本文我们来学习递归神经网络(Recursive Neural Network,RecNN),其是循环神经网络在有向无循环图上的扩展 。
递归神经网络是一类专门设计来处理具有层次结构或树形结构的数据的神经网络模型。它与更常见的循环神经网络(Recurrent Neural Network, RNN)在处理数据的方式上有所不同。
递归神经网络的一般结构为树状的层次结构:
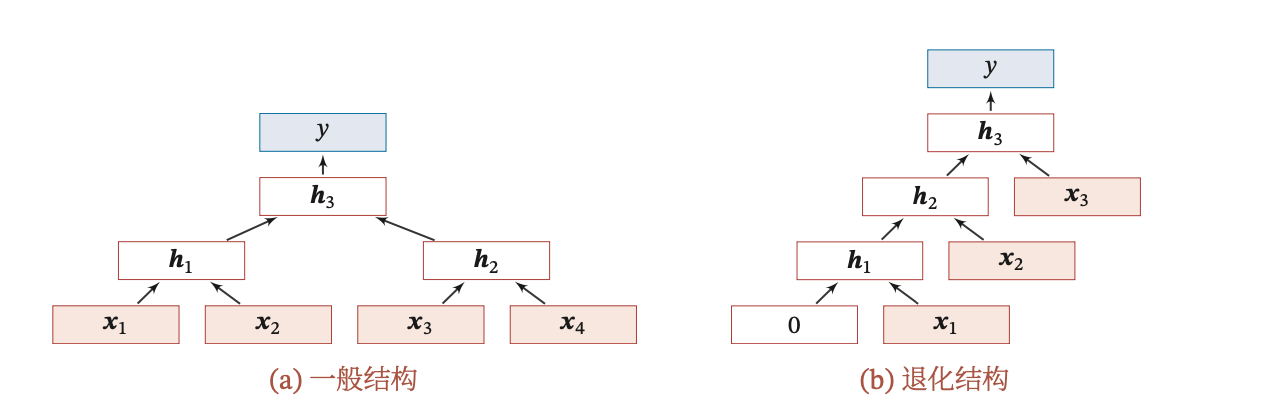
上图所示的递归神经网络具体可以写为:
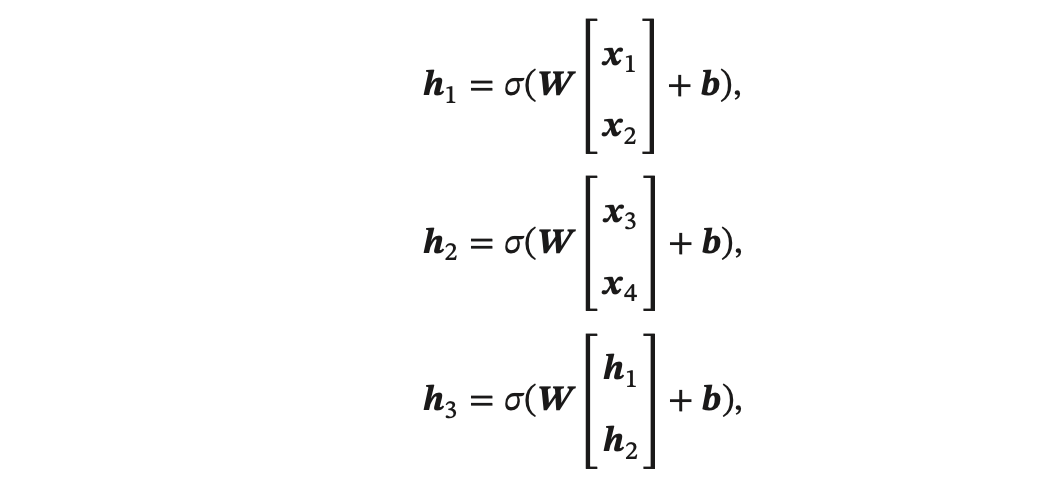
其中 𝜎(⋅) 表示非线性激活函数,𝑾 和 𝒃 是可学习的参数.同样,输出层 𝑦 可以为 一个分类器,比如:
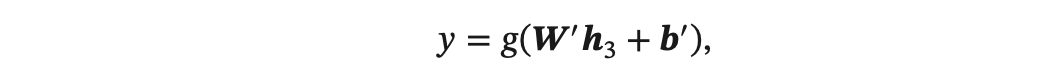
当递归神经网络的结构退化为线性序列结构时,递归神经网络就等价于简单循环网络。
下面将从原理、结构以及具体案例三个方面来解释这一模型,同时说明它与简单循环网络的联系和区别。
1. 递归神经网络的基本原理
-
数据结构导向
递归神经网络主要用于处理树形结构的数据,例如语句的句法解析树、情感分析中短语的结构、或抽象语法树等。它假设输入数据天然地构成一个分层的结构,每个节点代表了一个局部单元(如单词或短语),而非简单地按照时间顺序排列。 -
递归组合操作
在递归神经网络中,模型会对树的每个内部节点进行递归计算。具体来说,对树中每个非叶子节点,其向量表示通常通过对其子节点表示进行组合来获得。数学上可以表示为: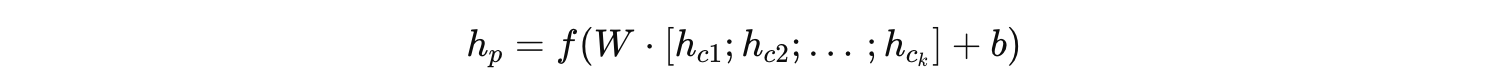
其中,hp 表示父节点的表示;hc1,hc2,…,hck 分别表示该父节点的各个子节点表示;矩阵 W 和偏置 b 是该递归组合操作的共享参数;ff 是非线性激活函数。整个树中,这一相同的组合函数被递归地应用,每次都是利用相同的参数来获得更高层次的抽象。
-
参数共享
与循环神经网络类似,递归神经网络在整个树结构中对所有组合操作使用相同的一组参数。这种参数共享使得模型不仅能减少需要学习的参数量,还能捕捉数据结构中普遍存在的规则和规律。
2. 与简单循环网络的联系和区别
联系
-
核心思想相似
无论是递归神经网络还是循环神经网络,都利用了“重复应用相同函数”的思想。两者都通过不断组合前面的信息来构建更复杂的表示,并且都采用参数共享的方式,从而简化模型学习问题。 -
参数共享机制
二者在各自的结构中都使用了相同的参数对多次重复的操作进行计算,只不过递归神经网络是在树的不同层次上递归应用,而循环神经网络则是在时间步骤上反复应用同一操作。
区别
-
数据结构不同
-
递归神经网络(RecNN):针对树形或层次结构数据,适用于解析具有自然层次结构的问题,如自然语言中的句法树、情感分析的短语递归组合、图像场景分割中的层次关系等。
-
循环神经网络(RNN):针对一维序列数据,例如时间序列、语音、文本、视频帧等,利用前一个时间步的隐藏状态来预测当前或未来的状态。
-
-
信息组合方式
在递归神经网络中,一个节点的表示通常同时依赖多个子节点的信息(如左右子节点或多个分支),而在简单循环神经网络中,当前状态通常仅依赖于当前输入和前一个时间步的隐藏状态,形成一条链式信息流。 -
应用场景
-
递归神经网络常用于需要理解数据内部结构层次(比如理解一个句子的整体语义)的任务。
-
循环神经网络更适合需要处理连续时间依赖信息(如语言生成或时间序列预测)的任务。
-
3. 具体案例
例子:自然语言处理中的句法分析
假设我们有一句话“这个电影非常精彩”,可以将其句子转化成一棵句法树,树中每个叶子节点是单词,而非叶子节点代表短语。
-
递归神经网络的应用:
-
叶子节点:各单词首先通过词嵌入获得对应的向量表示;
-
组合操作:然后使用相同的递归网络组合这些单词向量,首先合并构成短语,例如将“这个电影”组合成一个短语表示,再将“非常”和“精彩”组合,然后将这两个短语的表示再递归组合成整个句子的表示;
-
这种自底向上的组合能够有效捕捉句子内部语法和语义的层次关系,生成一个整体句子表示供后续任务(如情感分类或机器翻译)使用。
-
相较之下,若采用简单的循环神经网络处理同样的句子,信息会沿着时间序列顺序传递,主要依赖上一时刻的隐藏状态,未必能充分利用句子结构中的层次信息。
4. 参数学习
递归神经网络(Recursive Neural Network, RecNN)的参数学习本质上也是基于梯度下降的优化过程,不过由于其特殊的树形(或更一般的递归)结构,其误差传播方式需要“沿树”进行,即“结构反向传播”(Backpropagation Through Structure, BPTS)。
(1)前向传播和表示组合
在递归神经网络中,每个内部节点的表示是通过对其子节点表示进行组合来获得的。例如,对于一个二叉树结构,一个父节点的向量表示可写作:
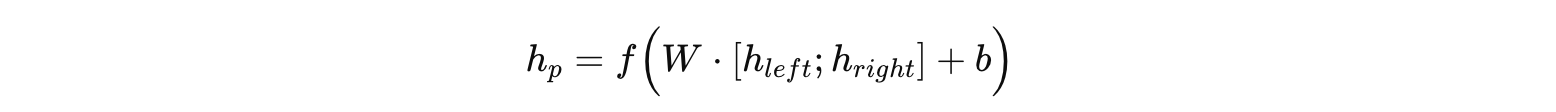
其中:
-
h_{left} 和 h_{right} 是左右子节点的表示,
-
W 是组合权重矩阵,
-
b 是偏置,
-
f 是非线性激活函数(如 tanh 或 ReLU)。
这一过程会递归地向上计算,直到生成根节点或最终任务所需的整体表示。
(2)损失函数定义
通常,在某个高层(例如根节点)会得到一个整体表示,然后根据该表示完成某项任务(如分类、情感分析等)。这时我们会定义一个损失函数,如交叉熵(对于分类任务)来衡量预测输出与真实标签之间的差距。
(3) 反向传播——结构反向传播(BPTS)
由于递归神经网络的前向计算在树的不同节点上共享同一组参数(例如组合矩阵 W 和偏置 b),在反向传播阶段需要沿着整棵树“展开”来计算梯度,这个过程称为结构反向传播:
-
梯度从根节点开始计算
根据损失函数对根节点输出的偏导数开始,利用链式法则把误差逐层传递到各个子节点。由于每个父节点的输出依赖于它的所有子节点,梯度计算时需要对这些依赖关系进行累加。 -
参数的梯度累加
由于所有节点都使用了相同的参数(例如 W),在整棵树上每次组合操作对参数的贡献都会被计算出来,然后将所有这些梯度累加,得到该参数的总梯度。 -
利用梯度下降更新参数
更新方式与其他深度学习模型类似,例如使用标准的随机梯度下降(SGD)或者自适应方法如 Adam 更新参数:
(4)举个具体例子
假设我们用于情感分析的递归神经网络,其任务是根据一个句子的语法解析树判断情绪。
-
前向传播:
-
每个叶节点(单词)通过词嵌入转换为向量表示。
-
按照树结构,底层的短语节点利用公式
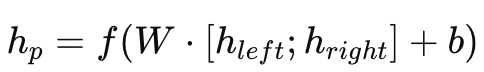 递归计算,从而得到整个句子的表示。
递归计算,从而得到整个句子的表示。
-
-
损失计算:
-
将句子表示输入一个分类层(例如全连接层 + softmax),输出情绪类别概率。
-
利用交叉熵损失计算误差。
-
-
反向传播:
-
损失从句子表示(根节点)反向传播到各个短语节点,再到叶节点。
-
每次梯度计算都使用链式法则,累加到共享参数 W 和 b 上。
-
-
参数更新:
-
使用梯度下降优化算法更新 W 和 b,使得整个树的节点表示逐渐能够更好地反映正确的情绪信息。
-
递归神经网络利用结构反向传播(BPTS)来更新在树形结构中共享的参数,通过在树上从根到叶逐层反传梯度,结合链式法则累积来自各路径的梯度,最终使用优化算法更新参数,从而实现模型在如句法解析、情感分类等任务上的有效学习。这一过程与传统神经网络的反向传播类似,但其梯度传播必须适应数据的树状结构,使得参数能够捕捉到数据中固有的层次关系。
5.结语:
递归神经网络通过将输入数据视为树或层次结构,使用相同的组合函数递归地将子结构信息合成更高层次的表示,非常适合处理具有内在层次结构的问题,如句法解析和情感分析。它与简单循环网络共享“信息传递”与“参数共享”的基本思想,但处理的数据结构和信息组合方式有所不同。理解递归神经网络,可以联想到在一棵树上自下而上地整合各个“叶子”节点的信息,逐步构建出整个树的综合表示。