罢了,理解起来还是需要花点时间。
4.2.2.1. Attention注意力公式
要理解Transformer中的Multi-Head Attention(图18),需要先了解(单头)自注意力机制,也就是论文提到的注意力计算公式Attention(Q,K,V)。
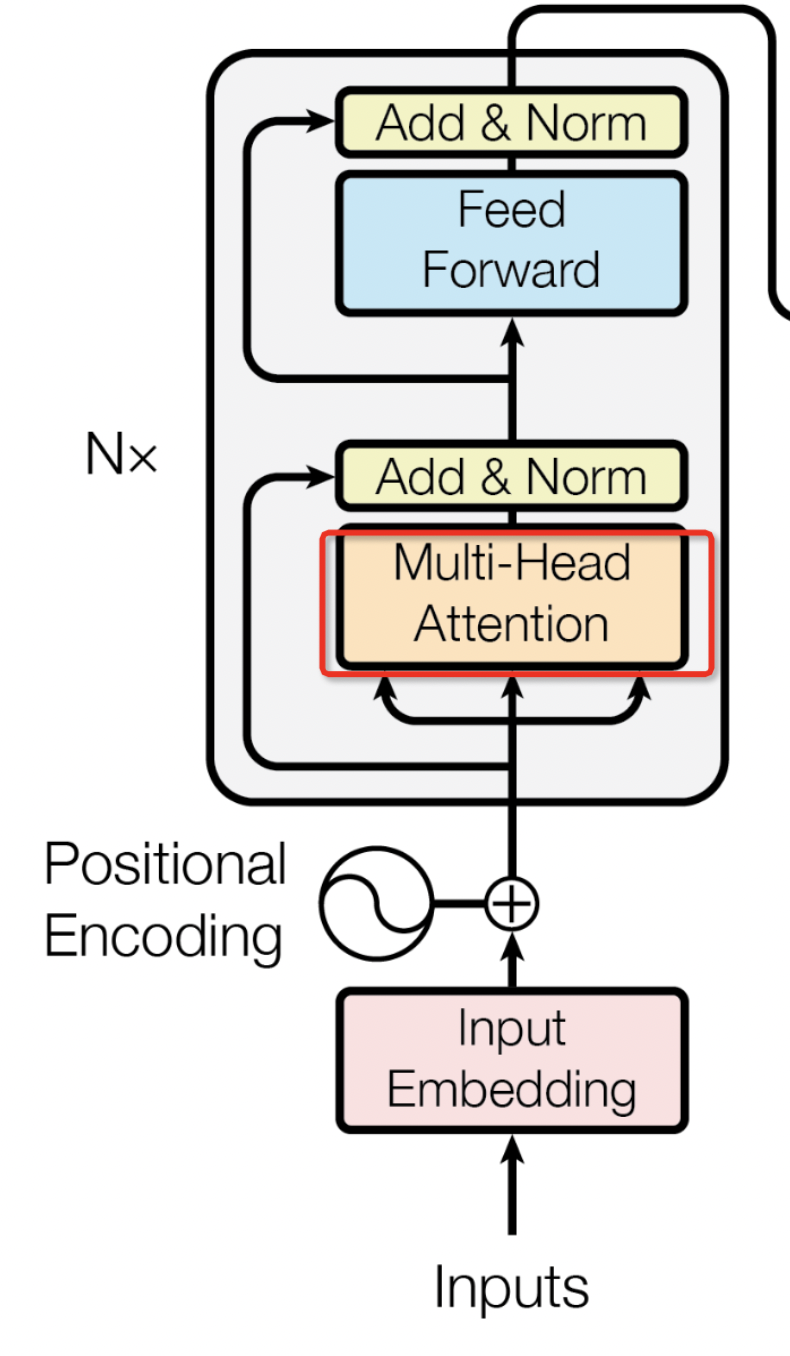
图18 Multi-Head Attention 示例
因为输入其实都只有1个,但是在Multi-Head Attention模块前其实有3个输入,代表Q、K、V,这三个向量都是来源于相同的输入编码,所以是自注意力机制。
4.2.2.2. Q,K,V
Q,K,V是什么?
我们需要知道Q,K,V代表的都是向量,比如Q是一系列[q1,q2,q3,....]集合,K是一系列[k1,k2,k3,...]集合,V是一系列[v1,v2,v3,...]集合。
- q代表的是query查询,后续会和每一个k进行匹配,找到最相似的k
- k代表的是key关键字,后续会被每一个q匹配
- v代表的是value值,代表从输入中提到到的信息
- 注意:每一个key,都对应一个value;计算query和key的匹配程度就是计算两者相关性,相关性越大,代表key对应value的权重也就越大,这就是不同信息的权重不一样,这就是注意力机制!
Q,K,V从哪里来?
Q,K,V是向量乘法得到的,如图19所示。
- 输入是文本“Thinking Machines”,2个单词
- 经过编码embedding后变为[x1,x2],2个向量
- 经过和一个共享的参数W^Q、W^K、W^V【这个参数是可训练的】相乘,就可以得到Q、K、V
- 在这里,Q就是[q1,q2];K就是[k1,k2];V就是[v1,v2]。
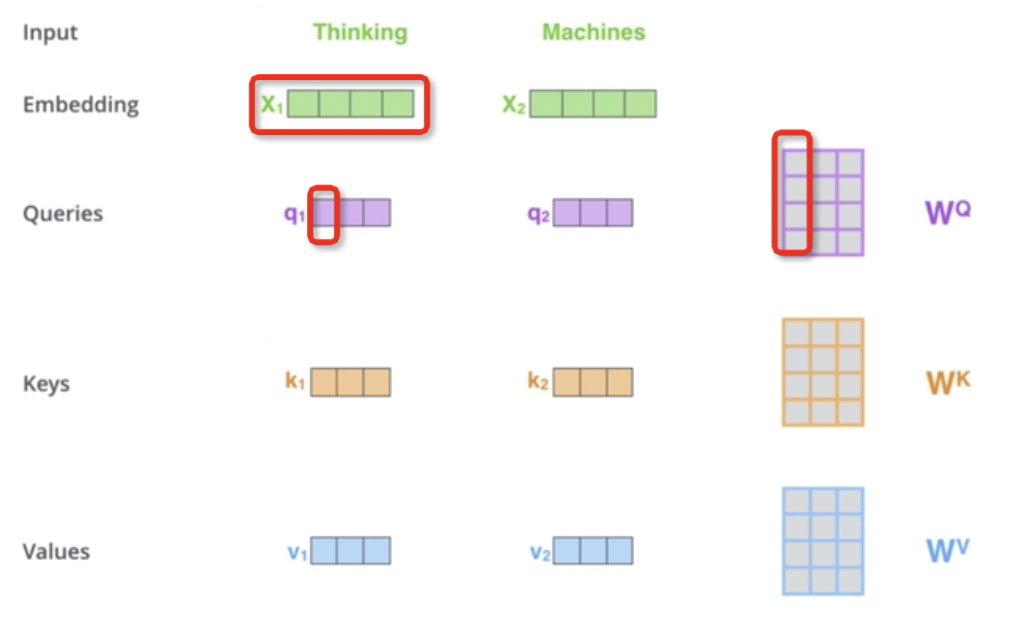
图19 Q、K、V来源
Q,K,V怎么用?
用法其实就是图20Attention计算公式,主要分为4步。
- 先使用点乘计算Q和K转置的相似性
- 然后再除以一个系数【这是进行点乘后的数值很大,导致通过softmax后梯度变的很小】
- 然后再经过一个softmax函数归一化,这样就得到了不同的注意力权重
- 最后再和信息value相乘
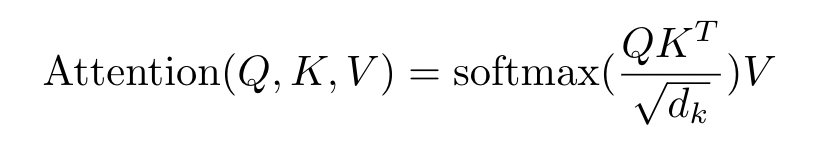
图20 Attention计算公式
可以举个例子,来说明一下各个参数的计算过程,如图21所示。假设输入仍然是两个单词,编码后得到[x1,x2],通过前面Q、K、V来源,我们得到了[q1,q2];[k1,k2];[v1,v2]
- 先使用点乘计算Q和K转置的相似性,图21里面q1和k1点乘【点乘结果为1,代表两者最相似;点乘结果为0,代表两者最不相似】,其实写k1转置会更合适,但是不影响理解意思。
-
- q1的大小是1✖️3
- k1转置的大小是3✖️1
- 相乘得到结果的大小1✖️1,比如就是图中的112,同理另外q2相乘得到96,所以得到结果[112 96]
- 然后再除以一个系数,假设这里系数为8,那么结果为[14 12]
- 最后再经过一个softmax函数归一化,得到结果[0.88 0.12],这里图片中写错了,应该是[0.54 0.46],这就是不同的信息权重,这就是注意力机制
- 最后再和信息value[v1,v2]相乘,得到最终的sum
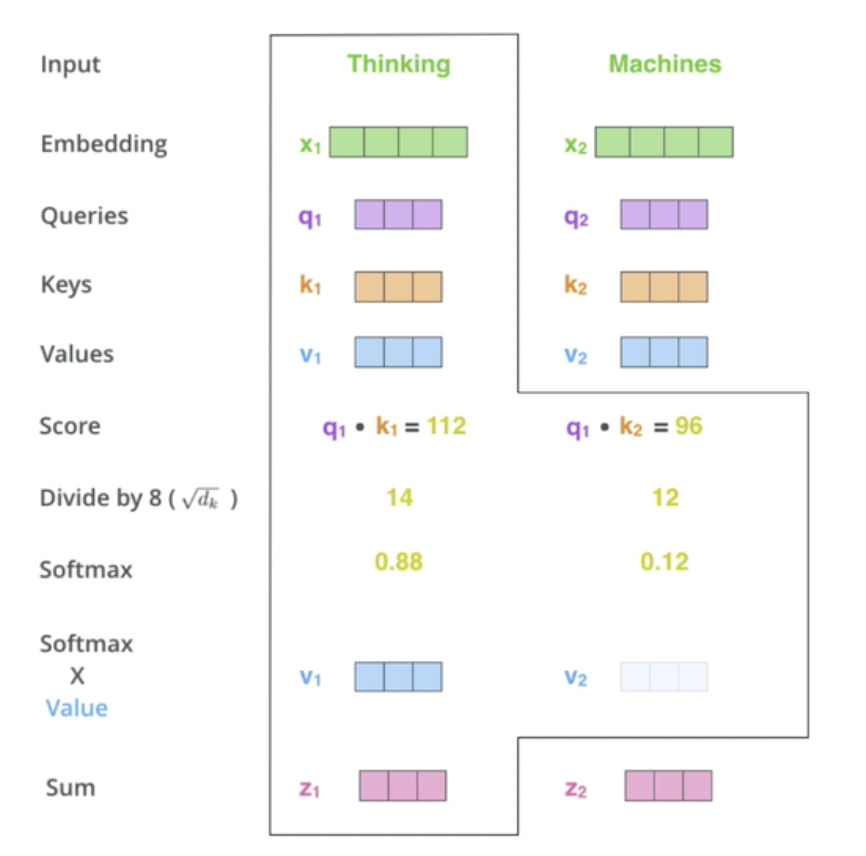
图21 Attention计算举例
在实际的计算过程中,用的都是矩阵乘法,所以是并行计算的,所以Transformer计算效率高,如图22所示。
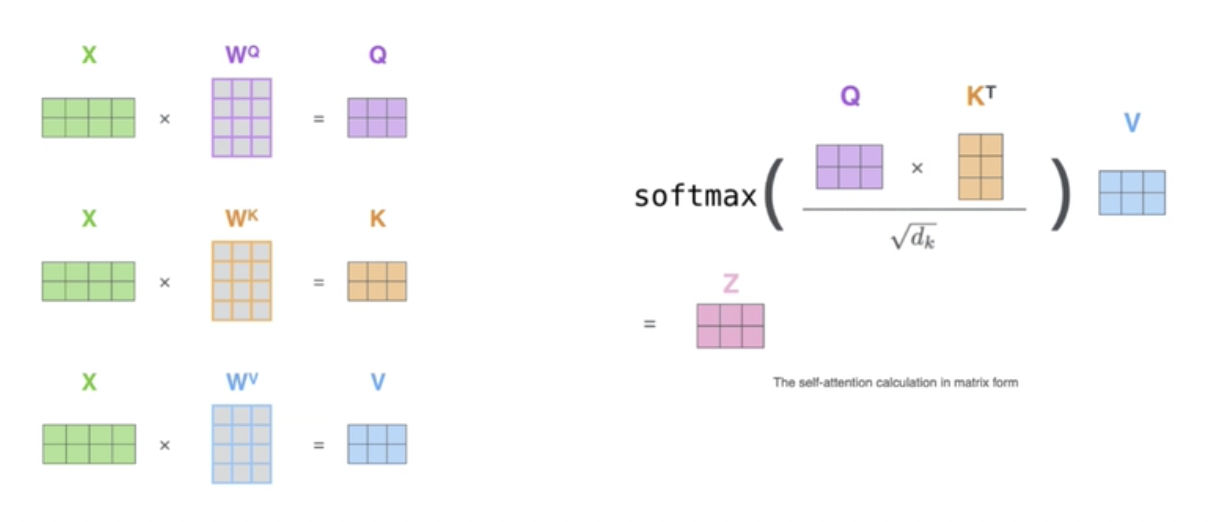
图22 Attention计算并行计算示例
4.2.3. Multi-Head Attention多头注意力机制
前面提到了单头自注意力机制,这是构成多头注意力机制的基础,论文中使用的是Multi-Head Attention,这里的注意力就是Self-Attention。
为什么需要多头注意力机制?因为卷积操作可以输出多通道,不同的通道可以代表的特征信息,Transformer也借鉴了这个思路,这里的head就有点类似于卷积操作中的channel通道。
多头注意力公式,如图23所示。

图23 多头注意力机制计算公式
同样的,举个例子,我们假设有2个head的情况,输入仍然是两个单词编码,这里假设为[a1,a2],然后经过和共享参数相乘得到Q、K、V,经过head 划分以及计算注意力,最终得到值[b1,b2]
- 因为head = 2, 所以把q1和一个矩阵相乘得到[q1_1, q1_2](有的源代代码中使用的是直接相除均分);同样的,q2和一个矩阵相乘得到[q2_1, q2_2].
- 然后利用Attention(Q,K,V)公式计算得到head1计算的输出b1_1,如图24
- 然后利用Attention(Q,K,V)公式计算得到head2计算的输出b1_2,如图25
- 再把b1_1,b1_2拼接concat[b1_1, b1_2]
- 和一个矩阵相乘得到一个值b1,如图26
- 重复上面步骤,可以得到另一个值b2
- 最终[a1,a2]经过多头注意力机制得到[b1,b2]

图24 多头注意力机制计算b1_1
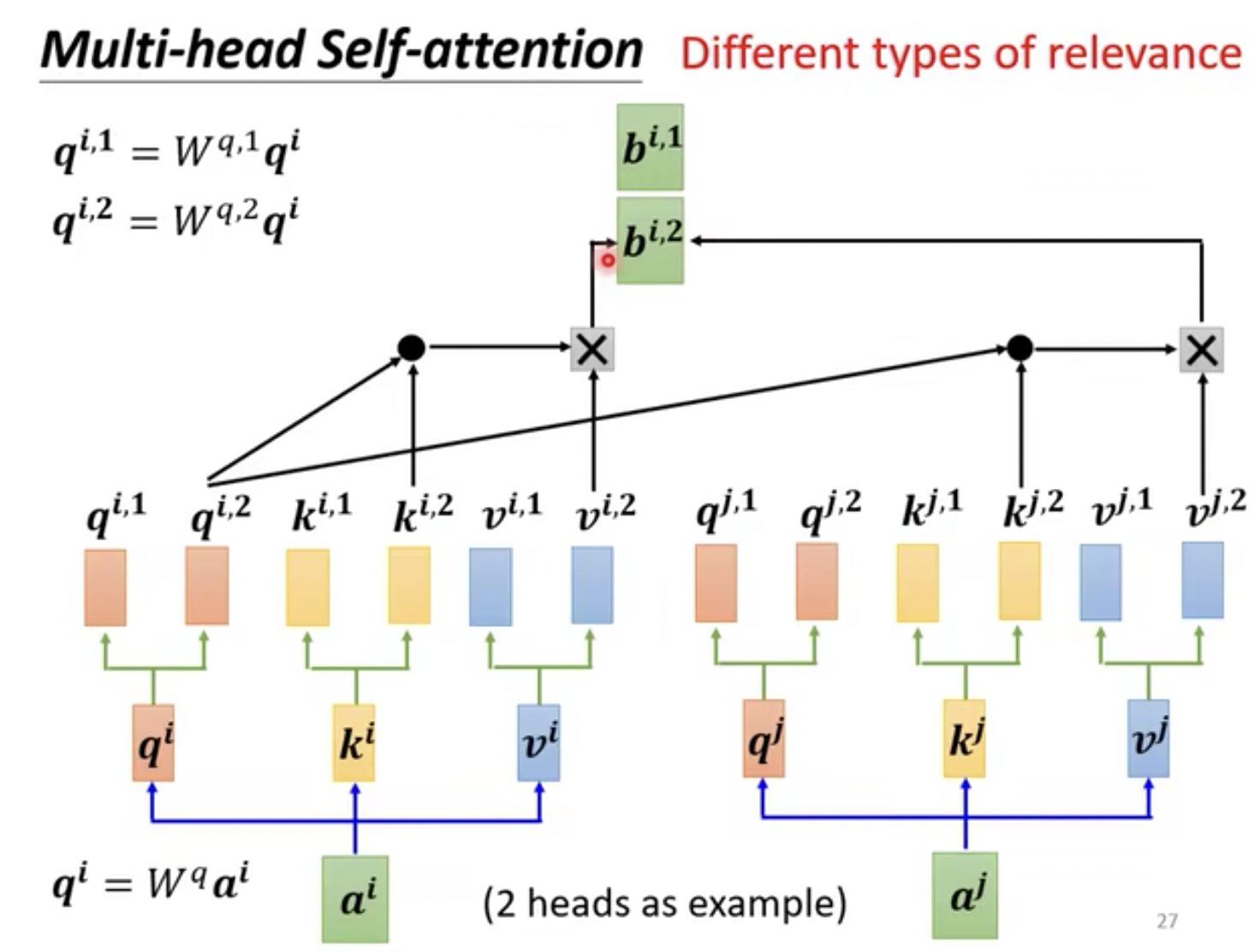
图25 多头注意力机制计算b1_2
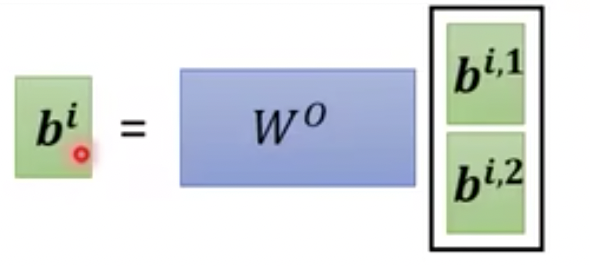
图26 多头注意力机制计算b1
4.2.4. Add残差机制
我们可以发现的是,在论文的Encoder部分中如图27所示,还有一个Add & Norm,这里的Add代表的就是残差,Norm代表的是Layer Normalization。
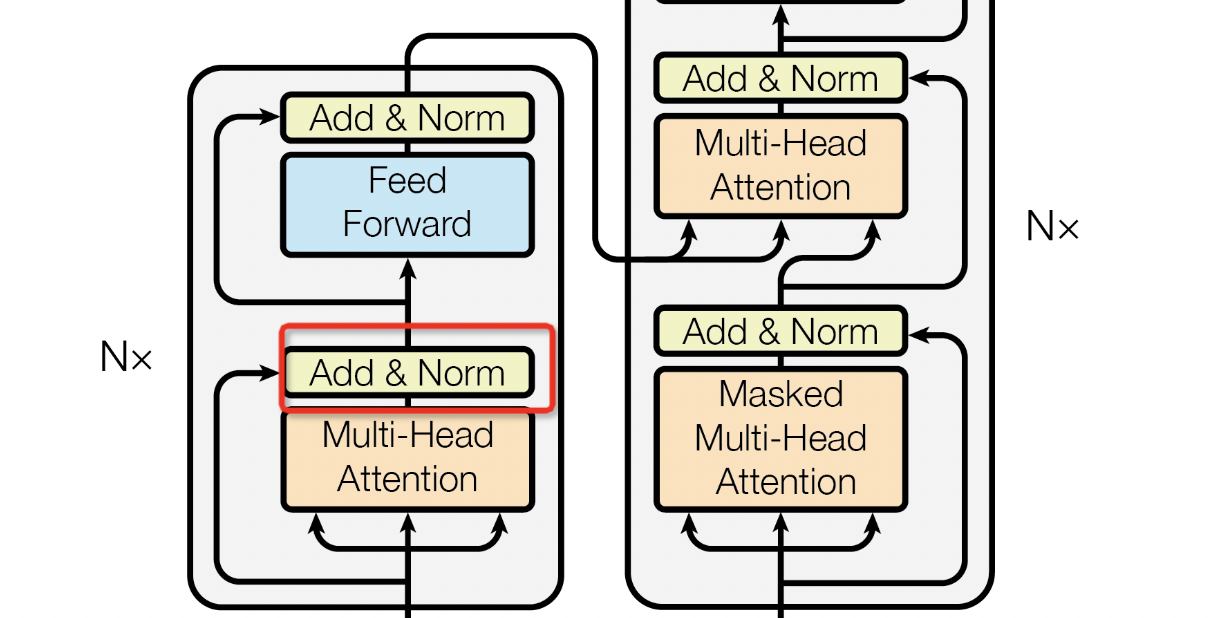
图27 Transformer中残差和归一化
残差网络的概念来源于CV大佬何恺明2015年提出的ResNet,《Deep Residual Learning for Image Recognition》,谷歌学术引用目前176823!!!目前这个backbone仍然是CV届主流的架构之一。
再提一句,凯明大神将于2024年加入MIT,回归学术界~
残差的概念很简单,就是把原始的输入也加入到了经过注意力机制的输出后面,如图28,这就是ResNet中的残差结构,多了一条shortcut分支,也就是等值变换identity。
- 输入为X
- 分之1输出:经过特征提取的值F(X)
- 分支2输出:经过等值变换的值,就是原始的输入X
- 最终输出为X+F(X)
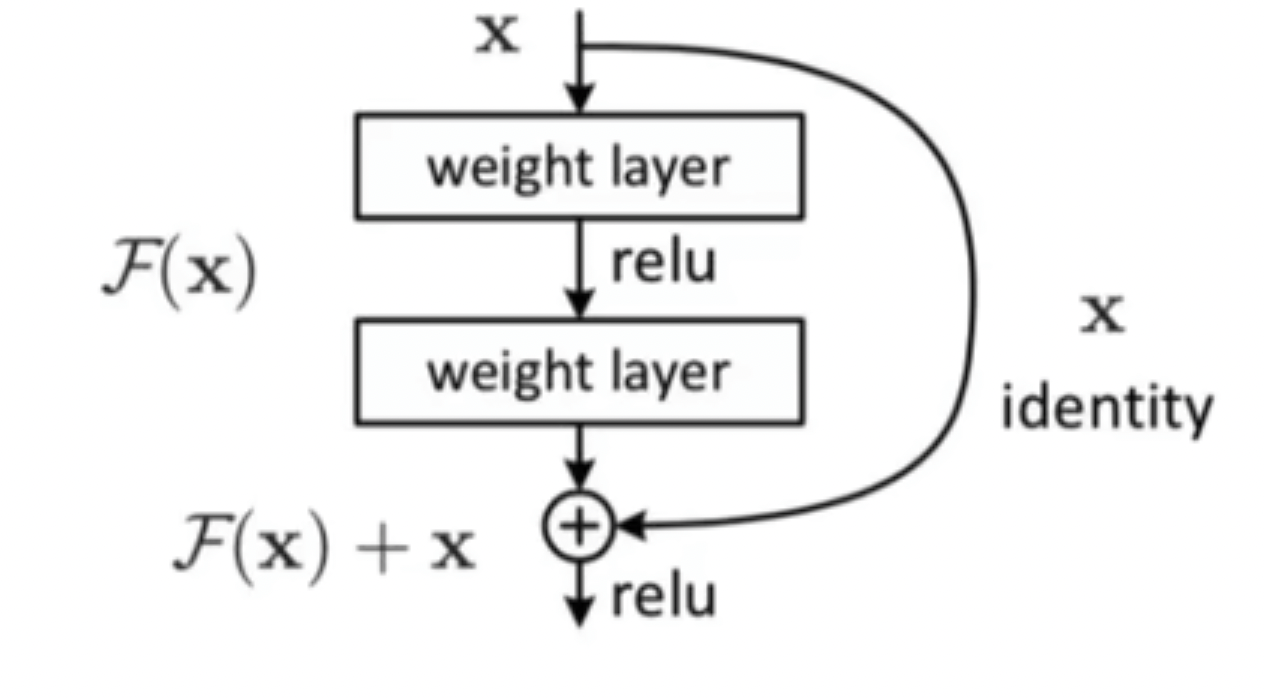
图28 残差结构示意图
同样的,在我们的Encoder结构中,加上残差结构后的输入输出如下所示。
- 输入:X
- 分之1输出:经过注意力计算提取的值Attention(X)
- 分支2输出:经过等值变换的值,就是原始的输入X
- 最终输出为X+Attention(X)
为什么需要残差结构?
原论文中有详细解释,主要是为了解决层数过多时的梯度消失的现象。
也可以通过数学上的链式求导法则来证明。AI离不开数学!
4.2.5. Layer Normalization
可能会遇到一个区分Batch Normalization vs Layer Normalization,也就是BN vs LN
- CV里面BN用的多
- NLP里面LN用的多
- 相似点,都是‘强迫’数据保持均值为0,方差为1的正态分布
- BN:批处理归一化,主要针对的是一个batch里面,所有的样本相同维度比如一堆图片,计算图片R、G、B三个通道的均值和方差。
- LN:层归一化,主要针对的是一个样本里面,不同维度取均值和方差。因为如果当文本长度差距比较大的时候,有的文本比如长度为1,有的文本长度为1000000,这样针对所有样本做BN,其实是效果不行的。【论文中用的是LN】
举个例子,如图29所示,这里假设的是二维输入【实际上文本输入是三维的】,假如前面9个文本都是有5个单词构成,第10个文本有20个单词。如果是做BN的话,会默认所有样本的相同位置的字都是有相似的含义的,比如“我”、“今”、“生”、...、“这”都是属于样本的第1个位置,显然他们含义不一样。LN的处理就是默认一个样本里面假设他们的语义信息是有相关性的,所以用来计算均值和方差。
- “我喜欢打球”
- “今天天气好”
- “生活很美好”
- ...
- “这句话仅仅只是个例子为了保持长度等于二十”
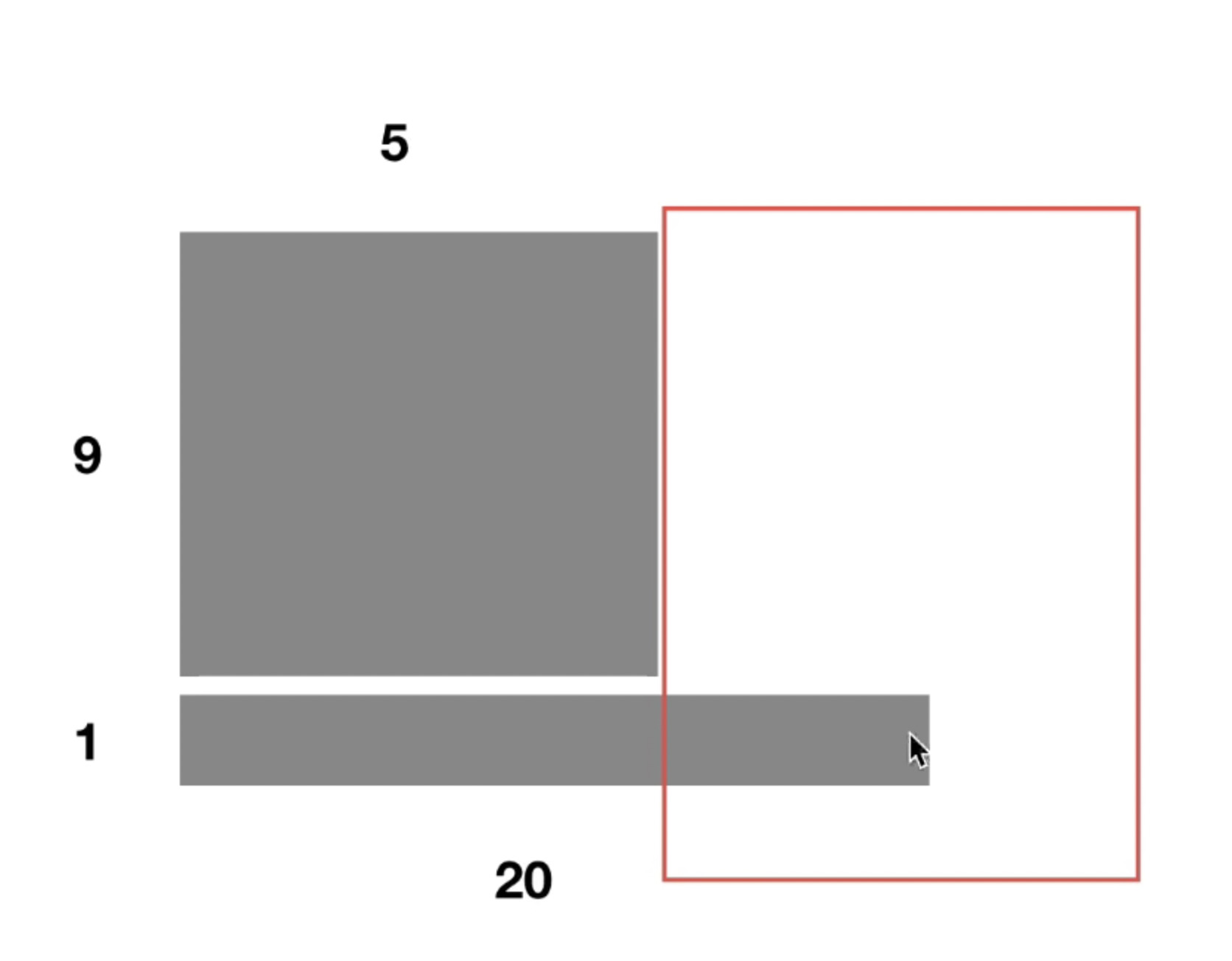
图29 BN和LN示例
4.2.6. Feed Forward前馈神经网络
直接上公式,如图30所示,其实就是两个全连接层FC(或者叫只有一个隐藏层的MLP)
- 第一个全连接层(xW1 + b1)会把维度从512变换到2048维
- 然后经过Max函数,也就是ReLU激活函数
- 然后第二个全连接层会把维度从2048变回原来的512维,保持了输入输出维度一致,因为还有残差连接。
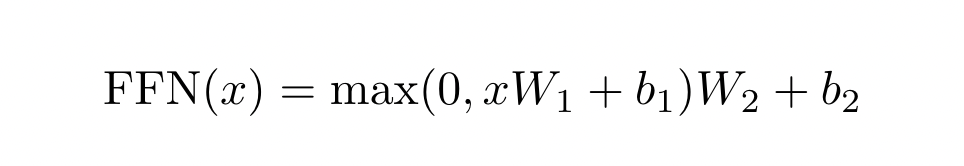
图30 FFN公式计算示例
不过值得注意的是,Encoder会堆叠N次,论文中N取值为6(Decoder也是堆叠6次),如图31所示。

图31 Encoder堆叠次数
4.3. Decoder解码器
在解码器部分,主要结构和Encoder结构有点类似,如图32所示,不同点主要是:
- 第一个注意力是遮掩后的多头注意力机制Masked Multi-Head Attention
- 第二个多头注意力的输入部分其中1个来源于Masked Multi-Head Attention,其中2个来源于Encoder编码器,这里有个cross attention的概念。
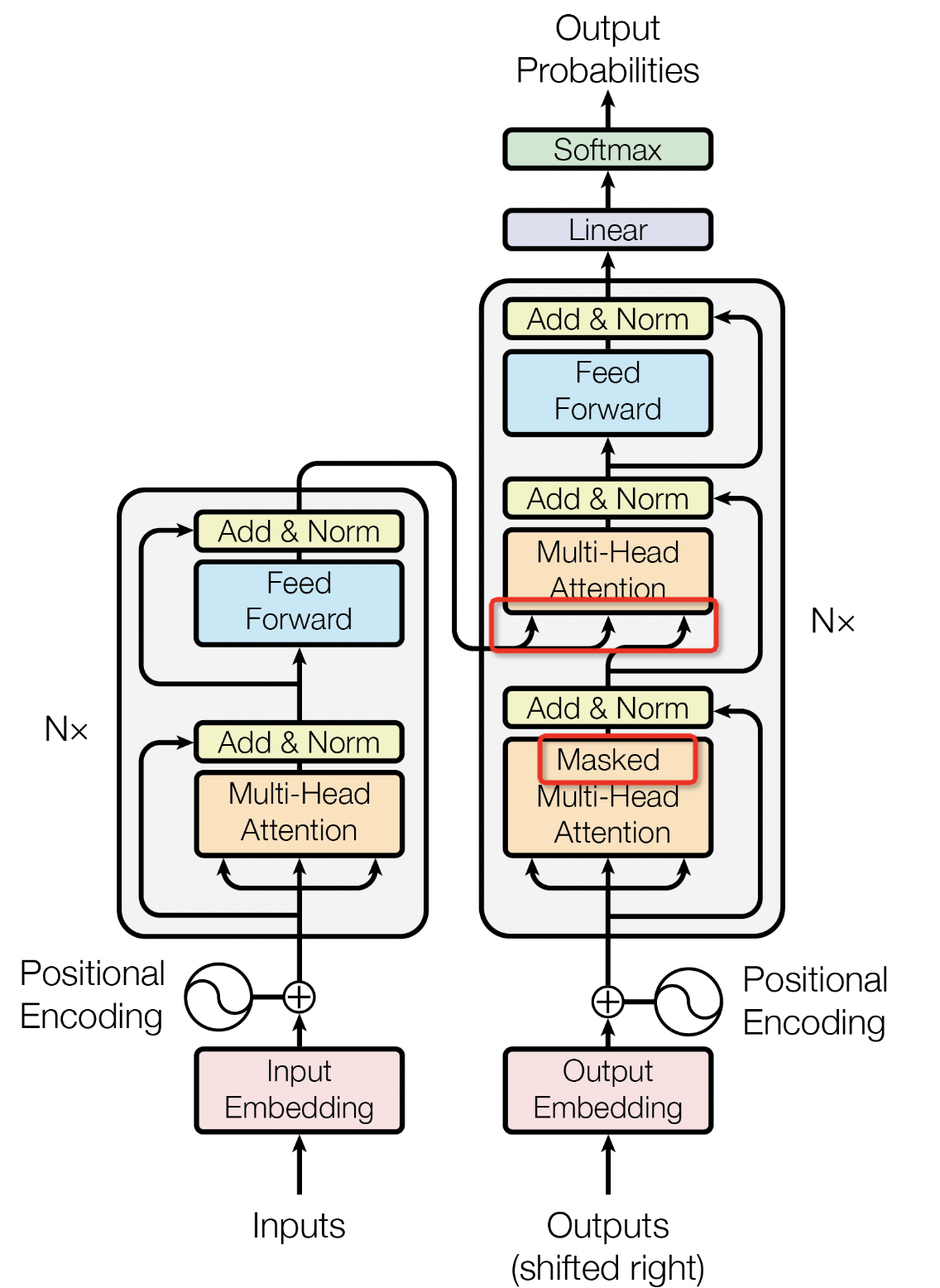
图32 Encoder和 Decoder部分对比
4.3.1. Masked Multi-Head Attention
首先Decoder中的输入部分,首先是来源于output编码后的向量,比如在机器翻译任务中的话,input是“hello world”,output对应的ground truth就是“你好世界”。比如在语音翻译任务中,input是“机器学习”的语音,output对应的ground truth就是“机器学习”文本。
现在把output输入到Masked Multi-Head Attention模块中,跟Multi-Head Attention计算类似,唯一的不同是在计算当前单词的时候,会遮挡住当前单词以及当前单词后续的词(会加入2个特殊符号,一个是BEGIN开始符号,一个END结束符号)。
举个例子,比如是正常的Self-Attention时候,如图33所示。
- 想要输出b1需要结合输入a1,a2,a3,a4
- 想要输出b2需要结合输入a1,a2,a3,a4
- 想要输出b3需要结合输入a1,a2,a3,a4
- 想要输出b4需要结合输入a1,a2,a3,a4
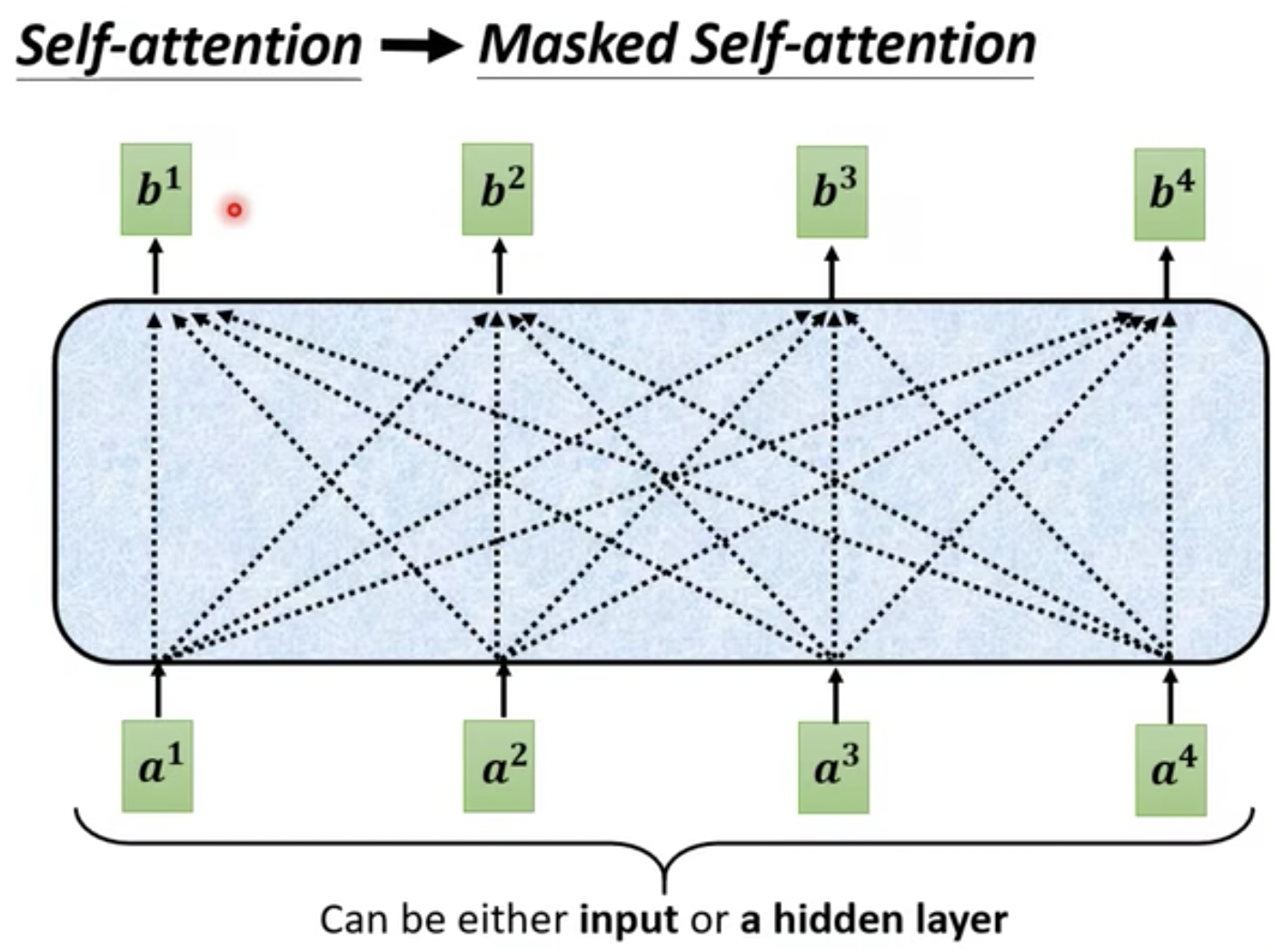
图33 正常的Self-Attention示例
如果是Masked Self-Attention时,如图34所示。
- 想要输出b1需要结合输入a1
- 想要输出b2需要结合输入a1,a2
- 想要输出b3需要结合输入a1,a2,a3
- 想要输出b4需要结合输入a1,a2,a3,a4

图34 Masked Self-Attention示例
更全面的展示,和上面的举例子对应起来就是如图35所示。
- 这里的Decoder的输出部分“机 器 学 习”对应着图34的[b1 b2 b3 b4]
- 这里的Decoder的输入部分“BEGIN 机 器 学”对应着图34的[a1 a2 a3 a4]
- 这里为了和上面对应,还有一个步骤没有画出来,就是会把“习”继续作为Decoder 输入,然后Decoder输出一个“END”符号,那么就结束。
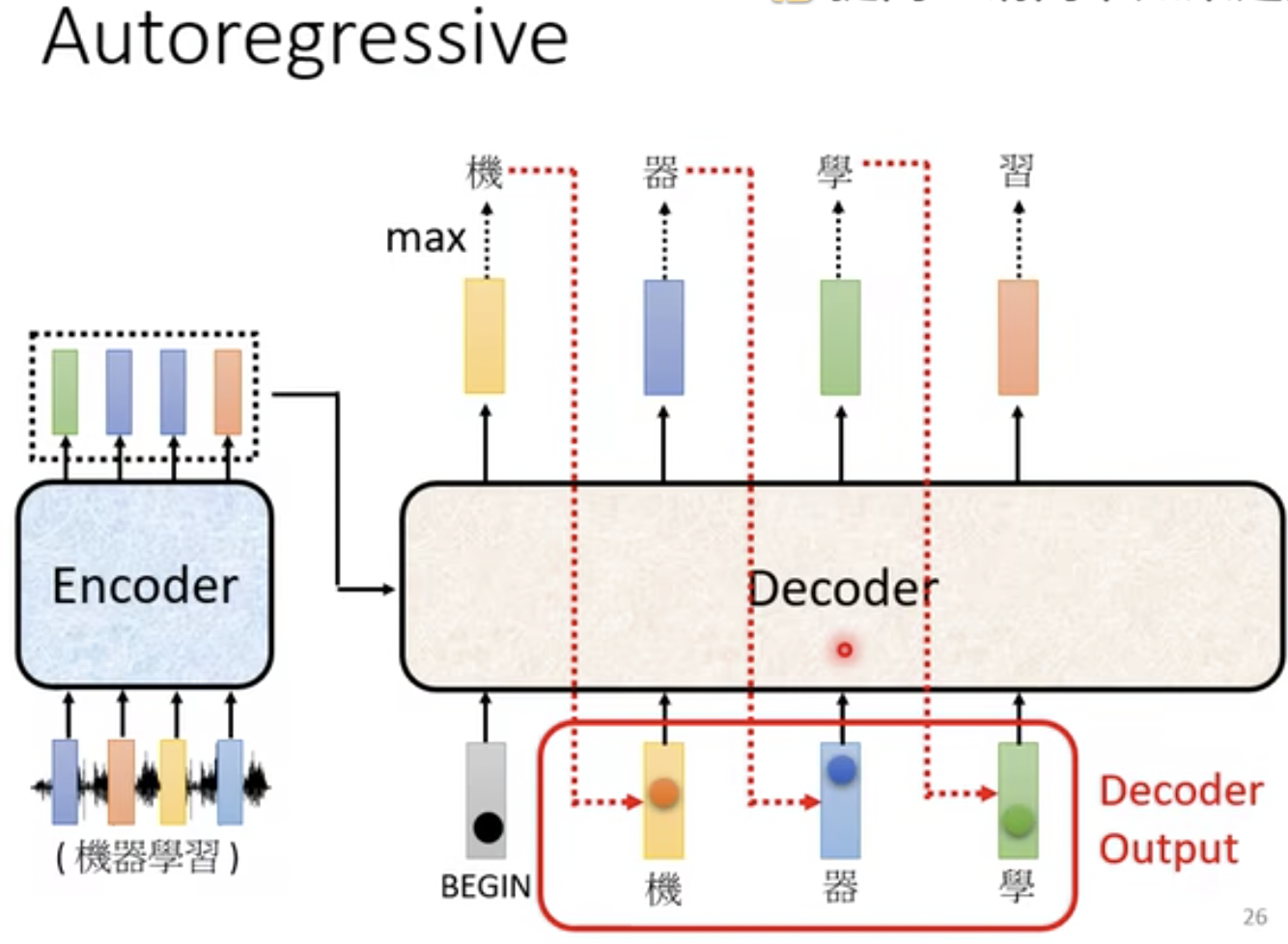
图35 Masked Self-Attention示例
为什么需要mask ?
其实这个跟预测输出的时候,我不能把输出值告诉你有点像,只能通过模型来预测。比如我想要知道这个语音对应的翻译是“机”,我不能把文字“机”也直接输送到模型里面。
4.3.2. Multi-Head Attention
Decoder解码器中的多头注意力机制的QKV来源于Encoder编码器和Decoder解码器,编码器提供K和V,解码器提供Q,如图36所示。
- 解码器Decoder提供的是q,就是一个query,比如是包含BEGIN特殊字符相关信息的
- 编码器Encoder提供的是k1,v1,k2,v2,k3,v3,通过Attention公式计算后得到加权后的值v。所以这里是cross attention.
- 这个值v会经过Add & norm模块、Feed Forward模块、Add & norm模块,然后重复堆叠Decoder模块,如上面提到的图32部分。
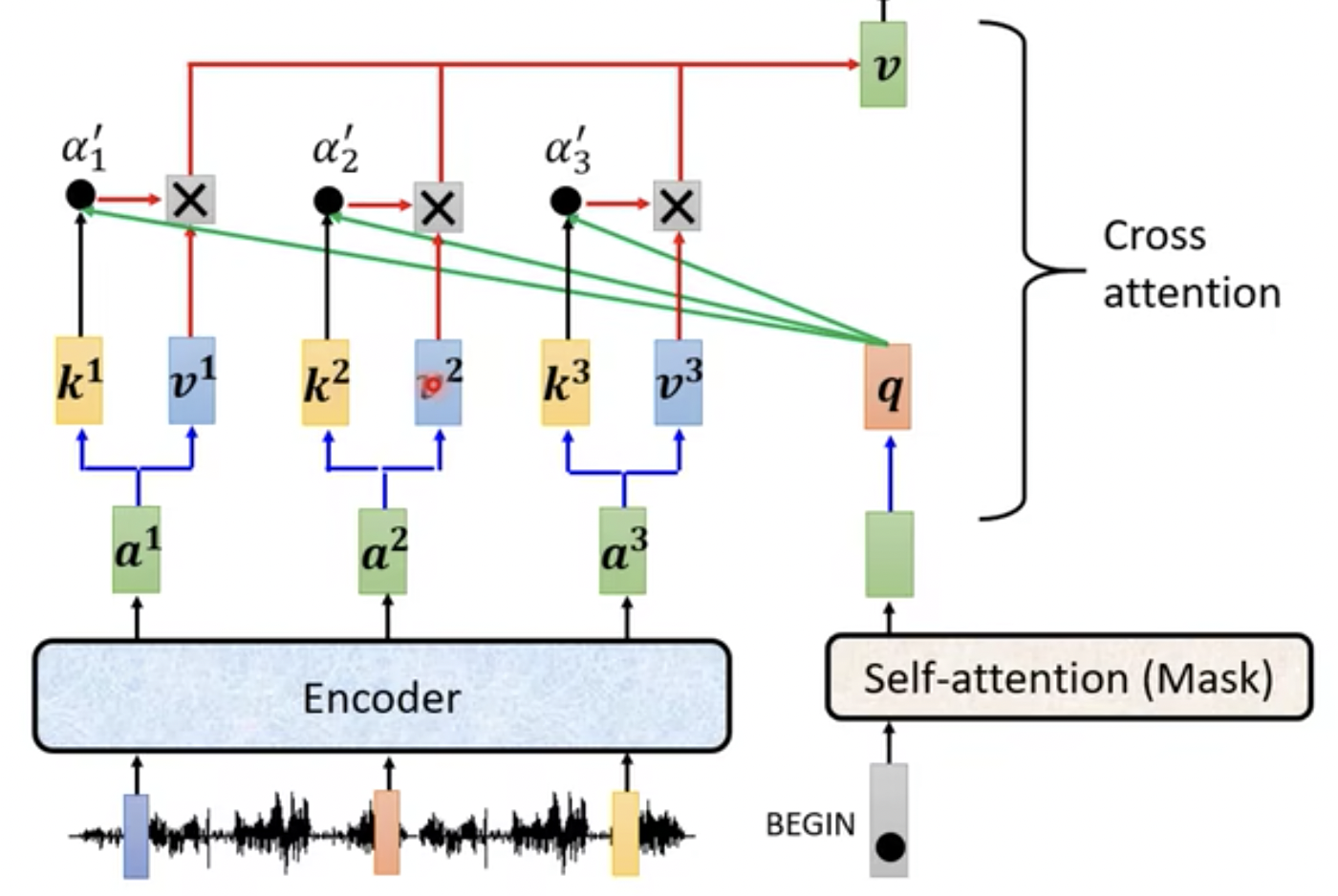
图36 Cross Attention示例
4.4. output
终于终于来到了输出部分
这里主要是一个线性层+softmax,如图37所示。
- input 是把所有的数据一次性扔进去
- output 是一个词一个词的扔进去
- 在经过多个Decoder解码器后,比如output 输入的是“BEGIN”字符,最后经过线性层Linear、Softmax层后输出预测的概率,选取概率最大的值就是我们模型最终的预测输出。
s

图37 output 示例
5. 参考链接
Text-to-SQL小白入门(一) - 知乎
https://arxiv.org/pdf/1706.03762.pdf
3.多头注意力机制详解_哔哩哔哩_bilibili
12.【李宏毅机器学习2021】Transformer (上)_哔哩哔哩_bilibili
Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
Transformer中Self-Attention以及Multi-Head Attention详解_哔哩哔哩_bilibili
参考了很多B站大佬视频,强推
讲的有不对的地方,请批评指正,感谢